文章目录
- 应用层核心:HTTP协议从基础到实战全解析
-
- 一、HTTP协议基础认知
-
- [1. 什么是HTTP?](#1. 什么是HTTP?)
- [2. 网络通信的核心:资源](#2. 网络通信的核心:资源)
- 二、URL:互联网资源的"唯一定位符"
-
- [1. URL的核心逻辑](#1. URL的核心逻辑)
- [2. URL的端口](#2. URL的端口)
- [3. 完整URL的结构拆解](#3. 完整URL的结构拆解)
- [4. 实战案例:搜索引擎URL拆解](#4. 实战案例:搜索引擎URL拆解)
- [5. URL的关键补充](#5. URL的关键补充)
- 三、HTTP的请求与响应:标准化通信格式
-
- [1. HTTP请求格式](#1. HTTP请求格式)
- [2. HTTP响应格式](#2. HTTP响应格式)
- [3. 核心报头](#3. 核心报头)
- 4.补充概念
- 四、HTTP核心特性:版本、状态码、请求方法
-
- [1. HTTP版本](#1. HTTP版本)
- [2. HTTP状态码](#2. HTTP状态码)
- 五、Cookie与Session:解决HTTP无状态问题
-
- [1. HTTP无状态的体现](#1. HTTP无状态的体现)
- [2. Cookie技术](#2. Cookie技术)
- [3. Session技术](#3. Session技术)
应用层核心:HTTP协议从基础到实战全解析
在实际开发中,我们偶尔会定制私有网络协议(比如 len+JSON格式的自定义协议,文章 中使用该方法),但实际中更多依赖成熟的通用协议------HTTP(超文本传输协议),与我们自己定制的协议类似,只不过HTTP协议功能更多,更复杂。本文将详细介绍HTTP协议。
本文暂时不进行socket编程,只讲解协议,在后期会更新代码编程教学
一、HTTP协议基础认知
1. 什么是HTTP?
HTTP(HyperText Transfer Protocol,超文本传输协议)定义了客户端(浏览器、手机APP、各类终端程序)与服务器之间的通信规则,核心目标是实现超文本的传输与交换。我们使用的浏览器就是一些厂商做出来的额客户端,可以将HTTP协议传输回来的超文本进行解析,渲染,形成我们所看到的网页,视频等。
超文本:不限于纯字符文本,还包含视频、图片、音频等各类文件资源;-
底层支撑:HTTP基于TCP协议实现可靠的字节流传输,是其能保证数据完整传输的核心。
2. 网络通信的核心:资源
网络通信本质上是进程间通信(服务器上的某一个进程与客户端上的某一个进程),进程间通信本质上是数据的读写,也就是IO问题。在访问网络时,我们做的无非也是获取信息或者推送信息,我们在网络通信中所获取的超文本信息(网页,图片,视频,音频等)都是资源,在我们访问之前(获取到之前)这些资源都是在服务器中存储的
