一、MySQL 事务核心知识点总结
1.事务的本质
定义 :事务是一个不可分割的工作单位,包含的一系列操作要么全部执行成功,要么全部失败回滚。典型场景 :银行转账(A 扣款、B 入账,必须同时成功或同时失败)。一句话记忆:要么都成,要么都不成。
2.事务四大特性(ACID)
这是面试必问点,记住每个特性的核心含义:
| 特性 | 英文 | 核心含义 | 面试举例 |
|---|---|---|---|
| 原子性 | Atomicity | 事务是最小的执行单元,不可拆分,要么全执行,要么全回滚 | 转账时,A 扣款失败则 B 入账也必须取消,不能只扣不增 |
| 一致性 | Consistency | 事务执行前后,数据库的完整性约束(如金额不变)始终保持 | 转账前后,A 和 B 的总金额不变 |
| 隔离性 | Isolation | 事务执行过程中对其他事务不可见(隔离级别不同表现不同) | A 转账过程中,其他事务看不到 A 的临时扣款状态 |
| 持久性 | Durability | 事务提交后,修改永久保存到数据库,即使系统崩溃也不会丢失 | 转账成功提交后,即使服务器断电,数据依然有效 |
记忆口诀:原(Atomicity)一(Consistency)隔(Isolation)久(Durability)
3.事务的四个隔离级别
面试常考隔离级别及对应问题,记住级别从低到高,并发度从高到低,一致性从低到高:
| 隔离级别 | 英文 | 核心特点 | 可能出现的问题 |
|---|---|---|---|
| 读未提交 | READ UNCOMMITTED | 允许读取其他事务未提交的数据 | 脏读(读到临时无效数据) |
| 读已提交 | READ COMMITTED | 只能读取其他事务已提交的数据 | 不可重复读(同一事务内两次查询结果不同) |
| 可重复读 | REPEATABLE READ | 同一事务内多次读取结果一致(MySQL 默认级别) | 幻读(新增 / 删除数据导致前后结果行数变化) |
| 可串行化 | SERIALIZABLE | 事务串行执行,完全隔离 | 性能最差,并发度最低 |
面试高频问题:
- MySQL 默认隔离级别是 可重复读(REPEATABLE READ)。
- 解决 "脏读" 至少需要 读已提交(READ COMMITTED) 级别。
- 解决 "幻读" 需要 可串行化(SERIALIZABLE) 级别,或 InnoDB 的 MVCC 机制。
4.事务操作核心命令(面试写代码必备)
cpp
-- 开启事务(二选一)
BEGIN;
-- 或
START TRANSACTION;
-- 执行数据操作(如转账:A扣款、B入账)
UPDATE account SET balance = balance - 100 WHERE name = 'A';
UPDATE account SET balance = balance + 100 WHERE name = 'B';
-- 提交事务(所有操作生效,持久化到数据库)
COMMIT;
-- 回滚事务(所有操作取消,恢复到事务开始前状态)
ROLLBACK;面试考点:
- 开启事务后,所有修改会先保存在缓存,
COMMIT才会写入磁盘。 - 如果事务执行中出错或主动执行
ROLLBACK,缓存中的修改会被丢弃。
5.面试高频问答速记
-
Q:什么是脏读、不可重复读、幻读?
- 脏读:读到其他事务未提交的临时数据。
- 不可重复读:同一事务内,两次读同一数据结果不同(被其他事务修改并提交)。
- 幻读:同一事务内,两次查询结果的行数不同(被其他事务新增 / 删除并提交)。
-
Q:ACID 分别指什么?
- A:原子性(Atomicity),C:一致性(Consistency),I:隔离性(Isolation),D:持久性(Durability)。
-
Q:MySQL 默认的隔离级别是什么?
