序
本文是国科大《模式识别与机器学习》课程的简要复习,基于课件然后让ai帮忙补充了一些解释。本文是第九到第十二章。(原本是包括第十三章深度学习部分的,但是单篇文章现在有字数限制,加上第十三章发不出来,那部分只好删掉写在另一篇文章里面)本文章更多是对于课件的知识点的记录总结,找了点例题和讲解,建议结合其他资料或者课件来看。
第九章 降维-特征变换
9.1 线性降维基础与动机
核心问题:高维数据 → 维度灾难
高维空间中,点与点之间的欧氏距离变得非常相似(大部分点都集中在球壳上),导致很多算法失效。
(想象:2维、3维距离分布还比较宽,到10维、100维、1000维后,距离几乎全部挤在非常窄的区间,几乎都差不多远了)
线性降维一般形式
数据:
X=(x1,x2,...,xN)∈RD×NX = (x^1, x^2, \dots, x^N) \in \mathbb{R}^{D \times N}X=(x1,x2,...,xN)∈RD×N (D维,N个样本)
低维表示:
Z=(z1,z2,...,zN)∈RD′×NZ = (z^1, z^2, \dots, z^N) \in \mathbb{R}^{D' \times N}Z=(z1,z2,...,zN)∈RD′×N (D' << D)
投影矩阵:
W=w1,w2,...,wD′∈RD×D′W = w_1, w_2, \\dots, w_{D'} \in \mathbb{R}^{D \times D'}W=w1,w2,...,wD′∈RD×D′ (列向量是投影方向)
降维公式(核心公式 ):
Z=WTX或对单个样本z=WTx Z = W^T X \qquad \text{或对单个样本} \quad z = W^T x Z=WTX或对单个样本z=WTx
【直观理解】
想象你在D维空间里有一堆点,你选D'个互相正交的"新坐标轴"(就是w1到wD'),然后把所有点投影到这些新轴上,得到的新坐标就是z。这就是线性降维最本质的操作。
这一章重点在mds和pca算法上:
MDS vs PCA 快速对比表
| 项目 | MDS | PCA |
|---|---|---|
| 输入 | 距离矩阵 D | 原始数据矩阵 X |
| 目标 | 保持点对间距离 | 最小重构误差 或 最大方差 |
| 是否需要原始坐标 | 不需要 | 需要 |
| 计算复杂度 | O(N³)(特征分解) | O(min(N,D)³) 或 SVD 更快 |
| 几何意义 | 全局距离保持 | 最大信息量方向投影 |
| 典型应用 | 心理度量、城市嵌入 | 特征提取、降噪、人脸识别 |
9.2 多维缩放 MDS(经典距离保持方法)
核心目标 :只给你距离矩阵 ,恢复出点的低维坐标,使得低维欧氏距离尽可能等于原始距离(距离保持 )

典型应用场景:城市间距离表 → 画地图(经典例子)
经典MDS算法核心步骤
(下面公式我跳过了推导过程,不好理解的话看下面例题就行。考试的话能记住公式会算应该够了)
-
已知距离矩阵 D=dijD = d_{ij}D=dij (dijd_{ij}dij是第i个点到第j个点的距离)
-
构造内积矩阵 B
假设低维点已中心化(∑zi=0\sum z^i = 0∑zi=0),则:
dij2=∥zi∥2+∥zj∥2−2(zi)Tzj d_{ij}^2 = \|z^i\|^2 + \|z^j\|^2 - 2 (z^i)^T z^j dij2=∥zi∥2+∥zj∥2−2(zi)Tzj
经过一系列行/列求和 + 中心化操作,最终得到:
bij=−12(dij2−1N∑kdik2−1N∑kdkj2+1N2∑k,ldkl2) b_{ij} = -\frac{1}{2} \left( d_{ij}^2 - \frac{1}{N}\sum_k d_{ik}^2 - \frac{1}{N}\sum_k d_{kj}^2 + \frac{1}{N^2}\sum_{k,l} d_{kl}^2 \right) bij=−21 dij2−N1k∑dik2−N1k∑dkj2+N21k,l∑dkl2
bij=−12(dij2−行平均−列平均+全局平均)b_{ij} = -\frac{1}{2} \Bigg( d_{ij}^2 \quad {\color{red} - \text{行平均} } \quad {\color{blue} - \text{列平均} } \quad {\color{purple} + \text{全局平均} } \Bigg)bij=−21(dij2−行平均−列平均+全局平均)
矩阵形式:
B=−12JD(2)JJ=I−1N11T(中心化矩阵) B = -\frac{1}{2} J D^{(2)} J \qquad J = I - \frac{1}{N} \mathbf{1}\mathbf{1}^T \quad \text{(中心化矩阵)}B=−21JD(2)JJ=I−N111T(中心化矩阵)
-
对 B 做特征值分解:
B=VΛVT B = V \Lambda V^T B=VΛVT
-
取前 D' 个最大特征值及其向量:
Z=Λ~1/2V~T Z = \tilde{\Lambda}^{1/2} \tilde{V}^T Z=Λ~1/2V~T
【直观理解】
MDS 就像"只知道城市间开车距离,却要画出一张尽量准确的地图"。它通过数学手段把"距离"转换成了"内积",再用特征分解直接得到坐标------非常优雅,但计算量大(O(N³))。
zzz = (z¹, z², ..., zᴺ) 就是我们最终想要得到的低维坐标
例题
假设3个城市A、B、C在一条直线上,距离矩阵D已知(单位:km)。
目标:用MDS降到1维(D'=1),恢复坐标。
输入:
距离矩阵D(对称,N=3):
D=(012101210)D = \begin{pmatrix} 0 & 1 & 2 \\ 1 & 0 & 1 \\ 2 & 1 & 0 \end{pmatrix}D= 012101210
矩阵是任意两个城市之间的距离,比如A到B=1, A到C=2, B到C=1
直线排列:A--1--B--1--C
步骤1:计算D的平方矩阵D(2)D^{(2)}D(2)(目的:距离平方便于内积公式)。
D(2)=(014101410)D^{(2)} = \begin{pmatrix} 0 & 1 & 4 \\ 1 & 0 & 1 \\ 4 & 1 & 0 \end{pmatrix}D(2)= 014101410
步骤2:计算行均值、列均值、总均值(目的:中心化,消除偏移)。
行均值(每行平均距离平方):
行1(1N∑jd1j2\frac{1}{N} \sum_j d_{1j}^2N1∑jd1j2): (0+1+4)/3 = 5/3
行2: (1+0+1)/3 = 2/3
行3: (4+1+0)/3 = 5/3
列均值同上(D是对称的)。
总均值(全局平均距离平方1N2∑i∑jdij2\frac{1}{N^2}\sum_i \sum_j d_{ij}^2N21∑i∑jdij2):所有元素和/9 = (0+1+4 +1+0+1 +4+1+0)/9 = 12/9 = 4/3
即:
1N∑jd1j2, 1N∑jd2j2, 1N∑jd3j2\]=\[5/3, 2/3, 5/3\]\\left\[ \\frac{1}{N} \\sum_j d_{1j}\^2, \\ \\frac{1}{N} \\sum_j d_{2j}\^2, \\ \\frac{1}{N} \\sum_j d_{3j}\^2 \\right\] = \[5/3, \\ 2/3, \\ 5/3\]\[N1∑jd1j2, N1∑jd2j2, N1∑jd3j2\]=\[5/3, 2/3, 5/3
步骤3:计算内积矩阵B(用公式,这里仔细看一下是哪个对应哪个)。
对每个bijb_{ij}bij:
bij=−12(dij2−1N∑kdik2−1N∑kdkj2+1N2∑k,ldkl2)b_{ij} = -\frac{1}{2} \left( d_{ij}^2 - \frac{1}{N}\sum_k d_{ik}^2 - \frac{1}{N}\sum_k d_{kj}^2 + \frac{1}{N^2}\sum_{k,l} d_{kl}^2 \right)bij=−21 dij2−N1k∑dik2−N1k∑dkj2+N21k,l∑dkl2
bij=−12(dij2−第i行平均−第j列平均+全局平均)b_{ij} = -\frac{1}{2} \Bigg( d_{ij}^2 \quad {\color{red} - \text{第i行平均} } \quad {\color{blue} - \text{第j列平均} } \quad {\color{purple} + \text{全局平均} } \Bigg)bij=−21(dij2−第i行平均−第j列平均+全局平均)
计算后:
b11=−12(0−5/3−5/3+4/3)=−12(−6/3)=1b_{11} = -\frac{1}{2} (0 - 5/3 - 5/3 + 4/3) = -\frac{1}{2} (-6/3) = \mathbf{1}b11=−21(0−5/3−5/3+4/3)=−21(−6/3)=1
b12=−12(1−5/3−2/3+4/3)=−12(0)=0b_{12} = -\frac{1}{2} (1 - 5/3 - 2/3 + 4/3) = -\frac{1}{2} (0) = \mathbf{0}b12=−21(1−5/3−2/3+4/3)=−21(0)=0
b13=−12(4−5/3−5/3+4/3)=−12(2)=−1b_{13} = -\frac{1}{2} (4 - 5/3 - 5/3 + 4/3) = -\frac{1}{2} (2) = \mathbf{-1}b13=−21(4−5/3−5/3+4/3)=−21(2)=−1
