论文阅读笔记。我是初学者,对很多专业知识的理解可能不够透彻,文中要是有分析不到位或者错误的地方,恳请大家不吝赐教,我会及时改正,非常感谢大家的帮助!
文章目录
- 一、前言
- 二、论文内容
-
- 1.内容概要
- 2.课题背景(前置知识)
-
- [(1)VLMs 的核心架构与性能依赖](#(1)VLMs 的核心架构与性能依赖)
- (2)高分辨率场景的核心挑战
- (3)TTFT(Time-To-First-Token)
- (4)Avg-5
- (5)帕累托最优曲线
- 3.相关工作
- 4.模型介绍
-
- (1)整体架构设计
- [(2)FastViTHD 视觉编码器](#(2)FastViTHD 视觉编码器)
- (3)关键设计亮点与优势
- (4)分辨率适配策略对比
- 5.实验测试
-
- (1)实验设置
- (2)实验结果与分析
-
- [① FastViTHD 与传统编码器对比](#① FastViTHD 与传统编码器对比)
- [② FastVLM 与现有 VLMs 对比](#② FastVLM 与现有 VLMs 对比)
- [③ token优化效果对比](#③ token优化效果对比)
- [④ 帕累托最优曲线验证](#④ 帕累托最优曲线验证)
- (3)结论
- 三、总结
一、前言
哈喽,大家好,本文我将来带大家阅读一篇顶会论文《FastVLM: Efficient Vision Encoding for Vision Language Models》,我将会分为两大部分来完成介绍。分别为论文内容阅读和论文代码复现。本篇我将详细介绍论文内容。
我们先简单介绍一下论文信息:
标题:FastVLM: Efficient Vision Encoding for Vision Language Models
领域:计算机视觉、多模态模型、视觉语言模型
会议:CVPR 2025
作者:Pavan Kumar Anasosalu Vasu、Fartash Faghri、Chun-Liang Li、Cem Koc、Nate True、Albert Antony、Gokul Santhanam、James Gabriel、Peter Grasch、Oncel Tuzel、Hadi Pouransari
论文:https://arxiv.org/abs/2412.13303
代码:https://github.com/apple/ml-fastvlm
二、论文内容
1.内容概要