- 可重复读(REPEATABLE READ)。
演示
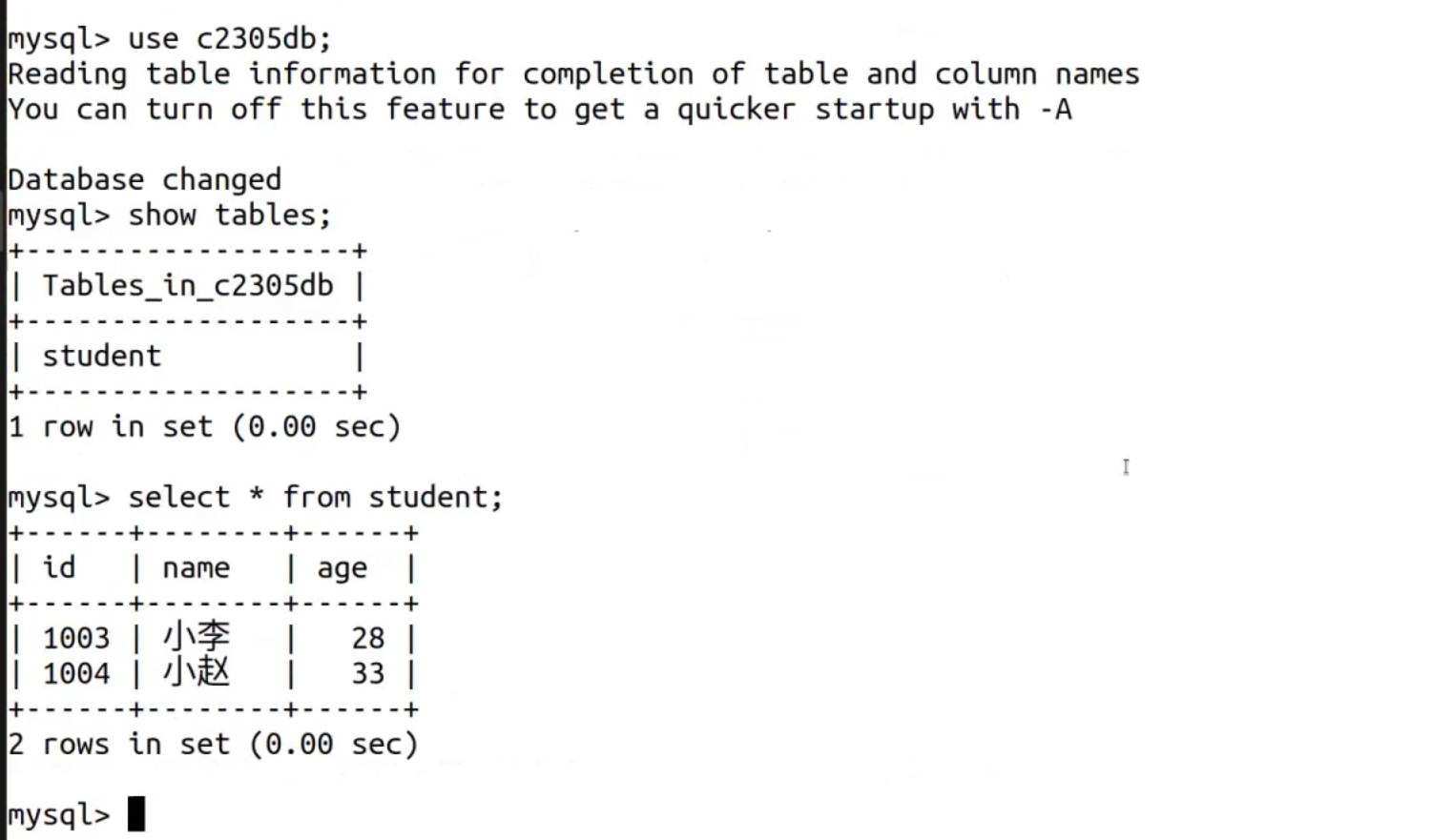
begin 事务开启
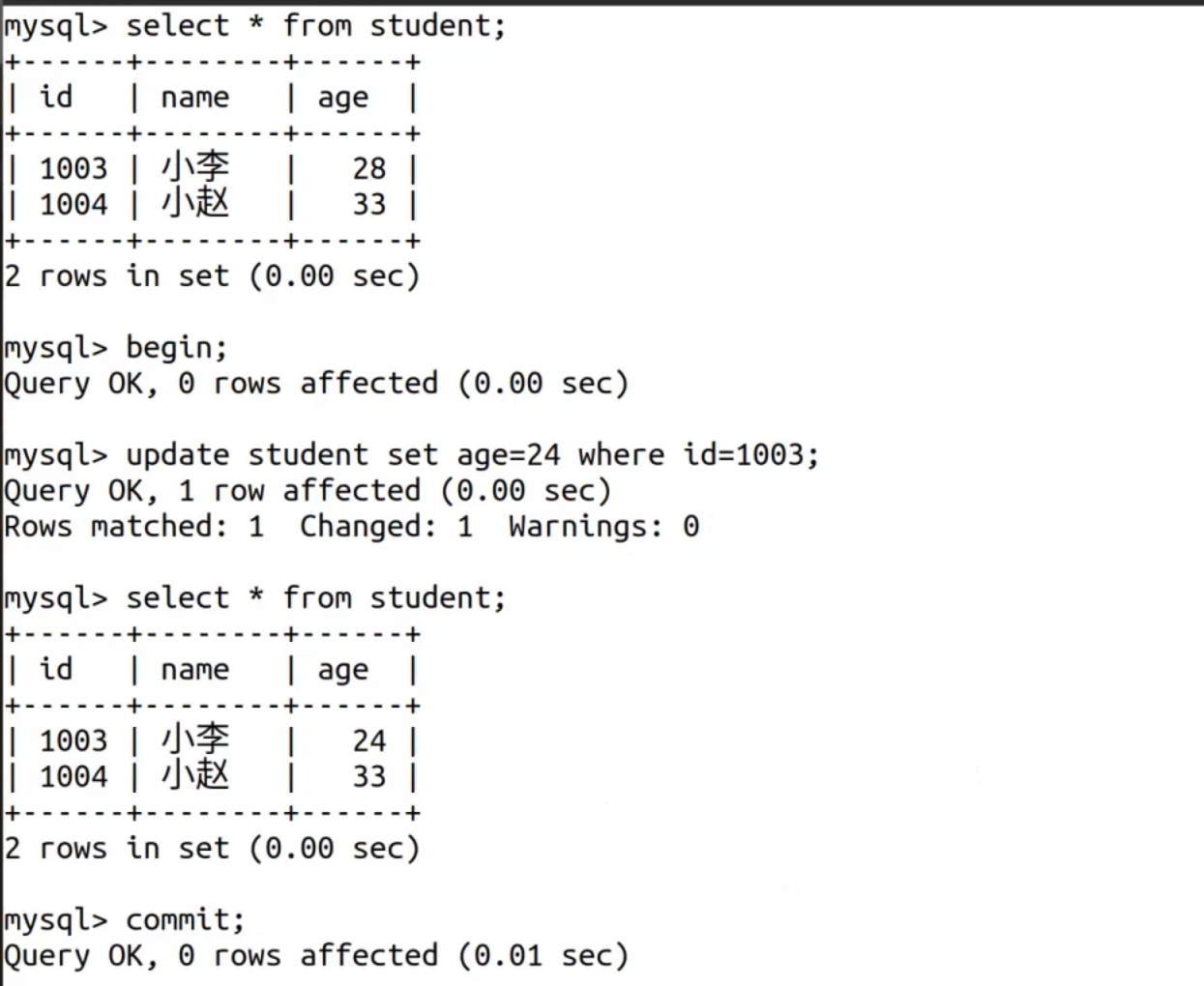
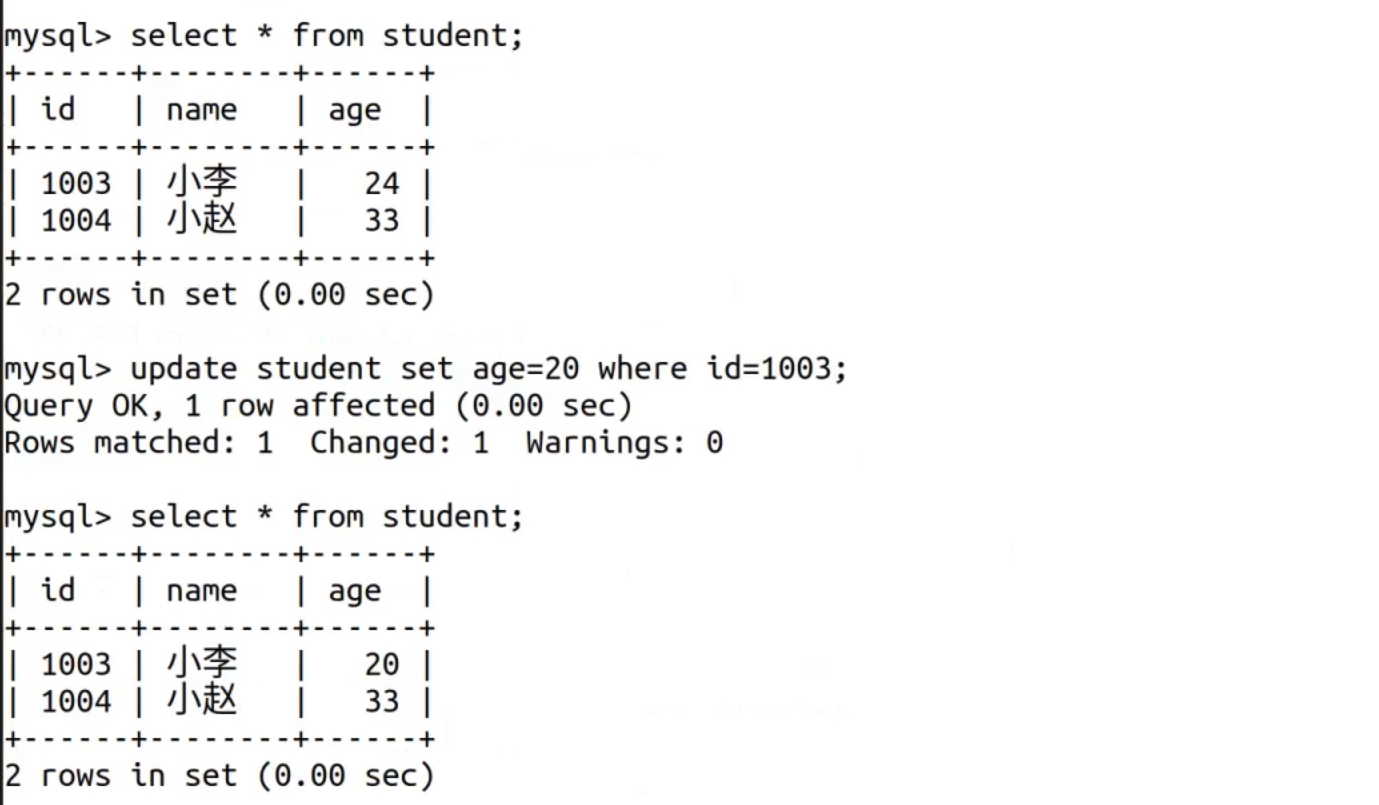
假如我现在认为出了问题 不想提交 现在就需要回滚,放弃刚才的操作

二、MySQL 事务隔离级别
1.隔离级别的核心逻辑
隔离级别定义了一个事务中的修改,在事务内和事务间的可见性规则。
- 隔离级别越低 → 并发度越高,系统开销越低,但一致性越差
- 隔离级别越高 → 一致性越好,但并发度越低,系统开销越高
不同存储引擎(如 InnoDB、MyISAM)对隔离级别的实现可能不同,需以实际引擎为准。
2.四种隔离级别对比
| 隔离级别 | 英文 | 核心特点 | 可见性 | 存在问题 | 适用场景 |
|---|---|---|---|---|---|
| 读未提交 | READ UNCOMMITTED | 事务中的修改即使未提交,对其他事务也可见 | 能读到其他事务未提交的数据 | 脏读(读到临时无效数据) | 几乎不用,仅在极端性能需求且能接受数据不一致时使用 |
| 读已提交 | READ COMMITTED | 只能读到其他事务已提交的修改 | 事务开始后,只能看见已提交的修改 | 不可重复读(同一事务内两次查询结果不同) | 大多数数据库(如 Oracle、SQL Server)的默认级别 |
| 可重复读 | REPEATABLE READ | 同一事务内多次读取同一数据,结果始终一致 | 事务开始时的快照数据,后续修改不可见 | 理论上存在幻读(InnoDB 通过 MVCC 解决) | MySQL InnoDB 的默认级别,平衡一致性与并发 |
