为什么标准化要把均值设为0、方差设为1?
先说均值。均值就是平均数,所有观测值加起来除以个数。
μ是均值,n是数据点总数,xᵢ是每个数据点,所以均值就是数据的重心位置。比如均值是20,那20就是平衡点。这不是说所有点到20的距离相等而是说两边的"重量"刚好在20这个位置抵消掉。
而方差衡量的是数据有多分散,定义是每个值与均值偏差的平方的平均值。
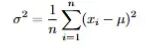
n是数据点总数,xᵢ是每个数据点,μ是均值。
那均值为0有什么用?
可以把数据想象成坐标系里的一团"点云"。每个值减去均值(x --- μ)之后,整团云就被平移到了原点位置。数据不再飘在某个角落而是以原点为中心分布。
这对很多机器学习算法都有好处,尤其是用梯度下降的时候。数据居中之后优化过程更平衡、收敛也更快。因为特征要是一开始就偏离原点很远,训练起来会麻烦不少。
那方差为1呢?
这是为了防止某个特征"欺负"其他特征。
举个例子:年龄和薪资两个特征,年龄范围10-70,薪资范围10,000-70,000。直接喂给模型的话,模型会觉得薪资比年龄重要1000倍(数字大嘛)。但这两个特征本来是独立的,凭什么薪资就更重要?
所以标准化就是除以标准差,让所有特征的方差都变成1。这样年龄和薪资就在同一个量级上了,变化幅度差不多。年龄有个小波动,不会因为薪资数字大就被模型无视掉。
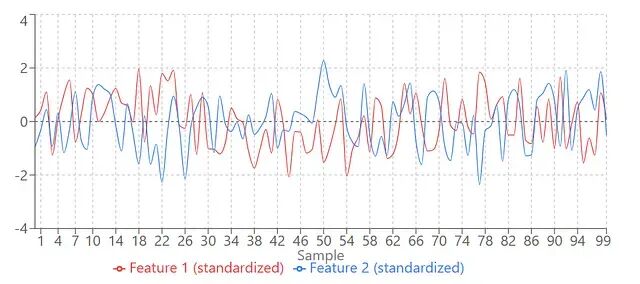
可视化效果:

标准化之前,特征1(红色,小尺度)和特征2(蓝色,大尺度)放一起,红色那条几乎看不见。标准化之后,两个特征尺度一致,都能清晰显示出来。模型终于可以公平对待它们了。
什么时候需要标准化?逻辑回归、神经网络、KNN这类用梯度下降的算法,标准化影响最大。
总结一下:
均值为0让数据居中,方差为1让特征尺度统一。两者配合,算法学得更快,也不会偏心某个特征。至于什么时候该用标准化、什么时候该用MinMaxScaler,老实说我也还在摸索。
https://avoid.overfit.cn/post/957b1b35bc1047e185dab369ae8d84ed
作者:vaishnavi