Elastic search
- [1、认识Elastic search](#1、认识Elastic search)
- 2、倒排索引
- 3、ES概念
- 4、安装ES和Kibana
- 5、安装ik分词器
- 6、拓展词库和停止词
-
- [6.1 进入 ik 分词器的 config 目录](#6.1 进入 ik 分词器的 config 目录)
- [6.2 修改IKAnalyzer.cfg.xml文件](#6.2 修改IKAnalyzer.cfg.xml文件)
- 7、索引库操作
-
- [7.1 mapping属性](#7.1 mapping属性)
- [7.2 新增索引库](#7.2 新增索引库)
- [7.3 删除、查询、修改索引库](#7.3 删除、查询、修改索引库)
- 8、文档操作
-
- [8.1 增加、删、查](#8.1 增加、删、查)
- [8.2 修改](#8.2 修改)
- 9、使用Java代码操作索引库和文档
-
- [9.1 hotel 数据结构分析](#9.1 hotel 数据结构分析)
- [9.2 初始化客户端](#9.2 初始化客户端)
- [9.3 创建索引库](#9.3 创建索引库)
- [9.4 删除和判断索引库是否存在](#9.4 删除和判断索引库是否存在)
- [9.5 查询MySQL数据新增到ES的索引库(新增文档)](#9.5 查询MySQL数据新增到ES的索引库(新增文档))
- [9.6 根据ID查询ES中的文档](#9.6 根据ID查询ES中的文档)
- [9.7 更新文档信息](#9.7 更新文档信息)
- [9.8 删除文档](#9.8 删除文档)
- [9.9 批量导入文档到ES](#9.9 批量导入文档到ES)
- 10、DSL分类
- 11、简单查询
-
- [11.1 全文检索查询](#11.1 全文检索查询)
- [11.2 精确查询](#11.2 精确查询)
- [11.3 地理查询](#11.3 地理查询)
- 12、复合查询
-
- [12.1 function score 算分函数查询](#12.1 function score 算分函数查询)
- 学习
的Elastic search写的笔记,笔记基于老师的PPT😄
1、认识Elastic search
📕 搜索引擎技术排名:
🖊 Elasticsearch:开源的分布式搜索引擎
🖊 Splunk:商业项目
🖊 Solr:Apache的开源搜索引擎
📕 Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/
📕 Lucene的优势:
🖊 易扩展
🖊 高性能(基于倒排索引)
📕 2004年Shay Banon基于Lucene开发了Compass
📕 2010年Shay Banon 重写了Compass,取名为Elasticsearch
📕 官网地址:https://www.elastic.co/cn/
📕 elasticsearch具备下列优势:
🖊 支持分布式,可水平扩展
🖊 提供Restful接口,可被任何语言调用
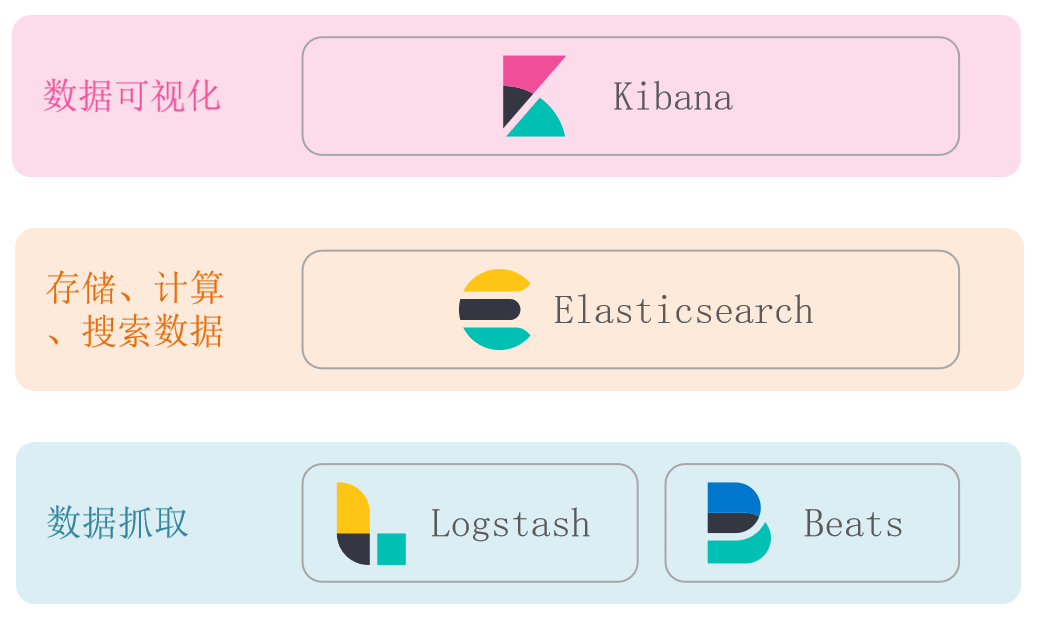
📕 elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
2、倒排索引
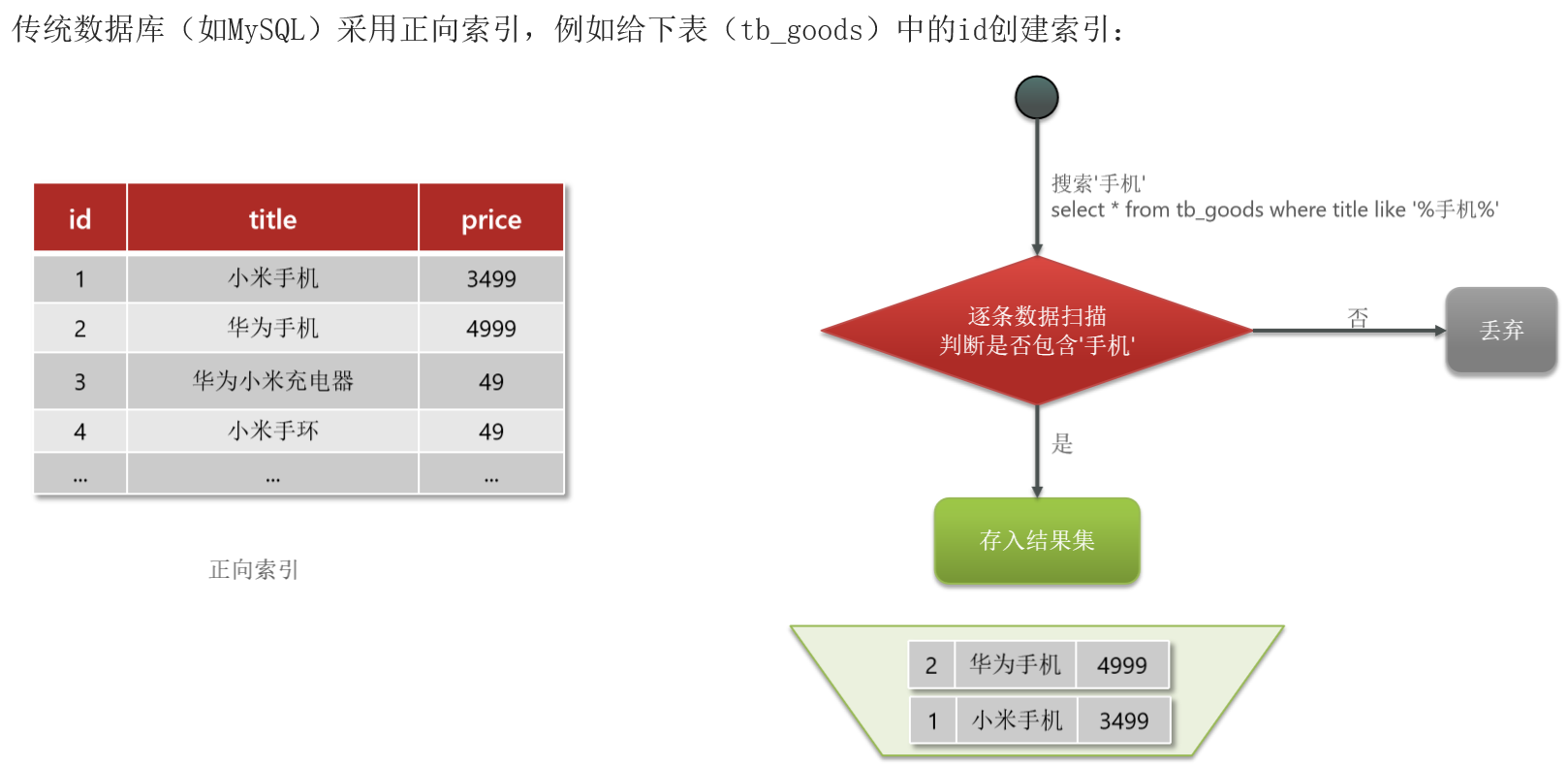
- 传统数据库以正向索引为主,它是 "
记录行 → 关键字段" 的映射,存储的是主键或索引列值对应的数据行地址,适合 ID、订单号这类结构化字段的精准查询,但对全文模糊匹配支持较差- 倒排索引是 "
关键字 → 记录文档" 的映射,核心存储词项对应的文档 ID 列表,专为全文检索、关键词匹配设计
📕elasticsearch采用倒排索引:
🖊 文档(document):每条数据就是一个文档
🖊 词条(term):文档按照语义分成的词语
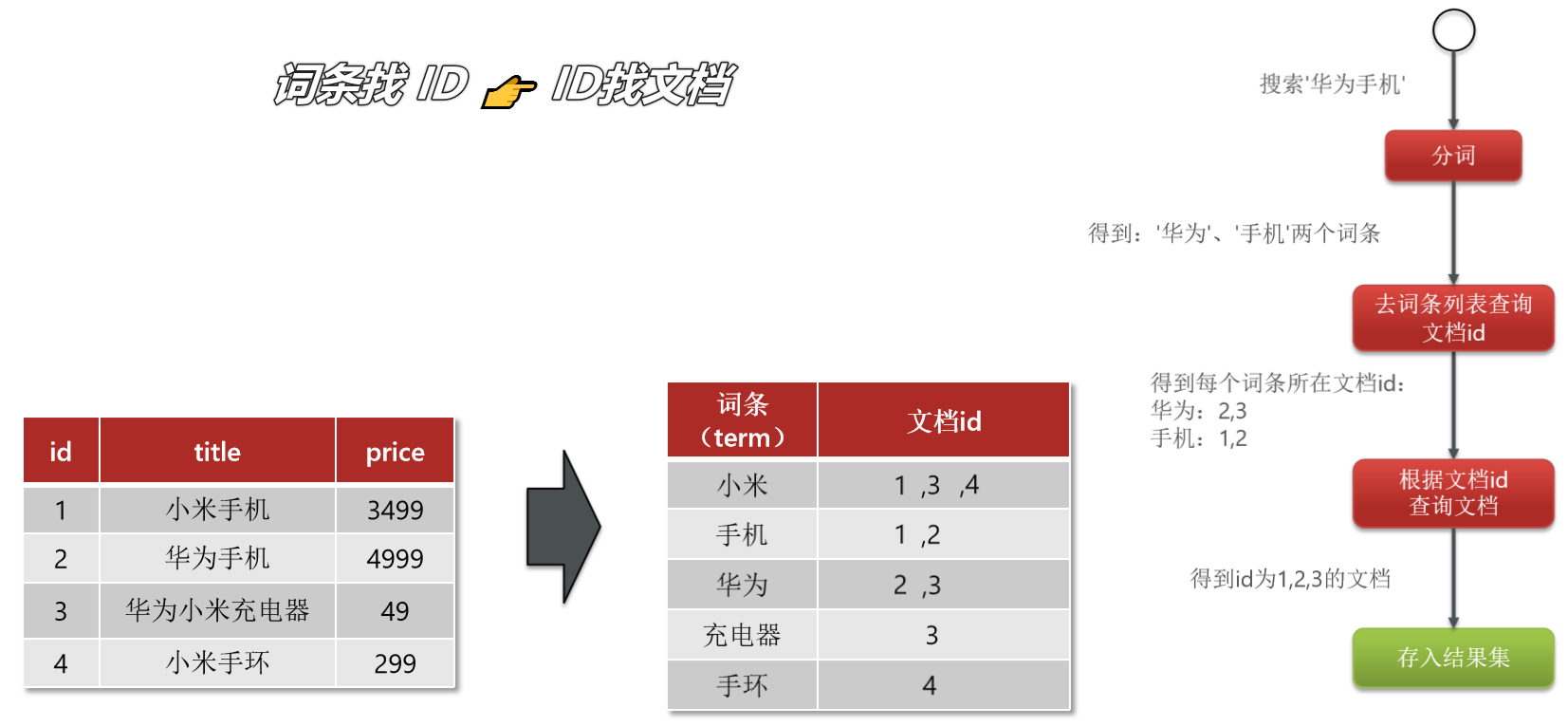
❓ 什么是文档和词条?
🖊 每一条数据 就是一个文档
🖊 对文档 中的内容分词 ,得到的词语就是词条
❓ 什么是正向索引?
🖊 基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
❓ 什么是倒排索引?
🖊 对文档内容分词,对词条创建索引,并记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档
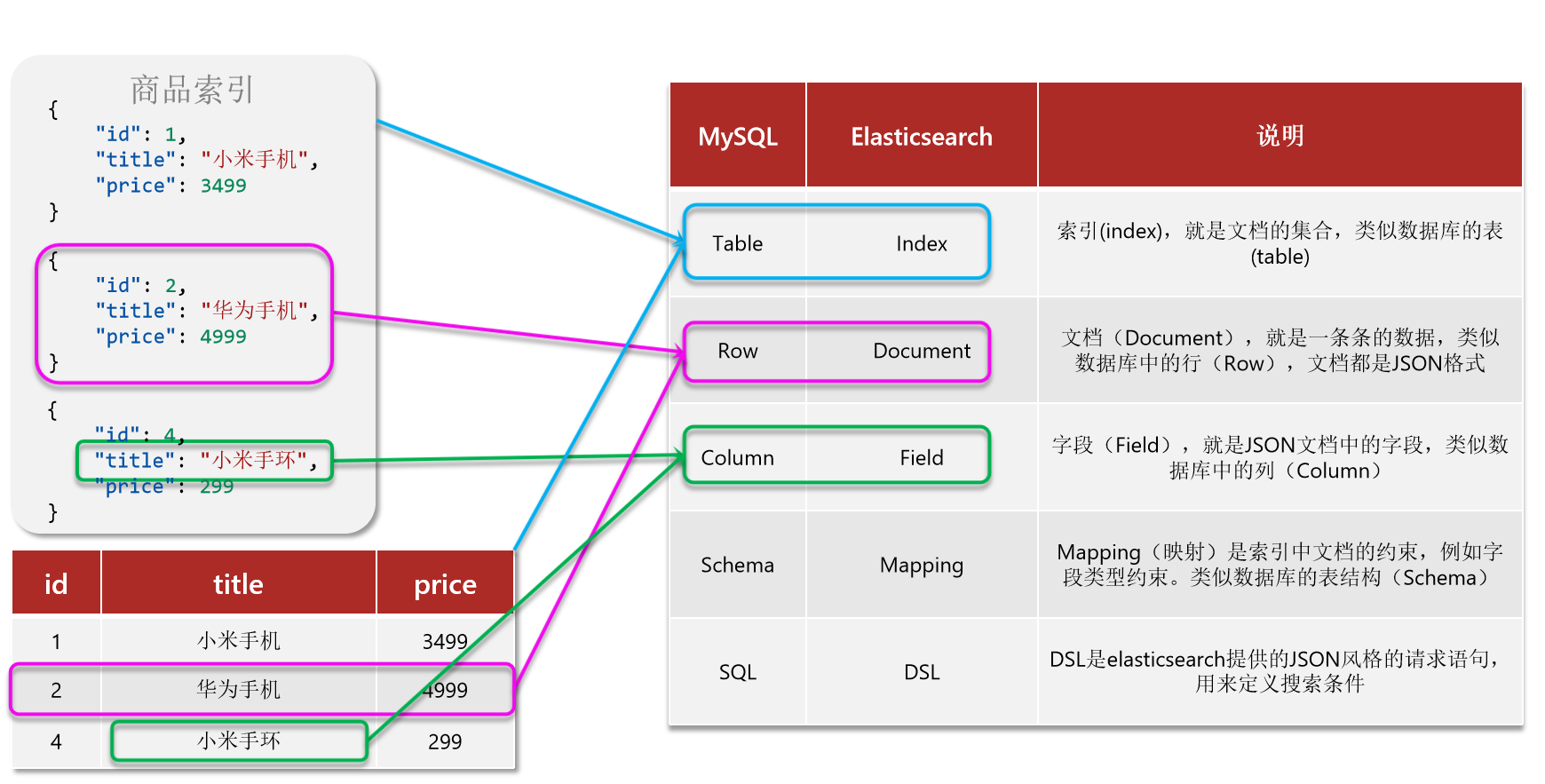
3、ES概念