b22=−12(0−2/3−2/3+4/3)=−12(0)=0b_{22} = -\frac{1}{2} (0 - 2/3 - 2/3 + 4/3) = -\frac{1}{2} (0) = \mathbf{0}b22=−21(0−2/3−2/3+4/3)=−21(0)=0
B=(10−1000−101)B = \begin{pmatrix} 1 & 0 & -1 \\ 0 & 0 & 0 \\ -1 & 0 & 1 \end{pmatrix}B= 10−1000−101
步骤4:对B做特征值分解(动机:提取主成分坐标)。
我们需要找到 BBB 的特征值 λ\lambdaλ 和特征向量 vvv。解方程 ∣B−λI∣=0|B - \lambda I| = 0∣B−λI∣=0:∣1−λ0−10−λ0−101−λ∣=0 ⟹ −λ((1−λ)2−1)=0\begin{vmatrix} 1-\lambda & 0 & -1 \\ 0 & -\lambda & 0 \\ -1 & 0 & 1-\lambda \end{vmatrix} = 0 \implies -\lambda((1-\lambda)^2 - 1) = 0 1−λ0−10−λ0−101−λ =0⟹−λ((1−λ)2−1)=0解得特征值为:λ1=2,λ2=0,λ3=0\lambda_1 = 2, \lambda_2 = 0, \lambda_3 = 0λ1=2,λ2=0,λ3=0。因为我们目标是降到 1维(D′=1D'=1D′=1),所以只取最大的特征值 λ1=2\lambda_1 = 2λ1=2。
求 λ1=2\lambda_1 = 2λ1=2 对应的单位特征向量 v1v_1v1:(B−2I)v=0 ⟹ (−10−10−20−10−1)(xyz)=0 ⟹ y=0,x=−z(B - 2I)v = 0 \implies \begin{pmatrix} -1 & 0 & -1 \\ 0 & -2 & 0 \\ -1 & 0 & -1 \end{pmatrix} \begin{pmatrix} x \\ y \\ z \end{pmatrix} = 0 \implies y=0, x=-z(B−2I)v=0⟹ −10−10−20−10−1 xyz =0⟹y=0,x=−z归一化后得:v1=(120−12)v_1 = \begin{pmatrix} \frac{1}{\sqrt{2}} \\ 0 \\ -\frac{1}{\sqrt{2}} \end{pmatrix}v1= 2 10−2 1
步骤5:取前D'=1个,计算Z(低维表示)。
恢复坐标 ZZZ公式为 Z=λ1⋅v1Z = \sqrt{\lambda_1} \cdot v_1Z=λ1 ⋅v1:Z=2⋅(120−12)=(10−1)Z = \sqrt{2} \cdot \begin{pmatrix} \frac{1}{\sqrt{2}} \\ 0 \\ -\frac{1}{\sqrt{2}} \end{pmatrix} = \begin{pmatrix} 1 \\ 0 \\ -1 \end{pmatrix}Z=2 ⋅ 2 10−2 1 = 10−1
最终结果:
恢复出的1维坐标为:城市 A:1 城市 B:0 城市 C:-1
9.3 主成分分析 PCA
核心目标:找数据最重要方向(主成分),投影后保留最大信息(方差)或最小重构误差。
PCA 是线性、无监督,常用于降噪、压缩、特征提取。
(PCA 是前面学过的 K-means 聚类算法的"松弛"版本,在实际应用中,人们经常在运行 K-means 之前先运行 PCA)
PCA 算法过程有两种常见实现(特征分解和 SVD)重点还是看例题就行。
输入:
数据矩阵X=(x1,...,xN)∈RD×NX=(x^1,\dots,x^N)\in\mathbb{R}^{D\times N}X=(x1,...,xN)∈RD×N(D 维,N 个样本)
目标低维维数D′D'D′
训练步骤(两种主流实现)
方式1:协方差矩阵 + 特征分解(最经典)
计算均值向量:xˉ=1N∑j=1Nxj\bar{x}=\frac{1}{N}\sum_{j=1}^N x^jxˉ=N1∑j=1Nxj
中心化:xi←xi−xˉx^i \leftarrow x^i - \bar{x}xi←xi−xˉ(对所有样本做,X 变为中心化矩阵)
计算协方差矩阵:S=XXT∈RD×DS=XX^T\in\mathbb{R}^{D\times D}S=XXT∈RD×D(注意:课件中直接用XXTXX^TXXT,未除以N或N-1)
对SSS进行特征值分解:S=WΛWTS=W\Lambda W^TS=WΛWT
得到特征值λ1≥λ2≥⋯≥λD\lambda_1\ge\lambda_2\ge\dots\ge\lambda_Dλ1≥λ2≥⋯≥λD
对应特征向量w1,w2,...,wDw_1,w_2,\dots,w_Dw1,w2,...,wD(已正交归一化)
取前D′D'D′个最大特征值对应的特征向量,组成投影矩阵:
W=(w1,w2,...,wD′)∈RD×D′W=(w_1,w_2,\dots,w_{D'})\in\mathbb{R}^{D\times D'}W=(w1,w2,...,wD′)∈RD×D′
方式2:直接用 SVD(数值更稳定)
同上:中心化XXX(均值xˉ\bar{x}xˉ保存,用于测试)
对中心化后的XXX做奇异值分解:X=UΣVTX=U\Sigma V^TX=UΣVT
U∈RD×DU\in\mathbb{R}^{D\times D}U∈RD×D(左奇异向量矩阵)
Σ∈RD×N\Sigma\in\mathbb{R}^{D\times N}Σ∈RD×N(奇异值对角矩阵)
V∈RN×NV\in\mathbb{R}^{N\times N}V∈RN×N
取UUU的前D′D'D′列:W=U:,1:D′W=U:,1:D'W=U:,1:D′(即u1,u2,...,uD′u_1,u_2,\dots,u_{D'}u1,u2,...,uD′)
测试/投影新样本 x(两种方式通用):
中心化:x′=x−xˉx'=x-\bar{x}x′=x−xˉ
得到低维表示:z=WTx′∈RD′z=W^Tx'\in\mathbb{R}^{D'}z=WTx′∈RD′
(可选)重构:x^=Wz+xˉ=WWT(x−xˉ)+xˉ\hat{x}=Wz+\bar{x}=WW^T(x-\bar{x})+\bar{x}x^=Wz+xˉ=WWT(x−xˉ)+xˉ
选择D′D'D′的方法:
方差保留比例(最常用):
∑d=1D′λd∑d=1Dλd≥t\frac{\sum_{d=1}^{D'}\lambda_d}{\sum_{d=1}^D\lambda_d}\ge t∑d=1Dλd∑d=1D′λd≥t(t=0.85~0.95)
交叉验证:用低维 z 做下游任务(如 KNN 分类),选效果最好的D′D'D′
可视化:看特征值衰减曲线(课件 MNIST 图),拐点后可截断
【直观理解】
PCA 就是在"找数据最拉伸的方向"(最大方差),把所有点投影到这些方向上。过程非常机械:中心化 → 算协方差/SVD → 取前k个方向 → 投影。
PCA-(协方差矩阵 + 特征分解) 例题详解(2D → 1D)
原始数据(3个样本,2维,未中心化):
样本1:(3,4)(3,4)(3,4)
样本2:(1,2)(1,2)(1,2)
样本3:(2,0)(2,0)(2,0)
第一步:计算均值并进行"去中心化"
PCA 处理的第一步必须是将坐标原点移动到数据的中心(均值点)。
计算均值 μ\muμ:
xxx 轴均值:μx=3+1+23=63=2\mu_x = \frac{3+1+2}{3} = \frac{6}{3} = 2μx=33+1+2=36=2
yyy 轴均值:μy=4+2+03=63=2\mu_y = \frac{4+2+0}{3} = \frac{6}{3} = 2μy=34+2+0=36=2
均值向量 μ=(2,2)\mu = (2, 2)μ=(2,2)
样本去中心化(每个样本减去均值):
新样本1:(3−2,4−2)=(1,2)(3-2, 4-2) = (1, 2)(3−2,4−2)=(1,2)
新样本2:(1−2,2−2)=(−1,0)(1-2, 2-2) = (-1, 0)(1−2,2−2)=(−1,0)
新样本3:(2−2,0−2)=(0,−2)(2-2, 0-2) = (0, -2)(2−2,0−2)=(0,−2)
现在我们的去中心化矩阵 XXX(按列排列样本)为:X=1−1020−2X = \begin{bmatrix} 1 & -1 & 0 \\ 2 & 0 & -2 \end{bmatrix}X=12−100−2
第二步:计算协方差矩阵
Σ\SigmaΣ协方差矩阵公式为 Σ=1NXXT\Sigma = \frac{1}{N} XX^TΣ=N1XXT(
有时分母用 N−1N-1N−1,这里我们按常规 PCA 教学中的 NNN 来计算):
计算 XXTXX^TXXT:XXT=1−1020−212−100−2XX^T = \begin{bmatrix} 1 & -1 & 0 \\ 2 & 0 & -2 \end{bmatrix} \begin{bmatrix} 1 & 2 \\ -1 & 0 \\ 0 & -2 \end{bmatrix}XXT=12−100−2 1−1020−2
XXT=2228XX^T = \begin{bmatrix} 2 & 2 \\ 2 & 8 \end{bmatrix}XXT=2228
