具身智能的边缘进化:基于宇树 Go2 与 NaVILA 的全栈视觉导航系统深度解析
文章目录
- [具身智能的边缘进化:基于宇树 Go2 与 NaVILA 的全栈视觉导航系统深度解析](#具身智能的边缘进化:基于宇树 Go2 与 NaVILA 的全栈视觉导航系统深度解析)
-
- 摘要 (Abstract)
- [一、 基础设施:ROS 2 工作空间与边缘计算架构](#一、 基础设施:ROS 2 工作空间与边缘计算架构)
-
- [1.1 ROS 2 工作空间拓扑](#1.1 ROS 2 工作空间拓扑)
- [1.2 高性能边缘推理架构 (Client-Server Architecture)](#1.2 高性能边缘推理架构 (Client-Server Architecture))
- [二、 核心理论:NaVILA ------ 机器人的空间认知大脑](#二、 核心理论:NaVILA —— 机器人的空间认知大脑)
-
- [2.1 什么是 VLA (Vision-Language-Action)](#2.1 什么是 VLA (Vision-Language-Action))
- [2.2 NaVILA vs. 通用 VLA (如 RT-2)](#2.2 NaVILA vs. 通用 VLA (如 RT-2))
- [三、 模型的生命周期:从预训练到 Sim-to-Real](#三、 模型的生命周期:从预训练到 Sim-to-Real)
-
- [3.1 阶段一:多模态对齐预训练 (Pre-training)](#3.1 阶段一:多模态对齐预训练 (Pre-training))
- [3.2 阶段二:指令微调 (Instruction Tuning / SFT)](#3.2 阶段二:指令微调 (Instruction Tuning / SFT))
- [3.3 阶段三:领域自适应 (Domain Adaptation & Sim-to-Real)](#3.3 阶段三:领域自适应 (Domain Adaptation & Sim-to-Real))
- [四、 工业级方案:分层导航与控制架构 (Hierarchical Control)](#四、 工业级方案:分层导航与控制架构 (Hierarchical Control))
-
- [4.1 宏观战略层:Global Planner](#4.1 宏观战略层:Global Planner)
- [4.2 局部战术层:Semantic Planner (VLA)](#4.2 局部战术层:Semantic Planner (VLA))
- [4.3 动作执行层:Whole-Body Control (RL)](#4.3 动作执行层:Whole-Body Control (RL))
- [五、 总结](#五、 总结)
摘要 (Abstract)
随着大语言模型(LLM)向多模态领域迈进,具身智能(Embodied AI)正迎来爆发时刻。本文将以宇树 Unitree Go2 四足机器人为载体,深度解析如何在边缘计算平台(NVIDIA Jetson Orin)上构建一套完整的视觉-语言-动作(VLA)导航系统。我们将跳出简单的脚本控制,从 ROS 2 工作空间架构出发,深入探讨 NaVILA 模型的内部机理、分层导航(Hierarchical Navigation)的工业级实现,以及强化学习(RL)在运动控制中的关键作用。本文旨在为机器人开发者提供一份从理论到部署的"全栈技术图谱"。

一、 基础设施:ROS 2 工作空间与边缘计算架构
在进行复杂的 AI 部署之前,一个标准化的工程环境是基石。
1.1 ROS 2 工作空间拓扑
我们的 ROS2-Gazebo-GO2 工作空间遵循模块化设计原则,将感知、决策与控制严格解耦:
- 感知层 (
cartographer/image_transport): 负责通过 LIDAR 构建环境栅格地图(SLAM),并通过 ROS 2 图像管道高效传输视觉帧。 - 决策层 (