许多的后端服务器都使用的linux操作系统,linux操作系统下一切皆文件,当客户端向服务器发起获取自愿的请求时,在服务器端首先要找到该资源才可以进行回应,因此在URL中带有路径,就是我们所要资源(文件资源)的路径,该路径在该机器中也一定是唯一的,
二、URL:互联网资源的"唯一定位符"
URL(Uniform Resource Locator,统一资源定位符)也叫超链接(俗称"网址"),其核心作用是精准定位互联网中的唯一资源。
1. URL的核心逻辑
IP地址定位互联网中的唯一主机,路径定位主机内的唯一文件资源,二者结合即可标识互联网中唯一的文件资源------这也是URL被称为"统一资源定位符"的原因。
2. URL的端口
成熟协议与端口号强绑定,HTTP默认使用80端口,HTTPS默认使用443端口。因此URL中通常省略端口号,浏览器发起请求时会自动拼接对应协议的默认端口(如访问http://www.example.com时,实际访问的是http://www.example.com:80,即访问80号端口)。
3. 完整URL的结构拆解
以示例 http://www.example.com:8080/products/index.html?category=books\&page=2#introduction 为例,URL各部分的含义如下:
| 组成部分 | 示例内容 | 核心说明 |
|---|---|---|
| 协议(Scheme) | http:// | 指定通信协议(如HTTP/HTTPS/FTP等),决定客户端与服务器的通信规则; |
| 主机(Host) | www.example.com | 服务器的域名/IP地址,会被包含在HTTP请求的Host头字段(如Host: www.example.com); |
| 端口(Port) | :8080 | 服务器监听HTTP请求的端口,省略时使用协议默认端口(HTTP=80、HTTPS=443); |
| 路径(Path) | /products/index.html | 资源在服务器的具体位置,是HTTP请求行的核心(如GET /products/index.html HTTP/1.1); |
| 查询字符串 | ?category=books&page=2 | 以?开头的键值对参数,多参数用&分隔,向服务器传递动态参数(分页、筛选等); |
| 片段(Fragment) | #introduction | 以#开头,仅浏览器端生效(定位页面锚点),不会发送到服务器; |
4. 实战案例:搜索引擎URL拆解