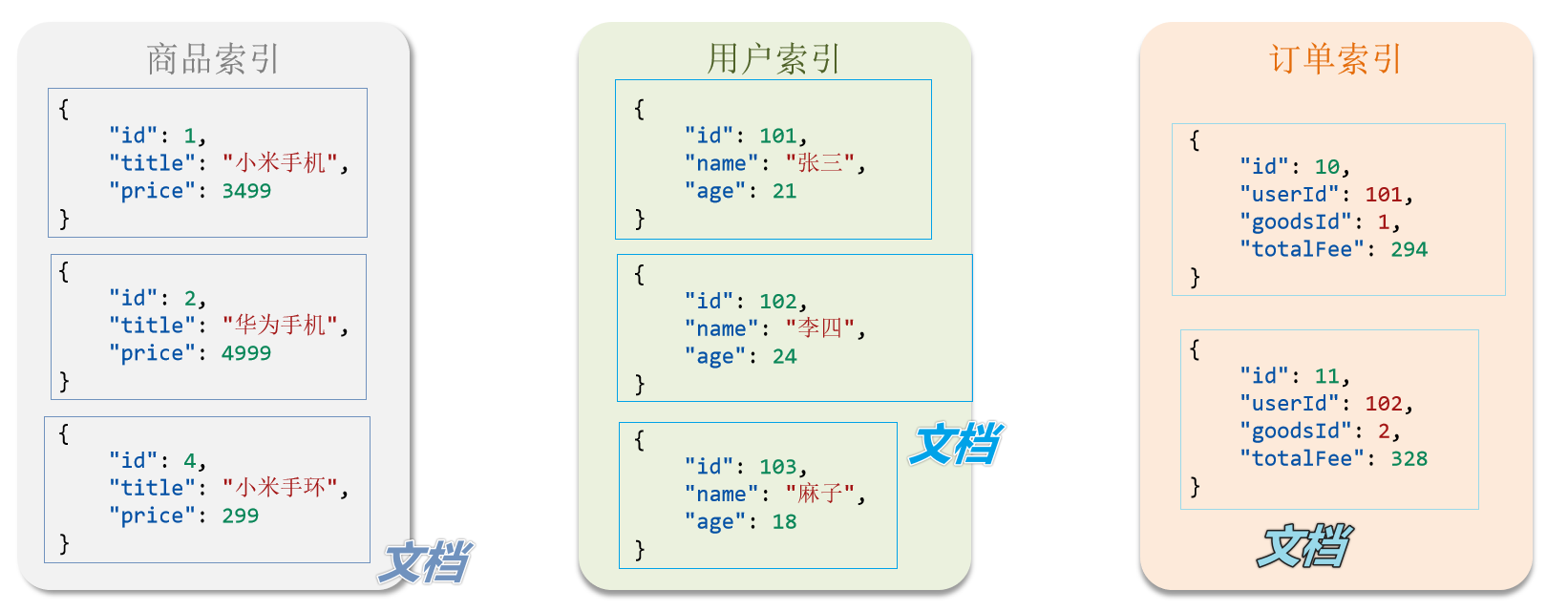
📕 es是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息
📕 文档数据会被序列化为json格式后存储在elasticsearch中
📕 索引(index):相同类型的文档 的集合
📕 映射(mapping):索引中文档的字段约束信息,类似表的结构约束
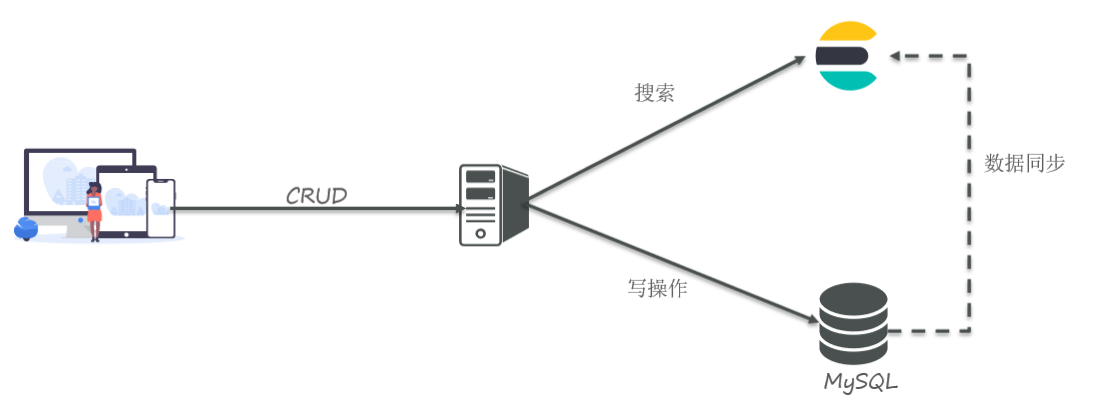
📕 MySQL擅长事务类型操作,确保数据安全和一致性
📕 ES擅长海量数据的搜索 、分析、计算
4、安装ES和Kibana
https://blog.csdn.net/m0_54189068/article/details/157259100
5、安装ik分词器
📕 es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。(默认的分词器不认识中文)



