测试学习记录,仅供参考!
添加allure测试报告显示信息
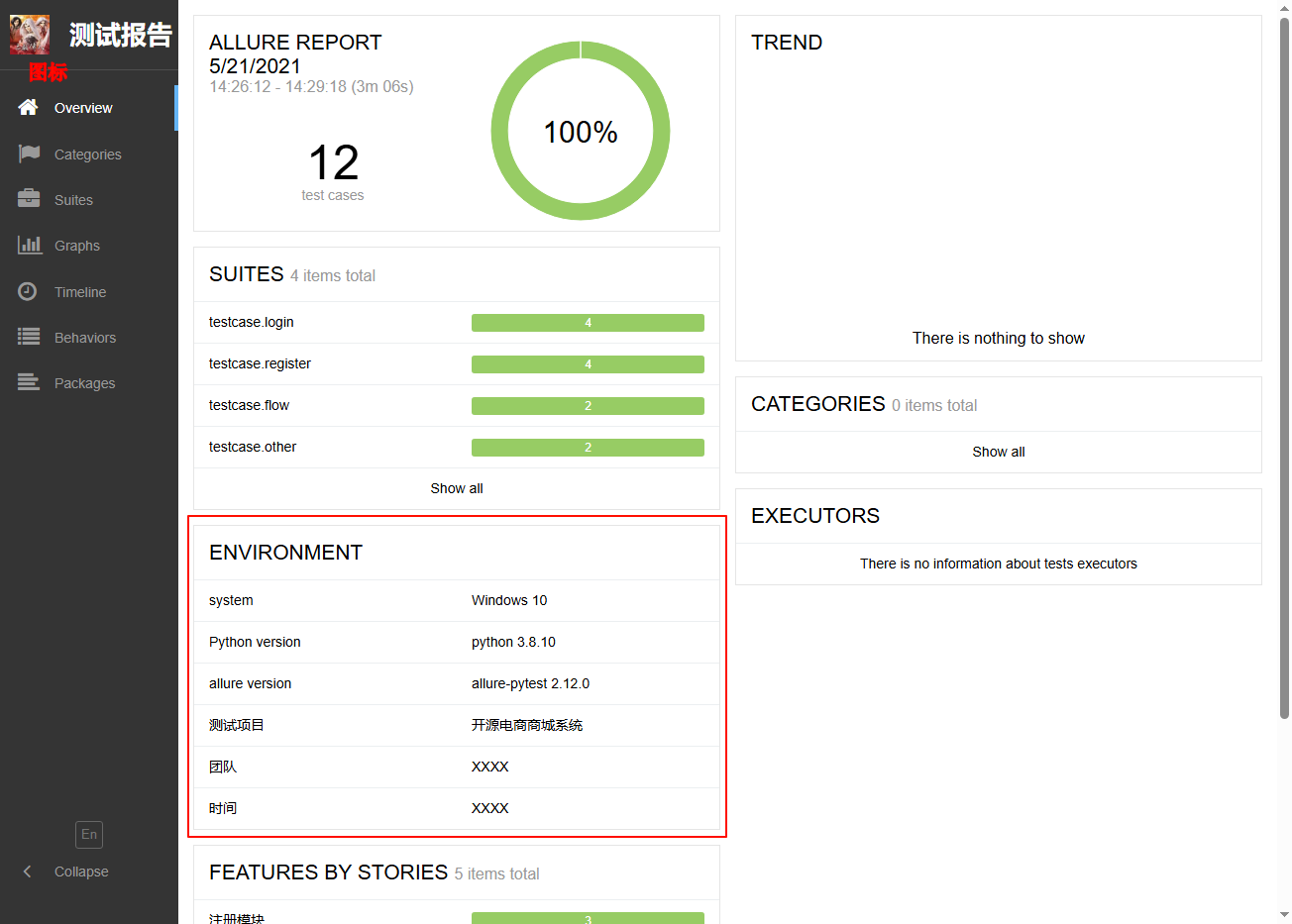
增加测试报告首页环境信息和修改 allure 测试报告显示图标;
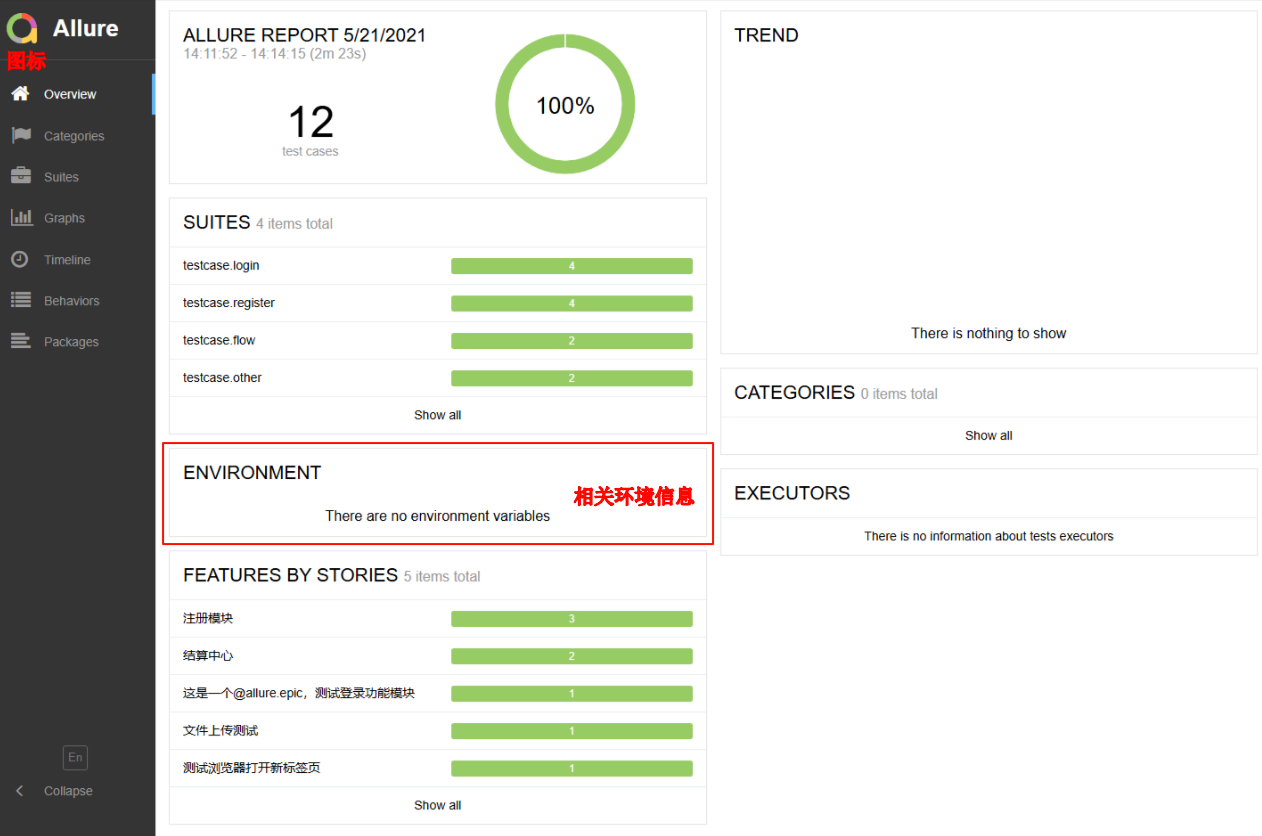
一、增加测试报告首页环境信息
1、在项目根目录下创建一个名称为 environment.xml 的配置文件,输入相关的环境配置信息;在生成测试报告时会读取此配置文件用于在allure 测试报告首页展示;
<environment>
<parameter>
<key>system</key>
<value>Windows 10</value>
</parameter>
<parameter>
<key>Python version</key>
<value>python 3.8.10</value>
</parameter>
<parameter>
<key>allure version</key>
<value>allure-pytest 2.13.8</value>
</parameter>
<parameter>
<key>测试项目</key>
<value>开源电商商城系统</value>
</parameter>
<parameter>
<key>团队</key>
<value>XXXXXX</value>
</parameter>
<parameter>
<key>时间</key>
<value>XXXXXXXX</value>
</parameter>
</environment>2、优化 run.py 文件内容;
import pytest
import os
import shutil
if __name__ == '__main__':
pytest.main()
shutil.copy('./environment.xml', './report/temp')
os.system('allure serve ./report/temp')二、修改 Allure 显示图标
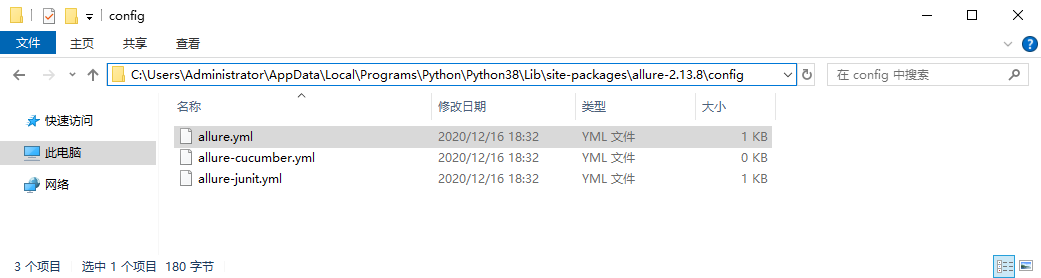
3、找到 allure.yml 文件(python 安装文件路径下 allure 资源包文件夹目录中--烦请根据自身实际情况)
例: C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Lib\site-packages\allure-2.13.8\config
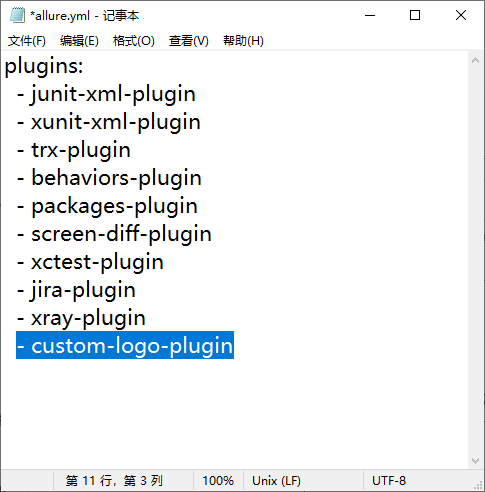
4、选中 allure.yml 文件,以记事本格式打开,增加"- custom-logo-plugin "后保存(自行修改);
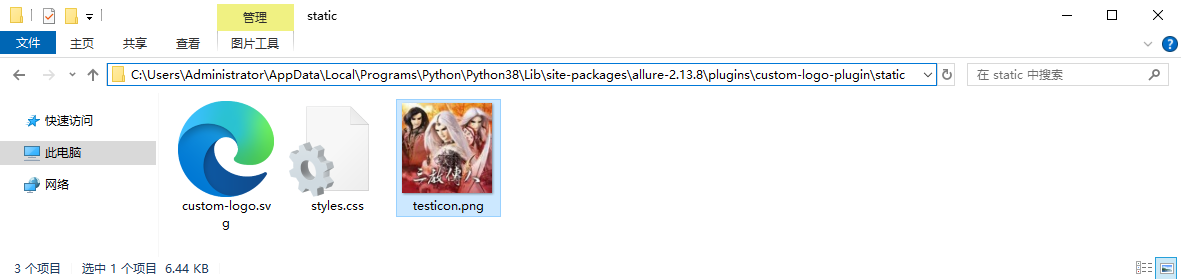
5、将要显示的图片放到相关的对应文件夹下(烦请自行设置);
C:\Users\Administrator\AppData\Local\Programs\Python\Python38\Lib\site-packages\allure-2.13.8\plugins\custom-logo-plugin\static
6、打开 styles.css 文件(打开方式自行选择,例如:记事本格式、写字板、Notepad++等等);
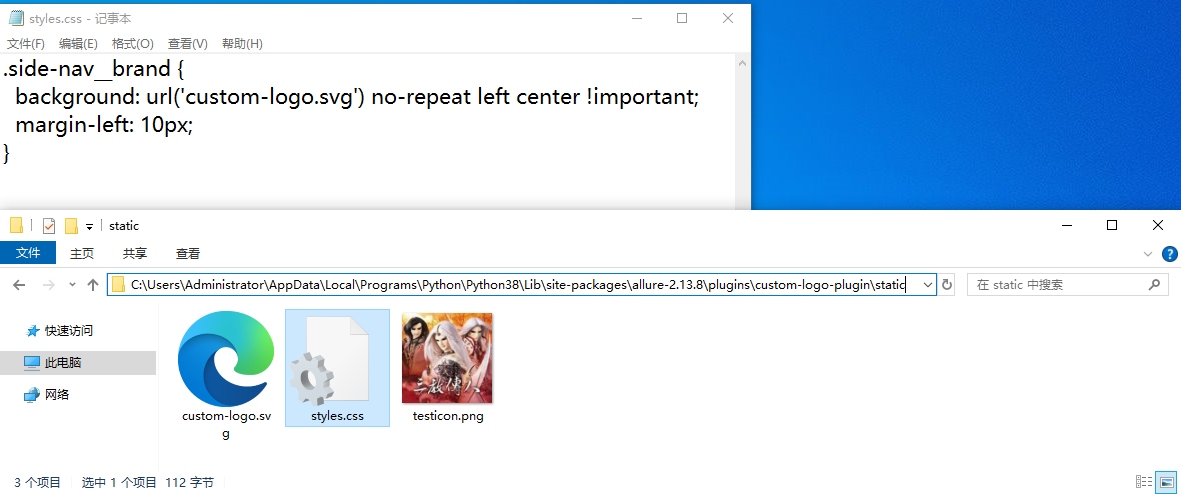
7、修改 styles.css 文件内容并保存(烦请根据实际图片大小和显示的内容自行设置);
testicon.png:图标的名字;
测试报告:图标旁要显示的内容;
.side-nav__brand {
background: url('testicon.png') no-repeat left center !important;
margin-left: 10px;
height: 40px;
background-size: contain !important;
}
.side-nav__brand span {
display: none;
}
.side-nav__brand:after {
content: "测试报告";
margin-left: 20px;
}8、运行主函数 run.py 文件,查看测试报告显示结果;
封装模拟鼠标键盘的操作
已定位到元素但无法进行输入操作的最终解决方法;
ElementNotInteractableException 是一个常见的异常,元素无法进行交互的异常;通常发生在尝试与网页上的某个元素进行交互时,但是此元素不可交互;说明前端开发人员把元素设置成了隐藏、禁用、不可操作等一系列防自动化参数、防爬虫手段机制等,此时调用 webdriver 里面的 send_keys 输入操作是无法输入的;封装一个通过模拟鼠标、键盘的输入操作进行输入内容,来解决无法进行输入的问题;
封装方法
封装模拟鼠标、键盘的输入方法
1、 优化项目根目录 util_tools 软件包下 basePage.py 文件,封装 模拟鼠标键盘的输入 方法;可参照webdriver 中的输入方法进行封装;
1)、定义函数方法 def send_keys_actions(self):
2)、跟 send_keys 方法一样,需要传两个参数:def send_keys_actions(self, locator: tuple, data):
3)、先找到元素:通过调用已经封装好的方法 element = self.location_element(*locator)
4)、调用模拟鼠标键盘的类:ActionChains()
5)、传入浏览器对象:ActionChains(self.__driver)
6)、调用 move_to_element() 方法:把找到的 element 元素传进来 move_to_element(element)
7)、点 click():ActionChains(self.__driver).move_to_element(element).click()
8)、再点 send_keys():ActionChains(self.__driver).move_to_element(element).click().send_keys()
9)、输入 data 内容:ActionChains(self.__driver).move_to_element(element).click().send_keys(data)
10)、提交动作链:ActionChains(self.__driver).move_to_element(element).click().send_keys(data).perform()
11)、参照 webdriver 的 send_keys 输入方法添加异常和日志信息;
def send_keys_actions(self, locator: tuple, data):
"""
模拟鼠标键盘的输入操作
:param locator: (tuple)定位元素信息,元组类型;
:param data: 输入的内容
:return:
"""
try:
element = self.location_element(*locator)
ActionChains(self.__driver).move_to_element(element).click().send_keys(data).perform()
logs.info(f"元素被输入内容:{locator},输入的内容为:{data}")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e模拟鼠标、键盘的操作把页面滑动到最下面
打开页面之后,把页面滑动到最下面;
2、使用window.scrollTo方法:通过调用window.scrollTo方法将页面滚动到指定位置。第一个参数表示水平滚动位置,第二个参数表示垂直滚动位置。这种方法适用于需要精确控制滚动位置的情况。需要注意的是,这种方法在使用时应确保页面内容已经加载完毕,否则可能无法正确获取到页面高度或元素位置。document.body.scrollHeight返回整个文档的高度(包括不可见的部分),然后**scrollTo(x, y)**方法将页面滚动到指定的x和y坐标,其中x通常为0,表示水平滚动位置,而y为目标位置。
def scroll_to_button(self):
"""使用JavaScript滚动页面到最底部"""
# self.__driver.execute_script('window.scrollTo(0, document.documentElement.scrollHeight);')
self.__driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')3、逐步优化完善 basePage.py 文件;
# 导包
from pyxnat.core.uriutil import file_path
from selenium import webdriver
from selenium.common import NoSuchElementException, TimeoutException
from selenium.webdriver.common.by import By
from time import sleep
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.wait import WebDriverWait
from config import setting
from util_tools.logs_util.recordlog import logs
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from datetime import datetime
import pytesseract
from PIL import Image
from selenium.webdriver.support.ui import Select
from util_tools.handle_data.configParse import ConfigParse
class BasePage(object):
def __init__(self, driver):
self.__driver = driver
self.__wait = WebDriverWait(self.__driver, setting.WAIT_TIME)
self.conf = ConfigParse()
def window_max(self):
self.__driver.maximize_window()
def window_full(self):
self.__driver.fullscreen_window()
def screenshot(self):
self.__driver.get_screenshot_as_png()
def open_url(self, url):
if url.startswith('http') or url.startswith('https'):
self.__driver.get(url)
logs.info(f'打开页面:{url}')
else:
new_url = self.conf.get_host('host') + url
self.__driver.get(new_url)
logs.info(f'打开页面:{new_url}')
def get_tag_text(self, locator: tuple):
try:
element = self.location_element(*locator)
element_text = element.text
logs.info(f'获取标签文本内容:{element_text}')
return element_text
except Exception as e:
logs.error(f'获取标签文本内容出现异常,原因为:{str(e)}')
@property
def current_url(self):
return self.__driver.current_url
@property
def title(self):
return self.__driver.title
def refresh(self):
self.__driver.refresh()
def scroll_to_button(self):
self.__driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
@property
def switch_to(self):
return self.__driver.switch_to
def iframe(self, frame):
try:
self.switch_to.frame(frame)
logs.info(f'切换到{frame}--iframe内部框架中')
except:
logs.error('切换到iframe框架失败!')
def switch_to_new_tab(self):
try:
original_window = self.__driver.window_handles[0]
all_window = self.__driver.window_handles
new_window = None
for window in all_window:
if window != original_window:
new_window = window
break
if new_window:
self.switch_to.window(new_window)
logs.info('成功切换到新标签页')
except TimeoutException:
logs.error('等待新标签页打开超时。')
except NoSuchElementException:
logs.error('未找到新标签页句柄。')
except Exception as e:
logs.error(f'切换窗口时发生异常:{str(e)}')
def exit_iframe(self):
self.switch_to.default_content()
@property
def alert(self):
return self.__wait.until(ec.alert_is_present())
def alert_confirm(self):
self.alert.accept()
def alert_cancel(self):
self.alert.dismiss()
def location_element(self, by, value):
try:
element = self.__wait.until(ec.presence_of_element_located((by, value)))
logs.info(f"找到元素:{by}={value}")
return element
except Exception as e:
logs.error(f"未找到元素:{by}={value}")
raise e
def location_elements(self, by, value):
try:
self.__wait.until(ec.presence_of_all_elements_located((by, value)))
elements = self.__driver.find_elements(by, value)
logs.info(f"找到元素列表:{by}={value}")
return elements
except Exception as e:
logs.error(f"未找到元素列表:{by}={value}")
raise e
def click(self, locator: tuple, force=False):
try:
element = self.location_element(*locator)
if not force:
self.__driver.execute_script("arguments[0].click()", element)
else:
self.__driver.execute_script("arguments[0].click({force:true})", element)
logs.info(f"元素被点击:{locator}")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def send_keys(self, locator: tuple, data):
try:
element = self.location_element(*locator)
element.send_keys(data)
logs.info(f"元素被输入内容:{locator},输入的内容为:{data}")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def send_keys_actions(self, locator: tuple, data):
try:
element = self.location_element(*locator)
ActionChains(self.__driver).move_to_element(element).click().send_keys(data).perform()
logs.info(f"元素被输入内容:{locator},输入的内容为:{data}")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def selects(self, locator: tuple, index):
try:
select = Select(self.location_element(*locator))
select.select_by_index(index)
logs.info(f'选择第{index}个数据')
except NoSuchElementException as e:
logs.error(f'元素无法定位:{e}')
raise e
def enter(self):
try:
ActionChains(self.__driver).send_keys(Keys.ENTER).perform()
logs.info("按下回车键")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def right_click(self, locator: tuple):
try:
element = self.location_element(*locator)
ActionChains(driver).context_click(element).perform()
logs.info("执行鼠标右键点击操作")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def double_click(self, locator: tuple):
try:
element = self.location_element(*locator)
ActionChains(driver).double_click(element).perform()
logs.info("执行鼠标双击操作")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def screenshots(self, image_name):
import os
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
file_name = f"{image_name}-{current_time}.png"
file_path = os.path.join(setting.FILE_PATH.get('screenshot'), file_name)
self.__driver.get_screenshot_as_file(file_path)
def screenshots_png(self):
return self.__driver.get_screenshot_as_png()
def clear(self, locator: tuple):
try:
element = self.location_element(*locator)
element.clear()
logs.info("清空文本")
except NoSuchElementException as e:
logs.error(f"元素无法定位:{e}")
raise e
def ocr_captcha(self, locator: tuple):
captcha_element = self.location_element(*locator)
captcha_path = setting.FILE_PATH['screenshot'] + '/captcha.png'
captcha_element.screenshot(captcha_path)
captcha_image = Image.open(captcha_path)
try:
captcha_text = pytesseract.image_to_string(captcha_image)
logs.info(f"识别到的验证码为:{captcha_text}")
return captcha_text
except pytesseract.pytesseract.TesseractNotFoundError:
logs.error("找不到tesseract,这是因为pytesseract模块依赖于TesseractOCR引擎来进行图像识别!")
def is_element_present(self, locator: tuple):
try:
self.__wait.until(ec.presence_of_element_located(*locator))
return True
except:
return False
def assert_is_element_present(self, locator: tuple):
try:
element = self.__driver.find_element(*locator)
assert element.is_displayed(), '元素不存在'
except NoSuchElementException as e:
logs.error(f'元素未找到:{e}')
raise AssertionError('元素不存在')
def assert_element_not_visible(self, locator: tuple):
try:
self.__wait.until(ec.invisibility_of_element_located(locator))
except TimeoutException:
logs.error('元素可见')
def assert_title(self, expect_title):
assert expect_title in self.title
if __name__ == '__main__':
driver = webdriver.Edge()未完待续。。。