以必应搜索"linux"的URL https://cn.bing.com/search?q=linux\&form=QBLH\&mkt=zh-CN 为例,拆解核心部分:
-
协议:https://(安全版HTTP,加密传输);
-
子域名+主域名:cn.bing.com(cn指向中国区,bing.com为必应主域名);
-
路径:/search(服务器处理搜索请求的核心路径);
-
查询字符串:
-
q=linux:q(query)为搜索关键词参数,值为"linux";
-
form=QBLH:标识搜索请求的来源表单;
-
mkt=zh-CN:指定"中文-中国"本地化配置。
-
5. URL的关键补充
URL编码(URLDecode)
若参数包含空格、汉字、特殊符号(&或?等),会被转为%XX格式(如空格→%20、"linux command"→q=linux%20command),避免URL解析错误。
三、HTTP的请求与响应:标准化通信格式
HTTP遵循"请求-响应"模型,客户端发送请求、服务器返回响应,二者均有严格的格式规范。
1. HTTP请求格式
HTTP请求以行为单位组织,核心分为四部分:
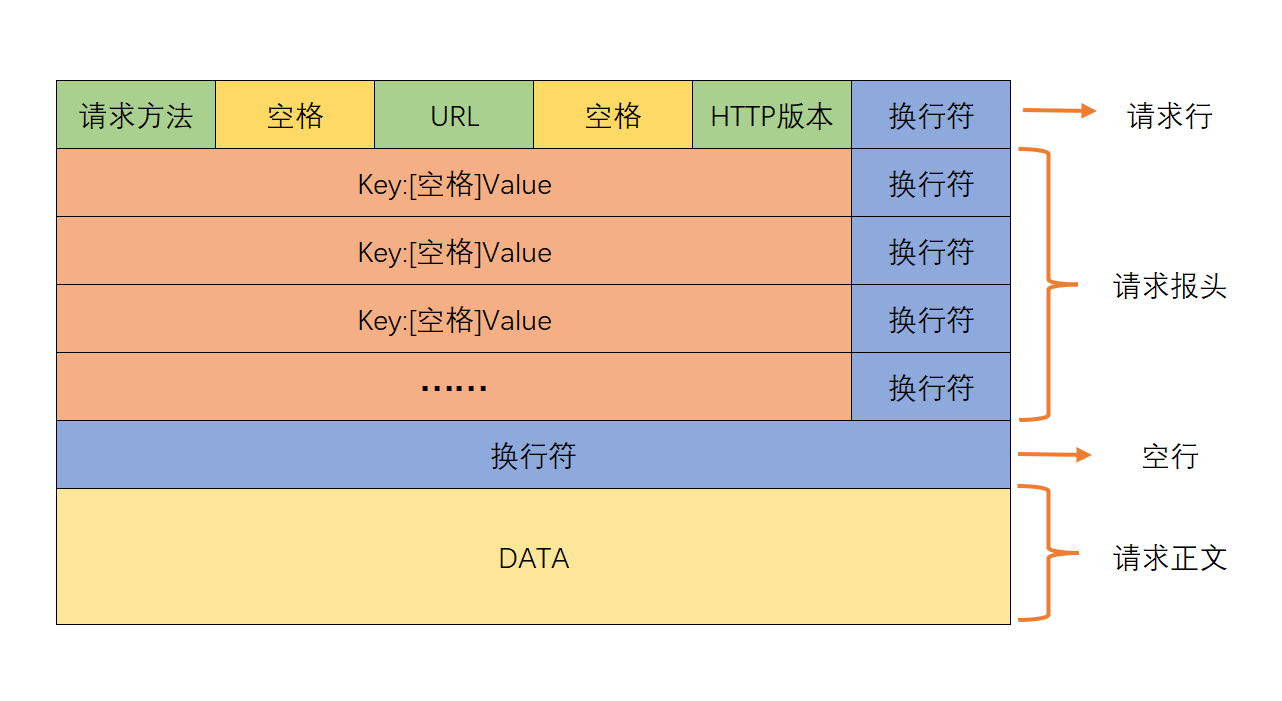
请求行:格式为请求方法 URI HTTP版本(如GET /index.html HTTP/1.1),包含核心请求指令;
-
-
URI:通常为URL的路径部分,标识要访问的资源;
- HTTP版本:如HTTP/1.0/HTTP/1.1/HTTP/2.0,区分协议功能支持;
-
-
请求报头:携带客户端信息(浏览器版本、系统类型)、请求属性(如Host/Content-Length);
-
空行:强制分隔报头与正文,是HTTP格式的必要组成;
-
请求方法:包括GET、POST、HEAD、DELETE等,定义对资源的操作类型;
-
请求正文:POST方法专用(传递大体积参数),GET方法无正文(参数通过URL传递)。
2. HTTP响应格式
HTTP响应与请求格式对应,核心分为四部分:
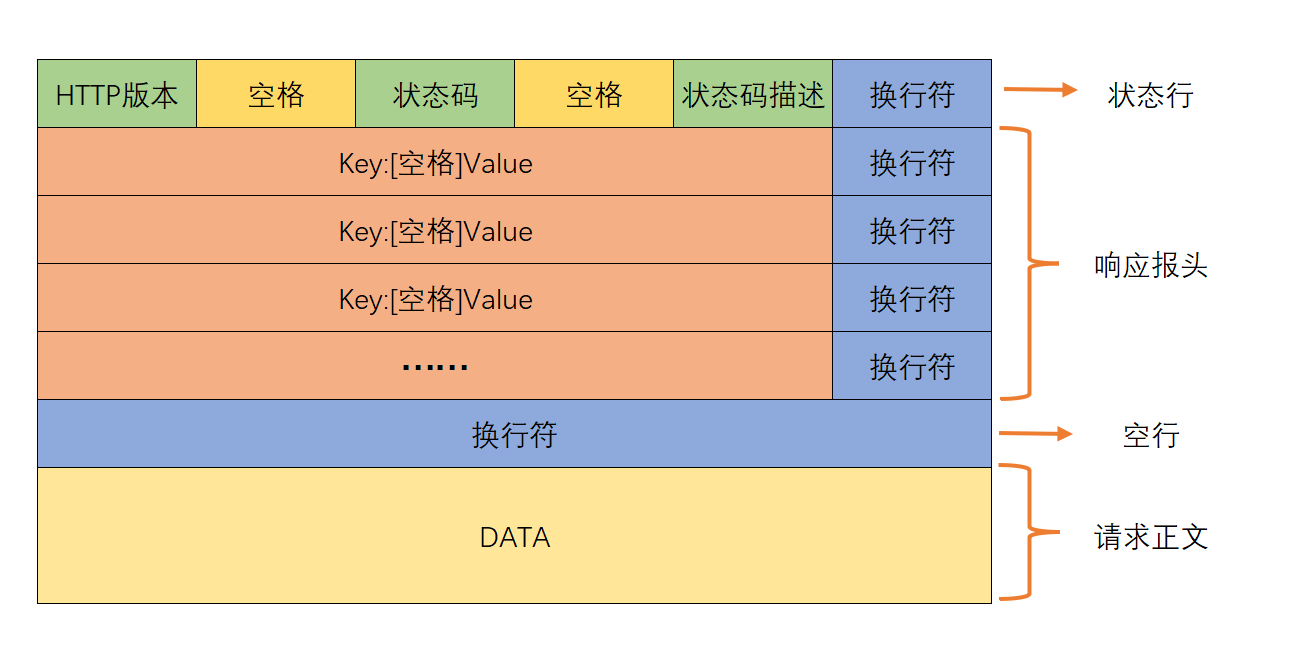
- 状态行:格式为HTTP版本 状态码 状态描述(如HTTP/1.1 200 OK);
- 响应报头:标识响应属性(如Content-Type/Content-Length),可省略;
- 空行:分隔报头与正文;
- 响应正文:URI对应的实际资源(HTML、图片、视频等)。
举例:
当我的服务器上有show.html这样的超文本资源时,并且有响应程序,那么就可以进行访问(平时所访问的网站也是这样的道理)。
在浏览器输入相应的URL,即 http://127.0.0.1:8888/show.html (IP为127.0.0.1,是因为我在本地测试,使用的本地回环IP,他会走一遍协议栈,在返回本主机。我使用的是8888端口,如果部署的服务需要公开,那么就要绑定80端口,因为别人会默认使用80端口,而我自己就随便使用了)
点击回车,即可发起请求,在我的服务器上将收到下面这样的HTTP请求:
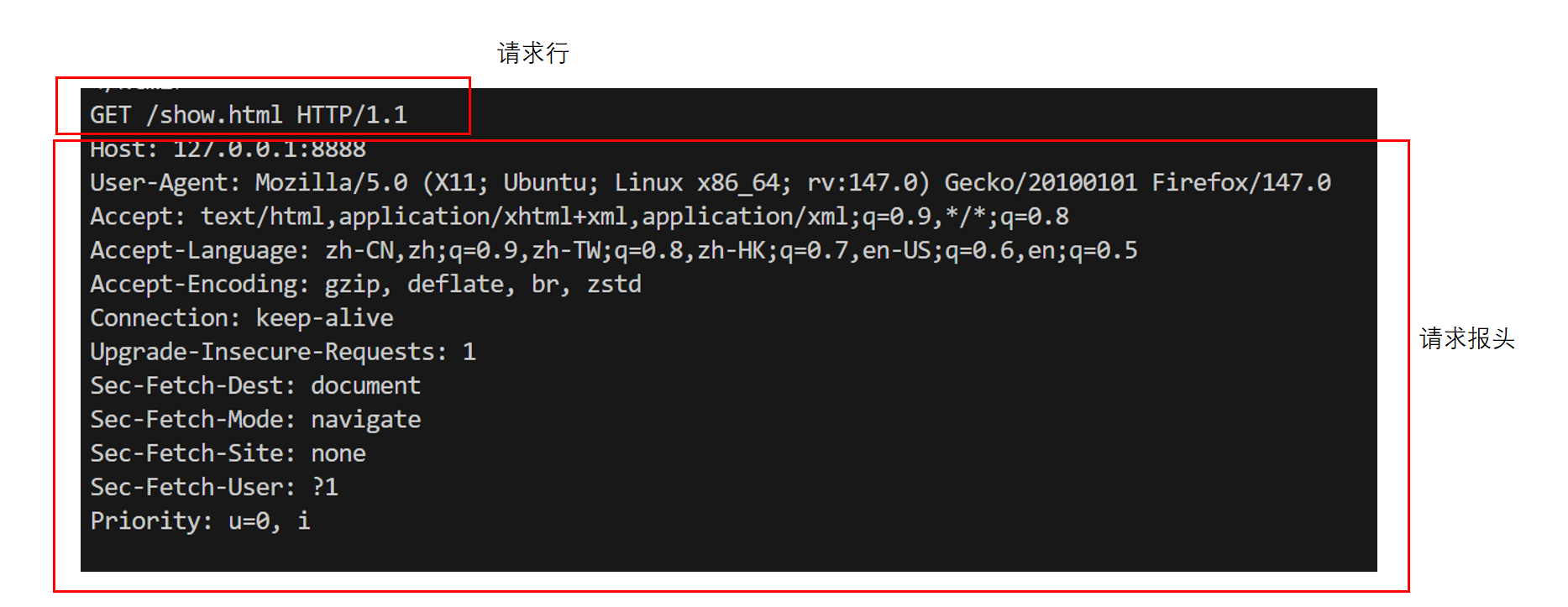
我的程序里面会构建这样的HTTP响应,响应正文是将文件show.html的内容直接拷贝即可,因为是超文本信息,直接传输即可。
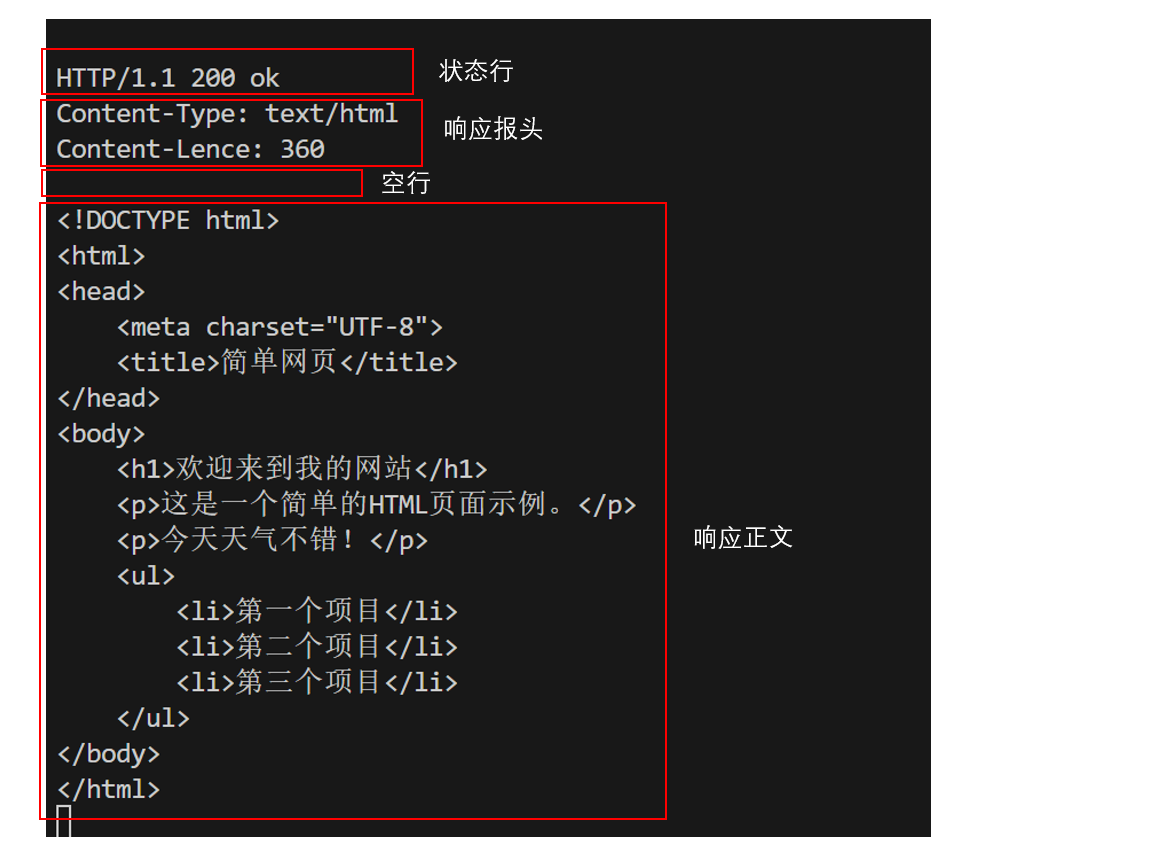
其中正文是超文本数据,即HTML语言所编写的前端程序,我不太懂前端,这是AI生成的,浏览器会将该HTML语言渲染为我们所看到的网页,如下:
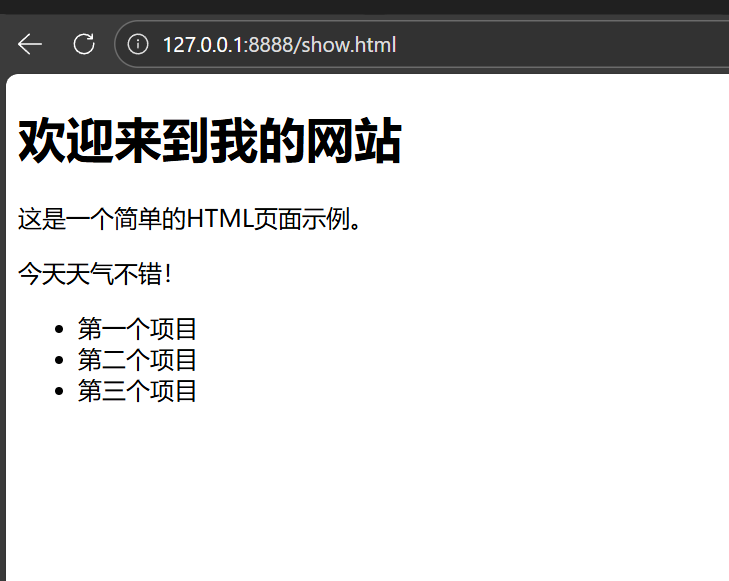
3. 核心报头
- Content-Length:有正文时必填,标识正文字节长度,是报头与正文分离的核心依据。
- Content-Type:标识响应正文的数据类型(如text/html表示HTML文本、image/jpeg表示JPG图片),是浏览器解析资源的核心依据。
- Host:客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。
- User-Agent:声明用户的操作系统和浏览器版本信息。
- Referer:指示当前页面是从哪个页面跳转过来的。
- Location:搭配3xx状态码使用,告诉客户端接下来要去哪里访问。
- Cookie:用于在客户端存储少量信息,通常用于实现会话(session)的功能。
4.补充概念
Web根目录:
服务器在响应时,HTTP响应报文完全由程序员在应用层通过代码构建,而非操作系统自动生成。因此,响应报文中的所有信息都需要手动填入,包括正文内容。正文通常是超文本信息,需要通过二进制读取方式将其完整写入响应报文的正文部分。为了便于管理不同资源,我们会在服务器工作路径下创建一个名为"webroot"的目录,将所有超文本资源集中存储于此。当用户请求资源时,服务器会在请求路径前自动拼接该目录路径,以实现资源的统一管理与访问。
默认首页:
当客户端仅访问根路径(/)时,服务器不应返回Web根目录的全部内容,而需自动拼接默认首页(如index.html)并返回该页面。这一行为需由服务器代码主动实现,而非服务器软件自动完成。
浏览器加载网页的过程:
浏览器首先请求并获取主页的HTML文档,随后自动扫描HTML中的标签(如图片、视频、样式表等),并针对这些附属资源发起额外的HTTP请求,最终将所有获取的资源在客户端拼接、渲染成完整的网页。
四、HTTP核心特性:版本、状态码、请求方法
1. HTTP版本
