1.Java垃圾回收概述
垃圾回收(Garbage Collection,GC)是Java虚拟机自动管理堆内存的机制,负责识别不再使用的对象并释放其占用的内存。
垃圾回收的触发机制如下:
-
**内存不足时:** 当JVM检测到堆内存不足,无法为新的对象分配内存时,会自动触发垃圾回收。
-
手动请求: 虽然垃圾回收是自动的,开发者可以通过调用System.gc() 或**Runtime.getRuntime().gc()**建议 JVM 进行垃圾回收。不过这只是一个建议,并不能保证立即执行。
-
JVM参数: 启动 Java 应用时可以通过 JVM 参数来调整垃圾回收的行为,比如:-Xmx(最大堆大小)、-Xms(初始堆大小)等。
-
**对象数量或内存使用达到阈值:** 垃圾收集器内部实现了一些策略,以监控对象的创建和内存使用,达到某个阈值时触发垃圾回收。
2.Java垃圾回收判断算法
引用计数法
基本原理: 为每个对象 分配一个专有的引用计数器,当一个对象被引用后,计数器+1,引用失效后,计数器-1,计数器为0时,表示对象不再被任何变量引用,可以被回收。
这个算法非常简单易懂,可是它有一个致命的缺点,就是循环引用的问题,接下来我们来看个循环引用的例子
java
// 一个简单的循环引用例子
class RefObject {
public Object instance = null;
}
public class Main {
public static void main(String[] args) {
RefObject objA = new RefObject(); // objA引用计数 = 1
RefObject objB = new RefObject(); // objB引用计数 = 1
objA.instance = objB; // objB引用计数 = 2 (被objA.instance引用)
objB.instance = objA; // objA引用计数 = 2 (被objB.instance引用)
objA = null; // objA引用计数减为1 (仅被objB.instance引用)
objB = null; // objB引用计数减为1 (仅被objA.instance引用)
// 此时,两个对象已经无法被外界访问(objA和objB变量都指向了null),
// 但它们彼此引用,引用计数均为1,无法被引用计数算法回收。
}
}可以看到,当objA和objB设置为null时,正常来说应该被垃圾回收,可是由于objA被objB引用,objB被objA引用,导致计数器不为0无法被回收,这就是循环引用的问题所在。所以大部分情况我们都是使用下面这种算法。
可达性分析算法
基本原理: 通过一系列称为 "GC Roots" 的根对象作为起始节点,从这些根节点开始,根据引用关系向下搜索, 的如果某个对象到GC Roots间没有任何引用链相连 ,则证明此对象是不可用的,可以被回收。
它与引用计数法最核心的区别在于:它不关心对象被引用了多少次,只关心能否从根节点触达。
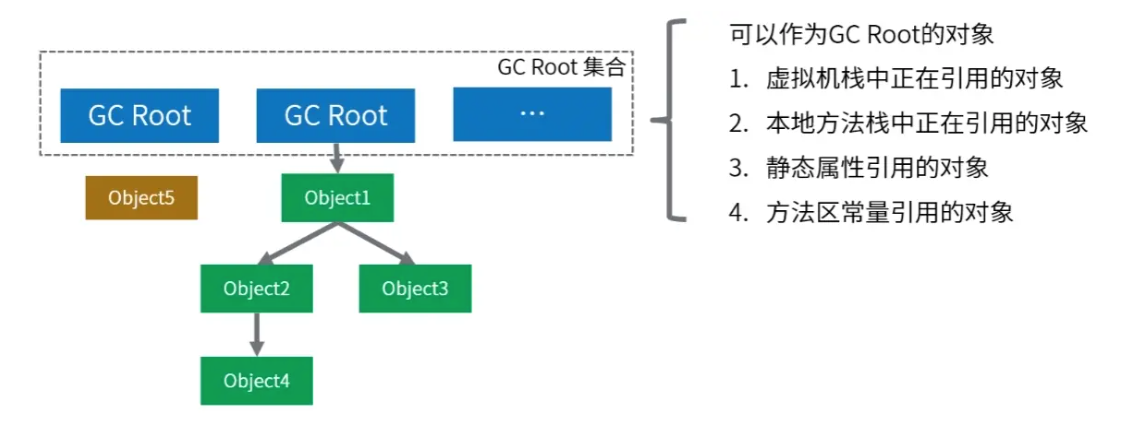
该算法从根本上解决了循环引用的问题。在上面的例子中,虽然A和B互相引用,但只要它们无法从GC Roots到达,就会被判定为垃圾。
话又说回来了,难道可达性分析算法就没用缺点吗?
