第一步:环境配置
MediaPipe 最新版与 Protobuf 新版在 Windows + Python 3.9 环境下存在极大的兼容性问题。经过反复测试,以下是"黄金兼容组合":
-
Python: 3.9
-
Torch: 2.4.1+cu121 (根据显卡适配)
-
MediaPipe :
0.10.9(必须锁定此版本) -
Protobuf :
3.20.3(必须降级到 3.20.x)
安装 PyTorch (GPU版)
针对 NVIDIA RTX 30/40 系列显卡,推荐使用 CUDA 12.1 版本的 PyTorch,性能释放最充分。
# 安装 Torch 2.4.1 + CUDA 12.1
python -m pip install torch==2.4.1+cu121 torchvision==0.19.1+cu121 torchaudio==2.4.1+cu121 --index-url https://download.pytorch.org/whl/cu121注:如果你没有 NVIDIA 显卡,可以直接运行
pip install torch torchvision torchaudio 安装 CPU 版本,但训练速度会慢很多。
安装 MediaPipe 黄金组合
# 锁定 MediaPipe 和 Protobuf 的版本,确保兼容性
python -m pip install mediapipe==0.10.9 protobuf==3.20.3安装其他工具库
安装 OpenCV(用于摄像头图像处理)和其他必要的数学计算库。
# 安装 OpenCV 和 NumPy
python -m pip install opencv-python opencv-contrib-python numpyMediaPipe 0.10.9
-
它的作用: Google 开发的超强视觉库。
-
神经网络看不懂原始的图片(一堆像素点)。
-
MediaPipe 负责看图片,精准地把手上的 21 个关节坐标 提取出来。它不负责判断是"石头"还是"剪刀",它只负责告诉你:"食指指尖在坐标 (0.5, 0.8) 的位置"。
-
-
为什么要锁定 0.10.9?
-
MediaPipe 的更新非常激进。最新版有时会修改函数名,或者引入不兼容的依赖。
-
0.10.9是在 Python 3.9 环境下经过大量开发者验证的**"无 Bug 稳定版"**。
-
(我的显卡为4060)
Protobuf 3.20.3
-
它的作用 : 全称 Protocol Buffers,也是 Google 开发的一种数据存储格式。
- 它在后台工作: MediaPipe 极其依赖它。MediaPipe 里的模型结构、数据传输,底层都是用 Protobuf 格式打包的。
-
为什么要降级到 3.20.x? (这是最关键的知识点)
-
版本大断层:Protobuf 从 3.x 升级到 4.x (甚至 5.x) 时,修改了底层的 Python 接口生成逻辑。
-
冲突爆发:MediaPipe 0.10.9 是基于 Protobuf 3.x 的逻辑编写的。
-
如果你的环境乱了,请按以下顺序"重置":
# 1. 卸载冲突包
pip uninstall -y mediapipe protobuf
# 2. 安装
pip install mediapipe==0.10.9 protobuf==3.20.3第二步:无干扰数据采集 (Auto Mode)
采用 "倒计时自动录制" 模式。
核心逻辑
-
程序自动倒计时 5 秒。
-
提示当前需要做的手势(如"数字 1")。
-
自动连续采集 300 帧骨架坐标(x, y)。
-
存入 CSV 文件。