协议版本区分功能支持:新版本通常新增/修改功能,旧版本无法使用新版本特性,因此请求/响应中必须携带版本号(如HTTP/1.1)。主流版本为HTTP/1.1,此外还有HTTP/1.0(早期版本)、HTTP/2.0(性能优化版)。
2. HTTP状态码
状态码是服务器返回的"响应状态标识",核心分类及含义如下:
| 状态码分类 | 含义 | 典型场景 |
|---|---|---|
| 1xx | 信息类状态码(临时响) | 100 Continue(继续请求) |
| 2xx | 成功类状态码 | 200 OK(请求成功) |
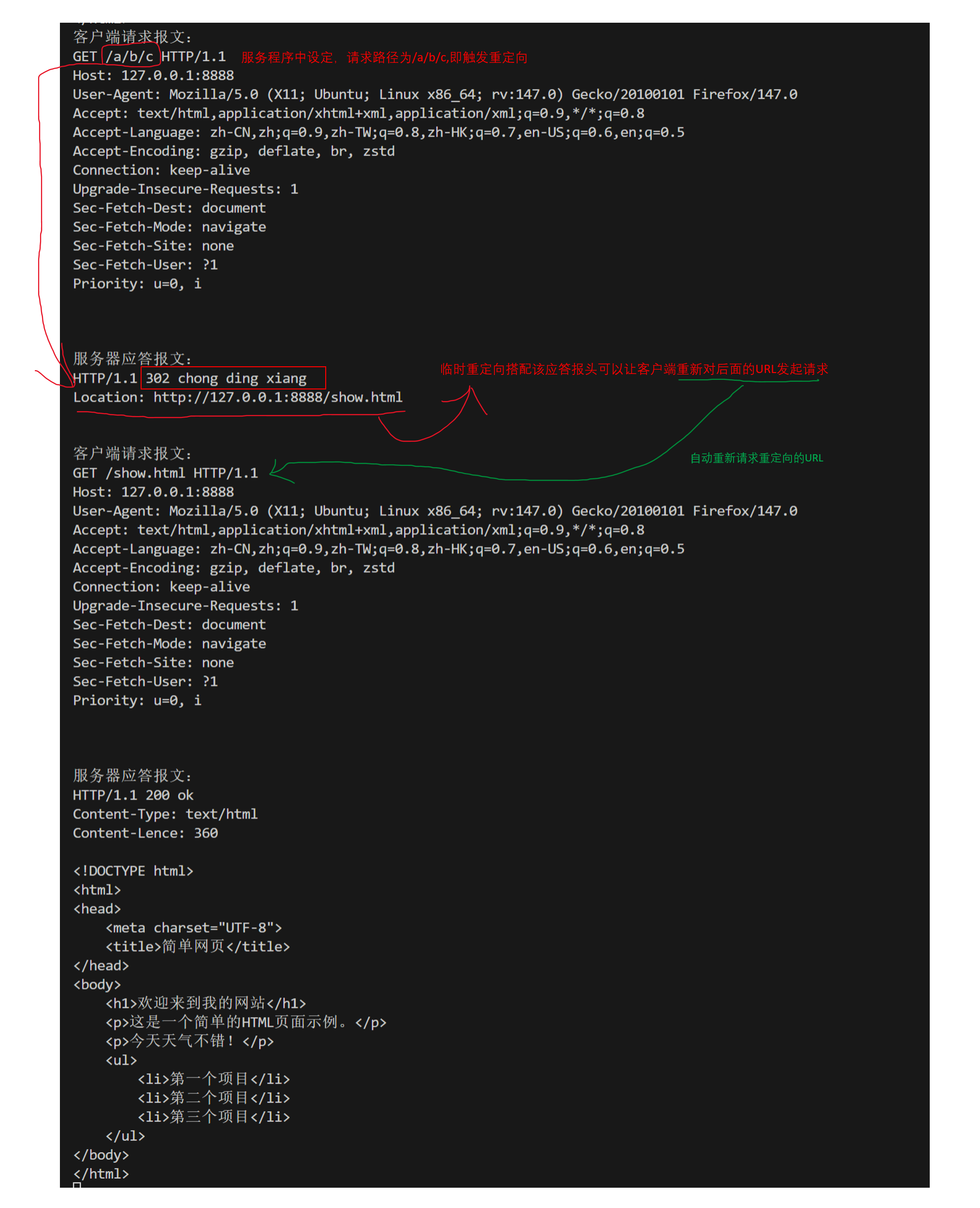
| 3xx | 重定向类状态码 | 301 永久重定向、302 临时重定向 |
| 4xx | 客户端错误状态码 | 404 Not Found(资源不存在) |
| 5xx | 服务器错误状态码 | 500 Internal Server Error(服务器异常) |
| 重定向的两种类型 |
-
临时重定向(302):每次访问旧地址,服务器返回新地址,客户端始终先访问旧地址;
-
永久重定向(301):客户端(如搜索引擎)首次重定向后,更新本地记录,后续直接访问新地址(常用于网站换域名)。
如下图所示:
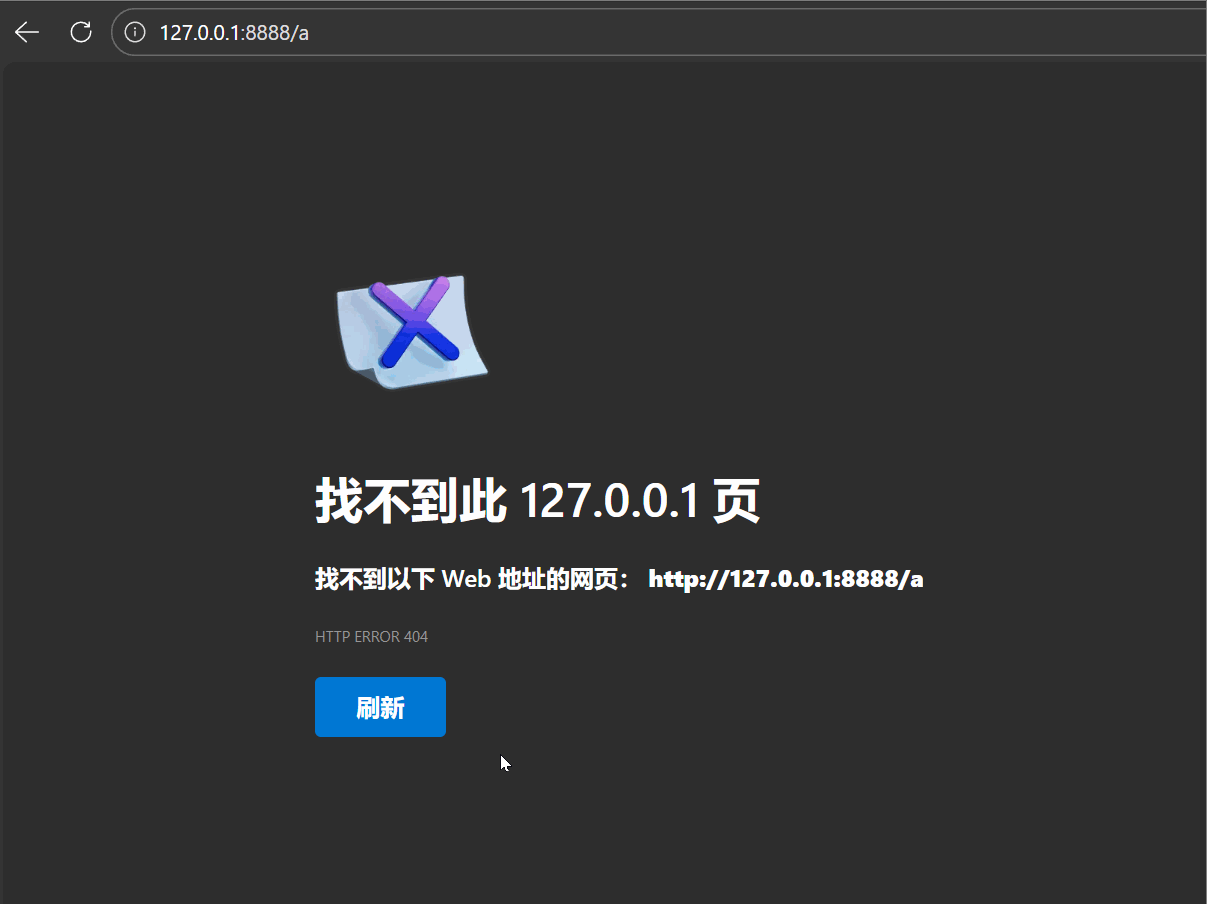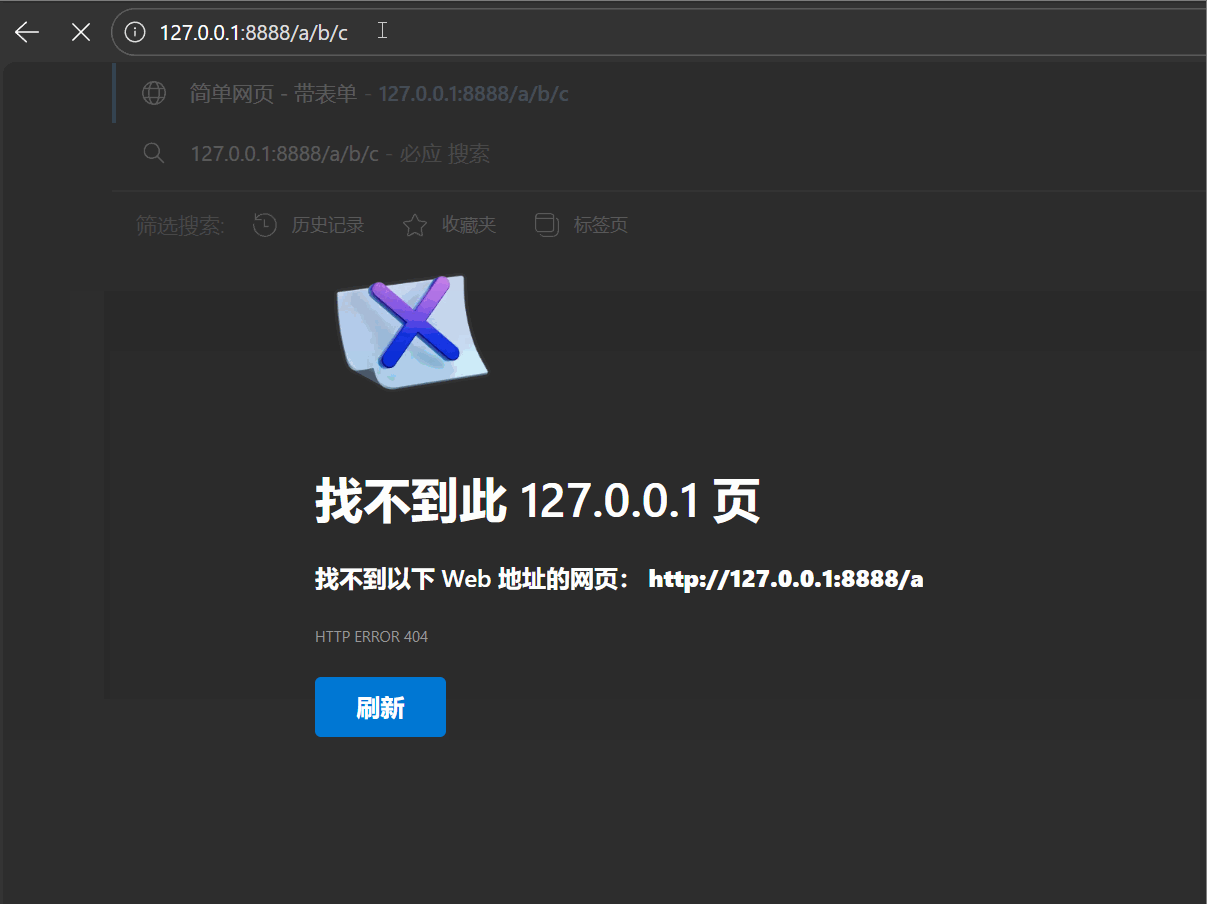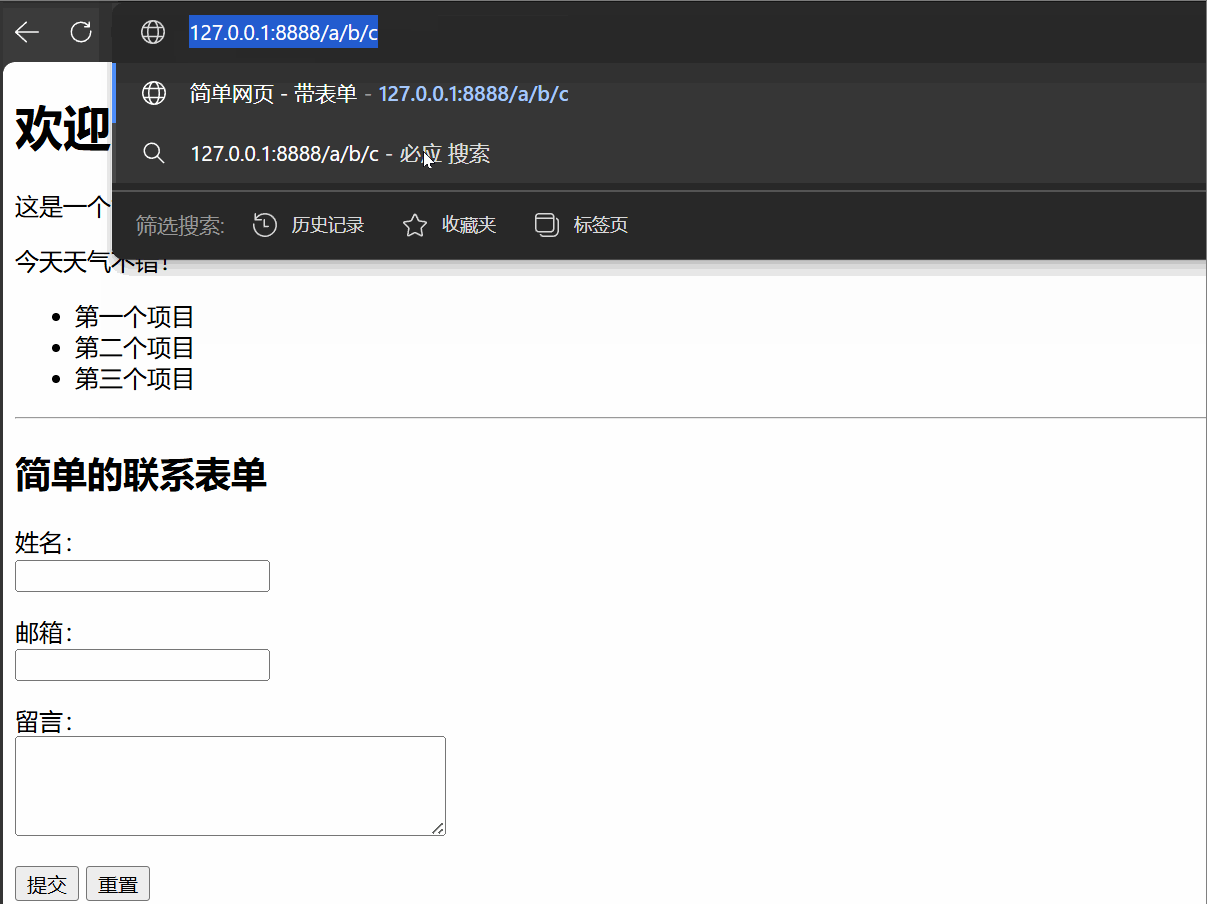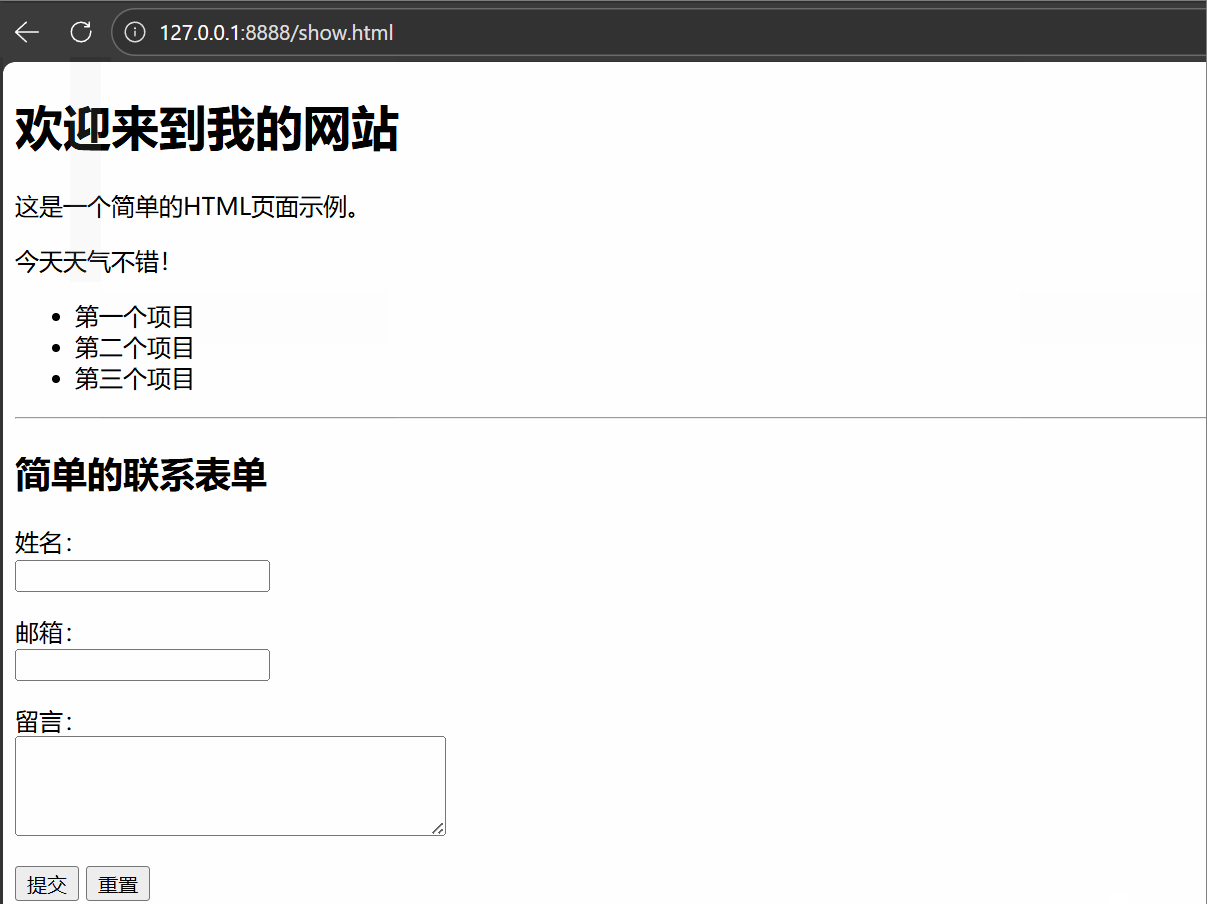
请求和响应数据如下:
永久重定向使用场景:
普通用户通常是通过关键词搜索来寻找目标网站,然后点击搜索结果进行访问,通常是浏览器提供的标签,点击标签就会跳转访问到对应的网站。这些标签如何来呢?在后台,浏览器(或搜索引擎)会通过持续爬取网页来收集和存储网站信息(主要是域名和关键词),以便在用户搜索时提供对应的结果标签(内含域名)。
如果网站已更换域名,但搜索引擎中仍保留着旧域名的链接,用户在点击该链接时,会经历一次重定向跳转到新域名。此时,浏览器(或搜索引擎)会识别出这是一个永久重定向,并随之更新其内部存储的链接,将旧域名替换为新域名。此后,当用户再次搜索或访问该网站时,浏览器就会直接使用新的域名,不再经过旧的链接跳转。
请求方法定义了客户端对服务器资源的操作类型,核心方法及特性如下:
| 方法 | 核心用途 | 传参方式 | 特性 |
|---|---|---|---|
| GET | 获取静态资源(网页、图片) | URL查询字符串 | 参数暴露、体量小、私密性差 |
| POST | 提交数据(表单、大参数) | 请求正文 | 参数隐藏、体量大、相对私密 |
