文章目录
- 1.发展历程
-
- 1.1词袋法
- [1.2 TF-IDF](#1.2 TF-IDF)
- [1.3 wrod2vec](#1.3 wrod2vec)
-
- [1.3.1 对不理解的地方详细的解释:](#1.3.1 对不理解的地方详细的解释:)
- [1.4 BGE模型](#1.4 BGE模型)
- [第一阶段:预训练 ------ 训练通用语义能力(90% 的工作量)](#第一阶段:预训练 —— 训练通用语义能力(90% 的工作量))
-
- [步骤 1:海量语料采集 ------ 收集 "训练原材料"](#步骤 1:海量语料采集 —— 收集 “训练原材料”)
- [步骤 2:语料清洗与预处理 ------ 筛选 "优质原材料"](#步骤 2:语料清洗与预处理 —— 筛选 “优质原材料”)
- [步骤 3:构造训练样本 ------ 制作 "训练题库"(锚句子 + 正样本 + 负样本)](#步骤 3:构造训练样本 —— 制作 “训练题库”(锚句子 + 正样本 + 负样本))
- [步骤 4:模型初始化 ------ 准备 "训练的基础模型"](#步骤 4:模型初始化 —— 准备 “训练的基础模型”)
- [步骤 5:配置训练参数 ------ 设定 "训练规则"](#步骤 5:配置训练参数 —— 设定 “训练规则”)
- [步骤 6:对比学习训练 ------ 模型 "正式学习"](#步骤 6:对比学习训练 —— 模型 “正式学习”)
- [步骤 7:预训练模型保存 ------ 得到 "通用版 BGE 模型"](#步骤 7:预训练模型保存 —— 得到 “通用版 BGE 模型”)
- [第二阶段:微调 ------ 训练专项语义能力(10% 的工作量,效果提升关键)](#第二阶段:微调 —— 训练专项语义能力(10% 的工作量,效果提升关键))