求协方差矩阵 Σ\SigmaΣ:Σ=132228=2/32/32/38/3\Sigma = \frac{1}{3} \begin{bmatrix} 2 & 2 \\ 2 & 8 \end{bmatrix} = \begin{bmatrix} 2/3 & 2/3 \\ 2/3 & 8/3 \end{bmatrix}Σ=312228=2/32/32/38/3
(注:为了计算方便,我们直接对 XXTXX^TXXT 进行特征分解,特征向量是一样的,只是特征值差了 1/N1/N1/N 倍)
第三步:特征分解(求解特征值和特征向量)
我们直接解刚才那个矩阵 A=2228A = \begin{bmatrix} 2 & 2 \\ 2 & 8 \end{bmatrix}A=2228:
解特征方程 ∣A−λI∣=0|A - \lambda I| = 0∣A−λI∣=0:
方程为 λ2−10λ+12=0\lambda^2 - 10\lambda + 12 = 0λ2−10λ+12=0。
解得:λ1=5+13≈8.61\lambda_1 = 5 + \sqrt{13} \approx 8.61λ1=5+13 ≈8.61(最大特征值)λ2=5−13≈1.39\lambda_2 = 5 - \sqrt{13} \approx 1.39λ2=5−13 ≈1.39求最大特征值对应的特征向量 v1v_1v1:
代入 λ1=5+13\lambda_1 = 5 + \sqrt{13}λ1=5+13 到 (A−λI)v=0(A-\lambda I)v=0(A−λI)v=0:
2−(5+13)228−(5+13)\]\[xy\]=\[00\] ⟹ \[−3−13223−13\]\[xy\]=\[00\]\\begin{bmatrix} 2-(5+\\sqrt{13}) \& 2 \\\\ 2 \& 8-(5+\\sqrt{13}) \\end{bmatrix} \\begin{bmatrix} x \\\\ y \\end{bmatrix} = \\begin{bmatrix} 0 \\\\ 0 \\end{bmatrix} \\implies \\begin{bmatrix} -3-\\sqrt{13} \& 2 \\\\ 2 \& 3-\\sqrt{13} \\end{bmatrix} \\begin{bmatrix} x \\\\ y \\end{bmatrix} = \\begin{bmatrix} 0 \\\\ 0 \\end{bmatrix}\[2−(5+13 )228−(5+13 )\]\[xy\]=\[00\]⟹\[−3−13 223−13 \]\[xy\]=\[00
取 2x+(3−13)y=02x + (3-\sqrt{13})y = 02x+(3−13 )y=0,得 v1≈0.29,0.96Tv_1 \approx 0.29, 0.96^Tv1≈0.29,0.96T(已单位化)。这个向量就是主成分方向。
第四步:降维投影(2D → 1D)
目标是将 2 维的去中心化数据投影到 v1v_1v1 方向上,得到 1 维坐标 zzz。
公式为:zi=v1T⋅xcentered_iz_i = v_1^T \cdot x_{centered\_i}zi=v1T⋅xcentered_i
样本1:0.29,0.96⋅12=0.29+1.92=2.210.29, 0.96 \cdot \begin{bmatrix} 1 \\ 2 \end{bmatrix} = 0.29 + 1.92 = \mathbf{2.21}0.29,0.96⋅12=0.29+1.92=2.21
样本2:0.29,0.96⋅−10=−0.290.29, 0.96 \cdot \begin{bmatrix} -1 \\ 0 \end{bmatrix} = \mathbf{-0.29}0.29,0.96⋅−10=−0.29
样本3:0.29,0.96⋅0−2=−1.920.29, 0.96 \cdot \begin{bmatrix} 0 \\ -2 \end{bmatrix} = \mathbf{-1.92}0.29,0.96⋅0−2=−1.92
总结
原始数据:(3,4),(1,2),(2,0)(3,4), (1,2), (2,0)(3,4),(1,2),(2,0)
1维表示(压缩后坐标):2.21,−0.29,−1.922.21, -0.29, -1.922.21,−0.29,−1.92
这三个数字就是降维后的结果。它们保留了原始数据中最大的方差(即样本之间的差异性)。
对比:MDS 是通过距离矩阵来恢复坐标,不需要知道原始坐标。PCA 是通过协方差矩阵来找投影方向,需要原始特征空间。
如果是svd方式计算,就是直接对 XXX 进行分解:X=UΣVTX = U\Sigma V^TX=UΣVT。
9.4 非线性降维:核PCA(Kernelized PCA)
这里到本章后面更侧重概念理解,上面两个小节会侧重计算过程(因为后面的方法在考试里面很难出计算题)。
为什么用核PCA?(核心动机)
线性PCA在数据呈非线性结构时失效
现实数据常有非线性(如人脸光照变化、基因表达曲线),需要先非线性映射到高维再线性降维,等价于原空间非线性降维。
核PCA就是"聪明实现":用核函数隐式升维,不需显式计算高维坐标。
性质与优缺点
- 性质:升维与降维统一、非线性与线性统一。核选择决定效果(高斯核最常用,捕捉局部非线性;多项式核捕全局)。
- 优点:处理非线性信号好,无迭代、无局部最小。
- 缺点:需调核参数,N大时内存/时间爆炸(O(N³)),对新样本投影需算所有训练点核(无显式W)。
- 适用场景:小样本非线性数据(如图像特征提取早期用)。
【直观理解】
普通PCA像用直尺量弯路,核PCA像先把弯纸"卷成筒"(高维展开成线性),再用直尺量------纸还是那张纸,但弯曲被"拉平"了。核函数是"魔术手",不用真卷纸,只算"相似度"就行。
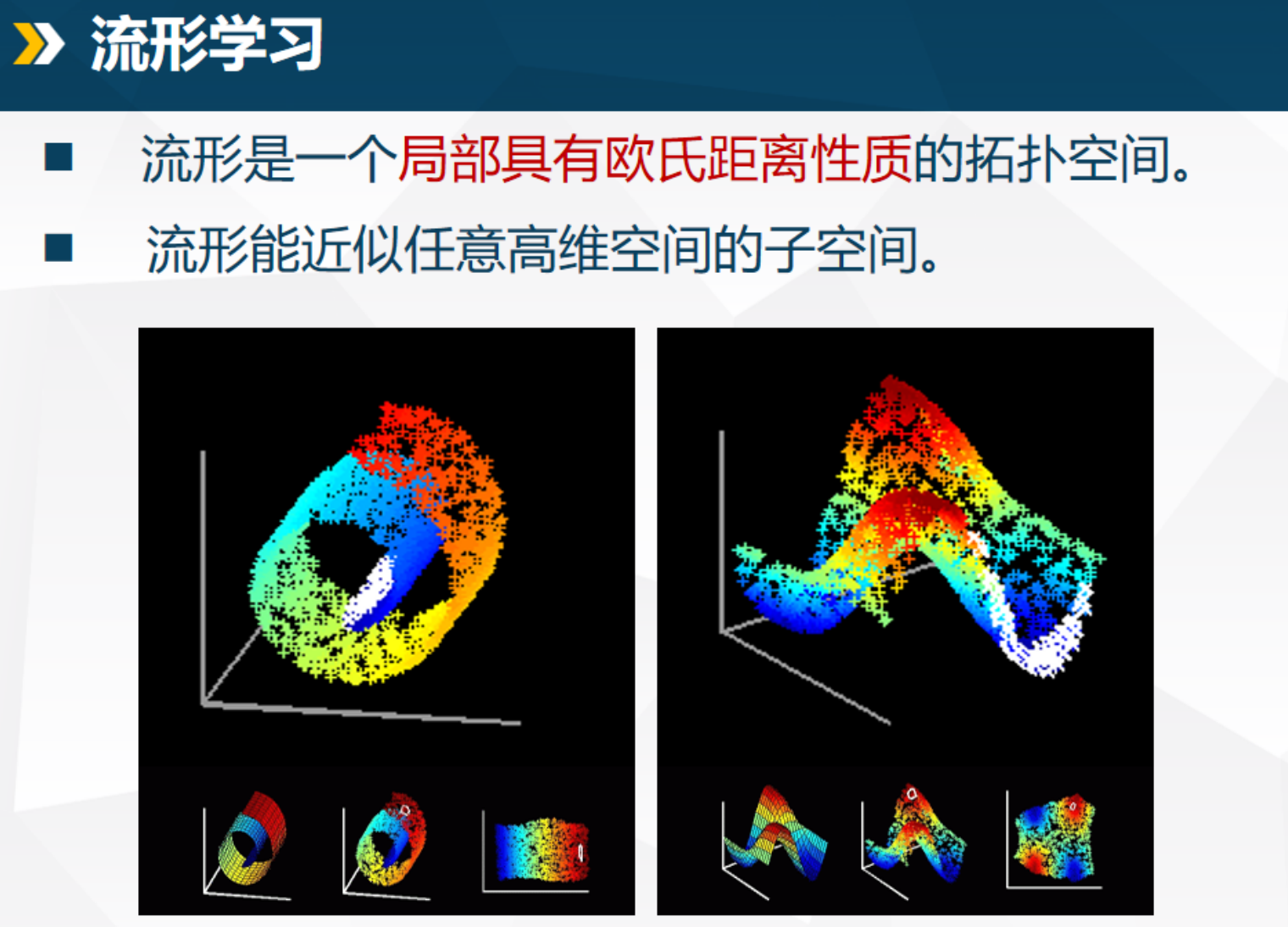
9.5 流形学习
为什么用流形学习?(核心假设与动机)
高维数据常躺在低维"流形"上(局部像欧氏空间的弯曲表面,如下图左边的瑞士卷)。
欧氏距离在高维失效(3D嵌入2D数据,欧氏距不准)。
流形学习假设数据均匀分布在低维流形上,想恢复内在几何结构 (测地距离:沿曲面最短路径)。

测地距离性质:
- 近点:用欧氏距近似。
- 远点:通过邻域点链累加(像图最短路径)。
各种流形方法区别
(这里不再一个一个介绍,后面章末总结那里加上了前面的pca,mds一起对比,更详细的可自行查阅学习)
整体性质
- 全局方法(ISOMAP):适合展开型流形(如卷曲平面),保留远距。
- 局部方法(LLE、Laplacian):适合复杂局部结构,但全局可能扭曲。
- t-SNE:最实用可视化工具,局部簇清晰,但距离/尺度无意义(别用下游任务)。
- 共同缺点:大多对新样本扩展难(非参数),噪声/采样密度敏感。
- 扩展:UMAP(页78~84,未在旧课件但推荐):更快、保留全局更好、可参数化、对新样本友好,当代替代t-SNE首选。
【直观理解】
流形像"皱巴巴的纸":高维观察皱巴巴,低维想展开平。ISOMAP像"拉直所有皱";LLE像"局部小块平整";t-SNE像"用力把簇分开,避免挤一起"(拥挤问题)。现实:MNIST手写数字、脸部表情常在低维流形上。
章末总结
本章所有降维方法大对比
| 类型 | 方法 | 保持什么 | 线性/非线性 | 全局/局部 | 典型考点 |
|---|---|---|---|---|---|
| 线性 | MDS | 距离 | 线性 | 全局 | 输入距离矩阵,无需坐标 补充:可通过平移/旋转/镜像得到多个等价解;经典算法基于双中心化 + 特征分解;常与ISOMAP对比 |
| 线性 | PCA | 方差/重构 | 线性 | 全局 | 最常用,二阶统计 补充:需中心化数据;最大方差方向 = 最小重构误差方向;特征值大小反映保留方差比例;SVD实现更稳定 |
| 非线性 | 核PCA | 高维方差 | 非线性 | 全局 | 核技巧,升维后线性 补充:不显式计算高维映射;需选择核函数及参数(如高斯核的σ);对新样本投影需计算所有训练样本的核;计算复杂度O(N³) |
| 流形 | ISOMAP | 全局测地距 | 非线性 | 全局 | 最短路径 + MDS 补充:用k-NN或ε球构建邻接图;测地距离 ≈ 图上最短路径;对噪声和采样密度不均敏感;典型应用:瑞士卷展开 |
| 流形 | LLE | 局部重构 | 非线性 | 局部 | 邻点线性表示 补充:每个点由最近邻线性重构;求解稀疏重构权重 → 低维嵌入保持权重;对局部空洞(holes)敏感;无参数迭代 |
| 流形 | t-SNE | 局部相似 | 非线性 | 局部优先 | 可视化,拥挤问题,随机性 补充:高维用高斯分布,低维用t分布解决拥挤问题;结果受随机初始化影响大;不适合除可视化外的下游任务;不保留全局距离 |
第十章 半监督学习
这一章虽然理论较多,但其核心思想非常直观------即"如何利用大量廉价的未标注数据来辅助少量昂贵的标注数据"。
10.1 引言与基本概念
- 为什么要用半监督学习?
在现实世界中,获取有标注数据 (Labeled Data) 往往非常昂贵且稀缺(需要专家人工标注),而无标注数据 (Unlabeled Data) 却极其丰富且廉价 。
全监督学习的成本极高。
半监督学习的目标:给定少量标注数据 DL\mathcal{D}_LDL 和大量无标注数据 DU\mathcal{D}_UDU(通常 U≫LU \gg LU≫L),我们希望结合两者,训练出一个比"仅用标注数据"更好的模型 。

10.2 三大核心假设和归纳式的概念
如果无标注数据和有标注数据之间没有任何联系,那么半监督学习是不可能成功的 。算法之所以有效,是因为数据分布满足以下某种假设。
-
平滑性假设 (Smoothness Assumption)
定义:如果高密度区域中的两个点 x1,x2x_1, x_2x1,x2 距离很近,那么它们的输出(标签)y1,y2y_1, y_2y1,y2 也应该很近 。
推论:如果两个点之间有一条高密度路径相连,那么它们很有可能属于同一类 。
通俗解释:"近朱者赤,近墨者黑" (Near by ink is black) 。
-
聚类假设 (Cluster Assumption)
定义 :如果两个点在同一个簇(Cluster)中,那么它们很有可能属于同一个类别 。
等价形式 :低密度分割。即决策边界应该尽量通过数据分布稀疏(低密度)的区域,而不应该切断高密度的簇 。关系:这是平滑性假设的一个特例 。
直观理解 :想象你在切蛋糕(找分类边界)。平滑性:蛋糕上的奶油是连在一起的,你不会觉得这块奶油的一半是甜的,另一半是咸的。低密度分割:切蛋糕时,你会顺着蛋糕之间的缝隙切(低密度区),而不会硬生生把一个完整的草莓(高密度簇)切成两半。
-
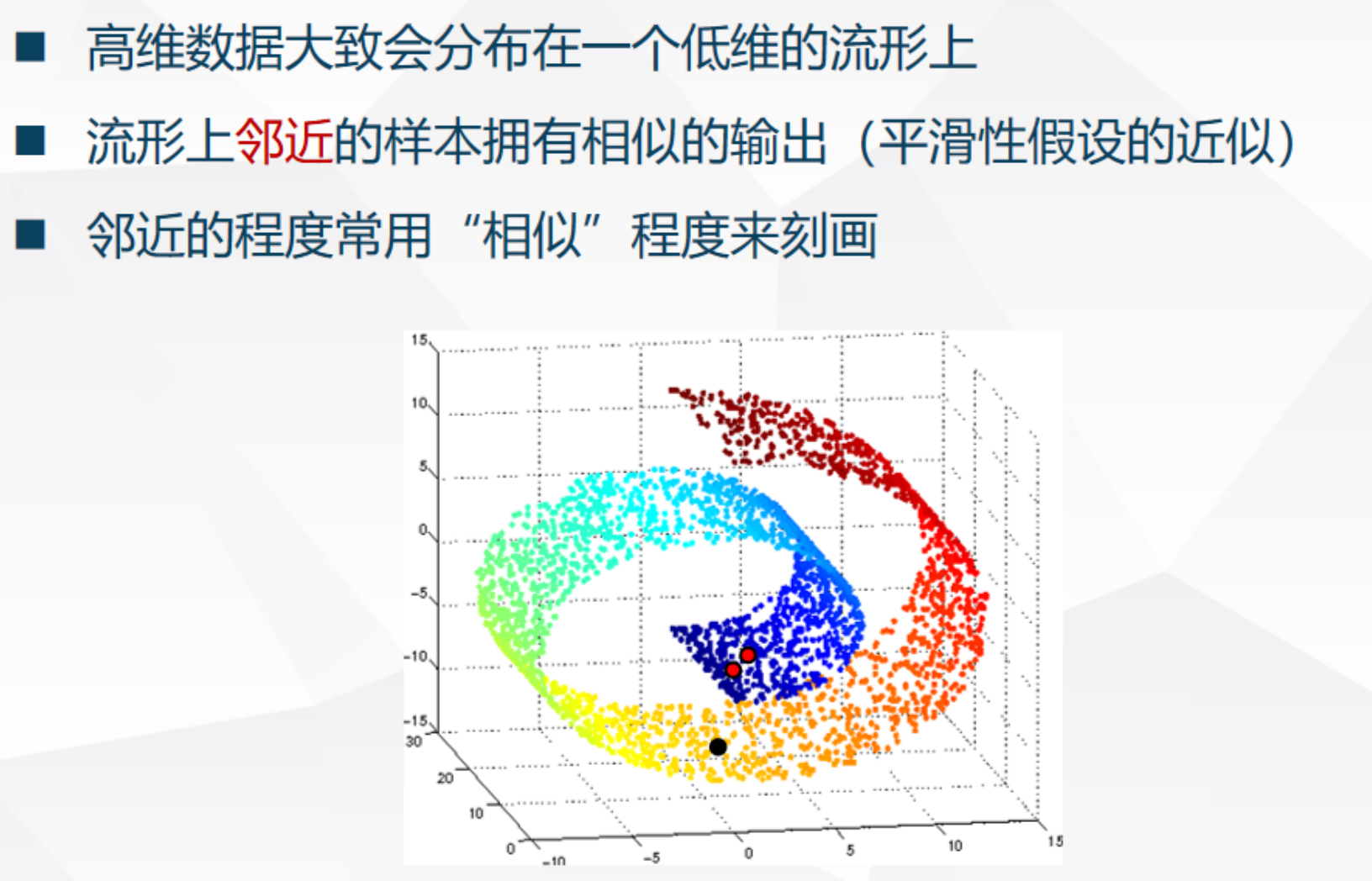
流形假设 (Manifold Assumption)
定义 :高维数据(如图像、文本)通常分布在一个低维的流形结构上 。
应用 :在流形上邻近的样本(而不是原始欧氏空间邻近)拥有相似的输出 。这通常用于基于图的算法中,通过图结构来近似流形。
直观理解 :想象一个瑞士卷 (Swiss Roll) 蛋糕。在三维空间看,蛋糕卷的一层和下一层可能挨得很近(欧氏距离小),但它们其实属于不同的层(类别不同)。流形假设就是要把这个卷展开成二维的平面,只有在展开后的平面上挨得近的点,才是真正的相似。

归纳式的这一类方法就像是一个"循环增强器"。
输入:一个现成的监督学习算法(如逻辑回归、SVM、KNN) + 少量标注数据 + 大量无标注数据。
输出:一个在增强数据集上训练好的更强的分类器。
10.3 自我训练
自我训练和下一节的多视角学习都是Wrapper Methods(包装式方法),即在现有的监督学习算法外层"套"一个半监督的循环。
(这一章多个算法之间的区分和对比放在最后总结那里,如果不涉及计算题目的话,这里面几个方法只说一下概念)
算法流程自我训练是最简单的半监督学习方法,其核心逻辑是**"滚雪球"** 。
- 初始阶段:仅使用少量的有标注数据 DL\mathcal{D}_LDL 训练一个初始模型 fff 。
- 循环标注:利用模型 fff 对大量的无标注数据 DU\mathcal{D}_UDU 进行预测,计算每个样本的置信度 。
- 扩充集合:挑选出模型"最笃定"(置信度最高)的一批样本,给它们打上伪标签 (Pseudo-labels),并把它们从 DU\mathcal{D}_UDU 挪到 DL\mathcal{D}_LDL 中 。
- 模型进化:使用更新后的有标注集合重新训练模型 fff,如此往复,直到 DU\mathcal{D}_UDU 为空或满足停止条件。
【直观理解】 自我训练就像是一个 "闭门造车"的学生 。他先自学了一点基础(初始模型),然后开始做大量的练习题(无标注数据)。他觉得自己最有把握的那些题,就直接当成标准答案(伪标签)背下来,并以此为基础继续往下学。
10.4 协同训练与多视角学习
核心思想:多视角互补
协同训练的前提是数据具有多视角 (Multi-view) 特征 。
例子:描述一个网页,视角1可以是"网页上的文字",视角2可以是"指向该网页的链接文本"。这两个视角虽然来源不同,但描述的是同一个东西 。
逻辑:如果两个视角都是"充分"的(单独一个视角就能分类),且"相互独立"(给定类别时,两个视角的特征不相关),那么我们就可以让两个模型互相教对方。
算法步骤:
- 基于视角1的特征训练模型 f1f_1f1,基于视角2训练 f2f_2f2。
- 让 f1f_1f1 在无标注数据中找它最自信的样本,标注后送给 f2f_2f2 作为训练集。
- 同时,让 f2f_2f2 找它最自信的样本,标注后送给 f1f_1f1 训练。
- 两个模型交叉授课,直到达到平衡。
【直观理解】 协同训练就像是 "两个互补的学生"在一起复习。学生A擅长文科,学生B擅长理科。遇到一张综合试卷(无标注数据),学生A先把文科题做了并教给B,学生B把理科题做了并教给A。通过这种"我教你,你教我" 的方式,两个人的综合水平都提高了。
10.5 生成式模型
生成式模型假设所有数据(无论有标还是无标)都是由同一个潜在的概率混合模型生成的。半监督学习的任务就是通过观测到的样本,利用 EM 算法 把这个模型的参数"抠"出来。
数学表达与推导:
假设数据由 KKK 个混合成分(组件)组成,每个成分对应一个类别。
其概率密度函数为:p(x∣Θ)=∑j=1Kαj⋅p(x∣θj)p(x|\Theta) = \sum_{j=1}^{K} \alpha_j \cdot p(x|\theta_j)p(x∣Θ)=j=1∑Kαj⋅p(x∣θj)αj\alpha_jαj:第 jjj 个混合成分的权重(即该类发生的先验概率),满足 ∑αj=1\sum \alpha_j = 1∑αj=1。
θj\theta_jθj:第 jjj 个成分的参数(如高斯分布的均值 μ\muμ 和方差 Σ\SigmaΣ)。
Θ\ThetaΘ:模型的所有参数集合。
推导动机: 对于有标注数据 (xi,yi)(x_i, y_i)(xi,yi),我们知道它属于哪个成分;
但对于无标注数据 xjx_jxj,我们不知道它属于谁。因此,我们需要最大化混合似然函数:L(Θ)=∑(x,y)∈DLln(αyp(x∣θy))+∑x∈DUln(∑j=1Kαjp(x∣θj))L(\Theta) = \sum_{(x,y) \in \mathcal{D}L} \ln(\alpha_y p(x|\theta_y)) + \sum{x \in \mathcal{D}U} \ln \left( \sum{j=1}^K \alpha_j p(x|\theta_j) \right)L(Θ)=(x,y)∈DL∑ln(αyp(x∣θy))+x∈DU∑ln(j=1∑Kαjp(x∣θj))左半部分:有监督部分,标签已知,直接计算。
右半部分:无监督部分,标签是隐变量,需要对所有可能的 KKK 个类求和。
上面两个公式是推导,实际运算的时候还会有个EM算法,下面会结合例题来理解EM算法在半监督学习下的使用。
在全监督学习中,我们直接统计频率;在纯无监督(聚类)中,我们只看 QijQ_{ij}Qij。
半监督的特殊点在于: 更新模型参数时,要把"确定性信息"(有标数据)和"概率性信息"(无标数据)加权合并。
EM 算法是两步循环,公式逻辑如下:
(前面的聚类那一节里面提到过em算法,直接使用即可)
E-步 :算"归属感" (Expectation)计算无标注样本 xix_ixi 属于第 jjj 类的概率(即响应度):Qij=αj⋅p(xi∣θj)∑k=1Kαk⋅p(xi∣θk)Q_{ij} = \frac{\alpha_j \cdot p(x_i | \theta_j)}{\sum_{k=1}^K \alpha_k \cdot p(x_i | \theta_k)}Qij=∑k=1Kαk⋅p(xi∣θk)αj⋅p(xi∣θj)
注意:这其实就是贝叶斯公式。分子是"我想去的那个类的概率",分母是"所有可能去的类的总概率"。αj\alpha_jαj 表示在还没看到具体的特征 xxx 之前,样本属于第 jjj 类的天然概率。手算题中,为了简化计算过程,老师通常会假设每一类出现的概率是均等的。
M-步 :算"新参数" (Maximization)以更新均值 μj\mu_jμj 为例,这是最常考的计算:
μj=∑x∈DL,y=jx+∑x∈DUQij⋅xNj+∑x∈DUQij\mu_j = \frac{\sum_{x \in \mathcal{D}L, y=j} x + \sum{x \in \mathcal{D}U} Q{ij} \cdot x}{N_j + \sum_{x \in \mathcal{D}U} Q{ij}}μj=Nj+∑x∈DUQij∑x∈DL,y=jx+∑x∈DUQij⋅x
变量解释:
分子左边:有标数据里,属于 jjj 类的样本直接相加。
分子右边:无标数据里,所有样本乘以它们属于 jjj 类的概率。
分母:这一类"名义上"的总人数(整数个有标样本 + 概率化后的无标样本)。
把它想象成 "班级合并" 。有标数据是"正式生",1个人就计1票;无标数据是"旁听生",他们只有 QijQ_{ij}Qij 的票权(比如 0.5 票)。更新班级平均分(均值)时,把所有人的"票权 ×\times× 分数"加起来,除以"总票数"即可。
权重 αj\alpha_jαj 的更新:别忘了混合比例 αj\alpha_jαj 也要更新。αj=该类总票数总样本量 (L+U)\alpha_j = \frac{\text{该类总票数}}{\text{总样本量 } (L+U)}αj=总样本量 (L+U)该类总票数初值问题:计算题通常会给你一个初始的 μ\muμ 和 σ\sigmaσ,第一步永远是先做 E-步。
典型例题
题目:已知两类 A 和 B。
有标:x1=1x_1=1x1=1 (A类)。无标:x2=3x_2=3x2=3。
已知:当前参数 μA=1,μB=5\mu_A=1, \mu_B=5μA=1,μB=5,且 A、B 两类先验概率 α\alphaα 相等,方差相等。
求:经过一轮 EM 后,新的 μA\mu_AμA 是多少?
第一步 (E-步):看无标点 x2=3x_2=3x2=3。
它到 μA=1\mu_A=1μA=1 距离是 2,到 μB=5\mu_B=5μB=5 距离也是 2。
所以它属于 A 和 B 的概率平分:Q2A=0.5,Q2B=0.5Q_{2A} = 0.5, Q_{2B} = 0.5Q2A=0.5,Q2B=0.5。
展开说一下这个计算
根据贝叶斯准则,无标注样本 xix_ixi 属于 AAA 类的概率 QiAQ_{iA}QiA 为:QiA=αA⋅12πσAexp(−(xi−μA)22σA2)αA⋅12πσAexp(−(xi−μA)22σA2)+αB⋅12πσBexp(−(xi−μB)22σB2)Q_{iA} = \frac{\alpha_A \cdot \frac{1}{\sqrt{2\pi}\sigma_A} \exp\left( -\frac{(x_i - \mu_A)^2}{2\sigma_A^2} \right)}{\alpha_A \cdot \frac{1}{\sqrt{2\pi}\sigma_A} \exp\left( -\frac{(x_i - \mu_A)^2}{2\sigma_A^2} \right) + \alpha_B \cdot \frac{1}{\sqrt{2\pi}\sigma_B} \exp\left( -\frac{(x_i - \mu_B)^2}{2\sigma_B^2} \right)}QiA=αA⋅2π σA1exp(−2σA2(xi−μA)2)+αB⋅2π σB1exp(−2σB2(xi−μB)2)αA⋅2π σA1exp(−2σA2(xi−μA)2)
在手工计算题中,老师为了不考查开方计算能力,通常会设定 αA=αB\alpha_A = \alpha_BαA=αB 且 σA=σB=σ\sigma_A = \sigma_B = \sigmaσA=σB=σ。此时,分子分母中所有的系数 α,2π,σ\alpha, \sqrt{2\pi}, \sigmaα,2π ,σ 全部约掉。公式简化为:QiA=exp(−(xi−μA)22σ2)exp(−(xi−μA)22σ2)+exp(−(xi−μB)22σ2)Q_{iA} = \frac{\exp\left( -\frac{(x_i - \mu_A)^2}{2\sigma^2} \right)}{\exp\left( -\frac{(x_i - \mu_A)^2}{2\sigma^2} \right) + \exp\left( -\frac{(x_i - \mu_B)^2}{2\sigma^2} \right)}QiA=exp(−2σ2(xi−μA)2)+exp(−2σ2(xi−μB)2)exp(−2σ2(xi−μA)2)
条件:x2=3,μA=1,μB=5x_2 = 3, \mu_A = 1, \mu_B = 5x2=3,μA=1,μB=5,假设 σ2=1\sigma^2 = 1σ2=1(为了方便计算)。步骤1:计算指数项样本到 A 的距离平方:(3−1)2=4(3-1)^2 = 4(3−1)2=4样本到 B 的距离平方:(3−5)2=4(3-5)^2 = 4(3−5)2=4步骤2:代入简化公式Q2A=e−4/2e−4/2+e−4/2=e−2e−2+e−2=11+1=0.5Q_{2A} = \frac{e^{-4/2}}{e^{-4/2} + e^{-4/2}} = \frac{e^{-2}}{e^{-2} + e^{-2}} = \frac{1}{1+1} = 0.5Q2A=e−4/2+e−4/2e−4/2=e−2+e−2e−2=1+11=0.5
这个公式本质上是在比拼 "距离的指数" 。如果一个点到两个中心的距离相等,那么它们的 e−diste^{-\text{dist}}e−dist 项就完全一样,分出来就是 0.50.50.5 vs 0.50.50.5。如果它离 A 近,离 B 远,那么分母中 A 的那一项就会比 B 大得多,导致 Q2AQ_{2A}Q2A 趋近于 111。
第二步 (M-步):更新 μA\mu_AμA。
分子(A类的总分):1×x1(正式生)+0.5×x2(旁听生)=1×1+0.5×3=2.51 \times x_1 (\text{正式生}) + 0.5 \times x_2 (\text{旁听生}) = 1\times1 + 0.5\times3 = 2.51×x1(正式生)+0.5×x2(旁听生)=1×1+0.5×3=2.5。
分母(A类的总票数):1(正式生)+0.5(旁听生)=1.51 (\text{正式生}) + 0.5 (\text{旁听生}) = 1.51(正式生)+0.5(旁听生)=1.5。
结果:μAnew=2.5/1.5=1.67\mu_A^{new} = 2.5 / 1.5 = 1.67μAnew=2.5/1.5=1.67。
再来一个例题
场景:一维空间下,已知两个高斯分布(A类和B类),方差均为1。
标注数据:x1=1x_1=1x1=1 (A类),x2=5x_2=5x2=5 (B类)。
无标数据:x3=3x_3=3x3=3。
当前均值:μA=1.5,μB=4.5\mu_A=1.5, \mu_B=4.5μA=1.5,μB=4.5。
解题步骤:步骤1 (E-步):
计算 x3x_3x3 的归属感。
计算 x3x_3x3 到 μA\mu_AμA 和 μB\mu_BμB 的距离。
由于 x3=3x_3=3x3=3 位于中间,假设算出 Q3A=0.5,Q3B=0.5Q_{3A}=0.5, Q_{3B}=0.5Q3A=0.5,Q3B=0.5(即它一半属于A,一半属于B)。
步骤2 (M-步):
更新 μA\mu_AμA。μAnew=x1(纯A)+x3⋅Q3A1+0.5=1+3⋅0.51.5≈1.67\mu_A^{new} = \frac{x_1(\text{纯A}) + x_3 \cdot Q_{3A}}{1 + 0.5} = \frac{1 + 3 \cdot 0.5}{1.5} \approx 1.67μAnew=1+0.5x1(纯A)+x3⋅Q3A=1.51+3⋅0.5≈1.67
结论:你可以看到,无标注样本 x3x_3x3 把 A 类的中心点从 1.5 "拉"向了 1.67。随着迭代,模型会找到最符合整体数据分布的中心。
10.6 半监督支持向量机S3VMs
核心思想: 低密度分割 (Low-density Separation)
理论出发点:
S3VMs 的全称是 Semi-Supervised Support Vector Machines。它最著名的实现是 TSVM (Transductive SVM)。 其核心假设是聚类假设:它认为分类边界(超平面)不应该穿过数据密集的区域,而应该通过数据稀疏的"缝隙"。
S3VM 的目标是尝试为每一个无标注样本 xj∈DUx_j \in \mathcal{D}_Uxj∈DU 寻找一个伪标签 y^j∈{−1,+1}\hat{y}_j \in \{-1, +1\}y^j∈{−1,+1},使得在所有样本上建立的 SVM 间隔最大化。
优化目标公式minw,b,y^12∥w∥2+CL∑i=1Lξi+CU∑j=L+1L+Uξj\min_{w, b, \hat{y}} \frac{1}{2}\|w\|^2 + C_L \sum_{i=1}^L \xi_i + C_U \sum_{j=L+1}^{L+U} \xi_jw,b,y^min21∥w∥2+CLi=1∑Lξi+CUj=L+1∑L+Uξj12∥w∥2\frac{1}{2}\|w\|^221∥w∥2:正则项,决定了超平面的间隔大小(值越小,间隔越大)。
CL∑ξiC_L \sum \xi_iCL∑ξi:标注数据的惩罚项。CLC_LCL 是对错分有标数据的惩罚权重。
CU∑ξjC_U \sum \xi_jCU∑ξj:无标注数据的惩罚项。CUC_UCU 是对错分无标数据的惩罚权重。
ξ\xiξ:松弛变量,允许部分样本不满足间隔约束。
在普通 SVM 中,标签 yyy 是常数;但在 S3VM 中,y^\hat{y}y^ 是变量。这意味着我们需要同时确定 "哪种打标方式最好"以及"在这种打标方式下间隔最大" 。
注意:由于 y^\hat{y}y^ 只能取 +1+1+1 或 −1-1−1,这变成了一个巨大的整数规划问题。在无标注数据量很大时,遍历所有标签组合是指数级的(2U2^U2U),这是无法直接求解的(NP-Hard)。
计算复杂度:S3VM 的主要缺点是计算开销大,因为涉及大量的标签尝试和交换。
局部最优:由于是启发式搜索,它可能会陷入局部最优解,而不是全局最好的分类边界
10.7 基于图的半监督学习核心思想:标签传播
核心思想:
基于图的方法将数据点看作图的节点,将点与点之间的相似度看作边的权重。
逻辑 :
如果两个点在图上的距离很近(或者有很多路径相连),那么它们的标签应该趋于一致。
流形假设的体现: 标签就像一种"颜色"或者"流感",从有标注的节点开始,沿着边向邻近的无标注节点扩散,直到全图达到某种平衡。
算法流程 (以标签传播 LP 为例)建图:
- 计算所有样本(有标+无标)两两之间的相似度 wijw_{ij}wij(常用高斯核函数 wij=exp(−∥xi−xj∥22σ2)w_{ij} = \exp(-\frac{\|x_i-x_j\|^2}{2\sigma^2})wij=exp(−2σ2∥xi−xj∥2))。
- 构建转移矩阵:对权重矩阵进行归一化,得到 P=D−1WP = D^{-1}WP=D−1W,其中 DDD 是度矩阵(对角线上是每行权重之和)。
- 迭代传播:传播步骤:F(t+1)=P⋅F(t)F^{(t+1)} = P \cdot F^{(t)}F(t+1)=P⋅F(t)。让每个节点根据邻居的标签来更新自己的标签。
- 重置步骤(重点):传播完后,必须把有标注节点的标签强行重置回原始真实标签。收敛:重复步骤3直到标签不再发生显著变化。
【直观理解】 想象你在一个社交网络里(图)。 只有几个人明确标注了自己是"摄影爱好者"(有标数据)。 标签传播的过程就像是:每天你都会受朋友的影响。如果你的朋友里大部分都是摄影爱好者,你也会慢慢变得倾向于这个标签。 重置步骤的意思是:那些"死忠粉"(原始有标点)永远不会被别人洗脑,他们始终坚持自己的标签,并不断向周围输出影响力。
**图拉普拉斯矩阵 **
用于衡量函数在图上的"平滑程度"。(fTLff^T L ffTLf 越小越平滑)。
定义:L=D−WL = D - WL=D−W。
权重矩阵 WWW:wijw_{ij}wij 表示点 iii 和点 jjj 的相似度。如果两个点很像,wijw_{ij}wij 就很大。
度矩阵 DDD:这是一个对角矩阵,对角线上的元素 dii=∑jwijd_{ii} = \sum_{j} w_{ij}dii=∑jwij。它代表了节点 iii 的"总影响力"或"总连接强度"。( 常用高斯核函数 wij=exp(−∥xi−xj∥22σ2)w_{ij} = \exp(-\frac{\|x_i-x_j\|^2}{2\sigma^2})wij=exp(−2σ2∥xi−xj∥2))
拉普拉斯矩阵 LLL:定义为 L=D−WL = D - WL=D−W。
正则项:在优化目标中,我们希望最小化 fTLff^T L ffTLf。这个式子展开后是 12∑wij(fi−fj)2\frac{1}{2} \sum w_{ij} (f_i - f_j)^221∑wij(fi−fj)2。
在优化时,我们经常看到这个项:fTLff^T L ffTLf。把它展开后,你会发现它等于:12∑i,j=1nwij(fi−fj)2\frac{1}{2} \sum_{i,j=1}^{n} w_{ij}(f_i - f_j)^221i,j=1∑nwij(fi−fj)2wijw_{ij}wij:权重(相似度)。(fi−fj)2(f_i - f_j)^2(fi−fj)2:预测标签的差异。
这个公式是一个 "惩罚项" 。
如果两个点 iii 和 jjj 的相似度 wijw_{ij}wij 很大(比如 0.9),但你给它们的预测标签 fif_ifi 和 fjf_jfj 差得很多(比如一个是 1,一个是 0),那么相乘之后的结果就会很大,导致系统"损失"巨大。
结论: 最小化 fTLff^T L ffTLf 就是在强迫"相似的点必须拥有相似的标签"。
物理意义:如果两个点 iii 和 jjj 之间权重 wijw_{ij}wij 很大(离得近),那么它们的预测值 fif_ifi 和 fjf_jfj 的差值就必须很小,否则损失函数就会爆炸。这完美契合了平滑性假设。
例题
场景:有三个点 x1,x2,x3x_1, x_2, x_3x1,x2,x3。x1x_1x1 是"正类" (标签=1);
x3x_3x3 是无标注点。相似度:w13=0.8w_{13} = 0.8w13=0.8(很近),w23=0.1w_{23} = 0.1w23=0.1(很远)。
我们想预测 x3x_3x3 的标签。
解题步骤:
场景重设:
节点 1:有标注,标签为 111(红色)。
节点 2:有标注,标签为 000(蓝色)。
节点 3:无标注,我们要猜它的颜色。
第一步:看邻居关系
题目给出的的权重(相似度)如下:w13=0.8w_{13} = 0.8w13=0.8 (节点 3 和节点 1 非常像)w23=0.1w_{23} = 0.1w23=0.1 (节点 3 和节点 2 不太像)
但是标签不能直接乘 0.80.80.8,因为权重的总和不一定是 111。我们需要算出节点 3 接收到的"影响力总量"。
计算节点 3 的度 d3d_3d3:d3=w31+w32=0.8+0.1=0.9d_3 = w_{31} + w_{32} = 0.8 + 0.1 = 0.9d3=w31+w32=0.8+0.1=0.9这里的 0.90.90.9 代表了节点 3 与外界的总联系强度。
第二步:计算转移概率矩阵
我们要看节点 3 的标签中,百分之多少来自节点 1,百分之多少来自节点 2:
来自 x1x_1x1 的比例:P31=w31d3=0.80.9≈0.889P_{31} = \frac{w_{31}}{d_3} = \frac{0.8}{0.9} \approx 0.889P31=d3w31=0.90.8≈0.889
来自 x2x_2x2 的比例:P32=w32d3=0.10.9≈0.111P_{32} = \frac{w_{32}}{d_3} = \frac{0.1}{0.9} \approx 0.111P32=d3w32=0.90.1≈0.111
第三步:迭代更新 (Iteration)
在这一轮传播中,节点 3 的标签 f3f_3f3 更新为:f3=P31⋅f1+P32⋅f2f_3 = P_{31} \cdot f_1 + P_{32} \cdot f_2f3=P31⋅f1+P32⋅f2f3=0.889×1+0.111×0=0.889f_3 = 0.889 \times 1 + 0.111 \times 0 = 0.889f3=0.889×1+0.111×0=0.889
第四步:在分类任务中,我们通常会设置一个阈值(通常是 0.50.50.5):因为 f3=0.889>0.5f_3 = 0.889 > 0.5f3=0.889>0.5,所以我们将 x3x_3x3 最终判定为 正类 (Label 1)。
10.8 半监督聚类
传统的聚类是盲目的,无监督的,而半监督聚类引入了监督信息(约束)。
两种核心约束
- 必连约束 (Must-link):样本 xix_ixi 和 xjx_jxj 必须属于同一个簇。
- 勿连约束 (Cannot-link):样本 xix_ixi 和 xjx_jxj 绝对不能属于同一个簇。
典型算法:约束 K-Means (COP-KMeans)
它在普通 K-Means 的基础上增加了一个"合规性检查":
在将样本点分配给最近的中心点时,先检查:
这个分配是否违反了必连约束?(比如 A 和 B 必须在一起,但你把 A 分到了 1 号簇,B 分到了 2 号簇)。
是否违反了勿连约束?