https://blog.csdn.net/m0_54189068/article/details/157259100
📕 ik分词器包含两种模式:
🖊 ik_smart:最少切分,粗粒度
🖊 ik_max_word:最细切分,细粒度
6、拓展词库和停止词
6.1 进入 ik 分词器的 config 目录
- 👇 查看ik分词器在哪个目录下面
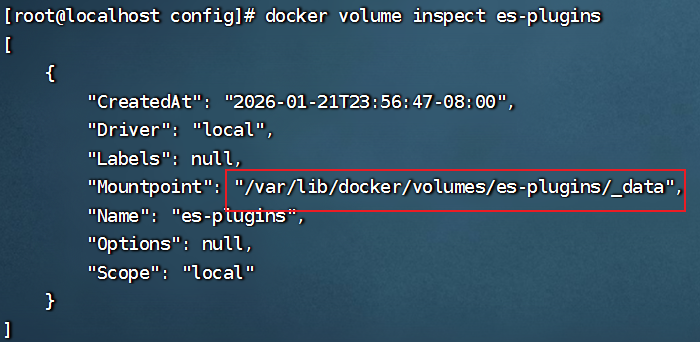
shell
docker volume inspect es-plugins- 6.2 进入config目录
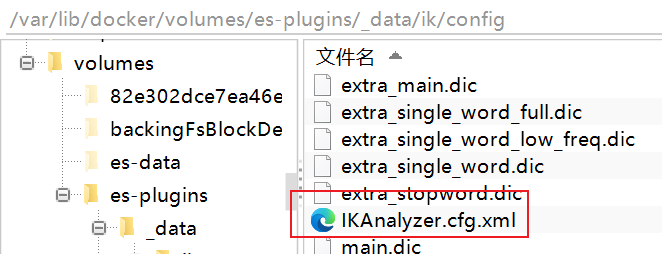
6.2 修改IKAnalyzer.cfg.xml文件
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my_new_word.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
这些文件和IKAnalyzer.cfg.xml文件放同一个目录下
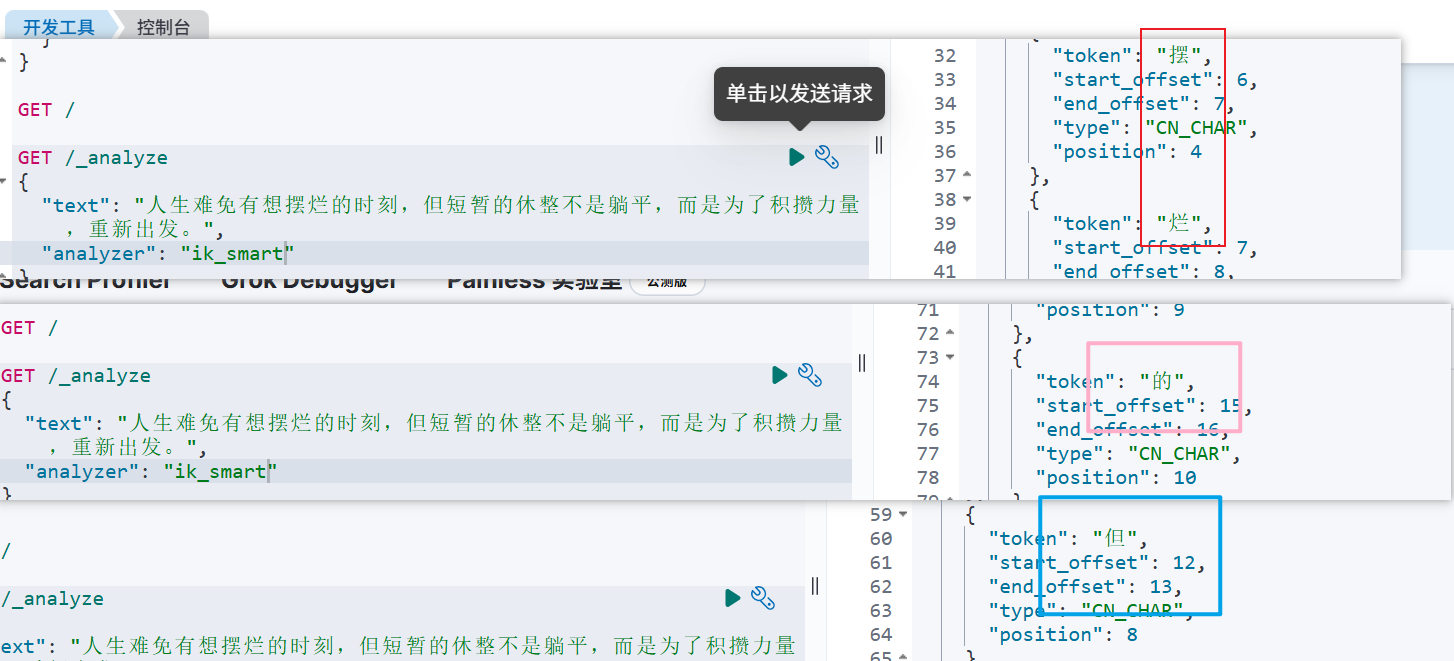
❓ 没有效果,目前没有解决
7、索引库操作
7.1 mapping属性
📕 mapping是对 索引库 中 文档 的约束,常见的 mapping 属性包括:
🖊 index:是否创建索引,默认为true
🖊 analyzer:使用哪种分词器
🖊 properties:该字段的子字段
🖊 type:字段数据类型,常见的简单类型有:
- 字符串:text (可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object




7.2 新增索引库
📕 ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

json
PUT /student
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart" # 使用ik分词器
},
"email": {
"type": "keyword",
"index": "false" # 不参与搜索
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword" # 参与搜索,但是使用的是默认的分词器
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
7.3 删除、查询、修改索引库

json
GET /student
DELETE /student 
json
PUT /student/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}8、文档操作
8.1 增加、删、查

json
POST /student/_doc/666
{
"age": 6,
"info": "世界上最幸运的人之一",
"email": "luckyboy@qq.com",
"name": {
"firstName": "国庆",
"lastName": "张"
}
}
GET /student/_doc/666
DELETE /student/_doc/666
8.2 修改

json
# 增量修改(只修改部分内容)
POST /student/_update/666
{
"doc": {
"age": 8,
"info": "世界上最幸运和健康的人之一",
"name": {
"firstName": "天易"
}
}
}
# 全量修改(把之前ID的文档删除,然后新增)
PUT /student/_doc/666
{
"name": {
"firstName": "天易",
"lastName": "张"
},
"age": 16,
"email": "happy@qq.com",
"info": "世界上最快乐的人之一"
}9、使用Java代码操作索引库和文档
📕 ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
- 在老师的资料的基础上完成下面的功能


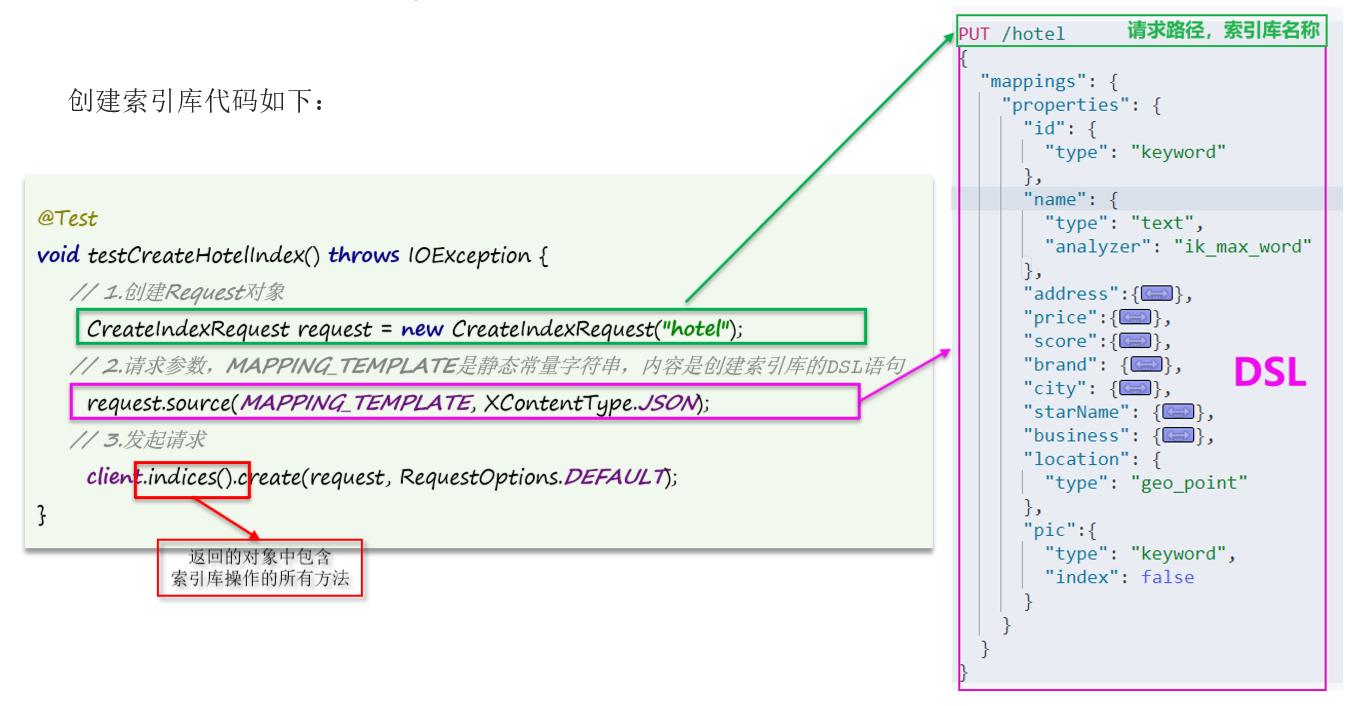
📕 根据课前资料提供的酒店数据创建索引库,索引库名为 hotel ,mapping 属性根据数据库结构定义。
🖊 基本步骤如下:
✏ 导入课前资料Demo
✏ 分析数据结构,定义mapping属性
✏ 初始化JavaRestClient
✏ 利用JavaRestClient创建索引库
✏ 利用JavaRestClient删除索引库
✏ 利用JavaRestClient判断索引库是否存在
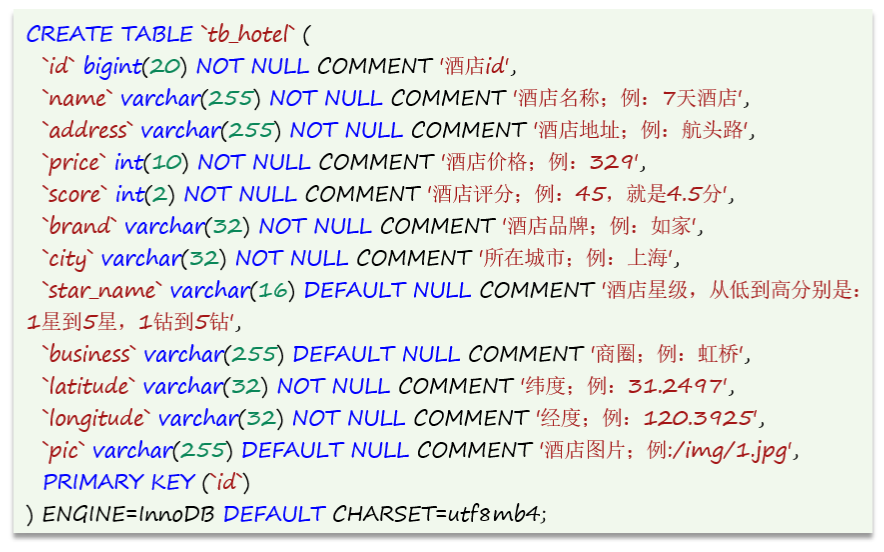
9.1 hotel 数据结构分析
-
在ES中,ID字段用字符串类型,要参与搜索,所以的 keyword类型
-
mapping 要考虑的问题:字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么❓

json
# 酒店索引库
PUT /hotel
{
"mappings": {
"properties": {
"id": { # 在ES中,ID用字符串表示,要参与搜索,但是不要分词
"type": "keyword",
"index": true # 默认值就是true, 表示默认要参与搜索
},
"name": {
"type": "text", # 酒店名称要参与搜索,并且也要分词
"analyzer": "ik_max_word"
},
"address": {
"type": "keyword",
"index": false # 不参与搜索
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": { # 品牌
"type": "keyword",
"copy_to": "all" # 共同搜索
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": { # 商圈
"type": "keyword",
"copy_to": "all"
},
"location": { # 经纬度
"type": "geo_point"
},
"pic": {
"type": "keyword",
"index":false
},
"all": { # 希望根据多个字段搜索,而且效率高,就把多个字段拷贝到指定字段(如 all)
"type": "text",
"analyzer": "ik_max_word"
}
}
}
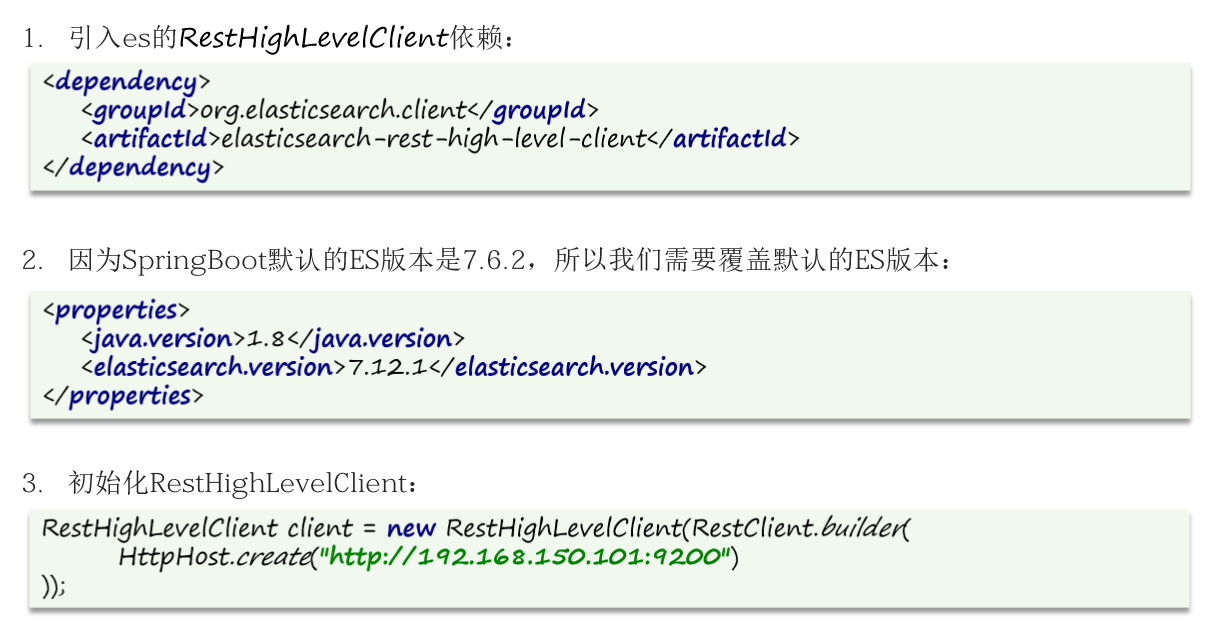
}9.2 初始化客户端
9.3 创建索引库
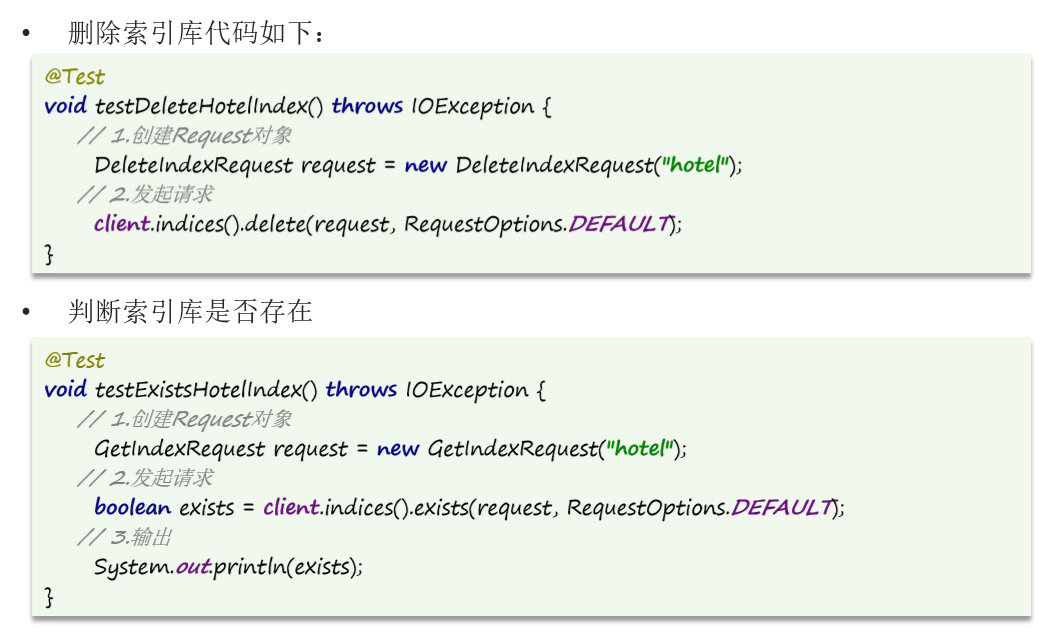
9.4 删除和判断索引库是否存在