| HEAD | 仅获取响应报头(无正文) | 同GET | 快速校验资源状态 |
| DELETE | 删除服务器资源 | URL/正文传参 | 操作服务器资源 |
| GET vs POST |
- GET:适合"读操作",参数暴露在URL中,传输体量有限;
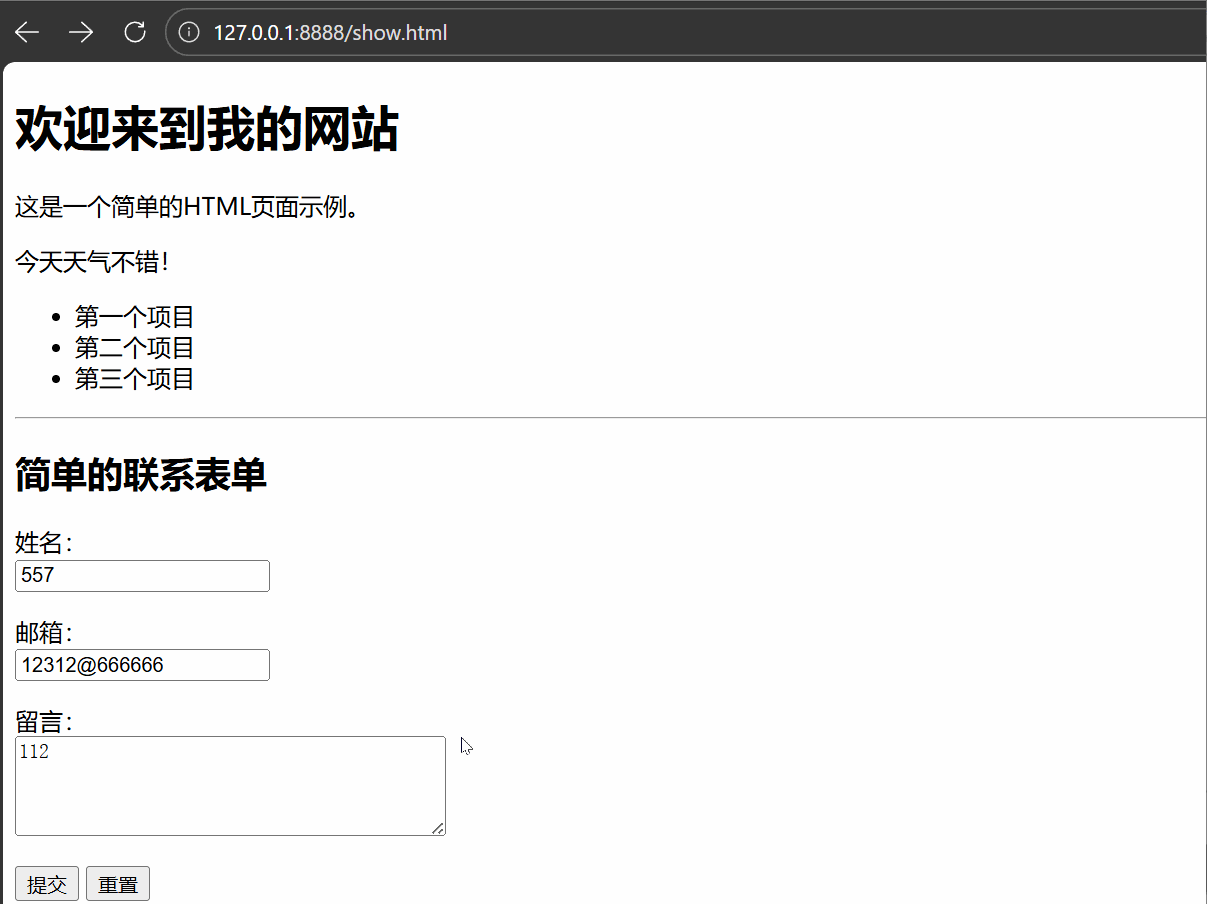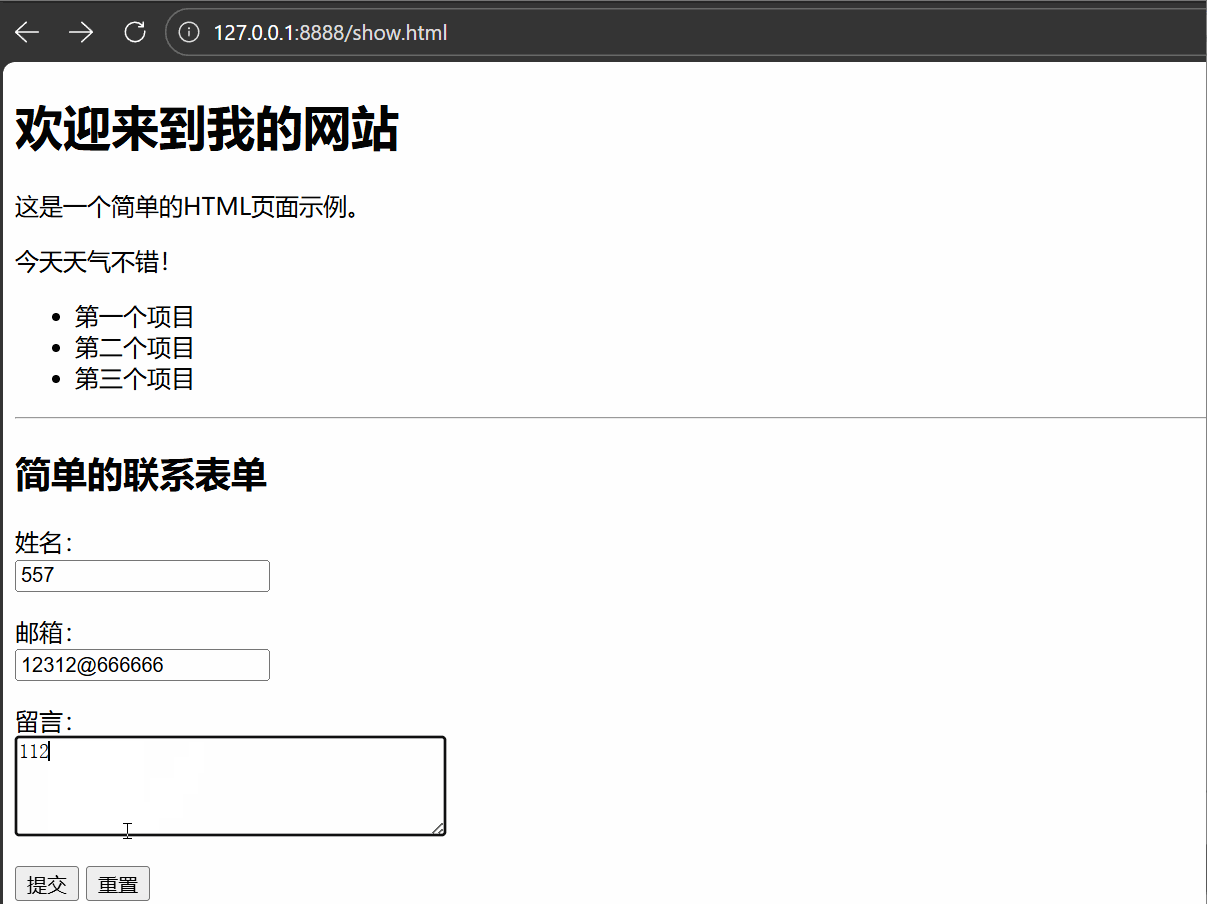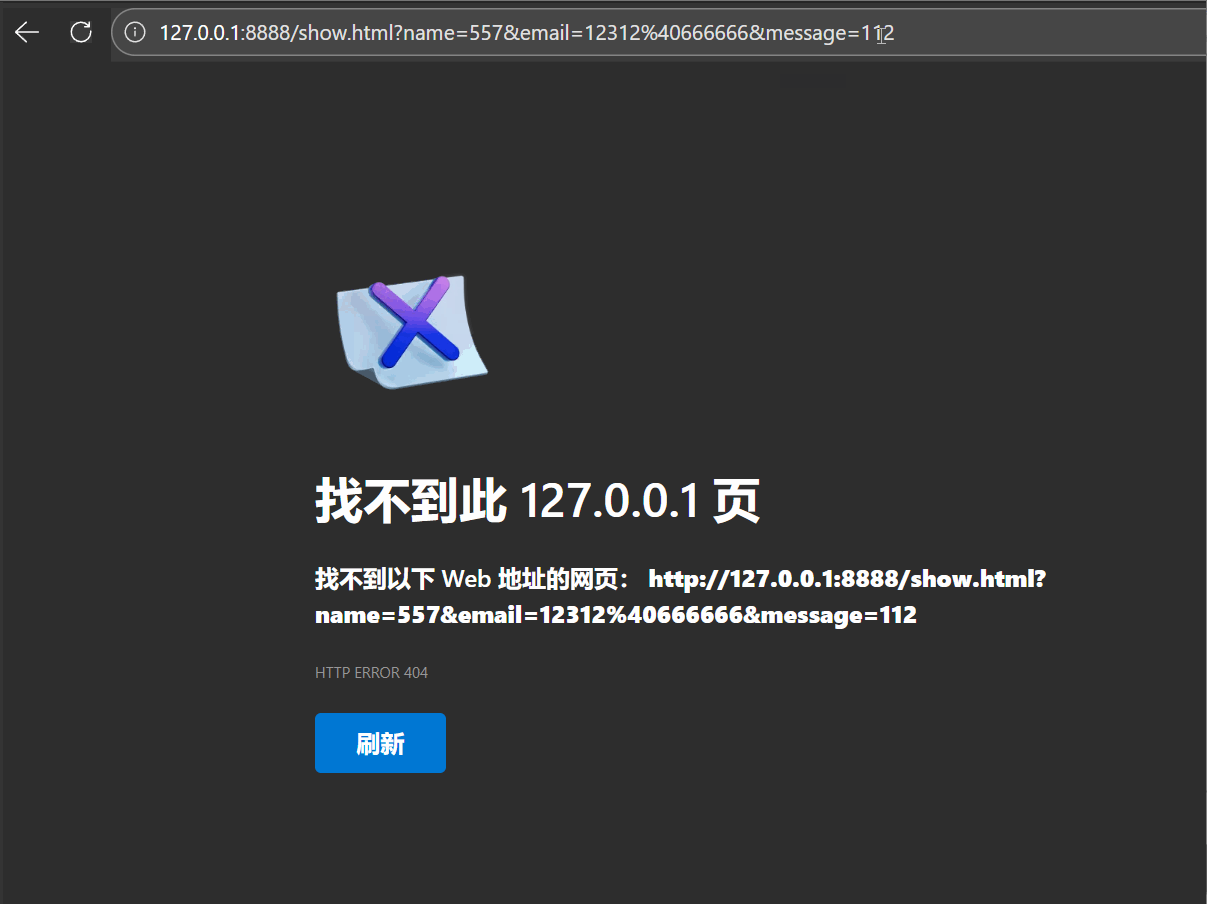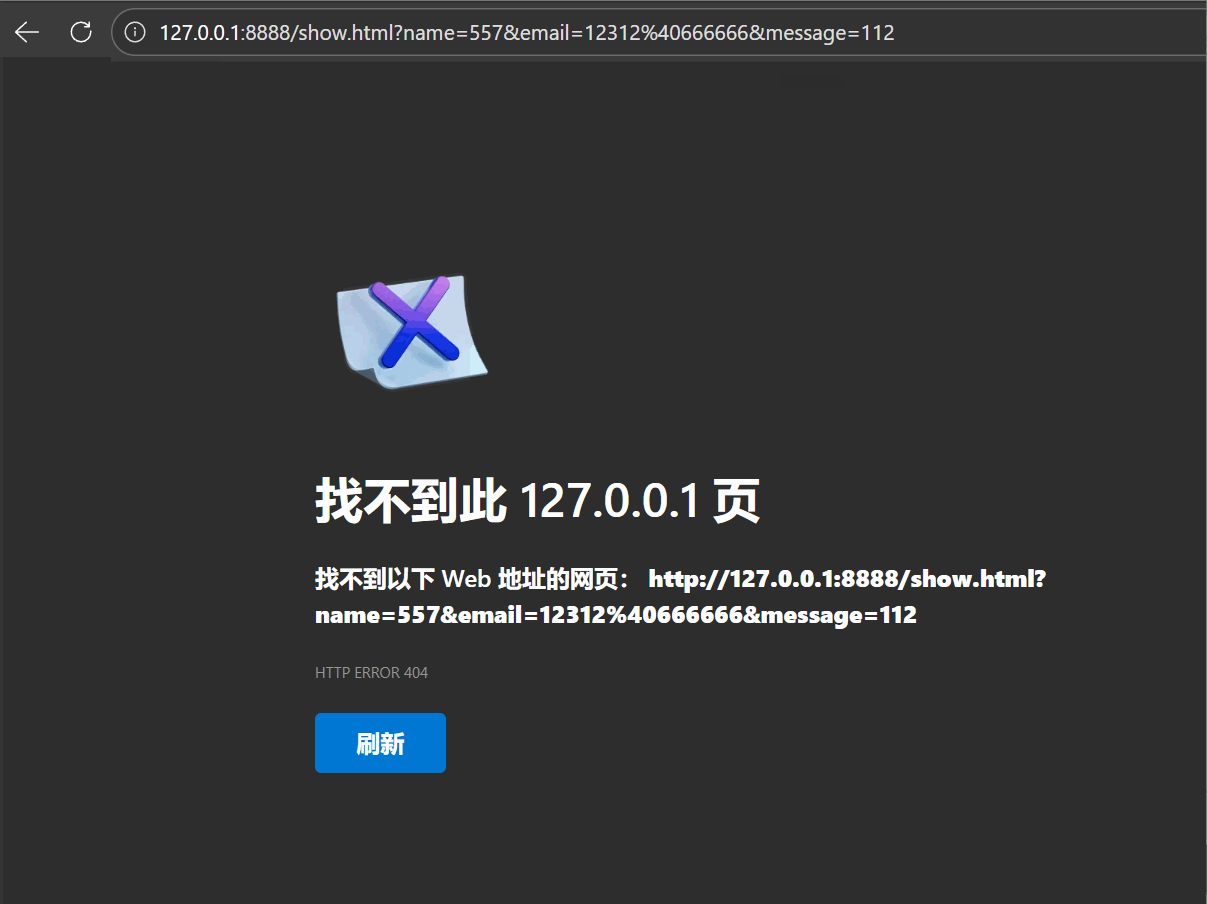
同时,服务器将收到如下数据
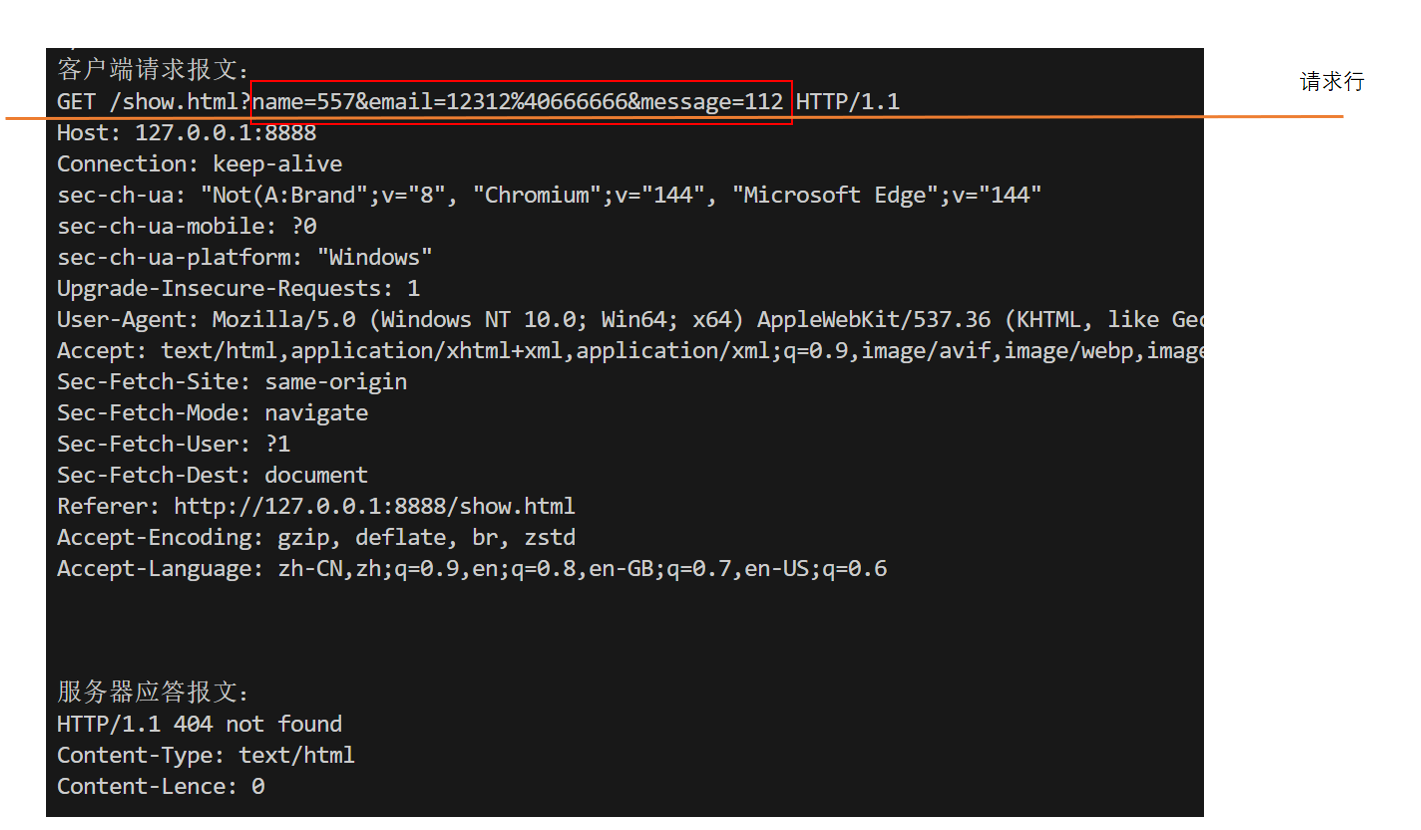
- POST:适合"写操作",参数在正文传输,体量无明显限制;
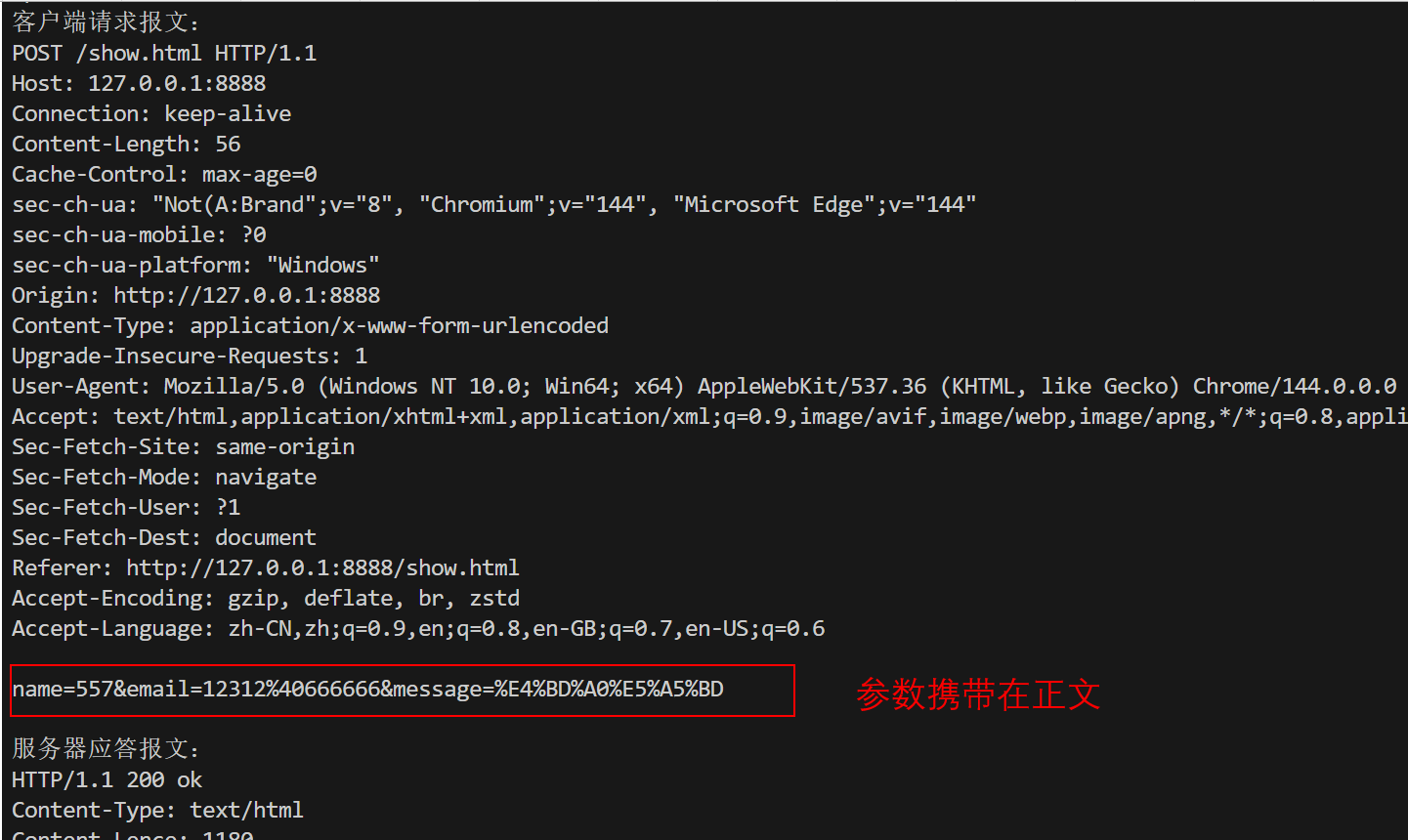
POST方法参数在正文,相对于GET方法较为安全,但是两者本质都不安全,因为是明文传输,被抓包后就可以直接看到。想要更好的安全性可以使用HTTPS协议,是加密的协议,与HTTP类似但是更安全。
前端提交方式
前端可通过form表单提交请求,默认使用GET方法;若需使用POST,需在表单中显式指定方法,参数会通过请求正文传递。
前文中展示的网页代码:
若要使用post方法提交表单,则将method = "get"改为 method = "post"
html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>简单网页 - 带表单</title>
</head>
<body>
<h1>欢迎来到我的网站</h1>
<p>这是一个简单的HTML页面示例。</p>
<p>今天天气不错!</p>
<ul>
<li>第一个项目</li>
<li>第二个项目</li>
<li>第三个项目</li>
</ul>
<hr>
<h2>简单的联系表单</h2>
<form action="/show.html" method="get">
<p>
<label for="name">姓名:</label><br>
<input type="text" id="name" name="name">
</p>
<p>
<label for="email">邮箱:</label><br>
<input type="email" id="email" name="email">
</p>
<p>
<label for="message">留言:</label><br>
<textarea id="message" name="message" rows="4" cols="40"></textarea>
