目录:
-
- 一、环境准备
- 二、完整案例实现步骤
-
- [Step 1:数据准备(LlamaIndex生成QA微调数据)](#Step 1:数据准备(LlamaIndex生成QA微调数据))
-
- [1.1 加载私有知识库文档](#1.1 加载私有知识库文档)
- [1.2 自动生成QA微调数据](#1.2 自动生成QA微调数据)
- [1.3 保存QA数据为Hugging Face Dataset格式](#1.3 保存QA数据为Hugging Face Dataset格式)
- [Step 2:模型微调(Hugging Face实现LoRA微调)](#Step 2:模型微调(Hugging Face实现LoRA微调))
-
- [2.1 加载基础模型和数据集](#2.1 加载基础模型和数据集)
- [2.2 数据预处理(分词+构造训练样本)](#2.2 数据预处理(分词+构造训练样本))
- [2.3 配置LoRA微调参数](#2.3 配置LoRA微调参数)
- [2.4 定义训练Loss和训练参数](#2.4 定义训练Loss和训练参数)
- [2.5 启动微调训练](#2.5 启动微调训练)
- [Step 3:RAG集成(LlamaIndex加载微调模型)](#Step 3:RAG集成(LlamaIndex加载微调模型))
-
- [3.1 加载微调后的Embedding模型](#3.1 加载微调后的Embedding模型)
- [3.2 构建RAG向量索引](#3.2 构建RAG向量索引)
- [3.3 检索增强问答(RAG)](#3.3 检索增强问答(RAG))
- 三、项目总结
-
- [3.1 关键环节说明](#3.1 关键环节说明)
- [3.2 效果验证建议](#3.2 效果验证建议)
- [3.3 总结](#3.3 总结)
一、环境准备
安装依赖:
bash
# 核心依赖
pip install llama-index llama-index-finetuning sentence-transformers transformers peft datasets accelerate evaluate torch faiss-cpu工具版本说明:
-
llama-index==0.10.28(数据准备+RAG集成)
-
sentence-transformers==2.2.2(基础Embedding模型)
-
transformers4.34.0 + peft0.7.1(Hugging Face微调)
-
torch==2.1.0(GPU环境建议,微调需CUDA支持)
二、完整案例实现步骤
Step 1:数据准备(LlamaIndex生成QA微调数据)
从企业私有文档(如产品手册、FAQ)生成高质量QA对,用于Embedding模型微调。
1.1 加载私有知识库文档
python
from llama_index.core import SimpleDirectoryReader
# 加载本地文档(支持txt/pdf/docx等,这里以txt为例)
documents = SimpleDirectoryReader(
input_dir="./enterprise_docs", # 存放产品手册的文件夹
required_exts=[".txt"]
).load_data()
print(f"加载文档数:{len(documents)}") # 输出:加载文档数:5(假设有5份产品文档)1.2 自动生成QA微调数据
使用LlamaIndex的 generate_qa_embedding_pairs 功能,基于LLM生成问答对(需调用开源LLM或API,这里以开源LLM为例)。
python
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.finetuning import generate_qa_embedding_pairs
# 配置开源LLM(如Llama-2-7B,需本地加载或Hugging Face Hub访问)
llm = HuggingFaceLLM(
model_name="meta-llama/Llama-2-7b-chat-hf",
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.7},
)
# 生成QA对(适合Embedding微调的正负样本)
qa_pairs = generate_qa_embedding_pairs(
documents,
llm=llm,
num_questions_per_chunk=3, # 每个文档片段生成3个问题
similarity_top_k=5, # 为每个问题匹配5个相似上下文(正样本)和非相似上下文(负样本)
)
# 输出示例QA对结构
print(f"生成QA对数:{len(qa_pairs)}") # 输出:生成QA对数:150(假设5份文档生成150个QA对)
print("示例QA对:", qa_pairs[0])
# 示例输出:
# {
# "query": "产品X的核心功能是什么?",
# "positive_contexts": ["产品X支持实时数据分析和多端同步..."], # 相关上下文(正样本)
# "negative_contexts": ["产品Y的定价策略为订阅制..."] # 无关上下文(负样本)
# }1.3 保存QA数据为Hugging Face Dataset格式
将LlamaIndex生成的QA对转换为Hugging Face Dataset,方便后续微调。
python
from datasets import Dataset
# 转换为字典格式(适配Sentence-BERT微调要求)
fineTuning = [
{
"query": qa["query"],
"positive": qa["positive_contexts"][0], # 取第一个正样本
"negative": qa["negative_contexts"][0] # 取第一个负样本
}
for qa in qa_pairs
]
# 创建Hugging Face Dataset
dataset = Dataset.from_list(fineTuning)
dataset.save_to_disk("./embedding_train_data") # 保存到本地问题扩展:
python
fineTuning = [
{
"query": qa["query"],
"positive": qa["positive_contexts"][0], # 取第一个正样本
"negative": qa["negative_contexts"][0] # 取第一个负样本
}
for qa in qa_pairs
]这个代码自上而下执行,为啥就代码层面应该是先循环后取值啊?