| 可串行化 | SERIALIZABLE | 事务串行执行,完全隔离 | 每次读取都会加锁,其他事务必须等待 | 性能极差,锁冲突多 | 仅在需要绝对一致性、可接受无并发的场景使用 |
3.面试高频考点速记
- MySQL 默认隔离级别:可重复读(REPEATABLE READ)。
- 大多数数据库默认隔离级别:读已提交(READ COMMITTED)。
- 脏读、不可重复读、幻读的对应级别 :
- 脏读 → 读未提交(READ UNCOMMITTED)
- 不可重复读 → 读已提交(READ COMMITTED)
- 幻读 → 可重复读(REPEATABLE READ)(InnoDB 通过 MVCC 解决)
- InnoDB 解决幻读的机制:多版本并发控制(MVCC)+ 间隙锁(Next-Key Lock)。
- 可串行化的实现方式:对读取的每一行加锁,事务串行执行,避免所有并发问题,但性能最差。
4.记忆口诀
未提脏,已提复,可重读,串行化
- 未提 → 读未提交 → 脏读
- 已提 → 读已提交 → 不可重复读
- 可重 → 可重复读 → 幻读(InnoDB 已解决)
- 串行 → 可串行化 → 完全隔离
三、MySQL 视图(View)核心知识点总结
1.视图的核心概念
- 本质 :视图是一张虚拟表 ,数据库中不存储实际数据,只存储定义视图的
SELECT语句。 - 数据来源 :视图的数据来自定义它时用到的基本表 ,每次查询视图时,都会动态执行
SELECT语句生成结果。 - 透明性:对用户来说,使用视图和使用普通表几乎完全一样,无需关心底层的查询细节。
2.为什么使用视图
- 简化复杂查询:把多表关联、过滤等复杂逻辑封装在视图里,后续只需查询视图,无需重复编写复杂 SQL。
- 复用 SQL 逻辑:同一段查询逻辑可以通过视图在多个地方复用,避免代码冗余。
- 数据安全与权限控制:可以只给用户开放视图的访问权限,而不是整个基本表,实现 "部分可见",保护敏感数据。