9.5 查询MySQL数据新增到ES的索引库(新增文档)


9.6 根据ID查询ES中的文档

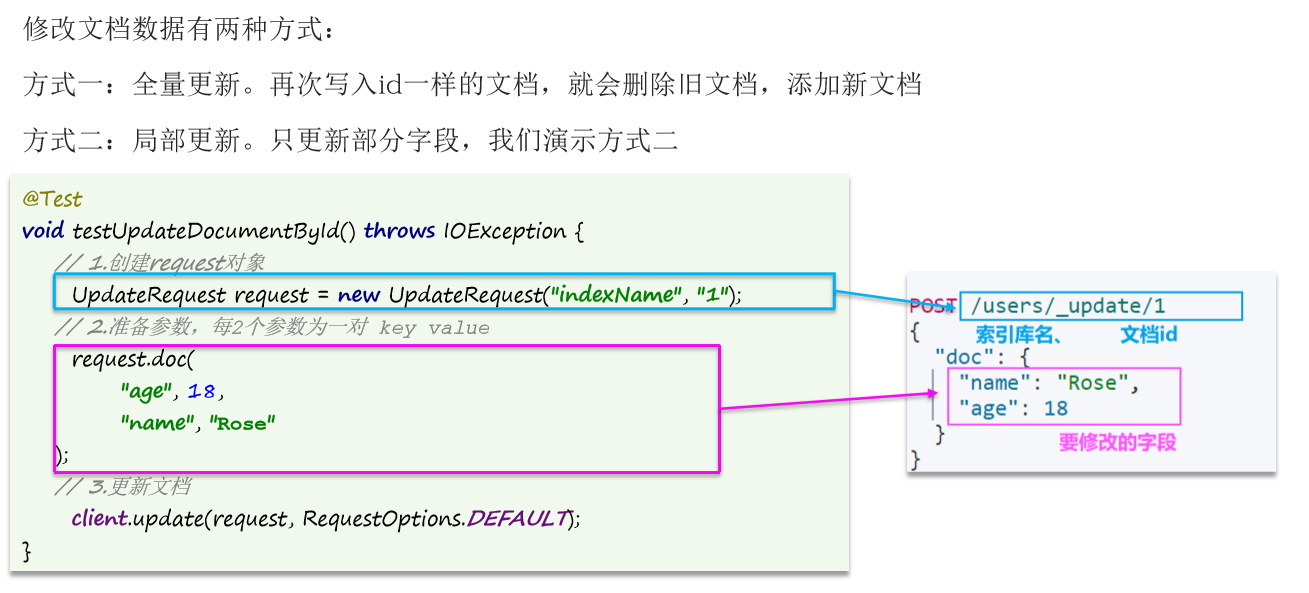
9.7 更新文档信息
9.8 删除文档


9.9 批量导入文档到ES

10、DSL分类
https://www.elastic.co/docs/explore-analyze/query-filter/languages/querydsl

- 查询的基本语法

json
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
11、简单查询
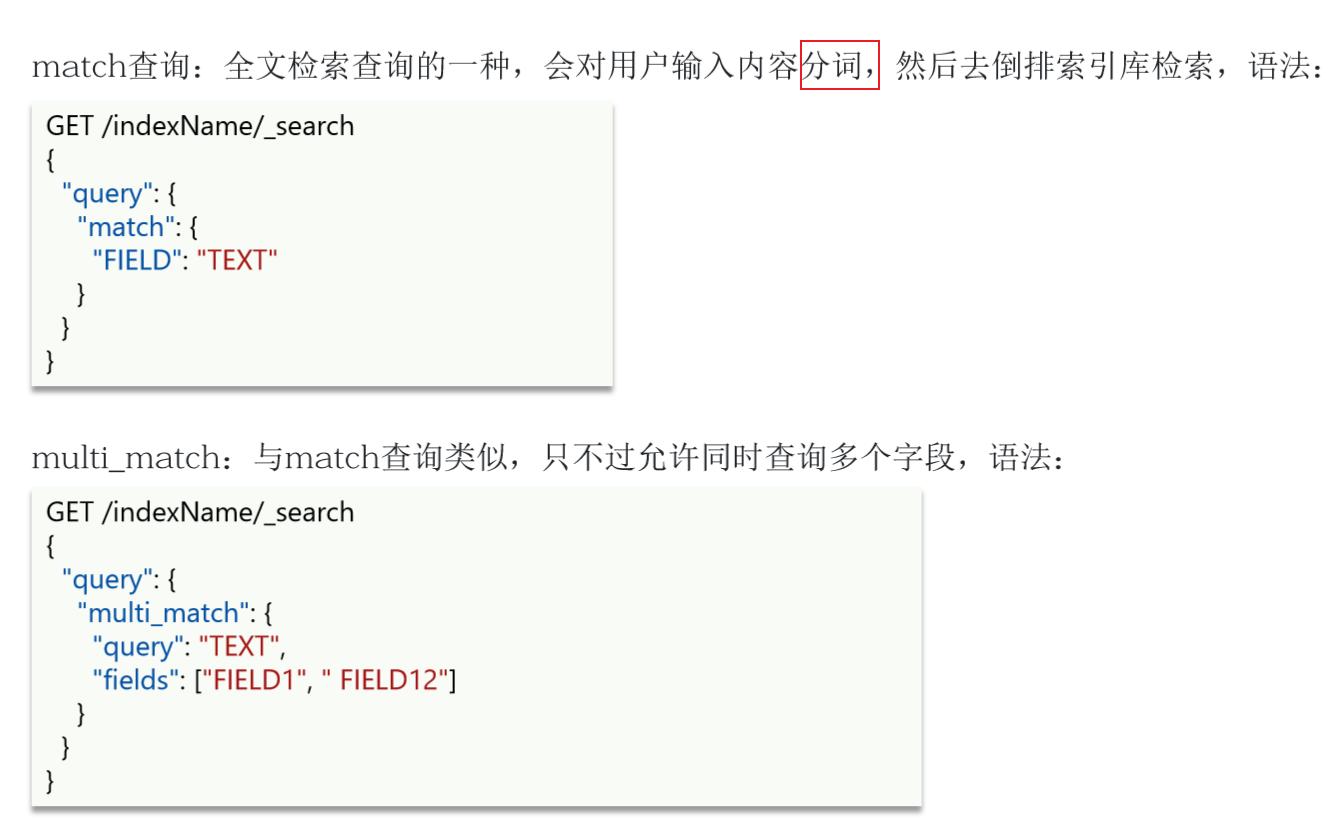
11.1 全文检索查询
📕 全文检索查询,会对用户输入内容分词,常用于搜索框搜索