数据格式 (number_gesture_data.csv):
-
label: 0~9 (代表数字) -
x0, y0 ... x20, y20: 21个关键点的归一化坐标。
第三步:搭建神经网络 (SimpleGestureNet)
数据量不大,不需要复杂的卷积网络(CNN)。直接使用全连接网络 (FCN/MLP) 处理坐标数据即可,速度极快。
模型结构 (PyTorch)
-
输入层: 42 (21个点 × 2个坐标 x,y)
-
隐藏层1: 64 (ReLU激活 + Dropout防止过拟合)
-
隐藏层2: 32 (ReLU激活)
-
输出层: N (取决于你要识别几种手势,例如识别 0-5 则为 6)
训练效果
-
优化器: Adam (lr=0.001)
-
损失函数: CrossEntropyLoss
-
耗时: 1000个 Epoch 仅需几秒钟 (GPU RTX 4060)。
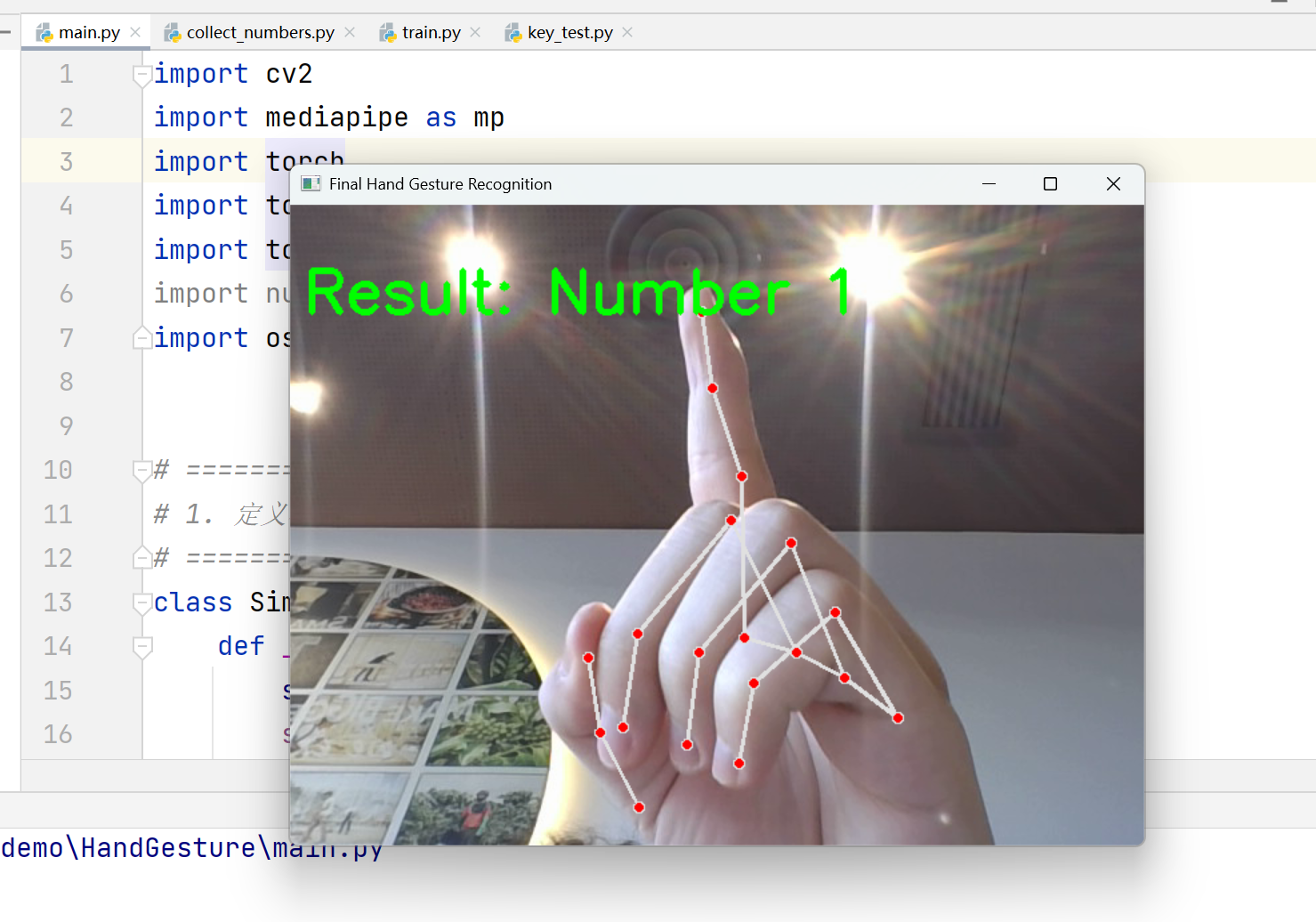
第四步:实时推理与展示
训练好模型保存为 .pth 文件后,在主程序中加载。
关键技巧:
-
OpenCV DSHOW 模式 :
cv2.VideoCapture(0, cv2.CAP_DSHOW),在 Windows 上开启摄像头速度更快。 -
镜像处理 :
cv2.flip(frame, 1),让画面符合人类照镜子的直觉。 -
置信度微调 :设置
min_detection_confidence=0.7,减少误识别。
总体代码:
import cv2
import mediapipe as mp
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import os
# ==========================================
# 1. 定义模型 (必须和训练时一模一样!)
# ==========================================
class SimpleGestureNet(nn.Module):
def __init__(self, input_size=42, num_classes=6):
super(SimpleGestureNet, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, num_classes)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# ==========================================
# 2. 配置与加载
# ==========================================
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"🚀 使用设备: {device}")
# 【重点!】这里的数字要和你训练时一样
# 如果你录制的是数字 1,2,3,4,5 (最大是5),这里就填 6 (因为0-5共6个数)
# 如果你录制的是数字 0-9 (最大是9),这里请改成 10
NUM_CLASSES = 6
model = SimpleGestureNet(num_classes=NUM_CLASSES).to(device)
# 加载训练好的权重
model_path = 'my_hand_model.pth'
if os.path.exists(model_path):
try:
model.load_state_dict(torch.load(model_path))
model.eval() # 切换到预测模式 (这一步非常重要!)
