Redis 深度剖析:结构、原理与存储机制
一、Redis 是什么?
Redis(Remote Dictionary Server,远程字典服务)是一款开源的、高性能的键值对(Key-Value)非关系型数据库(NoSQL),由 ANSI C 语言编写,运行在内存中,同时支持持久化到磁盘。
它和传统的关系型数据库(如 MySQL)最大的区别是:
不依赖表结构,以键值对存储数据,结构更灵活;
数据优先存内存,读写速度极快(官方测试能达到 10 万 + QPS);
支持多种数据类型,而非仅字符串。
二、Redis 的整体结构组成
Redis 的整体结构组成,从逻辑结构(数据层面) 和物理结构(运行架构层面) 两个维度来分析:
1、逻辑结构:Redis 数据存储的核心组成
这是 Redis 对开发者暴露的 "数据组织方式",核心是围绕「键(Key)」和「值(Value)」展开,且所有 Key 都是字符串类型,Value 则支持多数据类型。
(1) 核心:键空间(KeySpace)
Redis 内部维护一个全局的「键空间」,可以理解为一个超大的哈希表(Dictionary):
Key:唯一的字符串标识(如 user:1001、article:read:count),Redis 会对 Key 做哈希计算,快速定位对应的 Value;
Value:指向具体的数据结构(String/Hash/List/Set/ZSet 等);
附加属性:每个 Key 还关联了过期时间、数据类型、持久化标记等元信息(如 EXPIRE user:1001 3600 就是给 Key 设置 1 小时过期属性)。
(2) 底层数据结构(Value 的实现)
对外暴露的是 "抽象数据类型"(如 String),但底层会根据场景选择更高效的实现结构,这是 Redis 高性能的关键:
| 抽象数据类型 | 底层常用实现结构 | 说明 |
|---|---|---|
| String | 简单动态字符串(SDS) | 替代 C 语言原生字符串,支持动态扩容,且记录长度(O (1) 获取长度) |
| Hash | 哈希表 / 压缩列表 | 数据量小时用压缩列表(节省内存),数据量大时转为哈希表(提升读写) |
| List | 双向链表 / 压缩列表 | 同上,小数据用压缩列表,大数据用双向链表 |
| Set | 哈希表 / 整数集合 | 元素全是整数且数量少用整数集合,否则用哈希表 |
| ZSet | 压缩列表 / 跳表 + 哈希表 | 小数据用压缩列表,大数据用跳表(保证有序)+ 哈希表(快速查找) |
(3) 辅助逻辑组件
过期字典:单独维护一张哈希表,存储所有 Key 的过期时间,Redis 会通过 "惰性删除 + 定期删除" 清理过期 Key;
事务与锁:通过 MULTI/EXEC 标记事务,用 WATCH 实现乐观锁,保证操作的原子性;
发布订阅:维护 "频道 - 订阅者" 映射表,实现消息的广播推送。
2、物理结构:Redis 运行的架构组成
这是 Redis 服务端的 "运行时架构",从单机到集群,结构逐步扩展:
(1) 单机 Redis 的核心组成
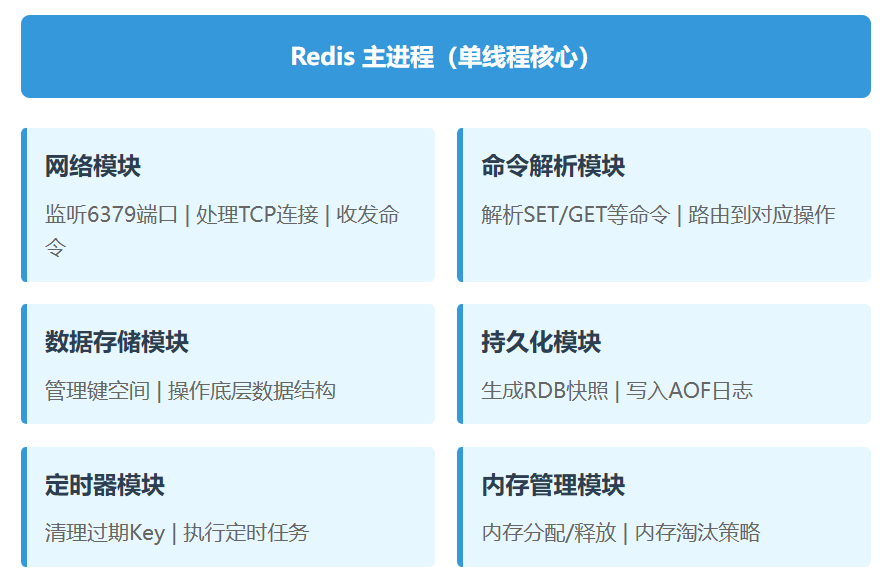
单机 Redis 物理架构(运行时模块)图解:
Redis 数据逻辑结构(存储层面)图解:

一台 Redis 服务器运行时,进程内包含以下核心模块:
MERMAID
graph TD
A[Redis 主进程] --> B[网络模块]
A --> C[命令解析模块]
A --> D[数据存储模块]
A --> E[持久化模块]
A --> F[定时器模块]
A --> G[内存管理模块]
B --> B1["监听端口(6379)"]
B --> B2["处理客户端连接(TCP)"]
C --> C1["解析命令(如SET/GET)"]
C --> C2[路由到对应数据操作]
D --> D1[键空间管理]
D --> D2[数据结构操作]
E --> E1[RDB快照生成]
E --> E2[AOF日志写入]
