目录
[3.1. 词嵌入(Word Embedding)](#3.1. 词嵌入(Word Embedding))
[3.2. 循环神经网络(Recurrent Neural Networks,RNN)](#3.2. 循环神经网络(Recurrent Neural Networks,RNN))
[3.3. 可视化神经机器翻译模型(Visualizing A Neural Machine Translation Model)](#3.3. 可视化神经机器翻译模型(Visualizing A Neural Machine Translation Model))
[3.4. 注意力(Attention)](#3.4. 注意力(Attention))
[3.5. 自注意力(Self-Attention)](#3.5. 自注意力(Self-Attention))
[3.6. 多头自注意力机制(Many Heads Self-Attention )](#3.6. 多头自注意力机制(Many Heads Self-Attention ))
[3.7. 残差(Residual)](#3.7. 残差(Residual))
[3.8. 小结](#3.8. 小结)
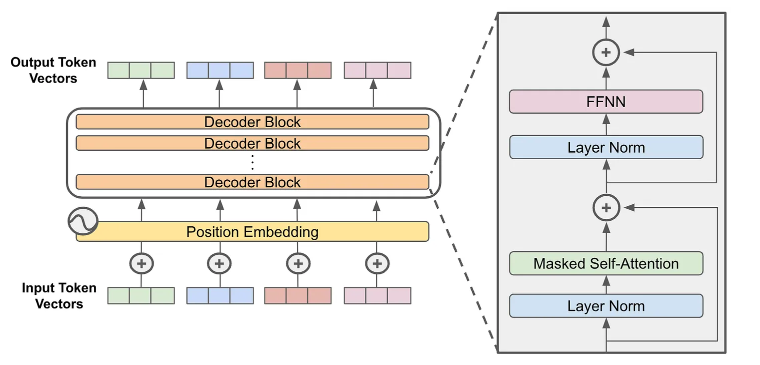
[4.Only Decoder Transformer](#4.Only Decoder Transformer)
[4.1. 掩码自注意力机制(Masked Self-Attention)](#4.1. 掩码自注意力机制(Masked Self-Attention))
[4.2. 注意力头(Attention Heads)](#4.2. 注意力头(Attention Heads))
[4.3. 分词(Tokenization)](#4.3. 分词(Tokenization))
[4.4. 词元嵌入和位置嵌入(Token Embedding & Position Embedding)](#4.4. 词元嵌入和位置嵌入(Token Embedding & Position Embedding))
1.LLM简介
LLM(Large Language Model)大型语言模型 (LLM )是一种利用自监督机器学习 方法,基于海量文本训练而成的语言模型,专为自然语言处理 任务而设计,尤其适用于语言生成。
更多介绍参考维基百科:https://en.wikipedia.org/wiki/Large_language_model
2.结构鸟瞰
以主流 decoder-only Transformer(GPT/LLaMA/Qwen 系)为例,最核心的结构可以抽象成:
Text → Tokenizer → token ids → Embedding(+Pos) → N×Transformer Block → logits → sampling → next token
Transformer Block 通常是两大子层(外加残差与归一化):
Self-Attention 子层:把序列中任意位置的信息按"相关性"混合,形成上下文表示(contextual representation)。