- 隐藏底层表结构:如果底层表结构发生变化,只需修改视图定义,无需修改上层应用的查询语句,降低耦合。
- 自定义数据展示:可以通过视图重新组织、格式化数据,满足不同用户的展示需求。
3.视图的性能问题
-
动态生成开销 :视图本身不存储数据,每次查询视图时,都要重新执行底层的
SELECT语句。如果视图定义包含多表关联、嵌套视图或复杂过滤,会导致性能下降。 -
不适合频繁更新 :对视图的更新(
INSERT/UPDATE/DELETE)会被转换为对基本表的操作,且有严格限制(如视图必须包含基本表的主键,不能有聚合函数等),频繁更新会影响效率。 -
优化建议 :复杂场景下,建议用物化视图(部分数据库支持)或提前计算结果存入物理表,替代普通视图。
4.视图的核心操作
1. 创建视图
-- 建议以 v_ 开头命名,方便识别
CREATE VIEW v_student_info AS
SELECT id, name, addr FROM student WHERE age >= 18;2. 查询视图
SELECT * FROM v_student_info;3. 修改视图
ALTER VIEW v_student_info AS
SELECT id, name, tel, addr FROM student WHERE age >= 18;4. 删除视图
DROP VIEW IF EXISTS v_student_info;5.面试高频补充知识点
-
视图与表的区别
特性 视图 表 存储 仅存储 SELECT定义,不存数据存储实际数据 占用空间 几乎不占空间 占用磁盘空间 数据更新 依赖基本表,有严格限制 直接更新 性能 每次查询动态生成,复杂场景性能差 直接读取数据,性能稳定 -
视图的可更新条件只有满足以下条件的视图才能被更新:
- 视图中不包含