- match_all
- match
- multi_match
json
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
json
GET /hotel/_search
{
"query": {
"match": {
"all": "外滩 如家"
}
}
}
json
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "如家 外滩",
"fields": [
"name",
"brand",
"business"
]
}
}
}📕 match 和 multi_match 的区别是什么?
🖊 match :根据一个字段查询(这个字段可能是由其他字段 copy_to 的字段)
🖊 multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
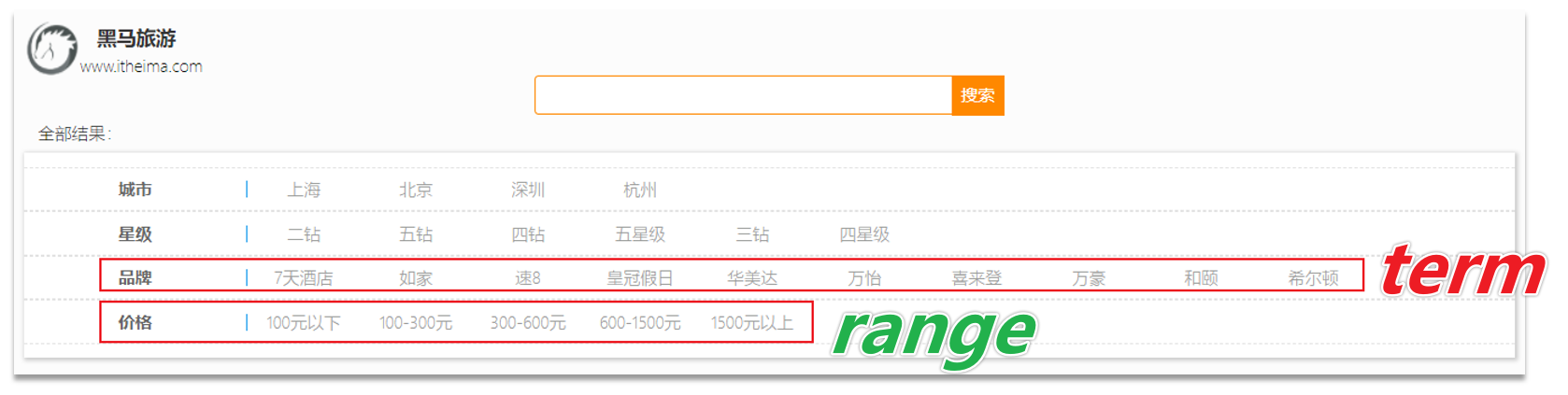
11.2 精确查询
📕 精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
🖊 term: 根据词条精确值查询
🖊 range: 根据值的范围查询


json
// term 查询
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "北京" // 不会分词
}
}
}
}
// range 查询
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": "100",
"lt": "300"
}
}
}
}11.3 地理查询
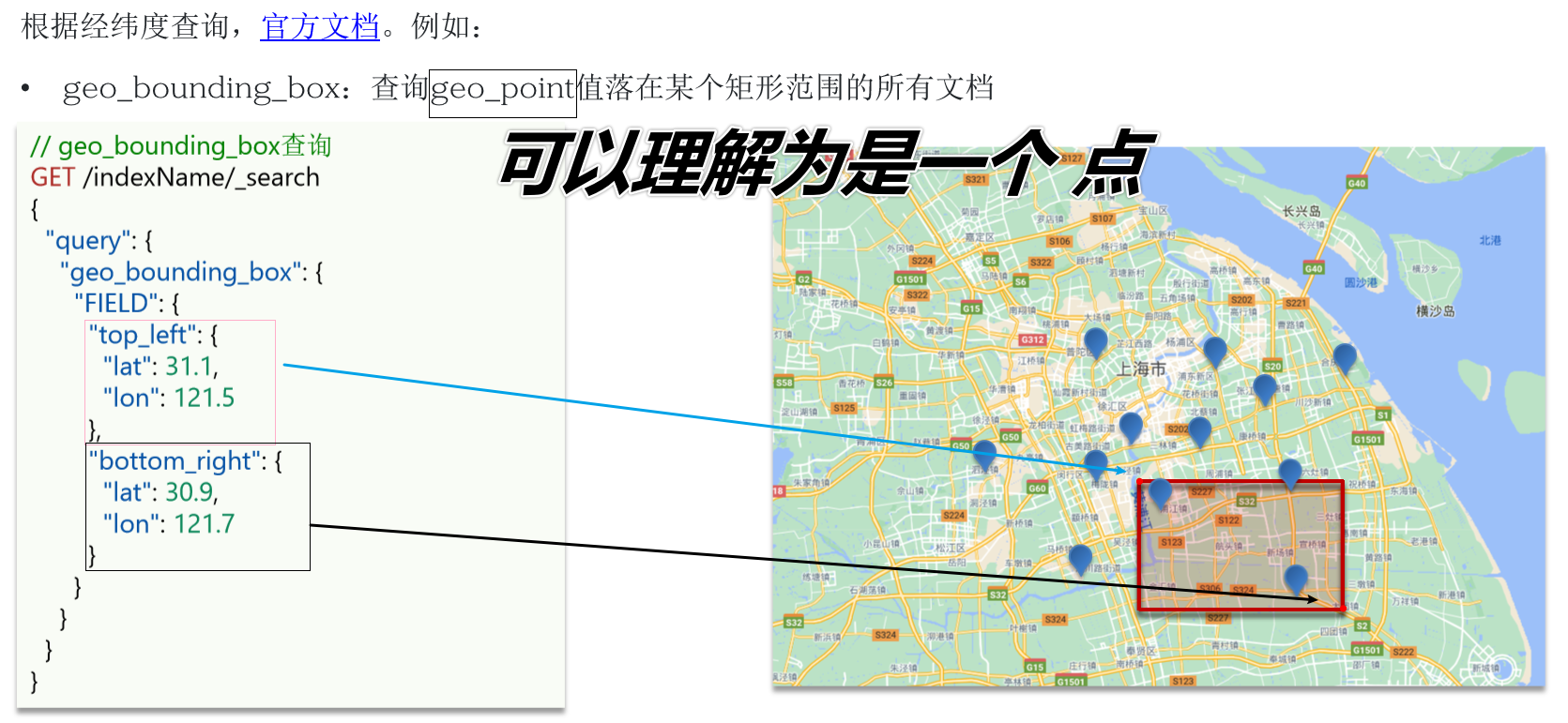
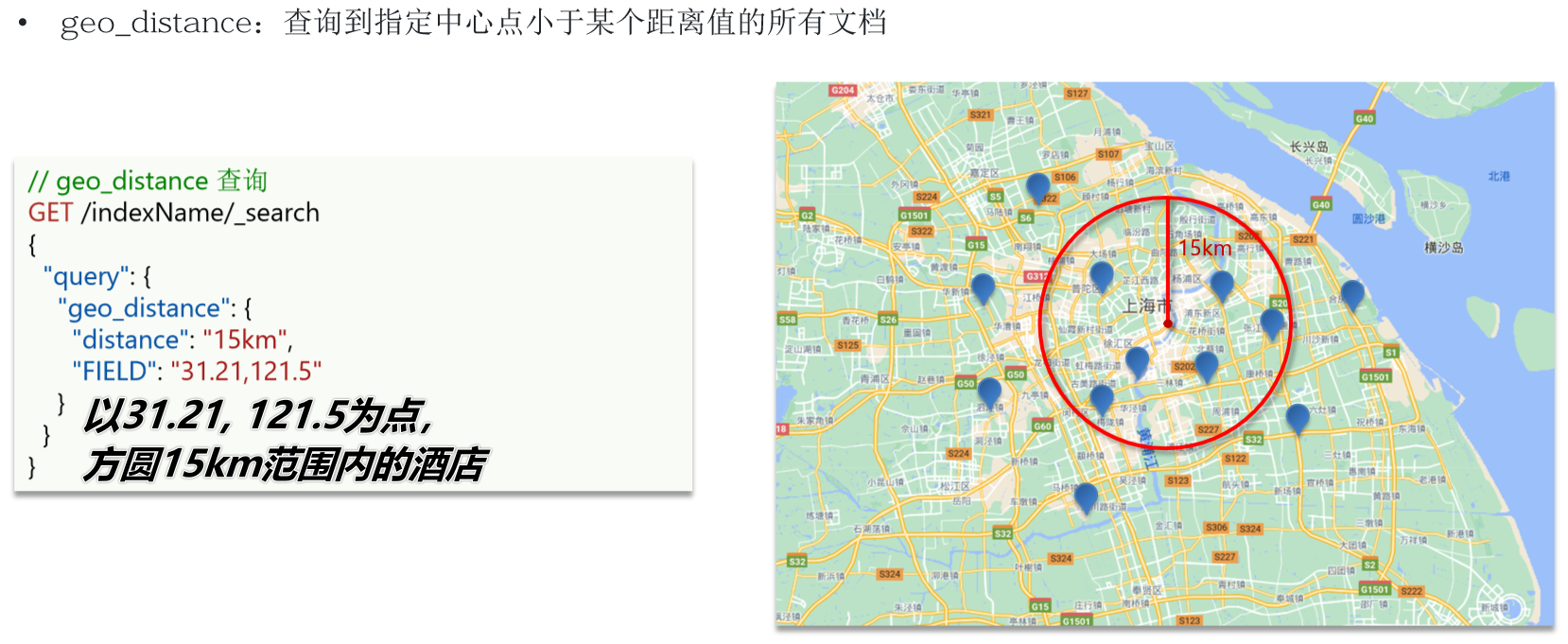
json
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "2km",
"location": "31.21, 121.5" // 我的位置附近2km的酒店
}
}
}12、复合查询
12.1 function score 算分函数查询