MLP/FFN 子层:对每个位置的表示做非线性变换(现代实现多用 SwiGLU/GeLU 等变体,属于工程细节可后看)。
3.Transformer
参考内容: https://jalammar.github.io/illustrated-transformer/?utm_source=chatgpt.com
3.1. 词嵌入(Word Embedding)
参考内容:
https://medium.com/deeper-learning/glossary-of-deep-learning-word-embedding-f90c3cec34ca
简而言之,神经网络是不认识单词和字符的,计算机只认识数字。词嵌入就是把单词转换成数字(向量),并且在空间中相关的单词距离会更近。
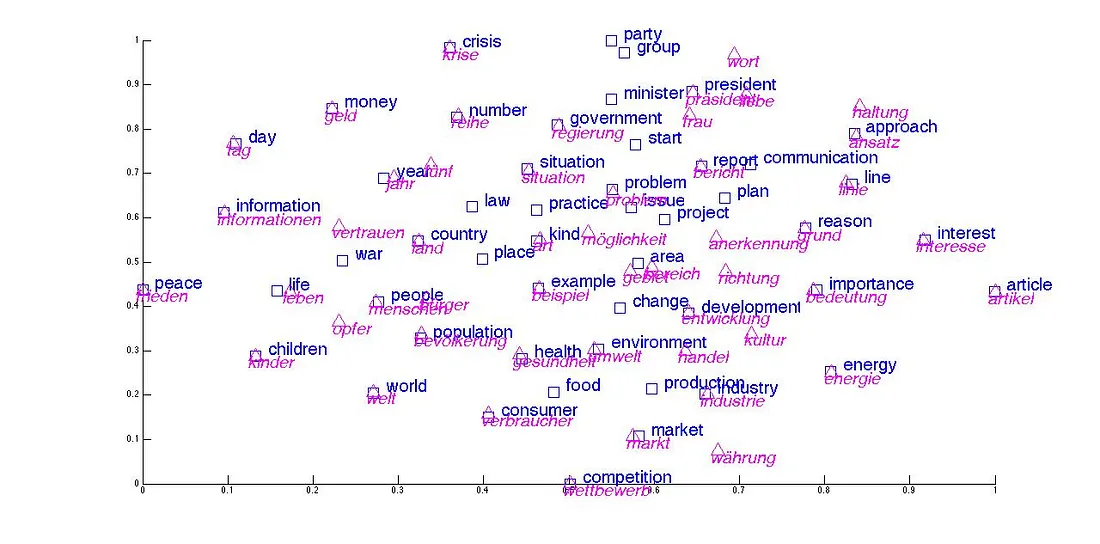
经典word2vec(单词to向量)嵌入算法
神经网络一般划分为:输入层 、隐藏层 、和输出层 。假设我们有10000个单词和300个神经元,对于每一个单词,都会在所有的神经元中进行传递,因此需要所有神经元的参数集合来确定一个单词,简称分类。
而对于所有单词的神经元参数表示之和,我们称之为嵌入矩阵,则在本场景中嵌入矩阵的规模就是10000×300。当我们想要直到某个单词在计算机中的表示(编码)是什么的时候,我们只需要查询嵌入矩阵表即可。
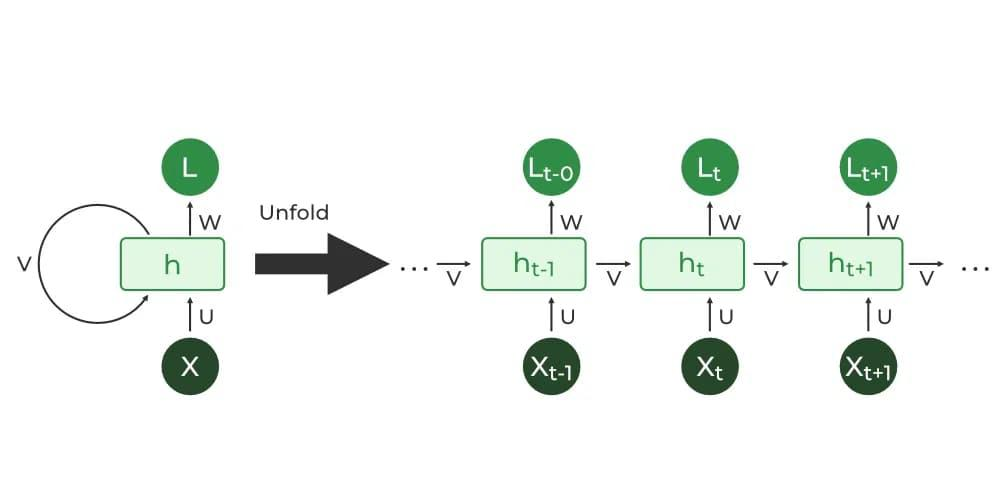
3.2. 循环神经网络(Recurrent Neural Networks,RNN)
通俗来讲,RNN(循环神经网络)就是一个"读一句话的翻译员",**每读一个词就更新一次脑内记忆。**这份记忆(状态)会带到下一步继续用。
输入:
内部记忆:状态
递推更新:
对于RNN 的本身,可以做一个解释 :
就是"我读到第 t 个词时,对前面内容的总结"。
图片来源于:https://www.geeksforgeeks.org/nlp/stacked-rnns-in-nlp/
状态叠加:
- 旧记忆(
- 新输入(
- 更新函数
所以所谓"叠加",就是每一步把当前输入写入一个固定大小的记忆槽
SSM参考:https://blog.csdn.net/m0_62102955/article/details/152311142?spm=1001.2014.3001.5501
3.3. 可视化神经机器翻译模型(Visualizing A Neural Machine Translation Model)
可视化神经机器翻译模型,也是基于注意力机制的序列到序列模型(seq2seq)。序列到序列模型是一种接收一系列项目(单词、字母、图像特征等)并输出另一系列项目的模型。
在神经机器翻译中,序列(seq) 是指一系列单词,它们被逐一处理。同样,输出结果也是一系列单词。
context(上下文) 本质上是一个向量,编码器和解码器都是循环神经网络(RNN)。


为什么word2vec是单词变向量,而seq2seq一句话就是一个向量?