-
- [步骤 1:领域数据准备 ------ 收集 "专业作战手册"](#步骤 1:领域数据准备 —— 收集 “专业作战手册”)
- [步骤 2:人工标注训练样本 ------ 制作 "专业题库"](#步骤 2:人工标注训练样本 —— 制作 “专业题库”)
- [步骤 3:微调训练 ------ 模型 "学专业技能"](#步骤 3:微调训练 —— 模型 “学专业技能”)
- [步骤 4:模型评估 ------ 检验 "专业技能水平"](#步骤 4:模型评估 —— 检验 “专业技能水平”)
- [步骤 5:最终模型导出 ------ 得到 "可用的 BGE 模型"](#步骤 5:最终模型导出 —— 得到 “可用的 BGE 模型”)
- [第三阶段:模型部署与使用 ------ 让模型 "上岗干活"](#第三阶段:模型部署与使用 —— 让模型 “上岗干活”)
- [BGE 完整训练流程总结表](#BGE 完整训练流程总结表)
1.发展历程

1.1词袋法
通过词语进行拆分,并进行向量化
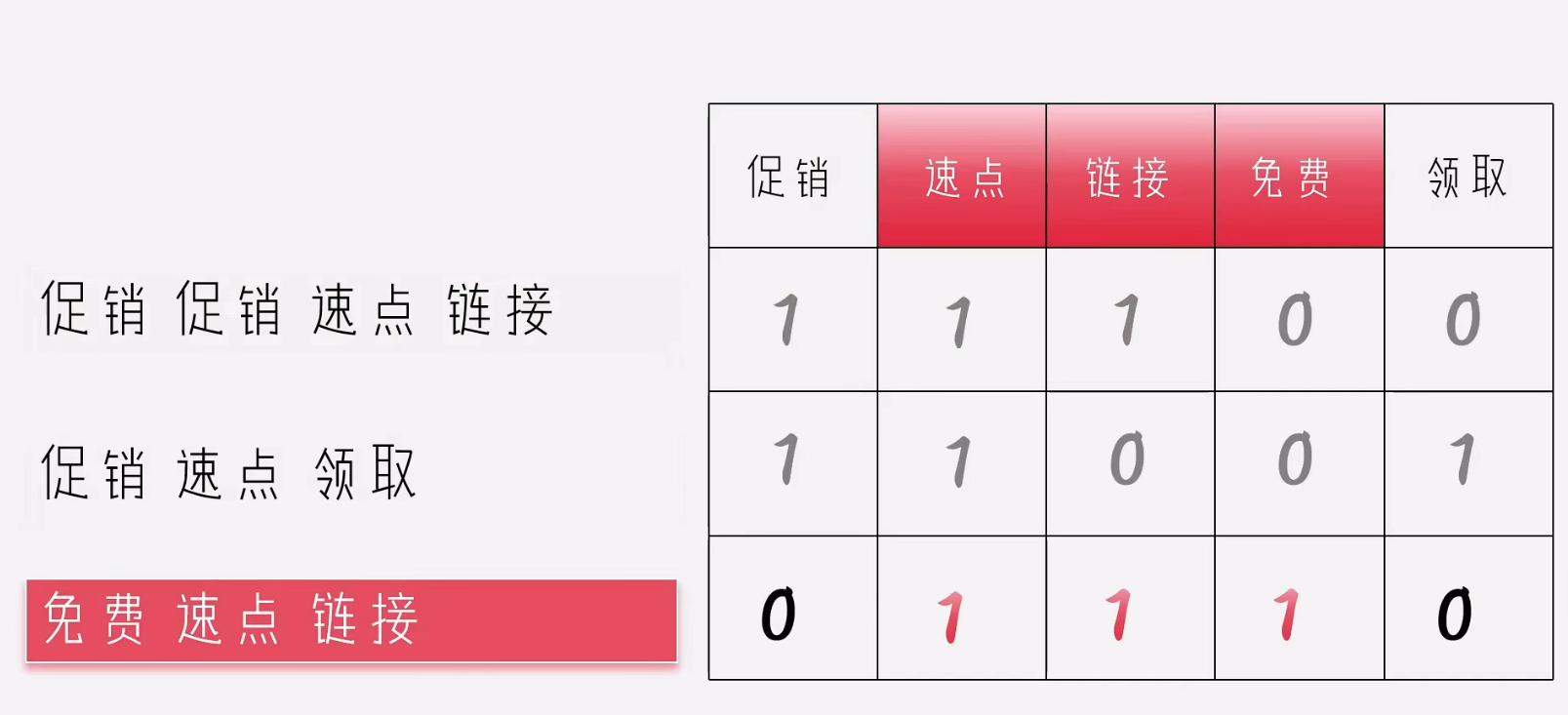

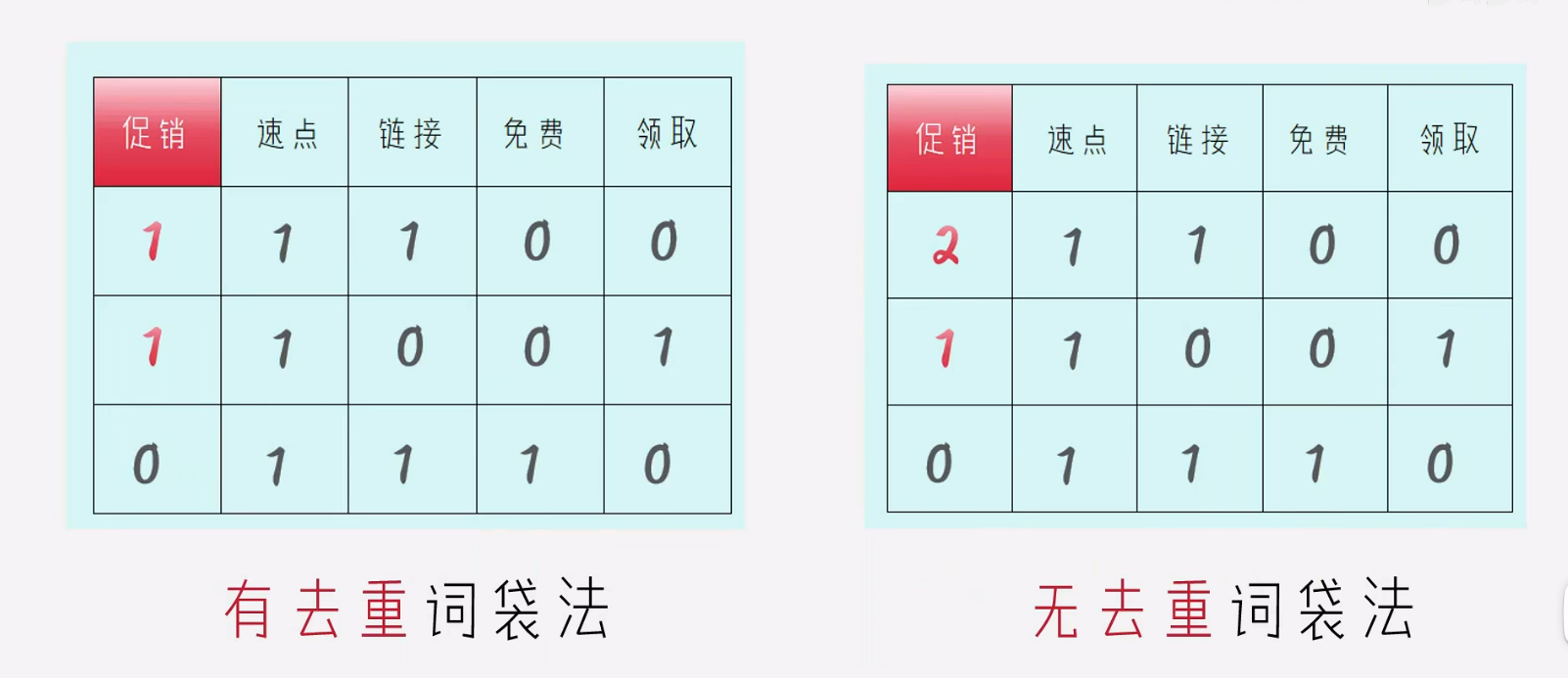
由于一个词语,多次出现所代表的含义可能就不同,所含的信息量也不同,所以出现,【词频】:
1.2 TF-IDF
但是此时又出现一个新的问题:有些词语的出现量很多,但是没有很大的意义,因此稀有度也很重要,可能就因为一个稀有的词语改变了一句话的含义。


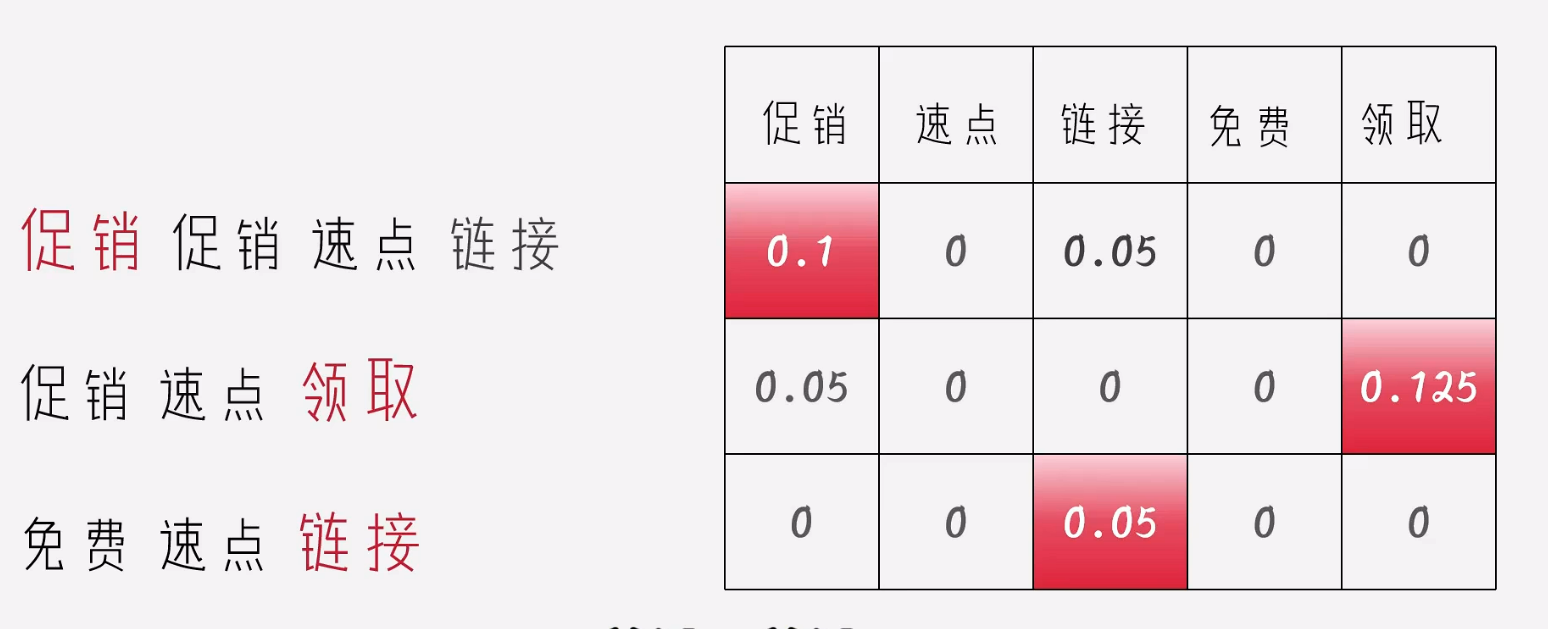
所以此时也要考虑文档的长度,通过文档长度和词语出现次数,总文档数和某个词语的数量,得出如下方式,稀有加log 是数学中常见的将曲线变的平滑,不至于因为异常的数据,导致很大的波动。