如果违反,则寻找次优的中心点,直到满足所有约束。如果找不到,则报错。
10.9 章末总结
| 章节 | 算法类别 | 核心假设 | 学习目标 | 数据效率 | 典型算法 |
|---|---|---|---|---|---|
| 10.3 | 包装式 (Wrapper) | 置信度/互补性 | 扩充有标训练集 | 依赖初始少量标注数据的质量 | 自我训练 (Self-training) |
| 10.4 | 多视角 (Multi-view) | 视角独立性 & 充分性 | 多个模型互相教导 | 高,利用了特征的冗余性 | 协同训练 (Co-training) |
| 10.5 | 生成式 (Generative) | 数据分布假设 (GMM) | 估计分布参数 Θ | 取决于模型与真实分布的拟合度 | EM 算法迭代更新 |
| 10.6 | 低密度分割 (Cluster) | 聚类假设 | 寻找最大间隔边界 | 中,利用无标签数据压缩边界 | S3VMs / TSVM |
| 10.7 | 基于图 (Manifold) | 流形假设 | 标签在图上的平稳分布 | 极高,能发现复杂的几何结构 | 标签传播 (Label Propagation) |
| 10.8 | 半监督聚类 (Constraint) | 监督约束 | 满足约束的簇划分 | 利用先验约束纠正聚类方向 | 约束 K-Means |
如何根据题目选算法?
| 章节 | 算法类别 | 核心想法(最直白版) | 什么时候最合适用它 | 典型算法 | 容易出问题的地方 |
|---|---|---|---|---|---|
| 10.3 | 包装式 (Wrapper) | 用已有模型给无标签数据"自信打标签",加进来再训 | 初始标签很少,但你用的模型本身已经挺靠谱了 | 自我训练 (Self-training) | 一开始标签错得多,后续雪球滚歪 |
| 10.4 | 多视角 (Multi-view) | 数据有两种独立视角(如文本+图片),互相教对方 | 数据天然有多个互补的特征视图(网页、图文、音视频等) | 协同训练 (Co-training) | 特征视图不独立或互补性差,效果反而下降 |
| 10.5 | 生成式 (Generative) | 假设数据服从某种分布(如高斯混合),用分布猜标签 | 数据分布简单、很符合统计模型假设(老派语音/简单图像) | EM算法 + GMM 等 | 现在复杂高维数据,分布假设基本不成立 |
| 10.6 | 低密度分割 | 相信同类点扎堆,类别间有"空旷"地带,画最大间隔 | 维度不高、类别边界清晰、传统SVM效果好的场景 | S3VM / TSVM | 高维、噪声大、类别重叠严重时基本失效 |
| 10.7 | 基于图 (Manifold) | 把数据连成图,标签像病毒一样沿着关系传播 | 数据有明显相似关系/连接(社交网络、图像、推荐系统等) | 标签传播 (Label Propagation) | 数据点之间没啥相似性,图建得稀碎 |
| 10.8 | 半监督聚类 (Constraint) | 普通聚类 + 加人手规则(必须同类/必须不同类) | 有领域知识或业务约束,能写出"must-link / cannot-link" | 约束 K-Means | 没啥可靠的先验约束,相当于普通聚类 |

一:
半监督学习最常用的三种基本假设是:
平滑假设
含义:特征空间中距离相近的样本(尤其在高密度区域),其输出标签也应该相似或相同。
代表算法:标签传播算法(Label Propagation)
→ 通过构建相似度图,让标签沿着图上的"近邻"平滑传播。
聚类假设
含义:数据在特征空间中自然形成若干簇(高密度区域),同一簇内的样本属于同一类别。
代表算法:低密度分割(Low-Density Separation)方法,例如 TSVM(Transductive Support Vector Machine)
→ 决策边界尽量穿过低密度区域,避免切割高密度簇。
流形假设
含义:高维数据实际分布在一个低维流形结构上,沿着流形测量的距离才能真正反映样本相似性。
代表算法:标签传播算法(Label Propagation)或 Laplacian Eigenmaps + 后续分类
→ 很多图-based方法(如Label Propagation、LGC)都强烈依赖流形假设。
二:
简述直推式和归纳式半监督学习算法的异同,并分别列举出3种代表性算法。
相同点:
两者都利用少量有标签数据 + 大量无标签数据来提升学习性能。
都依赖半监督学习的某些基本假设(如平滑、聚类、流形等)。
目标都是提高模型在测试数据上的泛化能力。
不同点:
| 方面 | 直推式(Transductive)半监督学习 | 归纳式(Inductive)半监督学习 |
|---|---|---|
| 关注对象 | 只针对当前给定的特定测试集(无标签数据就是测试集) | 学习一个通用的映射函数 f: X → Y,可用于任意未来新样本 |
| 是否建模泛化 | 不建模泛化能力,只优化当前训练+测试样本的整体性能 | 显式追求泛化能力,模型学到规则后可直接用于新数据 |
| 计算方式 | 通常一次性联合优化所有样本(有标签+无标签+测试) | 先用有标签+无标签训练出一个模型,再对新样本预测 |
| 适用场景 | 测试集已知且固定(实验室/竞赛场景常见) | 真实开放世界、在线预测场景 |
| 代表性 | 更"作弊"但有时效果极强 | 更实用,部署友好 |
直推式代表算法(3种):
TSVM(Transductive SVM)
Label Propagation(标签传播)
Label Spreading(标签扩散,带正则化的传播版本)
归纳式代表算法(3种):
Self-Training(自我训练)
Co-Training(协同训练)
Mean Teacher 或 FixMatch(现代一致性正则化方法,深度半监督主流)
第十一章 概率图模型
11.1 概率图模型概论
概率图模型(PGM)的本质是:用图的结构来表达变量之间的"依赖关系",从而简化极其复杂的概率计算。
核心公式复习
在图模型中,我们需要的核心只有两个规则:
积规则(Chain Rule):P(x,y)=P(y∣x)P(x)P(x, y) = P(y|x)P(x)P(x,y)=P(y∣x)P(x)。推广到多个变量,联合概率就是一连串条件概率相乘。
和规则(Sum Rule):P(x)=∑yP(x,y)P(x) = \sum_{y} P(x, y)P(x)=∑yP(x,y)。也就是我们常说的"边际化",想要求某个变量,就对其他不相关的变量求和。
11.2 有向概率图模型
有向图通常用来表示变量之间的因果关系。
联合概率分解【怎么用】:
给定一个有向图,联合概率分布等于每个节点在给定其"父亲节点"条件下的概率乘积。P(x1,...,xn)=∏i=1nP(xi∣parents(xi))P(x_1, ..., x_n) = \prod_{i=1}^n P(x_i | parents(x_i))P(x1,...,xn)=i=1∏nP(xi∣parents(xi))xix_ixi:当前节点。parents(xi)parents(x_i)parents(xi):指向该节点的所有直接父节点。
这就像是"查族谱"。每个人的性格(概率分布)只由他的亲生父母决定,而不需要追溯到曾祖父。这种"局部性"极大地减少了我们需要存储的参数量。
D-分离(条件独立性判断)
这是考试中最容易出题的地方。你需要判断在给定某些已知信息时,两个变量是否独立。
"贝叶斯球"(Bayesian Ball)算法(D-分离)这是判断条件独立性的唯一标准。考试通常给出一个图,问你:"已知 ZZZ 的情况下,XXX 和 YYY 独立吗?"
