Qwen3-TTS开源了一系列TTS模型,本文快速看一下【Qwen-TTS-Tokenizer】(语音表示基础)与【模型架构、训练与能力实现】两部分。

Qwen-TTS-Tokenizer
语音 Tokenizer 的核心作用是将连续的语音波形转换为离散的"语义-声学符号",既要保留语音的核心信息(说话人身份、韵律、内容),又要适配流式合成与低延迟需求。Qwen3-TTS 提出两种互补的 Tokenizer,分别针对"高质量合成"与"超低延迟流式"场景。
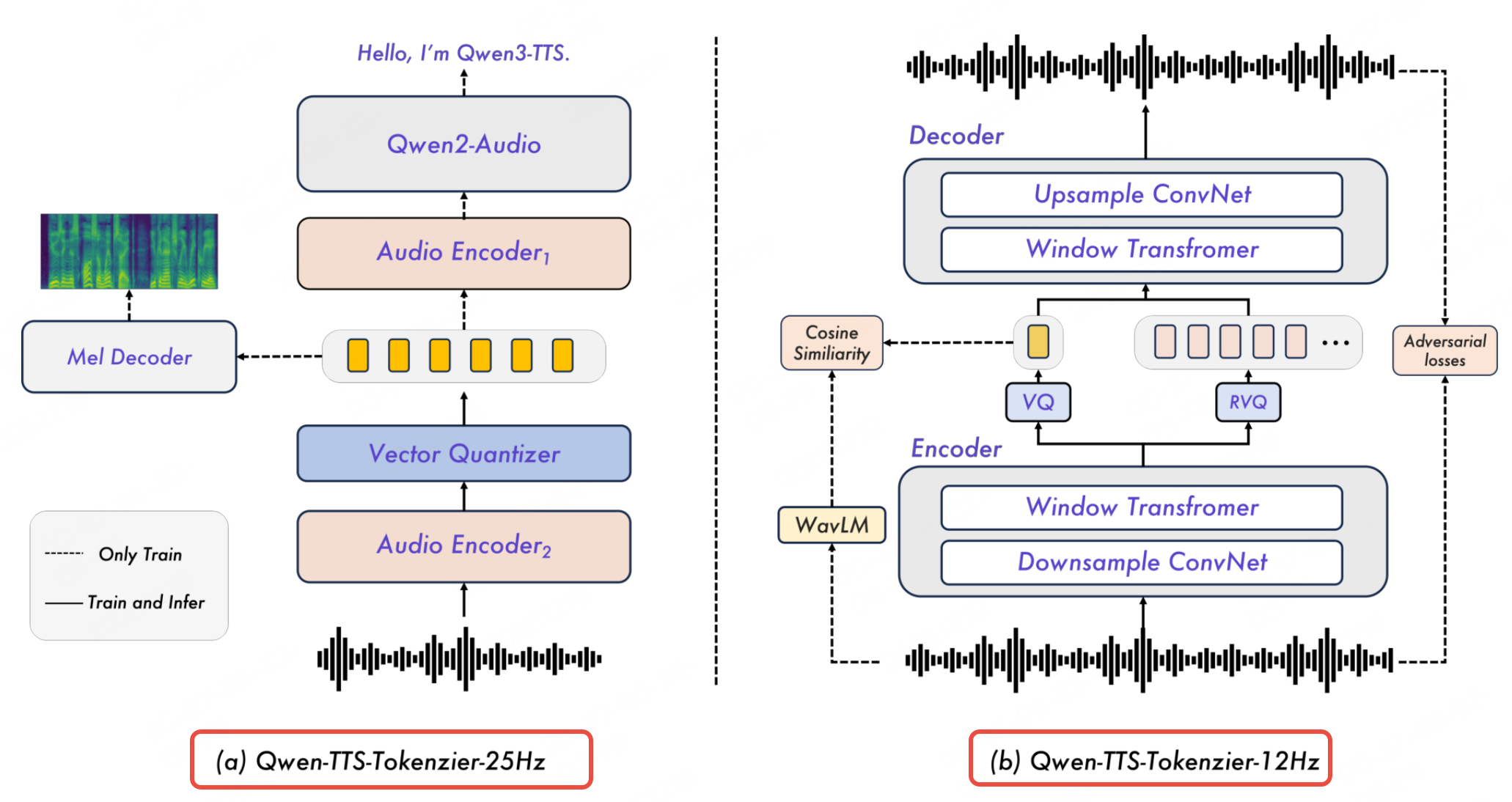
Qwen-TTS-Tokenizer-25Hz
Qwen-TTS-Tokenizer-25Hz的目标是在语义准确性 (支持多语言内容理解)与声学丰富度(支持高自然度合成)之间找平衡,适配长文本、高保真语音生成(如播客、有声书)。
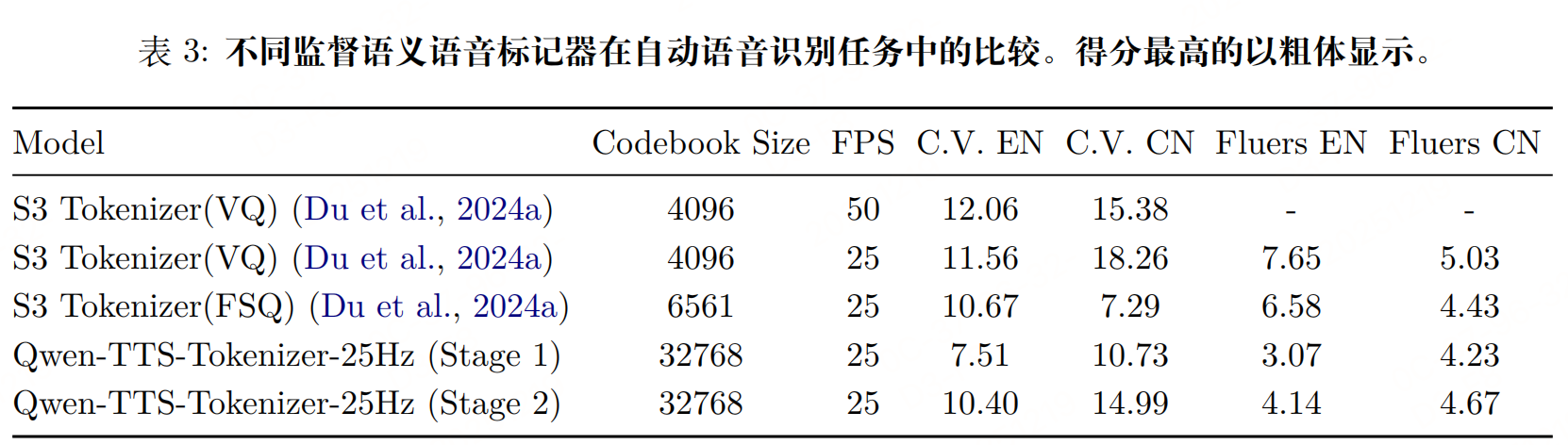
参数:25 Hz 采样率(每 40 ms 生成 1 个 Token)、单码本设计(码本大小 32768),基于 Qwen2-Audio 扩展。