</p>
<p>
<input type="submit" value="提交">
<input type="reset" value="重置">
</p>
</form>
<p><small>注意:这是一个示例表单,提交后不会有实际效果,除非您设置了相应的后端处理程序。</small></p>
</body>
</html>五、Cookie与Session:解决HTTP无状态问题
HTTP协议本身是无状态、无连接的:服务器不记录客户端的历史访问记录,每次请求都是独立的。
有些网站的资源在访问时,需要进行身份识别,分类响应。比如视频网站,有的视频需要会员才可以观看,有的则不需要,客户端在请求时,服务器必须能正确识别身份才可以响应请求。而HTTP协议是无状态,无链接的,他不知道用户此时是什么身份,此时就要用到cookie和session技术(登录会话管理),它可以让用户登陆一次,在关闭网页后一段时间内仍然可以保持登陆状态
1. HTTP无状态的体现
客户端多次请求相同资源,服务器会重复响应,无法识别"该客户端是否曾访问过",即无法关联多次请求的用户身份。
2. Cookie技术
Cookie是存储在客户端的用户信息,核心原理如下:
登录阶段:用户首次登录后,服务器在响应头中携带Set-Cookie的报头(相当于服务器向客户端写入信息),浏览器识别后保存Cookie;
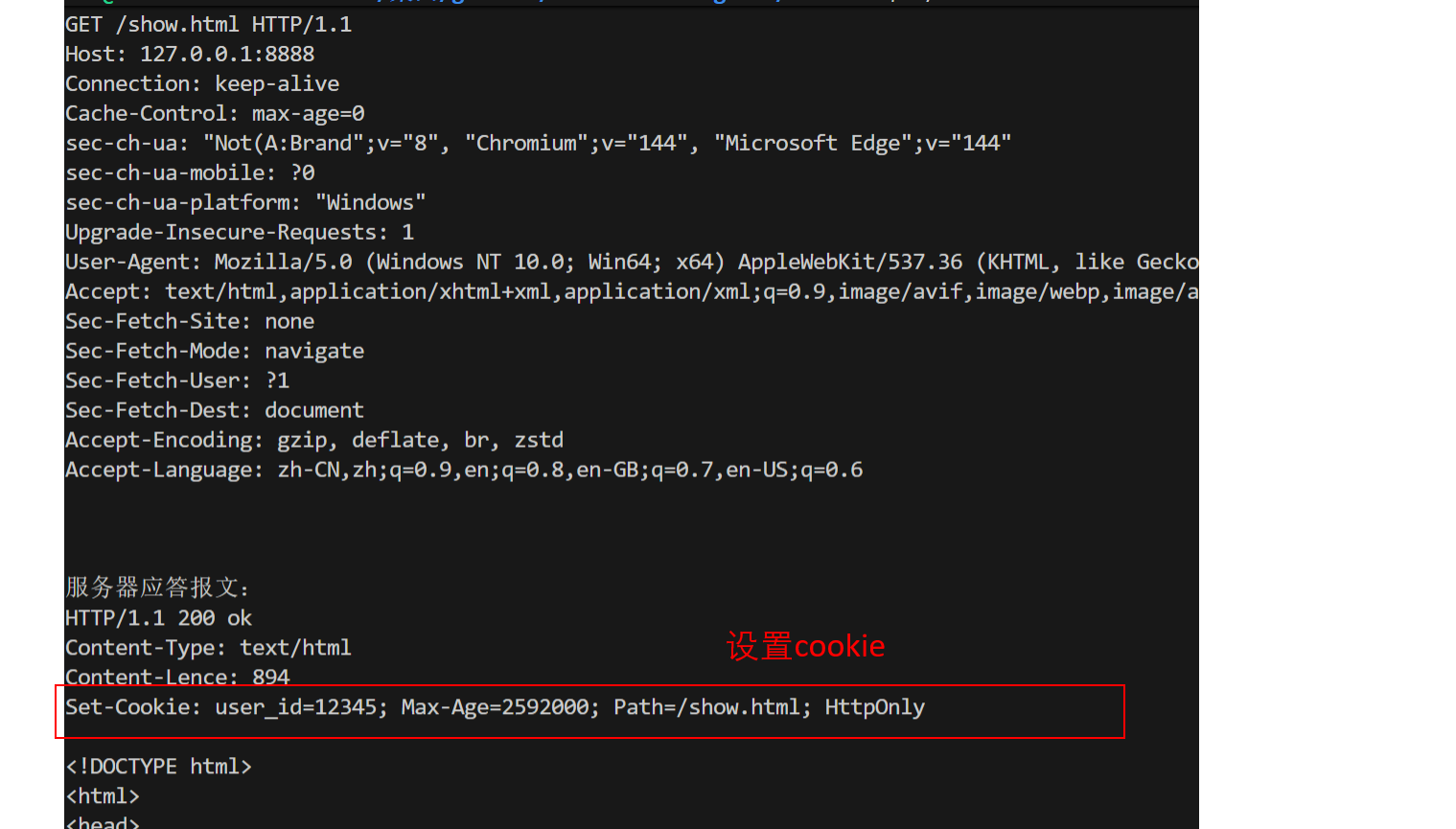
访问阶段:设置cookie成功后,浏览器会自动的将用户基本信息作为http请求的一部分进行拼接,这样服务器就可以对每次请求进行身份识别,实现资管推送的管理,直到该cookei失效
设置成功如下图:
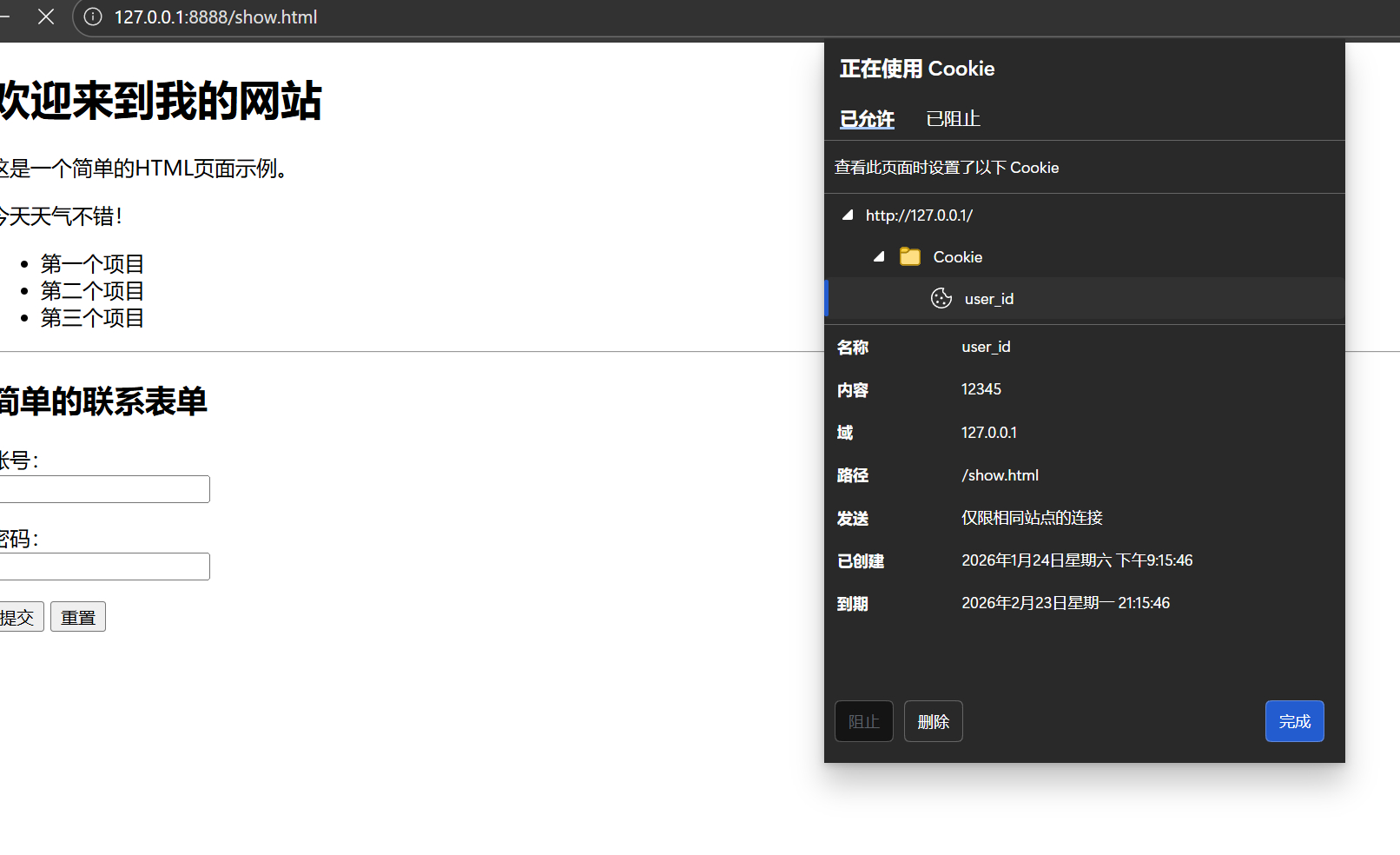
之后,客户端的请求报文中会自动携带cookie数据,如下图
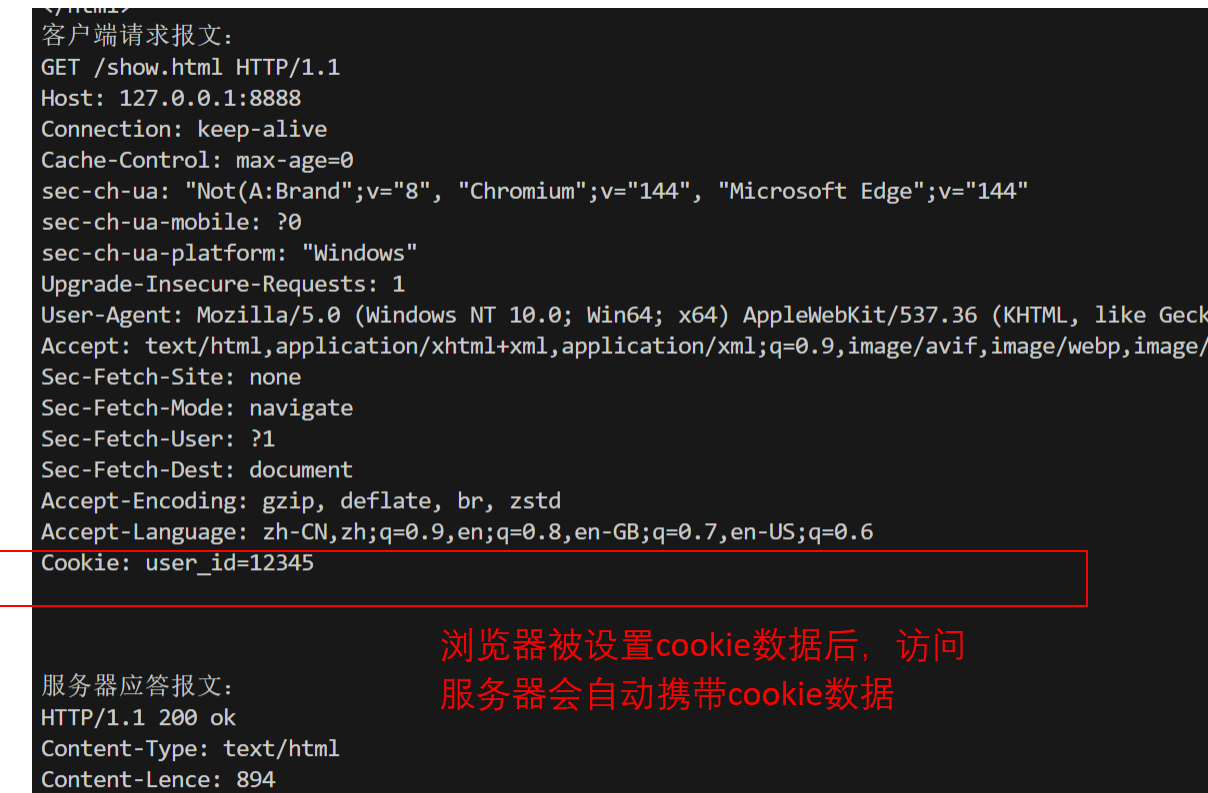
那么浏览器将cookie信息保存在那里呢?
内存级(浏览器关闭后,cookei失效)
文件级(在浏览器自己的工作目录下保存在文件中,浏览器关闭后在打开,可以读取文件,将cookie信息写入内存,访问服务器时进行携带信息)
- 补充:Cookie可设置过期时间、提交路径,支持多条Cookie同时设置(添加多行cookie响应报头),但单独使用存在安全风险,且存储容量有限(仅几KB)。
完整的设置cookie响应报头格式:
cpp