📕 elasticsearch 中的相关性打分算法是什么?
🖊 TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
🖊 BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平
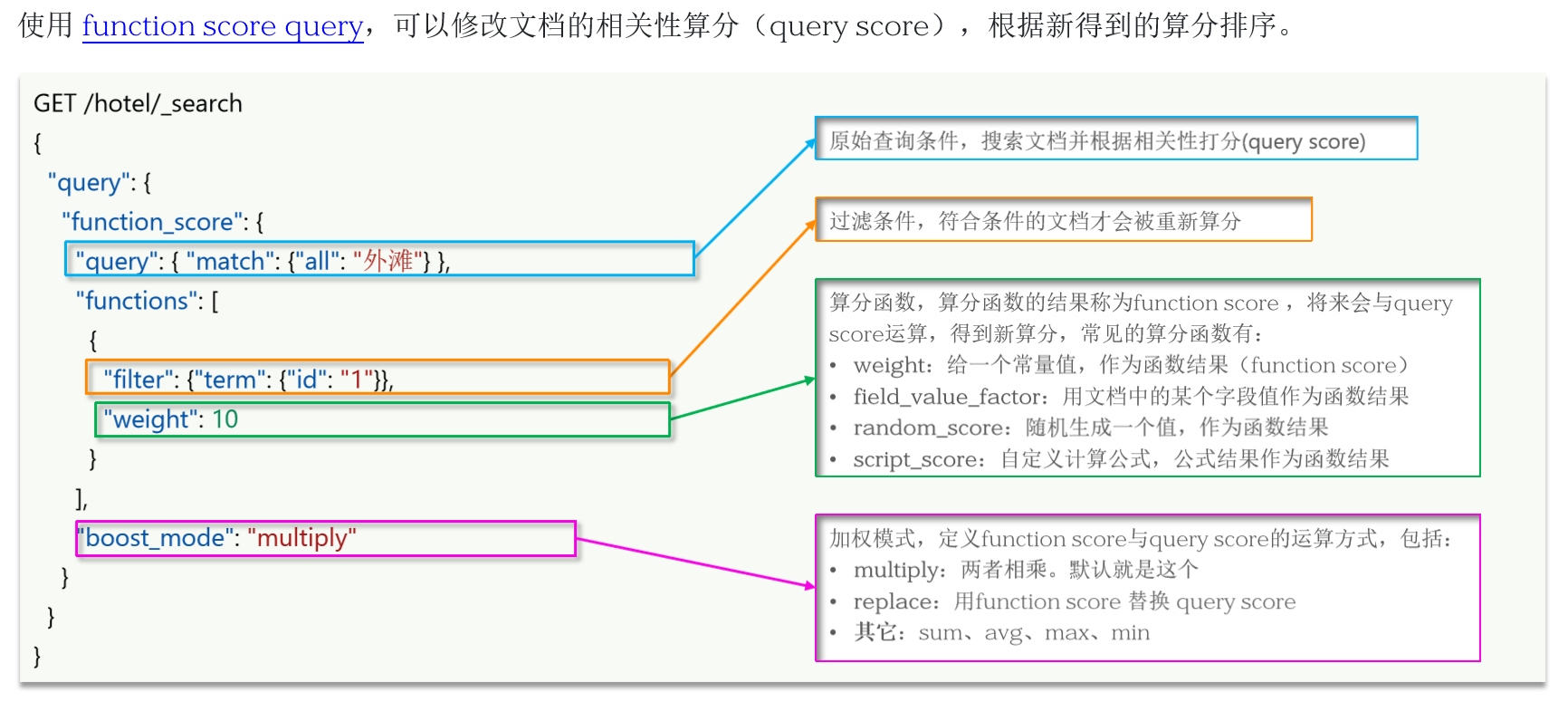


json
// function score 算分函数查询
GET /hotel/_search
{
"query": {
"function_score": {
"query": { // 简单查询,
"term": {
"brand": {
"value": "如家"
}
}
}, // 简单查询
"functions": [ // 算分函数
{
"filter": { // 过滤(给哪些文档重新计算_score)
"term": {
"id": "485775"
}
},
"weight": 8
}
], // 算分函数
"boost_mode": "sum" // 加权模式
}
}
}