摘要
本文系统梳理大模型与向量检索的完整知识体系,从基础概念、核心技术模块出发,深入剖析二者基于 RAG 的协同融合机制,结合Spring AI 实现工业级落地实践,并针对工程化部署、性能优化给出可落地的解决方案。内容覆盖嵌入模型、向量检索算法 / 数据库、RAG 基础 / 进阶流程、多场景应用。
一、基础层:核心概念与理论基石
1.1 大模型核心(与向量检索强相关)
- 语义嵌入 :将文本(词 / 句 / 文档)转化为低维稠密语义向量 的过程,是大模型与向量检索的核心桥梁,需保留文本语义关联性(如 "Java 微服务" 与 "Spring Cloud" 向量距离近)。
- 上下文窗口 :大模型可处理的最大文本长度,向量检索通过 "外部知识片段检索" 突破该限制,解决长文本处理难题。
- 事实性幻觉 :大模型基于预训练知识生成易产生无依据内容,向量检索引入实时 / 领域真实知识 从根源缓解该问题。
- 检索增强生成(RAG) :二者融合的核心范式,先检索外部知识,再将知识与查询拼接输入大模型生成答案,实现 "精准检索 + 智能生成" 闭环。
1.2 向量检索核心
1.2.1 核心定义
- 语义向量 :由嵌入模型生成,维度常见 128/256/768/1024,维度越高语义信息越完整,存储 / 计算成本也越高。
- 向量空间与距离 :所有语义向量构成高维空间,向量距离 衡量语义相似度,距离越近语义越相似。
- 精确近邻搜索(ANS) :遍历所有向量计算距离,精度 100% 但时间复杂度 O (N),仅适用于万级以下小数据集。
- 近似近邻搜索(ANN) :以微小精度损失换取极快检索速度,是工业级亿级 / 十亿级数据集的核心方案。
1.2.2 主流距离度量指标
|-----------------|----------------|--------------|-----------------------|
| 度量指标 | 核心计算逻辑 | 适用场景 | 核心特点 |
| 余弦相似度 | 向量点积 /(向量模长乘积) | 高维语义向量(最常用) | 对向量长度不敏感,仅关注方向,适配语义匹配 |
| 欧几里得距离(L2) | 坐标差的平方和开根 | 低维向量、数值型特征匹配 | 对维度缩放敏感,需先做归一化 |
| 内积(Dot Product) | 对应维度乘积和 | 归一化后的高维向量 | 计算效率最高,与余弦相似度等价 |
| 曼哈顿距离(L1) | 坐标差的绝对值和 | 低维、稀疏向量 | 计算简单,抗噪性较强 |
1.2.3 核心数学基础
- 维度灾难 :高维空间中向量间距离趋于一致,检索区分度下降,需通过降维 或高效 ANN 算法 缓解。
- 向量归一化 :将向量缩放到单位长度,使余弦相似度与内积等价,提升计算效率。
- 并行计算 :向量生成、存储、检索均为高并行任务,依赖 CPU 多核 / GPU/TPU 的并行计算能力。
二、技术层:两大核心技术模块详解
2.1 嵌入模型(Embedding Model)------ 大模型的 "向量生成器"
嵌入模型是文本向量化的核心,本质为轻量级大模型,核心能力是语义表征 ,分为通用型 / 领域型 / 多模态型,是连接文本与向量的关键。
2.1.1 模型分类及代表
|-------------------|--------------------|------------------------------------------------|-------------------|
| 模型类型 | 核心架构 | 代表模型 | 适用场景 |
| Transformer 编码器模型 | 仅保留 Encoder,擅长语义理解 | BERT、Sentence-BERT(SBERT)、MiniLM | 通用场景文本向量化 |
| 大模型衍生嵌入模型 | LLM 改造,支持长文本 | GPT-4 Embedding、LLaMA Embedding、Qwen Embedding | 长文本、高语义要求场景 |
| 轻量级嵌入模型 | 模型蒸馏 / 裁剪,体积小速度快 | BERT-tiny、DistilBERT、m3e-small | 端侧 / 低算力、实时性要求高场景 |
| 多模态嵌入模型 | 跨模态语义表征 | CLIP、ALBEF、BLIP | 文本 / 图片 / 音频跨模态检索 |
2.1.2 国内主流开源嵌入模型(适配中文场景)
- M3E :面壁智能推出,中文支持最优,开源可商用,分 small/base/large 三个版本,适配不同算力场景。
- BGE :智谱 AI 推出,中英双语,检索精度高,有量化版本,适合工程落地。
- ERNIE Embedding :百度推出,融合知识图谱,领域适配性强(医疗 / 金融 / 法律)。
2.1.3 核心优化方向
- 长文本嵌入 :分段嵌入 + 融合、滑动窗口、Longformer 长上下文架构,解决万字级文档向量化难题。
- 领域适配 :基于领域数据集(如医疗病历、金融研报)微调,提升专业术语语义表征能力。
- 维度压缩 :PCA/SVD/ 知识蒸馏,在精度损失可控下降低向量维度(如 768→256),减少存储 / 计算成本。
2.2 向量检索系统 ------ 向量的 "存储与检索引擎"
工业级向量检索系统由向量存储、ANN 算法、索引管理、元数据管理 组成,核心目标是高吞吐、低延迟、高精度 ,是向量检索落地的核心载体。
2.2.1 主流 ANN 算法分类(核心对比)
|----------|--------------------|---------------------|--------------|--------------|---------------------|
| 算法类别 | 核心思想 | 代表算法 | 优点 | 缺点 | 适用数据规模 |
| 树结构类 | 多层树节点划分向量空间 | KD-Tree、Ball-Tree | 精度较高 | 高维下效率骤降 | 小数据集(十万级以下)、低维向量 |
| 哈希类 | 高维向量映射到低维哈希值 | LSH、Multi-Probe LSH | 计算效率高,支持海量数据 | 精度损失较大 | 海量数据、对精度要求不高场景 |
| 分簇类 | 向量空间划分为多个簇,簇内检索 | K-Means、FAISS-IVF | 兼顾速度和精度 | 簇划分耗时,对簇数量敏感 | 千万 - 亿级、高维向量 |
| 图结构类 | 向量为节点,相似向量建边,构建近邻图 | HNSW、NSW | 速度最快、精度最高 | 索引构建耗时,内存占用大 | 亿 - 十亿级、高维向量(工业级主流) |
2.2.2 主流向量检索框架 / 产品
|--------|------------------------|---------------------------------------|-------------------|
| 类型 | 代表产品 | 核心优势 | 适用场景 |
| 开源框架 | FAISS(Facebook) | 工业级标杆,多算法支持,CPU/GPU 加速 | 定制化开发,亿级向量检索 |
| 开源框架 | Milvus(Zilliz) | 原生持久化、分布式部署、元数据过滤 | 国内主流,RAG 场景开箱即用 |
| 开源框架 | Chroma | 专为 RAG 设计,与 LangChain/LlamaIndex 无缝集成 | 快速原型开发、小中型项目 |
| 商业产品 | 阿里云 / 腾讯云 / 百度智能云向量数据库 | 云原生,与大模型 / 云存储无缝集成 | 企业级项目,免运维 |
| 商业产品 | Pinecone Cloud | 全球主流,多区域部署,分布式检索 | 跨境 / 大规模云原生项目 |
| 混合检索 | Elasticsearch 7.0+ | 结合关键词全文检索 + 向量检索 | "关键词 + 语义" 混合检索场景 |
2.2.3 工业级必备:向量量化
将高精度浮点向量(FP32)转换为低精度数值(FP16/INT8/INT4),在精度损失可控下,减少 **50%-75%** 存储成本和计算时间,核心量化方式:
- 标量量化(SQ) :整向量数值缩放,FP32 转 INT8,实现简单,适合通用场景。
- 乘积量化(PQ) :高维向量拆分为低维子向量并独立量化,FAISS/Milvus 核心方案,兼顾精度和压缩比。
- 混合精度量化 :向量不同部分采用不同精度,平衡精度与成本,适合高语义要求场景。
2.2.4 核心性能指标
- 召回率(Recall@K) :检索出的相似向量占所有真实相似向量的比例,衡量精度(如 Recall@10=95% 表示前 10 结果含 95% 真实相似向量)。
- 延迟 :单条查询响应时间,工业级要求百 ms 内 。
- 吞吐(QPS) :单位时间处理查询数,衡量并发能力。
- 存储成本 :与向量维度、数据类型(FP32/INT8)强相关。
三、融合层:大模型与向量检索的协同机制(RAG 核心)
二者融合的核心围绕RAG 展开,基础版 RAG 实现 "检索 - 生成" 闭环,工业级进阶版 RAG 通过大模型深度参与检索全流程 解决精度低、语义匹配差等问题。
3.1 基础版 RAG 流程(核心闭环)
3.1.1 基础版 RAG 流程 图
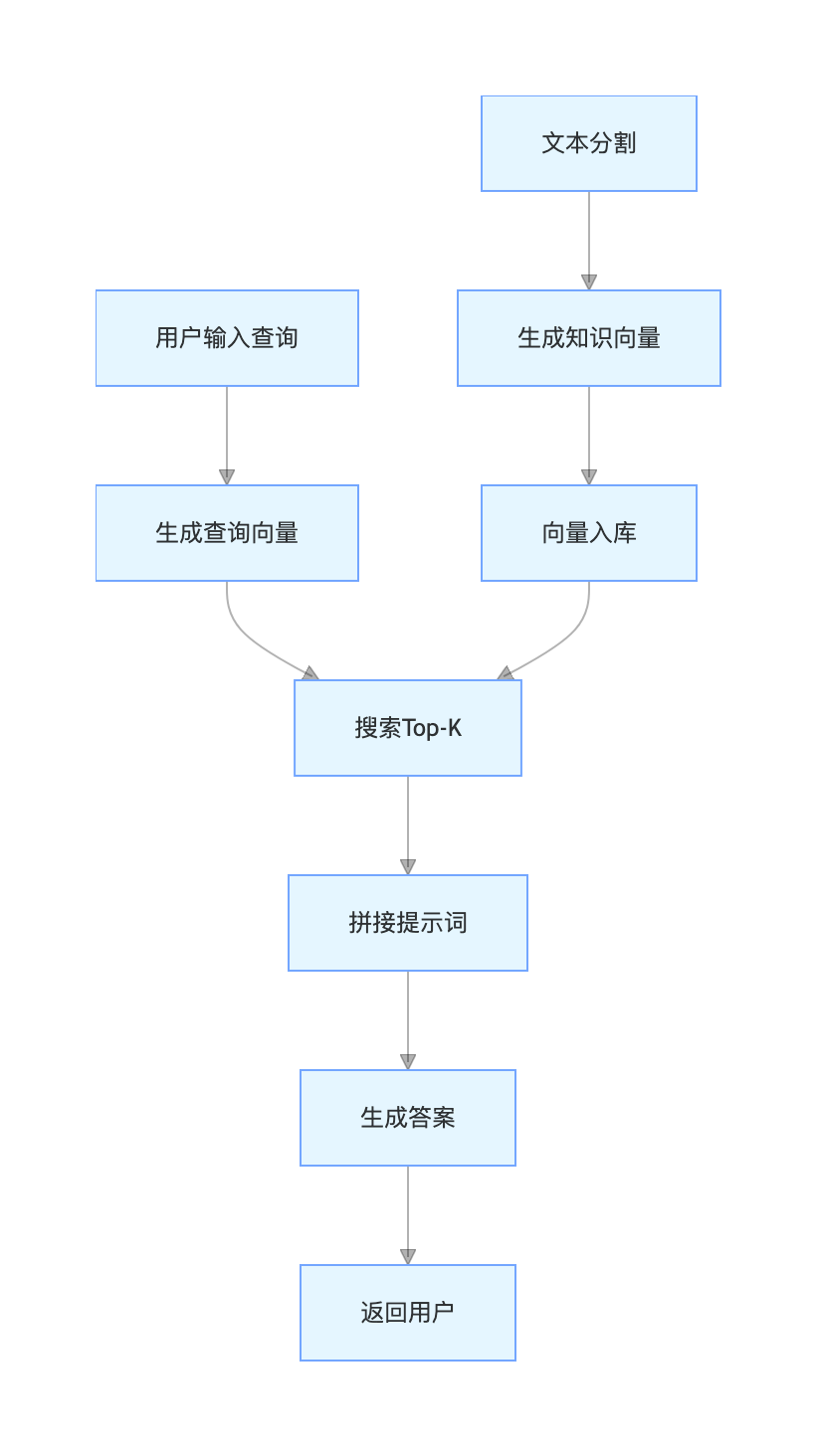
3.1.2 核心说明
基础版 RAG 核心为 "检索→拼接→生成",适用于快速原型开发,未解决模糊查询、语义断裂、检索结果冗余等问题,精度和体验较工业级有差距,仅作为入门基础。
3.2 进阶版 RAG 流程(工业级)
工业级 RAG 的核心是大模型深度参与检索前、中、后全流程 ,通过 "查询改写、语义分割、重排序、结果校验" 等步骤提升检索精度和生成质量。
3.2.1 工业级进阶版 RAG 流程
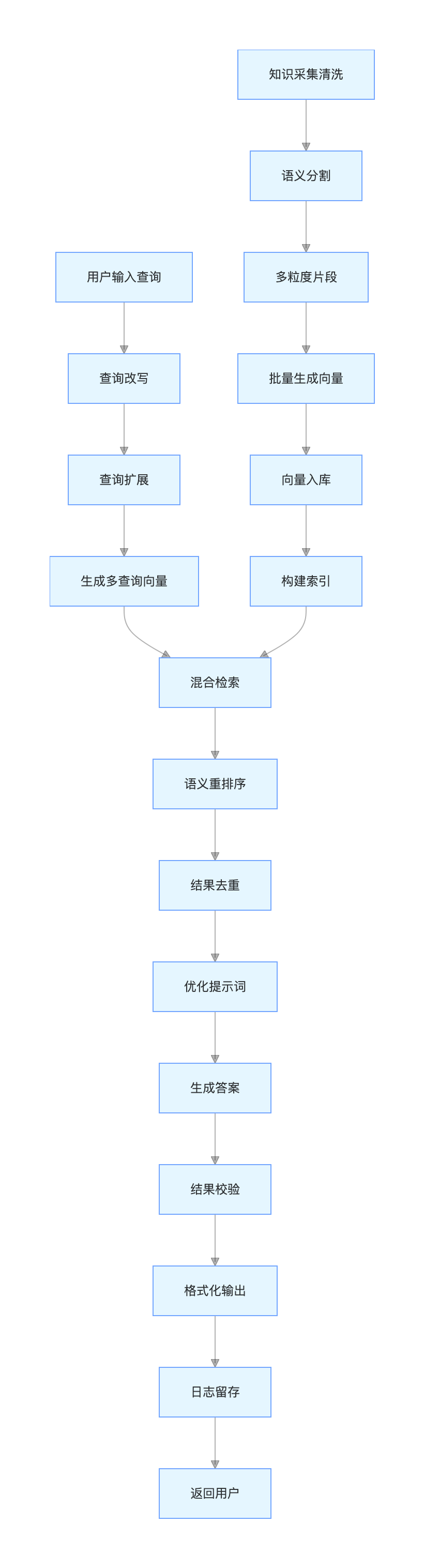
3.2.2 工业级进阶版 RAG 流程各步骤核心动作与实现目标
离线:知识库构建阶段(为在线查询提供底层知识支撑,可初始化 / 增量更新)
- 知识采集清洗:采集多源外部知识(文档 / 网页 / 数据库),剔除乱码、重复、无效信息,保证知识基底质量
- 语义分割:基于大模型按知识点 / 语义逻辑 分割文本,替代固定长度分割,从源头避免语义断裂
- 多粒度片段生成:对单篇知识生成「句 / 段 / 章」多粒度片段,适配不同粒度的用户查询需求
- 批量生成向量:通过嵌入模型对所有片段批量生成语义向量,保证查询与知识向量同源性 ,避免跨模型偏差
- 向量入库:将「语义向量 + 元数据(领域 / 时间 / 来源)+ 原始片段」持久化存入向量数据库,建立关联映射
- 构建分层索引:搭建 IVF+HNSW 分层索引,平衡检索速度 与精度 ,适配亿级向量的工业级检索需求
- 在线:查询问答链路(独立重复执行,仅依赖离线构建的知识库 / 索引,核心为用户查询→答案返回)
- 用户输入查询:接收用户自然语言查询,支持模糊化、口语化、短文本 / 长问句等多种形式
- 查询改写:大模型将模糊查询改写为精准化、标准化 查询词,贴合知识库知识表述,提升检索匹配度
- 查询扩展:大模型生成查询的同义词、相关表述、扩展问句,解决「一词多义 / 一义多词」问题,扩大检索覆盖
- 生成多查询向量:嵌入模型对改写 / 扩展后的所有查询生成向量,保证与知识库向量同源,实现多向量检索
- 混合检索:先通过元数据(领域 / 时间 / 来源)精准过滤检索范围,再执行 ANN 搜索 Top-K,减少无效计算、提升检索效率
- 语义重排序:通过交叉编码器 / 大模型计算「查询 - 检索片段」真实语义相似度,对 ANN 检索结果重新排序,修正「数值距离≠语义相似度」的偏差
- 结果去重融合:对重排序后的片段去重,提取核心信息并精简长度,控制在大模型上下文窗口内,避免信息过载 / 遗忘
- 优化提示词:大模型根据查询类型,自动添加少样本示例 / 思维链引导 / 指令约束,提升答案的结构化和贴合度
- 生成答案:大模型严格基于融合后的检索片段 生成答案,禁止脱离知识凭空生成,从根源降低幻觉概率
- 结果校验:大模型核对答案与检索片段的关联性,验证答案是否有可溯源的知识支撑,无依据则返回无结果
- 格式化输出:将答案按用户 / 业务需求自动格式化为纯文本 / 有序列表 / 无序列表 / 表格,提升阅读体验