| 结构类型 | 图示简述 | 独立性 (给定中间节点 Z 时) | 状态描述 \贝叶斯球 |
|---|---|---|---|
| 头到尾 (顺序结构) | X → Z → Y | X ⊥ Y | Z (独立) | 通道被 Z 阻塞(球被 ZZZ 挡住了) |
| 尾到尾 (分叉结构) | X ← Z → Y | X ⊥ Y | Z (独立) | 通道被 Z 阻塞(球被 ZZZ 挡住了) |
| 头到头 (汇合结构) | X → Z ← Y | 不独立 (若 Z 未知则独立) | Z 已知时通道反而开启 |
考试只用盯着 "头到头"(汇合结构)看,中间节点 ZZZ 被观测到时,本来不相关的 XXX 和 YYY 反而"联系"上了。只要记住:"V型(汇合结构、头到头)已知,路径即通"。
在汇合结构 X→Z←YX \to Z \leftarrow YX→Z←Y 中,如果 ZZZ 是未知的,就像路中间有个坑,贝叶斯球滚到 ZZZ 这里就掉下去了,到不了 YYY。得到结论:路不通 ⇒X\Rightarrow X⇒X 和 YYY 独立。
中间节点 ZZZ 已知(路修好了)逻辑:一旦你观察到了 ZZZ(或者 ZZZ 的任何子节点),就相当于给这个坑填上了土。贝叶斯球现在可以顺畅地从 XXX 滚到 YYY 了。结论:路通了 ⇒X\Rightarrow X⇒X 和 YYY 不独立(相关)
11.3 无向概率图模型 (Markov Random Fields)
无向图表示的是变量之间的关联关系,没有明确的因果之分(如图像中相邻像素的关系)。 核心概念:团(Clique)
团:图中结点的子集,其中任意两个结点之间都有边连接。
最大团:不能再增加任何一个结点使其仍是一个团。
因子分解
无向图不能写成简单的条件概率乘积,它使用势函数 ψC(xC)\psi_C(x_C)ψC(xC) 来表示:P(x)=1Z∏C∈CψC(xC)P(x) = \frac{1}{Z} \prod_{C \in \mathcal{C}} \psi_C(x_C)P(x)=Z1C∈C∏ψC(xC)C\mathcal{C}C:图中所有的最大团集合。
ψC\psi_CψC:势函数(必须非负),通常定义为 e−E(xC)e^{-E(x_C)}e−E(xC)(能量函数)。
ZZZ:配分函数(归一化因子),保证概率和为1。计算 ZZZ 通常非常困难。
11.4 典型的概率图模型:HMM (隐马尔科夫模型)
HMM 的"两个假设"与"三要素"两个假设:
齐次马尔科夫假设 :当前状态只跟前一个状态有关。
观测独立性假设:当前的观测只跟当前的状态有关。
三要素
(π,A,B)(\pi, A, B)(π,A,B):π\piπ:初始状态概率。
AAA:状态转移矩阵(状态 →\to→ 状态)。
BBB:观测概率矩阵(状态 →\to→ 观测,也叫发射概率)。
【矩阵大小】
状态转移矩阵 AAA:描述从一个状态跳到另一个状态的概率。
大小:N×NN \times NN×N(因为是 NNN 个状态到 NNN 个状态的映射)。
观测概率矩阵 BBB(也叫发射矩阵):描述在某个状态下,输出某个观测值的概率。
大小:N×MN \times MN×M(每一行对应一个状态,每一列对应一个可能的观测值)。
【例题】想象你在 20 个城市(状态)之间旅行。
AAA 矩阵:就是一张"城市间航线价格表",20×2020 \times 2020×20 涵盖了所有可能的出发和到达组合。
BBB 矩阵:如果每个城市有 100 种特产(观测),那么 BBB 就是一张"城市-特产对应表",大小就是 20×10020 \times 10020×100。
HMM 的三个基本问题
概率计算(评估):已知模型,求某个观测序列出现的概率。用前向-后向算法。
-
计算概率:
前向算法 (Forward Algorithm)目标:求观测序列 OOO 出现的概率 P(O∣λ)P(O|\lambda)P(O∣λ)。核心变量:αt(i)\alpha_t(i)αt(i)(前向概率)。递推公式:αt+1(j)=∑i=1Nαt(i)aijbj(ot+1)\alpha_{t+1}(j) = \left \\sum_{i=1}\^N \\alpha_t(i) a_{ij} \\right b_j(o_{t+1})αt+1(j)=i=1∑Nαt(i)aijbj(ot+1)其中:aija_{ij}aij:状态 iii 转移到 jjj 的概率。bj(ot+1)b_j(o_{t+1})bj(ot+1):状态 jjj 发射出观测 ot+1o_{t+1}ot+1 的概率。
-
预测(解码):已知观测序列,求最可能的隐藏状态序列。用 Viterbi 算法(本质是动态规划)。
寻找路径:Viterbi 算法
目标:求最可能的隐藏状态序列 I={i1,i2,...,iT}I = \{i_1, i_2, ..., i_T\}I={i1,i2,...,iT}。核心变量:δt(i)\delta_t(i)δt(i)(路径最大概率)。递推公式:δt(j)=max1≤i≤Nδt−1(i)aijbj(ot)\delta_t(j) = \max_{1 \le i \le N} \\delta_{t-1}(i) a_{ij} b_j(o_t)δt(j)=1≤i≤Nmaxδt−1(i)aijbj(ot)
- 学习:已知观测序列,求模型参数。用 Baum-Welch 算法(本质是 EM 算法)
| 维度 | 有向图 (Bayesian Net) | 无向图 (MRF) |
|---|---|---|
| 边表示 | 因果关系 (Causality) | 关联/耦合关系 (Correlation) |
| 局部概率 | 条件概率 P(xᵢ | paᵢ),意义明确 | 势函数 ψ(x_C),通常无直接物理意义 |
| 归一化 | 自然归一化,不需要算 Z | 需要计算复杂的 Z |
| 典型算法 | 朴素贝叶斯、HMM | 玻尔兹曼机、CRF、Ising 模型 |
例题
假设实验室里有三个盒子(状态 s1,s2,s3s_1, s_2, s_3s1,s2,s3),每个盒子里都装满了红球和白球。游戏规则:你随机选一个盒子拿出一个球,记录颜色,放回去;然后按照一定的概率跳到下一个盒子(可能还是同一个),再拿一个球。
你的任务:已知你拿出来的球序列是 {红,白},请推测你最可能是按照什么顺序在三个盒子间跳跃的。
参数描述:
假设有三个盒子 S={s1,s2,s3}S = \{s_1, s_2, s_3\}S={s1,s2,s3}(隐藏状态),每个盒子里都有红、白两种球 V={红,白}V = \{红, 白\}V={红,白}(观测变量)。实验者按照 HMM 模型随机挑盒子取球,最后给出的观测序列为 O={红,白}O = \{红, 白\}O={红,白}。已知模型参数如下:初始状态概率 π\piπ:π=(0.2,0.4,0.4)T\pi = (0.2, 0.4, 0.4)^Tπ=(0.2,0.4,0.4)T状态转移矩阵 AAA(从行状态跳到列状态):
A=0.50.20.30.30.50.20.20.30.5A = \begin{bmatrix} 0.5 & 0.2 & 0.3 \\ 0.3 & 0.5 & 0.2 \\ 0.2 & 0.3 & 0.5 \end{bmatrix}A= 0.50.30.20.20.50.30.30.20.5 观测概率矩阵 BBB(当前盒子摸出颜色的概率):
| 状态 (盒子) | 红球 | 白球 |
|---|---|---|
| s1s_1s1 (盒子1) | 0.5 | 0.5 |
| s2s_2s2 (盒子2) | 0.4 | 0.6 |
| s3s_3s3 (盒子3) | 0.7 | 0.3 |
问题:请使用 Viterbi 算法 找出最可能的隐藏盒子序列。
在 Viterbi 算法中,我们最关心的变量是 δt(i)\delta_t(i)δt(i):
定义:δt(i)\delta_t(i)δt(i) 表示在时间 ttt 时,路径到达状态 iii,且产生的观测序列与实际一致的所有路径中的最大概率。
变量表:ttt:时间步(本题中 t=1t=1t=1 是拿红球,t=2t=2t=2 是拿白球)。
iii:当前的盒子编号。
aija_{ij}aij:从盒子 iii 转移到盒子 jjj 的概率。
bj(ot)b_j(o_t)bj(ot):在盒子 jjj 观察到球颜色 oto_tot 的概率。还有记得递推公式,这里就是分别计算右边的式子的结果,找出能让右边式子达到最大值的那个。
δt(j)=max1≤i≤Nδt−1(i)aijbj(ot)\delta_t(j) = \max_{1 \le i \le N} \\delta_{t-1}(i) a_{ij} b_j(o_t)δt(j)=1≤i≤Nmaxδt−1(i)aijbj(ot)
计算前需要知道:
δt(i)\delta_t(i)δt(i):在时刻 ttt,观测序列为 o1...oto_1...o_to1...ot,且路径终点在状态 sis_isi 的所有路径中的最大概率。
ψt(i)\psi_t(i)ψt(i):记录产生上述最大概率时,时刻 t−1t-1t−1 的状态索引(用于最后回溯路径)。
步骤 1:初始化(t=1t=1t=1,观测 o1=红o_1 = 红o1=红)
计算第一天在各个盒子的最大概率(初始概率 ×\times× 该盒子出红球的概率):
δ1(1)=π1⋅b1(红)=0.2×0.5=0.10\delta_1(1) = \pi_1 \cdot b_1(红) = 0.2 \times 0.5 = \mathbf{0.10}δ1(1)=π1⋅b1(红)=0.2×0.5=0.10
δ1(2)=π2⋅b2(红)=0.4×0.4=0.16\delta_1(2) = \pi_2 \cdot b_2(红) = 0.4 \times 0.4 = \mathbf{0.16}δ1(2)=π2⋅b2(红)=0.4×0.4=0.16
δ1(3)=π3⋅b3(红)=0.4×0.7=0.28\delta_1(3) = \pi_3 \cdot b_3(红) = 0.4 \times 0.7 = \mathbf{0.28}δ1(3)=π3⋅b3(红)=0.4×0.7=0.28
记录回溯位置:ψ1(1)=0,ψ1(2)=0,ψ1(3)=0\psi_1(1) = 0, \psi_1(2) = 0, \psi_1(3) = 0ψ1(1)=0,ψ1(2)=0,ψ1(3)=0(起点无来源)。
步骤 2:递推计算(t=2t=2t=2,观测 o2=白o_2 = 白o2=白)
我们要算出第二天分别在三个盒子的概率。
每个盒子都要对比三条路:
-
计算 δ2(1)\delta_2(1)δ2(1) (第二天在盒子1的概率):
从 s1s_1s1 来:δ1(1)⋅a11=0.1×0.5=0.05\delta_1(1) \cdot a_{11} = 0.1 \times 0.5 = 0.05δ1(1)⋅a11=0.1×0.5=0.05
从 s2s_2s2 来:δ1(2)⋅a21=0.16×0.3=0.048\delta_1(2) \cdot a_{21} = 0.16 \times 0.3 = 0.048δ1(2)⋅a21=0.16×0.3=0.048
从 s3s_3s3 来:δ1(3)⋅a31=0.28×0.2=0.056\delta_1(3) \cdot a_{31} = 0.28 \times 0.2 = \mathbf{0.056}δ1(3)⋅a31=0.28×0.2=0.056 (最大)
最后乘上发射概率:δ2(1)=0.056×b1(白)=0.056×0.5=0.028\delta_2(1) = 0.056 \times b_1(白) = 0.056 \times 0.5 = \mathbf{0.028}δ2(1)=0.056×b1(白)=0.056×0.5=0.028
记录来源:ψ2(1)=3\psi_2(1) = 3ψ2(1)=3(说明去盒子1的最优路是从盒子3跳过来的)。
-
计算 δ2(2)\delta_2(2)δ2(2) (第二天在盒子2的概率):
从 s1s_1s1 来:δ1(1)⋅a12=0.1×0.2=0.02\delta_1(1) \cdot a_{12} = 0.1 \times 0.2 = 0.02δ1(1)⋅a12=0.1×0.2=0.02
从 s2s_2s2 来:δ1(2)⋅a22=0.16×0.5=0.08\delta_1(2) \cdot a_{22} = 0.16 \times 0.5 = 0.08δ1(2)⋅a22=0.16×0.5=0.08
从 s3s_3s3 来:δ1(3)⋅a32=0.28×0.3=0.084\delta_1(3) \cdot a_{32} = 0.28 \times 0.3 = \mathbf{0.084}δ1(3)⋅a32=0.28×0.3=0.084 (最大)
最后乘上发射概率:δ2(2)=0.084×b2(白)=0.084×0.6=0.0504\delta_2(2) = 0.084 \times b_2(白) = 0.084 \times 0.6 = \mathbf{0.0504}δ2(2)=0.084×b2(白)=0.084×0.6=0.0504
记录来源:ψ2(2)=3\psi_2(2) = 3ψ2(2)=3。
-
计算 δ2(3)\delta_2(3)δ2(3) (第二天在盒子3的概率):
从 s1s_1s1 来:0.1×0.3=0.030.1 \times 0.3 = 0.030.1×0.3=0.03
从 s2s_2s2 来:0.16×0.2=0.0320.16 \times 0.2 = 0.0320.16×0.2=0.032
从 s3s_3s3 来:0.28×0.5=0.140.28 \times 0.5 = \mathbf{0.14}0.28×0.5=0.14 (最大)
最后乘上发射概率:δ2(3)=0.14×b3(白)=0.14×0.3=0.042\delta_2(3) = 0.14 \times b_3(白) = 0.14 \times 0.3 = \mathbf{0.042}δ2(3)=0.14×b3(白)=0.14×0.3=0.042
记录来源:ψ2(3)=3\psi_2(3) = 3ψ2(3)=3。
步骤三:终止与路径回溯(Backtracking)
找终点:
在 t=2t=2t=2 时,比较 δ2(1),δ2(2),δ2(3)\delta_2(1), \delta_2(2), \delta_2(3)δ2(1),δ2(2),δ2(3)。0.028,0.0504,0.0420.028, \mathbf{0.0504}, 0.0420.028,0.0504,0.042。最大值是 0.0504,对应的状态索引 i2∗=2i^*_2 = \mathbf{2}i2∗=2(盒子2)。
找前一步:看 ψ2(2)\psi_2(2)ψ2(2)。ψ2(2)=3\psi_2(2) = 3ψ2(2)=3。所以前一步状态 i1∗=3i^*_1 = \mathbf{3}i1∗=3(盒子3)。
最终结论:观测序列 {红, 白} 最可能的隐藏状态序列是 {s3,s2}\{s_3, s_2\}{s3,s2}。
D-分离与条件独立 例题
考虑以下报警器模型( nodes:AAA 盗窃, BBB 地震, CCC 报警器响, DDD 警察出警):
A→CA \to CA→C (盗窃触发报警)B→CB \to CB→C (地震触发报警)C→DC \to DC→D (报警触发警察出警)
判断:在没有任何信息的情况下,AAA(盗窃)和 BBB(地震)是否独立?
找路径:AAA 和 BBB 之间的唯一路径是 A→C←BA \to C \leftarrow BA→C←B。
看结构:这是一个 汇合 结构,中间节点是 CCC。
判开关:目前 CCC 是未知的。路径是关闭的。
结论:路不通,A⊥BA \perp BA⊥B。独立。
判断:已知警察已经出警(DDD 已知),AAA 和 BBB 是否独立?
找路径:依然是 A→C←BA \to C \leftarrow BA→C←B。
看结构:依然是汇合结构。
判开关:虽然没直接给 CCC,但给了 CCC 的子节点 DDD(警察来了,那肯定是报警器响了)。在 V-structure 中,已知 CCC 或 CCC 的后代,都会开启路径。
结论:路通了,A⊥̸BA \not\perp BA⊥B。不独立。
判断:已知报警器响了(CCC 已知),AAA 和 DDD(出警)是否独立?
找路径:A→C→DA \to C \to DA→C→D。
看结构:这是一个顺序 结构。
判开关:中间节点 CCC 已知。路径关闭。
结论:路不通,A⊥D∣CA \perp D \mid CA⊥D∣C。条件独立。
11.5 推断与学习、条件随机场 (CRF, Conditional Random Fields)
这里只给出这部分的概念
CRF 是在 HMM 基础上为了解决"标注偏置"和"利用全局特征"而产生的模型。
- 核心定义模型性质:一种判别式 (Discriminative) 概率图模型。
- 建模目标:直接建模条件概率 P(Y∣X)P(Y \mid X)P(Y∣X),而不是联合概率。
- 线性链 CRF (Linear-chain CRF):最常用的形式,假设状态序列满足马尔科夫性
核心公式(参数化形式)P(y∣x)=1Z(x)exp(∑i,kλktk(yi−1,yi,x,i)+∑i,lμlsl(yi,x,i))P(y|x) = \frac{1}{Z(x)} \exp \left( \sum_{i,k} \lambda_k t_k(y_{i-1}, y_i, x, i) + \sum_{i,l} \mu_l s_l(y_i, x, i) \right)P(y∣x)=Z(x)1exp i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)
tkt_ktk (转移特征):描述标签之间的关联(如:动词后通常不接动词)。
sls_lsl (状态特征):描述观测与标签的关联(如:以"-ing"结尾的词多为动词)。
Z(x)Z(x)Z(x):归一化因子(配分函数),确保所有路径概率和为 1。
对比一下hmm和crf
| 维度 | HMM | CRF |
|---|---|---|
| 模型类型 | 生成式 | 判别式 |
| 假设 | 严格的独立性假设(观测独立等) | 无严格独立性假设,可利用全局特征 |
| 优势 | 简单、收敛快 | 准确率高、解决标注偏置问题 |
| 基本单元 | 概率分布 (A, B 矩阵) | 特征函数 (权重 λ, μ) |
"推断"就是已知模型,求某个变量的概率(边缘分布)或者求最可能的序列。
- 精确推断 (Exact Inference)
变量消去法 (Variable Elimination):通过分配律把求和号移进乘积项内,减少重复计算。
信念传播 (BP, Belief Propagation):在树状图上通过节点间互发"消息"来同步全局概率信息。
- 近似推断 (Approximate Inference)
采样法 (Sampling):如 MCMC (马尔科夫链蒙特卡罗) 采样。通过随机模拟大量样本来逼近真实分布。
变分推断 (Variational Inference):找一个简单的分布(如高斯分布)去不断"靠近"复杂的真实分布,把推断问题变成优化问题。
学习 (Learning) 简述
"学习"就是已知数据,求模型里的参数(比如那些 λ\lambdaλ 权重是多少)。
- HMM 的学习Baum-Welch 算法:属于 EM 算法。用于在不知道隐藏状态的情况下,通过迭代优化的方式估计参数。
- CRF 的学习准则:最大似然估计 (Maximum Likelihood Estimation)。方法:梯度上升法。难点:梯度收敛慢。
第十二章 集成学习
集成学习通过组合多个基学习器(Weak learners)来构建一个强学习器(Strong learner),从而提高系统的泛化性能 。
12.1 Bagging 、Bootstrap 采样与"0.632 规则"
Bagging 指的是"自助法"重采样,即有放回地随机抽取样本。
Bootstrap是 Bagging 的数学基础,考试极容易出一个小计算题或者填空题。
核心公式与推导结论:
给定包含 mmm 个样本的数据集 DDD,我们进行 mmm 次有放回采样得到数据集 D′D'D′。
考点: 某个特定样本始终不被抽到的概率是多少?
limm→∞(1−1m)m=1e≈0.368\lim_{m \to \infty} (1 - \frac{1}{m})^m = \frac{1}{e} \approx 0.368m→∞lim(1−m1)m=e1≈0.368
结论:
约 36.8% 的样本从未出现在训练集中(称为包外样本,Out-of-Bag, OOB)。
约 63.2% 的样本出现在训练集中。
填空:Bootstrap 采样中,训练集大约包含原始数据集中 63.2% 的独特样本。
应用:OOB 样本可以用来做什么? 答案:用来做验证集(Validation),不需要额外的交叉验证(Cross-Validation)。
12.2 AdaBoost
算法流程
AdaBoost 的核心是:让错题变重,让对题变轻,让好老师话语权大。
-
假设我们处于第 ttt 轮迭代:
计算错误率 ϵt\epsilon_tϵt:ϵt=∑i=1mwt,i⋅I(yi≠ht(xi))\epsilon_t = \sum_{i=1}^{m} w_{t,i} \cdot \mathbb{I}(y_i \neq h_t(x_i))ϵt=i=1∑mwt,i⋅I(yi=ht(xi))
(就是把分错样本的权重加起来)
-
计算当前分类器的权重 αt\alpha_tαt(老师的话语权):
αt=12ln(1−ϵtϵt)\alpha_t = \frac{1}{2} \ln \left( \frac{1 - \epsilon_t}{\epsilon_t} \right)αt=21ln(ϵt1−ϵt)直观考点:如果 ϵt=0.5\epsilon_t = 0.5ϵt=0.5(瞎猜),则 αt=0\alpha_t = 0αt=0(没话语权)。
如果 ϵt<0.5\epsilon_t < 0.5ϵt<0.5(比瞎猜好),αt>0\alpha_t > 0αt>0。
如果 ϵt>0.5\epsilon_t > 0.5ϵt>0.5(反向预测),αt<0\alpha_t < 0αt<0(反着听你的就是了)。
-
更新样本权重 wt+1w_{t+1}wt+1(关键步骤):
wt+1,i=wt,iZt×{e−αt,如果分对了eαt,如果分错了w_{t+1, i} = \frac{w_{t,i}}{Z_t} \times \begin{cases} e^{-\alpha_t}, & \text{如果分对了} \\ e^{\alpha_t}, & \text{如果分错了} \end{cases}wt+1,i=Ztwt,i×{e−αt,eαt,如果分对了如果分错了
(其中 ZtZ_tZt 是规范化因子,保证新权重之和为1)
例题
题目:有 4 个样本,初始权重均为 0.250.250.25。分类器 h1h_1h1 分错了第 4 个样本,分对了前 3 个。请计算下一轮第 4 个样本的权重。
解题步骤:
- 算错误率:只有第4个错了,且权重是0.25。ϵ1=0.25\epsilon_1 = 0.25ϵ1=0.25
- 算分类器权重:α1=12ln(1−0.250.25)=12ln(3)≈0.55\alpha_1 = \frac{1}{2} \ln(\frac{1-0.25}{0.25}) = \frac{1}{2} \ln(3) \approx 0.55α1=21ln(0.251−0.25)=21ln(3)≈0.55
- 算新权重(未归一化):分对的样本(1,2,3):0.25×e−0.55≈0.25×0.577=0.1440.25 \times e^{-0.55} \approx 0.25 \times 0.577 = 0.1440.25×e−0.55≈0.25×0.577=0.144分错的样本(4):0.25×e0.55≈0.25×1.73=0.4330.25 \times e^{0.55} \approx 0.25 \times 1.73 = 0.4330.25×e0.55≈0.25×1.73=0.433归一化(求 Z1Z_1Z1):Z1=3×0.144+0.433=0.432+0.433=0.865Z_1 = 3 \times 0.144 + 0.433 = 0.432 + 0.433 = 0.865Z1=3×0.144+0.433=0.432+0.433=0.865
- 最终第4个样本的权重:
w2,4=0.4330.865≈0.5w_{2,4} = \frac{0.433}{0.865} \approx 0.5w2,4=0.8650.433≈0.5
验证:分错的样本权重从 0.25 飙升到了 0.5。这就是 AdaBoost 的本质。
| 对比维度 | Bagging (如随机森林) | Boosting (如 AdaBoost/GBDT) |
|---|---|---|
| 样本采样 | Bootstrap 有放回采样 | 这里的权重高,下次重点采(或直接改权重) |
| 训练顺序 | 并行 (Parallel) - 互不干扰 | 串行 (Sequential) - 也就是这里的错题留给下一个做 |
| 偏差-方差 | 主要降低 方差 (Variance) | 主要降低 偏差 (Bias) |
| 基分类器要求 | 强一点、复杂一点 (如深层决策树/过拟合模型) | 弱一点、简单一点 (如浅层树桩/欠拟合模型) |
| 抗噪能力 | 强 (因为可以平均掉噪声) | 弱 (因为会拼命去拟合噪声/异常点) |
Bagging 能提高准确率吗? 能,但主要是通过"稳定"模型(降方差)来提高的,它不能把一个本身就是瞎猜(偏差极大)的模型变好。
Boosting 会过拟合吗? 会,特别是当它试图去拟合异常值(Outliers)的时候。
12.3 集成学习的其他概念
这里只会考概念题目,所以都罗列在一起了。
这一部分讨论的是如何通过不同的组合策略,让基学习器之间产生更好的化学反应。考试的重点在于区分不同融合方式的核心机制。
- 随机森林 (Random Forest, RF)随机森林是 Bagging 的加强版,它的核心在于双重随机性:
样本随机:通过 Bootstrap 采样,每个专家看的数据集不一样。
特征随机:在决策树分裂时,不再从所有 ddd 个特征中选最优,而是先随机选出 kkk 个特征子集(通常 k=log2dk = \log_2 dk=log2d),再从中选最优。
直观理解:如果说 Bagging 是给专家们发不同的卷子,随机森林就是不仅卷子不同,还把卷子的一部分题给遮住了。这样强制增加了专家之间的多样性,使得集成后的模型极其鲁棒,且能通过 OOB 样本自带验证效果。
- Stacking (堆叠法)
Stacking 是一种分层训练的组合策略。
第一层(初级学习器):用原始数据训练多个不同的模型(如 SVM、KNN)。
第二层(次级学习器/元学习器):将第一层模型的预测输出作为特征,训练一个新的模型。
直观理解:第一层是各科老师改卷子出分,第二层是一个校长,他根据这几个老师给出的分(预测值),总结出哪个老师更准,从而给出最终成绩。 注意:为了防止过拟合,第一层输出必须通过交叉验证(Cross-validation)产生。
- 混合专家模型 (MoE)
这是目前大模型(如 GPT-4)的核心技术。
结构:由多个专家网络(Experts)和一个门控网络(Gating Network)组成。
机制:条件计算。对于特定的输入,门控网络只"激活"一两个最相关的专家,其余专家保持静默。
直观理解:比起 Stacking 这种所有老师都要批改一遍的累活,MoE 是"专人专项"。你是数学题就发给数学组专家,你是语文题就发给文学专家。这大大节省了计算资源,并实现了模型规模的爆炸式增长而计算成本不增加。