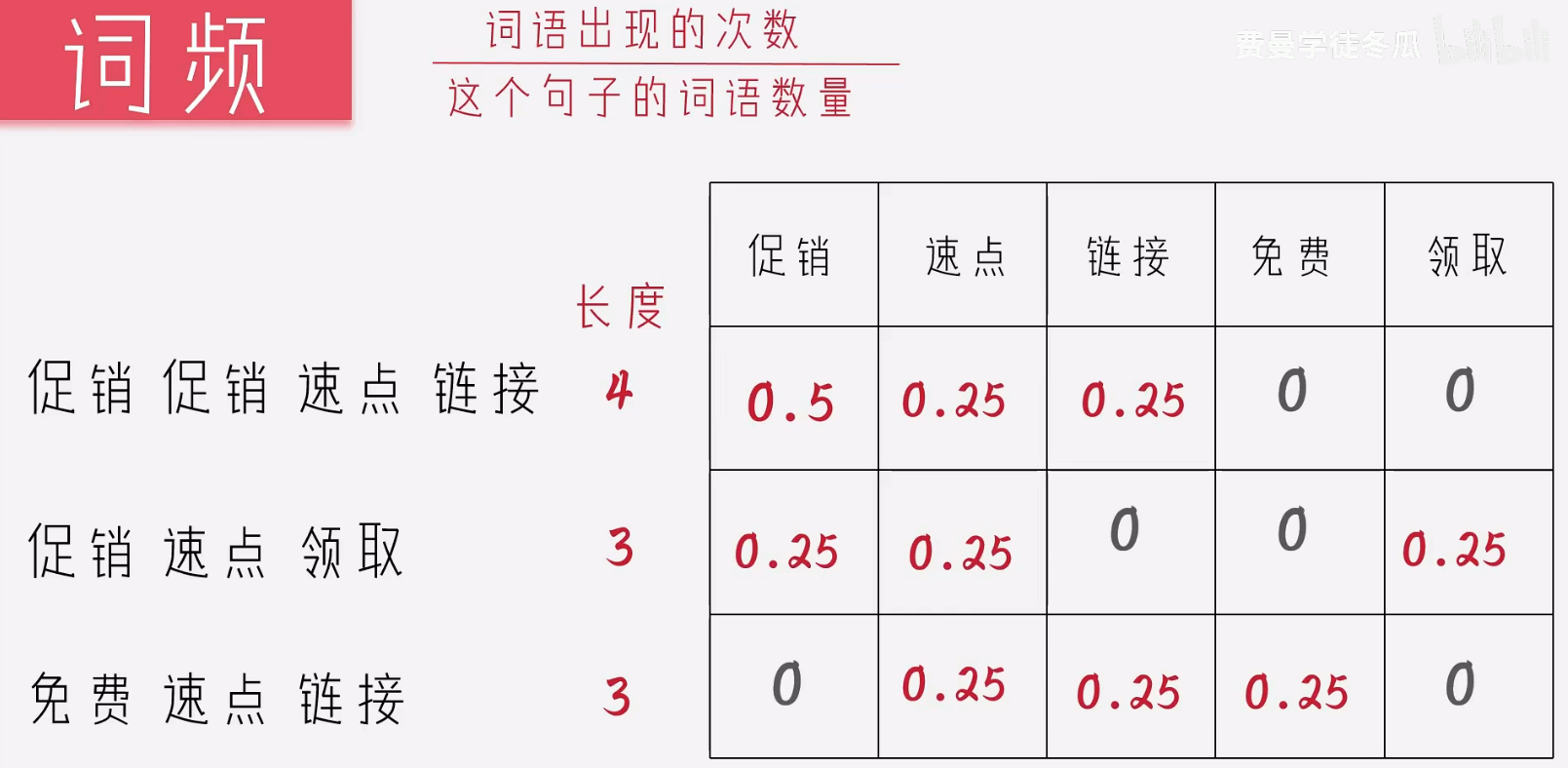
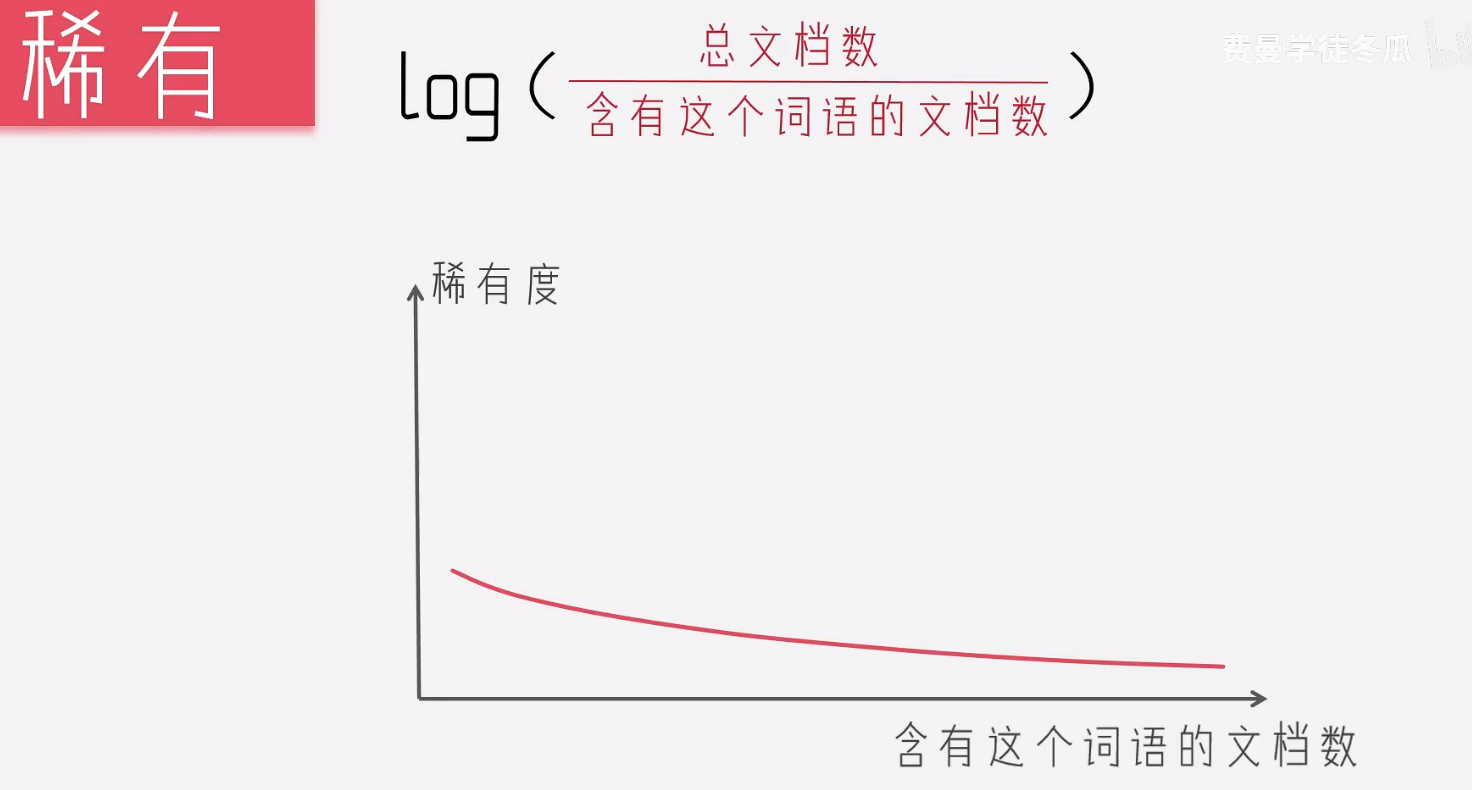
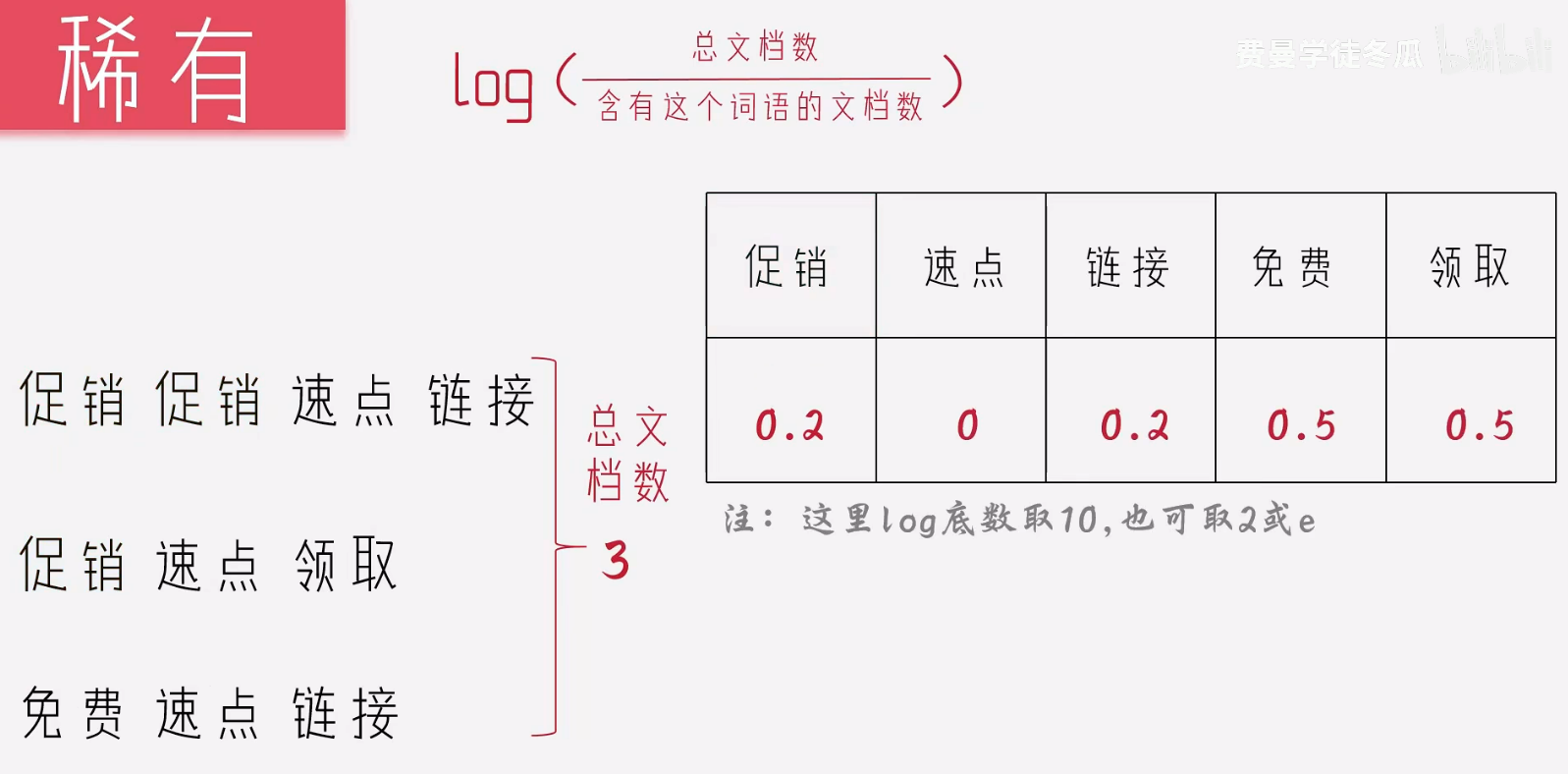
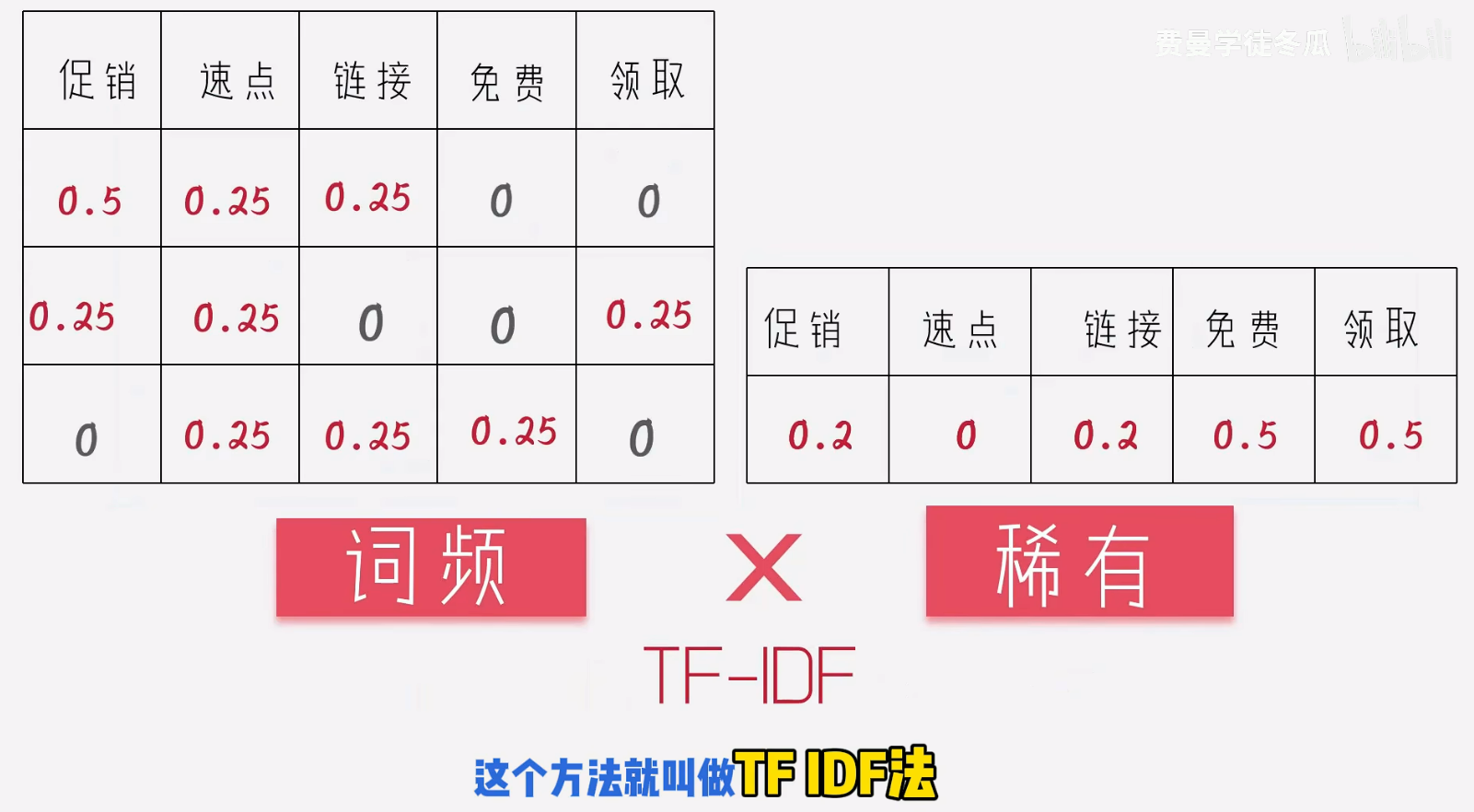
此时,数字越小的表示当前的词语就更加稀有。
1.3 wrod2vec
经过上面的迭代,以及逐渐完善,但是前面只是对词语进行的处理,而一个句子中不止只有词语,还存在语义。Word2Vec 的底层逻辑特别简单:一个单词的含义,由它周围的单词决定。例如:
- 这个电影很好。
- 这个电影很棒。
我们来看表达的应该是同一个意思,但是通过词语维度分析,这两句话关联不大。
此时出现谷歌推出word2vec方法:
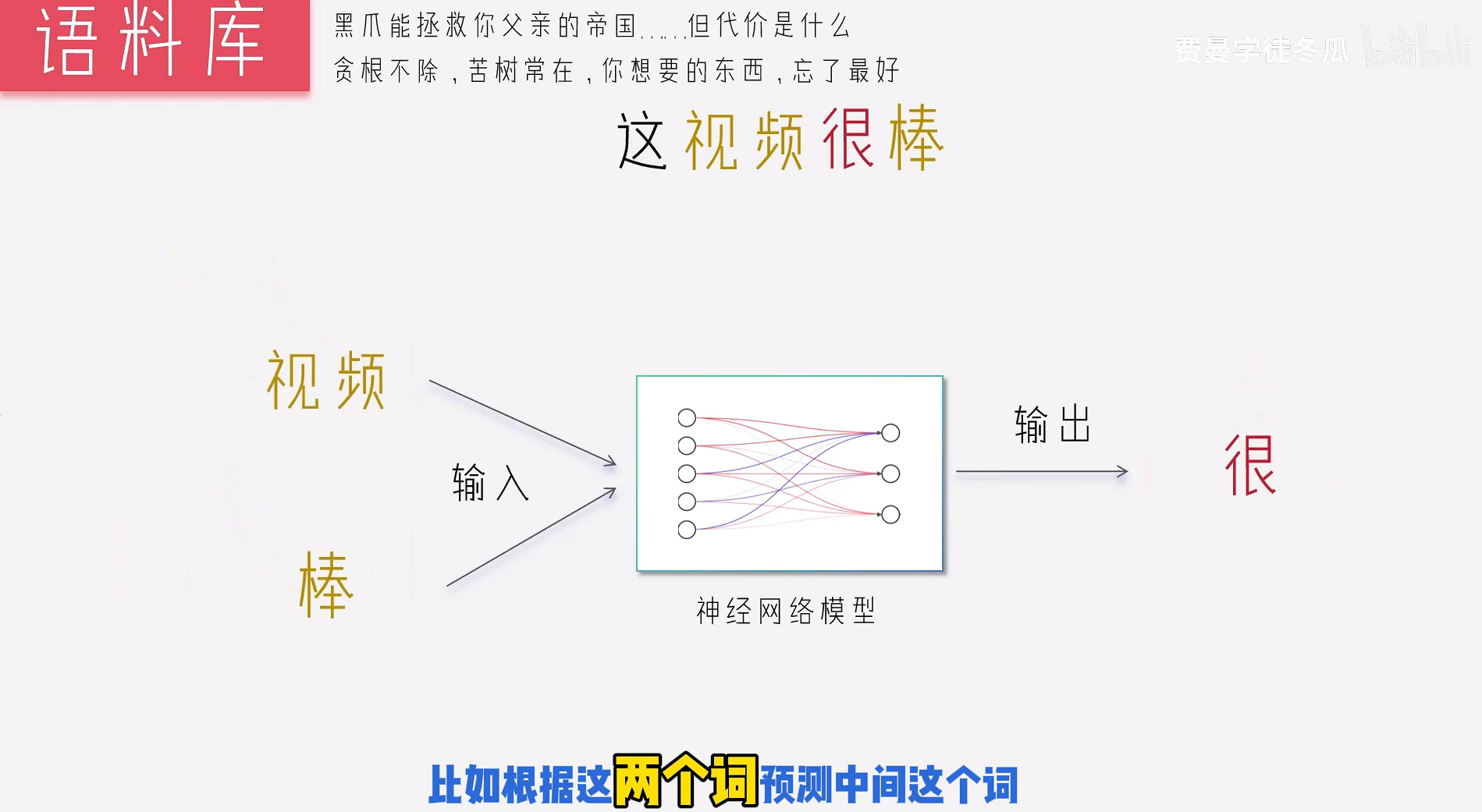
解释下面的含义:
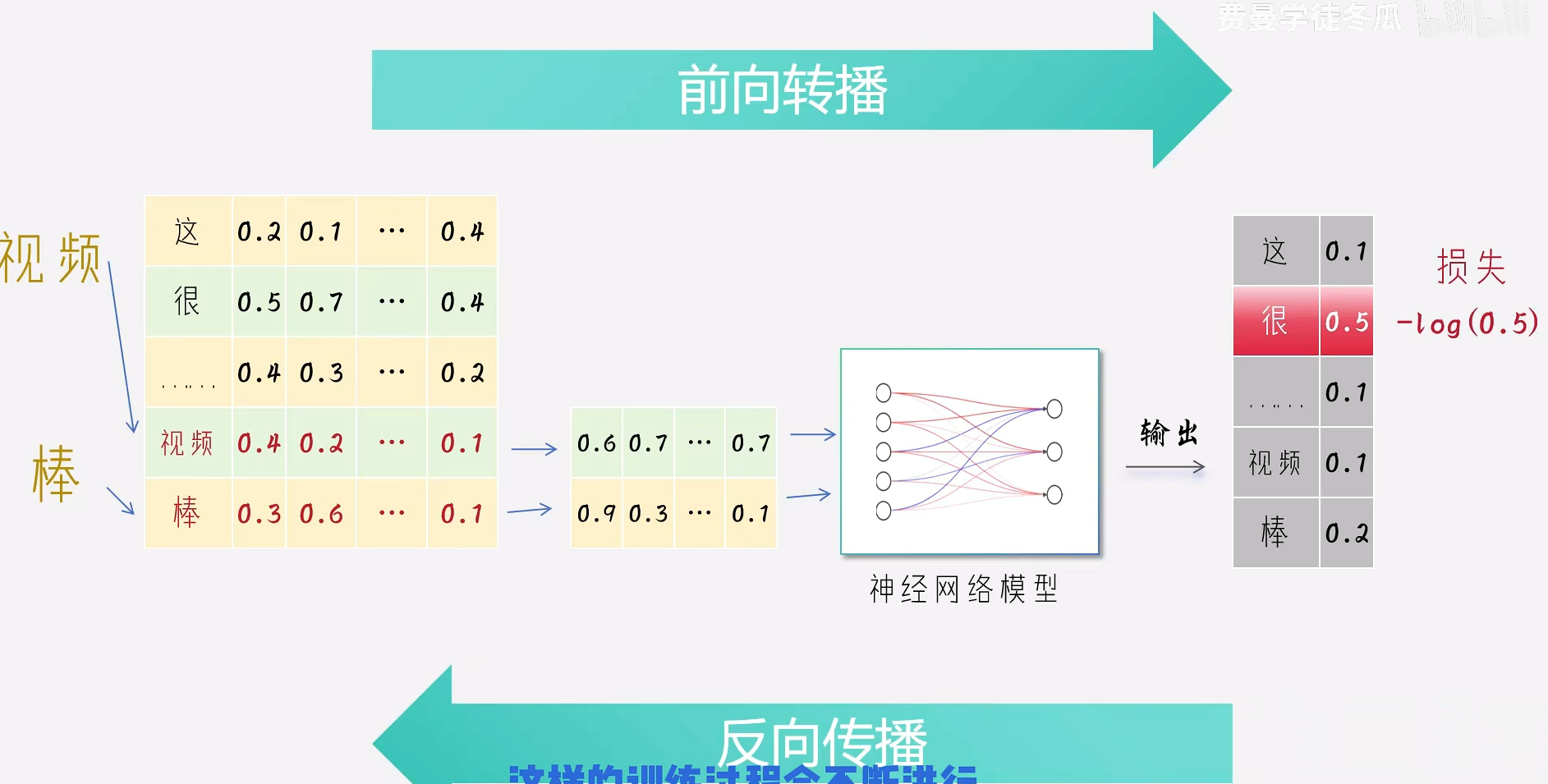

1.3.1 对不理解的地方详细的解释:
方法:通过询问豆包ai,使用询问方法:
- 我是一个纯小白,现在想要理解,word2vec模型是如何训练的,以及如何对我随机给的一句话进行处理的。详细进行说明,给出通俗易懂的例子。
- 步骤三中预处理的句子是什么。
- 步骤四中,训练迭代,如何让模型知道他训练的是对的,我如何对比正确答案的。
经过上面的步骤,现在终于理解了,如何实现的句子理解。