F --> F1[过期Key清理]
F --> F2["定时任务(如主从同步)"]
G --> G1[内存分配/释放]
G --> G2["内存淘汰策略(如LRU)"]网络模块:处理 TCP 连接,接收 / 返回客户端命令;
命令解析模块:把客户端的字符串命令(如 SET name zhangsan)解析为内部操作;
数据存储模块:核心,管理键空间和底层数据结构;
持久化模块:负责 RDB/AOF 数据落地;
定时器模块:处理过期 Key、定时同步等;
内存管理模块:避免内存泄漏,内存不足时按策略淘汰冷数据。
(2) 分布式 Redis 的架构组成
Redis 集群结构(分布式架构)图解:

生产环境中很少用单机,分布式架构核心组成:
主节点(Master):负责写操作,同步数据到从节点;
从节点(Slave):只读,分担读压力,作为主节点的备份;
哨兵(Sentinel):监控主从节点健康状态,主节点故障时自动切换(选新主);
集群节点(Cluster Node):每个节点负责一部分哈希槽(共 16384 个),通过槽映射存储数据,支持水平扩容;
中心路由(可选):如 Redis Cluster Proxy,简化客户端对集群的访问(无需感知节点分布)。
3、Redis 数据流转的简单示例
以 SET user:1001 name zhangsan EX 3600 为例,Redis 内部处理流程:
- 网络模块接收客户端的 SET 命令;
- 命令解析模块解析出 Key(user:1001)、Value(name zhangsan)、过期时间(3600 秒);
- 数据存储模块在键空间中创建 Key,Value 底层用 SDS 存储字符串,同时在过期字典中记录该 Key 的过期时间;
- 持久化模块(若开启 AOF)将该命令写入 AOF 日志;
- 若为集群环境,先计算 Key 对应的哈希槽,确认当前节点负责该槽后再执行操作;
- 执行完成后,网络模块向客户端返回 "OK"。
三、Redis的底层原理
1、核心执行模型:单线程 + 多路 IO 复用
这是 Redis 高性能的 "基石",很多人误以为 "单线程" 会慢,实则恰恰相反:
(1) 单线程的核心逻辑
Redis 主线程只负责命令解析、数据操作、响应返回这一核心流程,全程单线程执行:
优势:避免了多线程的上下文切换、锁竞争开销(这是很多多线程程序性能损耗的关键);
前提:Redis 操作的是内存(纳秒级),单线程足以处理每秒 10 万 + 的请求,CPU 不会成为瓶颈。
(2) 多路 IO 复用(解决单线程并发问题)
单线程如何处理成千上万个客户端连接?靠的是IO 多路复用模型(Redis 底层用 epoll/kqueue/select 实现,优先 epoll):
Redis主线程
IO多路复用器(epoll)
监听所有客户端Socket连接
检测有事件的Socket(读/写)
将事件按顺序放入事件队列
依次处理事件队列中的请求
执行命令(内存操作)
返回响应给客户端
核心逻辑:IO 多路复用器替主线程监听所有客户端连接,只有当 Socket 有 "可读 / 可写" 事件时,才通知主线程处理,主线程按顺序处理事件队列,既保证了并发,又避免了多线程问题。
2、核心数据结构的底层实现
Redis 对外暴露的 String/Hash 等 "抽象数据类型",底层会根据数据规模选择更高效的实现结构,这是 Redis 兼顾性能和内存的关键:
| 抽象类型 | 底层实现 | 适用场景 | 核心原理 |
|---|---|---|---|
| String | 简单动态字符串(SDS) | 所有字符串存储(如缓存、计数器) | 替代 C 语言原生字符串:1. 自带长度属性(O (1) 获取长度,C 字符串要遍历); 2. 动态扩容(预分配冗余空间,减少内存重分配); 3. 二进制安全(可存图片、视频等二进制数据) |
| Hash | 压缩列表(ziplist)→ 哈希表(dict) | 存储对象(如用户信息) | 小数据量(元素少、值小):用压缩列表(连续内存,省空间); 数据量达标:自动转为哈希表(数组 + 链表,O (1) 查找) |
| List | 压缩列表 → 双向链表(adlist) | 消息队列、最新列表 | 小数据:压缩列表; 大数据:双向链表(两端增删 O (1),遍历 O (n)) |
| Set | 整数集合(intset)→ 哈希表 | 去重、抽奖 | 元素全是整数且数量少:整数集合(连续内存,省空间); 其他情况:哈希表(值为 NULL,仅用键去重) |
| ZSet | 压缩列表 → 跳表(skiplist)+ 哈希表 | 排行榜、有序排名 | 小数据:压缩列表; 大数据:跳表(保证有序遍历 O (logn))+ 哈希表(O (1) 查找元素分数) |
补充:哈希表的扩容 / 缩容
Redis 哈希表(dict)是 "数组 + 链表" 结构(和 Java HashMap 类似),当负载因子(元素数 / 数组长度)超过阈值(默认 1)时,会触发扩容:
扩容:创建 2 倍大小的新数组,渐进式 rehash(分多次将旧数组数据迁移到新数组),避免一次性迁移阻塞主线程;
缩容:负载因子过低时,缩小数组,同样用渐进式 rehash。
3、持久化的底层原理
Redis 持久化(RDB/AOF)的底层逻辑,决定了数据安全性和恢复效率:
(1) RDB 底层原理(快照)
触发:主线程 fork 一个子进程(写时复制 COW 机制),子进程拥有主线程内存的 "快照";
写时复制(COW):fork 后,主线程写数据时,会复制一份被修改的内存页,子进程仍读取旧内存页,保证快照数据的一致性;
写入:子进程遍历内存中的键空间,将数据以二进制格式写入 .rdb 文件,完成后替换旧文件。
(2) AOF 底层原理(日志)
命令追加:所有写命令先写入 AOF 缓冲区(避免直接写磁盘阻塞主线程),再按策略刷盘到 .aof 文件;
AOF 重写:fork 子进程,遍历内存数据,生成 "最终状态" 的命令(如将 100 次 INCR 合并为 SET),替换旧的大 AOF 文件;
恢复:重启时,逐条执行 .aof 文件中的命令,重建内存数据。
(3) 混合持久化(Redis4.0+)
底层:重写 AOF 时,先写入 RDB 格式的全量数据,再追加增量 AOF 命令;
恢复:先加载 RDB 全量数据(快),再重放增量 AOF 命令(保证完整性)。
4、过期 Key 的底层处理
Redis 对过期 Key 的管理,底层靠 "过期字典 + 两种删除策略":
过期字典:独立的哈希表,存储 Key → 过期时间戳,O (1) 查询 Key 是否过期;
删除策略:
- 惰性删除:访问 Key 时,检查是否过期,过期则删除(不浪费 CPU,但可能导致过期 Key 长期占内存);
- 定期删除:主线程每隔 100ms,随机抽取部分过期 Key 检查并删除(平衡 CPU 和内存)。
5、集群的底层原理(Redis Cluster)
哈希槽 :集群共有 16384 个哈希槽,Key 通过 CRC16(key) % 16384 计算槽位,数据按槽分布在不同节点;
节点通信:节点间通过 Gossip 协议交换集群状态(如槽分配、节点上线 / 下线);
故障检测:节点互相发送 PING/PONG 消息,超过阈值未响应则标记为疑似下线,多数节点确认后标记为下线;
故障转移:下线主节点的从节点,通过投票竞选新主节点,接管原主节点的哈希槽。
四、Redis的存储机制
1、核心:内存优先的存储模式
Redis 本质是内存数据库,所有数据默认优先存储在内存中,这也是它读写速度极快(10 万 + QPS)的根本原因:
(1) 内存存储的核心结构
Redis 启动后,会在内存中构建「键空间(KeySpace)」------ 一个全局哈希表,管理所有 Key-Value 对;
Value 会根据数据类型(String/Hash/List 等),选择对应的底层数据结构(如 SDS、压缩列表、跳表等)存储,兼顾性能和内存利用率;
每个 Key 会关联元信息(过期时间、数据类型、持久化标记等),存储在独立的「过期字典」中,便于快速管理。
