作者:来自 Elastic Sherry Ger 及 Ryan Eno

虽然 best_compression 通常被视为用于 Elastic Observability 和 Elastic Security 使用场景的节省存储特性,但本文展示了它作为搜索性能调优手段的有效性。
测试 Elastic 领先的开箱即用能力。深入体验我们的示例 notebooks,开始免费的 cloud trial,或立即在本地机器上试用 Elastic。
在为高并发工作负载调优 Elasticsearch 时,标准做法是最大化 RAM,以将文档工作集保留在内存中,从而实现低搜索延迟。因此,best_compression 很少被用于搜索工作负载,因为它主要被视为 Elastic Observability 和 Elastic Security 使用场景中的一种节省存储手段,在这些场景中存储效率更为重要。
在这篇博客中,我们展示了当数据集规模显著超过 OS page cache 时,best_compression 通过减少 I/O 瓶颈来提升搜索性能和资源效率。
设置
我们的使用场景是在 Elastic Cloud CPU 优化实例上运行的高并发搜索应用。
- 数据规模:约 5 亿 文档
- 基础设施:6 个 Elastic Cloud( Elasticsearch service )实例(每个实例:1.76 TB 存储 | 60 GB RAM | 31.9 vCPU)
- 内存与存储比例:约 5% 的数据集可放入 RAM
问题表现:高延迟
我们观察到,当当前请求数量在 19:00 左右激增时,搜索延迟显著恶化。如图 1 和图 2 所示,当每个 Elasticsearch 实例的流量峰值约为每分钟 400 个请求时,平均查询服务时间恶化到超过 60ms。
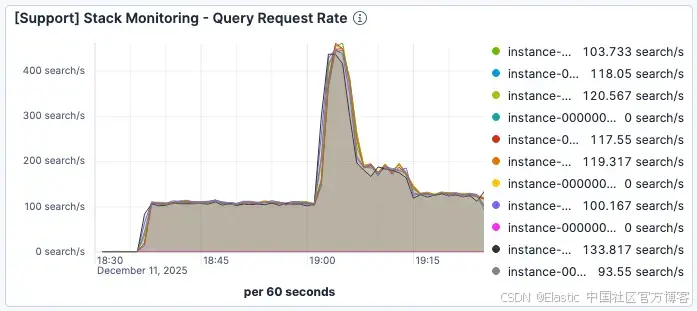 图 2。平均查询服务时间开始飙升,并上升并维持在 >60ms。
图 2。平均查询服务时间开始飙升,并上升并维持在 >60ms。
在最初处理连接之后,CPU 使用率仍然相对较低,这表明计算并不是瓶颈。
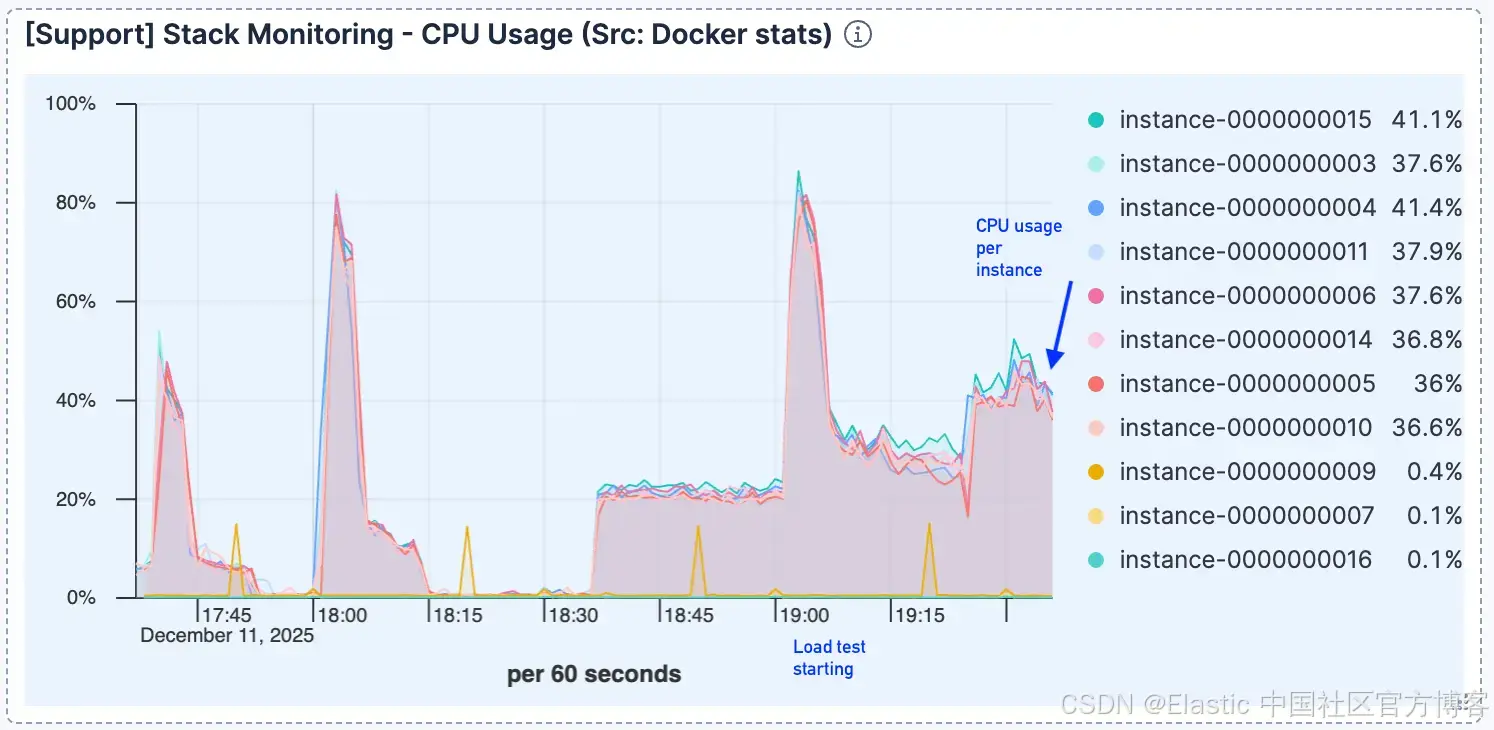 图 3。在最初的跃升之后,CPU 使用率仍然相对较低。
图 3。在最初的跃升之后,CPU 使用率仍然相对较低。
查询量与 page faults 之间出现了明显的相关性。随着请求增加,我们观察到 page faults 按比例上升,并在约 400k/分钟 达到峰值。这表明活跃数据集无法放入 page cache。
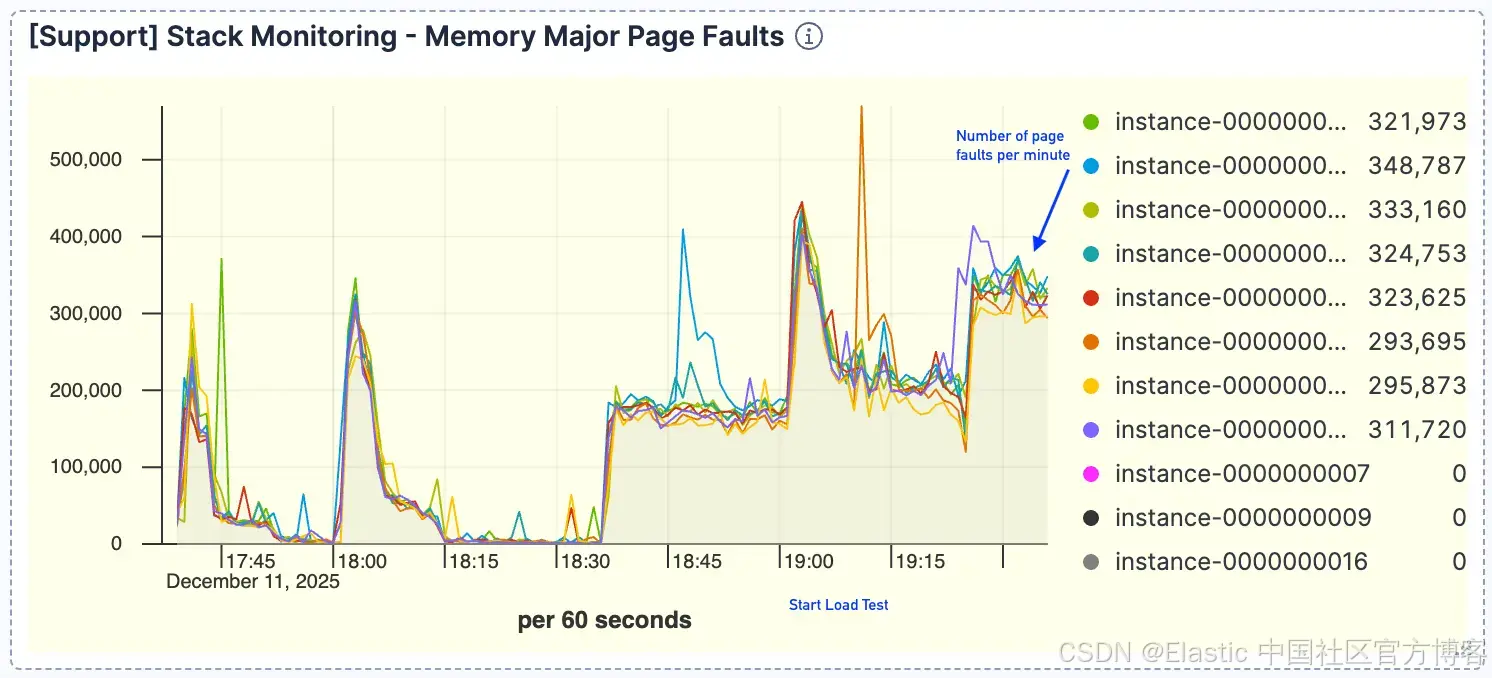 图 4。page faults 数量很高,并在约 400k/分钟 达到峰值。