Qwen-TTS-Tokenizer-12Hz
实现毫秒级首包延迟,适配实时交互场景(如语音助手、实时通话),同时保证基本自然度。
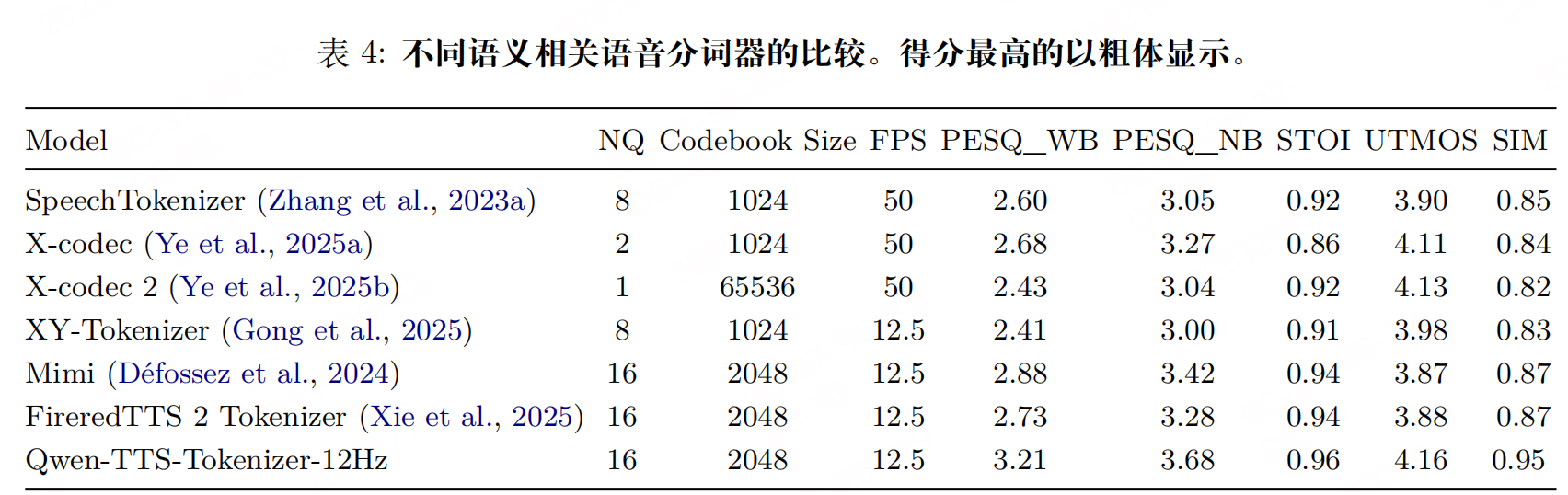
参数:12.5 Hz 采样率(每 80 ms 生成 1 个 Token)、16 层多码本设计(每层码本大小 2048),基于"语义-声学解耦"思路。
架构
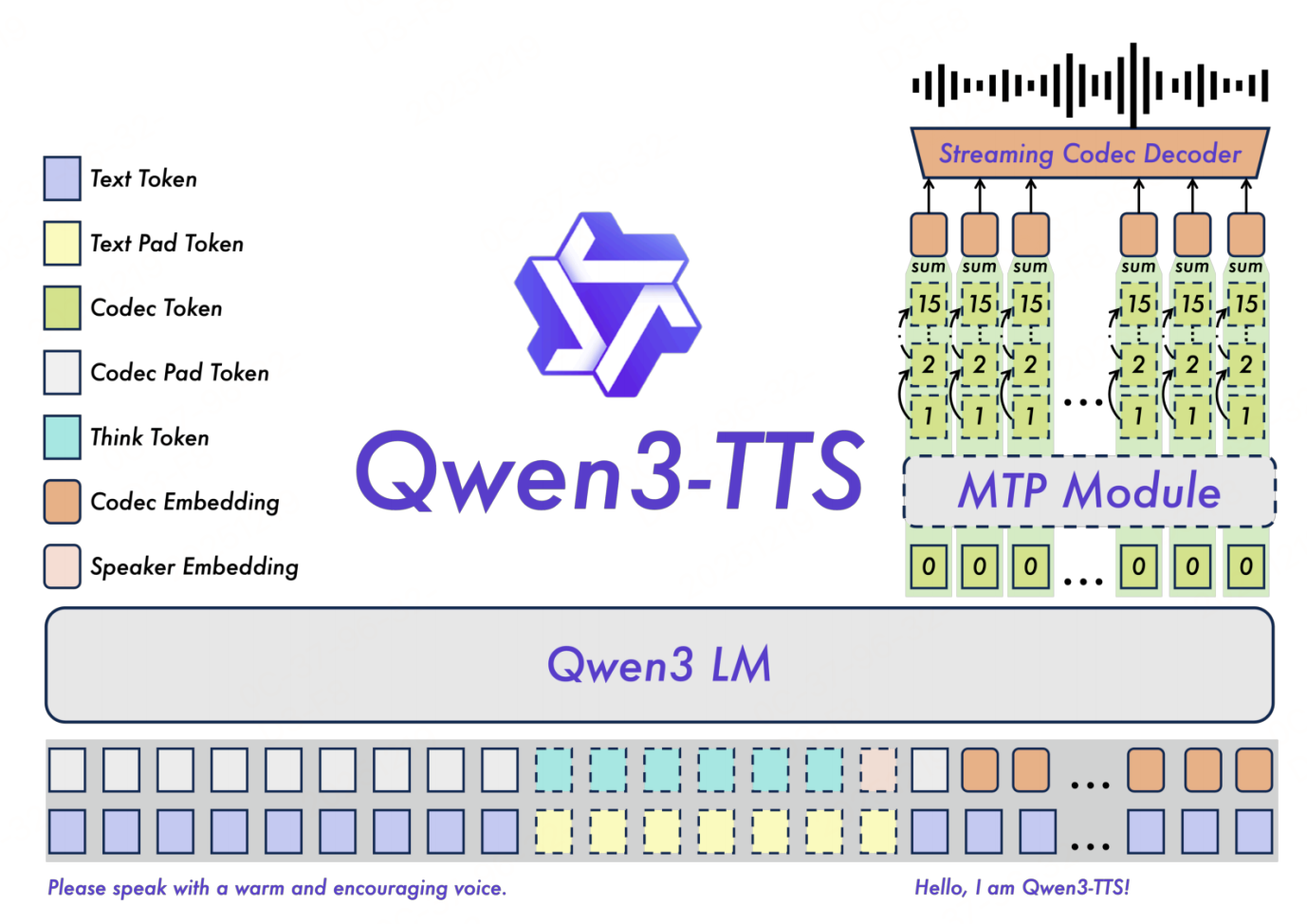