用自己的话讲解 :本质就是通过每个词语的上下文,来预测出现其他词语的概率,例如,我们自己知道一些正常的句子,我想吃苹果,我想吃香蕉,我想吃梨子...,我要走路,我要跑步,我要运动等等,这些句子都是我们可以理解的,但是机器不能理解,但是我们想要它能理解其中的简单意思,我们就要使用大量的如上的句子进行训练,通过不断尝试训练的题目,让其不断的调整整个语料表的向量位置,最后达到一个稳定(就是知道了例如吃后面可以跟苹果,香蕉等,苹果和香蕉的向量距离就会相对很近比苹果和跑步之间,此时苹果和香蕉的伪语义也就比较近),此时就可以让其实现对句子的扩写,以及为更加复杂的模型提供支持。
要使用的基础神经网络模型:
- CBOW(用上下文猜中心词)
- Skip-gram(用中心词猜上下文)
训练过程:
-
步骤一:数据预处理。
在训练前,要先把原始文本变成模型能看懂的格式: 1. 分词:把句子拆成独立单词。比如 "我爱吃苹果"→ `[我, 爱, 吃, 苹果]`(英文不用分词,空格分开就行)。 2. 去停用词:去掉没实际意义的词,比如 "的、得、地、啊"(这些词出现频率高,但对语义没帮助)。 3. 构建词汇表:把所有出现过的单词列出来,给每个单词分配一个**唯一 ID**。比如 `我=0,爱=1,吃=2,苹果=3`。 4. 低频词过滤:去掉只出现过 1-2 次的词(比如生僻字),减少计算量。 -
步骤二:初始化词向量
模型一开始不知道任何单词的语义,所以我们给每个单词随机分配一个固定长度的数字列表,这个列表就是初始词向量。 1.比如向量长度设为 100,"苹果" 的初始向量可能是 [0.12, 0.34, -0.56, ..., 0.78](共 100 个随机数)。 2.这个阶段的向量是 "瞎猜" 的,没有任何语义意义。 ---------------------------------------------------------------------------------- 维度的大小,决定了「词向量能装下多少语义信息」,但是维度的选择并不是越大越好。 - 维度 原则 1:「词汇表越大,维度就要越大」(最核心原则) 词汇表:就是你预处理后,所有不重复的单词总数(比如你的文本里有「苹果、香蕉、汽车、跑步」等,去重后一共多少个)。 情况 1:词汇表小(≤1000 个词,比如只训练一篇短文、几百句话)→ 选 50~100 维 足够; 比如:你只训练「我爱吃苹果、香蕉、橙子」这类简单句子,词汇表只有 20 个词,选 50 维就够用,100 维也可以,效果差不多; 情况 2:词汇表中等(1000~10000 个词,比如训练一本小说、几千条日常对话)→ 选 100~200 维; 情况 3:词汇表大(≥10000 个词,比如训练新闻、百科、几十万条文本)→ 选 200~300 维; 极限情况:词汇表超大(≥10 万词,专业 NLP 项目)→ 最多选 300~500 维 就够了。 -
步骤三:滑动窗口采样,(就是生成训练题目)
我们用设定好的窗口大小,在所有预处理后的句子上滑动采样,生成大量 "上下文 - 中心词" 对,作为模型的训练题。 1.比如句子 [我, 爱, 吃, 苹果, 很甜],窗口 = 2: - 中心词 = 吃 → 上下文 =[我,爱,苹果,很甜] - 中心词 = 苹果 → 上下文 =[爱,吃,很甜] - ... 2.句子 [我, 爱, 吃, 香蕉],窗口 = 2: - 中心词 = 吃 → 上下文 =[我,爱,香蕉] - 中心词 = 香蕉 → 上下文 =[爱,吃] - ... 3.句子 [我,特别, 喜欢, 跑步],窗口 = 2: - 中心词 = 喜欢 → 上下文 =[我,特别,跑步] - 中心词 = 跑步 → 上下文 =[特别, 喜欢] - ... 我们提供的语料库会很大,最终会生成几十万、几百万道这样的 "题目",供模型反复练习。 -
步骤 4:训练迭代(让模型 "刷题",修正向量)
