目录:导读
前言
1、MySQL数据库的联合索引
1)采用50个并发、持续压测300秒、在Linux服务器输入jmeter -n -t test.jmx
2)数据库中创建了联合索引:name、age、class这3个字段都用的同一个索引my_index并且是unique类型的
3)按理来说都是unique类型的性能应该是最好的、在接口请求里面http://ip:8080/user/search?age=18\&class=1 去请求接口
4)在Linux服务器端通过dstat -tcmnd --disk-util命令去监控应用服务器发现CPU还是消耗的比较多、数据库服务器里面CPU的idle已经为0%、没有空闲的CPU了
5)然后tps又恢复到300多了、说明还是存在慢SQL的问题
6)继续进行排查发现一个问题、联合索引属于左前缀使用的原则、就是数据库设置联合索引的时候是按照的name、age、class字段是设置的、这样会导致如果用selec * from student where name=xxx and age
和select * from student where name=xxx and class=xx 这样查询的是没有问题的、因为name在最前面是可以作用到unique的
7)但是如果是select * from student where age=18 and class=1里面是没有包含name字段的、并且如果有name字段但是也不是在最左侧查询出来unique索引也是作用不到的、对SQL进行explain发现还是用的扫描类型为全表扫描
所以才导致慢SQL性能大打折扣
8)这种情况的话可以把数据库中的索引顺序改为name、age、class、然后搜索的时候采用最左前缀原则、瞬间tps就提升了60倍能达到18000多tps了
联合索引
一个索引同时作用于多个字段
联合索引的最左前缀
联合索引检索数据时,会从最左边开始匹配(忽略sql字段顺序),如果匹配不到,就不使用索引 如:Student表有联合索引 my_index(name字段,age字段,class字段)
SQL是否使用索引
sql
select * from Student where name = 1 是
select * from Student where age = 2 否
select * from Student where class = 3 否
select * from Student where name= 1 and age = 2 是
select * from Student where name= 1 and class = 3 是
select * from Student where age= 2 and class = 3 否2、MySQL数据库的连接数
1)用Linux命令查看MySQL连接:netstat -anp|grep 127.0.0.111:3306|grep 127.0.0.111|wc -l 可以看到总共有20个连接
2)把MySQL数据库的连接数改为5之后、再次进行压测发现tps还是任然可以达到6000多、但是在压测的时候通过jstack 进程号>a.log抓到日志然后导出到本地