① 研究目的:解决视觉语言模型在处理高分辨率图像时面临的效率瓶颈问题。具体而言,旨在优化VLM在高分辨率输入下的"生成第一个token的时间"(TTFT),在保持或提升模型精度的同时,显著降低视觉编码延迟以及传递给大语言模型的视觉token的数量。
② 研究方法:提出了一种名为 FastVLM 的新型VLM,其核心创新在于设计了一个全新的视觉编码器 FastViTHD。
③ 研究结果:
在相同LLaVA-1.5设置下,相比基于ViT的先前工作,TTFT提升了 3.2倍。与在最高分辨率(1152×1152)下工作的LLaVA-OneVision模型相比,使用相同的0.5B参数LLM,在关键基准(如SeedBench、MMMU)上取得相当性能的同时,TTFT快了 85倍,且视觉编码器参数量小了 3.4倍。
在多种VLM基准测试上保持了与先进模型相媲美的精度。
论文证明仅通过优化视觉编码器架构和缩放输入分辨率,即可实现高效的token压缩,无需引入token修剪模块,简化模型设计。
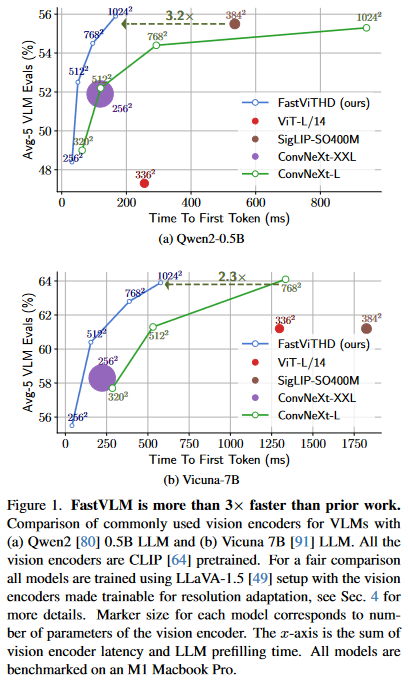
2.课题背景(前置知识)
(1)VLMs 的核心架构与性能依赖
视觉语言模型的经典架构由三部分组成:视觉编码器、投影层、LLM。 其中,视觉编码器负责提取图像特征并生成视觉token,视觉 - 语言投影层负责将视觉token映射到 LLM 的语义空间, LLM负责接收视觉token与文本输入,生成回答。
其中,视觉编码器的性能直接决定了 VLMs 的整体表现,尤其是在文本密集型任务中,高分辨率图像能提供更清晰的文本、图表细节,是提升模型准确率的关键。
(2)高分辨率场景的核心挑战
传统视觉编码器的预训练分辨率较低,直接输入高分辨率图像会导致特征提取效率低下。现有解决方案主要分为两类:一是对编码器进行持续预训练以适配高分辨率,但会增加训练成本;二是采用图像分块策略,将高分辨率图像分割为多个子图,分别编码后拼接,但这种方式会引入额外的分块与融合开销,且可能丢失全局特征。
高分辨率带来的直接后果是视觉token数量激增。同时,视觉编码延迟也随分辨率升高而急剧增长,最终使得TTFT过长,无法满足实时交互需求。
(3)TTFT(Time-To-First-Token)
生成第一个输出token所需要的总时间。由视觉编码延迟和LLM预填充延迟组成。
①视觉编码延迟:视觉编码器处理整张高分辨率图像,并提取出视觉token所花费的时间。
②LLM预填充延迟:大语言模型接收到所有输入token(包括用户文本问题和视觉令牌)后,进行一次性、并行的前向计算,为自回归生成做好准备所花费的时间。
(4)Avg-5