经典 RNN/LSTM/GRU 编码器的递推形式是:
所以"上下文只有一个向量"是因为:编码器只把最终隐状态
并且严格来说: 不能保证context精准包含所有的词,因此会出现信息瓶颈(information bottleneck)。
**另外,**两者解决的问题不同,学习目标也不同。
**word2vec:**学习分布式语义,进行词级别的表示粒度。
**seq2seq:**把输入序列映射到输出序列,进行句子级编码。
因为句子级别表示确实存在瓶颈,于是出现了Attention和后来的Transformer。
3.4. 注意力(Attention)
如果说Seq2seq模型(RNN)是只给解码器最终状态:
那么注意力机制就是让编码器输出整条状态序列:
解码器不再只能读最后的状态,而是能按需读取整条状态轨迹 ,因此显著缓解长序列丢信息的问题。这里指的是所有解码器都能获得全部编码状态。
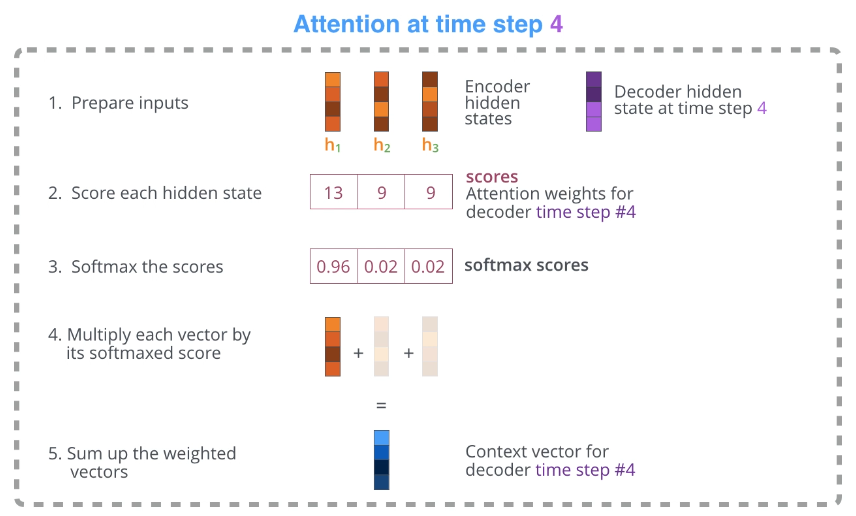
其次,注意力解码器 在输出之前会进行一个额外的步骤,为了专注于当前解码时间步 相关的输入部分,解码器会执行以下操作:
- 观察它接收到的编码器隐藏状态集合 ------每个编码器隐藏状态 都与输入句子中的某个特定词关联最为密切。
- 给每个隐藏状态打分(暂时忽略评分方式)。
- 将每个隐藏状态乘以其softmax得分,从而放大得分高的隐藏状态 ,并掩盖得分低的隐藏状态。
**时间步:**解码器在生成第t个输出词时的时刻。
**softmax:**常用的激活函数,用于拉大数值的区分度。
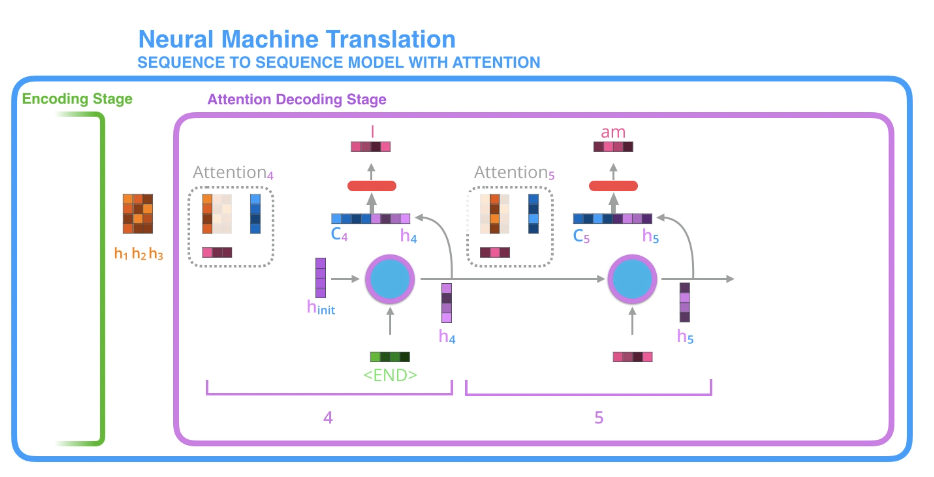
现在让我们将所有内容整合到下面的可视化图中,看看注意力过程是如何运作的:Encoding Stage:
假设编码器逐个读词,产生向量
所有
Attention Decoding Stage:
图中展示了两个解码时间步,分别生成了"I"和"am"。
解码器每一步生成一个词,通常会用到两类信息:
当前状态
上下文
Step 4: 生成"I"
- 解码器此时有初始状态
- 这个状态来源于编码器最后的整体信息。
- 比如对于
- 图中虚线框中条形块表示"关注强弱"
- 用这些权重把源句笔记做加权求和,得到
- 解码器把自己状态信息+源句上下文
Step 5: 生成"am"
同理:
得到
得到上下文
关键点:
每一步 attention 都可以"重新照源句",并且照的位置可以变。
所以翻译时能实现类似对齐:生成 "I" 可能主要看源句主语相关位置;生成 "am" 可能主要看谓语相关位置。
当解码器很靠后的时候,会不会"越到后面就少看一些"?
