为什么Netty要自己封装bytebuf,bytebuf为什么好用?
Java的网络编程中基本都是基于TCP的字节流进行数据传输的,所以Java提供了 ByteBuffer 作为传输数据的载体,但是原生的ByteBuffer不好用,而netty提供的ByteBuf比较好用,主要体现在:
自动扩容
原生的ByteBuffer只能在初始化的时候指定大小,并且当数据满了之后就无法继续填充了,而bytebuf初始化的时候会有一个初始大小,在后续写入的时候如果超过了ByteBuf的容量就会触发扩容机制,按照16的整数倍进行扩容
和ArrayList一样
自动处理读写指针
在原生的 ByteBuffer 中有limit,capacity两个指针,每次执行read的时候都是从position位置开始,position这个指针就是指向当前读到哪一个位置或是下一次写入的位置,所以每次写入之后想要读取需要调用一下 flip() 这个函数,否则会导致读取不到数据的情况
但是要是我们忘记主动去调用 flip() 函数,就会导致错误的情况,大大的增加了代码的风险
而Netty 的 ByteBuf 通过读写双指针来解决这个问题,并且在写入的时候我们可以直接去读取,无需关系内部的结构,对开发人员非常友好
此外Netty也提供了discardReadBytes 这个方法用来丢弃已经读取过的数据,和原生NIO中的compact() 类似
那你能说说ByteBuf的实现类型有哪些吗?一般是用哪些?怎么选择?
分为两个指标,基于堆内存还是基于直接内存,池化还是非池化
默认情况下就是直接内存,这个也是最通用的,如果需要堆内存的话需要调用特定的方法获取,堆内存的特点是处理数据会比较快,会比较适合处理一些内存的数据操作,而直接内存比较适合处理Socket相关的
除了安卓系统之外,其他系统默认就是池化的,池化比较适合处理高并发场景,而非池化比较适合正常流量场景,这个可以通过启动参数执行
Netty的零拷贝是如何实现的?
操作系统的零拷贝是指避免在用户态和内核态之间的数据拷贝
但是Netty的零拷贝不是这个意思,它是指数据操作时不需要将buffer从一个内存拷贝到另一个内存,通过减少这种数据拷贝从而提高性能
主要可以体现在下面几个方面:
- 直接使用堆外内存(也叫直接内存),这样就避免了数据从JVM的堆内存拷贝到操作系统的直接内存的过程
- **CompositeByteBuf 类:**将多个ByteBuf合并成一个逻辑上的ByteBuf,操作的时候就像是在操作同一个ByteBuf,但是又不需要去进行数据操作的过程
- **Unpooled.wrappedBuffer:**可以将一个Byte数组包装成一个ByteBuf,这个过程不会产生数据拷贝,只是改变了变量指向
- **ByteBuf.slice:**这个就是将一个ByteBuf切分成多份,逻辑上是多个ByteBuf,但是其实底层指向的是同一个Byte数组
- FileRegion:里面封装了FileChannel#transferTo() 方法,能实现将文件缓冲区的数据直接传到目标channel上,属于系统级别的零拷贝
什么是堆外内存?如何使用?
堆外内存就是直接内存,也就是操作系统中的。如果我们是将数据写到堆内存中,底层还需要把这个数据拷贝到操作系统的直接内存中才能进行拷贝,但是如果是写入到直接内存的话,就减少了这一个拷贝的过程
使用Netty进行通信的时候,如果允许Unsafe访问,或是非安卓系统且为默认配置的时候就会直接使用直接内存
public ByteBuf ioBuffer(int initialCapacity) {
if (PlatformDependent.hasUnsafe() || isDirectBufferPooled()) {
return directBuffer(initialCapacity);
}
return heapBuffer(initialCapacity);
}CompositeByteBuf 介绍一下具体的作用以及用在什么场景?
CompositeByteBuf 就是将多个ByteBuf在逻辑上合并成一个,但是底层其实还是多个
主要的场景就是可能发送方是将消息拆成两个ByteBuf,然后通过tcp传递过来,这个时候就需要接收方接收之后进行合并
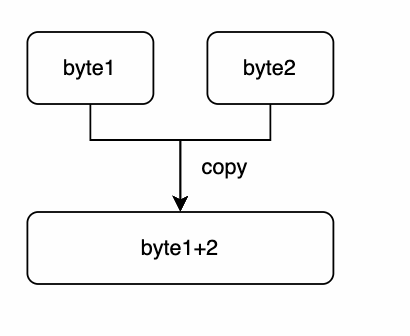
但是接收方想要合并就涉及到拷贝的操作,所以Netty为了节省这一次拷贝操作就提供了CompositeByteBuf这个类实现逻辑上的合并
好处:少了一步数据拷贝
Unpooled.wrappedBuffer 介绍一下
Unpooled.wrappedBuffer 是创建 CompositeByteBuf 对象的另一种推荐做法。
Unpooled.wrappedBuffer 方法可以将不同的数据源的一个或者多个数据包装成一个大的 ByteBuf 对象,其中数据源的类型包括 byte\[\]、ByteBuf、ByteBuffer 。包装的过程中不会发生数据拷贝操作 ,包装后生成的 ByteBuf 对象和原始 ByteBuf 对象是共享底层的 byte 数组。
byte[] bytes = new byte[1];
byte[] bytes2 = new byte[1];
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes, bytes2);ByteBuf.slice 介绍一下
就是将一个ByteBuf在逻辑上切分成多个分片,每个分片包含一部分数据,但是其实底层还是同一块内存
并且切分后的分片不能新增操作
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer();
ByteBuf f1 = byteBuf.slice(0, 4);
ByteBuf f2 = byteBuf.slice(4, 4);FileRegion文件传输 能说一下吗?
FileRegion 就是 Netty 的一个接口,基于Java底层的FileChannel#tranferTo方法实现的,可以根据操作系统直接将文件缓冲区的数据发送到目标channel中,这个底层是操作系统来实现的
FileRegion region = new DefaultFileRegion(raf.getChannel(), 0, raf.length());
ctx.writeAndFlush(region);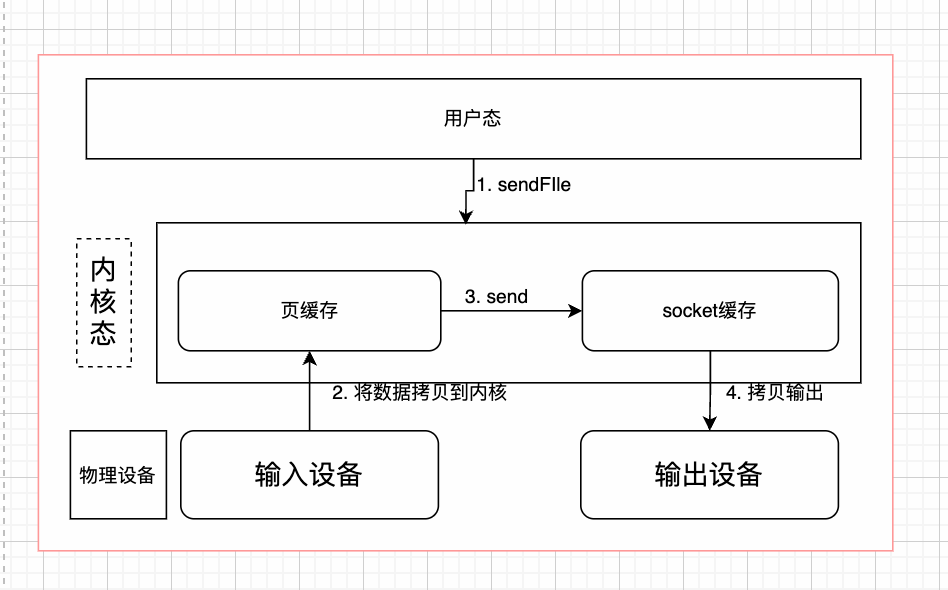
Netty 的线程模型是怎么样的?
Netty 通过 Reactor 模型 基于**多路复用器(selector)**接收并处理用户请求的。
多路复用可以理解为就是去询问操作系统是否准备好,如果准备好才去调用执行相应的操作
多路复用 在操作系统层面常见的实现方式 select(win)、epoll、poll
然后Netty的线程模型并不是一成不变的,而是看你的参数设置,可以分为(Reactor指的就是事件分发器):
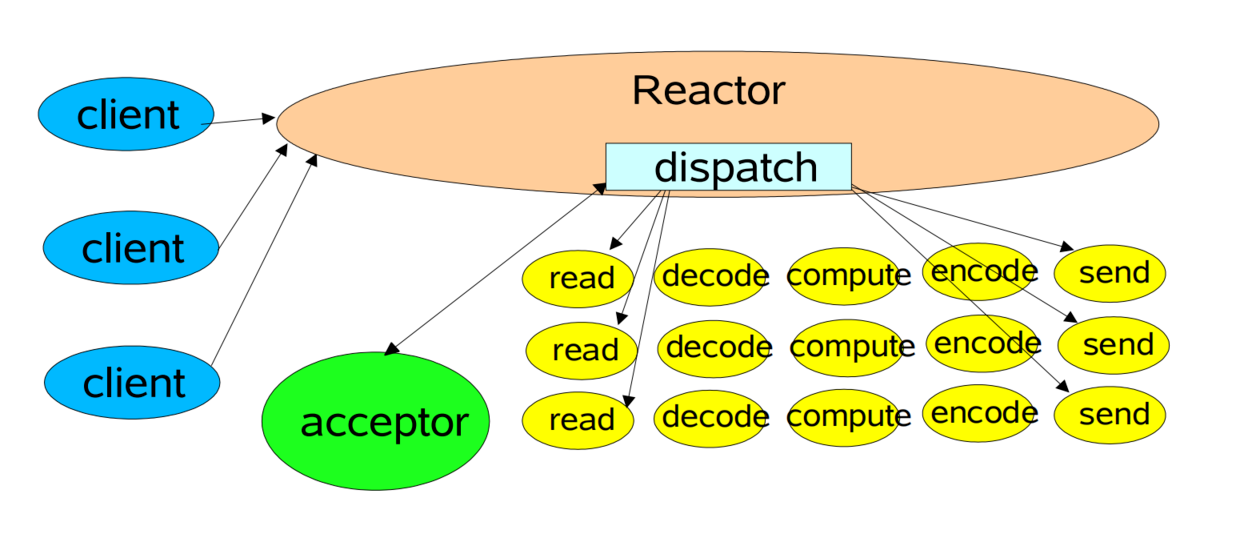
单Reactor单线程模型(就是只有一个NioEventLoopGroup且指定线程数为1)
这是最简单的Reactor模型,当有多个客户端连接到服务器的时候,服务器会先通过线程A和客户端建立连接,
有连接请求后,线程A会将不同的事件(如连接事件,读事件,写事件)进行分发,譬如有IO读写事件之后,会把该事件交给具体的Handler进行处理。
ServerBootstrap bootstrap = new ServerBootstrap();
NioEventLoopGroup group = new NioEventLoopGroup(1);
bootstrap.group(group);单Reactor多线程模型(只有一个NioEventLoopGroup但是线程数是多个)
为了利用多核CPU的优势,也为了防止在Reactor线程等待读写事件时候浪费CPU,所以可以使用线程池,由此升级为单Reactor多线程模式。

ServerBootstrap bootstrap = new ServerBootstrap();
NioEventLoopGroup group = new NioEventLoopGroup(5);
bootstrap.group(group);NioEventLoopGroup 里面会派出 一个 线程负责处理Accept操作,其他的线程负责 channel 上的 read/write操作
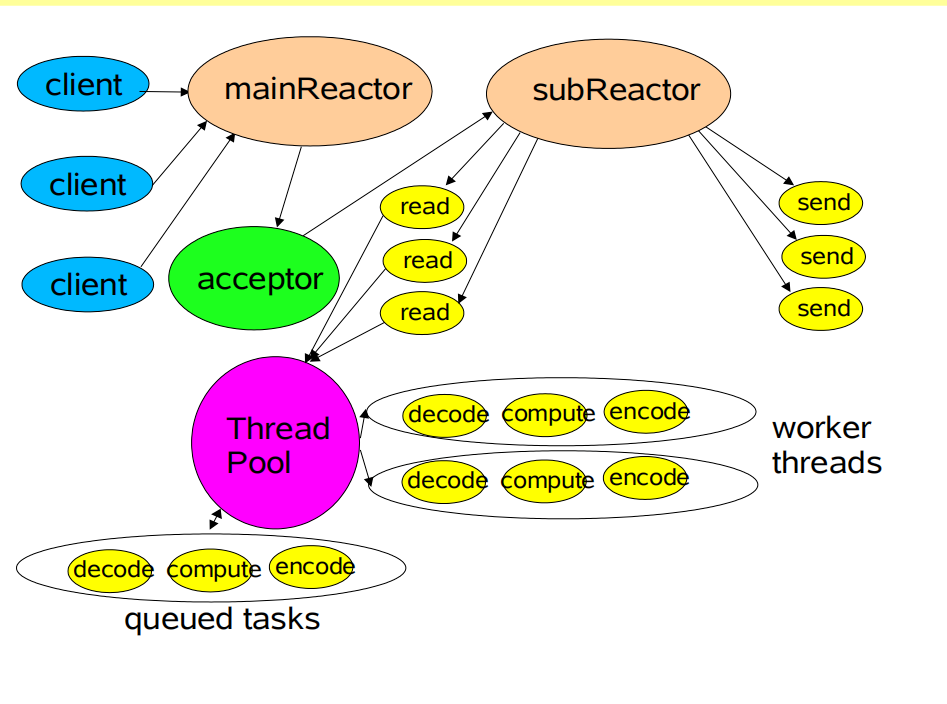
主从Reactor模型
在主从Reactor模型中,主Reactor线程只负责连接事件的处理,它把读写事件全部交给了子Reactor线程。这样即使在数据准备阶段子线程被阻塞,主Reactor还是可以处理连接事件。巧妙的解决了高负载下的连接问题。
ServerBootstrap bootstrap = new ServerBootstrap();
NioEventLoopGroup boss = new NioEventLoopGroup(1);
NioEventLoopGroup worker = new NioEventLoopGroup(5);
