1. 引言:文本特征工程的重要性
在自然语言处理(NLP)和机器学习领域,文本数据必须转换为数值形式才能被算法理解和处理。这一转换过程被称为文本特征工程,它是NLP任务成功的关键基础。文本特征工程不仅影响模型的性能,还直接影响模型对语义的理解能力。
scikit-learn作为Python中最流行的机器学习库,提供了强大而灵活的文本特征提取工具。其中,CountVectorizer(词袋模型)和TfidfVectorizer(TF-IDF模型)是两个最核心的文本向量化工具,它们将原始文本转换为数值特征矩阵,为后续的分类、聚类、回归等机器学习任务奠定基础。
2. 环境准备与数据预处理
2.1. 导入必要模块
首先,我们需要导入scikit-learn中的文本特征提取模块:
python
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizerCountVectorizer:实现词袋模型,将文本转换为词频矩阵。
TfidfVectorizer:实现TF-IDF模型,在词频基础上考虑词语的重要性。
2.2. 示例语料准备
在NLP任务中,语料(corpus)通常指文本数据的集合。这里我们使用已经分好词的中文示例语料:
python
corpus = [
'今天 天气 不错',
'明天 天气 不好',
'天气 心情 真好',
'我 的 心情 不好'
]需要注意的是,这里假设文本已经完成了分词处理,词语之间用空格隔开。在实际应用中,通常需要使用jieba等分词工具进行预处理。
3. 词袋模型(Bag-of-Words)详解
词袋模型是最简单但非常有效的文本表示方法,它忽略文本的语法和词序,只关注词语的出现频率。
3.1. CountVectorizer基础应用
python
# 创建CountVectorizer实例(默认会去除单字词,如"的")
vectorizer_bow = CountVectorizer()
# 拟合并转换语料
# fit_transform() = fit() + transform()
# fit():学习词汇表(即所有唯一的词语)
# transform():将文本转换为词袋向量
X_bow = vectorizer_bow.fit_transform(corpus)fit_transform()方法是词袋模型的核心,它实际上执行了两个步骤:
-
fit(训练):分析所有文档,构建词汇表
-
transform(转换):将每个文档转换为基于词汇表的向量
3.2. 结果分析与可视化
python
# 查看词袋模型结果
print("词袋模型结果:\n")
# 获取词典中的词(按字母顺序)
print("词汇表:\n", vectorizer_bow.get_feature_names_out())
# 稀疏矩阵节省内存(存储非零值)
print("稀疏矩阵表示(CSR格式):\n", X_bow)
# 转换为稠密矩阵(每行代表一个句子,每列代表一个词语)
print("稠密矩阵表示(词频统计):\n", X_bow.toarray().round(2))3.2.1. 词汇表分析
词汇表按照字母顺序排列,包含了所有文档中出现过的唯一词语(去除停用词后)。
3.2.2. 稀疏矩阵优势
-
内存效率:只存储非零值,节省大量内存
-
计算效率:适合高维稀疏数据
-
CSR格式:Compressed Sparse Row格式,优化行操作
3.2.3. 稠密矩阵解读
稠密矩阵中,每行对应一个文档,每列对应词汇表中的一个词,值表示该词在文档中出现的次数。
4. TF-IDF模型详解
TF-IDF(词频-逆文档频率)是对词袋模型的改进,它不仅考虑词频,还考虑词语在整个语料库中的重要性。
4.1. TF-IDF核心原理
TF-IDF的计算公式为:TF-IDF(t,d) = TF(t,d) × IDF(t)
4.1.1. 词频(TF)计算
TF(t,d)表示词语t在文档d中出现的频率,有多种计算方法:
-
原始词频:直接计数
-
标准化词频:除以文档总词数
-
对数缩放:log(1 + 词频)
4.1.2. 逆文档频率(IDF)计算
IDF(t) = log(总文档数 / 包含词语t的文档数) + 1
IDF值越高,表示词语越稀有,区分能力越强。
4.2. TfidfVectorizer实践应用
python
# 创建TF-IDF实例(默认使用L2归一化)
vectorizer_tfidf = TfidfVectorizer()
# 拟合并转换语料
X_tfidf = vectorizer_tfidf.fit_transform(corpus)
# 查看TF-IDF模型结果
print("TF-IDF模型结果:\n")
# 获取词典中的词(按字母顺序)
print("词汇表:\n", vectorizer_tfidf.get_feature_names_out())
# 稀疏矩阵表示
print("稀疏矩阵表示(CSR格式):\n", X_tfidf)
# 转换为稠密矩阵
print("稠密矩阵表示:\n", X_tfidf.toarray().round(2))4.3. TF-IDF参数调优
4.3.1. 常用参数配置
python
# 完整的TF-IDF配置示例
vectorizer_tfidf_advanced = TfidfVectorizer(
max_features=1000, # 最大特征数
min_df=2, # 最小文档频率
max_df=0.95, # 最大文档频率
ngram_range=(1, 2), # 考虑1-2元语法
stop_words='english' # 英文停用词(中文需自定义)
)4.3.2. 归一化选项
-
L1归一化:确保每个文档的向量和为1
-