这篇论文中自定义的综合性能指标,是五个具有代表性和互补性的基准测试得分的平均值:
①GQA:测试视觉推理与组合问答能力。
②TextVQA:测试图像中文本的阅读理解能力。
③POPE:测试模型的对象幻觉程度(得分越高,幻觉越少)。
④DocVQA:测试文档图像的问答能力。
⑤SeedBench:测试多模态生成式理解能力。
上面两个指标中,TTFT关注效率,Avg-5关注精度。
(5)帕累托最优曲线
论文中的帕累托最优曲线是不同(分辨率、LLM 规模)组合下,VLMs 在给定 TTFT 预算下能达到的最高准确率与达成目标准确率所需最低延迟的映射曲线。
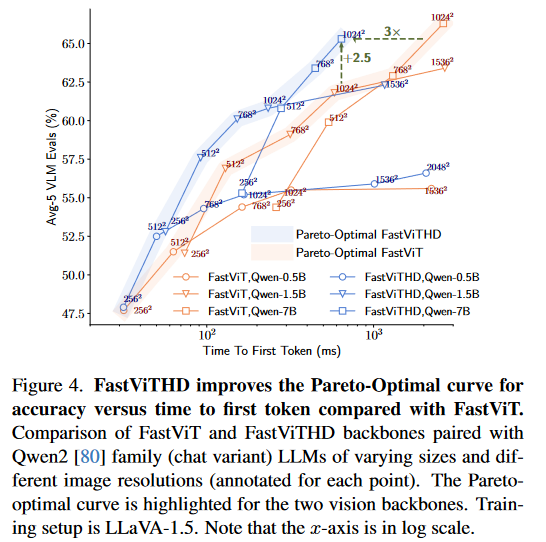
3.相关工作
(1)多模态模型
多模态模型的发展可分为三个阶段:
① 早期跨注意力融合架构:通过跨注意力机制在 LLM 的中间层融合图像嵌入与文本嵌入,实现视觉与语言的交互,但这种架构的融合效率较低,难以适配高分辨率图像。
② 主流自回归架构:以 LLaVA、mPLUG-Owl、Qwen-VL、InternVL 为代表,采用 "视觉编码器 + 投影层 + LLM" 结构,将视觉token通过投影层映射后与文本输入拼接,输入 LLM 进行自回归生成。这类模型性能优异,但受限于视觉编码器的效率,高分辨率下延迟问题突出。
③ 简化架构探索:尝试跳过视觉编码器,直接将原始图像输入 LLM 解码器,但由于缺乏预训练视觉特征的支持,性能落后于传统架构。
(2)视觉编码
为解决传统编码器的效率问题,现有研究主要分为四类方向:
① token剪枝与采样:针对 ViT 等各向同性架构,通过动态剪枝(如 LLaVA-PruMerge)、Matryoshka 采样等方法减少令牌数量,但这类方法需要额外设计剪枝模块,且可能导致特征信息丢失。
② 感知器式重采样:采用 Perceiver-style 重采样器或 pooling 技术压缩令牌,但会增加模型的推理开销。
③ 纯卷积编码器:以 ConvLLaVA 为代表,采用 ConvNeXT 等纯卷积架构作为视觉编码器,利用卷积的下采样特性减少令牌数量,但卷积层对全局特征的捕捉能力弱于 Transformer,在复杂场景下性能受限。
④ 分层混合架构:以 FastViT、ConvNeXT 为代表,通过多阶段下采样生成分层特征,减少token数量,但现有混合架构在高分辨率适配性上仍有优化空间(FastViT 的原始设计更侧重嵌入生成,而非高分辨率 VLM 场景)
4.模型介绍
(1)整体架构设计
FastVLM 沿用 LLaVA 的三段式架构,核心改进在于将视觉编码器替换为 FastViTHD,整体流程如下:
① 图像输入:支持 256×256 至 2048×2048 的灵活分辨率输入,无需分块即可直接处理高分辨率图像;
② 视觉编码:FastViTHD 对输入图像进行特征提取并生成token,输出少量高质量视觉token;
③ 投影融合:通过视觉 - 语言投影层将视觉token映射到与 LLM 匹配的语义空间;
④ 生成输出:映射后的视觉token与文本输入拼接,输入 LLM 解码器生成回答。
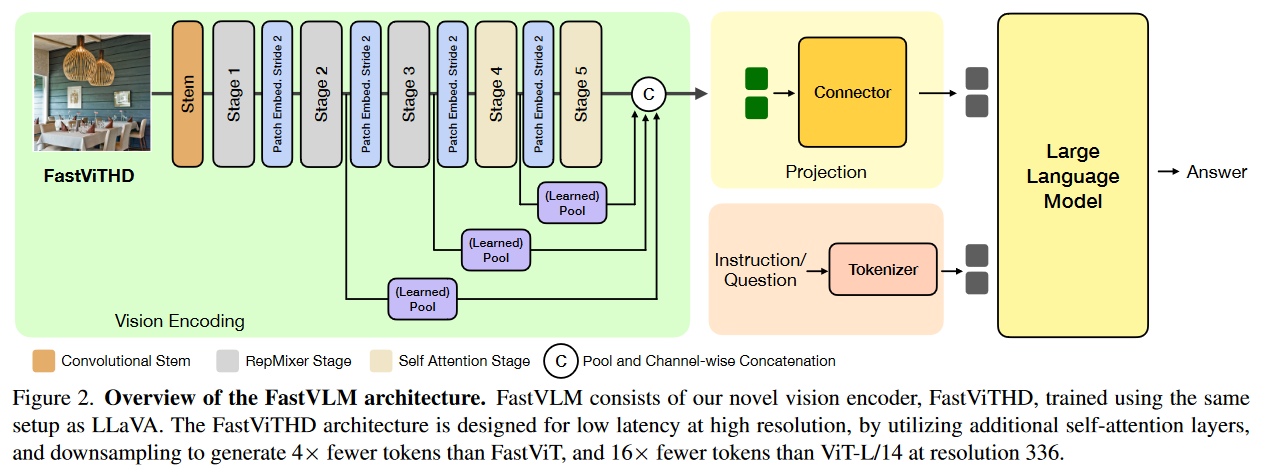
模型的训练支持两阶段或三阶段方案:
两阶段训练(沿用 LLaVA-1.5):阶段 1 仅训练投影层,使用 LLaVA-558K 对齐数据集,输入分辨率为编码器预训练分辨率;阶段 2 微调所有模块,使用 LLaVA-665K 监督微调数据集,输入分辨率设为目标分辨率。
三阶段训练(适配高分辨率):在两阶段基础上增加阶段 1.5(分辨率适配预训练),使用 15M 样本的数据集训练,将编码器分辨率从预训练值逐步提升至目标分辨率,进一步优化高分辨率下的特征提取能力。
(2)FastViTHD 视觉编码器
FastViTHD采用 "卷积 + Transformer" 混合设计,共分为 5 个阶段,前 3 阶段使用 RepMixer 块实现快速下采样,后 2 阶段使用多头自注意力块捕捉全局特征。
这种划分既利用了卷积在低分辨率阶段的高效下采样优势,又通过 Transformer 保证了高分辨率下的特征质量。
各阶段的深度(块数量)为 2, 12, 24, 4, 2,嵌入维度为 96, 192, 384, 768, 1536,MLP 扩展比为 4.0,总参数 125.1M,仅为 ViT-L/14(304M)的 41%,但特征表达能力相当。
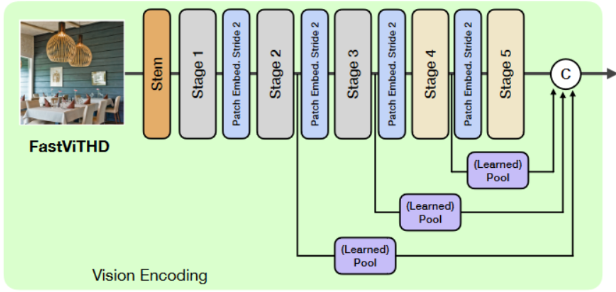
每个阶段通过步长为 2 的 Patch Embedding 实现下采样,最终将输入图像下采样 32 倍(传统 ViT 为 16 倍)。例如,336×336 分辨率输入经 FastViTHD 处理后生成 16 个视觉token,仅为 ViT-L/14(576 个)的 1/36,大幅减少了 LLM 的预填充压力。
聚合前 4 个阶段的特征信息,通过深度可分离卷积(DWConv)实现特征融合,相比平均池化(AvgPool)能更好地保留细节特征。论文实验显示,采用 DWConv 的融合方式可使 Avg-5 基准准确率提升 0.3 个百分点,在 TextVQA 等文本密集型任务中提升更为显著。
预训练方案:遵循 MobileCLIP 的 CLIP 预训练流程,使用 DataCompDR-1B 数据集进行预训练,确保视觉特征与语言语义的对齐性。
(3)关键设计亮点与优势
① 通过架构级的下采样设计,减少token数量,无需额外剪枝模块,避免了剪枝带来的特征损失和复杂度增加。
② 支持从 256×256 到 2048×2048 的连续分辨率缩放,且延迟增长可控。论文实验显示,当分辨率从 256×256 提升至 1024×1024 时,FastViTHD 的编码延迟从 10.1ms 增长至 235.6ms,而 ViT-L/14 在相同分辨率范围内的延迟从 127.4ms 增长至 1297ms,增长速率显著低于传统编码器。
③ 架构设计充分考虑了硬件加速特性,在 Apple Silicon 的神经引擎上可实现高效推理,为消费级硬件部署提供了可能。
(4)分辨率适配策略对比
论文对比了两种高分辨率适配策略:
静态分辨率:直接将模型输入分辨率设置为目标分辨率,适用于多数场景。实验显示,这种策略在 256×256 至 1024×1024 分辨率范围内,达到准确率与延迟之间的最佳平衡,避免了分块带来的额外开销。
动态分辨率:采用图像分块策略,将高分辨率图像分割为多个子图,编码器按子图分辨率处理后拼接令牌。论文实验表明,仅在极端分辨率且分块数较少时,动态分辨率才具有一定优势,且延迟仍高于同等分辨率下的静态策略。
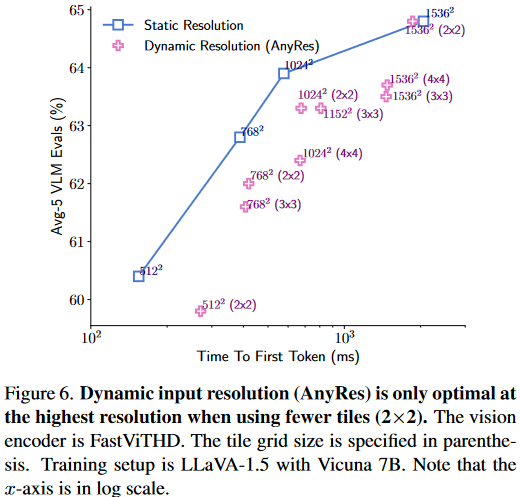
5.实验测试
(1)实验设置
① 硬件环境:M1 MacBook Pro(M1 Max 芯片,32GB RAM),用于测试模型在消费级硬件上的延迟与性能;
② 训练环境:单节点 8 块 NVIDIA H100-80GB GPU,用于模型预训练与微调。
③ 训练数据:
FastViTHD 预训练:DataCompDR-1B 数据集(10 亿图像 - 文本对);
阶段 1(投影层训练):LLaVA-558K 数据集;
阶段 1.5(分辨率适配):15M 样本的图像 - 文本对齐数据集;
阶段 2(微调):LLaVA-665K 数据集、1.1M 或 12.5M 样本的视觉指令微调数据集。
④ 评估基准:覆盖 6 类核心任务,包括通用推理(GQA、SeedBench)、文本密集型任务(TextVQA、DocVQA)、幻觉检测(POPE)、综合能力评估(MMMU、MMVet、LLaVA-in-the-wild),其中 Avg-5 指标(GQA、TextVQA、POPE、DocVQA、SeedBench 的平均准确率)作为核心评估指标,标准偏差仅 0.1,可靠性高。