bootstrap.group(boss, worker);其实就是有两个角色,boss就是主Reactor,它只负责接收accept请求,由于一个服务端只会用到一个线程来处理这种请求,所以可以设置成1,不设置也没关系
worker 就是 子Reactor,它负责channel上的 read/write 事件
这种也是我们的直播项目里面使用的方式
什么是粘包拆包?Netty是如何解决TCP的粘包和拆包问题的?
拆包粘包:
粘包拆包问题主要是TCP场景下会出现的,因为TCP是以数据流的形式进行传输,数据本身没有边界,并且TCP的一些优化算法或是双方缓冲区大小等问题的限制,会导致TCP将一个数据拆分成多份进行传输导致拆包或是为了效率将多个小数据合成一个传输造成粘包,,可以总结为就是因为消息本身没有边界导致的
注意:只有使用原生TCP才需要去解决这个问题,如果是使用的上层协议,例如HTTP或是WebSocket,大概率都是都是已经帮我们实现了粘包拆包问题的,所以使用这两个协议的时候不需要手动去解决;当然因为TCP性能好的原因,还是有很多使用场景的
Netty解决方式(一系列解码器):
Netty的解决方式可以总结为都是基于接收方和发送方双方约定,从而来解决粘包拆包问题
1. 定长解码器(FixedLengthFrameDecoder)
就是发送方和接收方提前约定好消息的长度,比如约定10个字节,这样接收方每次都按照10个字节进行解析
缺点 :不太灵活,假如客户端只需要发送1个字节,但是同样需要使用占位符的形式填充到10个字节,造成资源浪费,或者是来了一个消息的长度是大于10的,就无法完整发送
2. 分隔符解码器(LineBasedFrameDecoder、DelimiterBasedFrameDecoder)
就是双方约定一个消息结束的分隔符,然后发送方在每个消息结束的时候加一下这分隔符(\n),接收方每次截取到这个分隔符就认为是一次完整的数据
缺点:如果要发送的消息里面也有分隔符就比较麻烦
3. 定长解码器(LengthFieldBasedFrameDecoder)
这个其实就是发送的消息不是只有内容,还有一些标识信息,可以在消息中用一个字节来标识内容真正的长度,这样处理器就能根据这个长度作为消息的边界
4. 自定义解码器(ByteToMessageDecoder)
如果以上的手段还不满足项目需求的话,其实可以自己编写一个类,实现一下**ByteToMessageDecoder,**然后可以在里面去做特定的解码操作,因为可能有些场景是用到一些特定的序列化方式
我的项目里面用到的其实是这种方式,将解析出来的数据封装成一个实体对象传递给下游
Netty 性能好的原因?