如上图,Qwen3-TTS(双轨 autoregressive 架构:文本-语音双轨融合) 基于 Qwen3-LLM 构建,既保留 LM 的指令理解能力,又实现语音的实时生成。
架构组件
- 文本处理:采用 Qwen 标准文本 Tokenizer,将输入文本(含控制指令)转换为文本 Token;
- 语音处理:接入 Qwen-TTS-Tokenizer-24Hz/Qwen-TTS-Tokenizer-12Hz,将语音(参考音频或生成目标)转换为语音 Token;
- 说话人编码器:与骨干模型联合训练,提取参考语音的说话人嵌入(Speaker Embedding),确保音色一致性;
- 双轨表示:将文本 Token 与语音 Token 在"通道维度"拼接,形成统一输入,使 LM 能同时建模"文本语义"与"语音风格";
- Code2Wav 模块:将生成的语音 Token 转换为最终波形(即 Qwen-TTS-Tokenizer-24Hz/Qwen-TTS-Tokenizer-12Hz 中的流式解码器)。
分模型架构差异(25Hz和12Hz)
因 Tokenizer 设计不同,Qwen3-TTS 衍生出两类模型,适配不同场景:
| 模型类型 | 语音 Token 处理方式 | 核心优势 | 适用场景 |
|---|---|---|---|
| Qwen3-TTS-25Hz | 单级语音 Token 预测: 文本特征 + 前序语音 Token → 当前语音 Token,再通过块 DiT 重建波形 | 高保真度、长文本稳定性好(语义-声学平衡) | 高质量合成(播客、有声书) |
| Qwen3-TTS-12Hz | 分层语音 Token 预测: 1. 