⑤ 延迟测量方式:
视觉编码延迟:通过 coremltools v7.2 将编码器转换为 Core ML 格式,在 M1 Max 神经引擎上测试;
LLM 预填充延迟:通过 MLX 框架(Apple Silicon 优化)测试,将模型转换为 FP16 精度;
TTFT=视觉编码延迟+LLM 预填充延迟
(2)实验结果与分析
① FastViTHD 与传统编码器对比
论文表 3 显示,FastViTHD 在 224×224 分辨率下,编码延迟仅为 6.8ms,远低于 ViT-L/14(47.2ms)、ViTamin-L(38.1ms)和 ConvNeXT-L(34.4ms);同时,在 38 项多模态零样本任务中,FastViTHD 的平均准确率达到 66.3%,与 ViT-L/14(66.3%)相当,且高于 ConvNeXT-L(63.9%)。这表明 FastViTHD 在大幅降低延迟的同时,保持了优异的特征提取能力。
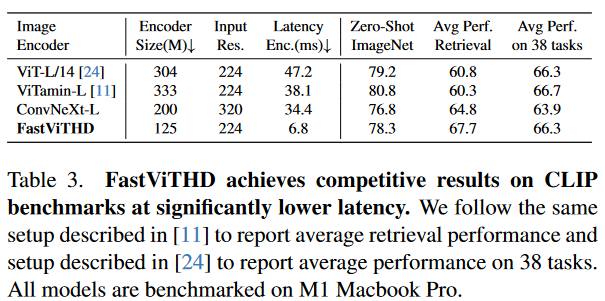
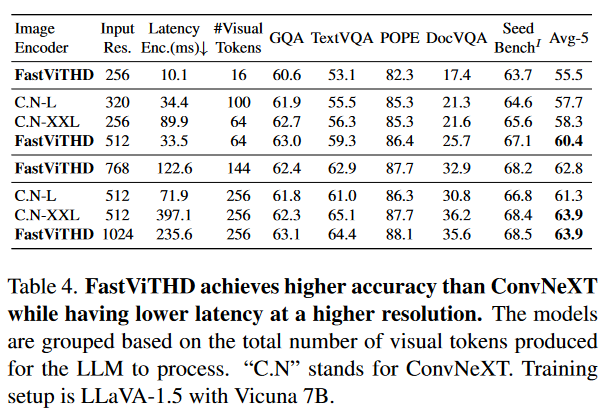
表 4 显示,在高分辨率场景下,FastViTHD 的优势更为显著:768×768 分辨率下,FastViTHD 的编码延迟为 122.6ms,生成 144 个token,Avg-5 准确率为 62.8%;而 ConvNeXT-XXL 在相同token数量下,编码延迟为 397.1ms,Avg-5 准确率为 63.9%,仅高出 1.1 个百分点,但延迟是 FastViTHD 的 3.3 倍。
② FastVLM 与现有 VLMs 对比
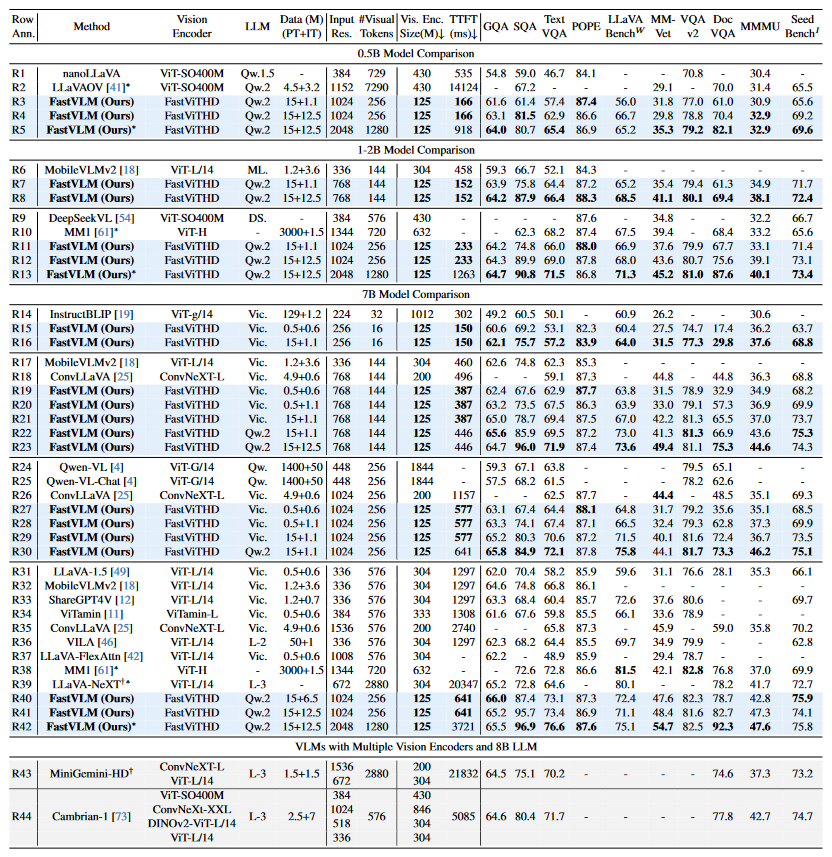
0.5B LLM 规模:与 LLaVa-OneVision(1152×1152 分辨率)相比,FastVLM(1024×1024 分辨率)的 TTFT 从 14124ms 降至 166ms,视觉编码器体积从 430M 降至 125M,MMMU 准确率为 30.9%,与 LLaVa-OneVision相当。
7B LLM 规模:与 ConvLLaVA(768×768 分辨率)相比,FastVLM 的 TTFT 从 496ms 降至 387ms,TextVQA 准确率从 59.1% 提升至 62.9%。
高分辨率扩展:当 FastVLM 的输入分辨率提升至 2048×2048 时,TTFT 为 918ms,Avg-5 准确率达到 69.6%,相比 1024×1024 分辨率提升 0.4 个百分点,显示出模型对极端高分辨率的适配能力。
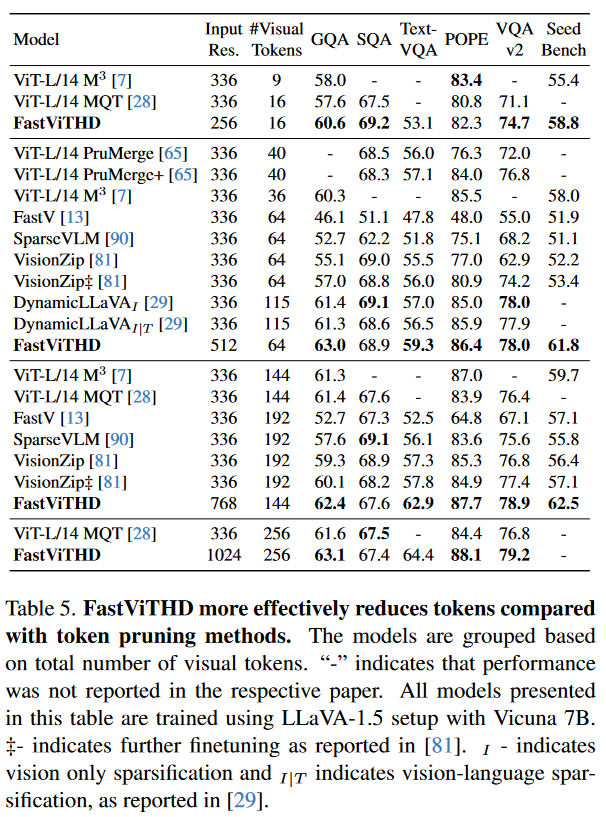
③ token优化效果对比
表 5 显示,FastViTHD 在相同token数量下,性能显著优于token剪枝方法:在 16 个token数量下,FastViTHD(256×256 分辨率)的 GQA 准确率为 60.6%,TextVQA 准确率为 53.1%,而 ViT-L/14 经 MQT 剪枝后(336×336 分辨率)的 GQA 准确率为 57.6%,TextVQA 准确率无数据,且编码延迟是 FastViTHD 的 12 倍以上。这表明,通过架构级设计减少token,比事后剪枝更高效,且能更好地保留特征信息。
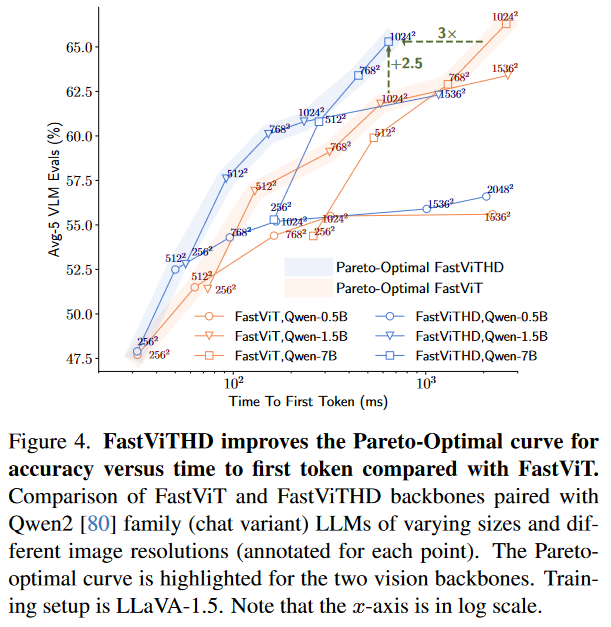
④ 帕累托最优曲线验证
论文图 4 展示了 FastViTHD 与 FastViT 的帕累托最优曲线,结果显示:在相同 TTFT 预算下,FastViTHD 的 Avg-5 准确率比 FastViT 高 2.5 个百分点;要达到相同准确率,FastViTHD 的 TTFT 是 FastViT 的 1/3。这验证了 FastViTHD 在准确率与 latency 平衡上的优越性,且这种优势在高分辨率、大 LLM 规模下更为突出。
(3)结论
卷积与 Transformer 混合的视觉编码器在 VLMs 中表现优于纯 ViT 或纯卷积架构,其核心优势在于既能借助卷积的高效下采样特性减少视觉token数量与编码延迟,又能通过 Transformer 有效捕捉全局特征以保障模型性能;
在分辨率适配方面,静态分辨率在多数场景下能够更好地平衡准确性和延迟,仅在极端高分辨率(1536×1536 以上)且硬件内存受限的特殊情况下,动态分块策略才具备补充价值;
FastVLM 通过 FastViTHD 的架构级优化,成功实现了当前最优的分辨率 - 延迟 - 准确率权衡,即便在消费级硬件上也能高效处理高分辨率图像,为 VLMs 的实际工程部署提供了切实可行的解决方案。
三、总结
这篇论文提出混合式视觉编码器 FastViTHD,以及基于 FastViTHD 的FastVLM 模型,通过卷积与 Transformer 的优势互补、多阶段下采样及多尺度特征融合等创新设计,实现分辨率、延迟与准确率的权衡。