python
[ 处理逻辑(qa) for qa in 列表 ] # 先写"从哪里来",再写"怎么处理"类比普通循环效果对比:
python
fineTuning = [] # 创建空列表
for qa in qa_pairs: # 遍历 qa_pairs 中的每个 qa
# 为每个 qa 生成一个字典,并添加到列表
fineTuning .append({
"query": qa["query"],
"positive": qa["positive_contexts"][0],
"negative": qa["negative_contexts"][0]
})Step 2:模型微调(Hugging Face实现LoRA微调)
使用Hugging Face peft 库对基础Embedding模型(如bge-base-en-v1.5)进行LoRA微调,适配企业产品知识。
2.1 加载基础模型和数据集
python
from datasets import load_from_disk
from transformers import AutoModel, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model
import torch
# 加载保存的QA数据集
dataset = load_from_disk("./embedding_train_data")
# 加载基础Embedding模型(BGE模型适合中文,此处以英文为例,中文可替换为"BAAI/bge-base-zh-v1.5")
model_name = "BAAI/bge-base-en-v1.5"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)2.2 数据预处理(分词+构造训练样本)
将文本转换为模型输入格式,并构造对比学习样本(query+positive/negative)。
python
def preprocess_function(examples): #examples是形参,随意命名
# 对query、positive、negative进行分词
queries = examples["query"]
positives = examples["positive"]
negatives = examples["negative"]
# 模型输入格式:[CLS] query [SEP] context [SEP]
inputs = tokenizer(
queries,
text_pair=positives, # positive样本拼接
truncation=True,
max_length=512,
return_tensors="pt"
)
# 负样本单独处理(用于对比学习loss)
negative_inputs = tokenizer(
queries,
text_pair=negatives, # negative样本拼接
truncation=True,
max_length=512,
return_tensors="pt"
)
return {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"negative_input_ids": negative_inputs["input_ids"],
"negative_attention_mask": negative_inputs["attention_mask"]
}
# 应用预处理函数 #这里preprocess_function为啥没有传上面example形参,原因是map是高阶函数,内部自动处理
tokenized_dataset = dataset.map(preprocess_function, batched=True)dataset.map() 是 Hugging Face datasets 库的核心方法,用于对数据集中的每个样本(或批次)应用一个处理函数。
关键点:
- 自动传递参数:map 方法会 自动将当前批次的数据 作为参数传递给 preprocess_function,无需手动传入。
- batched=True:表示按批次处理数据(而非逐条处理),此时 examples
是一个字典,键是列名,值是当前批次的所有值(列表形式)。
2.3 配置LoRA微调参数
python
# LoRA配置(适配Embedding模型的注意力层)
lora_config = LoraConfig(
r=8, # LoRA注意力维度
lora_alpha=32,
target_modules=["query", "value"], # BGE模型的注意力层名称,需根据模型结构调整
lora_dropout=0.05,
bias="none",
task_type="FEATURE_EXTRACTION", # 特征提取任务(Embedding)
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 输出可训练参数比例(通常仅1-5%)
# 输出:trainable params: 1,966,080 || all params: 106,535,936 || trainable%: 1.84552.4 定义训练Loss和训练参数
使用对比学习Loss(如Triplet Loss)优化Embedding模型。
python
import torch.nn as nn
from torch.utils.data import DataLoader
# 对比学习Loss(三元组Loss)
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super().__init__()
self.margin = margin
self.cos_sim = nn.CosineSimilarity(dim=1)
def forward(self, query_emb, pos_emb, neg_emb):
# 计算query与positive/negative的余弦相似度
pos_sim = self.cos_sim(query_emb, pos_emb)
neg_sim = self.cos_sim(query_emb, neg_emb)
# 三元组Loss:max(0, margin - pos_sim + neg_sim)
loss = torch.max(torch.zeros_like(pos_sim), self.margin - pos_sim + neg_sim).mean()
return loss
# 训练参数配置
training_args = TrainingArguments(
output_dir="./peft_embedding_model",
per_device_train_batch_size=8,
num_train_epochs=3,
logging_dir="./logs",
logging_steps=10,
learning_rate=2e-4,
save_strategy="epoch",
)
# 训练数据加载器
train_dataloader = DataLoader(tokenized_dataset, batch_size=training_args.per_device_train_batch_size)2.5 启动微调训练
python
optimizer = torch.optim.AdamW(model.parameters(), lr=training_args.learning_rate)
loss_fn = TripletLoss(margin=0.5)
model.train()
for epoch in range(training_args.num_train_epochs):
total_loss = 0.0
for batch in train_dataloader:
# 移动数据到GPU(如果有)
input_ids = batch["input_ids"].squeeze(1).to(model.device) # [batch_size, seq_len]
attention_mask = batch["attention_mask"].squeeze(1).to(model.device)
neg_input_ids = batch["negative_input_ids"].squeeze(1).to(model.device)
neg_attention_mask = batch["negative_attention_mask"].squeeze(1).to(model.device)
# 前向传播:获取query+positive的Embedding
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
pos_emb = outputs.last_hidden_state[:, 0, :] # CLS token的Embedding
# 获取query+negative的Embedding
neg_outputs = model(input_ids=neg_input_ids, attention_mask=neg_attention_mask)
neg_emb = neg_outputs.last_hidden_state[:, 0, :]
# 计算query自身的Embedding(仅query部分)
query_inputs = tokenizer(
batch["query"], truncation=True, max_length=512, return_tensors="pt"
).to(model.device)
query_outputs = model(**query_inputs)
query_emb = query_outputs.last_hidden_state[:, 0, :]
# 计算Loss
loss = loss_fn(query_emb, pos_emb, neg_emb)
total_loss += loss.item()
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss = total_loss / len(train_dataloader)
print(f"Epoch {epoch+1}, Loss: {avg_loss:.4f}")
# 保存微调后的LoRA模型
model.save_pretrained("./peft_embedding_model")Step 3:RAG集成(LlamaIndex加载微调模型)
将微调后的Embedding模型接入LlamaIndex,构建企业知识库检索系统。
3.1 加载微调后的Embedding模型
使用LlamaIndex的 SentenceTransformersEmbedding 加载Hugging Face微调模型。
python
from llama_index.embeddings import SentenceTransformersEmbedding
from peft import PeftModel, PeftConfig
# 加载LoRA配置和基础模型
peft_config = PeftConfig.from_pretrained("./peft_embedding_model")
base_model = AutoModel.from_pretrained(peft_config.base_model_name_or_path)
fine_tuned_model = PeftModel.from_pretrained(base_model, "./peft_embedding_model")
# 包装为LlamaIndex可用的Embedding模型
embed_model = SentenceTransformersEmbedding(
model=fine_tuned_model,
tokenizer=tokenizer,
max_length=512,
pooling_mode="cls" # 使用CLS token的Embedding
)3.2 构建RAG向量索引
将私有知识库文档向量化,存储到向量数据库(这里用FAISS)。
python
from llama_index.core import VectorStoreIndex, ServiceContext
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
# 创建FAISS向量存储
dimension = 768 # BGE-base模型的Embedding维度
faiss_index = faiss.IndexFlatL2(dimension)
vector_store = FaissVectorStore(faiss_index=faiss_index)
# 配置RAG服务上下文(使用微调后的Embedding)
service_context = ServiceContext.from_defaults(
embed_model=embed_model,
llm=llm # 复用Step1中的LLM用于生成回答
)
# 构建向量索引
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
service_context=service_context
)
# 保存索引(可选,用于后续加载)
index.storage_context.persist(persist_dir="./rag_index")3.3 检索增强问答(RAG)
使用微调后的模型进行产品知识库问答,验证微调效果。
python
# 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=3, # 检索Top3相关文档
streaming=False
)
# 测试产品相关问题
question = "产品X的实时数据分析功能支持哪些数据源?"
