多模态OCR赛道依旧卷,继续看一下新的多模态文档解析模型-LightOnOCR-2-1B系列,按照之前的划分(文档智能解析方案总结进展更新(含ocr-pipline、layout+VLM+纯多模态端到端解析)),这是一个端到端的模型,这个模型开源了其两个用于训练的开放标注数据集:lightonai/LightOnOCR-mix-0126一个包含超过 1600w标注的文档页面,另一个lightonai/LightOnOCR-bbox-mix-0126包含近50w标注,包括图形和图像的边界框。
- https://huggingface.co/datasets/lightonai/LightOnOCR-mix-0126
- https://huggingface.co/datasets/lightonai/LightOnOCR-bbox-mix-0126
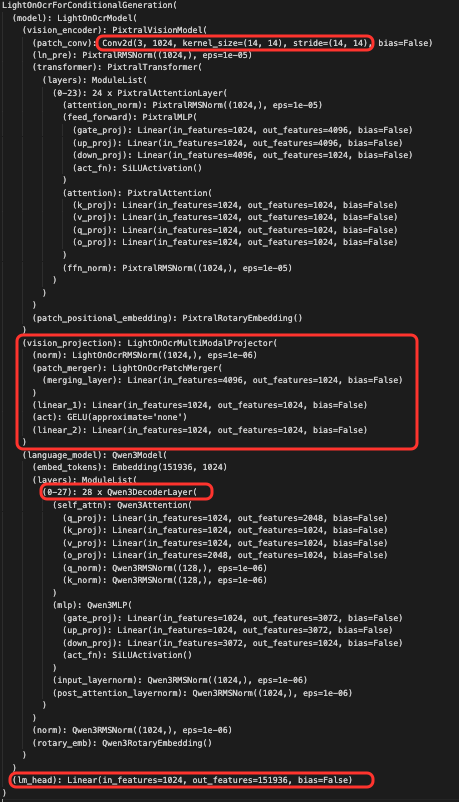
模型架构
如下图,模型结构和qwenvl一致,vit+patch_merger+LLM(qwen3-0.6B)组装。
case测试
https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo
简单测两个case,问题依旧表现在:
-
端到端到解析能力(ocr):表格单元格对齐、合并等问题,文字大面积重复问题
-
端到端到解析能力(ocr+定位):定位不准,幻觉等问题。
-
case1:
结果:

- case2:
结果:
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
- 再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法
- 如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法
- 端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法
- 多模态文档解析模型新进展:腾讯开源HunyuanOCR-1B模型架构、训练配方
- 强化学习GRPO(格式奖励)在多模态文档解析中的运用方法
...