vla_bridge/navigation2) :vla_bridge: 这是我们构建的核心中间件,它实现了 ROS 2 非结构化数据与 VLA 模型结构化输入之间的桥梁。navigation2(Nav2): 处理确定性的路径规划与代价地图(Costmap)更新。
- 控制层 (
quadropted_controller/go2_description): 包含机器人的 URDF 运动学描述与底层电机控制接口。 - 仿真层 (
gazebo_sim): 提供高保真的物理仿真环境,用于 Sim-to-Real 的前置验证。
1.2 高性能边缘推理架构 (Client-Server Architecture)
针对边缘端计算资源(Memory/Compute)与机器人实时控制(Real-time Control)之间的矛盾,我们采用 Client-Server 微服务架构 替代传统的单体应用模式:
- 服务端 (Inference Backend) : 采用 C++ 重构的
llama.cpp作为推理引擎。- 优势 : 通过底层 CUDA 优化与 KV Cache 量化(如
q8_0),在保持 NaVILA-8B 模型精度的同时,显著降低显存占用并提升推理吞吐量(Tokens/sec)。 - 接口: 暴露标准的 HTTP RESTful API,支持高并发请求。
- 优势 : 通过底层 CUDA 优化与 KV Cache 量化(如
- 客户端 (VLA Node) :
na_vila_node.py作为轻量级 ROS 节点。- 逻辑: 负责图像预处理(Resize/Base64)、Prompt 封装以及 Action 解码。这种设计允许推理服务灵活部署于本机后台或局域网高性能服务器,实现**"脑体分离"**。
二、 核心理论:NaVILA ------ 机器人的空间认知大脑
为什么选择 NaVILA 而非其他多模态模型?这涉及 VLA 模型的本质分类。
2.1 什么是 VLA (Vision-Language-Action)
VLA 是将计算机视觉(CV)、自然语言处理(NLP)与机器人动作(Action)统一在一个 Transformer 架构下的尝试。其推理链路为:
感知 (Pixel) + 意图 (Text) -> 认知 (Reasoning) -> 决策 (Action Token)
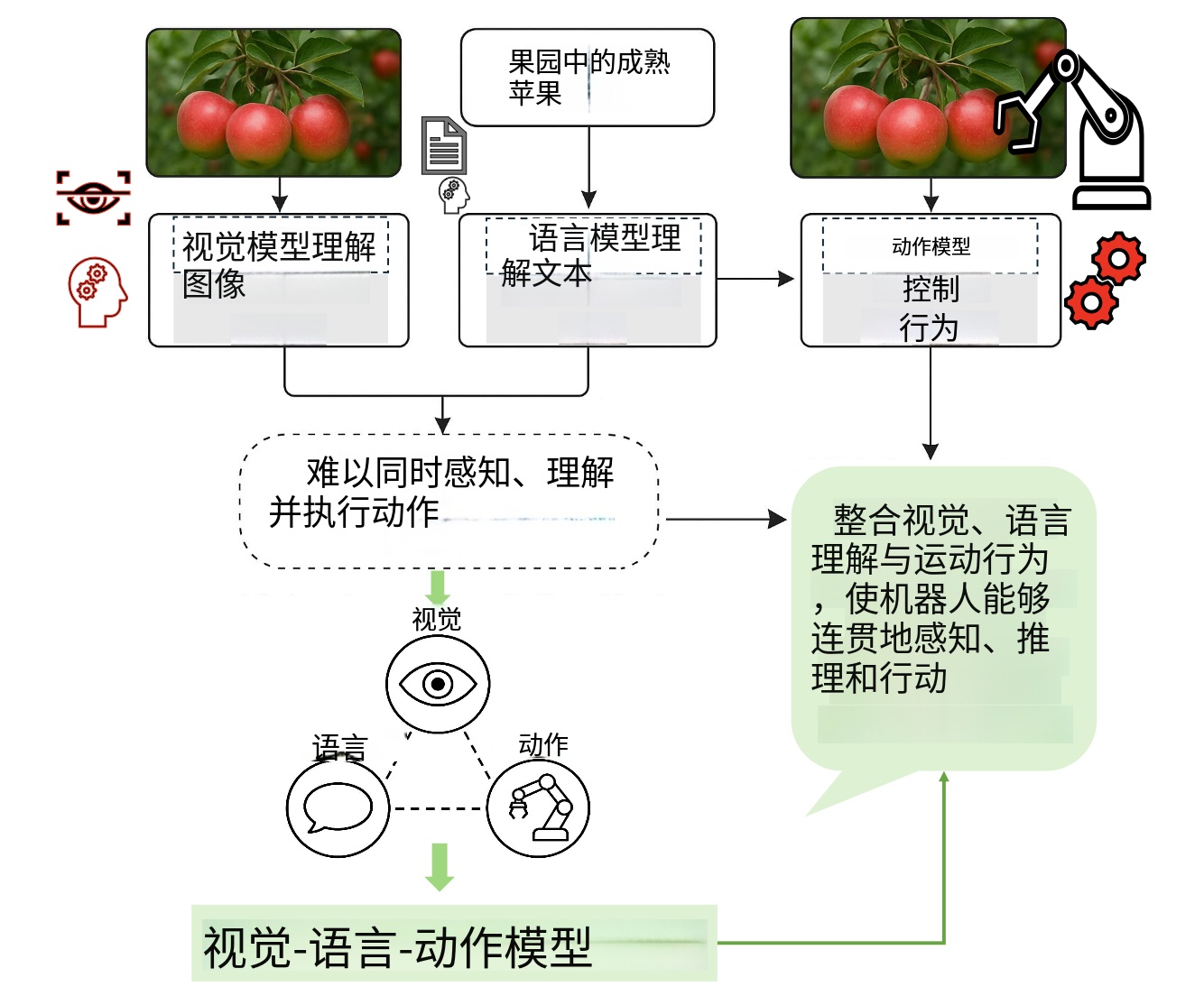
2.2 NaVILA vs. 通用 VLA (如 RT-2)
虽然同属 VLA,但两者的下游任务 (Downstream Tasks) 与 数据分布 (Data Distribution) 决定了它们的本质差异:
| 维度 | NaVILA (Navigation VLA) | RT-2 / General VLA |
|---|---|---|
| 专注领域 | Locomotion (移动与导航) | Manipulation (机械臂抓取) |
| 核心能力 | 几何语义理解: 空间透视、连通性判断、路标识别 | 物体物理属性: 抓取点检测、物体交互 |
| 训练数据 | Habitat, Gibson (第一人称漫游视频、以米为单位的轨迹) | Bridge Data (桌面操作视频、末端执行器位姿) |
| 输出空间 | Waypoints (航点), Velocity (速度向量: v, w) | SE(3) Pose (六自由度位姿), Gripper State |
NaVILA 的核心在于它具备**"空间几何感"**。它不仅仅识别"这是一扇门",它还理解"门是通往下一个区域的连接点",这种能力是 Nav2 等传统算法所不具备的语义推理能力。
三、 模型的生命周期:从预训练到 Sim-to-Real
