note
- Agentic Reasoning for Large Language Models
- 自进化推理机制,演化的核心包含两个基本机制:反馈与记忆。反馈为自我修正与优化提供评估信号,使智能体能够根据结果或环境响应来调整其推理策略。记忆则作为持久的基底,用于存储、组织和综合过往交互,从而实现跨任务的知识积累与复用。
- 其中,反思包括三种。反思性反馈,模型通过自我批判或验证来修正其推理;参数化适应,将反馈整合为更新后的模型参数;以及验证器驱动的反馈,通过二元结果信号引导重采样,无需内部反思。
文章目录
一、Agentic Reasoning LLM
《Agentic Reasoning for Large Language Models》(https://arxiv.org/pdf/2601.12538,https://github.com/weitianxin/Awesome-Agentic-Reasoning)。看核心6个点,其中做了一些罗列,是个不错的索引。
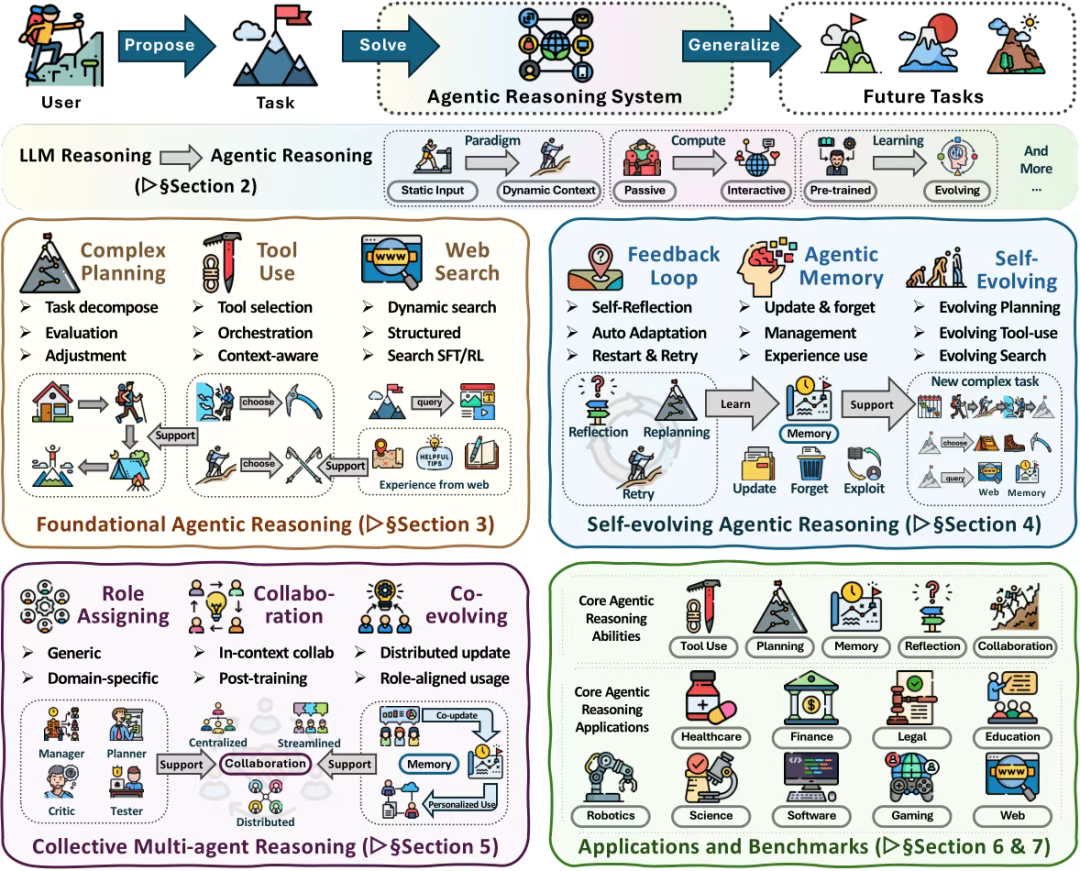
1、大语言模型推理 VS 智能体推理