不会。注意力机制下:
**编码器输出的整本记事本
解码器在不同步、不同词上,只是"聚光灯权重"不同,而不是把记事本撕掉一页。
另外还要注意一点:
因为不同语言所包含的信息不同,或许会出现某种语言的一个词,对应另一种语言的多个词,所以一定要看完整的上下文,才能完成精准翻译,也是其精华所在。
3.5. 自注意力(Self-Attention)
The animal didn't cross the street because it was too tired
这只动物没有过马路,因为它太累了。这句话中的"它"指的是什么?是指街道还是动物?对人类来说,这是个简单的问题,但对算法来说却并非如此。当模型处理单词"它"时,自注意力机制使其能够将"它"与"动物"联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力机制使其能够查看输入序列中的其他位置,寻找有助于更好地编码该单词的线索。
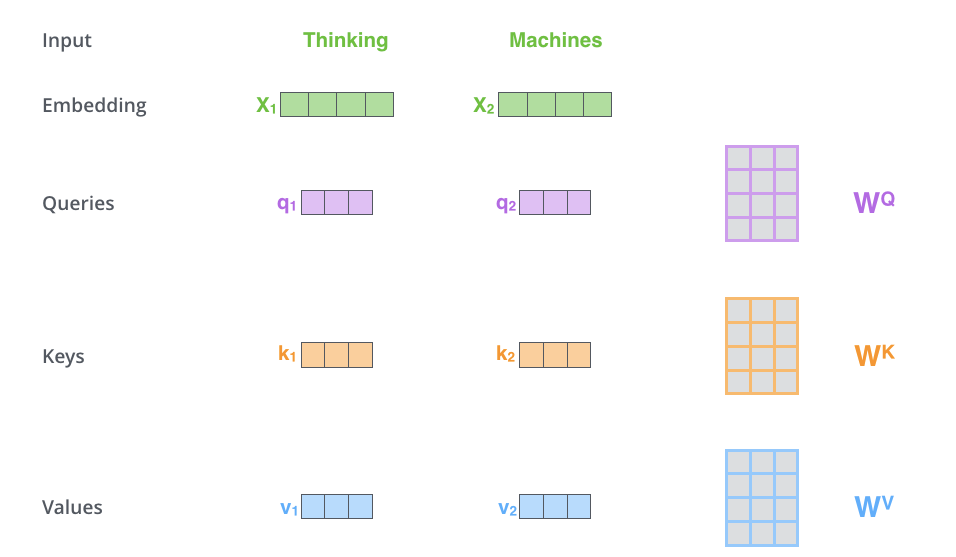
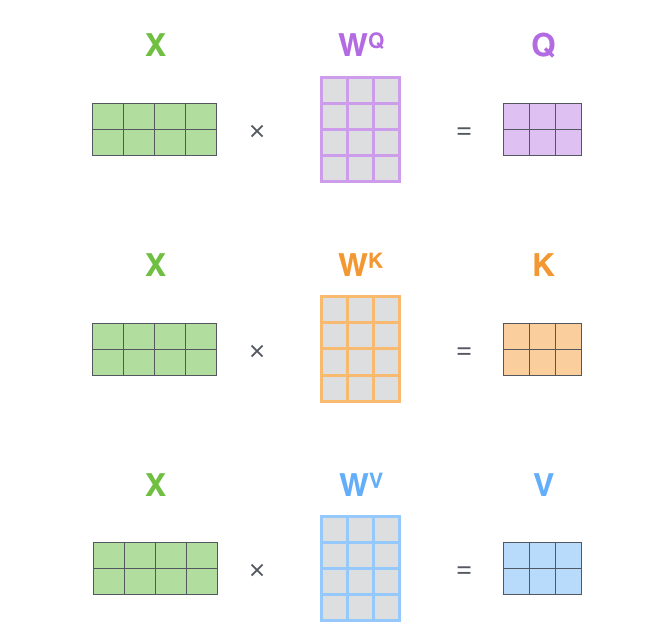
第一步:创建向量
根据编码器的每个输入向量(在本例中为每个词的词嵌入)创建三个向量。对于每个词,我们创建一个查询向量(Query) 、一个键向量(Key) 和一个值向量(Value) 。这些向量是通过将词嵌入 乘以我们在训练过程中训练的三个矩阵
请注意,这些新向量的维度比嵌入向量小 。它们的维度为 64,而嵌入向量和编码器输入/输出向量的维度为 512。它们并非必须更小,也并非一定是512和64,这仅仅是一种常见的工程架构选择,目的是使多头注意力机制的计算量(基本)保持恒定。