先进行前置的解释: 步骤二中我们会对语料库中的所有分词后的词语进行一个初始化向量(暂定100维) 例如: [我, 爱, 吃, 苹果, 很甜] 我:[0.1, 0.3, 0.2, .....] 爱:[0.5, 0.4, 0.9, .....] 吃:[0.3, 0.6, 0.7, .....] ... 此时的向量是完全随机的。 例如: 当模型拿到一道练习题(比如 CBOW:给上下文[爱,吃],猜中心词),它会: 1. 先取出「爱」和「吃」的当前词向量(初始是随机的,训练中是慢慢修正后的); 2. 把这两个向量做一个简单的「合并」(比如加起来取平均),得到一个「上下文总向量」; 3. 用这个总向量,去「匹配」词汇表里所有单词的向量,给每一个单词打一个「匹配分」; 4. 得分最高的那个单词,就是模型「猜出来的答案」。 比如模型猜出来的答案是 香蕉,那这个就是模型的「预测结果」。 - 补充:Skip-gram 的猜法逻辑一样,只是反过来 ------ 先取中心词的向量,再匹配所有单词的向量打分,得分最高的几个单词,就是模型猜的 "上下文邻居"。
第三步:最核心的问题解答!怎么「对比正确答案」?模型怎么知道「自己对还是错」?
层次 1:【简单对错判断】------ 最直观的 "对号入座"
这个是模型最基础的判断,和我们人类考试判卷一模一样:
-
如果 模型猜的答案 = 标准答案 → 模型知道:我做对了! 这个词的向量不用大改,稍微微调即可。
比如标准答案是
苹果,模型也猜对了苹果→ 对了! -
如果 模型猜的答案 ≠ 标准答案 → 模型知道:我做错了! 必须修正向量。
比如标准答案是
苹果,模型猜了香蕉/汽车/桌子→ 错了!
层次 2:【精准计算错误程度(误差 / 损失)】------ 模型知道「错得有多狠」
这一步是模型会 "主动修正自己" 的核心,也是你问的 "怎么对比" 的核心细节!