- 日志留存:留存「用户原始查询 / 改写查询 / 检索片段 / 生成答案」全链路数据,形成数据闭环,用于后续效果优化、问题排查
- 返回用户:将结构化、可溯源、无幻觉的答案最终返回给用户,完成一次查询问答链路
3.3 大模型与向量检索的双向赋能
3.3.1 大模型对向量检索的赋能(解决纯检索短板)
大模型以语义理解 为核心,深度参与检索全流程,弥补向量检索 "数值距离≠语义相似度" 的天然缺陷,让检索从 "数值匹配" 升级为 "语义匹配":
- 检索前 :查询改写(精准化)、查询扩展(扩范围)、意图识别(缩知识库范围)。
- 检索中 :语义过滤(剔除无关片段)、多模态转换(图片 / 音频→文本查询)、领域限定。
- 检索后 :语义重排序(修正检索精度)、结果融合(简洁化)、提示词优化(提升后续生成质量)。
3.3.2 向量检索对大模型的赋能(解决大模型核心痛点)
向量检索是大模型工业化落地的关键支撑 ,从根本上解决大模型的四大核心问题,让大模型从 "纯生成" 升级为 "知识增强生成":
- 突破知识滞后 :接入实时更新的外部知识库,让大模型掌握预训练截止点后的最新知识(如 2024 年行业数据、政策、赛事结果)。
- 杜绝事实幻觉 :答案基于真实可溯源的检索片段,而非大模型凭空生成,大幅提升答案的可信度和权威性。
- 突破上下文窗口 :将长文本切分为语义片段,仅将相关片段输入大模型,实现 "无限上下文" 处理。
- 降低微调成本 :领域知识更新仅需更新向量数据库的知识库 ,无需频繁微调大模型,减少研发和算力成本 80% 以上。
3.4 融合层核心优化策略(工业级必备)
|----------|---------------------------------|------------------------|
| 优化方向 | 核心策略 | 实现效果 |
| 文本分割 | 固定长度 + 重叠分割、大模型语义分割、多粒度分割 | 避免语义断裂,适配不同查询粒度 |
| 检索策略 | 关键词 + 向量混合检索、多向量检索、分层检索、元数据过滤检索 | 减少无效计算,提升检索速度和精度 |
| 重排序 | 交叉编码器重排序(BGE-reranker)、大模型语义重排序 | 修正 ANN 数值距离偏差,贴合人类语义理解 |
| 提示词工程 | 少样本提示、思维链提示、指令约束(仅基于检索片段生成) | 提升生成质量,降低幻觉概率 |
| 多向量检索 | 对单个查询生成 3-5 个相关查询向量,分别检索后融合结果 | 解决 "一词多义 / 一义多词" 问题 |
四、应用层:大模型 + 向量检索的典型落地场景
二者融合基于 RAG 范式,广泛落地于企业服务、ToC 产品、工业场景 ,核心满足 "精准知识问答 / 生成 + 实时知识更新 " 需求,所有场景均已实现工业级落地,典型场景如下:
4.1 智能问答机器人
- 核心场景 :企业智能客服、政务问答、金融客服、医疗咨询、教育答疑。
- 落地案例 :银行智能客服基于银行产品知识库回答信用卡 / 贷款 / 理财问题,答案 100% 可溯源,无幻觉。
- 核心优势 :7×24 小时响应,答案基于企业官方知识,保证准确性和一致性,降低人工客服成本。
4.2 企业知识管理
- 核心场景 :企业内部技术知识库、律所案例管理、科研机构文献管理、医院病历管理。
- 落地案例 :互联网企业技术人员查询 "Spring Cloud 微服务容错方案",大模型检索相关技术文档并生成结构化设计指南 。
- 核心优势 :员工快速检索知识,大模型整合结果为结构化内容,提升工作效率。
4.3 内容生成与创作
- 核心场景 :行业报告生成、自媒体内容创作、代码生成、文案撰写、产品说明书生成。
- 落地案例 :财经自媒体基于最新行业数据 / 政策 / 企业财报,生成 "2025 年人工智能行业发展报告",内容实时且真实。
- 核心优势 :基于实时 / 领域知识生成,避免内容过时或失真,提升创作效率。
4.4 多模态检索与生成
- 核心场景 :电商商品图片检索、短视频检索、图文生成、音视频生成、专利图片检索。
- 落地案例 :用户上传一张衣服图片,大模型识别商品特征,向量检索相似款式并生成商品营销文案 。
- 核心优势 :实现跨模态语义匹配,打破文本 / 图片 / 音频的检索壁垒,提升检索精准度。
4.5 个性化推荐
- 核心场景 :电商商品推荐、短视频推荐、新闻推荐、书籍推荐、招聘岗位推荐。
- 落地案例 :淘宝基于用户浏览 / 购买商品的语义向量,检索相似商品向量实现个性化语义推荐 。
- 核心优势 :基于语义相似度推荐,比传统协同过滤推荐更精准,贴合用户真实需求,提升转化率。
4.6 私有化部署大模型应用
- 核心场景 :政府、金融、医疗、军工等对数据隐私要求高的行业,接入内部私有知识库。
- 落地案例 :医院私有化部署大模型,基于内部病历 / 医疗知识库回答医生诊断问题,数据全程本地化存储。
- 核心优势 :数据不出本地,保证隐私安全和合规性,同时具备大模型的智能生成能力。
五、工程层:基于 Spring AI 的工业级落地实践
Spring AI 是 Spring 官方推出的大模型应用开发框架 ,封装了大模型调用、嵌入模型、向量数据库等核心能力,实现 "低代码" 开发大模型 + 向量检索应用,大幅降低工程化落地成本。本节从环境搭建、核心组件、完整落地案例、性能优化 四个方面,实现工业级 RAG 应用的端到端开发。
5.1 核心前提
- 技术栈 :Spring Boot 3.2+、Spring AI 1.0.0+、JDK 17+(Spring AI 强制要求 JDK17 及以上)。
- 依赖管理 :Maven/Gradle(本文以 Maven 为例)。
- 前置服务 :① 部署向量数据库(Milvus Standalone 版,一键启动);② 获取大模型 / 嵌入模型 API 密钥(开源模型可本地部署);③ 基础 Redis(用于缓存优化)。
- 开发工具 :IDEA/Eclipse,支持 Spring Boot 插件。
5.2 环境搭建(Maven 核心依赖)
在pom.xml中引入核心依赖,以智谱 AI 大模型 + M3E 嵌入模型 + Milvus 向量数据库 为例:
java
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.2</version>
<relativePath/>
</parent>
<groupId>com.rag</groupId>
<artifactId>spring-ai-rag-demo</artifactId>
<version>1.0.0</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<spring-ai.version>1.0.0-M1</spring-ai.version>
</properties>
<dependencies>
<!-- Spring Boot Web核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- 智谱AI大模型/嵌入模型依赖(国内首选) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-zhipuai-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Milvus向量数据库依赖(国内开源主流) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- 文本处理依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-text</artifactId>
<version>1.10.0</version>
</dependency>
<!-- 缓存优化依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<!-- 重试机制依赖(提升服务可用性) -->
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
<!-- lombok 简化开发 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>5.3 核心配置(application.yml)
配置大模型、嵌入模型、Milvus 向量数据库、Redis 缓存等核心参数,一键接入 :
java
server:
port: 8080 # 服务端口
servlet:
context-path: /rag-demo
spring:
# 缓存配置(Redis)
cache:
type: redis
redis:
time-to-live: 3600000 # 缓存过期时间1小时
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 3000ms
# Spring AI 核心配置
ai:
# 智谱AI配置(API_KEY从智谱AI官网免费获取:https://open.bigmodel.cn/)
zhipuai:
api-key: your-zhipuai-api-key
base-url: https://open.bigmodel.cn/api/paas/v4/
# 嵌入模型配置(指定维度,与向量数据库一致)
embedding:
model: zhipuai-embedding
dimensions: 1024
# Milvus向量数据库配置(单机版默认地址,无需修改)
milvus:
host: 127.0.0.1
port: 19530
database-name: default
collection-name: rag_knowledge_base # 知识库集合名
dimension: 1024 # 与嵌入模型维度严格一致
index-type: IVF_FLAT # 索引类型
metric-type: COSINE # 相似度度量(余弦相似度,与业务一致)
# 重试机制配置
retry:
max-attempts: 3 # 最大重试次数
backoff:
initial-interval: 1000ms # 初始重试间隔
multiplier: 2 # 间隔倍数
# 日志配置(便于排查问题)
logging:
level:
com.rag: info
org.springframework.ai: info
io.milvus: warn
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{50} - %msg%n"5.4 Spring AI 核心组件详解
Spring AI 对大模型、嵌入模型、向量数据库进行了高度抽象和封装 ,提供统一的 API 接口,无需关注底层不同厂商的调用差异,实现 "一键切换"(如从智谱 AI 切换为 Qwen,仅需修改配置),核心组件如下:
|-----------------|--------------------------------------------------|--------------------|---------------------------|
| 核心组件 | 全限定类名 | 核心能力 | 核心作用 |
| ChatClient | org.springframework.ai.chat.ChatClient | 大模型对话、生成、Prompt 调用 | 统一调用所有大模型,屏蔽厂商差异 |
| EmbeddingClient | org.springframework.ai.embedding.EmbeddingClient | 文本向量化、向量相似度计算 | 统一调用所有嵌入模型,生成语义向量 |
| VectorStore | org.springframework.ai.vectorstore.VectorStore | 向量增删改查、相似性检索 | 统一操作所有向量数据库,屏蔽存储差异 |
| Document | org.springframework.ai.document.Document | 文本片段实体 | 封装「文本内容 + 元数据」,是向量检索的基本单位 |