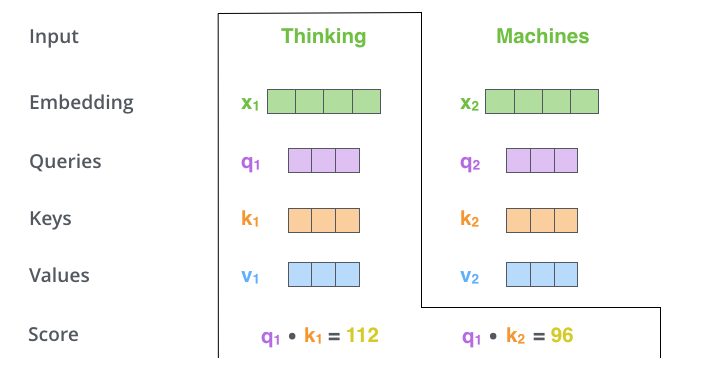
第二步:计算得分假设我们要计算本例中第一个词"Thinking"的自注意力。我们需要将输入句子中的每个词与这个词进行比较并给出得分。这个得分决定了在编码特定位置的词时,应该给予输入句子的其他部分多少关注。
得分计算方式为:
设我们要进行查询的单词
则对于任意单词
这里运算是点乘运算
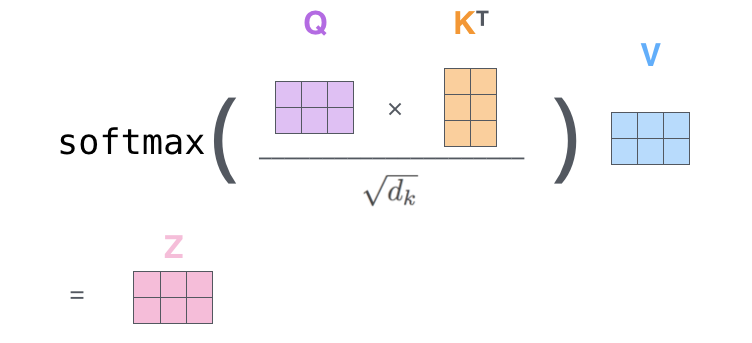
第三步和第四步:归一化这一步仅仅一个公式:
或者:
当且仅当
将结果输入到 softmax 操作中。softmax 操作会将分数归一化,使它们全部为正且总和为1。
这里我们还要强调一下softmax 为什么能做到归一化:对一组
也就是说,无论输入正负,通过softmax都能变成整数且所有元素之和为1。
第五步和第六步:计算V向量和Z向量将每个值向量乘以softmax得分为将它们相加做准备)。这里的目的是保持我们想要关注的词的值不变,并消除无关词的影响(例如,通过将它们乘以0.001这样的小数)。
将加权值向量相加。这就产生了该位置(第一个词)自注意力层的输出。
至此,自注意力机制的计算就完成了。我们可以将得到的向量传递给前馈神经网络。
为了方便理解,我们做两种形象化的比喻:
1. 直观来讲
q向量代表:x向量表示的是什么意思/需要什么信息。
k向量代表:x的关键词(用来快速检索x)。
v向量代表:x可以被引用的内容。
最后输出 (注意力输出)就是:位置
这一段改写后的内容 = 我根据自己的需求,从全局所有笔记里挑选(加权汇总)出来的引用内容。
2.上下文补全
在 Transformer 里,每个位置的表示要回答一个问题:
"这个 token 在当前上下文里到底是什么意思?"
