现有的多模态文档解析模型在对ocr(公式、表格)等进行格式化解码时,解码不是特别稳定,如下图:
基于视觉语言模型(VLM)的端到端方法虽简化流程,但在处理公式、表格等格式化文本时,输出熵值(不确定性)远高于纯文本(常相差一个数量级)。
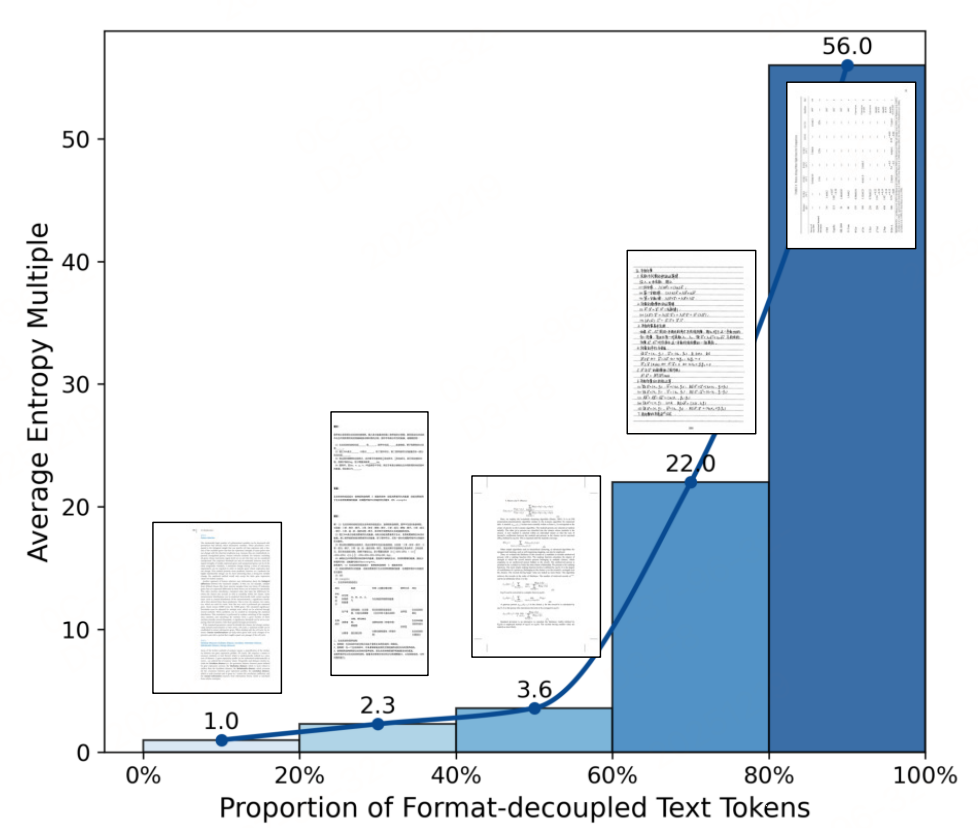
格式化文本的高熵特性源于其存在多种语义等价的表达形式(如1/2与\frac{1}{2}),这些高熵样本可引导模型探索多样化推理路径,为强化学习(RL)提供有效反馈。,因此,提出了格式解耦强化学习(FD-RL) 方法,核心是通过"感知后推理"的两阶段训练范式,实现格式化内容的精准识别。
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
- 再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法
- 如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法
- 端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法
...
方法:FD-RL
采用SFT-then-RL两阶段训练范式,搭配定制化数据工程,核心围绕"筛选高价值样本"和"反馈格式有效性"展开。
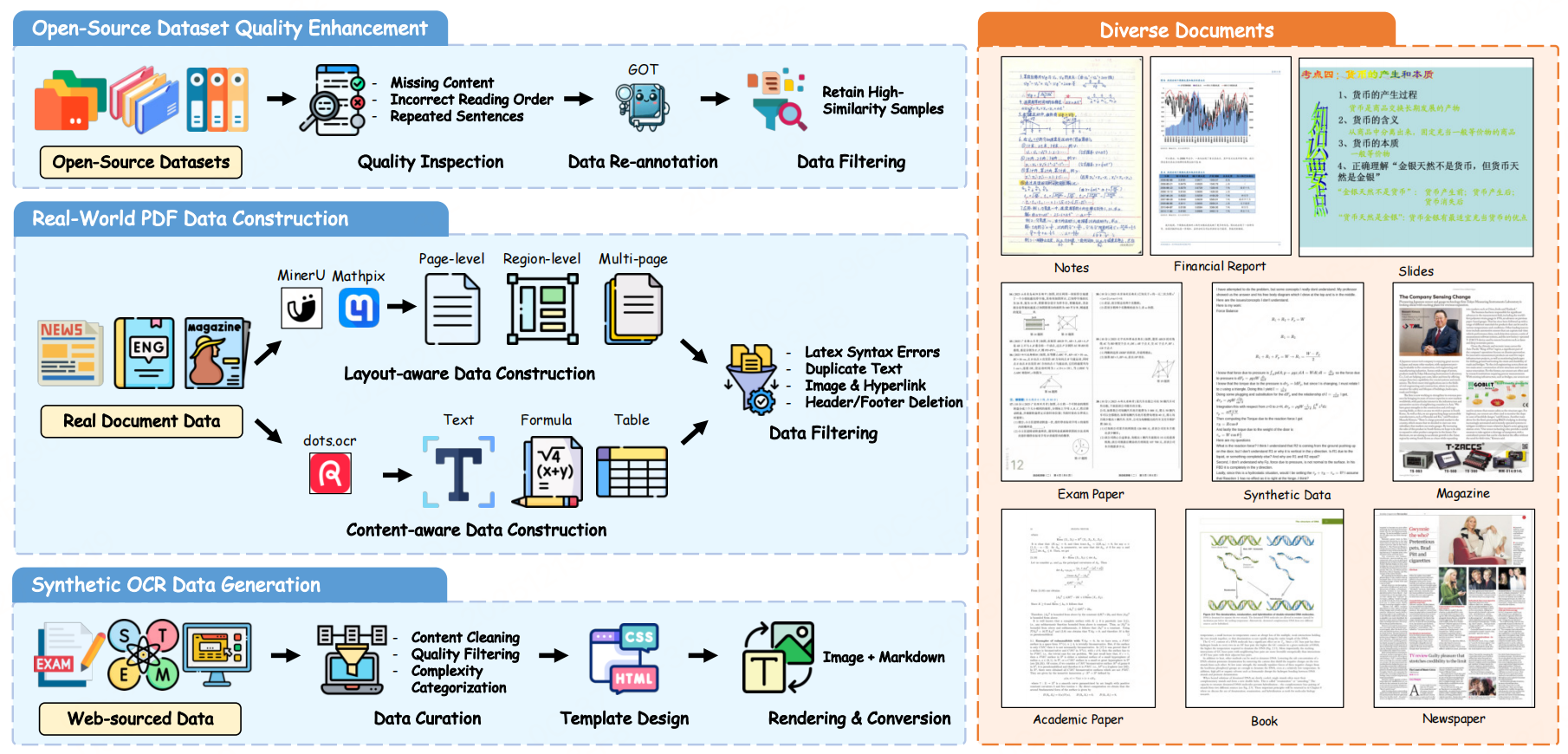
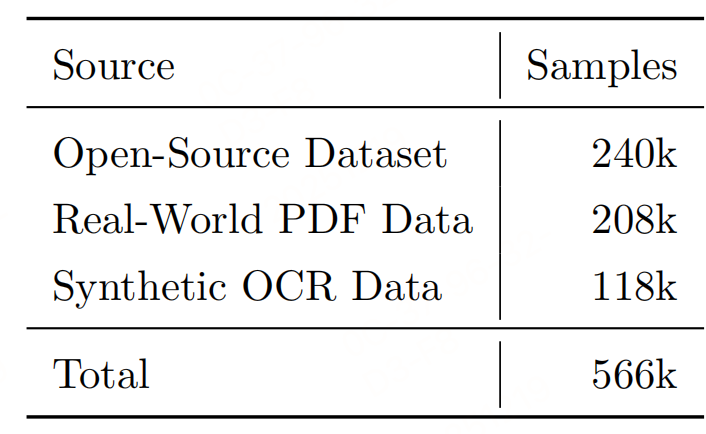
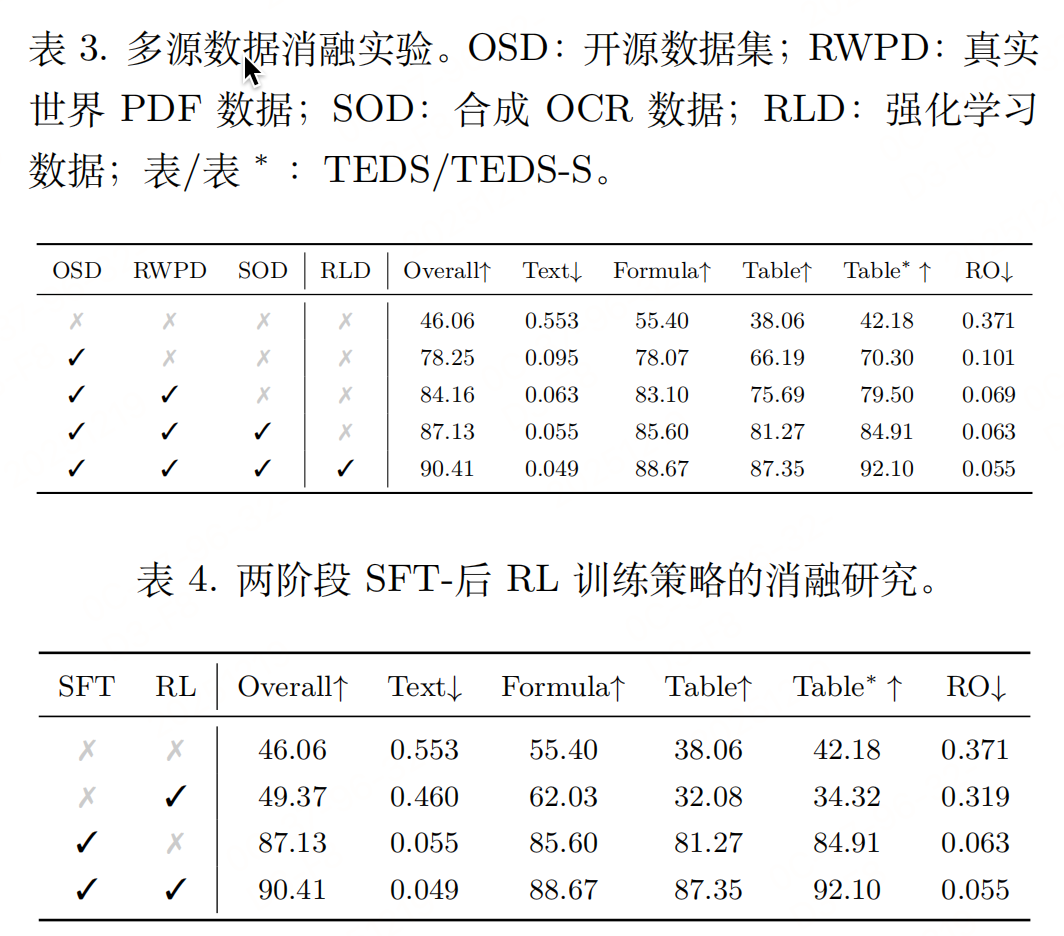
1. 多源数据工程(构建566k样本训练集)
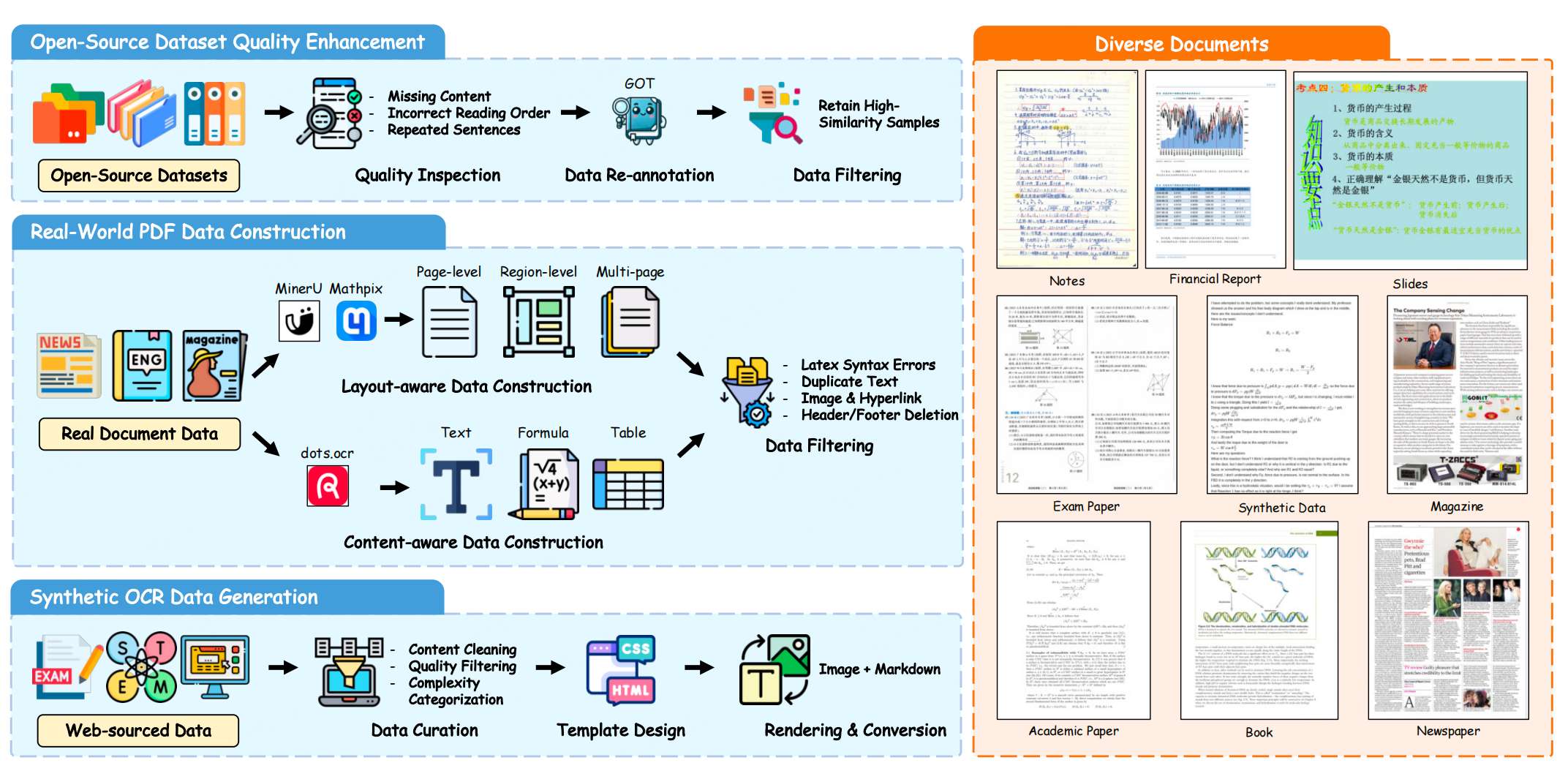
为覆盖多样化文档场景,整合三类数据并优化质量:
- 开源数据集(240k样本):清洗标注错误(缺失内容、阅读顺序错误),保留高相似度样本;
- 真实PDF数据(208k样本):分"布局感知"(页面/区域/多页粒度)和"内容感知"构建,去除页眉页脚、重复文本等干扰;
- 合成OCR数据(118k样本):生成教育场景(K12到STEM)的公式、表格样本,弥补真实数据稀缺性。
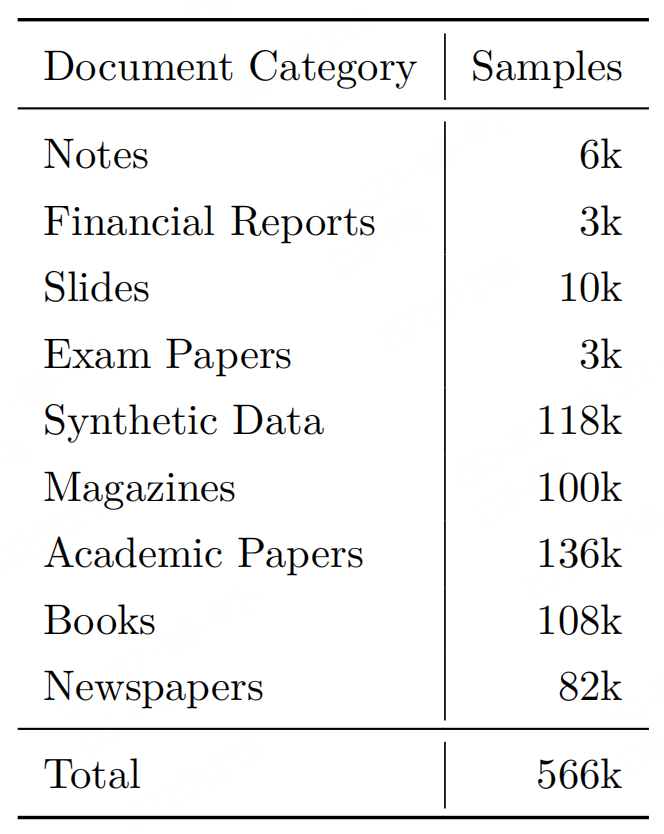
- 覆盖9类文档:学术论文、书籍、报纸、杂志、试卷、幻灯片等,确保泛化性。
2. 两阶段训练pipline
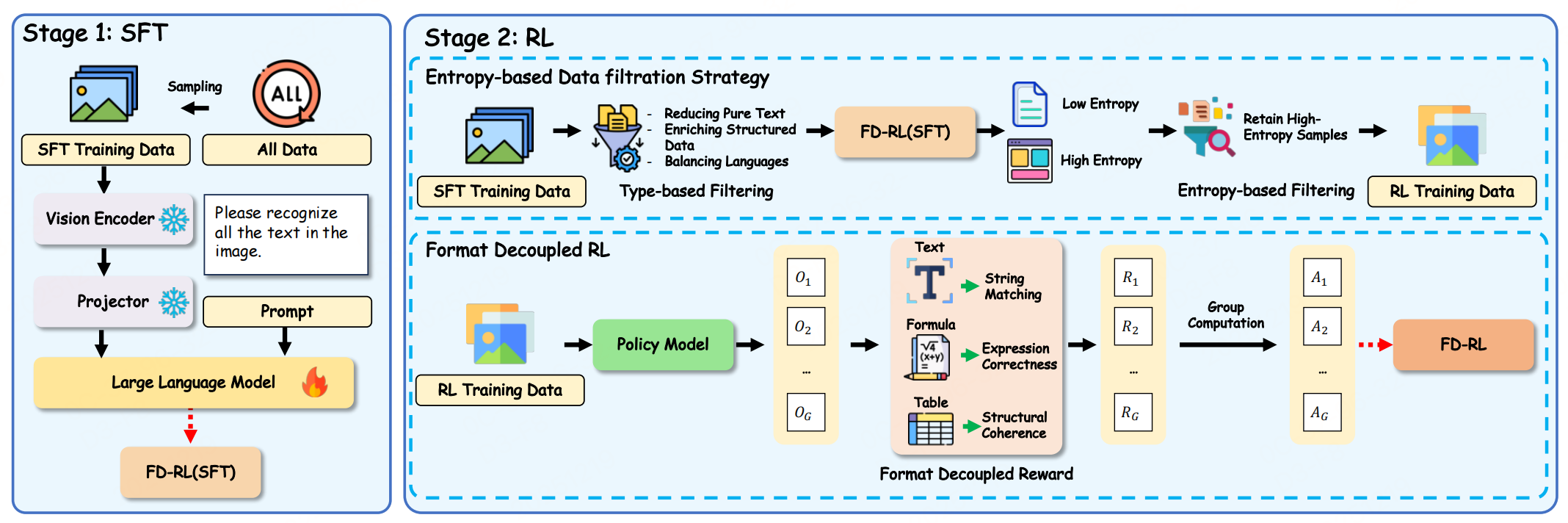
第一阶段:SFT
基于Qwen3-VL-4B,冻结视觉编码器和投影层,仅微调大语言模型(LLM)参数,学习基础OCR能力(文本识别、基础格式感知),为后续RL提供强基线。
数据情况:
第二阶段:基于GRPO算法格式解耦强化学习
针对格式化文本设计两大模块:
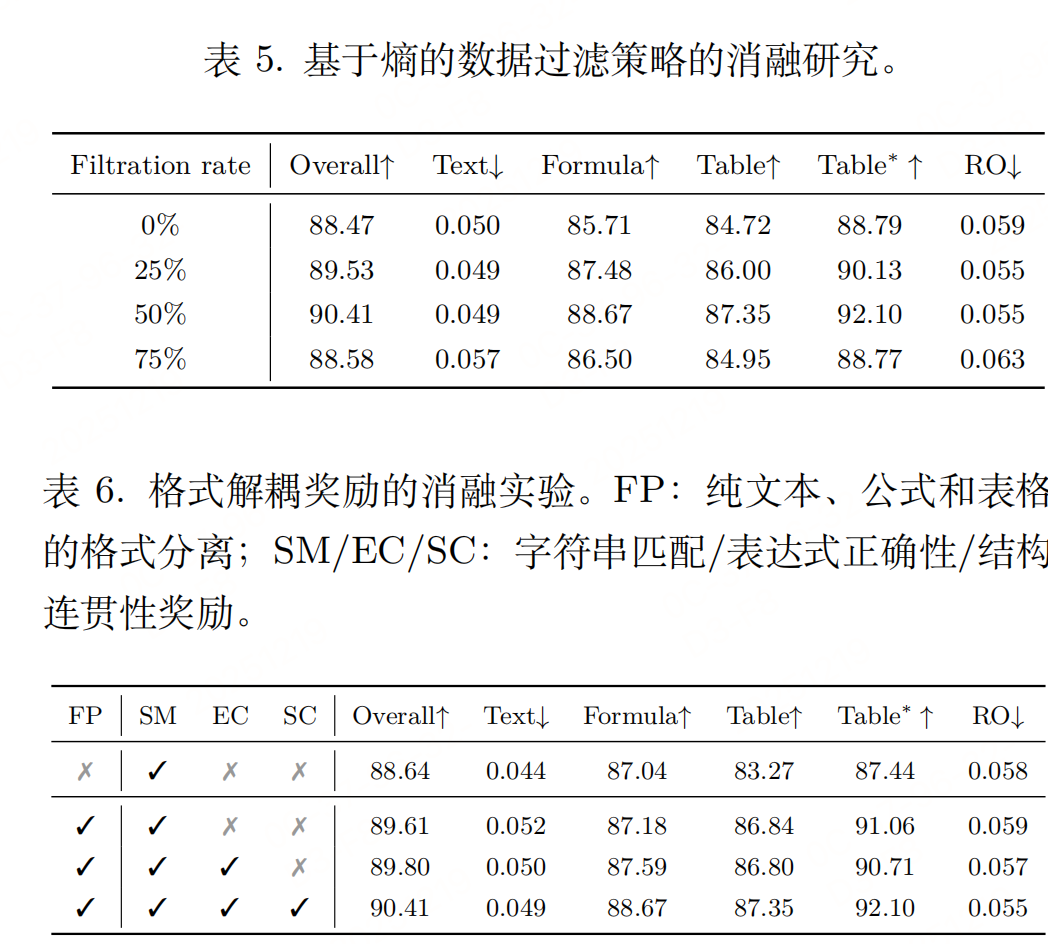
- 基于熵的数据过滤:用SFT模型推理候选样本,计算token平均熵,筛选top 50%高熵样本(格式化密集型数据)作为RL训练集;
- 格式解耦奖励函数 :将模型输出按"纯文本、公式、表格"分离,针对性设计奖励:
- 纯文本:归一化编辑距离(字符级匹配);
- 公式:转换为LaTeX后用BLEU分数(表达式正确性);
- 表格:TEDS分数(结构一致性);
- 整体奖励:加权融合非空格式的专项奖励,避免格式错误被内容错误掩盖。
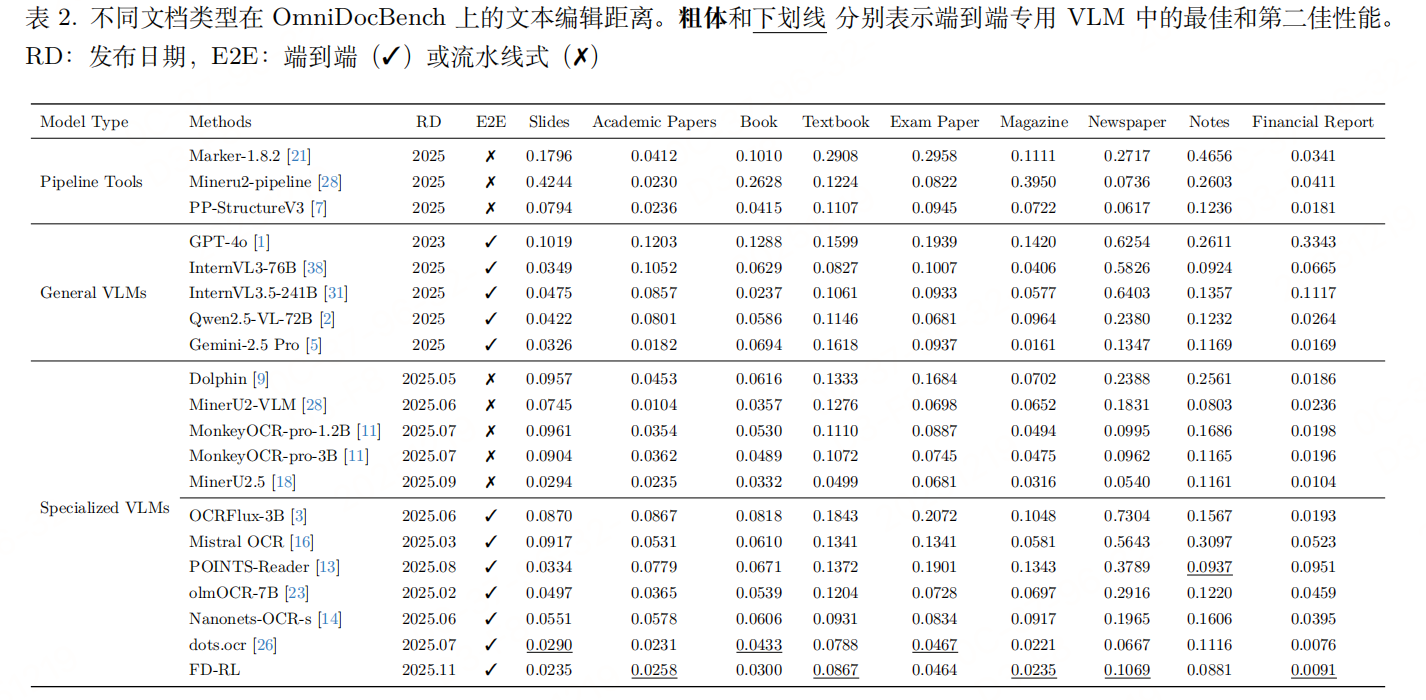
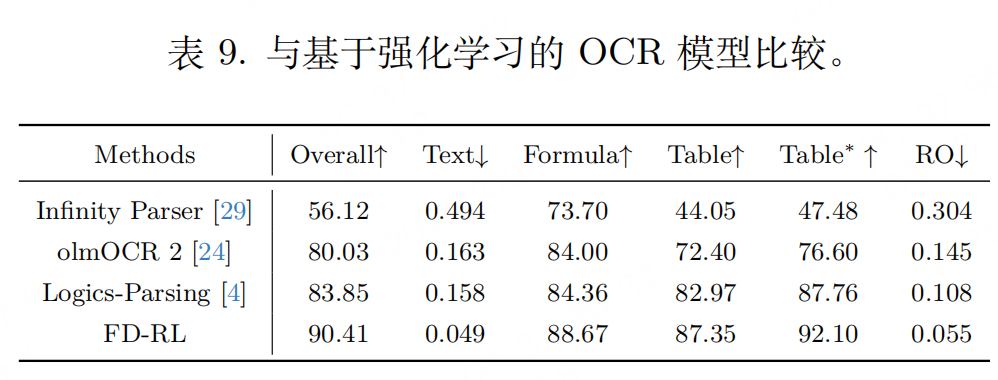
实验性能
评价指标
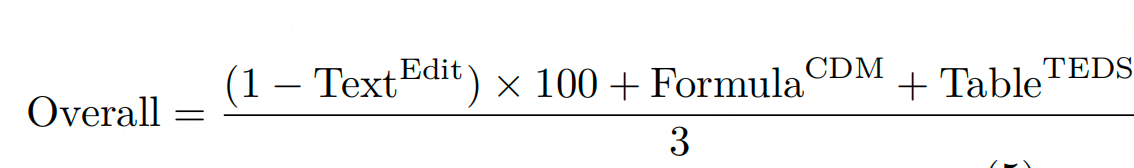
参考文献
- https://github.com/DocTron-hub/FD-RL
- Reading or Reasoning? Format Decoupled Reinforcement Learning for Document OCR,https://arxiv.org/pdf/2601.08834