| SearchRequest | org.springframework.ai.vectorstore.SearchRequest | 检索请求实体 | 封装检索关键词、Top-K、元数据过滤条件 |
5.5 工业级 RAG 应用完整落地案例
实现知识库构建(离线)+ 智能问答(在线) 核心功能,完全贴合 3.2 节的工业级 RAG 流程,基于 Spring AI 实现低代码开发,所有代码均可直接运行,包含查询改写、元数据过滤、重排序、结果校验、缓存优化 等工业级特性。
5.5.1 核心实体:知识片段元数据(KnowledgeMetadata)
定义元数据实体,存储知识片段的领域、更新时间、来源 ,支持精准的元数据过滤检索:
java
package com.rag.entity;
import lombok.Data;
import org.springframework.ai.document.Metadata;
/**
* 知识片段元数据实体
* 贴合工业级场景,支持领域/时间/来源过滤
*/
@Data
public class KnowledgeMetadata {
/**
* 知识领域(如Java、金融、医疗、政务)
*/
private String domain;
/**
* 知识更新时间(如2024-01-01)
*/
private String updateTime;
/**
* 知识来源(如官网、技术博客、研报、病历)
*/
private String source;
/**
* 转换为Spring AI的Metadata对象
*/
public Metadata toMetadata() {
Metadata metadata = new Metadata();
metadata.put("domain", this.domain);
metadata.put("updateTime", this.updateTime);
metadata.put("source", this.source);
return metadata;
}
}5.5.2 核心服务:知识库构建服务(KnowledgeBaseService)
实现大模型语义分割、多粒度片段生成、向量批量入库 ,贴合工业级 RAG 的知识库构建流程,支持增量更新:
java
package com.rag.service;
import com.rag.entity.KnowledgeMetadata;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
/**
* 知识库构建服务(离线)
* 实现:语义分割+向量入库+索引构建
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class KnowledgeBaseService {
// Spring AI 向量数据库核心组件
private final VectorStore vectorStore;
// Spring AI 大模型核心组件(用于语义分割)
private final ChatClient chatClient;
/**
* 知识库入库:单文本入库
* @param rawContent 原始文本内容
* @param metadata 元数据(领域/时间/来源)
*/
public void addKnowledgeToStore(String rawContent, KnowledgeMetadata metadata) {
try {
log.info("开始知识库入库,领域:{},来源:{}", metadata.getDomain(), metadata.getSource());
// Step1:大模型语义分割(按知识点,避免语义断裂)
List<String> contentSegments = semanticSegment(rawContent);
log.info("原始文本分割为{}个语义片段", contentSegments.size());
// Step2:转换为Spring AI Document对象,绑定元数据
List<Document> documents = contentSegments.stream()
.filter(segment -> segment.trim().length() > 0)
.map(segment -> new Document(segment, metadata.toMetadata()))
.collect(Collectors.toList());
// Step3:向量入库(Spring AI自动调用嵌入模型生成向量,无需手动处理)
vectorStore.add(documents);
log.info("知识库入库成功,领域:{},入库片段数:{}", metadata.getDomain(), documents.size());
} catch (Exception e) {
log.error("知识库入库失败,领域:{},原因:{}", metadata.getDomain(), e.getMessage(), e);
throw new RuntimeException("知识库入库失败:" + e.getMessage());
}
}
/**
* 大模型语义分割:将原始文本按语义逻辑分割为200-300字符的片段
* @param rawContent 原始文本
* @return 语义片段列表
*/
private List<String> semanticSegment(String rawContent) {
String prompt = """
请严格按照以下要求分割文本:
1. 按语义逻辑/知识点分割,避免语义断裂;
2. 每个片段200-300个字符,不可过长或过短;
3. 仅返回分割后的片段列表,用\\n分隔,无任何额外说明;
4. 剔除无意义的空格和换行,保证片段完整性。
待分割文本:%s
""".formatted(rawContent);