DISTINCT、GROUP BY、HAVING、聚合函数(SUM/COUNT等)。 - 视图的
SELECT语句不包含多表关联或子查询。 - 视图必须包含基本表的主键或唯一约束字段。
- 视图中不包含
-
适用场景 vs 不适用场景 ✅ 适合 :复杂查询复用、权限控制、隐藏底层结构。❌ 不适合:频繁更新的场景、对性能要求极高的场景。
四、索引MySQL 索引核心知识点整理(面试版)
1.引入索引的背景
核心问题
在数据量较大的场景下,数据库的查询效率会成为系统性能的瓶颈。
类比理解
就像在图书馆找书,如果没有索引(图书分类目录),你需要逐书架查找;有了索引,就能快速定位目标位置。
业务场景
绝大多数软件系统的数据库操作以查询为主,优化查询是提升系统性能的关键。
2.索引的本质与特性
定义
索引是一种帮助 MySQL 高效获取数据的数据结构,它是一个特殊文件,包含指向数据表中所有记录的引用指针。
核心特点
- 本质是数据结构:不是单纯的文件,而是为加速查询设计的存储结构。
- 存储依赖存储引擎 :不同存储引擎(如 InnoDB、MyISAM)的索引文件存储形式不同。
- InnoDB:索引和数据存放在同一个文件(.ibd),采用聚簇索引结构。
- MyISAM:索引和数据分开存储(.MYI 为索引文件,.MYD 为数据文件)。
- 类似书籍目录:通过索引可以快速定位数据位置,避免全表扫描。
3.索引为什么选择 B+ 树
常见候选数据结构对比
| 数据结构 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Hash 表 | 等值查询速度极快(O (1)) | 1. 不支持范围查询(如 >, <, BETWEEN)2. 需要将数据全量加载到内存,空间浪费大3. 无法利用索引排序 |
仅等值查询的场景(如字典查询) |