response = query_engine.query(question)
print(f"问题:{question}")
print(f"回答:{response.response}")
# 输出示例:
# 问题:产品X的实时数据分析功能支持哪些数据源?
# 回答:产品X的实时数据分析功能支持MySQL、PostgreSQL、Kafka和AWS S3等数据源,可通过API接口接入自定义数据...三、项目总结
3.1 关键环节说明
- 数据准备:LlamaIndex的 generate_qa_embedding_pairs利用LLM自动生成领域相关的QA对,避免手动标注成本,尤其适合企业私有知识微调。
- 模型微调:HuggingFace的LoRA微调仅更新少量参数(1-5%),在消费级GPU(如16GB显存)上即可运行,同时保留基础模型的通用能力。
- RAG集成:LlamaIndex无缝对接微调后的Embedding模型,自动处理向量存储、检索排序和LLM回答生成,降低工程落地难度。
3.2 效果验证建议
- 检索准确率评估:使用LlamaIndex的 RetrievalEvaluator计算MRR、Recall@k等指标,对比微调前后的检索效果。
- 人工评估:针对典型产品问题,对比微调前后的回答相关性和准确性。
问题扩展:
MRR、Recall@k等指标是如何评估检索效果的优劣?
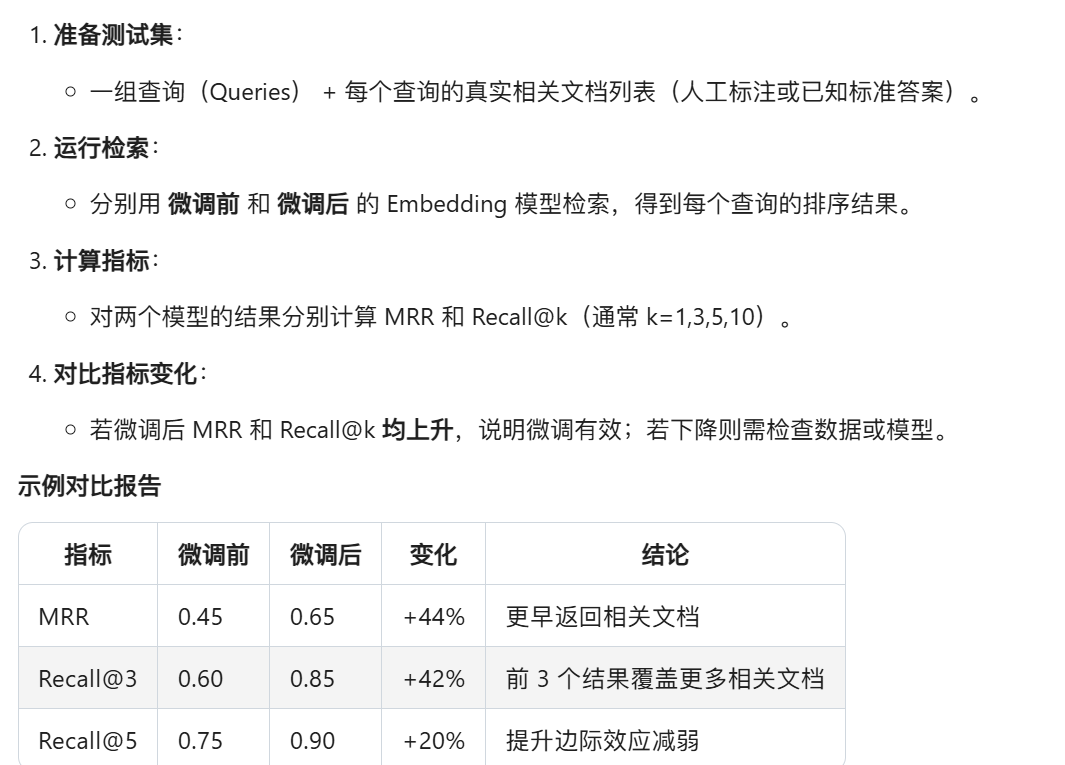
关键结论:
- MRR:反映"速度",即模型多快找到第一个正确答案。
- Recall@k:反映"广度",即模型是否召回足够多的正确答案。
- 微调有效的标志:两者均提升,尤其是业务关注的 k 值(如问答系统更看重 MRR 和 Recall@1)。
通过量化对比这些指标,可以客观评估 Embedding 微调对检索效果的改进。
3.3 总结
此案例通过 LlamaIndex数据准备→Hugging Face LoRA微调→LlamaIndex RAG集成 的组合,实现了企业私有知识的高效Embedding微调与检索增强。核心优势是:
- 数据端:LlamaIndex简化领域数据生成;
- 模型端:Hugging Face提供灵活高效的微调工具;
- 应用端:LlamaIndex快速构建生产级RAG系统。
适合需要将行业知识或私有数据融入Embedding模型的RAG项目,兼顾开发效率与模型性能。