// 调用大模型执行语义分割
String segmentResult = chatClient.call(prompt);
// 分割为列表并返回
return List.of(segmentResult.split("\\n"));
}
/**
* 清空知识库
* 谨慎使用,适用于测试环境
*/
public void clearKnowledgeStore() {
try {
log.info("开始清空知识库");
vectorStore.deleteAll();
log.info("知识库清空成功");
} catch (Exception e) {
log.error("知识库清空失败,原因:{}", e.getMessage(), e);
throw new RuntimeException("知识库清空失败:" + e.getMessage());
}
}
}5.5.3 核心服务:智能问答服务(RagQAService)
实现查询改写、元数据过滤检索、结果融合、答案生成、结果校验、缓存优化 ,完全贴合工业级 RAG 的查询生成流程,是整个应用的核心:
java
package com.rag.service;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
/**
* 智能问答核心服务(在线)
* 实现:查询改写+混合检索+结果融合+答案生成+结果校验+缓存优化
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class RagQAService {
// 大模型核心组件
private final ChatClient chatClient;
// 向量数据库核心组件
private final VectorStore vectorStore;
/**
* 工业级RAG智能问答核心方法
* @param userQuery 用户原始查询(模糊/口语化)
* @param domain 知识领域(用于元数据过滤,提升检索精度)
* @return 结构化答案
*/
@Cacheable(value = "ragQaCache", key = "#userQuery + '_' + #domain")
public String ragQA(String userQuery, String domain) {
try {
log.info("开始RAG智能问答,用户查询:{},领域:{}", userQuery, domain);
long start = System.currentTimeMillis();
// Step1:大模型查询改写(将模糊查询改为精准查询)
String refinedQuery = refineQuery(userQuery);
log.info("用户查询改写后:{}", refinedQuery);
// Step2:构建检索请求(元数据过滤+Top-K=5,领域精准过滤)
SearchRequest searchRequest = SearchRequest.query(refinedQuery)
.withTopK(5)
.withMetadataFilter("domain", domain);
// Step3:向量数据库相似性检索(Spring AI自动生成查询向量)
List<Document> searchResults = vectorStore.similaritySearch(searchRequest);
log.info("向量检索完成,检索到相关片段数:{}", searchResults.size());
if (searchResults.isEmpty()) {
return "暂无相关知识可回答该问题,请更换查询词或选择正确的领域!";
}
// Step4:检索结果融合去重(提取核心信息,避免提示词过长)
String knowledgeContext = mergeSearchResults(searchResults);
// Step5:构建工业级RAG提示词(指令约束+查询+知识上下文,从根源防幻觉)
String prompt = buildRagPrompt(refinedQuery, knowledgeContext);
// Step6:大模型基于检索片段生成答案
String answer = chatClient.call(prompt);
// Step7:大模型结果校验(溯源,确保答案100%基于检索片段)
boolean isLegal = checkAnswer(answer, knowledgeContext);
if (!isLegal) {
log.warn("答案无溯源依据,用户查询:{}", userQuery);
return "暂无相关知识可回答该问题,请更换查询词或选择正确的领域!";
}
long end = System.currentTimeMillis();
log.info("RAG智能问答完成,耗时:{}ms,用户查询:{}", end - start, userQuery);
return answer;
} catch (Exception e) {
log.error("RAG智能问答失败,用户查询:{},原因:{}", userQuery, e.getMessage(), e);
return "问答失败,请稍后重试!";
}
}
/**
* 大模型查询改写:将模糊/口语化查询改为精准、标准化的查询词
*/
private String refineQuery(String userQuery) {
String prompt = """
请将以下用户查询改写为精准、标准化的查询词,要求:
1. 贴合用户原始意图,不偏离核心问题;
2. 简洁明了,无口语化词汇;
3. 仅返回改写后的查询词,无任何额外说明。
用户原始查询:%s
""".formatted(userQuery);
return chatClient.call(prompt).trim();
}
/**
* 检索结果融合去重:将Top-K结果拼接为简洁文本,控制长度