骨干模型预测"语义码本(第 0 层)" 2. MTP 模块生成"声学码本(1-15 层)" | 超低延迟、音色一致性强(分层建模) | 实时交互(语音助手、客服) |
MTP 模块:Multi-Token Prediction(多 Token 预测),针对 12Hz 多码本设计,可一次性生成所有声学码本,避免逐码本预测的延迟累积,同时提升声学细节的连贯性。
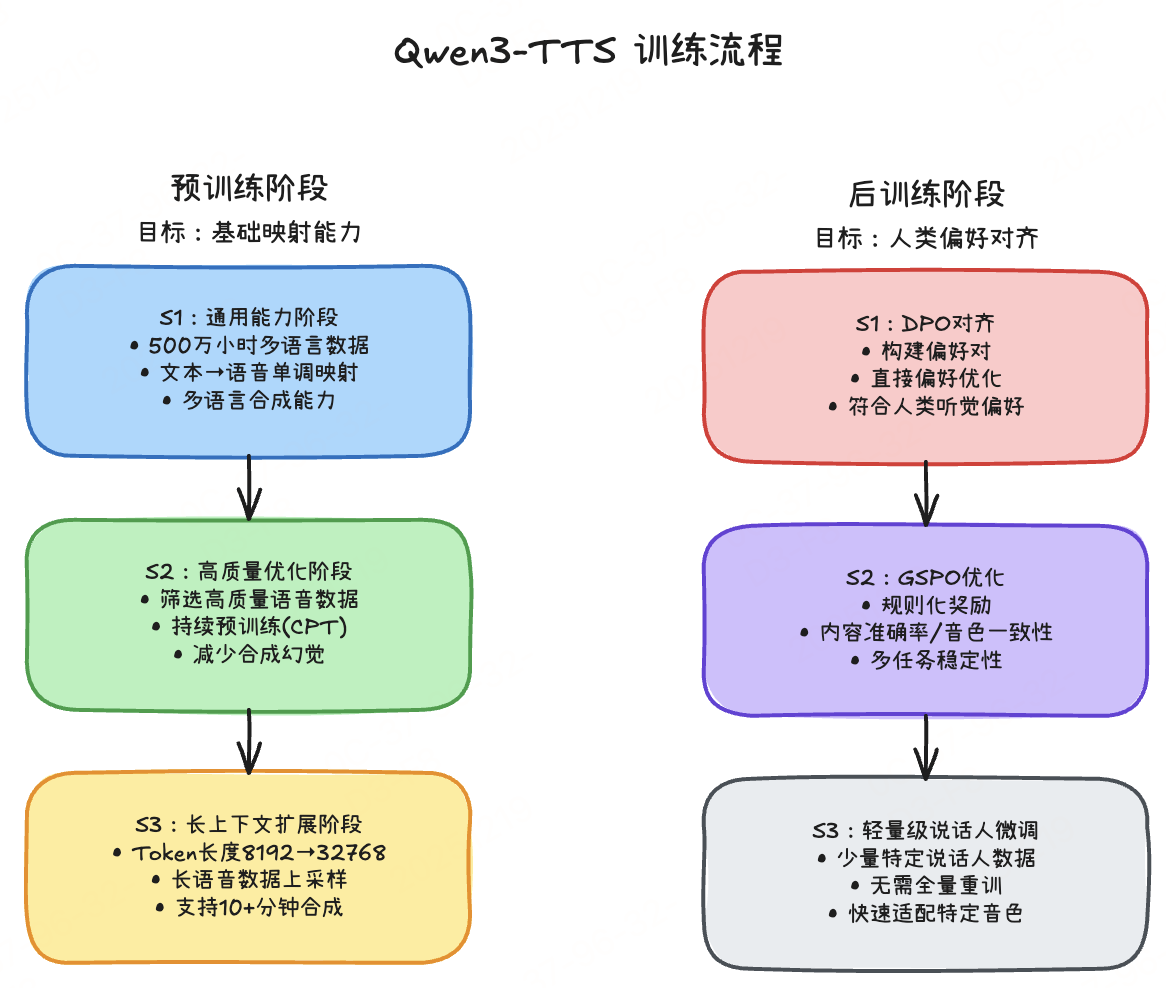
训练方法概览
Qwen3-TTS 采用 "预训练-后训练"两阶段流程,从"基础能力"到"人类偏好对齐"逐步优化,覆盖多语言、长文本、可控性等需求。
