更多技术博客欢迎大佬来交流
www.zealsinger.xyz
关键要点
- Nacos2.x 内存注册表是服务发现的核心数据结构
- 服务调用链路分为客户端查询和服务端处理两个主要阶段
- 订阅模式通过定时任务和gRPC实现高效数据同步
- 内存注册表采用多级索引结构优化查询性能
- 客户端与服务端通过订阅关系实现实时数据推送
一、客户端服务查询逻辑
Nacos2.x 内存注册表作为服务发现的核心组件,在服务调用链路中扮演着至关重要的角色。客户端查询服务实例的过程涉及多个关键步骤,我们将从源码角度深入剖析其实现原理。
这里我们之前其在Nacos1.4.X版本的分析中有说过的,当时我们对于Nacos2.X版本中的实现也是有一定的提及的,所以我们不会很详细的从头到尾讲,大家可以先去回顾一下
Nacos源码学习计划-Day05-服务调用时的调用链路(如何获取服务信息) - ZealSingerの博客啦~
之前有提到,Nacos2.X版本中就是通过实现Spring Cloud服务发现接口,依赖于NacosServiceDiscovery来和Nacos服务端进行交互,在NacosServiceDiscovery中查询服务列表的操作其实就是调用的namingService().selectInstances(),我们可以进去看看他的逻辑
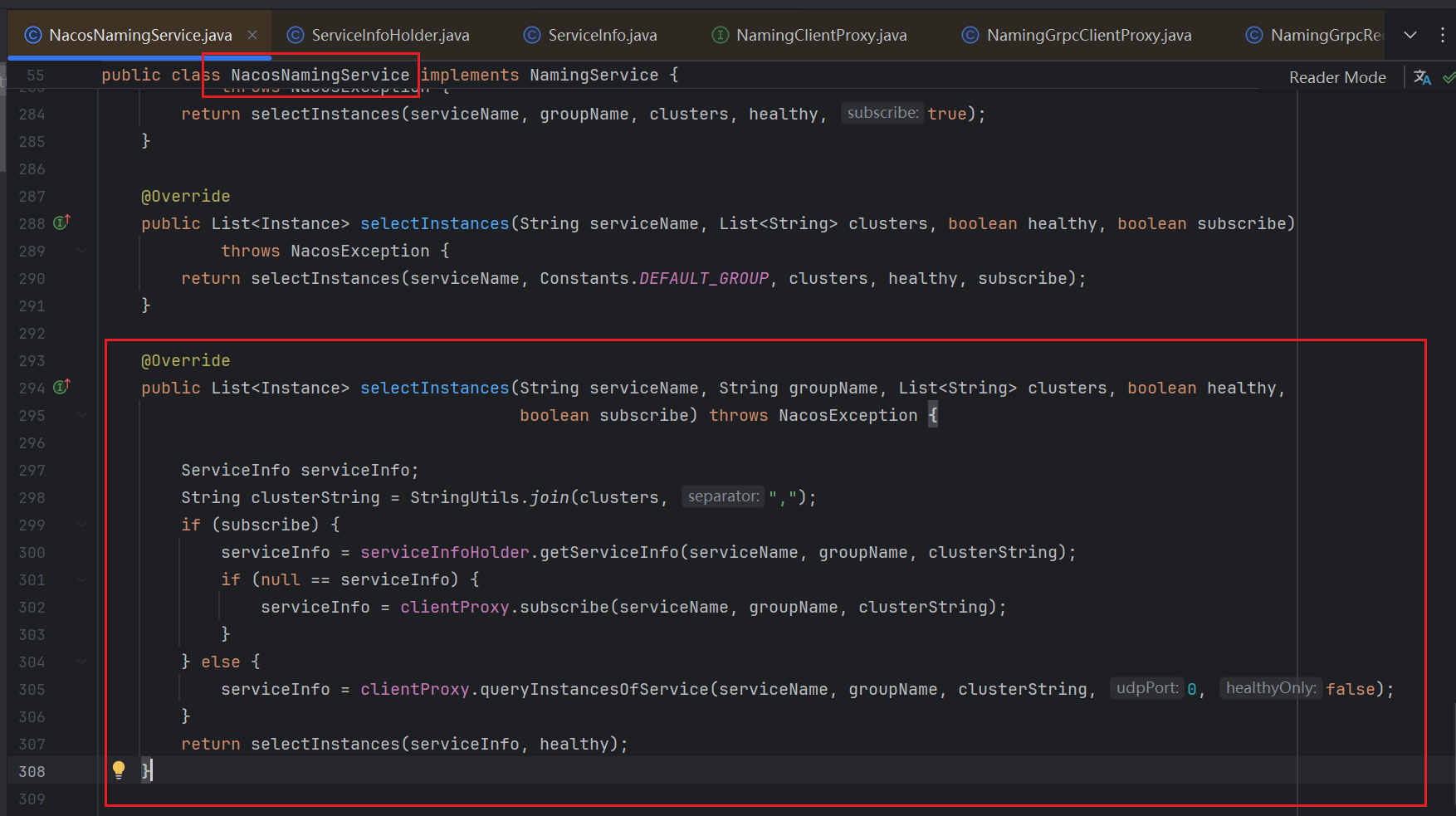
这里需要注意,不要看到return语句中的selectInstances去了,这个里面是对于serviceInfo对象中的hosts的健康状态的判断,用于去除不健康的数据,也就是说我们服务端直接返回的是serviceInfo,所以我们要看这个对象的获取逻辑,也就是如下这行逻辑
java
@Override
public List<Instance> selectInstances(String serviceName, String groupName, List<String> clusters, boolean healthy,
boolean subscribe) throws NacosException {
ServiceInfo serviceInfo;
String clusterString = StringUtils.join(clusters, ",");
// 判断是否需要 订阅,默认为 true
if (subscribe) {
// 查询 Nacos 本地缓存数据
serviceInfo = serviceInfoHolder.getServiceInfo(serviceName, groupName, clusterString);
// 如果本地缓存数据为空,则通过 client 对象请求服务端获取数据,这里是调用的订阅方法
if (null == serviceInfo) {
serviceInfo = clientProxy.subscribe(serviceName, groupName, clusterString);
}
} else {
serviceInfo = clientProxy.queryInstancesOfService(serviceName, groupName, clusterString, 0, false);
}
// 返回数据
return selectInstances(serviceInfo, healthy);
}这个subscribe大家先知道他是客户端是否采用订阅模式,默认情况下就是true即开启订阅模式,该配置影响的也就是客户端查询服务实例的方式和时机,区别的体现也是就是我们上述代码中
二、订阅模式下的内存注册表交互
订阅模式下,我们可以很清楚的看到,先执行的serviceInfoHolder.getServiceInfo先查询缓存,其底层就是在客户端内存Map中进行get()操作,然后再执行的clientProxy.subscribe就是查询服务端且进行订阅,我可以来看一下这个过程的逻辑,这个subscribe是需要寻找对应的实现类的,我们可以直接查看clientProxy数据类型,就知道要看哪个了
java
@Override
public ServiceInfo subscribe(String serviceName, String groupName, String clusters) throws NacosException {