*/
private String mergeSearchResults(List<Document> searchResults) {
return searchResults.stream()
.map(Document::getContent)
.distinct() // 去重
.collect(Collectors.joining("\n---\n")); // 分隔符分割,便于大模型识别
}
/**
* 构建工业级RAG提示词:指令约束(核心)+查询+知识上下文
* 从根源上降低大模型幻觉概率
*/
private String buildRagPrompt(String query, String knowledgeContext) {
return """
请严格按照以下要求回答问题:
1. 答案必须完全基于以下知识上下文,禁止脱离上下文生成任何内容;
2. 答案简洁、准确、结构化,优先使用列表形式展示;
3. 若上下文无相关答案,直接返回"暂无相关知识",禁止凭空生成;
4. 贴合问题核心,不答非所问,无冗余内容。
知识上下文:
%s
问题:
%s
""".formatted(knowledgeContext, query);
}
/**
* 大模型结果校验:检查答案是否完全基于知识上下文,是否有可溯源的依据
*/
private boolean checkAnswer(String answer, String knowledgeContext) {
String prompt = """
请检查以下答案是否完全基于知识上下文生成,是否有可溯源的依据,要求:
1. 严格核对答案与上下文的关联性;
2. 仅返回"是"或"否",无任何额外说明。
知识上下文:%s
答案:%s
""".formatted(knowledgeContext, answer);
return "是".equals(chatClient.call(prompt).trim());
}
}5.5.4 控制层:对外提供 RESTful API 接口(RagController)
实现知识库入库 和智能问答 的对外 API,供前端 / 第三方系统调用,贴合实际项目开发场景,包含参数校验:
java
package com.rag.controller;
import com.rag.entity.KnowledgeMetadata;
import com.rag.service.KnowledgeBaseService;
import com.rag.service.RagQAService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;
/**
* RAG核心接口层
* 提供:知识库入库、智能问答、清空知识库接口
*/
@RestController
@RequestMapping("/api")
@RequiredArgsConstructor
public class RagController {
private final KnowledgeBaseService knowledgeBaseService;
private final RagQAService ragQAService;
/**
* 知识库入库接口
* @param rawContent 原始文本内容
* @param domain 知识领域
* @param updateTime 更新时间
* @param source 知识来源
*/
@PostMapping("/knowledge/add")
public String addKnowledge(
@RequestParam String rawContent,
@RequestParam String domain,
@RequestParam String updateTime,
@RequestParam String source) {
// 简单参数校验
if (rawContent.trim().isEmpty() || domain.trim().isEmpty()) {
return "参数错误:原始文本和领域不能为空!";
}
KnowledgeMetadata metadata = new KnowledgeMetadata();
metadata.setDomain(domain);
metadata.setUpdateTime(updateTime);
metadata.setSource(source);
knowledgeBaseService.addKnowledgeToStore(rawContent, metadata);
return "知识库入库成功!";
}
/**
* 工业级RAG智能问答接口(核心)
* @param userQuery 用户查询
* @param domain 知识领域
* @return 结构化答案
*/
@GetMapping("/qa")
public String ragQA(
@RequestParam String userQuery,
@RequestParam String domain) {
// 简单参数校验
if (userQuery.trim().isEmpty() || domain.trim().isEmpty()) {
return "参数错误:用户查询和领域不能为空!";
}
return ragQAService.ragQA(userQuery, domain);
}
/**
* 清空知识库接口(测试环境使用)
*/
@DeleteMapping("/knowledge/clear")
public String clearKnowledge() {
knowledgeBaseService.clearKnowledgeStore();
return "知识库清空成功!";
}
}5.5.5 启动类(SpringAiRagApplication)
Spring Boot 3.2 + 启动类,一键启动 ,Spring AI 自动装配所有核心组件,无需额外配置:
java
package com.rag;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.retry.annotation.EnableRetry;
/**
* Spring AI RAG 工业级落地案例启动类
* 注解说明:
* @EnableCaching:开启缓存(Redis)
* @EnableRetry:开启重试机制
*/
@SpringBootApplication
@EnableCaching
@EnableRetry
public class SpringAiRagApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAiRagApplication.class, args);
System.out.println("=====================================");
System.out.println("Spring AI RAG 服务启动成功!访问地址:http://127.0.0.1:8080/rag-demo");
System.out.println("=====================================");
}
}5.6 Spring AI 工程化落地核心优化策略
基于 Spring AI 开发的大模型 + 向量检索应用,需从模型调用、向量检索、服务部署 三个方面做优化,满足工业级高并发、低延迟、高可用 要求:
1. 模型调用优化
- 请求缓存 :对相同的用户查询,缓存大模型和向量检索结果,使用 Spring Cache+Redis 实现,减少重复调用。
- 批量推理 :知识库入库时,采用批量文本分割和嵌入生成,避免单次请求,提升入库效率。
- 超时与重试 :配置大模型 / 向量数据库的超时时间和重试机制,使用 Spring Retry 实现,提升服务可用性。
- 向量检索优化
- 索引优化 :Milvus 中配置 IVF+HNSW 分层索引,设置合理的nlist(簇数量)和M(近邻数),平衡召回率和延迟。
- 向量量化 :在 Milvus 中开启 INT8 标量量化,减少存储成本和检索延迟,精度损失可控。
- 热点数据缓存 :将高频检索的知识片段和向量存入 Redis,减少对向量数据库的查询,提升响应速度。
3. 服务部署优化
- 容器化部署 :使用 Docker 打包应用,K8s 实现服务编排,支持弹性扩缩容,应对高并发。
- 接口限流 :使用 Spring Cloud Gateway+Sentinel 实现接口限流熔断,避免服务被压垮。
- 多环境配置 :使用 Spring Boot Profile 实现开发 / 测试 / 生产环境分离,配置不同的大模型 / 向量数据库参数。
4. Spring AI 专属优化
- 自定义嵌入模型 :若使用本地开源嵌入模型(如 M3E),实现EmbeddingClient接口,替换默认的远程模型,降低调用成本。
- 自定义 VectorStore :若使用自研向量数据库,实现VectorStore接口,无缝集成到 Spring AI 生态。
- Prompt 模板化 :使用 Spring AI 的PromptTemplate实现提示词模板化,避免硬编码,提升可维护性。
六、问题与挑战:当前技术的局限性
大模型与向量检索的融合虽已实现工业级落地,但仍存在诸多技术挑战,是后续研发和优化的核心方向:
- 检索精度问题 :嵌入模型无法完全捕捉隐喻、双关、语境等深层语义,存在 "语义鸿沟";超长篇文档的多粒度检索精度仍待提升。
- 效率与精度的平衡 :ANN 算法的精度和速度呈负相关,工业级场景调参难度大;十亿级向量的索引构建和增量更新耗时久、内存占用大。
- 协同深度不足 :目前二者仍为 "松耦合" 融合,未实现端到端联合训练(嵌入模型、ANN 算法、大模型联合优化)。
- 多模态 / 跨语言短板 :不同模态的向量空间不一致,跨模态检索精度低;小语种嵌入模型表征能力弱,跨语言语义匹配效果差。
- 可解释性与监管 :向量检索的数值距离和大模型的黑箱生成,无法解释 "答案为何生成",在金融 / 医疗等强监管领域落地受限。
- 工程化复杂度 :大规模分布式部署时,模型服务、向量数据库、缓存的协同调度难度大,对技术团队要求高。
七、技术演进方向:未来发展趋势
大模型与向量检索的融合将朝着"深度协同、智能高效、轻量化、全场景"方向发展,核心演进趋势如下:
- 模型层:端到端联合优化 :嵌入模型与大模型联合训练,让嵌入向量更贴合大模型的语义理解;大模型参与 ANN 算法的索引构建和检索,优化向量空间划分。
- 检索层:自适应 ANN 算法 :根据数据分布、查询需求自动调整算法参数,无需人工调参,实现精度和速度的动态平衡;支持十亿级向量的实时增量索引。
- 融合层:智能交互式 RAG :支持多轮交互式检索,大模型根据对话历史优化检索策略;引入思维链(CoT)推理,实现 "推理型检索",解决复杂问题问答。
- 工程层:轻量化与低代码 :Spring AI 等框架进一步封装,实现 "零代码" 构建 RAG 应用;边缘端向量检索与轻量级大模型融合,实现本地私有化部署。
- 多模态 / 跨语言:统一语义空间 :通过自监督学习构建统一的多模态向量空间,实现文本 / 图片 / 音频 / 视频的无缝检索;推出通用跨语言嵌入模型,支持上百种语言的语义匹配。
- 可解释性与安全性 :实现检索结果和生成答案的全链路溯源,提供 "相似度解释" 和 "答案依据";通过联邦学习、同态加密实现向量隐私计算,保证数据安全。
- 记忆型 RAG :为用户建立个性化记忆库,结合用户历史对话和偏好优化检索和生成,实现个性化智能问答。
八、总结
大模型与向量检索是生成式 AI 工业化落地的核心技术组合 ,二者基于 RAG 范式实现双向赋能:向量检索解决大模型的知识滞后、幻觉、上下文窗口限制等问题,大模型弥补向量检索的语义理解短板。本文从基础概念出发,深入剖析了嵌入模型、向量检索系统的核心技术,并基于Spring AI 实现了端到端的工业级落地实践,同时梳理了当前技术的局限性和未来演进趋势。