与传统LLM推理相比,关键差异体现在范式(被动→交互)、输入(静态→动态)、计算(单步→多步)、记忆(上下文窗口→外部记忆)、学习(离线预训练→持续改进)等维度
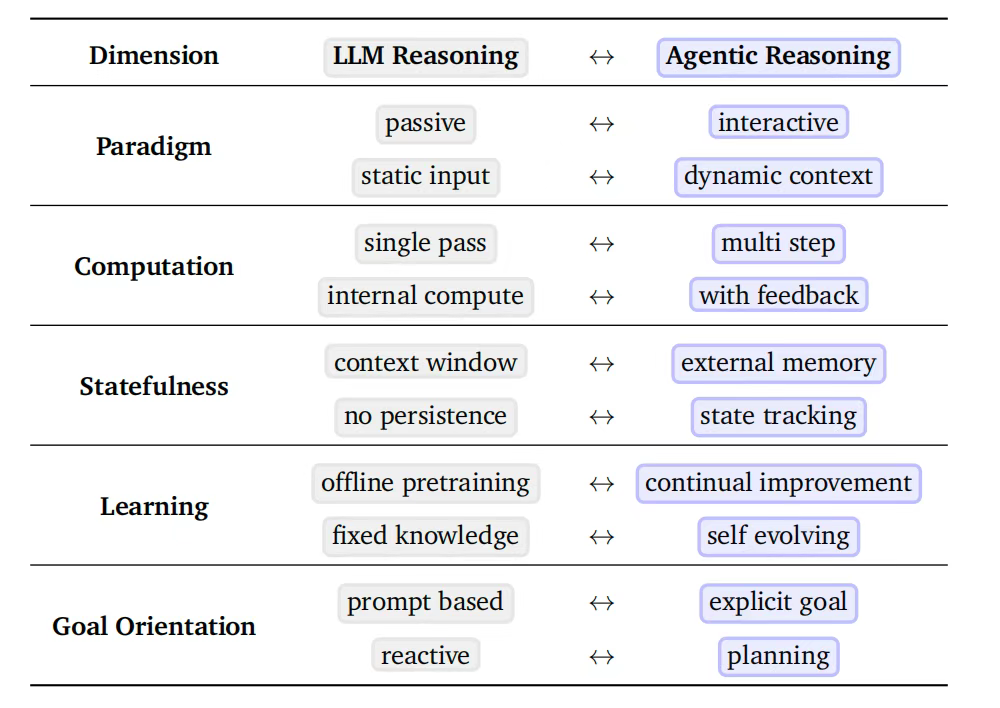
2、两种优化模式
两种优化模式:两种优化模式的核心区别在于是否更新模型参数

上下文内推理(无参数更新) 方式,通过结构化编排、树搜索、自适应工作流等方式,在推理时动态调整交互流程,代表方法有ReAct、ToT,在在不更新参数的情况下扩展推理时的交互。
训练后推理(有参数更新) 方式,通过监督微调(SFT)、强化学习(RL,如PPO、GRPO)将成功的推理模式内化到模型权重,代表方法有ToolLLM(SFT)、Search-R1(RL)。
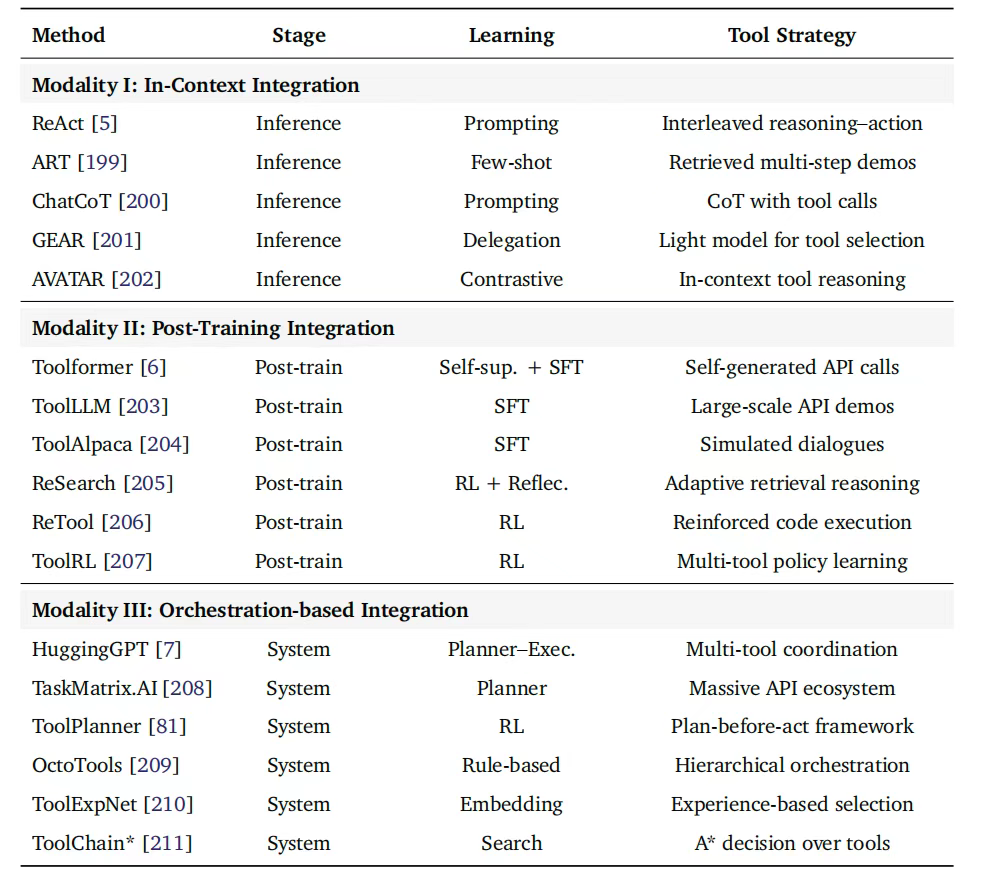
3、工具使用优化
工具使用最优化,可分为三种风格:上下文内工具集成、后训练工具集成,以及编排式工具集成。
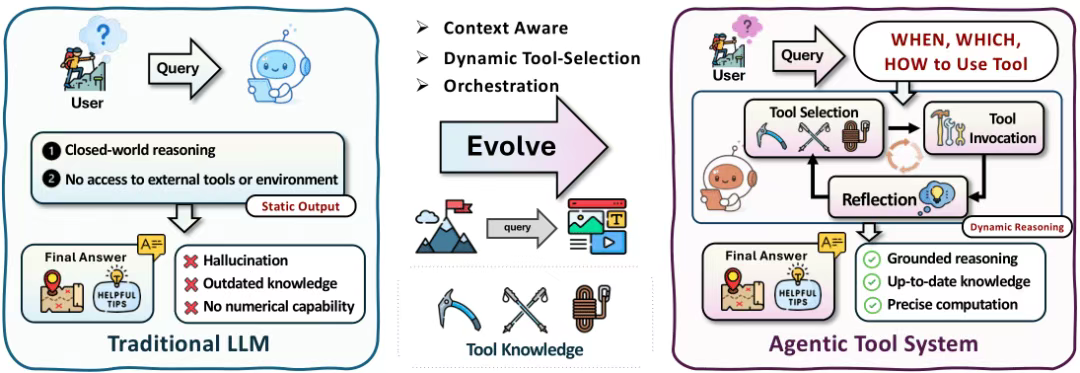
具体分类:
4、Agentic search
优化传统RAG依赖于向量数据库上的静态检索,而Agentic搜索引入了自主决策机制,以决定何时、如何以及检索什么内容,从而实现动态搜索、上下文检索、批判与适应环以及工具使用。
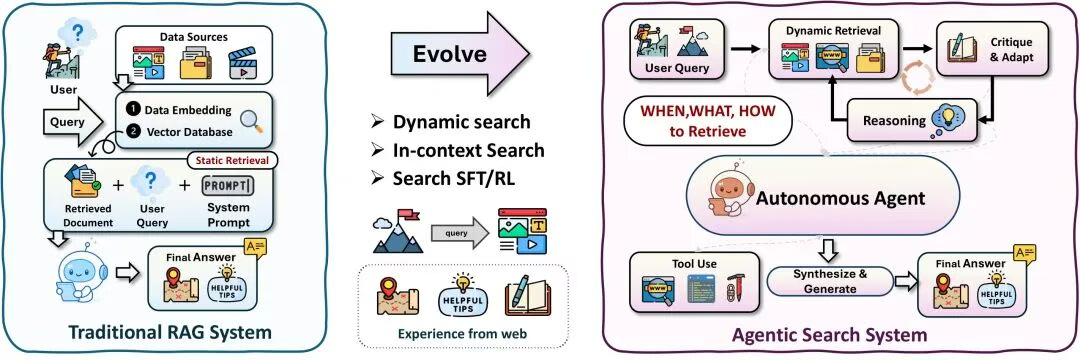
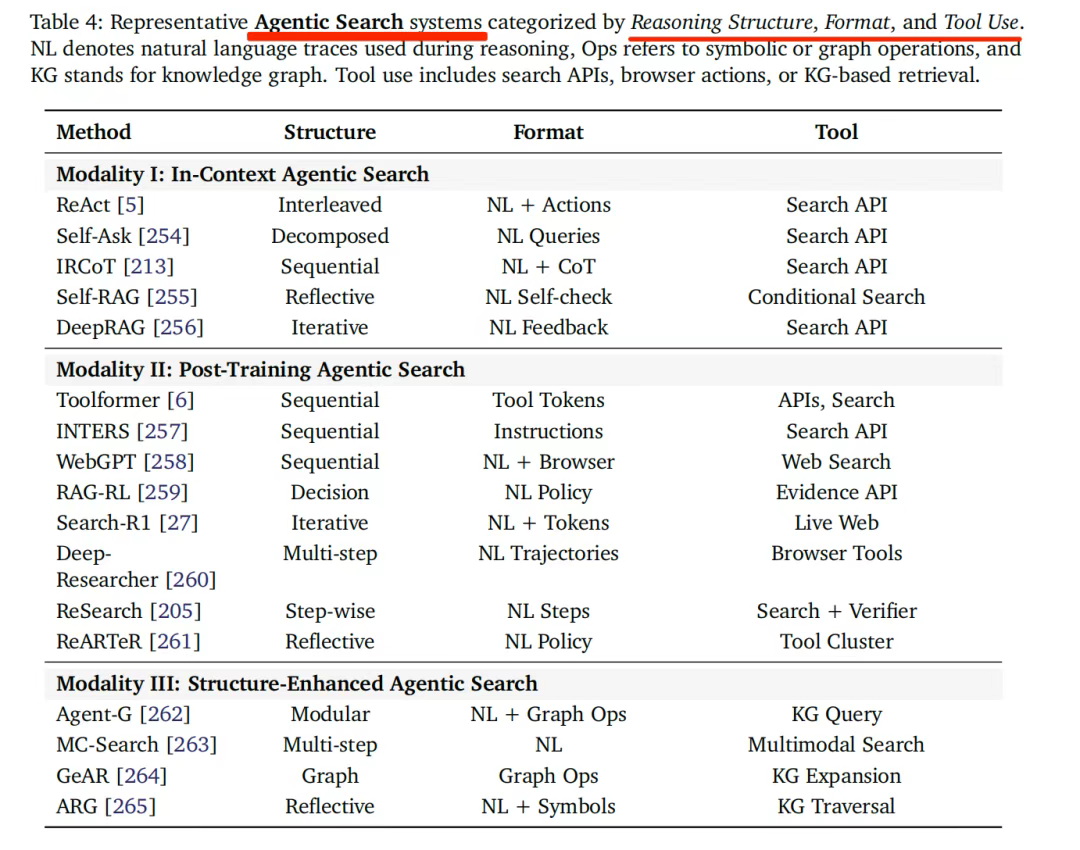
具体实现范式可以分为上下文内In-Context Search、后训练Post-Training Searc和结构增强型Structure-Enhanced Search几种实现,现有系统的具体情况如下表所示,可以看其中的方法、结构、数据格式以及使用的工具。
5、自进化推理机制
演化的核心包含两个基本机制:反馈与记忆。反馈为自我修正与优化提供评估信号,使智能体能够根据结果或环境响应来调整其推理策略。记忆则作为持久的基底,用于存储、组织和综合过往交互,从而实现跨任务的知识积累与复用。
其中,反思包括三种。反思性反馈,模型通过自我批判或验证来修正其推理;参数化适应,将反馈整合为更新后的模型参数;以及验证器驱动的反馈,通过二元结果信号引导重采样,无需内部反思。
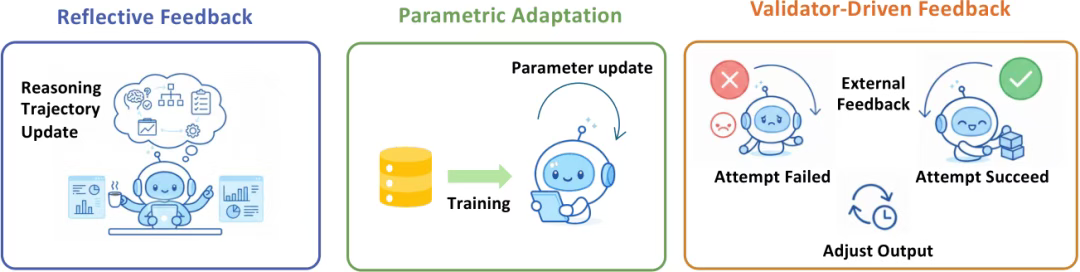
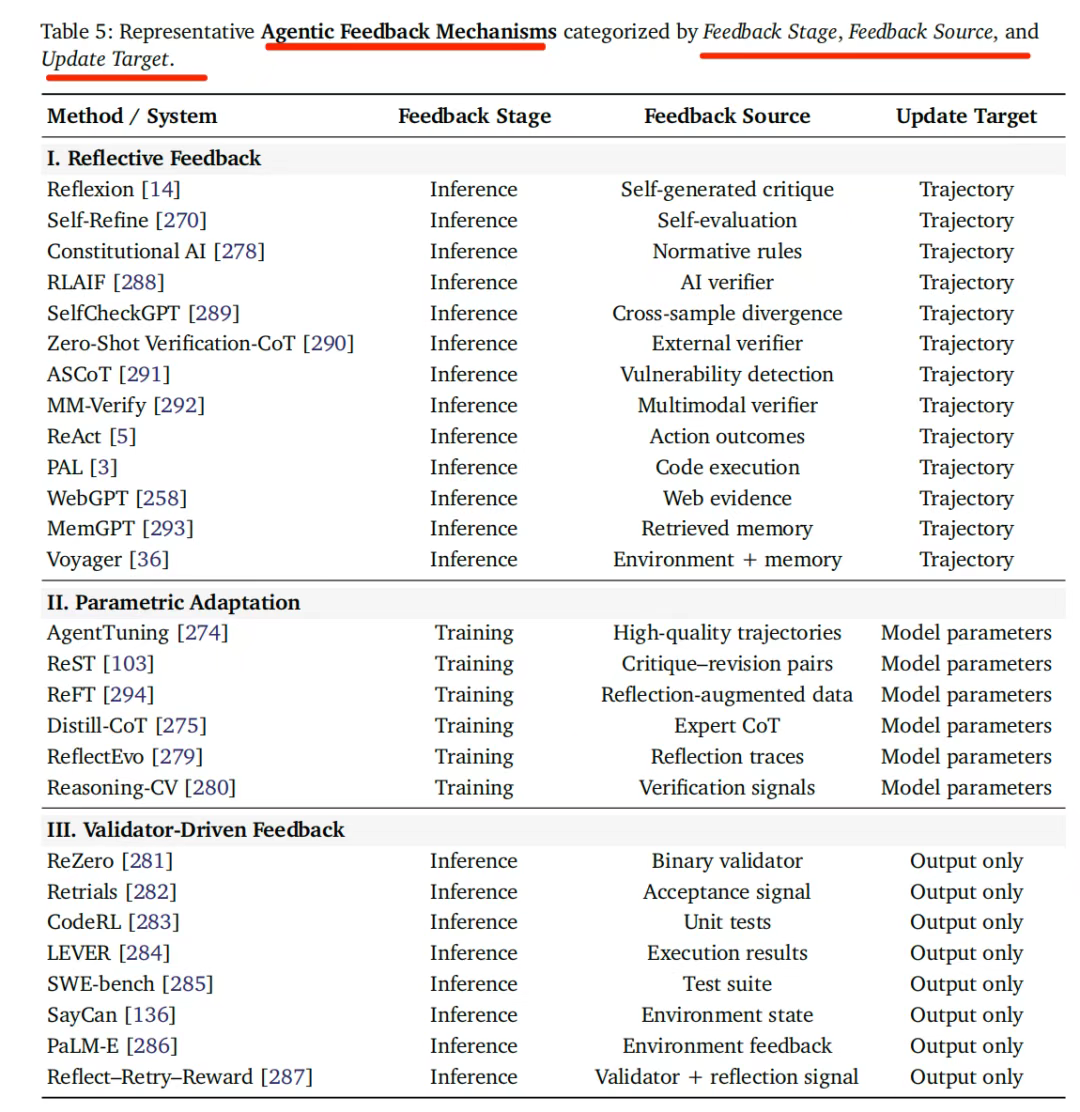
当前代表的工作,其反馈阶段、反馈来源以及更新的目标可以看下:
6、Agentic Memory记忆
从实现上,分成多种:上下文记忆捕获先前交互中的文本和语义信息;结构化记忆将这些信息整合为图表示和多模态表示;后训练控制使智能体能够通过学成的基于奖励的机制,实现记忆的演化、更新和检索。
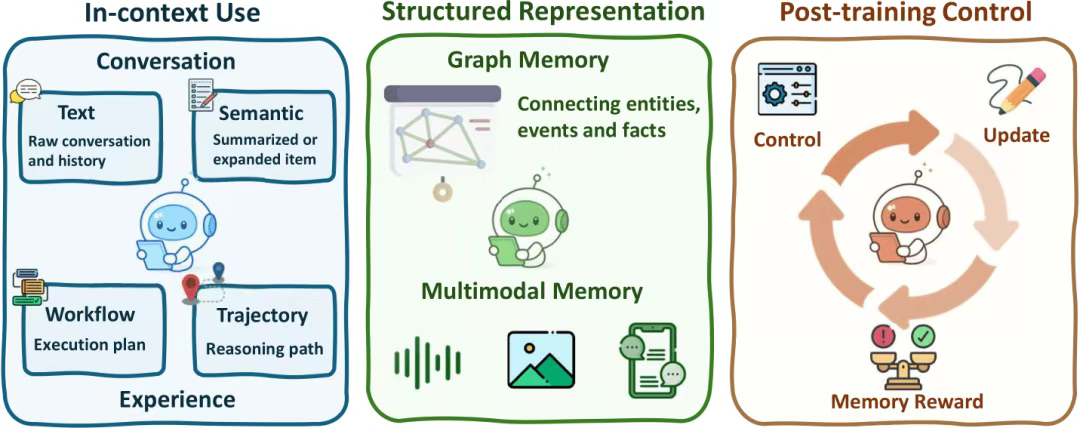
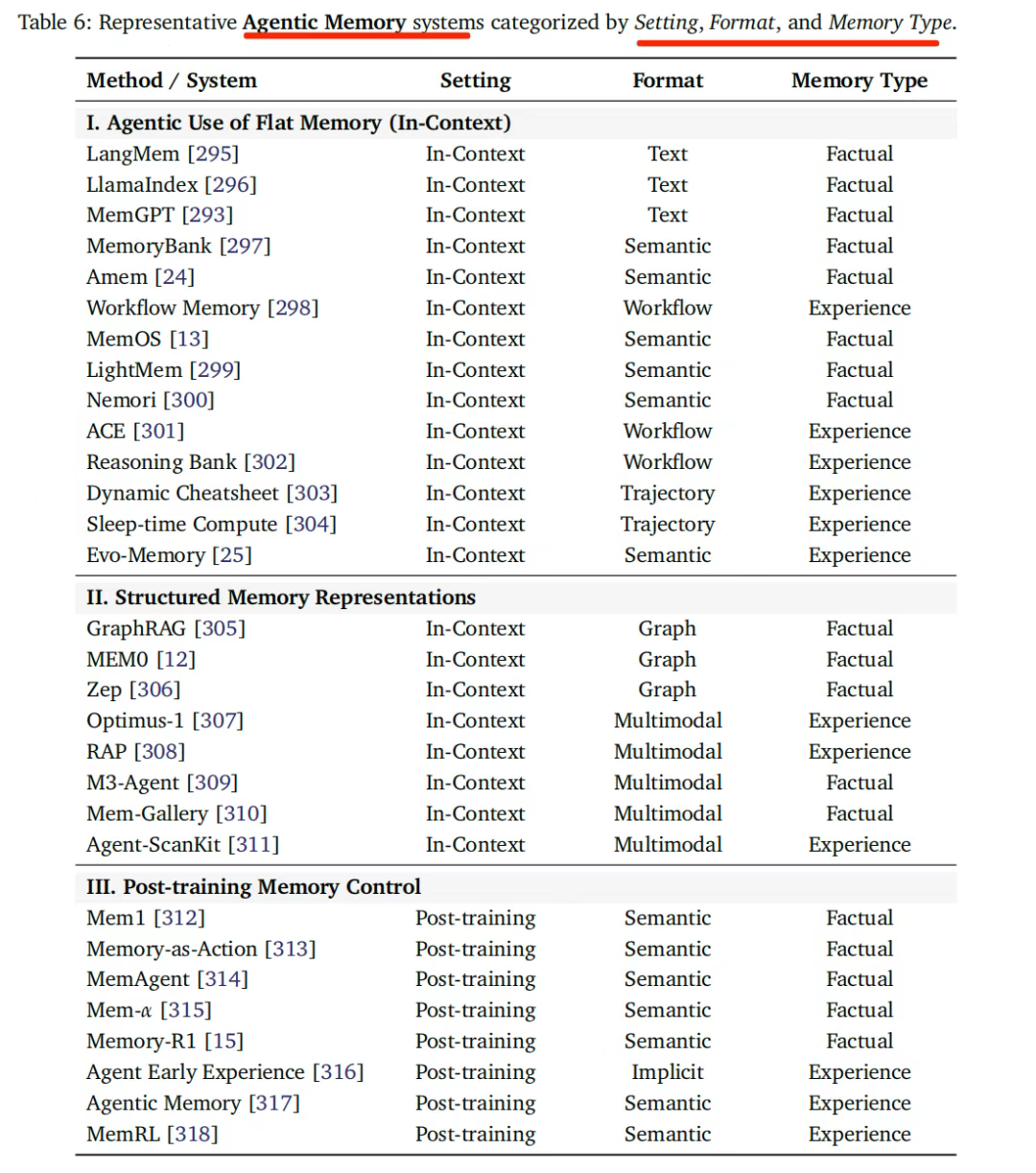
依旧可以从当前的代表记忆系统中做个归类:
Reference
1 Agentic Reasoning for Large Language Models