光知道对错还不够,比如:
- 模型猜
苹果,标准答案是苹果→ 没错,误差 = 0 - 模型猜
香蕉,标准答案是苹果→ 错了,但「水果和水果」的错误,误差很小 - 模型猜
汽车,标准答案是苹果→ 错了,「水果和汽车」的错误,误差超大
-
第四步:出现错误后,会动态的修改当前词语的向量坐标,存在两个调整规则如下。
- 根据误差方向调整:错在哪,就往反方向改。
- 比如模型用「爱、吃」的向量,猜成了「香蕉」,标准答案是「苹果」→ 模型就把「苹果」的向量,往「爱、吃」的向量方向挪一点点 ,同时把「香蕉」的向量,往远离「爱、吃」的方向挪一点点。这样下次再遇到「爱、吃」的上下文,模型就更容易猜到「苹果」,而不是「香蕉」。
- 根据误差大小调整:错得越狠,改得越多;错得越少,改得越少。
- 猜苹果→汽车(误差超大):「苹果」的向量大幅度调整,往正确方向挪一大步。
- 猜苹果→香蕉(误差很小):「苹果」的向量小幅度调整,只挪一小步。
- 猜对了(误差 = 0):向量完全不调整。
调整的最终目标
让模型的「预测结果」和「标准答案」的误差值,越来越小,直到几乎为 0 ------ 也就是模型能稳稳的猜对每一道题,这个时候,单词的词向量就稳定了,也有了真正的「语义意义」(苹果和香蕉近,苹果和汽车远)。
1.4 BGE模型
由于词表都是准备好的,所以每个词语表达方法一样,但是同一个词语在不同的语境中是不一样的。因此出现下面的方式,相同的词语在不同的语境中,对于的向量也不同。
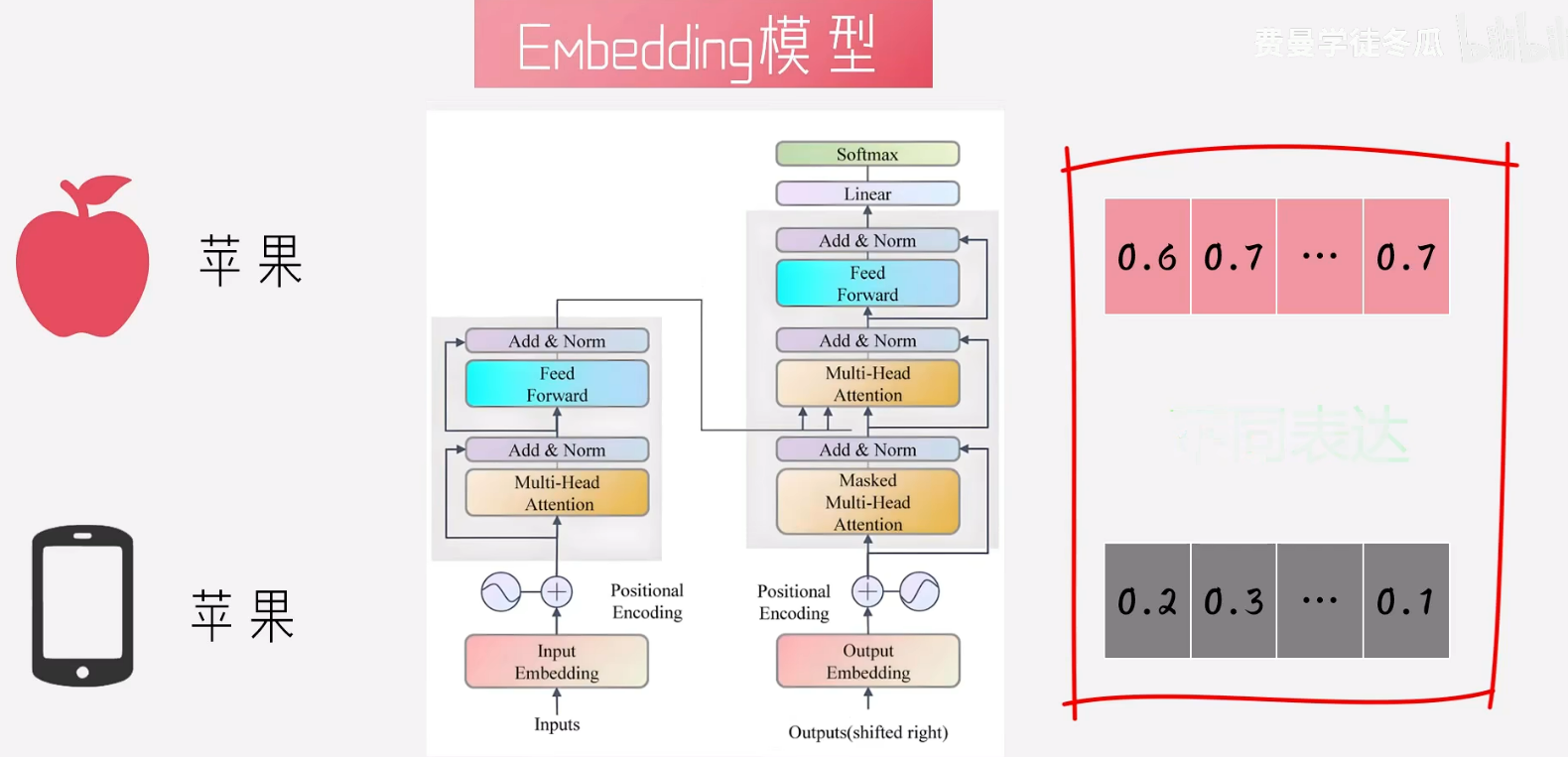
个人理解 :
BEG模型原理,也是通过大量的文本进行训练,只是不是使用词作为向量,而是将一个句子/段落/文档进行向量化,然后通过奖励和惩罚机制。
- 奖励:如果锚句子的向量和正样本的向量靠得近 → 给模型加分;
- 惩罚 :如果锚句子的向量和负样本的向量靠得近 → 给模型扣分。
模型会进行反复的调整内部参数,直到满足:正样本向量紧紧贴着锚句子,负样本向量离得远远的 ,用几百万、几千万组这样的 "锚句子 + 正负样本" 反复训练,模型就会形成稳定的语义判断能力 。
由于这个训练数据是通过机器进行生成的,所以对于特定领域的效果不是很好,因此可能还需要进行微调,此时微调的数据就需要人工进行标注处理。
实现步骤:
BGE 模型的训练是一个 **"先打通用基础,再做专项优化"的两步走过程,核心分为 预训练 (训练通用语义理解能力)和 微调(适配特定场景)。整个流程就像"先培养全能士兵,再训练特种部队。
第一阶段:预训练 ------ 训练通用语义能力(90% 的工作量)
预训练的目标是让模型掌握通用语言的语义规律 (比如 "猫吃鱼" 和 "猫咪爱吃鱼" 是同义句),不需要任何人工标注,完全靠机器自动完成,训练数据量通常是 亿级别的文本。
步骤 1:海量语料采集 ------ 收集 "训练原材料"
做什么
从公开渠道抓取海量、多样的文本数据,作为模型学习的 "素材库"。
怎么做
- 数据源:爬取百科(维基、百度百科)、新闻资讯、论文库、开源书籍、论坛帖子、电商评论等公开文本;多语言版 BGE(如 bge-m3)还会采集英文、日文等多语言语料。
- 数据要求:覆盖多个领域(科技、生活、金融、教育等),保证模型学到的语义不偏科。
通俗类比
就像给士兵收集全世界的 "作战手册",涵盖各种场景,让士兵见多识广。
关键注意点
避免抓取低质量文本(比如乱码、重复内容、无意义的水帖)。
步骤 2:语料清洗与预处理 ------ 筛选 "优质原材料"
做什么
对采集到的原始文本进行 "提纯",去掉无用信息,统一格式,方便后续处理。
怎么做
- 去重:删除完全重复或高度相似的文本(比如同一篇文章被多次爬取)。
- 去噪:过滤乱码、特殊符号、广告弹窗文本、低长度文本(比如少于 5 个字的无意义句子)。
- 标准化:统一文本编码(比如转为 UTF-8)、统一大小写(英文)、修正错别字(可选)。
- 分段:把长文档(比如一篇万字论文)切成短句子 / 短段落(长度控制在模型能处理的范围,比如 512 个词)。
通俗类比
把收集来的作战手册筛选一遍,扔掉破损、重复的,只留清晰完整的。
步骤 3:构造训练样本 ------ 制作 "训练题库"(锚句子 + 正样本 + 负样本)
这是预训练的核心步骤,目的是把清洗后的文本转换成模型能学习的 "锚 - 正 - 负" 样本对。方法完全自动化,不需要人工标注,具体有 3 种常用方式(和之前讲的一致):
| 样本构造方法 | 锚句子来源 | 正样本来源 | 负样本来源 |
|---|---|---|---|
| 数据增广法 | 从清洗后的语料中随机抽一句(如Python for循环遍历列表) |
对锚句子做同义改写:同义词替换、语序调整、增减冗余词(如用for循环在Python中遍历列表) |
从语料库随机抽无关句子(如今天奶茶很好喝) |
| 多语言对齐法 | 抽一句中文(如BGE是文本嵌入模型) |
对应的标准英文翻译(如BGE is a text embedding model) |
随机抽一句不相关的英文(如The cat is sleeping) |
| 文档结构法 | 从一篇文档中抽一句(如BGE用于语义检索) |
从同一篇文档 抽另一句(如BGE能生成语义向量) |
从另一篇文档 抽一句(如Word2Vec是单词嵌入模型) |
最终输出
生成亿万级别的 "锚句子 - 正样本 - 负样本" 三元组,每个三元组都是一组训练数据。
通俗类比
把作战手册改成 "判断题":锚句子是题干,正样本是 "正确答案",负样本是 "错误干扰项"。
步骤 4:模型初始化 ------ 准备 "训练的基础模型"
做什么
选择一个预训练好的 Transformer 底座模型,作为 BGE 的初始参数(不需要从零开始训练,节省算力)。
怎么做
- 常用底座 :中文 BGE 常用 BERT-base-zh 或 RoBERTa-base ;多语言 BGE 常用 XLM-RoBERTa(支持多语言)。
- 模型结构调整 :在 Transformer 顶部加一个池化层 (专门用来提取
[CLS]标记的向量,作为句子的最终嵌入)。