(2) 内存存储的优势与风险
优势:内存读写是纳秒级,远快于磁盘(毫秒级),且 Redis 单线程模型避免了线程切换开销,进一步提升效率;
风险 :内存易失(断电 / 进程崩溃会丢数据)、内存容量有限(单节点内存不宜过大),因此需要持久化 和集群分片来解决。
2、关键:持久化机制(内存 → 磁盘)
为了避免内存数据丢失,Redis 设计了两种核心持久化方式,可单独或混合使用:
| 持久化方式 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|
| RDB(快照) | 定时将内存中全量数据生成二进制快照文件(.rdb)保存到磁盘 | 1. 文件体积小,恢复速度快;2. 适合备份、灾备;3. 对性能影响小(fork 子进程执行) | 1. 定时生成,可能丢失两次快照间的数据;2. 大数据集下 fork 子进程会短暂阻塞主线程 |
| AOF(追加日志) | 记录所有写操作命令(如 SET、HSET)到日志文件(.aof),重启时重放命令恢复数据 | 1. 数据完整性高(可配置每秒 / 每次命令刷盘);2. 日志是文本格式,易理解、易修复 | 1. 文件体积远大于 RDB,恢复速度慢;2. 写操作会频繁刷盘,性能开销略高 |
(1) RDB 工作流程
触发条件
Redis主线程fork子进程
子进程遍历内存键空间,生成RDB文件
替换旧RDB文件,完成快照
手动触发:SAVE/BGSAVE命令
自动触发:配置文件指定时间+写操作数(如1分钟10次写)
核心:fork 子进程执行快照,主线程继续处理客户端请求,几乎不阻塞;
触发时机 :手动执行 BGSAVE(异步)/ SAVE(同步,会阻塞),或配置文件自动触发(如 save 60 10 表示 60 秒内有 10 次写操作就触发)。
(2) AOF 工作流程
执行写命令
将命令追加到AOF缓冲区
根据刷盘策略写入AOF文件
always:每次命令都刷盘(最安全,性能最差)
everysec:每秒刷盘(默认,平衡安全与性能)
no:由操作系统决定(性能最好,最不安全)
AOF文件过大
执行AOF重写(BGREWRITEAOF)
生成精简的新AOF文件(合并重复命令、删除无效命令)
核心优化 :AOF 重写(BGREWRITEAOF)------ 避免日志文件无限膨胀,比如将 INCR count 100次 合并为 SET count 100,大幅减小文件体积。
(3) 混合持久化(Redis 4.0+ 推荐)
结合 RDB 和 AOF 的优点:
重写 AOF 文件时,先写入 RDB 格式的全量数据,再追加增量的 AOF 命令;
恢复时先加载 RDB 全量数据,再重放增量 AOF 命令,兼顾恢复速度和数据完整性。
3、兜底:内存淘汰机制(内存满了怎么办)
Redis 内存达到配置上限(maxmemory)时,会触发内存淘汰策略,删除部分数据释放内存,避免 OOM(内存溢出):
(1) 核心淘汰策略(Redis 6.0+ 主流)
| 策略 | 逻辑 | 适用场景 |
|---|---|---|
| volatile-lru | 从设置了过期时间的 Key 中,淘汰最近最少使用的 | 缓存场景(大部分 Key 有过期时间) |
| allkeys-lru | 从所有 Key 中,淘汰最近最少使用的 | 纯缓存场景(所有数据都是缓存,无持久化需求) |
| volatile-ttl | 从设置了过期时间的 Key 中,淘汰剩余过期时间最短的 | 时效性强的缓存(如验证码、临时令牌) |
| volatile-random | 从设置了过期时间的 Key 中,随机淘汰 | 对淘汰规则无特殊要求,追求性能 |
| allkeys-random | 从所有 Key 中,随机淘汰 | 测试 / 低优先级场景 |
| noeviction(默认) | 不淘汰任何 Key,内存满时拒绝所有写操作 | 数据不可丢失的场景(如计数、分布式锁) |
(2) 淘汰流程
- Redis 每次执行写操作前,检查内存是否超过