print(f"✅ 成功加载模型: {model_path}")
except RuntimeError as e:
print(f"\n❌ 模型加载失败!尺寸不匹配。")
print(f"报错提示: {e}")
print("💡 解决办法:请修改代码第 36 行的 NUM_CLASSES,改成你训练时的类别数量。")
exit()
else:
print(f"❌ 找不到模型文件: {model_path}")
print("请确认你是否已经运行过 train.py 并且生成了 .pth 文件")
exit()
# ==========================================
# 3. 初始化 MediaPipe
# ==========================================
mp_hands = mp.solutions.hands
hands = mp_hands.Hands(
static_image_mode=False,
max_num_hands=1,
min_detection_confidence=0.7, # 调高一点,防抖
min_tracking_confidence=0.5
)
mp_draw = mp.solutions.drawing_utils
# ==========================================
# 4. 摄像头预测循环
# ==========================================
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW) # Windows加速
# 定义显示的文字 (你可以随便改,比如把 1 改成 "One")
gesture_names = {
0: "Unknown",
1: "Number 1",
2: "Number 2 (Yeah)",
3: "Number 3",
4: "Number 4",
5: "Number 5",
6: "Number 6",
7: "Number 7",
8: "Number 8",
9: "Number 9"
}
print("\n✨ 系统准备就绪!请对着摄像头做手势...")
while True:
ret, frame = cap.read()
if not ret: break
# 镜像 + 转RGB
frame = cv2.flip(frame, 1)
img_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(img_rgb)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 画骨架
mp_draw.draw_landmarks(frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)
# 提取坐标
landmark_list = []
for lm in hand_landmarks.landmark:
landmark_list.extend([lm.x, lm.y])
# 转 Tensor
input_tensor = torch.tensor([landmark_list], dtype=torch.float32).to(device)
# 【核心步骤】模型预测
with torch.no_grad():
output = model(input_tensor)
# 获取概率最大的那个类别的索引
_, predicted_idx = torch.max(output, 1)
pred_class = predicted_idx.item()
# 获取名字 (如果在字典里没有,就直接显示数字)
display_text = gesture_names.get(pred_class, f"Num {pred_class}")
# 屏幕显示 (绿色大字)
cv2.putText(frame, f"Result: {display_text}", (10, 80),
cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 255, 0), 3)
# 在控制台打印概率 (可选,方便调试)
# print(f"预测: {pred_class}")
cv2.imshow('Final Hand Gesture Recognition', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()实际上代码并不复杂,但是环境配置需要花点时间
训练的代码:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import os
import csv
# ==========================================
# 1. 配置 & 读取数据
# ==========================================
# 自动找桌面的数据文件
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
data_file = os.path.join(desktop_path, 'number_gesture_data.csv')
print(f"📂 正在读取数据: {data_file}")
# 使用 numpy 读取 CSV (跳过第一行表头)
try:
# 尝试读取数据
raw_data = np.loadtxt(data_file, delimiter=',', skiprows=1, dtype=np.float32)
except Exception as e:
print(f"❌ 读取失败!请检查文件是否存在。\n报错信息: {e}")
exit()
if raw_data.size == 0:
print("❌ 数据文件是空的!请重新录制。")
exit()
# 拆分 标签(y) 和 特征(x)
# CSV格式: [label, x0, y0, ... x20, y20]
x_data = raw_data[:, 1:] # 第2列到最后是坐标
y_data = raw_data[:, 0] # 第1列是标签
# 自动计算有多少类 (比如你录了 1-5,最大数是5,我们就设类别数为 6,方便处理)
num_classes = int(np.max(y_data)) + 1
print(f"📊 数据加载成功!共 {len(x_data)} 条数据")
print(f"🔍 识别范围: 0 ~ {num_classes - 1} (包含未录制的空位)")
# 转换为 PyTorch 的张量
X = torch.from_numpy(x_data)
Y = torch.from_numpy(y_data).long() # 标签必须是整数
# ==========================================
# 2. 定义模型 (必须和 main.py 里的一模一样)
# ==========================================
class SimpleGestureNet(nn.Module):
def __init__(self, input_size=42, num_classes=3):
super(SimpleGestureNet, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, num_classes)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x)
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleGestureNet(num_classes=num_classes).to(device)
print(f"💻 训练设备: {device}")
# ==========================================
# 3. 开始训练
# ==========================================
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 1000 # 训练 1000 轮 (很快的)
print("\n🚀 开始训练...")
for epoch in range(epochs):
# 数据送入设备
inputs = X.to(device)
labels = Y.to(device)
# 1. 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 2. 反向传播 & 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")
print("✅ 训练完成!")
# ==========================================
# 4. 保存模型
# ==========================================
# 保存到当前项目文件夹下
save_path = 'my_hand_model.pth'
torch.save(model.state_dict(), save_path)
print(f"💾 模型已保存为: {save_path}")
print("👉 下一步:请去修改 main.py 来加载这个新模型!")代码结果: