大家好,我是java1234_小锋老师,最近更新《AI大模型应用开发入门-拥抱Hugging Face与Transformers生态》专辑,感谢大家支持。
本课程主要介绍和讲解Hugging Face和Transformers,包括加载预训练模型,自定义数据集,模型推理,模型微调,模型性能评估等。是AI大模型应用开发的入门必备知识。

使用datasets库加载Huggingface数据集
Huggingface以及魔塔社区提供了很多数据集,我们可以使用这些数据集来训练和微调模型。
我们首先要安装下datasets库。
pip install datasets -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.comIMDb 数据集包含电影评论和相应的情感标签(正面或负面)。这个数据集非常适合情感分析和舆情分析的任务。
https://huggingface.co/datasets/stanfordnlp/imdb我们用里面的测试集和训练集文件。
Parquet是一种列式存储文件格式,专为高效存储和处理大规模数据设计,广泛应用于大数据生态系统(如Spark、Hadoop)。其核心特点包括:
1,高效压缩:通过列式存储实现高压缩比(如Snappy、Gzip编码),显著减少磁盘空间占用。
2,查询优化:支持映射下推(仅读取所需列)和谓词下推(过滤无效数据),提升查询性能。 3,嵌套数据支持:原生处理复杂嵌套结构(如JSON、Map),无需扁平化存储。
我们可以通过datasets库的load_dataset()方法来加载数据集。
测试代码:
from datasets import load_dataset
# 加载 IMDb 数据集
dataset = load_dataset(path="./imdb")
train = dataset['train'] # 获取训练集
test = dataset['test'] # 获取测试集
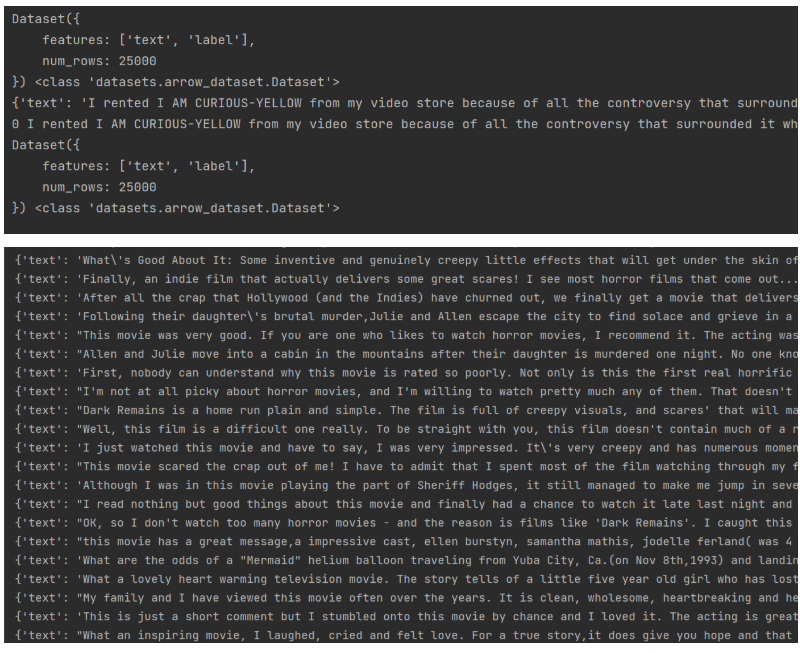
print(train, type(train))
print(train[0], type(train[0])) # 每个元素是一个字典
print(train[0]['label'], train[0]['text'])
print(test, type(test))
# 遍历数据集
for i in train:
print(i)运行输出:
微博评论csv下载
https://www.modelscope.cn/datasets/Sunnyshan/weibo_sentimentcsv文件的数据集获取代码:
from datasets import load_dataset
# 加载微博数据集
dataset = load_dataset(path="csv", data_files="./weibo_senti_100k.csv")
# 获取数据集
train = dataset['train']
for i in train:
print(i)运行输出:
