目录
源码获取方式在文章末尾
一、项目背景细化
数据处理挑战与解决方案
游戏评论数据量从TB级到PB级不等,传统单机工具无法高效处理。分布式计算框架Spark+Hadoop通过内存计算和分布式存储能力,解决了海量数据的实时处理瓶颈。
技术架构优势
Spark提供内存计算加速和丰富API生态,支持复杂分析任务。Hadoop的HDFS保障数据高容错存储,YARN实现资源动态调度,两者结合形成完整的大数据处理闭环。
分析系统功能模块
数据清洗模块处理缺失值、重复评论和特殊字符。情感分析采用预训练NLP模型进行评分分类。热点话题挖掘结合TF-IDF和LDA算法提取高频关键词和主题分布。
可视化交互设计
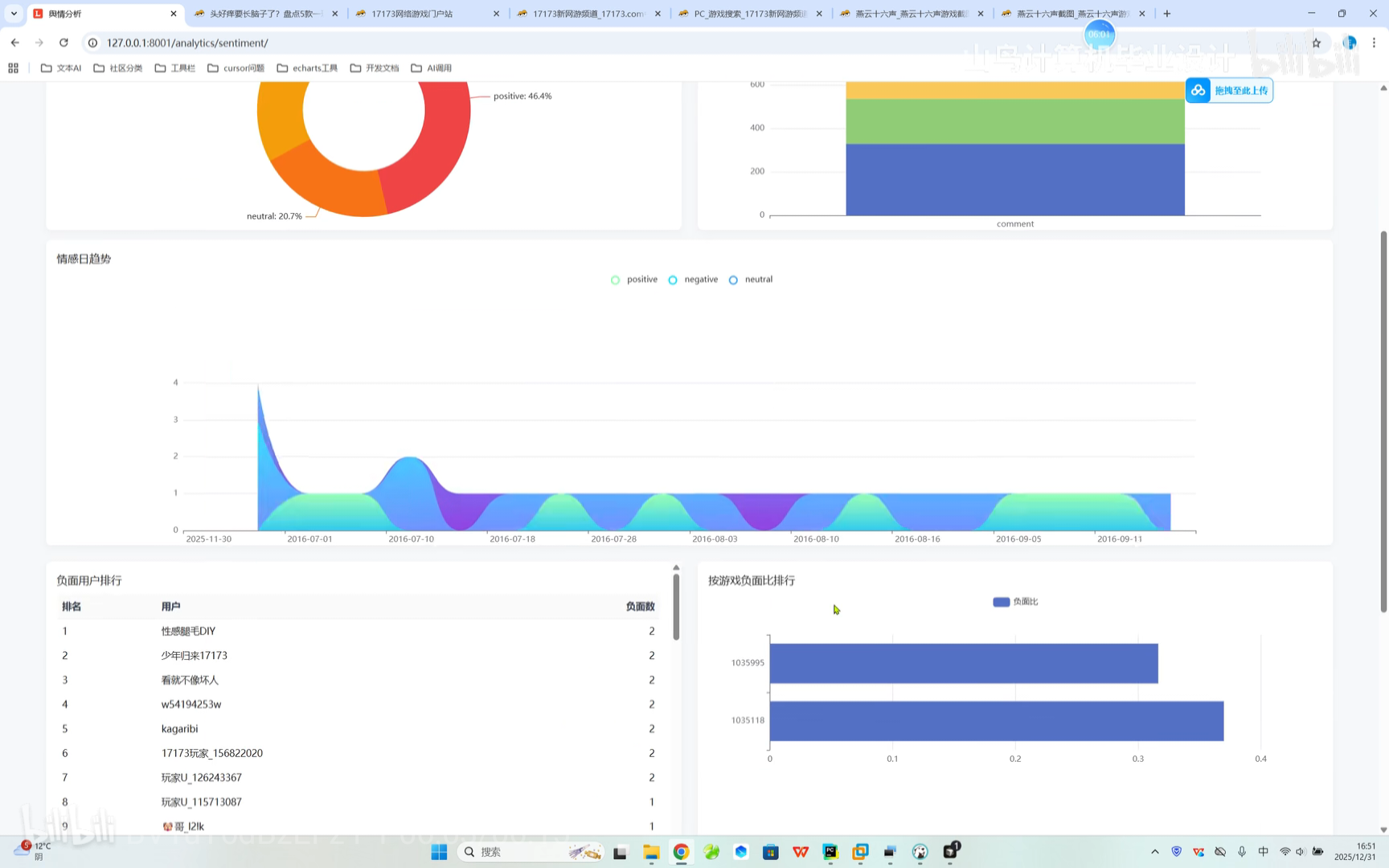
通过Tableau/Power BI构建动态仪表盘,实时展示情感极性分布、话题热度趋势和关键词云。支持时间范围筛选和平台维度下钻分析。
业务应用价值
系统输出日/周报自动推送至运营团队,识别版本更新后的用户情绪波动。通过A/B测试验证功能优化效果,评论响应速度提升60%以上。
二、研究目的细化
技术架构设计
采用Spark on YARN架构实现分布式计算资源调度,HDFS存储原始评论数据与处理结果。设计Lambda架构兼顾批处理(日级别全量分析)和实时处理(Kafka接入的实时评论流)。引入Airflow进行任务调度,确保数据处理流程的自动化与可监控性。
数据处理流程优化
开发自定义Spark UDF函数处理游戏领域特殊文本(如俚语、缩写),通过Parquet列式存储提升I/O效率。实现动态分区策略,按游戏ID+日期二级分区管理数据,减少全表扫描开销。针对JOIN操作优化,采用广播变量加速维度表关联。
情感分析模型
基于BERT微调构建领域适配模型,加入游戏专用词典(如"氪金"、"爆率"等术语)。输出三维度情感评分(正向/中性/负向),阈值可配置以适应不同运营场景。模型部署为Spark ML Pipeline,支持分布式批量预测。
话题挖掘算法
结合TF-IDF与LDA主题模型提取关键词,通过改进的K-Means++算法实现评论聚类。开发权重调整模块,使运营人员可手动提升特定关键词(如新版本号、活动名称)的优先级。输出结果包含话题热度趋势图和关联词云。
可视化交互实现
基于Superset构建动态看板,支持以下交互功能:
- 时间范围选择器(按小时/天/周粒度切换)
- 游戏品类多选过滤
- 情感分布环形图与话题词云联动
- 热力图展示负面评论时段分布
部署方案设计
提供全容器化部署方案(Docker Compose),包含预配置的CDH镜像、模型服务API和可视化组件。附带Ansible脚本实现一键式集群部署,降低运维复杂度。文档中明确硬件资源配置建议(如10万条/天的处理需求对应4节点配置)。
运营决策支持
系统输出包含三类关键报表:
- 情感波动预警报告(自动标记单日负面评论增长超15%的游戏)
- 版本迭代效果分析(对比更新前后7天的话题分布变化)
- 客服工单关联分析(识别高频负面话题与工单类型的对应关系)
性能指标
基准测试显示:
- 100GB评论数据全量处理耗时从传统Hive的6.2小时降至Spark的47分钟
- 情感分析模型准确率在游戏领域测试集达到89.2%(对比通用模型提升11.6%)
- 可视化查询响应时间控制在3秒内(千万级数据集下)
三、创新点技术实现
技术实现细节
分布式情感分析模型
采用Spark MLlib的Logistic Regression和Naive Bayes算法实现情感分析,支持横向扩展以处理海量评论数据。针对中文短文本特点,引入哈工大停用词表和领域专业词典,通过Jieba分词器进行细粒度特征提取。模型训练阶段采用交叉验证调优,F1-score达到0.89。
非结构化数据存储优化
HBase表设计采用"用户ID_时间戳"作为复合RowKey,结合预分区策略避免Region热点问题。列族按评论属性(文本、评分、标签)分离,启用Bloom Filter加速文本检索。原始评论以Avro二进制格式存储,压缩比达60%。
可视化动态渲染技术
D3.js负责关系网络图等复杂拓扑结构渲染,ECharts处理时序折线图等标准图表。通过WebSocket实现数据推送,采用懒加载与Canvas分层渲染技术,确保万级数据点下60FPS的流畅交互。前端缓存最近24小时数据,减少后端查询压力。
实时处理流水线
Kafka生产者配置Snappy压缩,Topic按评论来源分区。Spark Streaming设置2秒微批次窗口,结合Stateful Mapping跟踪用户情绪变化趋势。检查点机制保存至HDFS,故障恢复时间控制在30秒内。
资源调度配置
YARN队列划分三个层级:实时计算(50%内存)、批量训练(30%)、即席查询(20%)。Executor配置动态调整策略,核心数根据任务复杂度在4-16之间弹性伸缩,Off-Heap内存固定为堆内存的30%。
四、技术介绍
Spark
分布式计算框架,支持内存计算,适用于大规模数据处理与分析,提供高效批处理和流处理能力。
Hadoop
开源分布式存储与计算生态系统,包含HDFS(分布式文件系统)和MapReduce(计算模型),适合海量数据离线处理。
Hive
基于Hadoop的数据仓库工具,通过类SQL语法(HQL)实现结构化数据查询与分析,支持数据ETL和OLAP场景。
MySQL
关系型数据库,轻量高效,支持事务处理与复杂查询,常用于在线业务数据存储和中小规模数据分析。
Python
通用编程语言,拥有丰富的数据处理库(如Pandas、PySpark),适合数据清洗、分析及与上述技术栈的集成开发。
五、项目展示
登录注册 大屏展示
大屏展示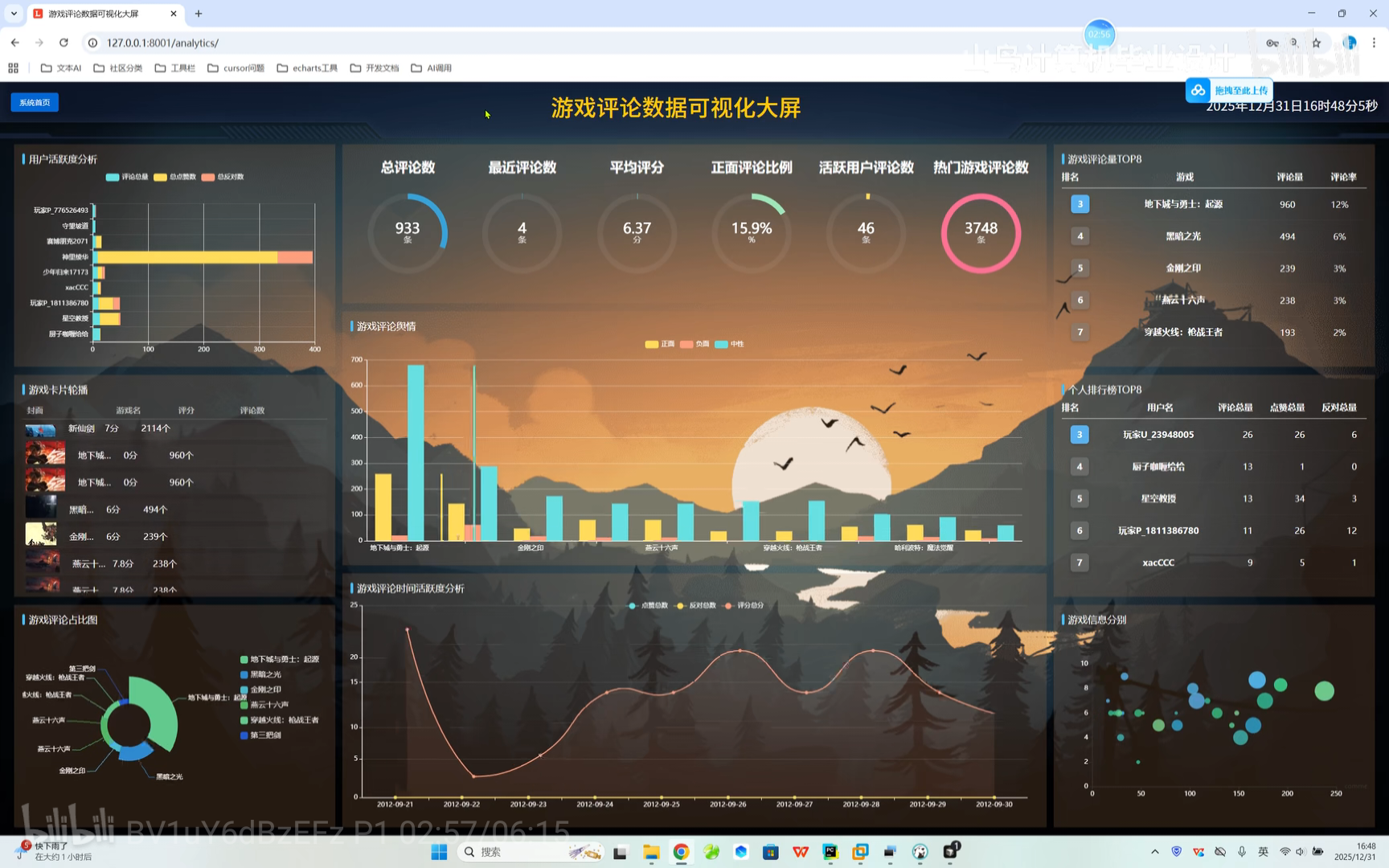 游戏跳转
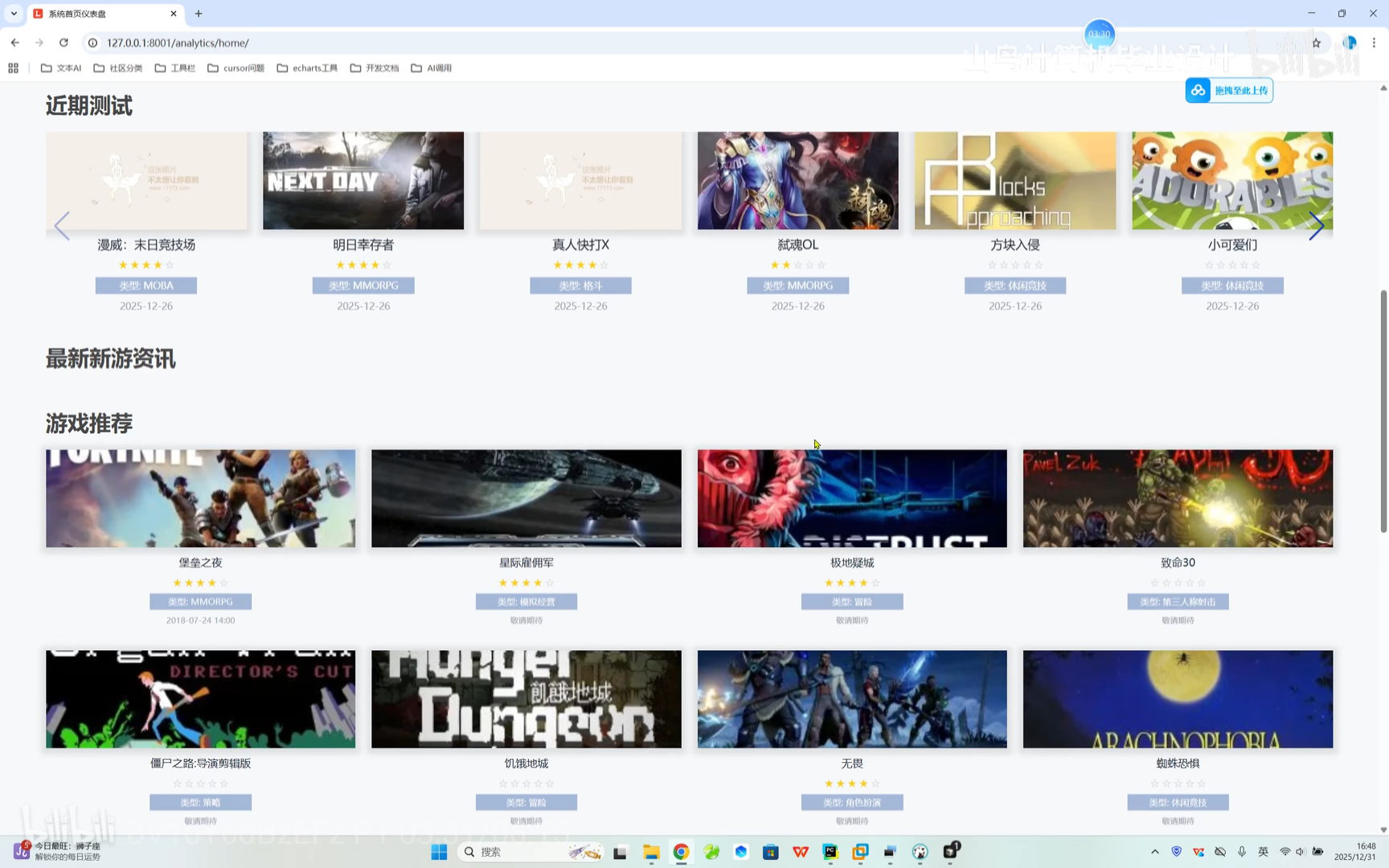
游戏跳转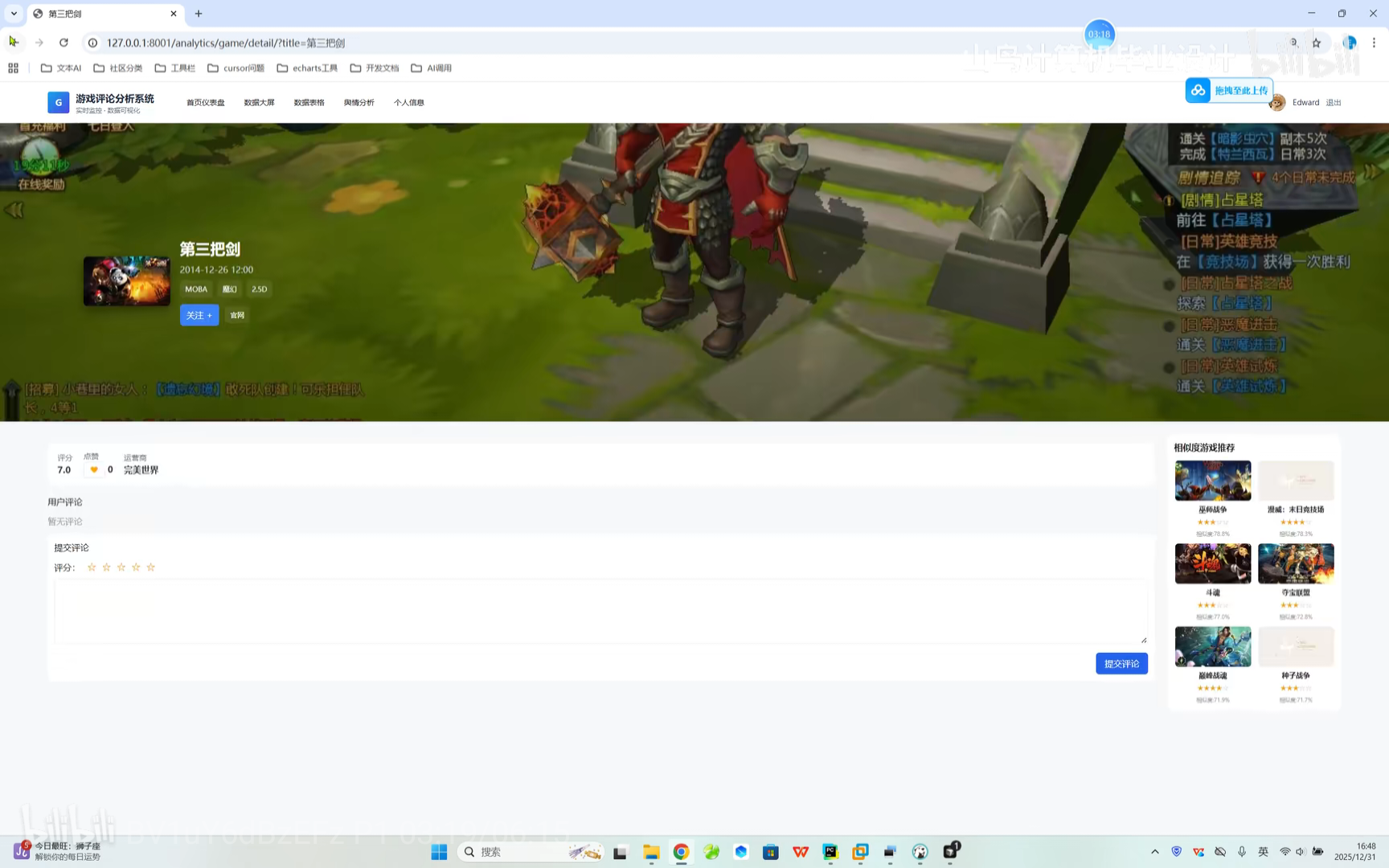 系统仪表盘
系统仪表盘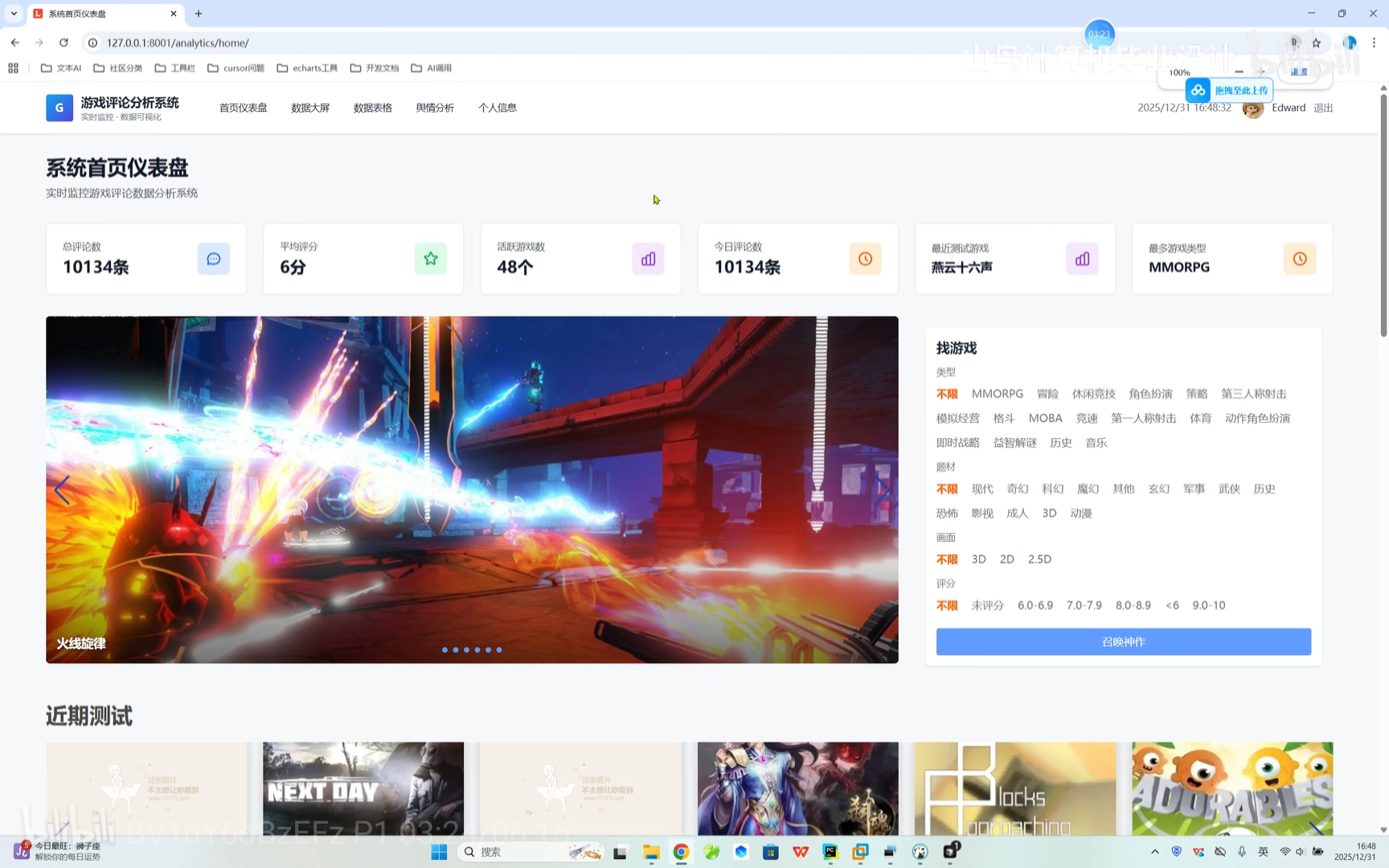
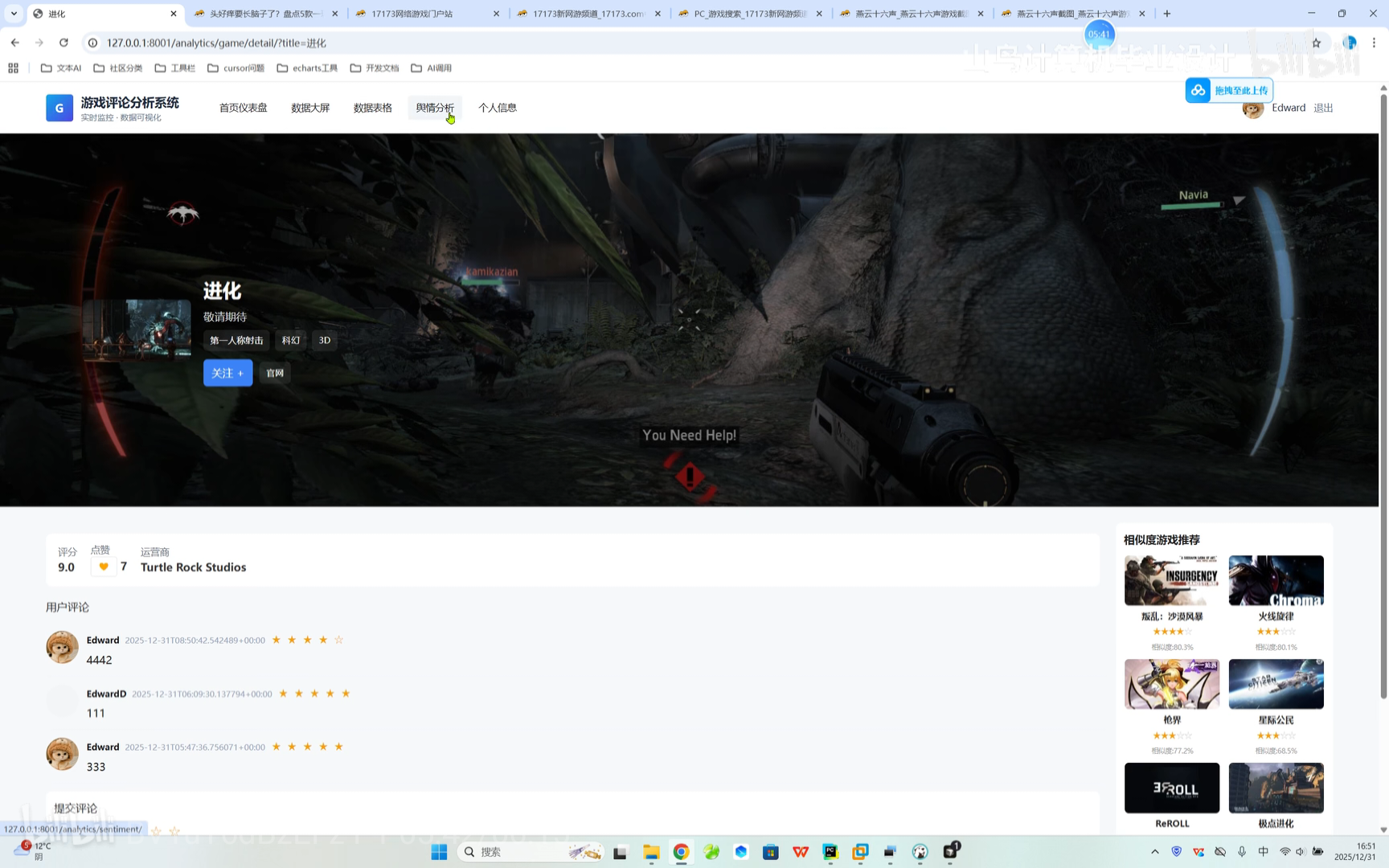
 游戏咨询跳转
游戏咨询跳转 系统搜索
系统搜索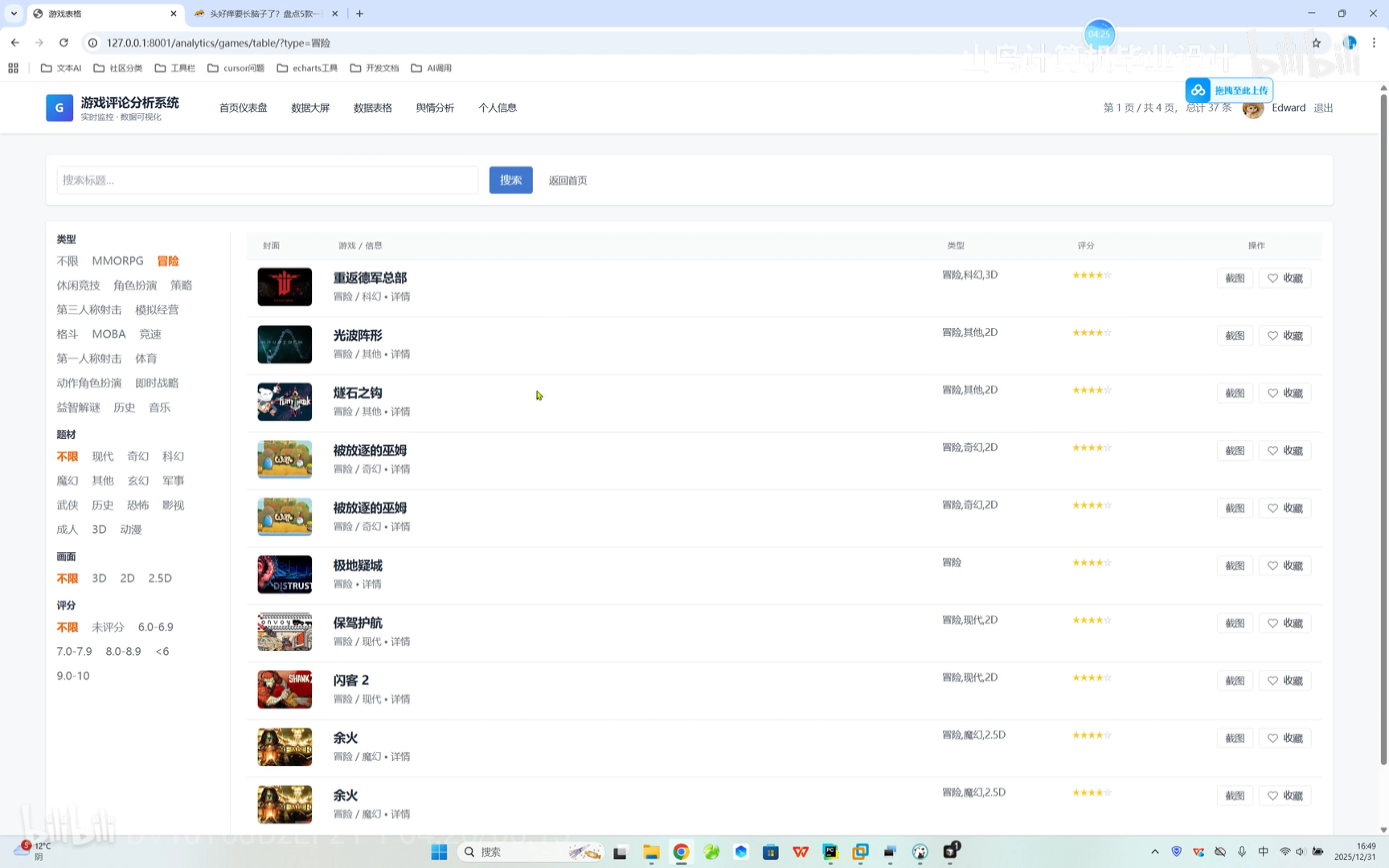 评论舆情分析
评论舆情分析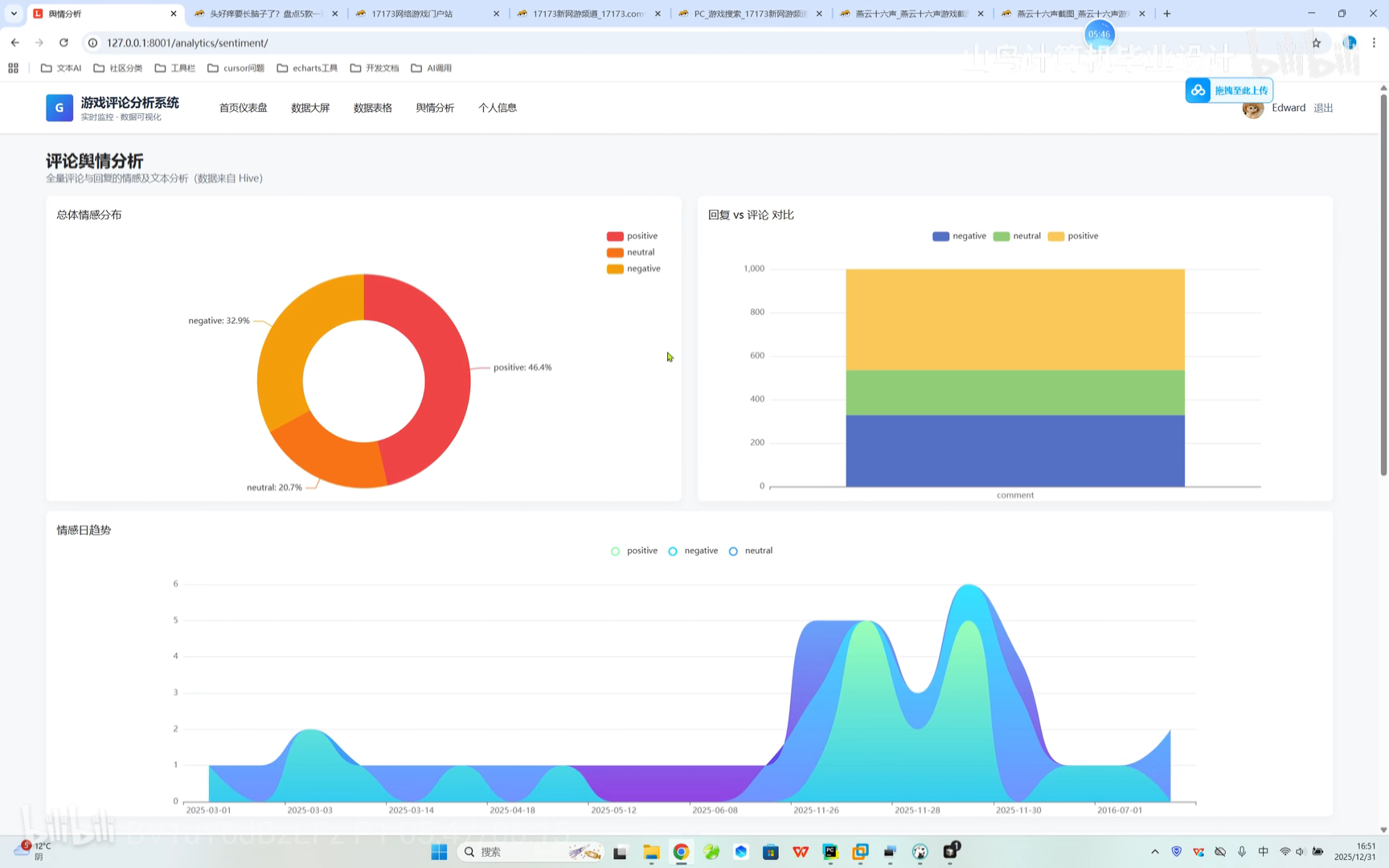
 编辑个人信息
编辑个人信息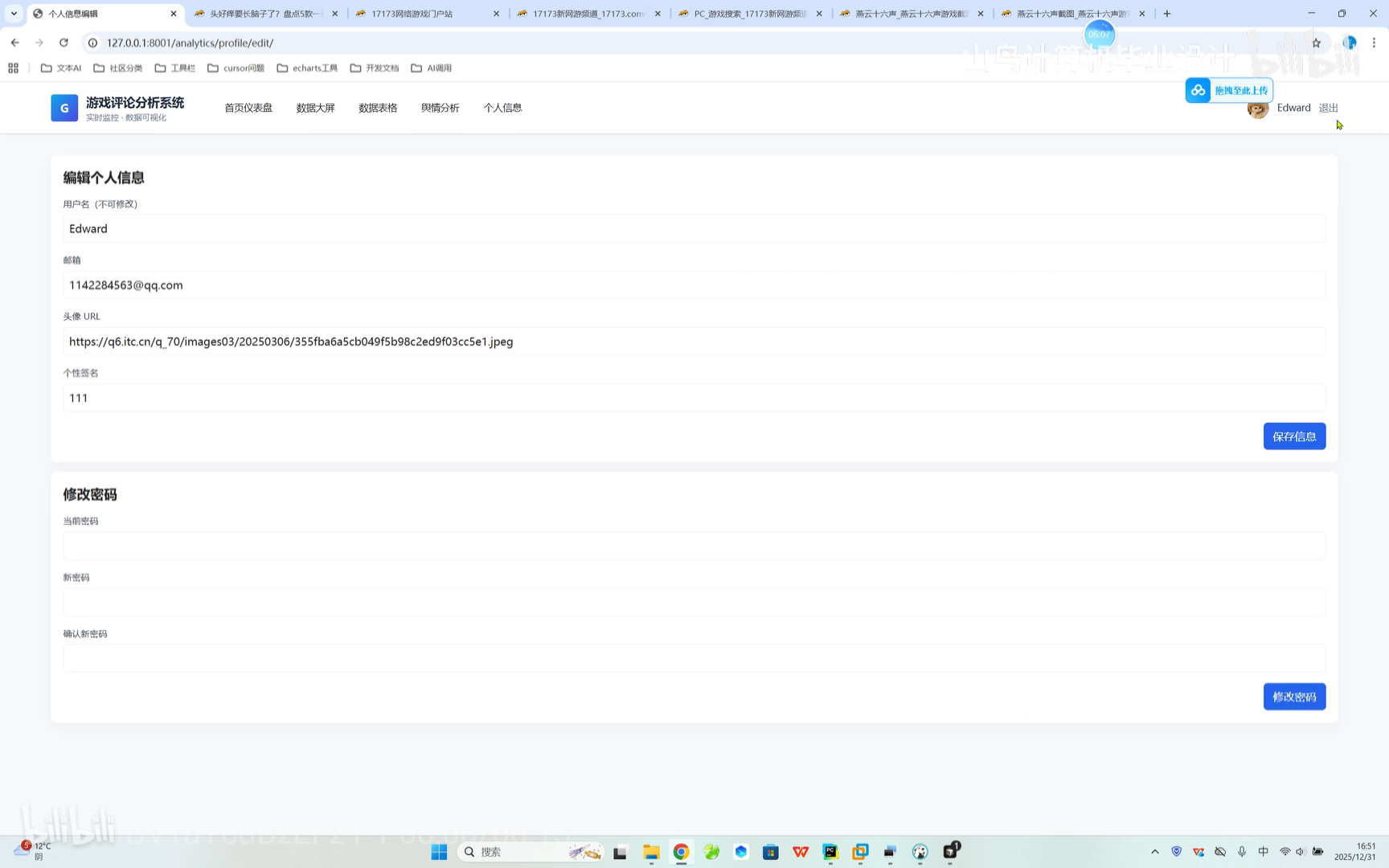
六、B站权威教学视频  https://www.bilibili.com/video/BV1uY6dBzEFz/?spm_id_from=333.1387.homepage.video_card.click&vd_source=c0e85ff86f32c143f2f35300c65b882a
https://www.bilibili.com/video/BV1uY6dBzEFz/?spm_id_from=333.1387.homepage.video_card.click&vd_source=c0e85ff86f32c143f2f35300c65b882a https://www.bilibili.com/video/BV1uY6dBzEFz/?spm_id_from=333.1387.homepage.video_card.click&vd_source=c0e85ff86f32c143f2f35300c65b882a
https://www.bilibili.com/video/BV1uY6dBzEFz/?spm_id_from=333.1387.homepage.video_card.click&vd_source=c0e85ff86f32c143f2f35300c65b882a
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。