图 4。page faults 数量很高,并在约 400k/分钟 达到峰值。
同时,JVM heap 使用情况看起来正常且健康。这排除了垃圾回收问题,并确认瓶颈在于 I/O。
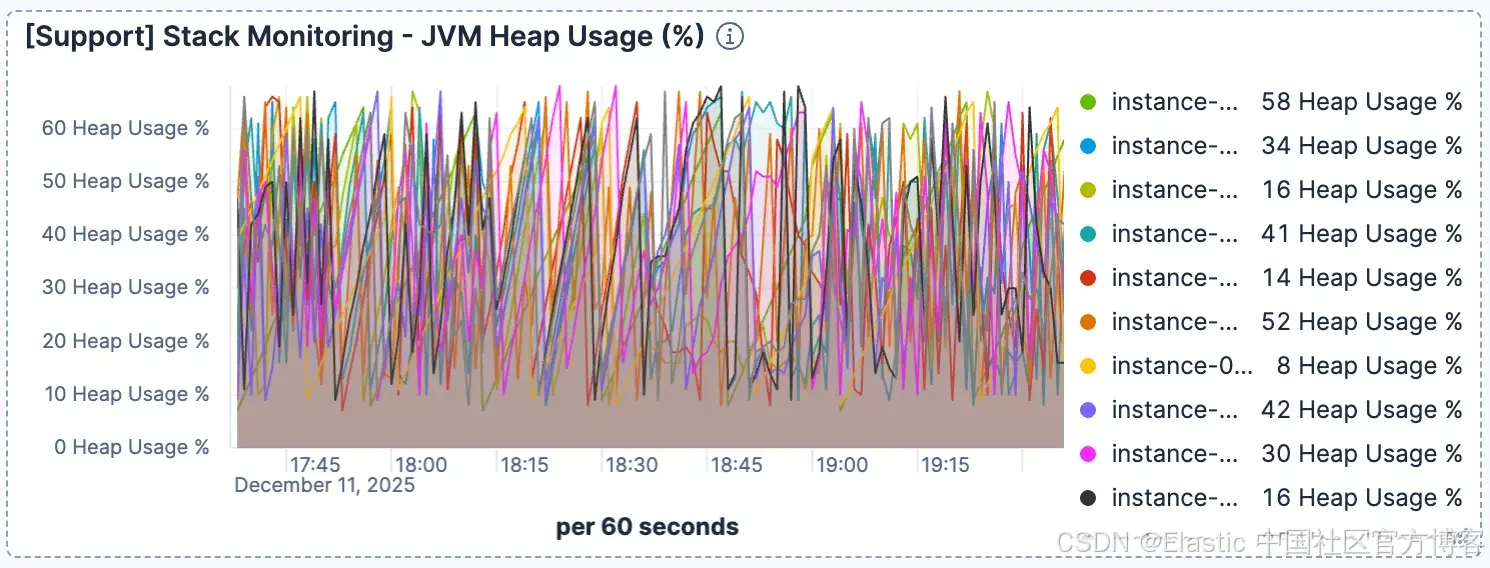 图 5。Heap 使用保持平稳。
图 5。Heap 使用保持平稳。
诊断:I/O 瓶颈
系统存在 I/O 瓶颈。Elasticsearch 依赖 OS page cache 从内存中提供索引数据。当索引过大以至于无法放入缓存时,查询会触发代价高昂的磁盘读取。虽然典型解决方案是水平扩展(增加节点/RAM),但我们希望先在现有资源上尽可能提升效率。
解决方法
默认情况下,Elasticsearch 对索引段使用 LZ4 压缩,在速度和大小之间取得平衡。我们假设切换到 best_compression(使用 zstd)可以减小索引大小。更小的占用允许更大比例的索引放入 page cache,以牺牲微不足道的 CPU(用于解压缩)换取磁盘 I/O 的减少。
要启用 best_compression,我们通过索引设置 index.codec: best_compression 重新索引数据。或者,也可以通过关闭索引、重置索引 codec 为 best_compression,然后执行段合并来实现相同效果。