L2归一化:确保每个文档的向量欧氏长度为1(默认)
-
不使用归一化:保留原始TF-IDF值
5. 两种方法的比较与应用场景
5.1. 核心差异对比
5.1.1. 特征权重计算
-
词袋模型:仅考虑词频,高频词权重高
-
TF-IDF模型:平衡词频和词语区分度,常用但非重复词权重高
5.1.2. 优缺点分析
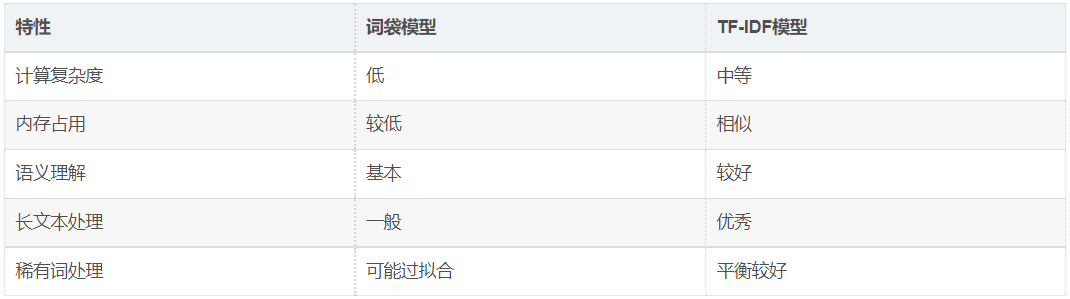
5.2. 适用场景推荐
5.2.1. 词袋模型适用场景
-
主题建模:如LDA主题模型
-
简单分类任务:当特征维度不是关键因素时
-
实时应用:对计算速度要求高的场景
-
基准模型:作为更复杂模型的对比基准
5.2.2. TF-IDF模型适用场景
-
信息检索:搜索引擎相关性排序
-
文本分类:新闻分类、情感分析等
-
文档相似度计算:推荐系统、去重检测
-
关键词提取:自动摘要、内容分析
5.3. 实际应用建议
5.3.1. 特征工程流程
-
文本预处理:分词、去除停用词、词干提取等
-
特征选择:根据任务选择合适的特征提取方法
-
参数调优:通过交叉验证优化模型参数
-
特征组合:考虑结合其他特征(如词性、句法特征)
5.3.2. 性能优化技巧
-
使用稀疏矩阵:保持数据稀疏性,提高计算效率
-
批量处理:对于大规模数据,采用增量学习或分批处理
-
特征降维:使用PCA或TruncatedSVD减少特征维度
-
缓存机制:对于重复使用的特征矩阵,使用缓存提高效率
6. 总结与进阶方向
6.1. 核心要点回顾
通过本文的讲解,我们深入理解了两种重要的文本特征提取方法:
词袋模型(CountVectorizer):简单直接,基于词频统计,适合基础文本分析任务。
TF-IDF模型(TfidfVectorizer):综合考虑词频和词语重要性,适合更精细的文本处理。
6.2. 进阶学习方向
6.2.1. 深度学习文本表示
-
词嵌入:Word2Vec、GloVe、FastText等
-
上下文表示:BERT、ELMo、GPT等预训练模型
-
句子编码:Sentence-BERT、InferSent等
6.2.2. 特征工程扩展
-
N-gram特征:捕捉词语组合信息
-
字符级特征:处理未登录词和拼写错误
-
句法特征:词性标注、依存句法等
-
语义特征:情感极性、实体识别等
6.3. 实践建议
在实际项目中,建议遵循以下最佳实践:
-
从简单开始:先用词袋模型建立基线,再尝试更复杂的方法
-
理解数据:深入分析文本数据的特性,选择合适的特征提取方法
-
持续优化:特征工程是一个迭代过程,需要不断调整和优化
-
结合领域知识:特定领域的文本处理可能需要定制化的特征工程方法
7. 代码示例
python
# 机器学习库(自然语言处理/NLP) 的特征工程
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 示例语料(假设已经分好词,用空格隔开)
corpus = [
'今天 天气 不错',
'明天 天气 不好',
'天气 心情 真好',
'我 的 心情 不好'
]
#################################################################################
# 词袋模型(Bag-of-Words)
# 创建 CountVectorizer 实例(默认会去除单字词,如"的")
vectorizer_bow = CountVectorizer()
# 拟合并转换语料
# fit_transform() = fit() + transform()
# fit() : 学习词汇表(即所有唯一的词语)
# transform() : 将文本转换为词袋向量
X_bow = vectorizer_bow.fit_transform(corpus)
# 查看结果
print("词袋模型结果:\n")
# 获取词典中的词(按字母顺序)
print("词汇表:\n",vectorizer_bow.get_feature_names_out()) # 按字母顺序排序
# 稀疏矩阵节省内存(存储非零值)
print("稀疏矩阵表示(CSR格式):\n",X_bow)
# 转换为稠密矩阵(每行代表一个句子,每列代表一个词语)
print("稠密矩形阵表示(词频统计):\n",X_bow.toarray().round(2)) # 保留2位小数,便于阅读
print("\n#################################################################################")
# 创建 TF-IDF 实例(默认使用L2归一化)
vectorizer_tfidf = TfidfVectorizer()
# 拟合并转换语料
# TF-IDF 公式:TF-IDF(t,d) = TF(t,d) * IDF(t)
# TF(t,d): 词语 t 在文档 d 中的出现次数
# IDF(t): 词语 t 在所有文档中的逆文档频率
X_tfidf = vectorizer_tfidf.fit_transform(corpus)
# 查看结果
print("TF-IDF 模型结果:\n")
# 获取词典中的词(按字母顺序)
print("词汇表:\n",vectorizer_tfidf.get_feature_names_out()) # 按字母顺序排序
# 稀疏矩阵节省内存(存储非零值)
print("稀疏矩阵表示(CSR格式):\n",X_tfidf)
# 转换为稠密矩阵(每行代表一个句子,每列代表一个词语)
print("稠密矩形阵表示(稠密表示):\n",X_tfidf.toarray().round(2)) # 保留2位小数,便于阅读