举例:英文里 "bank" 在不同上下文含义不同。仅靠词向量 xix_ixi 很难确定。注意力层让它做一件事:
-
用
-
把这些相关位置的语义(
因此就是:
"
它是经过注意力层"阅读上下文后"的版本,所以天然被当作该层的输出。
另外真正的自注意力在计算时,为了加速是以矩阵形式进行的:
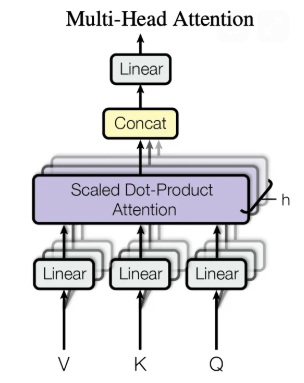
3.6. 多头自注意力机制(Many Heads Self-Attention )
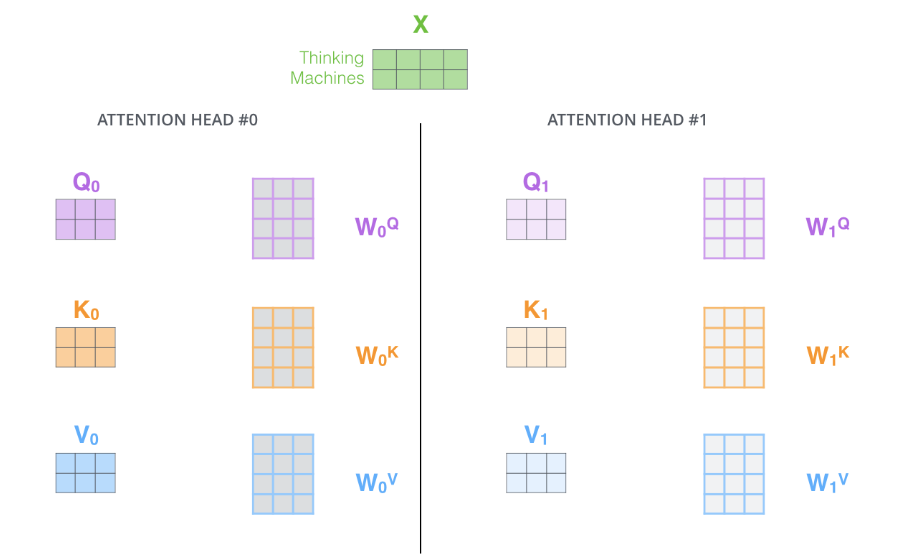
一个嵌入向量矩阵,对应一组K,Q,V,就是自注意力机制。
那么,一个嵌入向量矩阵,对应多组K,Q,V,就是多头自注意力机制。
这里我们强调:
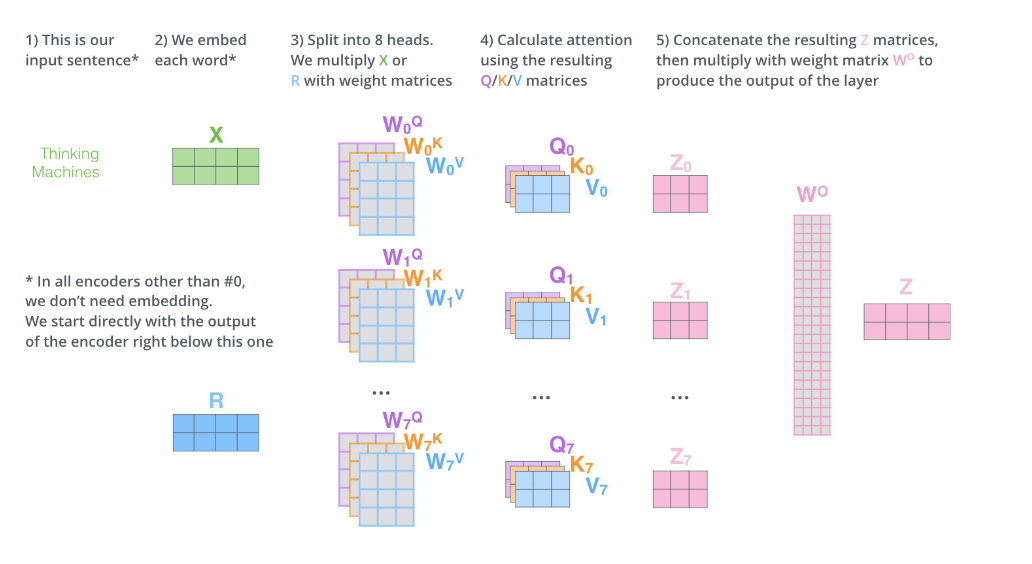
如果我们重复上述自注意力计算,每次使用不同的权重矩阵,重复八次,最终会得到八个不同的 Z 矩阵。这就给我们带来了一些挑战。前馈层并不期望接收到八个矩阵,它期望的是一个矩阵(每个词对应一个向量)。因此,我们需要一种方法将这八个矩阵合并成一个矩阵。
我们该如何实现呢?我们将矩阵连接起来,然后乘以一个额外的权重矩阵
3.7. 残差(Residual)
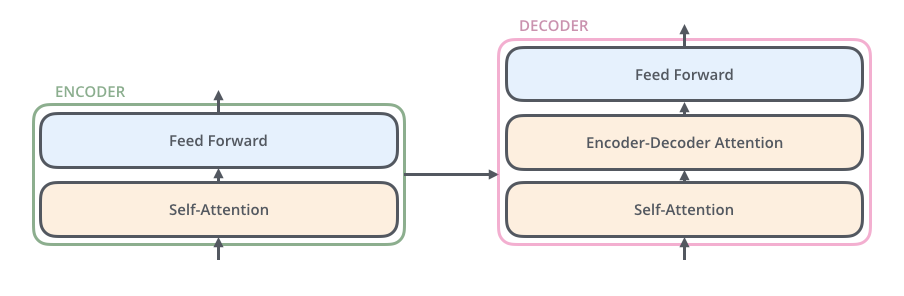
需要提及编码器架构中的一个细节,即每个编码器中的每个子层(自注意力、ffnn)周围都有一个残差连接,并且之后会进行层归一化步骤。
图中每个子层(Self-Attention、Feed Forward)后面都有 Add & Normalize:
- Add:做残差相加
- Normalize:做 LayerNorm(让数值稳定)
典型公式:
这里:
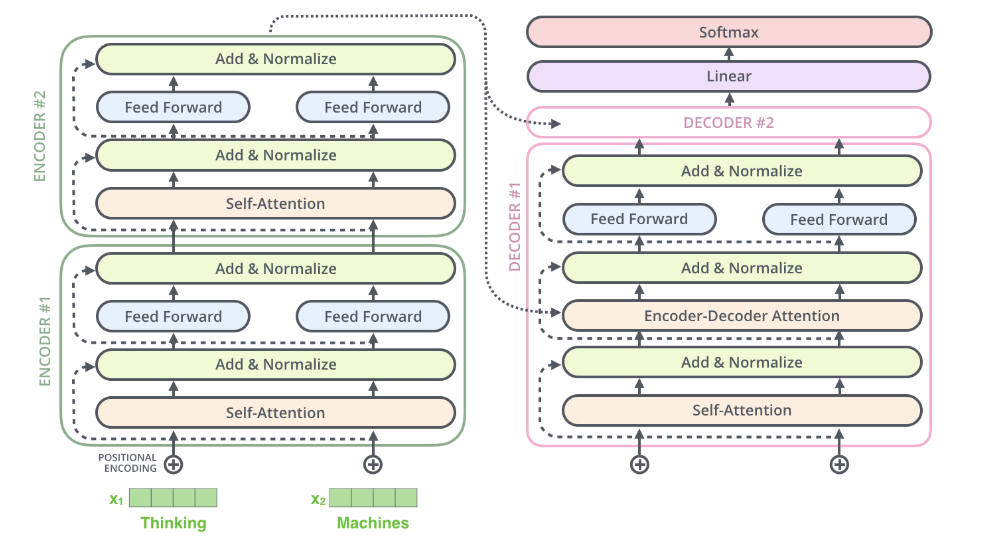
简单比喻一下:
-
自注意力:给每个词查资料、做引用摘要
-
残差:把"原句"保留,然后把"引用摘要"贴在旁边当补充
-
LayerNorm:整理排版,避免数值发散
3.8. 小结
本章节主要以NMT(机器翻译) 的视角对Transformer的基本技术做了一个串接,而Transformer是LLM的重要组成部分,对于它的学习我们值得付出一定的时间。通过对Jay Alammar、Jaron Collis的文章进行了翻译理解和拓展,我们对Transformer应该有了一个初步的认识。
但是这知识开始,我们学到的"教科书"级别的Transformer并非LLM中的Decoder-only Transformer,因此我们还需要做一个过渡,再深入探索。
4.Only Decoder Transformer
参考内容: https://cameronrwolfe.substack.com/p/decoder-only-transformers-the-workhorse
4.1. 掩码自注意力机制(Masked Self-Attention)
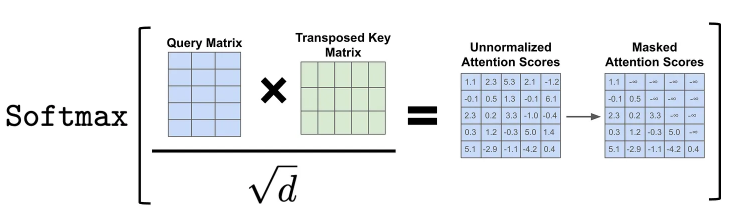