3)查看日志发现很多的timed waiting == 》发现很多都是和druid.pool数据库连接池相关的==》并且很多都是创建等到创建连接的、抓取一次日志等待的地方就多达70多次
4)如果是tps6000满足了那就OK、但是还是满足不了的话可以去改MySQL的连接数
5)在部署的项目当中找到application.properties这个文件里面 ==》把连接池初始化建立的连接数改为5、最小连接数改为5、最大活动连接数改为50
6)增加线程数为10的时候、tps为12000多、数据库服务器的CPU使用率为95%、这个时候应该没有慢SQL、因为有慢SQL的话数据库服务器的CPU基本上得100%、并且去看日志发现与业务线程相关的没有timed waiting
连接数监控命令
sql
show variables like '%connections%'
show status like '%thread%其中:
Threads_connected 当前打开的连接的数量
Threads_cached线程缓存内的线程的数量
Threads_created创建的线程数
Threads_running激活的(非睡眠状态)线程数
show status like '%connection%'
Connections 试图连接MySQL服务器的次数
application.properties配置文件的参数
routeros
# 连接池初始大小
spring.datasource.initialSize=5
# 连接池最小空闲数量
spring.datasource.minIdle=5
# 连接池最大数量
spring.datasource.maxActive=50
# 配置获取连接等待超时的时间spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=600003、MySQL数据库的SQL优化
1)在 where 及 order by 涉及的列上建立索引,避免全表扫描,索引不要太多,一个表一般不要超过4个索引
2)避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3)避免在where子句中对字段进行函数或者在表达式操作,否则将导致引擎放弃使用索引而进行全表扫描
4)避免在where子句中对字段进行左右模糊查询,否则将导致引擎放弃使用索引而进行全表扫描
5)查询语句中尽量不要使用 *,减少内存使用
6)尽量减少子查询,使用关联查询(left join,right join,inner join)替代
7)减少使用IN或者NOT IN ,使用exists,not exists或者关联查询语句替代
8)or 的查询尽量用 union或者union all 代替(在确认没有重复数据或者不用剔除重复数据时,union all会更好)
9)合理的增加冗余的字段(减少表的联接查询)
10)建表的时候能使用数字类型的字段就使用数字类型(type,status...),数字类型的字段作为条件查询比字符串的快
11)减少用模糊查询比如select * from 表名 where name like "%zhang" ==》因为这样的话索引会失效、会从const唯一扫描变成全表扫描all了、性能大幅度下降