Set-Cookie: <cookie-name>=<cookie-value>; Expires=<expiry-date>; Max-Age=<max-age-in-seconds>; Domain=<domain-value>; Path=<path-value>; Secure; HttpOnly; SameSite=<same-site-value>其中,只有< cookie-name>=< cookie-value>是必需的,其他属性都是可选的。
各属性说明:
- < cookie-name>=< cookie-value>:Cookie的名称和值。
- Expires:Cookie的最长有效时间,形式为符合HTTP-date规范的时间戳。例如:Expires=Wed, 21 Oct 2015 07:28:00 GMT
- Max-Age:Cookie从设置开始计时的生存时间,单位为秒。如果同时设置了Expires和Max-Age,Max-Age优先级更高。
- Domain:指定Cookie可以送达的主机名。如果没有指定,默认为当前文档访问地址中的主机部分(不包含子域名)。如果指定了Domain,则一般包含子域名。
- Path:指定一个URL路径,这个路径必须出现在要请求的资源的路径中才可以发送Cookie首部。字符%x2F(即"/")用作文件夹分隔符,子文件夹也会被匹配到。
- Secure:一个带有安全属性的Cookie只有在使用SSL和HTTPS协议的时候才会被发送到服务器。
- HttpOnly:设置后,无法通过JavaScript的Document.cookie API访问Cookie,这有助于防范跨站脚本攻击(XSS)。
- SameSite:允许服务器设定何时发送Cookie,以防止跨站请求伪造攻击(CSRF)。可选值:Strict, Lax, None
完整报头示例:
cpp
Set-Cookie: user_id=12345; Max-Age=2592000; Expires=Wed, 31 Dec 2025 23:59:59 GMT; Path=/; Domain=.example.com; Secure; HttpOnly; SameSite=Lax3. Session技术
光有cookie不安全,因为cookie在报文中明文保存,别人抓包了会泄露数据,因此引入了Session技术。
Session是服务器端的会话管理技术,解决Cookie的安全性和容量问题,核心原理如下:
首次访问:
服务器生成唯一sessionid,通过Set-Cookie写入客户端;同时服务器将用户信息直接存储在服务器上,不再通过cookie写入客户端,而是维护sessionid与用户信息的映射关系,;
后续访问:
客户端请求时携带sessionid,服务器通过该ID匹配用户信息,实现身份识别;
优势:
用户核心信息存储在服务器端,无需将用户数据在网络中传输,只传输sessionid,更安全,且服务器上无Cookie的容量限制。