从原理那我们也不难看出,可达性分析算法的实现相比于引用计数法更加复杂了,同时,为了保证分析结果的准确性,在进行可达性分析时,必须在一个一致性快照 中进行。这意味着在分析期间,整个执行系统必须被冻结,不允许对象的引用关系发生变化。这个过程就是著名的Stop The World(STW),是垃圾收集器产生停顿的主要原因之一。
3.Java垃圾回收算法
标记-清除算法
**基本原理:**先标记所有存活对象,再清除未标记对象
一个简单的实现如下:
java
// 算法伪代码示意
public class MarkSweep {
void mark(Object obj) {
if (obj != null && !obj.isMarked()) {
obj.setMarked(true);
mark(obj.references); // 递归标记所有引用对象
}
}
void sweep(Heap heap) {
for (Object obj : heap.objects) {
if (!obj.isMarked()) {
heap.free(obj); // 释放未标记对象
} else {
obj.setMarked(false); // 重置标记位
}
}
}
}该算法简单直接 ,不过效率不高 而且会产生内存碎片。
复制算法
**基本原理:**内存分成两块,每次申请内存时都使用其中的一块,当内存不够时,将这一块内存中所有存活的复制到另一块上。然后将然后再把已使用的内存整个清理掉。
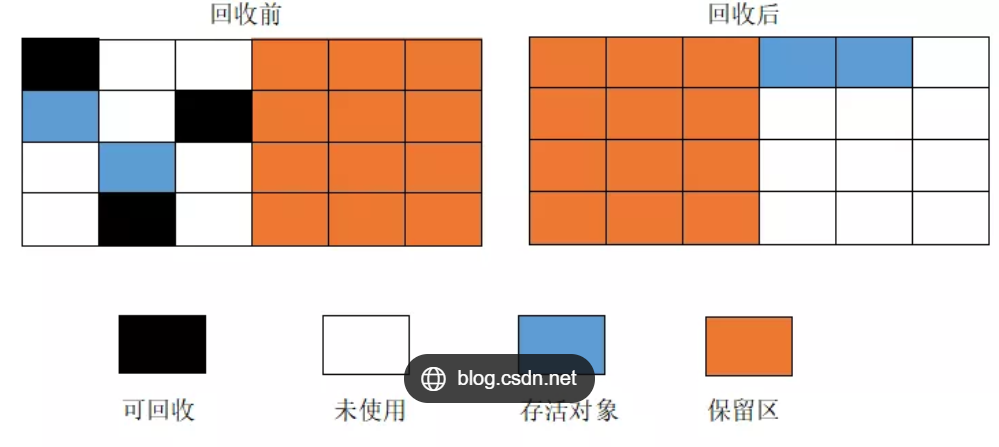
该算法解决了不会产生内存碎片的问题,可又带来了新的问题:每次申请内存时只能申请一半的内存空间,内存利用率严重不足。
标记-整理算法