POST my-index/_close
PUT my-index/_settings
{
"codec": "best_compression"
}
POST my-index/_open
POST my-index/_forcemerge?max_num_segments=1结果
结果验证了我们的假设:存储效率的提升直接转化为搜索性能的大幅提升,同时 CPU 使用率没有增加。
应用 best_compression 后,索引大小减少了约 25%。虽然低于重复日志数据的缩减幅度,但这 25% 的减少有效地增加了相同比例的 page cache 容量。
在下一次负载测试中(从 17:00 开始),流量更高,每个 Elasticsearch 节点的峰值达到每分钟 500 个请求。
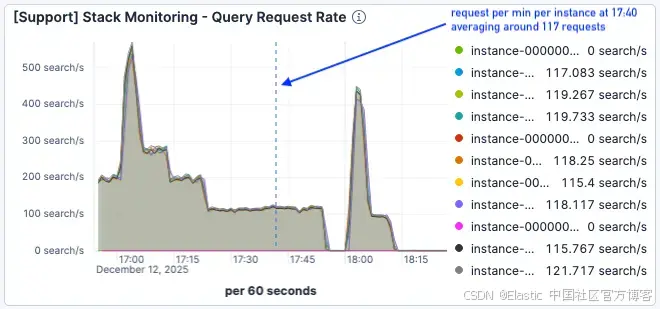 图 6。负载测试在约 17:00 开始。
图 6。负载测试在约 17:00 开始。
尽管负载更高,CPU 使用率却低于上一次测试。之前测试中的高 CPU 使用很可能是由于过多 page fault 处理和磁盘 I/O 管理的开销造成的。
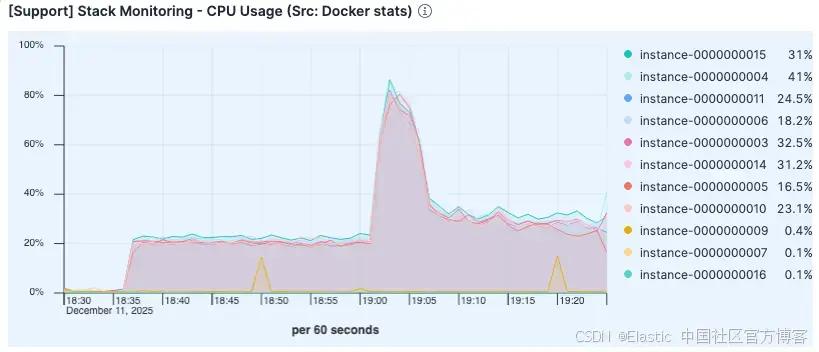 图 7。CPU 使用率低于上一次测试。
图 7。CPU 使用率低于上一次测试。