| 二叉搜索树(BST) | 理论上查询效率较高 | 1. 数据有序时会退化为链表,查询效率降至 O (n)2. 树高过高,磁盘 I/O 次数多 | 数据量极小且无序的场景 |
| 平衡二叉树(AVL / 红黑树) | 保持树平衡,查询效率稳定在 O (log n) | 1. 树高仍然较高(百万级数据需约 20 层)2. 每个节点仅存 1 条数据,磁盘 I/O 次数多 | 内存中的小数据量场景 |
| B 树 | 多叉结构,降低树高,减少 I/O 次数 | 1. 非叶子节点存储数据,空间利用率低2. 范围查询需要回溯节点,效率低 | 少量数据的磁盘存储场景 |
| B+ 树 | 1. 非叶子节点仅存索引,空间利用率高,树高更矮2. 所有数据存在叶子节点,且叶子节点间用链表相连3. 范围查询只需遍历叶子节点链表,效率极高4. 磁盘块读写效率高(一次 I/O 可读取更多索引) | 插入 / 删除时需维护节点平衡,实现稍复杂 | 数据库索引的标准实现(InnoDB 默认索引结构) |
B+ 树成为最优选择的核心原因
- 适配磁盘 I/O 模型:数据库数据存储在磁盘,I/O 是性能瓶颈。B+ 树的多叉结构大幅降低树高,将磁盘 I/O 次数从平衡二叉树的 20+ 次降至 3-4 次。
- 范围查询效率高:叶子节点通过链表相连,执行范围查询时只需遍历链表,无需回溯非叶子节点。
- 空间利用率更高:非叶子节点仅存储索引键,不存数据,一个磁盘块可容纳更多索引项,进一步减少 I/O 次数。
4.面试高频延伸问题
- 聚簇索引 vs 非聚簇索引
- 聚簇索引(InnoDB 主键索引):索引和数据存储在一起,叶子节点直接存数据行。
- 非聚簇索引(二级索引):叶子节点存储主键值,需回表查询获取完整数据。
- 最左前缀原则 联合索引生效需遵循最左前缀匹配,例如
(a,b,c)索引仅对a、a,b、a,b,c的查询生效。 - 索引失效场景 字段使用函数、类型隐式转换、模糊查询以
%开头、OR连接的字段未全部建索引等。