通俗类比
给士兵准备一套基础的 "作战装备",不用从零造装备。
步骤 5:配置训练参数 ------ 设定 "训练规则"
做什么
设置训练的超参数,决定模型 "怎么学、学多久"。
关键参数(小白能懂的核心参数)
- 批次大小(Batch Size):一次喂给模型多少组样本(比如 256/512),越大训练越快,但需要更多算力。
- 学习率(Learning Rate):模型每次调整参数的 "步长"(比如 2e-5),步长太大会学歪,太小会学太慢。
- 训练轮数(Epoch):把所有训练样本学几遍(比如 3-5 轮),学太多会 "死记硬背"(过拟合)。
- 损失函数 :用 InfoNCE 损失(对比学习专用损失),作用是 "奖励锚句子和正样本靠近,惩罚锚句子和负样本靠近"。
通俗类比
制定训练规则:每天训练多少题、每次改进的幅度多大、总共训练多少轮。
步骤 6:对比学习训练 ------ 模型 "正式学习"
做什么
把样本喂给模型,让模型在对比学习中不断调整参数,学会语义匹配。
具体过程(分 4 步循环)
- 输入样本:把一批 "锚句子 - 正样本 - 负样本" 输入模型,模型分别生成三者的向量。
- 计算相似度 :计算锚句子向量和正样本、所有负样本的余弦相似度。
- 计算损失:用 InfoNCE 损失函数算 "误差值"------ 如果锚句子和正样本相似度高、和负样本相似度低,误差就小;反之误差就大。
- 调整参数 :模型根据误差值,用梯度下降算法微调内部参数,让下一次的误差更小。
循环执行
重复上述步骤,直到训练轮数完成,模型的误差稳定在较低水平。
通俗类比
士兵做判断题,教官(损失函数)告诉士兵 "对了还是错了",士兵不断调整作战思路,直到正确率越来越高。
步骤 7:预训练模型保存 ------ 得到 "通用版 BGE 模型"
做什么
训练完成后,保存模型的最终参数,得到通用版 BGE 模型 (比如 bge-base-zh)。
输出结果
模型文件包含两部分:
- Transformer 模型参数(核心);
- 分词器(Tokenizer):用于后续处理新句子的分词。
通俗类比
士兵完成基础训练,成为 "全能士兵",可以应对大部分通用场景。
第二阶段:微调 ------ 训练专项语义能力(10% 的工作量,效果提升关键)
预训练模型是 "通用型" 的,在法律、医疗、金融等专业领域表现一般。微调的目标是用小样本让模型适配特定领域 ,训练数据量通常是 几千到几万组,需要少量人工标注。
步骤 1:领域数据准备 ------ 收集 "专业作战手册"
做什么
收集特定领域的文本数据,比如法律领域的合同、法条;医疗领域的病历、科普文章。
关键要求
数据要和目标场景强相关(比如做法律问答,就用法律文本)。
步骤 2:人工标注训练样本 ------ 制作 "专业题库"
做什么
人工标注 "锚句子 - 正样本 - 负样本" 三元组,保证样本的精准性。
标注规则(以法律领域为例)
- 锚句子 :选领域核心问题(如
合同无效的情形有哪些)。 - 正样本 :标注同义句(如
民法典规定的合同无效条件是什么)。 - 负样本 :标注领域内无关句子(如
合同履行期限如何确定)。
通俗类比
给全能士兵定制 "法律作战手册",标注哪些是正确答案,哪些是干扰项。
步骤 3:微调训练 ------ 模型 "学专业技能"
做什么
用标注好的领域样本,在预训练 BGE 模型的基础上继续训练。
关键操作
- 参数冻结:冻结 Transformer 底层的大部分参数(只微调顶部几层),避免模型忘记通用能力。
- 低学习率:用比预训练更小的学习率(比如 1e-5),小步调整参数,防止学偏。
- 少量轮数:只训练 1-2 轮,避免过拟合(模型死记硬背标注样本)。
步骤 4:模型评估 ------ 检验 "专业技能水平"
做什么
用领域测试集评估微调后模型的效果,判断是否达标。
评估指标(核心:语义匹配准确率)
- 输入测试样本的锚句子,让模型匹配最相似的句子;
- 计算模型匹配到正样本的比例 ------ 比例越高,效果越好。
通俗类比
让士兵参加 "法律作战考试",看正确率是否达标。
步骤 5:最终模型导出 ------ 得到 "可用的 BGE 模型"
做什么
评估达标后,保存微调后的模型参数,得到最终可使用的 BGE 模型。
输出形式
模型文件可以直接用 sentence-transformers 库加载,用于生成句子向量、语义检索等任务。
第三阶段:模型部署与使用 ------ 让模型 "上岗干活"
训练完成后,模型就可以投入实际使用了,常用方式有 2 种:
- 本地调用:用 Python 加载模型,直接处理文本(比如之前给你的代码示例);
- 服务化部署:把模型封装成 API 接口,供其他程序调用(比如做成一个语义检索接口)。
BGE 完整训练流程总结表
| 阶段 | 步骤 | 核心任务 | 通俗类比 |
|---|---|---|---|
| 预训练 | 1. 语料采集 | 收集海量公开文本 | 收集全世界的作战手册 |
| 2. 语料清洗 | 提纯文本,去重去噪 | 筛选完整清晰的手册 | |
| 3. 样本构造 | 自动生成锚 - 正 - 负样本 | 把手册改成判断题题库 | |
| 4. 模型初始化 | 加载 Transformer 底座 | 准备基础作战装备 | |
| 5. 参数配置 | 设置训练规则 | 制定训练计划 | |
| 6. 对比学习训练 | 模型调整参数学语义 | 士兵刷题,不断改进 | |
| 7. 保存预训练模型 | 得到通用版 BGE | 训练出全能士兵 | |
| 微调 | 1. 领域数据准备 | 收集专业领域文本 | 收集法律 / 医疗专业手册 |
| 2. 人工标注样本 | 制作精准的专业题库 | 定制专业判断题 | |
| 3. 微调训练 | 模型学专业语义 | 士兵学专业作战技能 | |
| 4. 模型评估 | 测试专业效果 | 专业技能考试 | |
| 5. 导出最终模型 | 得到领域专用 BGE | 训练出特种部队 | |
| 部署 | 模型上线使用 | 本地调用或服务化部署 | 特种部队上岗执行任务 |