maxmemory; - 若超过,按配置的淘汰策略筛选要删除的 Key;
- 删除 Key 释放内存后,再执行当前写操作;
- 若淘汰后内存仍不足(如所有 Key 都是持久化的),则返回错误(
OOM command not allowed when used memory > 'maxmemory')。
4、补充:集群存储(分片机制)
单节点内存有限,Redis Cluster 通过哈希槽分片扩展存储能力:
- 整个集群共有 16384 个哈希槽;
- 每个 Key 通过
CRC16(key) % 16384计算所属槽位; - 集群中的每个节点负责一部分槽位(可手动分配或自动均衡);
- 数据按槽位分布在不同节点,实现水平扩容,突破单节点内存上限。
五、Redis 的特性
1. 丰富的数据类型
这是 Redis 最核心的能力,常用类型包括:
| 数据类型 | 说明 | 典型场景 |
|---|---|---|
| String | 字符串(最基础),可存文本、数字 | 缓存用户信息、计数器(如文章阅读量) |
| Hash | 哈希表(键值对的集合) | 存储对象(如用户的姓名、年龄、手机号) |
| List | 有序列表(双向链表) | 消息队列、最新评论列表 |
| Set | 无序集合(元素唯一) | 去重、抽奖、共同好友 |
| Sorted Set(ZSet) | 有序集合(按分数排序) | 排行榜(如游戏战力排名) |
2. 内存存储 + 持久化
内存存储:保证超高读写性能;
持久化:避免内存数据丢失,支持两种方式:
(1) RDB:定时将内存数据快照保存到磁盘(适合备份、灾备);
(2) AOF:记录所有写操作,重启时重放操作恢复数据(数据更完整)。
3. 高可用与分布式
主从复制:一台主节点(写)+ 多台从节点(读),分担读压力,主节点故障可切换到从节点;
哨兵(Sentinel):自动监控主从节点,故障时自动切换,保证高可用;
集群(Cluster):将数据分片存储在多台服务器,支持水平扩容,解决单节点内存上限问题。
4. 其他实用特性
过期时间:可给键设置过期时间(如缓存验证码,5 分钟失效);
发布订阅:类似消息队列,支持一对多的消息推送;
事务:支持简单的事务(批量执行命令,要么全做要么全不做,但不支持回滚);
管道(Pipeline):批量发送命令,减少网络交互次数,提升效率。
六、Redis 的典型应用场景
1.缓存:最核心场景。把数据库中常用的数据(如商品信息、用户信息)缓存到 Redis,请求先查 Redis,查不到再查数据库,大幅降低数据库压力;
2.计数器:利用 Redis 单线程原子性,实现高并发下的精准计数(如文章阅读量、视频播放量、点赞数);
3.分布式锁:解决分布式系统中多节点并发竞争问题(如秒杀场景防止超卖);
4.消息队列:利用 List 或 Stream 实现简单的消息队列,替代部分 Kafka/RabbitMQ 场景;
5.排行榜 / 限流:ZSet 做排行榜,结合过期时间实现接口限流(如限制用户每分钟最多请求 10 次)。
七、Redis 的简单使用示例(命令行)
启动 Redis 服务后,通过 redis-cli 连接,执行基础命令:
BASH
# 1. 设置 String 类型键值对,过期时间10秒
SET code "123456" EX 10
# 2. 获取键值
GET code
# 3. 设置 Hash 类型(存储用户信息)
HSET user:1 name "张三" age 25 phone "13800138000"
# 4. 获取 Hash 中的某个字段
HGET user:1 name
# 5. 给计数器加1
INCR article:1:read_count总结
1.Redis 是内存型键值数据库,核心优势是高性能、灵活的数据类型、支持持久化和分布式;
2.主要用于缓存、计数器、分布式锁、排行榜等高性能场景,是 Java 后端开发的必备技术;
3.它不是替代关系型数据库,而是和 MySQL 等配合使用(如 "MySQL + Redis" 架构),互补长短。