基本原理: 标记-整理算法的"标记"过程与"标记-清除算法"的标记过程一致,但标记之后不会直接清理。而是将所有存活对象都移动到内存的一端。移动结束后直接清理掉剩余部分。
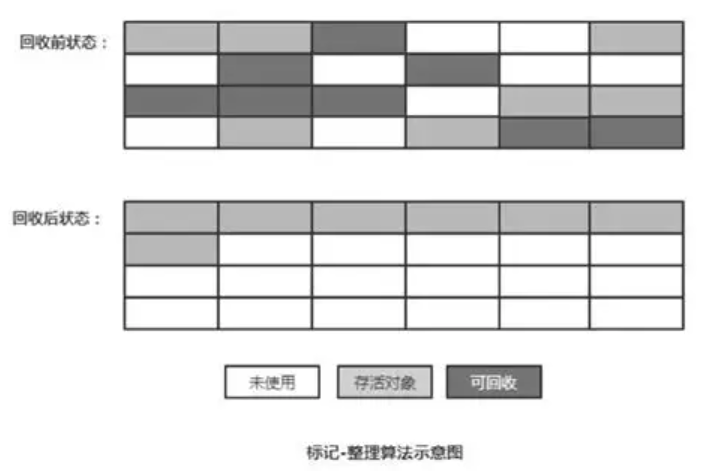
该算法既解决了内存碎片问题的产生,也提高内存利用率,不过整理阶段需要移动对象,开销较大。
分代收集算法
基本原理: 分代收集是将内存划分成了新生代和老年代。分配的依据是对象的生存周期,或者说经历过的垃圾回收次数。对象创建时,一般在新生代申请内存,当经历一次 GC 之后如果对还存活,那么对象的年龄 +1。当年龄超过一定值(默认是15)后,如果对象还存活,那么该对象会进入老年代。
不同分代使用的回收机制也不用,我们来介绍下这两种内存划分
新生代:
-
Eden区(80%):新对象分配区
-
Survivor区(20%):Minor GC后存活对象存放区
-
使用复制算法,回收频率高,由于
老年代:
-
存放长期存活对象
-
使用标记-清除或标记-整理算法
4.Java中常见的垃圾回收器
Serial收集器
- 垃圾回收算法:复制算法
- 特点:单线程,简单高效
- 工作模式:暂停所有用户线程(STW),进行垃圾回收
JVM配置示例:
java
# JVM 参数
-XX:+UseSerialGCParallel收集器
实际上是Serial收集器的多线程版本
JVM配置示例:
java
# JVM 参数
-XX:+UseParallelGC # 新生代Parallel Scavenge,老年代Serial Old
-XX:+UseParallelOldGC # 新生代Parallel Scavenge,老年代Parallel Old
-XX:+UseParNewGC # 新生代ParNew,需配合CMS使用
-XX:ParallelGCThreads=n # 设置并行GC线程数适合对延迟不敏感,高吞吐量需求的场景。