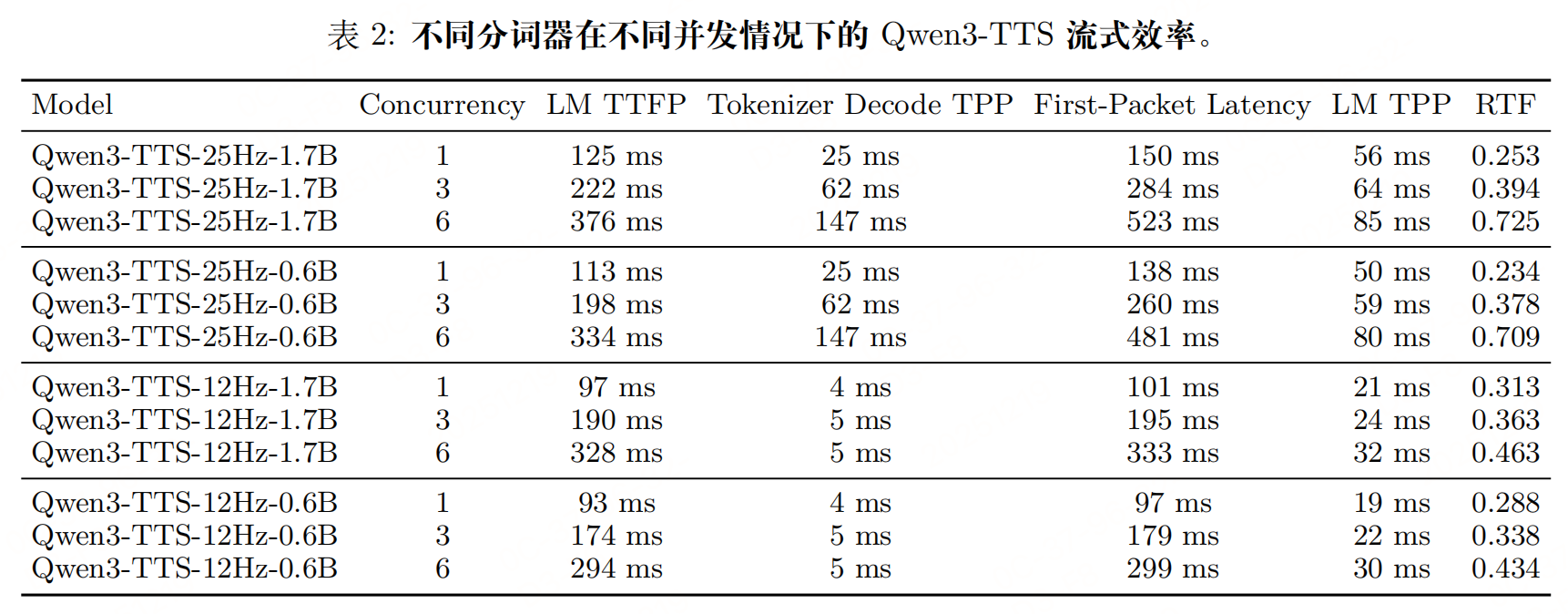
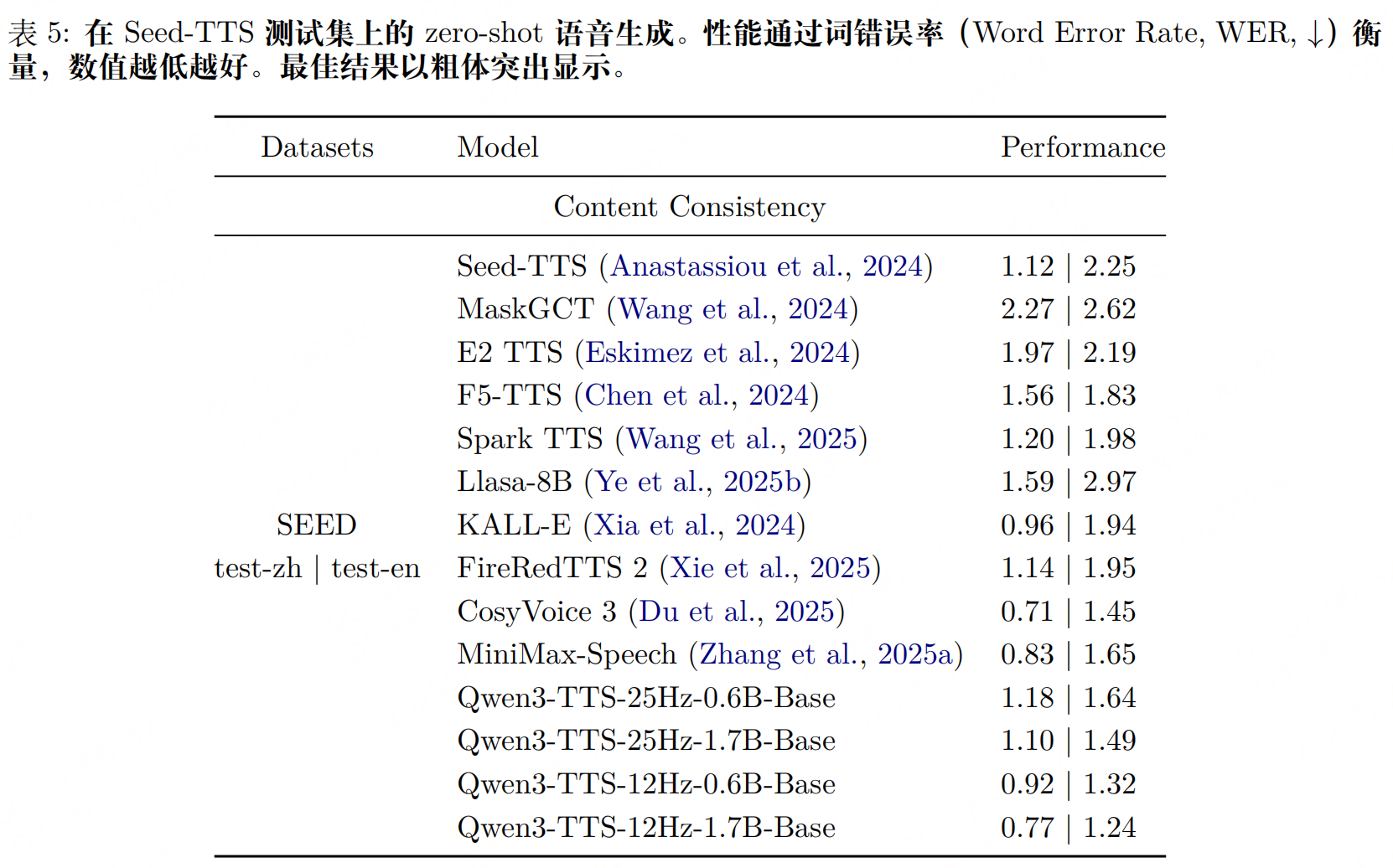
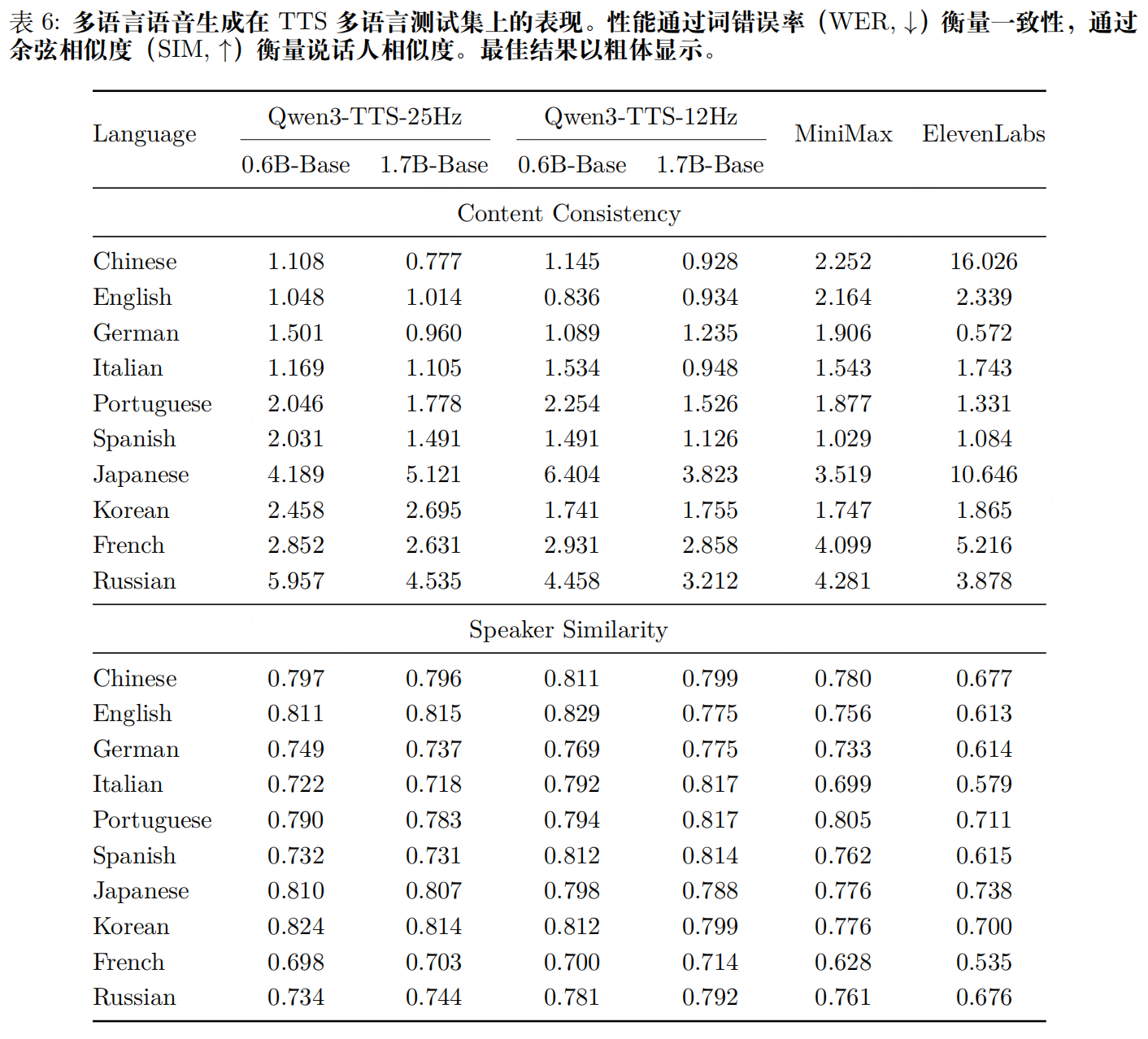
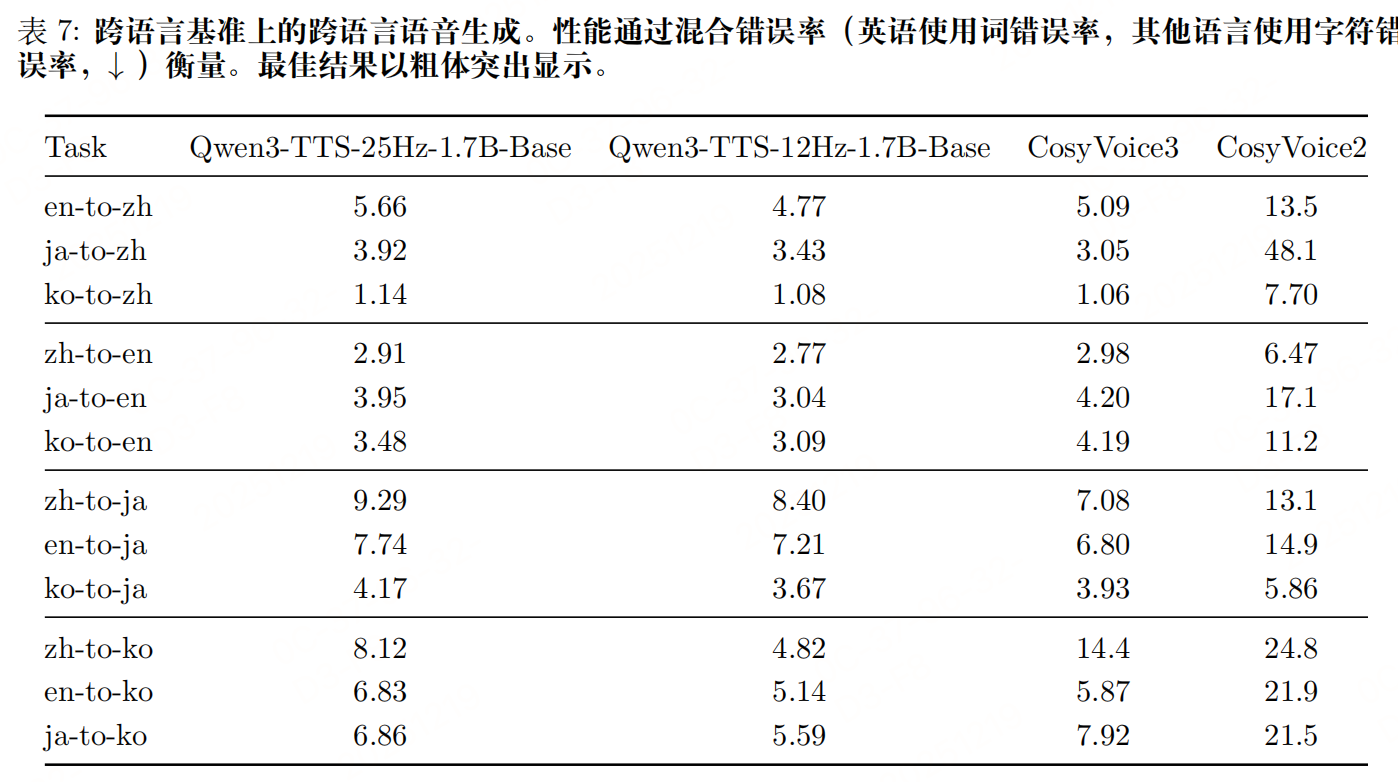
实验
参考文献
- Qwen3-TTS Technical Report,https://arxiv.org/pdf/2601.15621v1