仅解码器(Decoder-only)Transformer使用一种称为掩码(或因果)自注意力机制的自注意力变体。正如第3章所说,普通的注意力机制允许在计算注意力分数时考虑序列中的所有标记,但掩码自注意力机制通过**"屏蔽"序列中给定标记之后的标记**来修改底层注意力模式。
通俗点说,当对第
如图,
这个屏蔽的具体方法就是在对该矩阵的每一行执行softmax 操作之前,我们可以将注意力矩阵**对角线以上的元素值全部设置为负无穷大,**这样它们的注意力得分均为零。
4.2. 注意力头(Attention Heads)
我们目前描述的注意力操作使用 softmax 函数对序列中计算出的注意力分数进行归一化。虽然这种方法可以形成有效的概率分布,但也限制了自注意力机制关注序列中多个位置的能力------概率分布很容易被一个词或者几个词所主导。
可以用一个直观例子理解:在归一化前,我们得到一组得分,计算得出后两个的占比几乎为0,这就会让
主导。
直观上来讲,单个注意力是在捕捉关系。多头注意力是为了并行捕捉多种关系,覆盖更多位置,学习稳定的模式。
对于注意力头的相关参数,可表示如下:
存在token的维度为
对于token 的维度,我们不能只停留在自注意力 的**词嵌入,**事实上,token的生成,是LLM中相当重要的阶段之一,我们会在下面继续讲。
4.3. 分词(Tokenization)
Transformer 接收原始文本作为输入。处理文本的第一步是将其分词,即将其转换为一系列离散的词或子词。这些词和子词通常被称为词元(token)。
这里每个蓝色小方块就是一个 token。注意:token 不一定等于一个完整的英文单词,它可能是:
一个完整词(如
are、cool)一个词的一部分(子词),例如LLMs被拆开(图里#s表示"s 这个后缀片段")
**子词(subword)**是一种策略,为了防止此表爆炸和未知词的出现:
- 世界上新词、拼写变体、专有名词太多,词表会变得极大,训练与部署成本很高。
- 模型会频繁遇到没见过的词。如果按词切分,这些词无法编码,而子词可以把它拆成更小的已知片段,仍能表达。
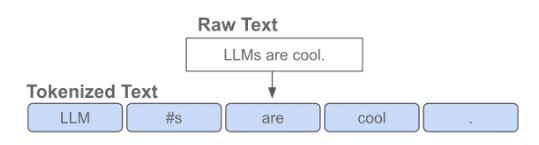
所以现代 LLM 普遍采用 BPE / SentencePiece / WordPiece 这类子词算法:把高频的字符片段合并成 token,让"常见词尽量是一个 token、不常见词可以拆成多个 token"。
另外,Tokenization的输出不是字符,而是词/子词在词表中的ID。
["LLM", "s", "are", "cool", "."] -------------------------------- [19342, 29, 389, 1234, 13]随后模型才会做下一步:把 token ids 查表变成向量(Embedding),进入 Transformer 计算。
Token的维度其实是指embedding后的维度,Token本身其实是被拆分的句子,是词/子词。