关键是,page faults 显著下降。即使在更高的吞吐量下,faults 也维持在每分钟 <200k 左右,而基准测试中则超过 300k。
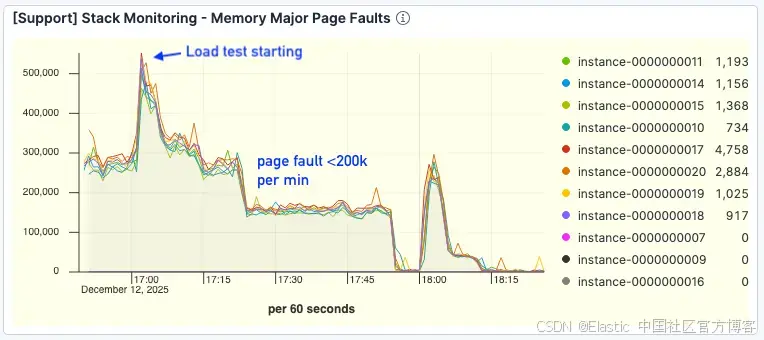 图 8。page faults 数量显著改善。
图 8。page faults 数量显著改善。
虽然 page faults 的结果仍未达到最优,但查询服务时间减少了约 50%,即使在更高负载下也保持在 30ms 以下。
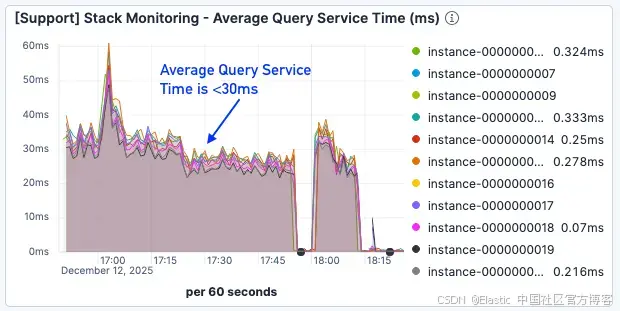 图 9。平均查询服务时间低于 30ms。
图 9。平均查询服务时间低于 30ms。
结论:搜索中的 best_compression
对于数据量超过可用物理内存的搜索使用场景,best_compression 是一个强有力的性能调优手段。
缓存未命中时的传统解决方案是水平扩展以增加 RAM。然而,通过减小索引占用,我们实现了相同的目标:最大化 page cache 中的文档数量。下一步,我们将探索索引排序,以进一步优化存储,并从现有资源中挤出更多性能。
原文:https://www.elastic.co/search-labs/blog/improve-elasticsearch-performance-best-compression