并发标记清除回收器 (CMS)
老年代并行收集器,以获取最短回收停顿时间为目标的收集器,具有高并发、低停顿 的特点,追求最短GC回收停顿时间
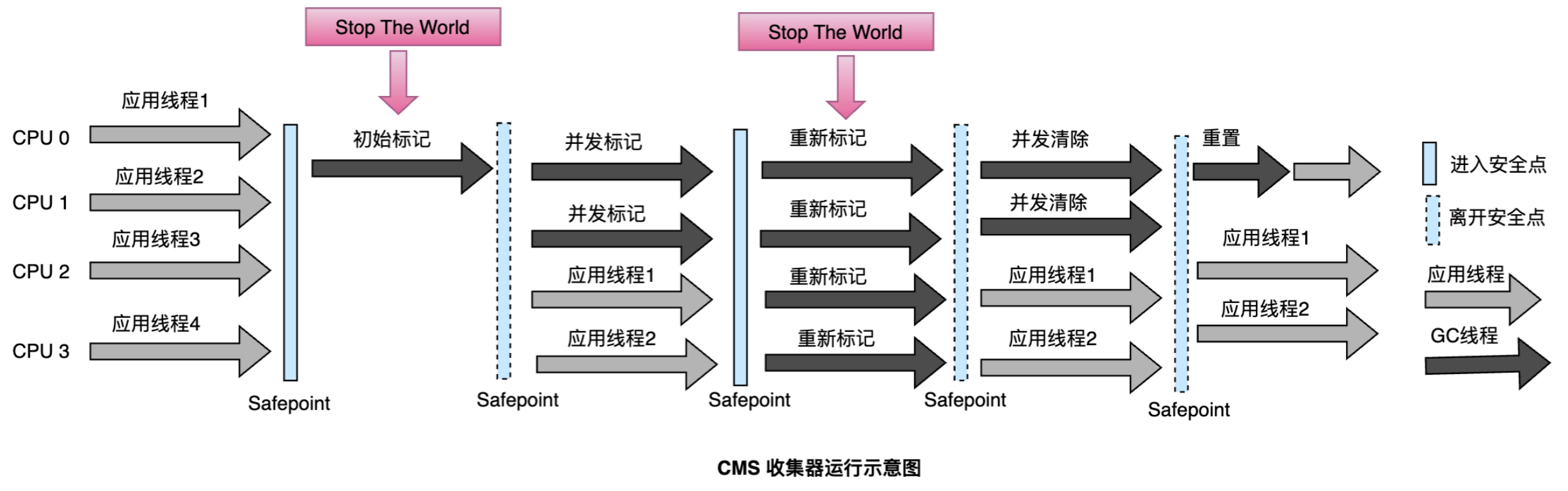
收集过程:
-
初始标记:STW,标记GC Roots直接关联对象
-
并发标记:与应用程序并发,遍历整个对象图
-
重新标记:STW,修正并发标记期间的变动
-
并发清除:与应用程序并发,清理死亡对象
JVM配置示例:
java
# JVM 参数
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=68 # 老年代使用率触发阈值
-XX:+UseCMSCompactAtFullCollection # 开启碎片整理相应的,CMS回收器也有部分缺点,如对CPU资源敏感 ,无法处理浮动垃圾 (并发时新产生的垃圾),**内存碎片问题(**标记-清除算法)
G1 回收器
这是目前使用率最高的垃圾回收器,它做了一个革命性的设计:不再物理分代,而是逻辑分区的Region, 此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而前几种收集器回收的范围仅限于新生代或老年代
下面是G1垃圾回收器的基本流程:
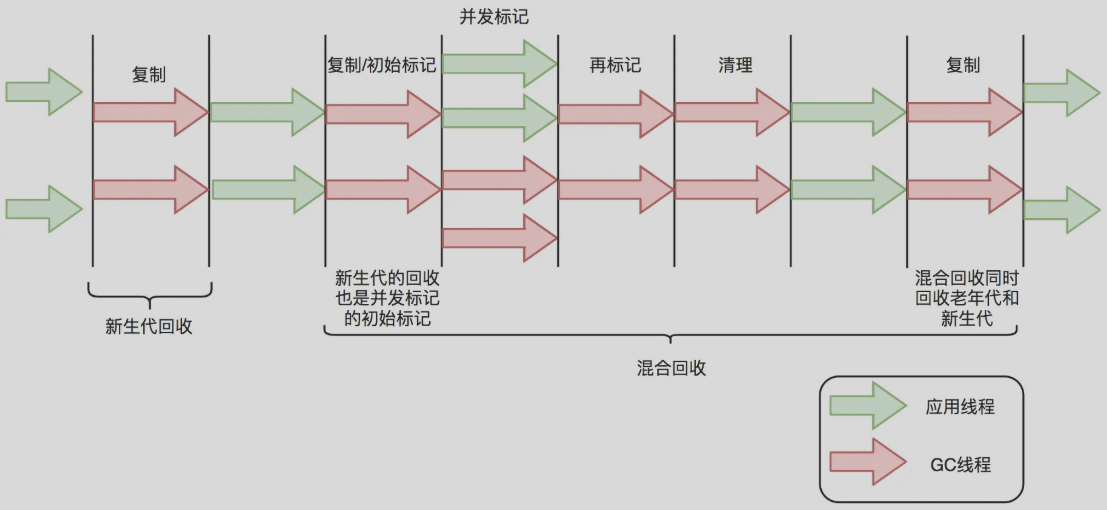
JVM配置示例:
java
# JVM 参数
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200 # 目标最大停顿时间
-XX:G1HeapRegionSize=n # Region大小(1M~32M,2的幂)制作不易,如果对你有帮助请**点赞,评论,收藏,**感谢大家的支持