完整版!企业级性能测试实战,速通Jmeter性能测试到分布式集群压测教程
|-------------------------------------|
| 下面是我整理的2026年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
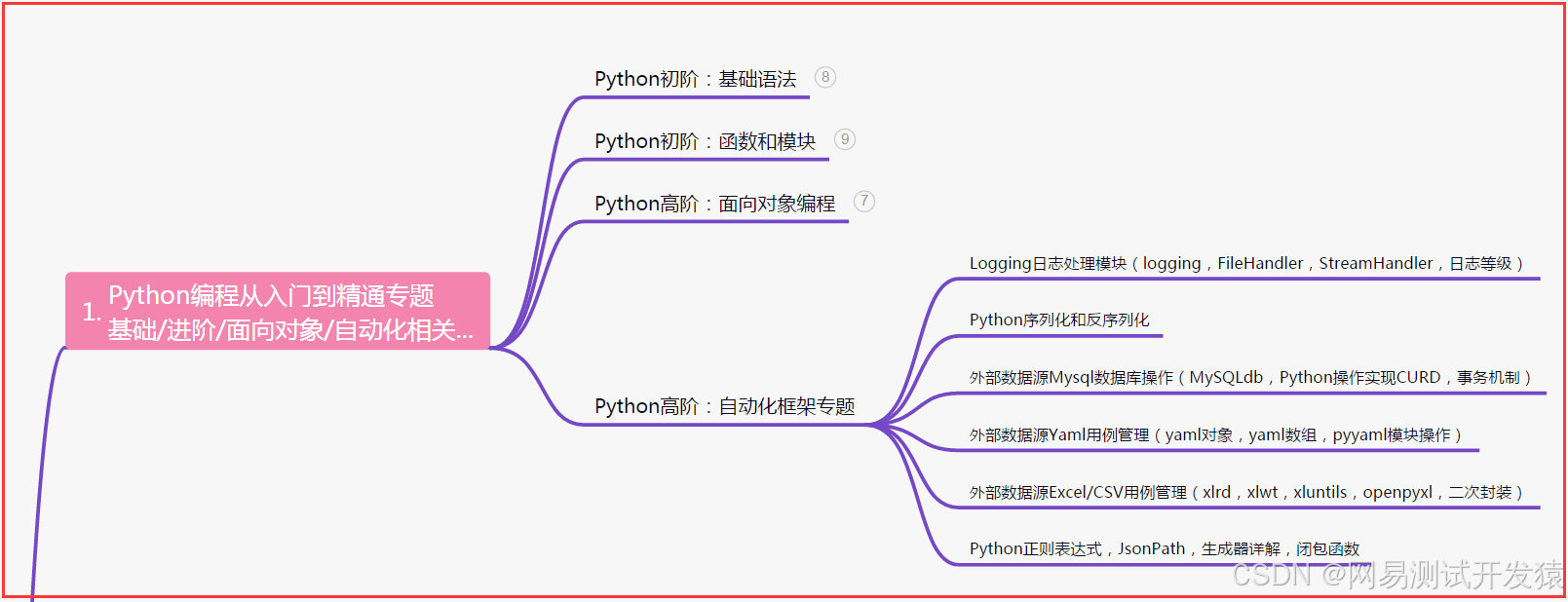
二、接口自动化项目实战
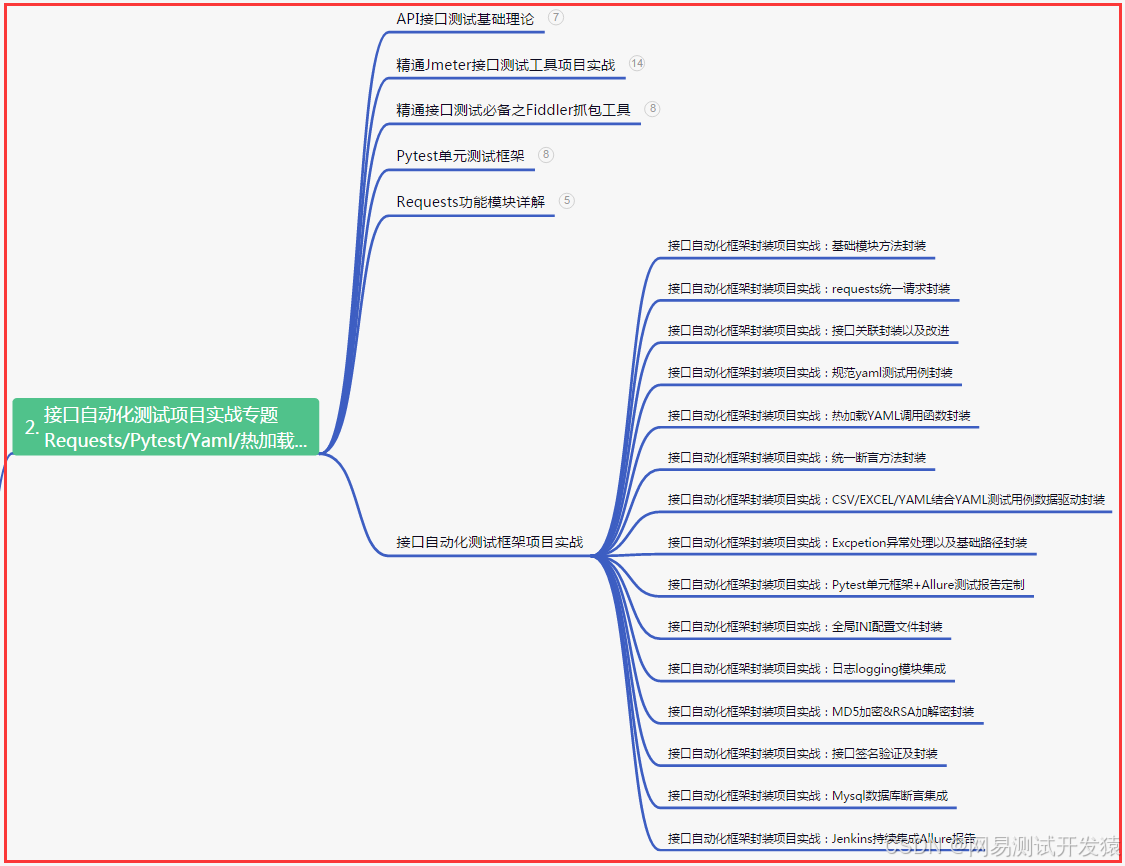
三、Web自动化项目实战
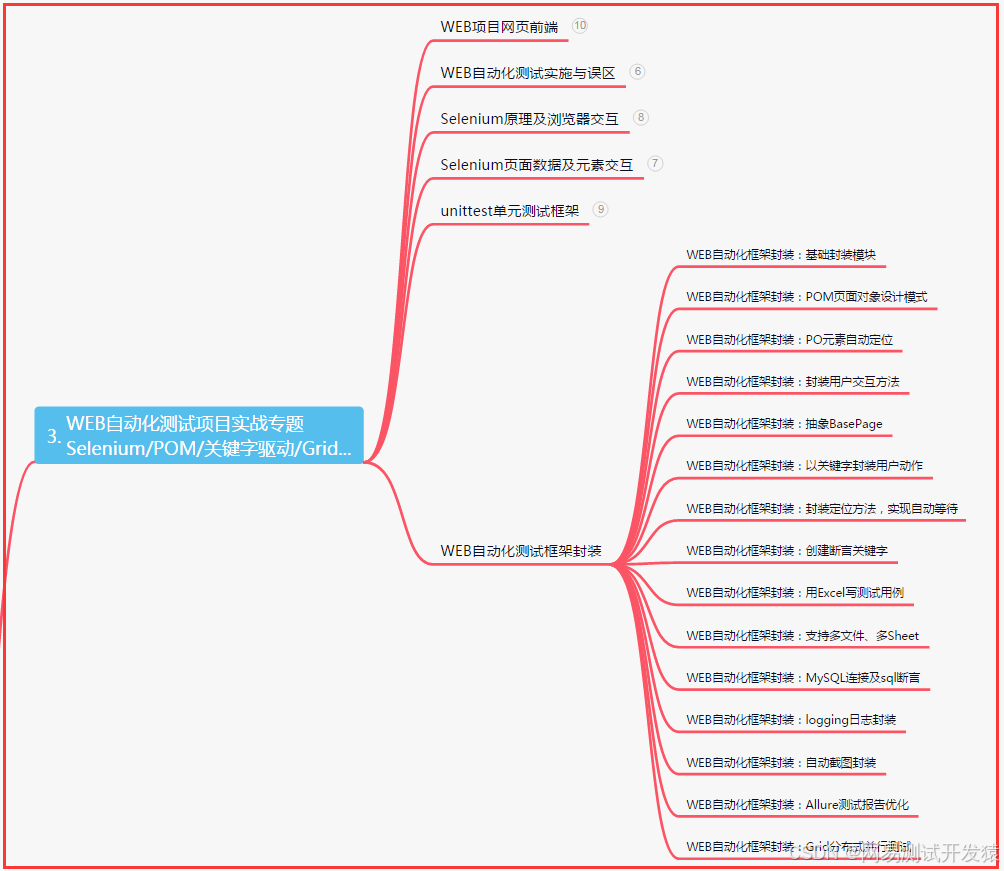
四、App自动化项目实战
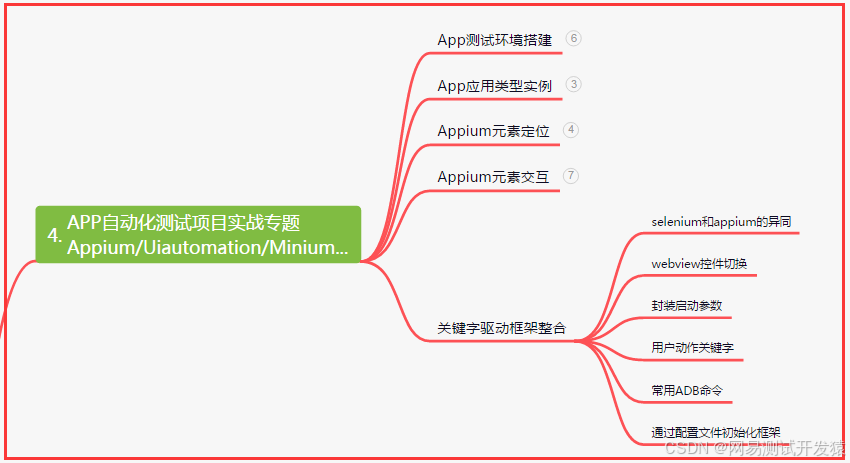
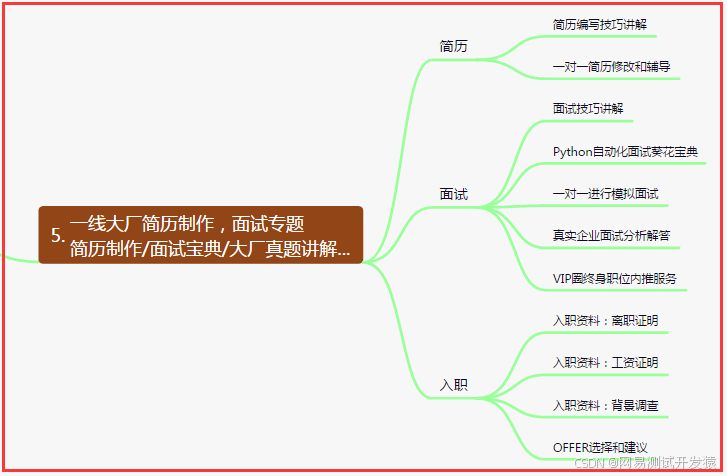
五、一线大厂简历
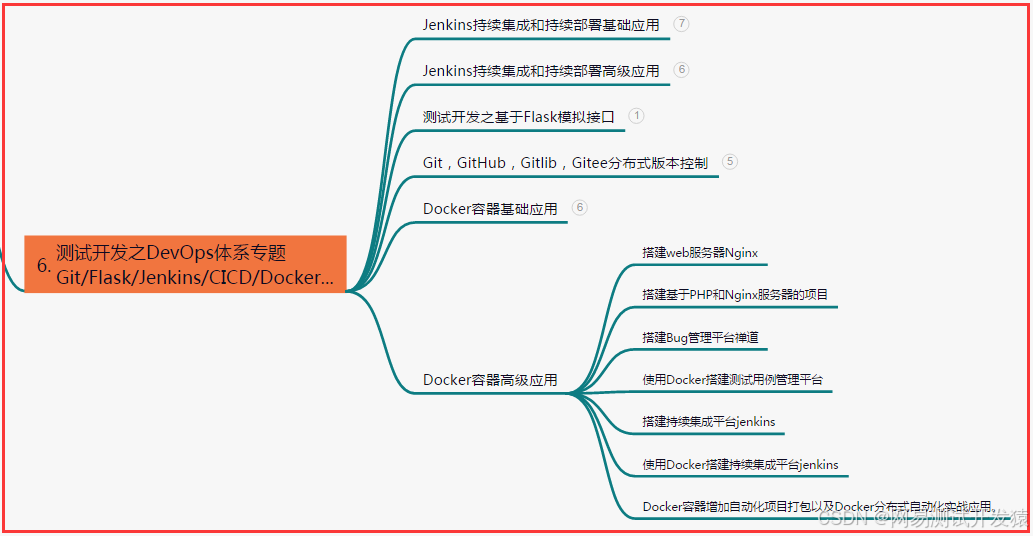
六、测试开发DevOps体系
七、常用自动化测试工具

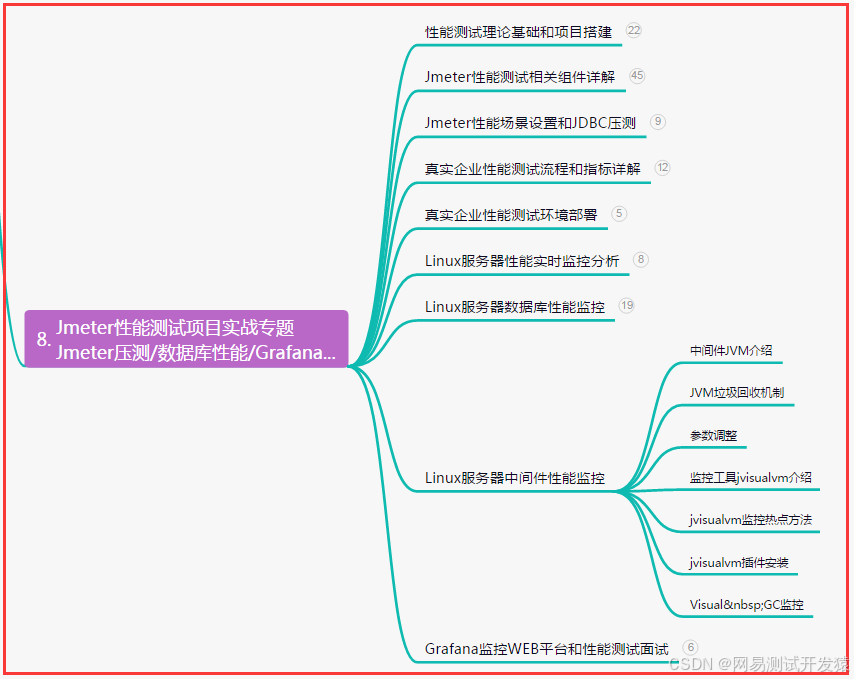
八、JMeter性能测试
九、总结(尾部小惊喜)
人生最珍贵的不是终点站的掌声,而是追梦路上的每一个脚印。当你觉得疲惫时,请记住:钻石经过打磨才能璀璨,雄鹰经历断羽才能高飞。你的坚持,正在书写属于自己的传奇篇章!
别让任何人定义你的极限!你拥有的不是天花板,而是等待突破的起点。那些看似不可能的梦想,终将在你日复一日的坚持中变得触手可及。你,就是自己人生的造梦者!