4.4. 词元嵌入和位置嵌入(Token Embedding & Position Embedding)
还是拿这个举例子,截止到Tokenization,模型到手只有一串数,下一步就是如何把数变成向量。
Token Embedding:
["LLM", "s", "are", "cool", "."] -------------------------------- [19342, 29, 389, 1234, 13]模型有一张可学习的Embeding表(向量词典):
规模为:
其中:
对每个 id 做一次查表:
id=19342 ------> 向量
id=29 ------> 向量
...
id=13 ------>向量
把它们堆叠起来,就得到一个矩阵:
token embedding只表达"这是什么 token",但还没表达"它在第几个位置"。
Position Embedding:自注意力(self-attention)有一个关键性质:它本身不关心顺序。如果你把一堆 token 向量打乱顺序丢进去,注意力层从数学结构上并不会自动知道"谁在前谁在后"。
位置嵌入/位置编码的目的,是把**"顺序"**注入模型。
经典做法是:绝对位置向量相加
生成每个Token的位置向量
对于最终输入的内容:
也就是:嵌入向量+位置向量。
最终的
到这里,Token的含义和处理就告一段落了,我们会把处理出来的嵌入向量输入给4.1. 中描述的掩码自注意力网络( Causal Mask,因果遮罩**)。** 在其内部,Position embedding:告诉模型"顺序是什么",Causal mask:规定信息流"只能从左到右",即第个位置只能看
的内容。
4.5. LLM基本成型
在上文相关知识的学习下,LLM我们基本有眉目了:
1.语句输入,划分为Token(词,子词),对Token进行Embedding,并加入位置Embedding信息
2.输入进堆叠的Decoder,先做归一化稳定数值,然后输入到掩码注意力学习上下文关联
3.做归一化稳定数值,进入前馈神经网络,FFN 的输出同样通过残差加回,并再做归一化。
4.每经过一层,表示都会再次经历"掩码自注意力的上下文检索 + FFN 的局部重组"。
5.通过所有 decoder blocks 之后,我们拿到最终的输出 token 向量(每个位置一个
6.如果是在训练阶段,会对每个位置的 logits 与真实的下一个 token 计算交叉熵损失,从而并行学习"下一 token 预测";如果是在推理生成阶段,通常只取最后一个位置的 logits,对其做 softmax 得到概率分布,然后用 greedy 或 temperature/top-p/top-k 等策略采样出下一个 token id。
7.最后,把新采样得到的 token id 追加到原序列末尾,重复同样的过程:再次得到新的输出 logits、再采样下一个 token,如此迭代,直到生成 EOS 或达到长度上限。整个过程中,因果掩码保证"当前只能用历史",而多层 block 负责把"历史信息"逐步加工成能支持下一 token 预测的表征。