- 非阻塞IO模型 :Netty采用了IO多路复用技术,让多个IO的阻塞复用到一个select线程阻塞上,能够有效的应对大量的并发请求
- 高效的Reactor线程模型:支持多种Reactor线程模型,可以根据业务场景的性能诉求,自行选择
- 零拷贝:尽量避免不必要的内存拷贝
- 内存池设计(ByteBuf) :使用直接内存,并且可重复利用
- 无锁串行化设计:避免使用锁带来的额外开销
- 高性能序列化协议:支持 protobuf 等高性能序列化协议
说说Netty的无锁化串行设计?
首先Netty是多线程的,但是我们知道,多线程往往会带来很多并发安全的问题,所以就避免不了使用锁,但是Netty并没有使用锁,但是依旧是线程安全的
第一点就需要说一下Netty的线程模型,它无论是哪一种模型(单Reactor单线程,单Reactor多线程,或是主从Reactor),它都是限制了一个服务端用来接收accept事件的线程只有一个(线程模型的功劳)
此外就是线程池技术 ,Netty是使用线程池技术来解决Read/write事件的,并且一个客户端连接一旦完成初始化之后就会和一个线程进行绑定(一个channel会绑定一个唯一的 EventLoop),后续这个通道上的读写操作都是这个线程来负责,这样就避免了多个线程同时处理一个通道读写事件的危险,当然因为一个线程可以绑定多个客户端,所以当某一个线程的任务比较饱满的时候就会导致其它的客户端可能会等的稍微久一点
讲一下Netty的对象池技术?
Netty内置的对象池就是用来解决一些对象重复创建和销毁的问题,可以做到复用,从而提高系统的可靠性和性能
对象池是一种非常常见的设计模式,它在多线程的环境中特别有用,能够有效地减少线程的上下文切换和资源的浪费,同时也有利于避免内存泄漏等问题。Java中的字符串池,其实也就是一种对象池技术
那比较常用的其实就是ByteBuf,因为我们使用的时候可能会频繁的使用到ByteBuf,但是频繁的创建和消费会比较浪费性能,所以Netty内置相关的对象池,默认情况下就是开启池化模式(安卓环境除外),这样大大的提高对象的利用率
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer();直接通过这种方式申请的就是对象池中的一个实例,在我们使用完之后,netty会自动的把这个对象归还给对象池
Netty 对象池技术主要有以下几个优势:
- 提高性能:重复利用对象可以避免频繁地创建和销毁对象,从而减少了系统开销,提高了系统的性能。
- 提高可靠性:通过避免对象的重复创建和销毁,可以避免一些潜在的内存泄漏问题,从而提高系统的可靠性和稳定性。
- 简化编程:通过使用对象池,可以让开发人员更加专注于业务逻辑的实现,而不必过于关心对象的创建和销毁。
Netty 支持哪些序列化协议?
Netty支持很多种序列化协议,基本上市面上常见的序列化协议他都支持的。如:
Java原生序列化:Java原生的序列化协议,可以序列化所有实现了Serializable接口的对象。Java序列化虽然简单易用,但是序列化后的字节数较大,序列化性能较差,且不具备跨语言的能力,因此不太常用。
JSON序列化:JSON是一种轻量级的数据交换格式,易于阅读和编写,同时也具备跨语言的能力,因此在分布式系统中广泛使用。Netty内置了多种JSON序列化库,包括Jackson、FastJSON等。
XML序列化:XML也是一种常用的数据交换格式,可以用于跨语言的数据交换。Netty内置了多种XML序列化库,包括JAXB、XStream等。
Protobuf序列化:Protobuf是Google开源的一种高效、灵活的二进制序列化协议,具有良好的跨语言能力和高效的序列化性能,被广泛应用于分布式系统中。Netty内置了对Protobuf的支持。
Thrift序列化:Thrift也是一种由Apache开源的二进制序列化协议,具有跨语言、高效等特点,被广泛应用于分布式系统中。Netty也提供了对Thrift的支持。
Netty中使用到了哪些设计模式?
单例模式、策略模式、责任链模式、工厂模式、观察者模式、装饰器模式等