NAMING_LOGGER.info("[SUBSCRIBE-SERVICE] service:{}, group:{}, clusters:{} ", serviceName, groupName, clusters);
String serviceNameWithGroup = NamingUtils.getGroupedName(serviceName, groupName);
String serviceKey = ServiceInfo.getKey(serviceNameWithGroup, clusters);
// 开启实例查询定时任务
serviceInfoUpdateService.scheduleUpdateIfAbsent(serviceName, groupName, clusters);
// 会再一次查询缓存数据
ServiceInfo result = serviceInfoHolder.getServiceInfoMap().get(serviceKey);
if (null == result || !isSubscribed(serviceName, groupName, clusters)) {
// 如果还是为空,则会使用 grpc 来请求服务端
result = grpcClientProxy.subscribe(serviceName, groupName, clusters);
}
// 更新本地缓存
serviceInfoHolder.processServiceInfo(result);
return result;
}scheduleUpdateIfAbsent开启了一个 实例查询定时任务,在这个定时任务中会去更新本地缓存的数据,我们来看一下里面的逻辑
java
private final Map<String, ScheduledFuture<?>> futureMap = new HashMap<String, ScheduledFuture<?>>();
public void scheduleUpdateIfAbsent(String serviceName, String groupName, String clusters) {
// 生成一个 serverKey
String serviceKey = ServiceInfo.getKey(NamingUtils.getGroupedName(serviceName, groupName), clusters);
// 判断当前 serviceKey 是否有开启定时任务,如果有就不开启了
if (futureMap.get(serviceKey) != null) {
return;
}
// 加了一把同步锁,以免并发冲突
synchronized (futureMap) {
// 加锁之后又再一次进行判断,双重检测
if (futureMap.get(serviceKey) != null) {
return;
}
// 最后开 UpdateTask 定时任务
ScheduledFuture<?> future = addTask(new UpdateTask(serviceName, groupName, clusters));
futureMap.put(serviceKey, future);
}
}每次查询一个新的 service 都会开启这么一个定时任务,来为本地数据进行更新操作。我们再来看看这个 UpdateTask 做了什么事情,代码如下:
java
@Override
public void run() {
long delayTime = DEFAULT_DELAY;
try {
// 如果没有订阅且map中不包含任务 则取消该任务
if (!changeNotifier.isSubscribed(groupName, serviceName, clusters) && !futureMap.containsKey(
serviceKey)) {
NAMING_LOGGER.info("update task is stopped, service:{}, clusters:{}", groupedServiceName, clusters);
isCancel = true;
return;
}
// 从本地缓存中获取一次,如果本地缓存中为空
ServiceInfo serviceObj = serviceInfoHolder.getServiceInfoMap().get(serviceKey);
if (serviceObj == null) {
// 为空就会通过 gRPC 去查询服务端的数据
serviceObj = namingClientProxy.queryInstancesOfService(serviceName, groupName, clusters, 0, false);
// 更新本地缓存
serviceInfoHolder.processServiceInfo(serviceObj);
// 更新获取时间
lastRefTime = serviceObj.getLastRefTime();
return;
}
// 如果本地缓存不为空,会判断该本地缓存最后一次刷新的时间,是否小于等于 最后一次数据刷新时间
if (serviceObj.getLastRefTime() <= lastRefTime) {
// 小于等于的话,会重新请求服务端数据,然后更新本地缓存
// 需要注意queryInstancesOfService方法的后面两个参数 0是updPort 这个是;历史兼容问题,Nacos1.X版本中会通过upd协议进行服务端对客户端的主动推送,这个参数用于告诉服务端,客户端在哪个端口进行监听接受
// 但是Nacos2.X版本中已经全面采用gRPC了,所以这个参数其实是没有意义,所以直接传入0即可
// 最后一个boolea类型的参数,代表healthOnly,即是否只返回健康实例,如果传入false则代表无论健康还是不健康的实例都会被传回
serviceObj = namingClientProxy.queryInstancesOfService(serviceName, groupName, clusters, 0, false);
serviceInfoHolder.processServiceInfo(serviceObj);
}
lastRefTime = serviceObj.getLastRefTime();
// 如果为empty 则代表请求失败了 则会累计请求失败次数
// 因为我们在查询的时候设置了healthOnly参数为false,所以如果返回为空则说明从服务端的角度而言单体或者集群中满足条件的健康实例和非健康实例,这个对于客户端缓存而言的效果就是没有,所以empty可以直接和请求fail进行绑定
if (CollectionUtils.isEmpty(serviceObj.getHosts())) {
// 累计请求失败次数 实质上就是failCount这个变量递增
incFailCount();
return;
}
// 计算下一次定时任务执行的时间,这里的结果是 6s
delayTime = serviceObj.getCacheMillis() * DEFAULT_UPDATE_CACHE_TIME_MULTIPLE;
// 当请求成功之后,会重置错误次数为 0
resetFailCount();
} catch (Throwable e) {
// 记录请求失败的次数
incFailCount();
NAMING_LOGGER.warn("[NA] failed to update serviceName: {}", groupedServiceName, e);
} finally {
if (!isCancel) {
// 这里就根据请求失败的次数,来动态调整定时任务的执行时间,防止频繁地重试
executor.schedule(this, Math.min(delayTime << failCount, DEFAULT_DELAY * 60),
TimeUnit.MILLISECONDS);
}
}
}定时任务开启之后,我们会通过subscribe方法对服务端发起订阅查询这个RPC请求,其逻辑如下,可以发现就是发起了一个SubscribeServiceRequest的请求
java
/**
* Execute subscribe operation.
*
* @param serviceName service name
* @param groupName group name
* @param clusters clusters, current only support subscribe all clusters, maybe deprecated
* @return current service info of subscribe service
* @throws NacosException nacos exception
*/
public ServiceInfo doSubscribe(String serviceName, String groupName, String clusters) throws NacosException {
SubscribeServiceRequest request = new SubscribeServiceRequest(namespaceId, groupName, serviceName, clusters,
true);
SubscribeServiceResponse response = requestToServer(request, SubscribeServiceResponse.class);
redoService.subscriberRegistered(serviceName, groupName, clusters);
return response.getServiceInfo();
}三、非订阅模式下的内存注册表交互
至于非订阅模式下,代码逻辑就很简单了
serviceInfo = clientProxy.queryInstancesOfService(serviceName, groupName, clusterString, 0, false);可以看到,这个逻辑其实也是订阅模式下UpdateTask的run逻辑中RPC查询服务端的方法,其实就是调用了同一个方法进行RPC查询,所以这里我们不需要多解释。
| 方法 | 设计意图 |
|---|---|
subscribe |
以「一次订阅请求」换「后续无感知的推送更新」,减少客户端与服务端的交互次数,提升性能(订阅模式的核心价值) |
queryInstancesOfService |
满足「单次实时查询」场景(如手动触发的实例校验、非长连接场景),牺牲性能换实时性,同时通过降级缓存保证容错 |
四、服务端处理订阅查询请求
我们在分析订阅模式下的请求逻辑的时候,看到了实际上就是发出了一个SubscribeServiceRequest的请求到服务端,老规矩,我们利用Idea的搜索功能到服务端查看一下服务端是如何处理的
很轻松我们就能找到SubscribeServiceRequestHandler这个处理器,其逻辑为
java
@Override
@Secured(action = ActionTypes.READ)
public SubscribeServiceResponse handle(SubscribeServiceRequest request, RequestMeta meta) throws NacosException {
// 从request中获取相关目标服务的数据
String namespaceId = request.getNamespace();
String serviceName = request.getServiceName();
String groupName = request.getGroupName();
String app = request.getHeader("app", "unknown");
String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);
// 利用参数创建一个临时service 即被调用的那个服务的Service
Service service = Service.newService(namespaceId, groupName, serviceName, true);
// 利用请求元数据 创建请求订阅的对象 即请求发起者
Subscriber subscriber = new Subscriber(meta.getClientIp(), meta.getClientVersion(), app, meta.getClientIp(),
namespaceId, groupedServiceName, 0, request.getClusters());
// 获取健康的实例
ServiceInfo serviceInfo = ServiceUtil.selectInstancesWithHealthyProtection(serviceStorage.getData(service),
metadataManager.getServiceMetadata(service).orElse(null), subscriber);
if (request.isSubscribe()) {
// 如果是订阅模式 在这里进行订阅关系的绑定 当订阅关系绑定成功后 会触发服务端推送服务数据
clientOperationService.subscribeService(service, subscriber, meta.getConnectionId());
} else {
clientOperationService.unsubscribeService(service, subscriber, meta.getConnectionId());
}
return new SubscribeServiceResponse(ResponseCode.SUCCESS.getCode(), "success", serviceInfo);
}主体逻辑的分析就是如上,我们现在来看看里面的几个方法
五、selectInstancesWithHealthyProtection 方法分析
这个方法的直接逻辑是获取有健康保证的实例,其方法定义如下
java
/**
* Select instance of service info with healthy protection.
* @param serviceInfo original service info
* @param serviceMetadata service meta info
* @param subscriber subscriber
* @return new service info
*/
public static ServiceInfo selectInstancesWithHealthyProtection(ServiceInfo serviceInfo, ServiceMetadata serviceMetadata, Subscriber subscriber) {
return selectInstancesWithHealthyProtection(serviceInfo, serviceMetadata, subscriber.getCluster(), false, false, subscriber.getIp());
}该方法的第一个参数是ServiceInfo对象,这个参数的获取是通过serviceStorage.getData(service)获取到的,我们来看一下他的逻辑
Kotlin
private final ConcurrentMap<Service, ServiceInfo> serviceDataIndexes;
public ServiceInfo getData(Service service) {
// 判断缓存中是否有数据,如果有直接取缓存数据,缓存没有就调用 getPushData(service)
return serviceDataIndexes.containsKey(service) ? serviceDataIndexes.get(service) : getPushData(service);
}我们第一次查,肯定是没有缓存的,也就是肯定走后面的getPushData()方法
java
public ServiceInfo getPushData(Service service) {
// emptyServiceInfo的作用是将Service对象转化为ServiceInfo对象,注意这个result目前其hosts是空的
ServiceInfo result = emptyServiceInfo(service);
if (!ServiceManager.getInstance().containSingleton(service)) {
return result;
}
// getAllInstancesFromIndex方法赋值hosts
result.setHosts(getAllInstancesFromIndex(service));
serviceDataIndexes.put(service, result);
return result;
}
private List<Instance> getAllInstancesFromIndex(Service service) {
Set<Instance> result = new HashSet<>();
Set<String> clusters = new HashSet<>();
for (String each : serviceIndexesManager.getAllClientsRegisteredService(service)) {
Optional<InstancePublishInfo> instancePublishInfo = getInstanceInfo(each, service);
if (instancePublishInfo.isPresent()) {
Instance instance = parseInstance(service, instancePublishInfo.get());
result.add(instance);
clusters.add(instance.getClusterName());
}
}
// cache clusters of this service
serviceClusterIndex.put(service, clusters);
return new LinkedList<>(result);
}其中getAllInstancesFromIndex方法很关键,分析如下
java
private List<Instance> getAllInstancesFromIndex(Service service) {
// 这里的 service 参数对应我们需要查询的服务 stock-service
Set<Instance> result = new HashSet<>();
Set<String> clusters = new HashSet<>();
// each = clientId,通过 service 获取对应 service 全部的 ClientId
for (String each : serviceIndexesManager.getAllClientsRegisteredService(service)) {
// 通过 clientId 查找对应的 Instance 信息
Optional<InstancePublishInfo> instancePublishInfo = getInstanceInfo(each, service);
if (instancePublishInfo.isPresent()) {
// 对象转换
Instance instance = parseInstance(service, instancePublishInfo.get());
result.add(instance);
clusters.add(instance.getClusterName());
}
}
// 缓存该 service 对应有哪些 集群
serviceClusterIndex.put(service, clusters);
return new LinkedList<>(result);
}getAllClientsRegisteredService的底层其实就是我们上一节分析过的内容,从publisherIndexes这个Map中获取对应clientId集合
java
// 这个map保存的是<Service,Set<clientId>>的对照关系
private final ConcurrentMap<Service, Set<String>> publisherIndexes = new ConcurrentHashMap<>();
private final ConcurrentMap<Service, Set<String>> subscriberIndexes = new ConcurrentHashMap<>();
public Collection<String> getAllClientsRegisteredService(Service service) {
return publisherIndexes.containsKey(service) ? publisherIndexes.get(service) : new ConcurrentHashSet<>();
}接下来的逻辑也很明显了,拿到对应的clientId之后就可以查找client从而获得对应的实例信息(之前有提到过这两者之间的关系),也就是getInstanceInfo的逻辑
java
private Optional<InstancePublishInfo> getInstanceInfo(String clientId, Service service) {
// 通过 clientId 获取每一个对应的 client 连接对象
Client client = clientManager.getClient(clientId);
if (null == client) {
return Optional.empty();
}
// 在 client 对象中,获取实例信息,getInstancePublishInfo的底层就是从publishers这个Map中获取,这个Map中维护了Service和Instance的对照关系
return Optional.ofNullable(client.getInstancePublishInfo(service));
}到这里,我们整个查找的过程差不多接近尾声了,这个通过Service查找到对应的Instance的流程和我们上一节提到的内存表的设计关系是完全一致的
六、绑定订阅关系
查找到有健康保障的实例时候,就需要绑定订阅关系了
java
if (request.isSubscribe()) {
// 添加订阅者,如果被订阅的服务有变动,需要通知订阅者
clientOperationService.subscribeService(service, subscriber, meta.getConnectionId());
} else {
clientOperationService.unsubscribeService(service, subscriber, meta.getConnectionId());
}subscribeService的代码逻辑如下
java
/**
* 订阅者列表
*/
protected final ConcurrentHashMap<Service, Subscriber> subscribers = new ConcurrentHashMap<>(16, 0.75f, 1);
/**
* 添加订阅者
* @param service service 被查询的对象
* @param subscriber subscribe 订阅者 对应请求调用者
* @param clientId id of client 维护请求调用者和Nacos之间的关系
*/
@Override
public void subscribeService(Service service, Subscriber subscriber, String clientId) {
// 被调用者对象/服务对象
Service singleton = ServiceManager.getInstance().getSingletonIfExist(service).orElse(service);
// 订阅者/发其请求者
Client client = clientManager.getClient(clientId);
if (!clientIsLegal(client, clientId)) {
return;
}
// 订阅者/发其请求者 对应的 Client 对象中,添加订阅者订阅者信息
client.addServiceSubscriber(singleton, subscriber);
client.setLastUpdatedTime();
// 发布客户端订阅事件
NotifyCenter.publishEvent(new ClientOperationEvent.ClientSubscribeServiceEvent(singleton, clientId));
}
@Override
public boolean addServiceSubscriber(Service service, Subscriber subscriber) {
// 添加 服务者-订阅者 之间的映射关系内存缓存map
if (null == subscribers.put(service, subscriber)) {
MetricsMonitor.incrementSubscribeCount();
}
return true;
}可以看到如上代码的作用,主要就是发布了通知事件且在 订阅者的client对象中添加了key=服务对象;value=订阅者的缓存内容
这里需要注意一下ConcurrentHashMap<Service, Subscriber> subscribers 他是属于client层面的,也就是每个client中的一份,而不是staic或者说不是全局的
怎么理解呢,就是如果大家先不这么理解,可能会有UU认为就是,这个map是一对一的关系,表示的是服务者-订阅者,那么是不是代表一个服务只能被一个订阅者订阅呢?然后我们来分析这个问题
首先从业务层面而言,这个理解肯定不对,我们有两个客户端clientA和clientB,然后我们有个远端服务ServiceC,A和B进行服务调用的时候肯定都会需要查询服务C,按照默认设置都是订阅模式,那么肯定需要A和B同时都能动态感知ServiceC的变化,也就是需要A和B都订阅C,事实上我们Nacos中自然是能这么使用的。所以从业务角度而言,肯定需要支持被多个订阅者订阅、
然后从代码层面来看,就需要结合我们所说的,这个Map是每个client层面的,也就是说ServiceC-clientB这个属于clientB中的map,ServiceC-clientA这个属于clientA中的map,ServiceC-clientA标识cleintA订阅了ServiceC,如果我们还有别的微服务,A同样需要监听,也就会出现ServiceC1-clientA,ServiceC2-clientA,ServiceC3-clientA...
那么我们所说的,一个ServiceC对于所有的订阅他的client是如何存储的呢?订阅功能的需求而言,肯定会需要统一维护,当出现变更的时候才能快速的进行通知,这个其实就是我们之前的ConcurrentMap<Service, Set<String>> subscriberIndexes这种类型的map,保存的是<Service,Set<clientId>>的对照关系七、ClientSubscribeServiceEvent 事件处理
在上述逻辑的最后呢,发布了ClientSubscribeServiceEvent这个事件,我们来分析一下这个地方,同样的,通过Idea的全局搜索,我们可以找到处理这个事件的地方,其实也是我们一开始进行RPC注册时候处理注册事件的地方,我们先来稍微的看一下
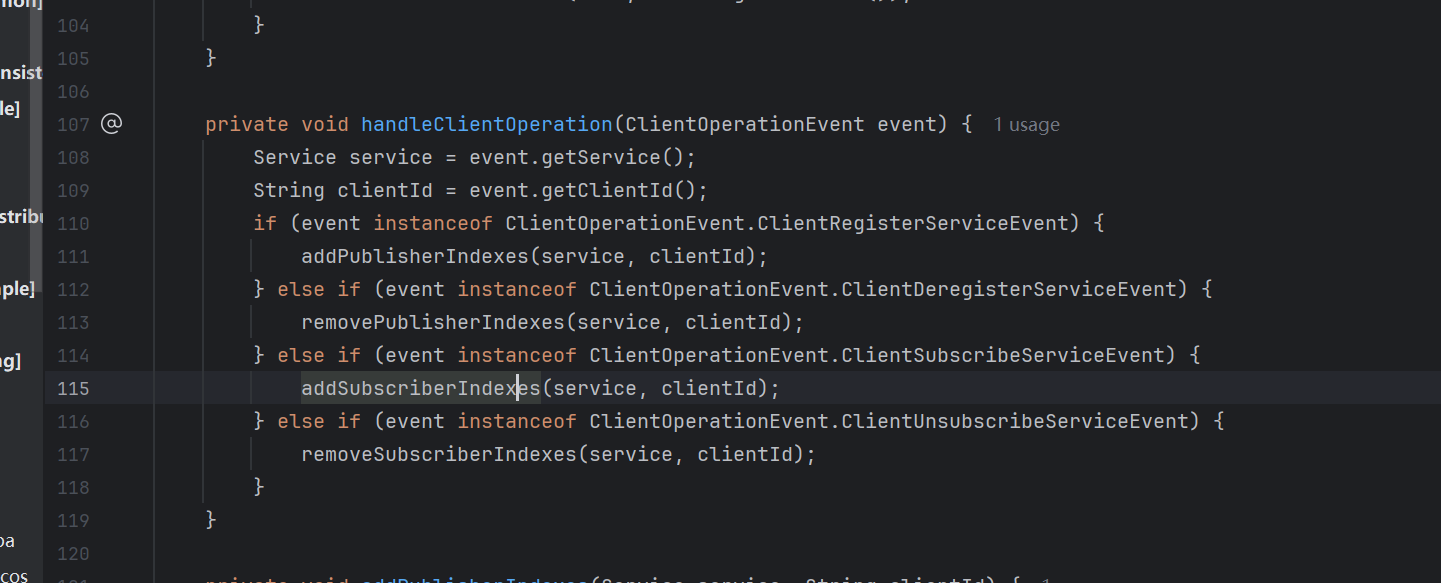
addSubscriberIndexes具体逻辑如下 ,如果是第一次订阅的客户端,会发布ServiceSubscribedEvent服务订阅事件
java
private void addSubscriberIndexes(Service service, String clientId) {
subscriberIndexes.computeIfAbsent(service, (key) -> new ConcurrentHashSet<>());
// Fix #5404,只有第一次放入的时候需要通知
if (subscriberIndexes.get(service).add(clientId)) {
// 发布订阅事件
NotifyCenter.publishEvent(new ServiceEvent.ServiceSubscribedEvent(service, clientId));
}
}同样的,利用Idea的全局查找功能,可以很方便地找到对应的事件处理逻辑
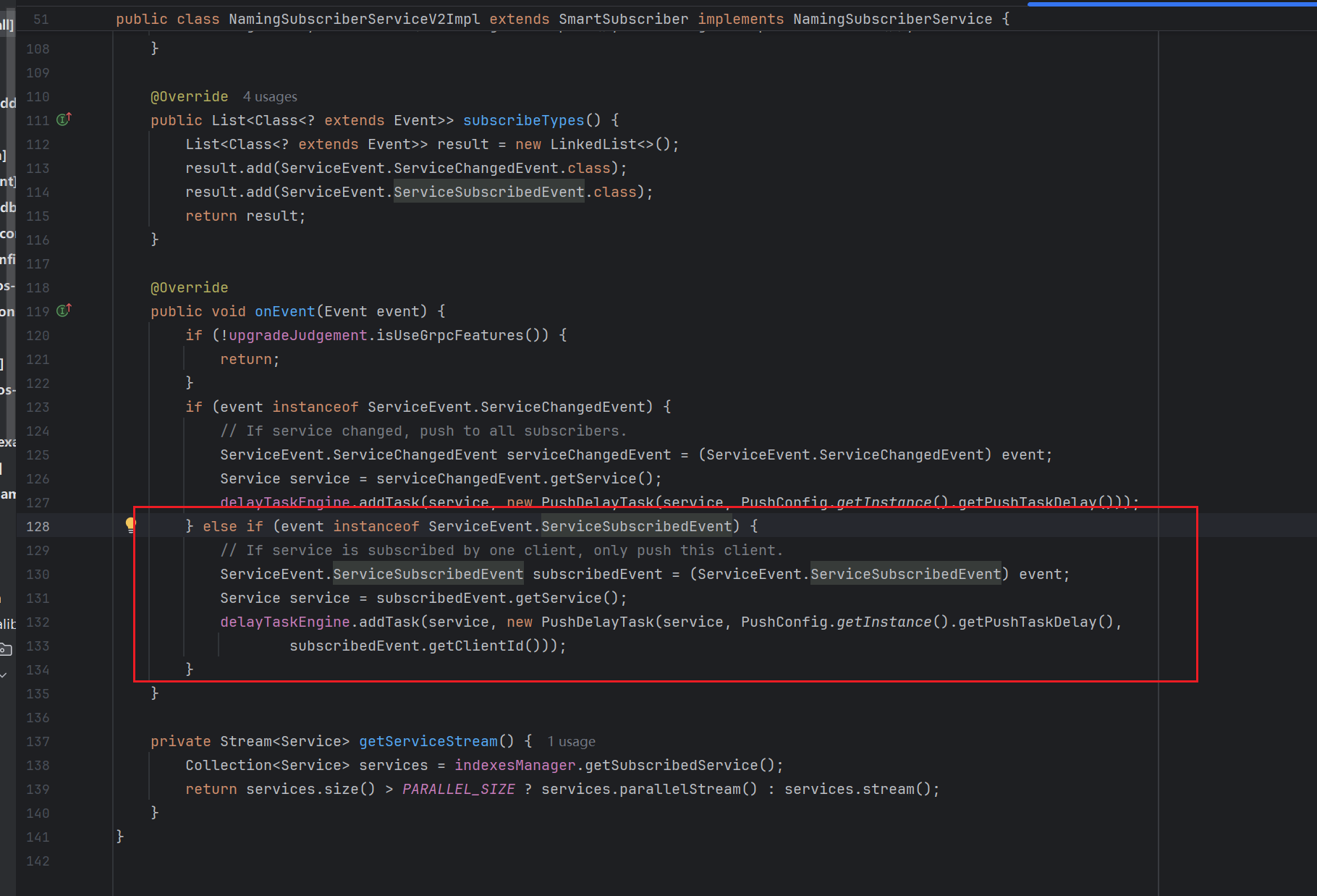
可以看到,代码中将由service, clientId封装成的ServiceSubscribedEvent对象再次封装为了PushDelayTask对象,且调用delayTaskEngine.addTask()方法将其加入到任务队列中
java
@Override
public void addTask(Object key, AbstractDelayTask newTask) {
lock.lock();
try {
AbstractDelayTask existTask = tasks.get(key);
if (null != existTask) {
// merge是任务合并,因为任务队列中可能还会有该key下的其他任务,需要将new和old进行合并处理提高效率
// 但是任务类型(meger方法是AbstractDelayTask接口下的,不同的实现类其逻辑不同)的不同,所以有的稍微复杂一点,有的只是简单的将clientId合并
newTask.merge(existTask);
}
tasks.put(key, newTask);
} finally {
lock.unlock();
}
}八、总结与展望
Nacos2.x 内存注册表作为服务发现的核心数据结构,通过多级索引和高效查询机制,为微服务架构提供了强大的服务发现能力。从服务调用链路的角度来看,客户端通过订阅模式与服务端进行高效交互,而服务端则通过内存注册表快速响应查询请求。
内存注册表的设计充分考虑了性能和扩展性,采用了ConcurrentHashMap等高效数据结构,同时通过事件驱动架构实现了实时数据同步。未来,随着微服务架构的不断发展,Nacos2.x 内存注册表有望在更多场景中发挥重要作用,支持更复杂的服务发现需求。
SEO标题:Nacos2.x 内存注册表:从服务调用链路深入理解
元描述:深入解析Nacos2.x内存注册表的设计原理、实现机制和服务调用链路。掌握客户端查询逻辑、服务端处理流程和订阅模式实现,提升微服务架构的服务发现效率。