一个可用的 VLA 模型并非一蹴而就,它经历了三个阶段的进化。
3.1 阶段一:多模态对齐预训练 (Pre-training)
- 机制 : 冻结视觉编码器(如 CLIP/SigLIP)和 LLM,仅训练 Projector (投影层)。
- 目的: 让 LLM "看懂"图片。将视觉特征映射到 LLM 的 Token Embedding 空间。
- 现象: 此时模型擅长 Captioning("这是一张走廊的图片"),但不懂控制。
3.2 阶段二:指令微调 (Instruction Tuning / SFT)
- 机制 : 使用指令数据集
<Image, "Navigate to kitchen", Action>进行全量或参数高效微调。 - 核心 : 引入思维链 (Chain-of-Thought),让模型学会:"为了去厨房(Goal) -> 我看到了前方有障碍(Observation) -> 我应该先左转避让(Reasoning) -> 输出动作(Action)"。
- 成果: 模型学会了从"描述者"转变为"决策者"。
3.3 阶段三:领域自适应 (Domain Adaptation & Sim-to-Real)
为了让模型适配特定的办公环境(如你的办公室),我们需要进行特定域微调。
- 技术路径 : LoRA (Low-Rank Adaptation)。
- 实施步骤 :
- 数据采集: 使用手柄遥控机器人采集本地数据(图像+Odom)。
- 数据清洗 : 构建
<Local_Image, Expert_Action>数据对。 - 微调: 仅训练模型参数的 1%(LoRA Adapter),使其快速适应本地的光照、纹理和布局。
四、 工业级方案:分层导航与控制架构 (Hierarchical Control)
在 1km 级长距离穿越任务中,单一模型无法包揽全局。工业界标准解法是分层架构。
4.1 宏观战略层:Global Planner
- 组件 : SLAM (Cartographer) + Nav2 + GNSS/RTK。
- 职责: 解决"我在哪"和"怎么去几公里外"的问题。
- 原理: 利用构建好的全局地图(Metric Map),通过 A* 或 Dijkstra 算法规划出一条无碰撞的长距离路径,生成稀疏航点(Waypoints)。
4.2 局部战术层:Semantic Planner (VLA)
- 组件 : NaVILA。
- 职责: 解决"语义理解"和"最后 10 米"的问题。
- 场景: 当全局规划到达终点附近(如便利店门口),由于 GPS 误差或地图缺失,Nav2 失效。此时 VLA 接管,理解"进入自动门"、"寻找红色椅子"等语义指令。
4.3 动作执行层:Whole-Body Control (RL)
- 组件 : 强化学习 (Reinforcement Learning)。
- 职责: 解决"四足平衡"与"运动执行"的问题。
- 原理 :
- VLA 或 Nav2 输出的是简单的 Velocity Command (cmd_vel):"前进 0.5m/s"。
- RL 策略网络(Policy Network)作为"小脑",接收这一指令及本体传感器数据(IMU、关节编码器),高频(500Hz)计算 12 个电机的力矩,确保机器人在执行指令时保持动态平衡,不摔倒、不打滑。
五、 总结
在宇树 Go2 上部署 NaVILA 是一次对现代机器人全栈技术的综合实践。我们不仅实现了基于 llama.cpp 的高效边缘计算架构,更打通了从 SLAM 全局规划到 VLA 语义决策,再到 RL 动作控制的完整闭环。
这套系统展示了具身智能的未来方向:云端大模型提供通用认知,边缘小模型处理实时决策,底层控制器保障物理执行。 随着多模态大模型的参数量不断优化(如 TinyLlama, Phi-3),这种高智能、低延迟的导航系统将很快在巡检、物流与陪伴机器人中普及。