一、引言
在当今数据驱动的时代,Kafka已成为众多企业实时数据管道和流处理架构的中流砥柱。作为一个分布式流处理平台,Kafka不仅支撑着企业内部的消息传递,还成为了连接各个系统的神经中枢。然而,随着业务规模的扩大和依赖度的提高,Kafka的稳定性直接关系到整个企业的业务连续性。
就像一辆高速行驶的汽车需要仪表盘一样,Kafka集群也需要一套完善的监控体系。没有监控,我们就无法了解集群的健康状况,更无法在问题发生前进行预防性维护。传统的"发现问题-分析-解决"的被动响应模式已经不能满足现代企业对系统可靠性的要求,我们需要构建一个能够提前预警、主动发现问题的监控体系。
本文面向Kafka运维工程师、SRE团队和对Kafka有一定了解的开发人员,旨在分享如何构建一套完整的Kafka监控体系。通过阅读本文,你将了解:
- Kafka关键监控指标及其含义
- 多种指标收集方案及其优缺点对比
- 指标存储与可视化的实现方法
- 基于监控数据的问题诊断与优化策略
- 真实项目中的监控体系构建经验与踩坑总结
让我们一起深入探讨如何让Kafka集群在你的"掌控"之中。
二、Kafka关键监控指标梳理
监控Kafka就像医生检查病人的各项生命体征,需要关注不同层面的指标才能全面了解系统健康状况。以下我们将从集群、Broker、Topic和Consumer Group四个层面梳理关键指标。
集群层面指标
集群层面的指标反映了Kafka整体的健康状态,就像人体的体温和血压一样,是最基础的健康指标。
-
控制器状态与选举情况
ActiveControllerCount:应该始终为1,如果为0或大于1表示集群存在异常LeaderElectionRate:控制器选举频率,频繁选举通常意味着网络不稳定或节点异常
-
分区状态与分布
OfflinePartitionsCount:离线分区数,健康集群应为0UnderReplicatedPartitions:副本同步不足的分区数,应为0- 分区在broker间的分布均衡度(自定义指标)
-
副本同步情况
ISRShrink/ISRExpand:ISR集合收缩/扩大的速率,频繁变化表示副本同步不稳定ReplicaMaxLag:副本最大延迟,反映了副本同步的健康状况
Broker层面指标
Broker作为Kafka的服务节点,其资源使用情况直接影响集群性能和稳定性。
-
资源使用率
- CPU使用率:过高可能导致请求处理延迟增加
- 内存使用率:特别关注堆内存使用情况和GC频率
- 磁盘IO:读写吞吐量和IOPS,是常见的性能瓶颈
- 磁盘使用率:预警磁盘空间不足
-
网络吞吐量
BytesInPerSec/BytesOutPerSec:进出流量,反映集群负载- 网络连接数:包括生产者、消费者和内部复制连接
-
请求处理指标
RequestQueueSize:请求队列深度,队列积压表示处理能力不足RequestHandlerAvgIdlePercent:请求处理线程空闲百分比- 各类请求的延迟:Produce/Fetch/Metadata等请求的处理时间
重点提示:broker的资源使用率应保持在安全阈值内,一般建议CPU使用率不超过70%,磁盘使用率不超过80%,以保留足够的冗余应对流量高峰。
Topic层面指标
Topic是Kafka的核心概念,也是业务关注的焦点,其性能直接影响到上下游系统。
-
消息吞吐量
MessagesInPerSec:每秒进入topic的消息数BytesInPerSec/BytesOutPerSec:每秒进出topic的字节数
-
消息堆积情况
- 最大偏移量与最小偏移量的差值,反映消息总量
- 各分区堆积量分布,用于判断是否存在数据倾斜
-
延迟指标
- 生产者端到端延迟:消息从发送到收到确认的时间
- 端到端延迟:从生产到消费的全链路延迟(需自定义埋点)
Consumer Group层面指标
消费者组指标反映了数据消费的健康状况,是发现系统瓶颈的重要窗口。
-
消费进度与Lag情况
ConsumerLag:消费者落后于生产者的消息数量LagTrendRate:Lag变化趋势,上升趋势更值得关注
-
消费者重平衡情况
- 重平衡频率:频繁重平衡会导致消费暂停
- 重平衡持续时间:过长会影响消费效率
-
各分区消费速率
- 分区间消费速率对比,用于发现消费不均衡
- 单个消费者的处理能力,用于容量规划
以下是一个简单的监控指标分层表格,可以帮助您快速理解各层次关键指标:
| 监控层面 | 核心指标 | 预警阈值(示例) | 影响范围 |
|---|---|---|---|
| 集群 | ActiveControllerCount | !=1 | 全局 |
| OfflinePartitionsCount | >0 | 全局 | |
| Broker | CPU使用率 | >70% | 单机/可能全局 |
| 磁盘使用率 | >80% | 单机/可能全局 | |
| Topic | 消息吞吐量异常变化 | 突增/骤降50% | 业务相关 |
| 生产延迟 | >500ms | 上游系统 | |
| Consumer | ConsumerLag | >10000或连续3次上升 | 下游系统 |
| 重平衡频率 | >3次/小时 | 消费者组 |
从集群到消费者组,这些指标构成了一个完整的监控链条,让我们能够全方位了解Kafka的运行状态。接下来,我们将探讨如何高效地收集这些指标。
三、指标收集方案
有了明确的监控指标目标,下一步就是确定如何高效收集这些指标。就像修车师傅需要各种测量工具一样,我们也需要选择适合的工具来收集Kafka的运行数据。
JMX指标采集
Kafka暴露了丰富的JMX指标,这些指标是监控体系的基础。
常用JMX指标解析
Kafka的JMX指标命名遵循一定规则,通常格式为kafka.{component}:type={type},name={metric-name}。以下是一些核心指标的含义:
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec:每秒接收的消息数kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions:副本数不足的分区数kafka.controller:type=KafkaController,name=ActiveControllerCount:活跃控制器数量
JMX采集工具比较
市面上有多种工具可以采集JMX指标,主要有两种方案:
Prometheus JMX Exporter:
- 优点:轻量级,直接与Java应用集成,指标格式符合Prometheus规范
- 缺点:需要修改Kafka启动脚本,每次配置变更可能需要重启服务
- 适用场景:已经使用Prometheus生态的团队
Jolokia:
- 优点:提供RESTful API访问JMX数据,便于集成多种监控系统
- 缺点:多一层HTTP请求,性能略低于JMX Exporter
- 适用场景:需要灵活对接多种监控系统的场景
踩坑提醒 :在大规模集群中,JMX数据采集可能会对Broker性能产生影响。建议适当调整采集频率(如60秒),并关注JMX连接数限制。我们曾在一个200+节点的集群中因JMX连接数耗尽导致监控数据丢失,最终通过增大
-Dcom.sun.management.jmxremote.rmi.port参数解决。
示例代码:配置JMX Exporter
以下是在Kafka broker上配置Prometheus JMX Exporter的步骤:
-
首先,下载JMX Exporter JAR文件
-
创建配置文件
kafka-jmx-exporter.yml:
yaml
# 示例配置,可根据需要调整
lowercaseOutputName: true
lowercaseOutputLabelNames: true
whitelistObjectNames:
- kafka.server:*
- kafka.controller:*
- kafka.network:*
- java.lang:type=GarbageCollector,*
- java.lang:type=Memory,*
- java.lang:type=OperatingSystem,*
rules:
# 转换规则示例
- pattern: "kafka.server<type=(.+), name=(.+)><>Value"
name: kafka_server_$1_$2
- pattern: "kafka.controller<type=(.+), name=(.+)><>Value"
name: kafka_controller_$1_$2- 修改Kafka启动脚本,增加JMX Exporter参数:
bash
# 在kafka-server-start.sh中添加以下内容
export KAFKA_OPTS="$KAFKA_OPTS -javaagent:/path/to/jmx_prometheus_javaagent-0.16.1.jar=9999:/path/to/kafka-jmx-exporter.yml"- 重启Kafka服务后,可通过
http://kafka-broker:9999/metrics访问指标数据
Kafka自带指标工具
除了JMX指标,Kafka自带的性能测试工具也可以提供有价值的监控数据。
kafka-producer-perf-test与kafka-consumer-perf-test
这两个工具可以模拟生产和消费场景,测量真实的吞吐量和延迟情况。
生产者性能测试:
bash
# 测试向指定topic发送1000000条消息的性能
bin/kafka-producer-perf-test.sh \
--topic test-topic \
--num-records 1000000 \
--record-size 1000 \
--throughput 100000 \
--producer-props bootstrap.servers=kafka1:9092,kafka2:9092 acks=1输出结果包含:
- 每秒发送的记录数
- 每秒发送的MB数
- 平均延迟
- 最大延迟
- 各百分位的延迟统计
消费者性能测试:
bash
bin/kafka-consumer-perf-test.sh \
--bootstrap-server kafka1:9092,kafka2:9092 \
--topic test-topic \
--messages 1000000 \
--threads 1这些工具可以编写为定时任务,定期运行并收集结果,为监控系统提供真实的端到端性能数据。
实践建议:我们在生产环境中每小时运行一次性能测试,使用专门的测试topic,结果存入时序数据库。这样可以长期跟踪集群性能变化趋势,及早发现性能退化问题。
埋点监控
除了系统级监控,业务层面的埋点监控也非常重要,它能提供更贴近业务场景的数据。
客户端埋点方案设计
埋点监控的核心思想是在关键代码路径上插入监控代码,收集并上报指标。在Kafka客户端,我们通常关注以下埋点点位:
- 生产者发送前
- 生产者收到确认后
- 消费者接收到消息时
- 消费者处理完消息后
生产者/消费者端指标埋点示例代码
生产者埋点示例:
java
// 使用拦截器进行埋点
public class MonitoringProducerInterceptor implements ProducerInterceptor<String, String> {
private final Counter messageCounter = MetricRegistry.counter("kafka.producer.message.count");
private final Timer sendTimer = MetricRegistry.timer("kafka.producer.send.time");
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 记录消息数量
messageCounter.inc();
// 记录消息大小
MetricRegistry.histogram("kafka.producer.message.size").update(record.value().length());
// 添加时间戳,用于计算端到端延迟
record.headers().add("send_timestamp", String.valueOf(System.currentTimeMillis()).getBytes());
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 记录确认时间
sendTimer.update(System.currentTimeMillis() - Long.parseLong(new String(record.headers().lastHeader("send_timestamp").value())), TimeUnit.MILLISECONDS);
// 记录成功/失败计数
if (exception != null) {
MetricRegistry.counter("kafka.producer.error.count").inc();
} else {
MetricRegistry.counter("kafka.producer.success.count").inc();
}
}
// 其他方法省略...
}
// 配置生产者使用拦截器
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
props.put("interceptor.classes", "com.example.MonitoringProducerInterceptor");
// 其他配置...
KafkaProducer<String, String> producer = new KafkaProducer<>(props);消费者埋点示例:
java
// 使用拦截器进行埋点
public class MonitoringConsumerInterceptor implements ConsumerInterceptor<String, String> {
private final Timer processingTimer = MetricRegistry.timer("kafka.consumer.processing.time");
private final Timer e2eLatencyTimer = MetricRegistry.timer("kafka.consumer.e2e.latency");
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// 记录批次大小
MetricRegistry.histogram("kafka.consumer.batch.size").update(records.count());
// 计算端到端延迟
for (ConsumerRecord<String, String> record : records) {
Header header = record.headers().lastHeader("send_timestamp");
if (header != null) {
long sendTime = Long.parseLong(new String(header.value()));
e2eLatencyTimer.update(System.currentTimeMillis() - sendTime, TimeUnit.MILLISECONDS);
}
}
return records;
}
// 记录消费者组重平衡事件
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
MetricRegistry.counter("kafka.consumer.commit.count").inc();
}
// 其他方法省略...
}
// 配置消费者使用拦截器
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
props.put("interceptor.classes", "com.example.MonitoringConsumerInterceptor");
// 其他配置...
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);埋点数据流转与存储
埋点数据的收集只是第一步,还需要有效的流转和存储机制:
-
数据上报方式:
- 直接推送到监控系统API
- 写入本地文件,由agent采集
- 发送到专门的监控topic,由监控系统消费
-
数据聚合:
- 客户端本地聚合,减少数据量
- 服务端分层聚合,如1分钟、5分钟、1小时聚合
-
存储选择:
- 时序数据库:InfluxDB、Prometheus、TimescaleDB等
- 普通数据库加时间索引
- 日志系统:ELK、Loki等
完善的指标收集是监控体系的基础,下一步我们将探讨如何存储和可视化这些指标,让数据"说话"。
四、指标存储与可视化方案
收集了指标数据后,接下来的挑战是如何高效地存储这些数据并将其转化为直观的可视化界面。这就像是把医院的各种检查数据转化为医生可以理解的诊断报告一样重要。
Prometheus + Grafana方案
Prometheus和Grafana的组合是当前最流行的开源监控解决方案之一,特别适合Kafka这类分布式系统的监控。
架构设计与部署实践
一个典型的基于Prometheus + Grafana的Kafka监控架构包含以下组件:
- JMX Exporter:部署在每个Kafka broker上,暴露JMX指标
- Prometheus:定期抓取各Exporter的指标,并存储时序数据
- Alertmanager:处理告警规则触发的告警信息
- Grafana:提供可视化界面和仪表板
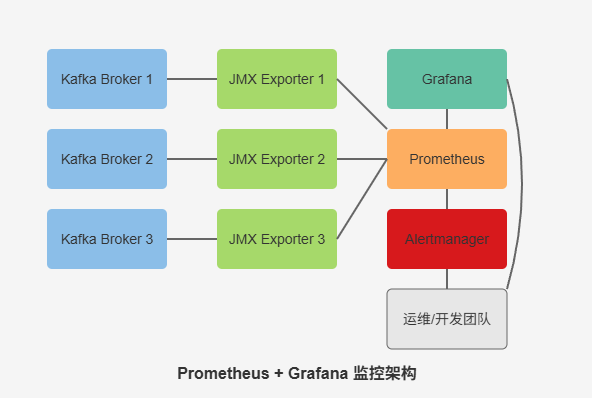
部署实践中的关键步骤:
- 高可用部署:Prometheus应部署多实例,避免单点故障
- 数据保留策略:根据存储容量设置合理的数据保留周期,如15天原始精度,90天降采样数据
- 水平扩展:大规模集群可采用Thanos或VictoriaMetrics实现Prometheus的存储扩展
踩坑提醒:在一个拥有500+Topic的Kafka集群中,我们发现Prometheus抓取JMX数据时会产生大量时间序列,导致内存使用激增。通过在JMX Exporter配置中精细化设置抓取规则,并增加Prometheus的内存配置,最终解决了这个问题。
自定义抓取Kafka指标配置
以下是一个针对Kafka优化的Prometheus抓取配置示例:
yaml
# prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kafka'
static_configs:
- targets:
- 'kafka1:9999' # JMX Exporter端口
- 'kafka2:9999'
- 'kafka3:9999'
relabel_configs:
# 添加broker_id标签
- source_labels: [__address__]
regex: '([^:]+):.+'
target_label: instance
- source_labels: [__address__]
regex: '([^:]+):.+'
target_label: broker_id
replacement: '${1}'
metric_relabel_configs:
# 过滤不需要的指标,减少存储压力
- source_labels: [__name__]
regex: 'kafka_server_brokertopicmetrics_bytesin_total'
action: keep
# 可添加更多过滤规则告警规则配置最佳实践
有效的告警规则能够帮助我们在问题扩大前发现并解决它们:
yaml
# kafka_alerts.yml
groups:
- name: kafka_alerts
rules:
# 副本同步异常告警
- alert: KafkaUnderReplicatedPartitions
expr: kafka_server_replicamanager_underreplicatedpartitions > 0
for: 5m
labels:
severity: critical
annotations:
summary: "Kafka under-replicated partitions (instance {{ $labels.instance }})"
description: "有分区副本同步异常,可能影响数据可靠性\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
# 消费延迟告警(需自定义指标)
- alert: KafkaConsumerLagHigh
expr: kafka_consumer_group_lag > 10000 and rate(kafka_consumer_group_lag[5m]) > 0
for: 10m
labels:
severity: warning
annotations:
summary: "Kafka consumer lag high (instance {{ $labels.instance }})"
description: "消费者组{{ $labels.group }}在主题{{ $labels.topic }}上的消费延迟持续增加,当前延迟: {{ $value }}"ELK方案
ELK (Elasticsearch, Logstash, Kibana) 生态也是监控Kafka的流行选择,特别适合已经使用ELK进行日志管理的团队。
使用Metricbeat采集Kafka指标
Metricbeat是Elastic Stack的轻量级指标采集器,内置了Kafka模块:
yaml
# metricbeat.yml
metricbeat.modules:
- module: kafka
metricsets:
- partition
- consumergroup
period: 10s
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
username: "monitoring_user" # 如果启用了SASL验证
password: "monitoring_pwd"
- module: jolokia
metricsets: ["jmx"]
period: 10s
hosts: ["kafka1:8778", "kafka2:8778", "kafka3:8778"] # Jolokia端口
namespace: "kafka"
jmx.mappings:
- mbean: 'kafka.server:type=BrokerTopicMetrics,name=*'
attributes:
- attr: Count
field: broker_topic_metrics.${name}
# 更多JMX映射配置...
output.elasticsearch:
hosts: ["es1:9200", "es2:9200", "es3:9200"]
index: "metricbeat-%{+yyyy.MM.dd}"Elasticsearch索引设计与优化
对于Kafka监控数据,合理的Elasticsearch索引设计至关重要:
- 索引模板优化:
json
{
"index_patterns": ["metricbeat-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.refresh_interval": "10s",
"index.routing.allocation.total_shards_per_node": 2
},
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"kafka": {
"properties": {
"broker_id": { "type": "keyword" },
"topic": { "type": "keyword" },
"partition": { "type": "integer" }
}
}
}
}
}-
ILM策略:使用Elasticsearch的Index Lifecycle Management管理索引生命周期,如7天热数据,30天温数据,90天后删除。
-
写入优化:调整bulk写入大小、线程数和队列大小,平衡写入吞吐量和延迟。
Kibana仪表板构建
基于Elasticsearch数据构建Kibana仪表板是ELK方案的亮点:
-
多层次仪表板:
- 集群总览:健康状态、总吞吐量、关键指标
- Broker详情:各节点资源使用情况、请求处理能力
- Topic监控:按Topic展示生产/消费情况、延迟统计
- Consumer组监控:消费进度、Lag趋势
-
可视化类型选择:
- 指标值:使用Gauge展示当前值和阈值
- 时间趋势:使用Line Chart展示变化趋势
- 分布情况:使用Heat Map展示数据分布
-
告警集成:配置Elasticsearch Watcher或Kibana Alerting提供告警能力
自研监控平台
对于特殊需求或已有监控体系的团队,自研监控平台也是一个选择。
架构设计与技术选型
自研监控平台通常包含以下组件:
- 数据采集层:定制采集Agent,支持多种协议和数据源
- 数据传输层:通常使用Kafka自身作为传输通道
- 数据处理层:实时计算引擎(Flink/Spark)进行数据聚合和分析
- 数据存储层:时序数据库存储原始和聚合指标
- 应用层:可视化界面、告警系统和API服务
技术选型关键考量点:
- 扩展性:支持指标种类和数据量的快速增长
- 性能:高并发写入和查询性能
- 兼容性:与现有系统的集成能力
- 成本:开发和维护成本评估
时序数据存储优化
时序数据库是监控系统的核心,几种主流选择的对比:
| 数据库 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| InfluxDB | 写入性能好,查询语言强大 | 开源版集群能力弱 | 中小规模部署 |
| TimescaleDB | 兼容PostgreSQL生态,SQL查询 | 写入性能略低于专用TSDB | 需要关系型能力的场景 |
| VictoriaMetrics | 高压缩比,集群扩展性好 | 生态相对较新 | 超大规模监控 |
| OpenTSDB | 基于HBase,易于水平扩展 | API较为简单,查询功能有限 | 已有Hadoop生态的团队 |
数据存储优化策略:
-
降采样:不同时间粒度存储不同精度数据,如:
- 原始数据:保留7天,10s一个点
- 5分钟聚合:保留30天
- 1小时聚合:保留1年
-
预聚合:针对常用查询提前计算聚合结果
- 按Topic聚合的吞吐量
- 按Consumer Group聚合的Lag情况
-
冷热分离:热数据使用高性能存储,冷数据迁移到低成本存储
前端可视化框架选择
自研平台的前端可视化框架选择也很关键:
-
开源图表库:
- ECharts:功能丰富,支持多种图表类型
- D3.js:高度定制化,适合复杂可视化需求
- G2:声明式语法,易于上手
-
仪表盘框架:
- Grafana:可直接集成,省去开发成本
- Dashboard框架:如AntV G2Plot,提供仪表盘组件
-
前端技术栈:
- React + Ant Design:组件丰富,生态完善
- Vue + Element UI:上手简单,适合快速开发
实践经验:我们曾在一个金融机构的项目中自研监控平台,采用InfluxDB存储短期数据,TimescaleDB存储长期聚合数据,前端使用React + ECharts实现。这种组合既满足了高性能需求,又提供了SQL的灵活查询能力。
无论选择哪种方案,关键是根据自身需求和现有技术栈找到最适合的解决方案。下面,我们将探讨如何利用监控系统解决Kafka运维中的实际问题。
五、典型监控场景与解决方案
监控的目的不仅是看到数据,更重要的是能够解决实际问题。就像医生不仅要看懂检查报告,还要给出诊断和治疗方案一样。以下是几个典型的Kafka监控场景和对应的解决思路。
消费延迟监控
消费延迟(Consumer Lag)是Kafka运维中最常关注的指标之一,它直接反映了系统处理能力与数据生产速度的平衡状态。
消费Lag计算方法
Lag计算有多种方法,各有优缺点:
-
传统方法 :
Lag = 最新偏移量(Log End Offset) - 消费偏移量(Current Offset)java// 示例代码:使用AdminClient获取消费组Lag public Map<TopicPartition, Long> getConsumerGroupLag(String groupId) { Map<TopicPartition, Long> result = new HashMap<>(); try (AdminClient adminClient = AdminClient.create(adminProps)) { // 获取消费组的已提交偏移量 Map<TopicPartition, OffsetAndMetadata> offsets = adminClient.listConsumerGroupOffsets(groupId).partitionsToOffsetAndMetadata().get(); // 获取主题分区的最新偏移量 Set<TopicPartition> partitions = offsets.keySet(); Map<TopicPartition, ListOffsetsResult.ListOffsetsResultInfo> endOffsets = adminClient.listOffsets(partitions.stream().collect( Collectors.toMap(tp -> tp, tp -> OffsetSpec.latest()))).all().get(); // 计算每个分区的Lag for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) { TopicPartition tp = entry.getKey(); long consumedOffset = entry.getValue().offset(); long latestOffset = endOffsets.get(tp).offset(); result.put(tp, latestOffset - consumedOffset); } } catch (Exception e) { log.error("获取消费组Lag失败", e); } return result; } -
基于时间的Lag:通过消息时间戳计算延迟时间
java// 在消费者端计算时间延迟 for (ConsumerRecord<String, String> record : records) { long messageTimestamp = record.timestamp(); // 消息生产时间戳 long currentTime = System.currentTimeMillis(); long lagMs = currentTime - messageTimestamp; // 记录延迟指标 timelagHistogram.update(lagMs); } -
Kafka Streams方法:利用Streams API的内置监控
javaStreamsBuilder builder = new StreamsBuilder(); // ... Streams拓扑定义 ... KafkaStreams streams = new KafkaStreams(builder.build(), props); // 获取消费Lag指标 Map<MetricName, ? extends Metric> metrics = streams.metrics(); for (Map.Entry<MetricName, ? extends Metric> entry : metrics.entrySet()) { if (entry.getKey().name().equals("records-lag")) { System.out.println("Consumer Lag: " + entry.getValue().metricValue()); } }
预警阈值设定策略
Lag告警不能简单设置一个固定阈值,应考虑以下因素:
-
动态阈值法:根据历史数据自动调整阈值
- 基于过去N天同时段的Lag均值+3倍标准差
- 根据业务高峰/低谷期设置不同阈值
-
多维度阈值:
- 绝对值阈值:如10000条消息
- 相对值阈值:如5分钟内增长率>50%
- 处理时间阈值:如按当前速率需要>30分钟才能处理完
-
分级告警:
- 警告级:Lag开始持续增长
- 严重级:Lag超过可接受业务延迟
- 紧急级:Lag快速增长且无法在可接受时间内恢复
实践经验:在一个电商订单系统中,我们设置了三级Lag告警:1)Lag>5000且连续3次增长触发警告;2)Lag>50000触发严重告警;3)预计处理时间>15分钟触发紧急告警。这种多级策略有效减少了误报,同时确保真正的问题能被及时发现。
案例:如何解决消费积压问题
当监控发现消费积压时,解决步骤通常如下:
-
根因分析:
- 检查消费者日志,寻找错误或异常
- 查看消费者处理逻辑,是否有性能瓶颈
- 监控下游系统,是否存在反压
- 检查网络连接和资源使用情况
-
短期应对:
- 增加消费者实例数(前提是分区数足够)
- 优化消费批次大小和提交频率
- 暂时简化处理逻辑,提高处理速度
-
长期解决:
- 重构消费者处理逻辑,提高效率
- 增加主题分区数,提高并行度
- 实现削峰填谷机制,如优先级队列
- 建立完善的监控预警,实现早期干预
真实案例分析:
我们曾遇到一个支付通知消费者突然积压的问题。通过监控发现,Lag从平时的几百条突增到5万+,且持续增长。
1. 根因分析:
- 消费者日志显示大量数据库连接超时
- 数据库监控显示连接数接近上限
- 时间点与营销活动开始吻合
2. 紧急处理:
- 增加数据库连接池大小
- 临时增加消费者实例(从3个增至10个)
- 启用备用数据库节点分担读压力
3. 长期方案:
- 实现数据库读写分离
- 引入本地缓存减少数据库访问
- 优化消费者代码,实现批量操作
- 增加主题分区数,从6个增至24个通过监控及时发现并解决消费积压问题,可以有效避免系统响应延迟和级联故障。
性能瓶颈定位
性能瓶颈往往是多个因素综合作用的结果,需要综合分析多维度指标。
结合多维度指标进行分析
性能分析需要"全局视角",关注以下维度的关联:
-
吞吐量与资源使用率关联:
- 吞吐量上升但CPU使用率不变:可能是IO或网络瓶颈
- 吞吐量与CPU使用率同步上升直至CPU饱和:CPU瓶颈
- 吞吐量上不去但GC频繁:内存瓶颈
-
延迟与队列深度关联:
- 请求队列深度增加但处理延迟正常:请求突增但处理能力足够
- 队列深度增加同时延迟增加:处理能力不足
-
磁盘操作与吞吐量关联:
- 磁盘写入速度接近上限时吞吐量不再增长:磁盘写入瓶颈
- 读请求增加但磁盘读吞吐量不变:可能受缓存影响
常见性能瓶颈模式识别
通过监控数据可以识别几种典型的性能瓶颈模式:
-
CPU瓶颈模式:
- 症状:CPU使用率>80%,请求队列增长,延迟增加
- 监控指标:
system.cpu.usage,RequestQueueSize,RequestHandlerAvgIdlePercent - 可能原因:请求处理线程数不足,消息序列化/反序列化开销大,复杂的ACL检查
-
磁盘IO瓶颈模式:
- 症状:磁盘IO接近上限,但CPU不高,吞吐量无法增长
- 监控指标:
diskio.io_time,diskio.write_bytes,log_flush_rate_and_time_ms - 可能原因:磁盘性能不足,日志分区不合理,刷盘策略过于激进
-
网络瓶颈模式:
- 症状:网络带宽接近上限,连接数高,但系统资源不紧张
- 监控指标:
network.in_bytes_rate,network.out_bytes_rate,ConnectionCount - 可能原因:网络带宽限制,大量小消息,网络配置不优
-
GC瓶颈模式:
- 症状:GC频率高,GC暂停时间长,吞吐量周期性下降
- 监控指标:
jvm.gc.collection_time,jvm.memory.heap_used_percent - 可能原因:堆内存配置不合理,消息缓存过大,内存泄漏
案例:通过监控发现并解决吞吐量下降问题
以下是一个真实案例的解决过程:
问题现象:监控显示某个Kafka集群的消息吞吐量在特定时间段(每天凌晨1点-3点)会下降约40%,但CPU使用率反而上升。
分析过程:
1. 查看多维度指标,发现:
- CPU使用率从平时的40%上升到70%
- GC频率从每小时几次增加到每分钟多次
- 磁盘写入速度下降明显
- 这个时间段恰好是日志保留策略触发删除的时间
2. 假设验证:
- 检查log cleaner线程的活动情况
- 监控发现log compaction活动与吞吐量下降高度重合
- 磁盘IO显示大量随机读写操作
3. 解决方案:
- 调整日志清理时间,避开业务高峰期
- 优化log.cleaner.io.max.bytes.per.second参数,限制清理速度
- 增加专用的log cleaner线程,与请求处理线程隔离
- 考虑SSD存储提升随机IO性能
结果:
调整后,凌晨时段的吞吐量恢复正常,CPU使用率也回到正常水平。这个案例说明,性能问题往往需要结合多维度指标才能定位根因。异常行为检测
除了明显的性能问题,监控系统还应能发现潜在的异常行为,防患于未然。
常见异常模式及指标特征
Kafka运行中的异常行为通常表现为以下模式:
-
Controller频繁选举:
- 指标特征:
ActiveControllerCount频繁变化,LeaderElectionRate高 - 潜在风险:分区Leader频繁切换,影响可用性和性能
- 可能原因:网络不稳定,ZooKeeper会话超时设置不合理
- 指标特征:
-
副本同步异常:
- 指标特征:
UnderReplicatedPartitions>0,ISRShrink频率高 - 潜在风险:降低数据可靠性,可能导致数据丢失
- 可能原因:broker性能问题,网络拥塞,配置不合理
- 指标特征:
-
分区不平衡:
- 指标特征:各broker之间的分区数量差异大,某些broker负载过高
- 潜在风险:集群资源利用不均,热点broker性能下降
- 可能原因:新增分区未触发重平衡,broker加入/离开后未手动重平衡
-
消费者停滞:
- 指标特征:消费偏移量长时间不变,但生产者持续生产
- 潜在风险:消息积压,处理延迟增加
- 可能原因:消费者崩溃,处理逻辑异常,授权问题
基于统计方法的异常检测
简单的阈值告警不足以发现所有异常,可以采用更高级的统计方法:
-
移动平均法:
python# 简化的移动平均异常检测算法 def detect_anomaly_with_moving_avg(values, window_size=24, threshold=3): if len(values) < window_size: return False # 计算移动平均 moving_avg = sum(values[-window_size:-1]) / (window_size - 1) # 计算移动标准差 moving_std = (sum((x - moving_avg) ** 2 for x in values[-window_size:-1]) / (window_size - 1)) ** 0.5 # 当前值与移动平均的偏差 deviation = abs(values[-1] - moving_avg) # 如果偏差超过N个标准差,判定为异常 return deviation > threshold * moving_std -
季节性感知方法:
python# 考虑周期性的异常检测(如每天同时段对比) def detect_seasonal_anomaly(values, season_period=24*7, lookback=4, threshold=2): if len(values) < season_period * lookback: return False # 获取历史同期数据点 historical_values = [values[-(i*season_period+1)] for i in range(1, lookback+1)] # 计算历史同期均值和标准差 hist_mean = sum(historical_values) / len(historical_values) hist_std = (sum((x - hist_mean) ** 2 for x in historical_values) / len(historical_values)) ** 0.5 # 当前值与历史同期的偏差 current_value = values[-1] deviation = abs(current_value - hist_mean) # 如果偏差超过阈值,判定为异常 return deviation > threshold * hist_std -
机器学习方法:
- 时间序列异常检测算法如ARIMA、Prophet
- 无监督学习方法如Isolation Forest、One-Class SVM
- 深度学习方法如LSTM Autoencoder
实践经验:在一个金融支付系统中,我们使用季节性感知的异常检测方法监控交易量指标,成功提前30分钟发现了一次潜在的系统异常。相比固定阈值,这种方法的误报率降低了70%,同时提高了真实异常的捕获率。
案例:如何通过监控及时发现Partition不平衡问题
分区不平衡是一个常见但容易被忽视的问题,可能导致集群负载不均:
监控发现问题:
我们在监控中添加了一个"分区分布均衡度"指标,计算方法为集群中分区数最多的broker与最少的broker之间的差异百分比。该指标正常应保持在20%以内。
某次版本升级后,监控系统触发了告警,显示分区分布差异达到47%。进一步检查发现:
- Broker-5上托管了523个分区
- Broker-3上仅托管了276个分区
- 集群平均每个broker约390个分区
根因分析:
1. 检查Broker添加历史,发现Broker-3是新增节点
2. 查看分区分配策略配置,发现auto.leader.rebalance.enable=false
3. 新建Topic时未启用机制重新平衡现有分区
解决方案:
1. 短期:手动触发分区重分配
```bash
# 生成重分配计划
kafka-reassign-partitions.sh --generate \
--bootstrap-server kafka:9092 \
--topics-to-move-json-file topics.json \
--broker-list "1,2,3,4,5" > reassignment-plan.json
# 执行重分配
kafka-reassign-partitions.sh --execute \
--bootstrap-server kafka:9092 \
--reassignment-json-file reassignment-plan.json- 长期:
- 启用自动Leader再平衡:auto.leader.rebalance.enable=true
- 实现自动化脚本,定期检查并触发分区再平衡
- 扩展监控,为分区分布添加可视化面板
成果:
重平衡后,分区分布差异降至12%,各Broker负载趋于均衡,集群整体吞吐量提升约15%。
通过监控及时发现并解决问题,可以防止小问题演变成大故障。接下来,我们将探讨如何构建一个全面、高效的监控体系。
## 六、监控体系最佳实践
构建一个完善的Kafka监控体系不仅仅是技术问题,还涉及到组织流程和最佳实践。就像建造一座大厦,需要精心的规划、合理的结构和高效的管理。
### 分层监控策略
有效的监控策略应该采用分层方法,确保从底层基础设施到上层应用的全面覆盖。
#### 基础设施层
基础设施层监控关注Kafka赖以运行的物理或虚拟环境:
- **主机级监控**:
- 系统负载:CPU、内存、磁盘IO、网络
- 操作系统:文件句柄、进程数、TCP连接状态
- 硬件状态:磁盘健康状况、RAID控制器状态(物理机场景)
- **网络级监控**:
- 带宽利用率:特别是数据中心间链路
- 网络延迟:关注broker间通信延迟
- 丢包率:网络质量问题的早期指标
- **虚拟化/容器层**:
- 资源分配:vCPU、内存、存储配额
- 调度状态:Pod状态、容器健康检查(Kubernetes环境)
- 资源竞争:宿主机过度订阅情况
推荐工具和实践:
- 主机监控:Prometheus Node Exporter + Grafana
- 网络监控:SNMP采集器、Ping测试、MTR跟踪
- 容器监控:Kubernetes Metrics API、Prometheus cAdvisor
> **实践提示**:不要忽视基础设施层的监控,许多看似是Kafka问题的故障实际源于底层基础设施。我们曾遇到一个集群性能周期性下降的案例,最终定位是与其共享存储阵列的另一个系统在执行定时备份任务。
#### 中间件层
中间件层关注Kafka本身及其依赖组件的运行状况:
- **Kafka Broker监控**:
- 前文详述的各类JMX指标
- 日志监控:ERROR级别日志频率和模式
- 进程状态:JVM堆内存、GC情况
- **ZooKeeper监控**(如果使用):
- 四字命令监控:mntr、stat等命令结果
- 连接数:活跃连接和临时节点数
- 请求延迟:请求处理时间分布
- **Kafka Connect监控**(如果使用):
- 连接器状态:运行状态、错误统计
- 任务分布:各worker负载分布
- 处理延迟:消息处理时间
典型监控配置示例(Prometheus配置片段):
```yaml
# ZooKeeper监控配置
- job_name: 'zookeeper'
static_configs:
- targets:
- 'zk1:8080' # 使用ZooKeeper Exporter
- 'zk2:8080'
- 'zk3:8080'
# Kafka Connect监控
- job_name: 'kafka-connect'
metrics_path: '/metrics'
static_configs:
- targets:
- 'connect1:8083'
- 'connect2:8083'应用层
应用层监控关注业务视角的指标,帮助理解Kafka对业务的服务质量:
-
端到端监控:
- 消息传递延迟:从生产到消费的全链路延迟
- 成功率:消息发送/消费的成功百分比
- 错误率:各类错误占比和趋势
-
业务指标关联:
- 业务处理量与Kafka吞吐量关联
- 关键业务流程的消息流转路径
- 高价值消息的单独跟踪
-
SLA监控:
- 可用性指标:服务中断时间计算
- 吞吐量保证:是否满足承诺的处理能力
- 延迟SLA:消息处理时间是否在承诺范围内
应用层监控实现示例:
java
// 生产者端测量端到端延迟的埋点代码
public class EndToEndLatencyProducer {
private final KafkaProducer<String, String> producer;
private final String topic;
private final MetricRegistry metrics = new MetricRegistry();
private final Timer sendTimer = metrics.timer("e2e.send.time");
// 构造函数省略...
public void sendWithTracking(String key, String value) {
// 添加跟踪ID和时间戳
String trackingId = UUID.randomUUID().toString();
long startTime = System.currentTimeMillis();
// 将跟踪信息放入header
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
record.headers().add("tracking_id", trackingId.getBytes());
record.headers().add("send_time", String.valueOf(startTime).getBytes());
// 存储发送时间用于后续计算延迟
trackingSendTimes.put(trackingId, startTime);
// 发送消息
producer.send(record, (metadata, exception) -> {
Timer.Context context = sendTimer.time();
try {
if (exception == null) {
// 记录发送成功
metrics.counter("messages.sent.success").inc();
} else {
// 记录发送失败
metrics.counter("messages.sent.error").inc();
}
} finally {
context.stop();
}
});
}
}
// 消费者端计算端到端延迟
public class EndToEndLatencyConsumer {
private final KafkaConsumer<String, String> consumer;
private final MetricRegistry metrics = new MetricRegistry();
private final Histogram e2eLatencyHistogram = metrics.histogram("e2e.latency.ms");
// 构造函数省略...
public void consume() {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理业务逻辑...
// 计算端到端延迟
byte[] sendTimeBytes = record.headers().lastHeader("send_time").value();
if (sendTimeBytes != null) {
long sendTime = Long.parseLong(new String(sendTimeBytes));
long latency = System.currentTimeMillis() - sendTime;
e2eLatencyHistogram.update(latency);
// 按延迟区间统计
if (latency < 100) {
metrics.counter("e2e.latency.under100ms").inc();
} else if (latency < 500) {
metrics.counter("e2e.latency.under500ms").inc();
} else if (latency < 1000) {
metrics.counter("e2e.latency.under1s").inc();
} else {
metrics.counter("e2e.latency.over1s").inc();
}
}
}
}
}分层监控策略确保了对系统的全面观测,避免了监控盲点,同时也方便了不同角色(如SRE、开发、业务人员)关注其最相关的指标。
告警体系构建
收集监控数据只是第一步,构建有效的告警体系才能让监控真正发挥价值。
告警级别定义
明确的告警级别有助于团队对问题做出适当的响应:
| 级别 | 定义 | 响应时间 | 通知方式 | 示例 |
|---|---|---|---|---|
| P0-紧急 | 生产环境严重问题,直接影响业务连续性 | 立即(5分钟内) | 电话+短信+邮件+工单 | 集群不可用、数据丢失 |
| P1-严重 | 功能严重受损,但有临时解决方案 | 30分钟内 | 短信+邮件+工单 | 大量分区不同步、严重消费延迟 |
| P2-警告 | 局部功能受影响,需要关注 | 4小时内 | 邮件+工单 | 单个Topic延迟、少量分区不同步 |
| P3-提示 | 潜在问题或性能优化建议 | 24小时内工作日 | 邮件 | 资源使用率过高、性能下降趋势 |
级别划分示例代码(Prometheus告警规则):
yaml
groups:
- name: kafka_alerts
rules:
# P0级别告警
- alert: KafkaClusterDown
expr: count(up{job="kafka"} == 0) / count(up{job="kafka"}) > 0.5
for: 2m
labels:
severity: P0
annotations:
summary: "Kafka集群大部分节点不可用"
description: "超过50%的Kafka节点已下线,请立即检查集群状态!"
# P1级别告警
- alert: KafkaUnderReplicatedPartitionsHigh
expr: kafka_server_replicamanager_underreplicatedpartitions > 100
for: 5m
labels:
severity: P1
annotations:
summary: "Kafka副本同步异常"
description: "大量分区({{ $value }})副本同步异常,可能影响数据可靠性"
# P2级别告警
- alert: KafkaConsumerGroupLagGrowing
expr: rate(kafka_consumer_group_lag[5m]) > 0 and kafka_consumer_group_lag > 5000
for: 15m
labels:
severity: P2
annotations:
summary: "消费者组{{ $labels.group }}消费延迟持续增长"
description: "消费者组{{ $labels.group }}在主题{{ $labels.topic }}上的消费延迟持续增长,当前延迟: {{ $value }}"
# P3级别告警
- alert: KafkaDiskUsageHigh
expr: node_filesystem_avail_bytes{mountpoint=~"/kafka.*"} / node_filesystem_size_bytes{mountpoint=~"/kafka.*"} < 0.2
for: 30m
labels:
severity: P3
annotations:
summary: "Kafka磁盘空间不足警告"
description: "节点{{ $labels.instance }}的磁盘空间低于20%,请考虑扩容或清理"告警聚合与抑制策略
告警风暴是运维团队的噩梦,良好的聚合和抑制策略可以提高告警信噪比:
-
告警聚合:
- 时间聚合:短时间内相同告警只发送一次
- 空间聚合:同类型不同实例的告警合并
- 层级聚合:高级别告警可以包含低级别告警
-
告警抑制:
- 依赖抑制:上游组件故障时抑制下游组件告警
- 维护期抑制:计划内维护期间抑制预期内的告警
- 告警静默:临时手动抑制特定类型告警
抑制规则示例(Alertmanager配置):
yaml
# alertmanager.yml
route:
group_by: ['job', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'default-receiver'
routes:
- match:
severity: P0
receiver: 'emergency-team'
group_wait: 0s # 紧急告警立即通知
repeat_interval: 30m
- match:
severity: P3
receiver: 'email-only'
group_wait: 2m
repeat_interval: 12h # 低级别告警降低重复频率
inhibit_rules:
# 当Kafka集群不可用时,抑制与该集群相关的所有告警
- source_match:
alertname: KafkaClusterDown
target_match_re:
alertname: Kafka.*
equal: ['job']
# 当ZooKeeper不可用时,抑制Kafka控制器告警
- source_match:
alertname: ZooKeeperClusterDown
target_match:
alertname: KafkaControllerAlert
equal: ['environment']告警通知渠道与值班体系
告警产生后,需要确保它能够被正确处理:
-
多样化通知渠道:
- 即时通讯:企业微信、Slack、钉钉
- 短信/电话:紧急情况直接通知
- 邮件:详细信息和非紧急通知
- 工单系统:自动创建处理工单
-
值班体系设计:
- 轮值制度:明确的值班表和交接流程
- 升级机制:未响应告警的自动升级路径
- 知识库:常见问题处理流程文档
-
告警响应流程:
- 确认告警:验证告警真实性
- 初步诊断:快速定位问题范围
- 问题解决:执行修复操作或临时措施
- 事后复盘:记录经验教训,改进监控
告警通知集成示例(基于Webhook的企业微信通知):
python
# webhook_handler.py
from flask import Flask, request, jsonify
import requests
import json
app = Flask(__name__)
# 企业微信机器人Webhook地址
WECHAT_WEBHOOK = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=YOUR_KEY"
@app.route('/alert', methods=['POST'])
def handle_alert():
alert_data = request.json
# 解析告警信息
alerts = alert_data.get('alerts', [])
for alert in alerts:
severity = alert.get('labels', {}).get('severity', 'unknown')
summary = alert.get('annotations', {}).get('summary', 'No summary')
description = alert.get('annotations', {}).get('description', 'No description')
# 根据级别设置不同颜色
color = {
'P0': 'red',
'P1': 'orange',
'P2': 'yellow',
'P3': 'green'
}.get(severity, 'gray')
# 构造企业微信消息
message = {
"msgtype": "markdown",
"markdown": {
"content": f"### {severity} 级告警: {summary}\n" +
f"> {description}\n\n" +
f"**状态**: {alert.get('status')}\n" +
f"**开始时间**: {alert.get('startsAt')}\n" +
f"[查看详情](http://grafana.example.com)"
}
}
# 发送到企业微信
requests.post(WECHAT_WEBHOOK, json=message)
return jsonify({"status": "success"}), 200
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)完善的告警体系让团队能够及时、有序地应对各种问题,最大限度地减少服务中断和业务影响。
监控数据应用
收集监控数据的最终目的是将其转化为价值,帮助改进系统和业务。
容量规划与预测
监控数据可以帮助我们预测未来需求并据此规划容量:
-
趋势分析:
- 识别关键指标的增长模式(线性、指数等)
- 基于历史数据预测未来增长
-
容量模型:
- 建立吞吐量与资源消耗关系模型
- 根据业务预期增长估算资源需求
-
升级计划:
- 确定升级时机(如资源使用率超过70%)
- 评估不同升级方案的成本效益
容量规划数据分析示例:
python
import pandas as pd
import numpy as np
from prophet import Prophet
import matplotlib.pyplot as plt
# 加载历史数据
df = pd.read_csv('kafka_metrics.csv')
df = df[['timestamp', 'messages_in_per_sec']]
df.columns = ['ds', 'y'] # Prophet要求的格式
df['ds'] = pd.to_datetime(df['ds'])
# 创建模型并拟合
model = Prophet(yearly_seasonality=True, weekly_seasonality=True, daily_seasonality=True)
model.fit(df)
# 预测未来90天
future = model.make_future_dataframe(periods=90)
forecast = model.predict(future)
# 容量评估
current_max = df['y'].max()
predicted_max = forecast['yhat_upper'].max()
growth_ratio = predicted_max / current_max
print(f"当前最大吞吐量: {current_max:.2f} 消息/秒")
print(f"预测90天内最大吞吐量: {predicted_max:.2f} 消息/秒")
print(f"增长比例: {growth_ratio:.2f}x")
# 容量决策
if growth_ratio > 1.5:
print("建议: 在30天内扩容集群")
print(f"建议配置: 当前Broker数 x {max(1.5, growth_ratio)}")
elif growth_ratio > 1.2:
print("建议: 在60天内评估扩容需求")
else:
print("建议: 当前容量足够,90天内无需扩容")
# 可视化预测结果
model.plot(forecast)
plt.title('Kafka消息吞吐量预测')
plt.ylabel('消息数/秒')
plt.savefig('capacity_forecast.png')性能调优依据
监控数据是性能调优的关键依据:
-
瓶颈识别:
- 利用监控数据定位系统瓶颈点
- 评估不同组件的资源饱和度
-
参数优化:
- A/B测试不同配置的性能影响
- 记录参数变更与性能指标的关联
-
调优循环:
- 建立基准-变更-测量-分析的调优流程
- 量化每次调优带来的性能改善
性能调优案例:
案例:基于监控数据优化生产者性能
初始状态:
- 监控显示平均生产延迟为120ms
- 大量的生产者MetadataRequests请求
- 消息批次填满率(batch.size利用率)仅为40%
调优过程:
1. 调整metadata.max.age.ms从300000(5分钟)增加到600000(10分钟)
- 效果:MetadataRequests频率降低50%,平均延迟降至100ms
2. 增加batch.size从16KB到64KB,同时增加linger.ms从0到10ms
- 效果:批次填满率提高到85%,吞吐量提升30%,但平均延迟增加到110ms
3. 调整compression.type从none改为lz4
- 效果:网络带宽使用降低45%,延迟维持在110ms左右
4. 优化buffer.memory,从默认的32MB增加到128MB
- 效果:高峰期性能更稳定,避免了缓冲区耗尽错误
最终结果:
- 吞吐量提升:原始吞吐量的2.1倍
- 资源效率:同等硬件条件下支持更多客户端
- 稳定性:峰值时段不再出现延迟尖刺
关键收获:没有监控数据就无法识别真正的瓶颈,也无法衡量调优的效果。业务洞察与价值挖掘
监控数据不仅对技术团队有价值,还可以为业务决策提供依据:
-
业务指标关联:
- 将Kafka指标与业务KPI关联分析
- 识别技术指标与业务成功的相关性
-
用户行为分析:
- 基于消息流分析用户行为模式
- 识别高峰期和特殊事件的特征
-
产品优化方向:
- 发现用户体验瓶颈
- 指导产品功能优先级排序
业务洞察案例:
案例:电商平台基于Kafka监控的业务优化
背景:电商平台使用Kafka处理订单流、用户行为事件和库存变更。
监控发现:
1. 订单主题流量模式分析
- 周二和周五晚上8点-10点是订单峰值
- 促销开始后15-20分钟达到流量峰值
- 手机用户产生的订单消息比PC用户多3倍
2. 用户行为分析
- "加入购物车"到"下单"的转化时间中位数为47分钟
- 浏览商品后5分钟内未加入购物车的用户转化率极低
- 支付流程中断最频繁发生在支付方式选择页面
业务优化措施:
1. 根据流量模式优化排班和促销时间
- 将客服人员集中在高峰期
- 大促活动错峰开始,避免系统负载过高
2. 产品功能优化
- 针对加入购物车后的用户增加个性化推送
- 改进支付方式选择页面,减少选项复杂度
- 优化移动端体验,提高转化效率
3. 技术架构调整
- 为订单主题增加分区,提高并行处理能力
- 实现促销期间的流量削峰填谷机制
成果:
- 订单转化率提升12%
- 促销期系统稳定性提升,订单处理延迟降低30%
- 客服资源分配更合理,满意度提升监控数据的价值不仅限于保障系统稳定,还可以成为业务决策的重要依据。通过建立技术指标与业务成功的桥梁,监控系统可以为企业创造更多价值。
七、踩坑经验总结
在构建和维护Kafka监控体系的过程中,我们难免会遇到各种问题和挑战。以下是一些来自实战经验的踩坑总结和应对策略。
监控系统稳定性保障
监控系统本身的稳定性至关重要,否则会出现"谁来监控监控系统"的困境。
避免监控系统成为单点故障
-
监控系统高可用设计:
- 部署多实例Prometheus服务,通过负载均衡访问
- 实现Alertmanager的高可用集群
- 监控数据的多副本存储
-
监控系统自监控:
- 部署独立的"元监控"系统监控主监控系统
- 关注关键指标如抓取成功率、存储使用情况
- 设置监控系统自身的告警规则
-
优雅降级机制:
- 定义核心指标和非核心指标的优先级
- 在资源紧张时优先保证核心指标的采集
- 实现采集频率的动态调整机制
监控系统自监控配置示例:
yaml
# 监控Prometheus本身的抓取任务
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 监控系统健康检查告警规则
groups:
- name: monitoring_health
rules:
- alert: MonitoringSystemDown
expr: up{job="prometheus"} == 0 or up{job="alertmanager"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "监控系统组件不可用"
description: "组件 {{ $labels.job }} 实例 {{ $labels.instance }} 已停止运行"
- alert: HighScrapeFailureRate
expr: sum(scrape_samples_scraped) / sum(scrape_samples_scraped + scrape_samples_post_metric_relabeling) < 0.5
for: 15m
labels:
severity: warning
annotations:
summary: "指标抓取失败率高"
description: "超过50%的目标抓取失败,请检查监控配置和目标可达性"踩坑案例:我们曾在一个大型金融项目中遇到监控系统不稳定的问题。起初,单个Prometheus实例负责监控整个Kafka集群(50+节点)和相关系统。当集群流量激增时,监控数据量也随之爆增,导致Prometheus频繁OOM。解决方案是实现了Prometheus的联邦集群,多个Prometheus实例分别负责不同子系统的监控,再由一个中心Prometheus聚合关键指标。同时,通过使用VictoriaMetrics作为长期存储,显著提升了系统的稳定性和性能。
监控数据采集对业务的影响控制
监控采集本身也会消耗系统资源,需要平衡监控全面性和资源消耗:
-
控制采集频率:
- 根据指标变化特性设置不同的采集间隔
- 快速变化指标:15-30秒
- 缓慢变化指标:1-5分钟
- 静态配置信息:仅在变更时采集
-
减少采集数据量:
- 使用过滤规则只采集必要指标
- 合理设置标签,避免标签基数爆炸
- 在Agent端进行数据聚合,减少传输量
-
资源限制与隔离:
- 为监控组件设置明确的资源限制
- 在高负载时自动降低采集频率
- 使用专用节点部署监控组件
优化采集配置示例:
yaml
# JMX Exporter优化配置
lowercaseOutputName: true
lowercaseOutputLabelNames: true
whitelistObjectNames:
- kafka.server:type=BrokerTopicMetrics,name=*
- kafka.server:type=ReplicaManager,name=*
- java.lang:type=GarbageCollector,name=*
- java.lang:type=Memory
# 减少高基数标签
rules:
- pattern: "kafka.server<type=BrokerTopicMetrics, name=(.+), topic=(.+)><>Count"
name: kafka_server_brokertopicmetrics_$1_total
type: COUNTER
labels:
topic: "$2"
# 过滤非关键主题,只监控重要主题
# 过滤测试主题
match: topic!~"test.*"实践经验:在一个处理金融交易的Kafka集群上,我们发现JMX Exporter默认抓取了所有Topic的所有指标,结果生成了数百万个时间序列,不仅给监控系统带来压力,还占用了大量Broker资源。通过精简监控配置,仅保留关键Topic和核心指标,我们将监控引起的CPU开销从10%降至2%以下,同时提高了监控系统的响应速度。
常见误判情况与处理
监控系统可能会产生误报或漏报,需要不断优化告警规则和处理流程。
消费Lag临时性增大的判断
消费Lag增加不一定表示问题,可能是正常的业务波动:
-
区分正常波动与异常积压:
- 结合历史同期数据判断波动是否正常
- 考虑增长率而非绝对值
- 检查是否有计划内的数据批量导入
-
智能告警规则:
- 使用变化率和持续时间组合条件
- 考虑业务高峰期自动调整阈值
- 与绝对数量和处理时间结合考量
优化的Lag告警规则:
yaml
# 考虑增长趋势和历史模式的Lag告警
- alert: KafkaConsumerLagAbnormal
expr: |
(
# 当前Lag超过历史同期均值的3倍
kafka_consumer_group_lag > 3 * avg_over_time(kafka_consumer_group_lag[1d] offset 1d)
# 且Lag增长率大于0
and rate(kafka_consumer_group_lag[10m]) > 0
# 且绝对值超过某个最小阈值
and kafka_consumer_group_lag > 5000
)
# 业务高峰期使用更高阈值
unless (hour() >= 10 and hour() < 11) or (hour() >= 19 and hour() < 21)
for: 15m
labels:
severity: warning
annotations:
summary: "异常消费延迟"
description: "消费组{{ $labels.group }}的Lag异常增加,当前值{{ $value }}远高于历史同期水平"集群重启时的监控数据波动
集群维护操作会导致指标出现异常波动,需要区分正常维护和真实问题:
-
维护窗口标记:
- 在计划维护前设置维护窗口标记
- 维护期间抑制预期内的告警
- 维护结束后验证指标恢复正常
-
指标稳定性评估:
- 定义指标恢复标准,如连续N次采集稳定
- 在维护后进行跟踪检查,确保所有指标恢复
- 对比维护前后的基准数据
维护窗口配置示例(Alertmanager):
yaml
# 定义维护窗口静默规则
silences:
# 计划内维护期间的静默规则
- name: "scheduled_maintenance"
matchers:
- name: "job"
value: "kafka"
isRegex: false
startsAt: "2023-05-20T22:00:00Z"
endsAt: "2023-05-21T02:00:00Z"
createdBy: "ops_team"
comment: "Scheduled Kafka cluster upgrade maintenance"
# 维护后的恢复检查脚本(伪代码)
function checkRecoveryAfterMaintenance() {
# 获取关键指标
metrics = getKeyMetrics('kafka_broker_status', 'last_30m')
# 检查指标稳定性
for metric in metrics:
if standardDeviation(metric.values) > 0.1 * mean(metric.values):
sendAlert("指标尚未稳定: ${metric.name}")
return false
# 与基准比较
baseline = getBaseline('kafka_performance')
currentPerf = getCurrentPerformance()
if currentPerf.throughput < 0.9 * baseline.throughput:
sendAlert("性能未恢复到基准水平")
return false
return true
}踩坑经验:在一次Kafka集群版本升级后,我们遇到了监控系统的"假警报风暴"。原因是升级后的Kafka暴露了一些新的JMX指标,而我们的监控系统没有相应的基准数据,导致大量"异常"告警。解决方法是:1) 在大型维护前先在测试环境获取新版本的指标特征;2) 为新增指标设置初步阈值;3) 维护后使用"学习模式",收集一段时间的数据作为新基准。
扩展性问题
随着业务规模的增长,监控系统的扩展性问题逐渐显现,需要提前规划应对策略。
大规模集群监控压力处理
当Kafka集群规模增长时,监控系统可能面临性能挑战:
-
分层监控架构:
- 实现监控数据的分区和联邦
- 核心指标和全量指标分开存储
- 使用边缘采集器减少中心节点压力
-
采样监控:
- 对高频指标进行采样处理
- 实现动态采样率调整
- 保留原始数据的统计特征
-
资源垂直扩展:
- 为监控系统选择高性能硬件
- 针对监控场景优化存储引擎
- 实现监控数据的压缩和归档
大规模监控架构示例:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Exporter 1 │ │ Exporter 2 │ │ Exporter N │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│Prometheus 1 │ │Prometheus 2 │ │Prometheus N │
│(分区1指标) │ │(分区2指标) │ │(分区N指标) │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└──────────────────┼──────────────────┘
│
▼
┌───────────────┐
│ Prometheus │
│ Federation │ ─────┐
└───────┬───────┘ │
│ ▼
│ ┌───────────────┐
│ │ Thanos/ │
│ │ VictoriaMetrics│
│ │ 长期存储 │
▼ └───────────────┘
┌───────────────┐
│ Grafana │
└───────────────┘历史数据存储与查询优化
随着时间推移,监控数据量呈指数级增长,需要特别关注存储和查询效率:
-
数据生命周期管理:
- 实现多级存储策略
- 自动降采样和归档
- 过期数据清理策略
-
查询优化技术:
- 预计算常用聚合查询
- 实现查询结果缓存
- 使用分布式查询引擎
-
存储技术选择:
- 评估列式存储和时序数据库
- 考虑压缩算法和索引策略
- 实现冷热数据分离
数据生命周期配置示例:
yaml
# Prometheus数据保留配置
storage:
tsdb:
path: /var/lib/prometheus
retention.time: 15d # 保留15天原始精度数据
# VictoriaMetrics数据降采样策略
downsampling:
# 5分钟粒度数据保留30天
- interval: 5m
retention: 30d
# 1小时粒度数据保留90天
- interval: 1h
retention: 90d
# 1天粒度数据保留1年
- interval: 1d
retention: 365d
# 查询优化配置
query:
max_samples: 50000000
timeout: 2m
cache:
enabled: true
size: 1GB实践案例:我们在一个大型金融机构的实践中,采用了多层次存储策略来管理Kafka监控数据。在这个拥有200+Broker的Kafka集群中,每天产生约5TB的原始监控数据。我们的解决方案是:1) 实时监控使用Prometheus保留7天数据;2) 中期数据(30天)存储在VictoriaMetrics中,使用5分钟聚合;3) 长期数据(1年)使用TimescaleDB存储,使用1小时聚合,并按月分区。查询时根据时间范围自动选择数据源,大大提高了查询效率,同时控制了存储成本。
通过总结和分享这些踩坑经验,我们希望能帮助更多团队少走弯路,更快地构建稳定可靠的Kafka监控体系。在下一章,我们将通过一个完整案例,展示如何将这些理念和实践应用到实际项目中。
八、案例分享:全链路监控体系构建
理论知识需要结合实际案例才能真正理解和应用。本章将分享一个真实项目中构建Kafka全链路监控体系的案例,从需求分析到最终效果,完整展示监控体系的构建过程。
业务背景与挑战
项目背景:某大型电商平台的订单处理系统,使用Kafka作为核心消息总线,连接订单创建、支付处理、库存管理、物流配送等多个业务域。
系统规模:
- Kafka集群:3个环境,共计36个broker
- Topic数量:约200个业务Topic
- 消息量:日均处理20亿条消息,峰值TPS 50,000+
- 客户端:50+微服务,涉及Java、Go、Python等多语言
面临挑战:
- 可见性不足:各团队只能看到自己负责的部分,缺乏端到端视图
- 故障定位困难:问题发生时难以快速确定是生产者、Kafka还是消费者问题
- 性能瓶颈未知:系统性能波动,但无法准确定位瓶颈点
- 多语言客户端:不同语言的客户端指标不统一,难以整合
- 业务关联缺失:技术监控与业务影响无法直接关联
监控体系架构设计
经过需求分析和技术调研,我们设计了一个分层的监控架构:
┌─────────────────────────────────┐
│ 业务视图层 │
│ ┌─────────┐ ┌─────────────────┐ │
│ │订单链路图│ │异常订单检测面板 │ │
│ └─────────┘ └─────────────────┘ │
└─────────────────────────────────┘
▲
│
┌─────────────────────────────────┼─────────────────────────────────┐
│ 应用视图层 │
│ ┌─────────────┐ ┌───────────────┐ ┌────────────┐ ┌──────────────┐ │
│ │生产者监控面板│ │Kafka集群监控 │ │消费者监控 │ │端到端延迟面板 │ │
│ └─────────────┘ └───────────────┘ └────────────┘ └──────────────┘ │
└─────────────────────────────────┼─────────────────────────────────┘
▲
│
┌─────────────────────────────────┼─────────────────────────────────┐
│ 数据处理层 │
│ ┌─────────────┐ ┌───────────────┐ ┌────────────────────────────┐ │
│ │实时计算(Flink)│ │指标聚合服务 │ │异常检测引擎 │ │
│ └─────────────┘ └───────────────┘ └────────────────────────────┘ │
└─────────────────────────────────┼─────────────────────────────────┘
▲
│
┌─────────────────────────────────┼─────────────────────────────────┐
│ 数据采集层 │
│ ┌─────────────┐ ┌───────────────┐ ┌────────────┐ ┌──────────────┐ │
│ │JMX Exporter │ │Client SDK埋点 │ │日志解析器 │ │链路追踪Agent │ │
│ └─────────────┘ └───────────────┘ └────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────────┘技术选型:
- 监控数据采集:Prometheus + JMX Exporter, OpenTelemetry
- 指标存储:Prometheus(短期), InfluxDB(长期)
- 链路追踪:Jaeger
- 日志管理:ELK Stack
- 可视化平台:Grafana
- 告警系统:Alertmanager + 自研告警网关
- 数据处理:Flink实时计算 + 自研聚合服务
核心指标看板展示
根据不同用户角色的需求,我们设计了多层次的监控面板:
1. Kafka集群监控面板
关注Kafka集群的健康状态和性能指标,主要面向平台运维团队:
核心指标:
- 集群健康状态(Controller状态、分区状态)
- Broker资源使用(CPU、内存、磁盘IO)
- 消息吞吐量(生产/消费TPS)
- 请求处理质量(请求队列、响应时间)
实现细节:
yaml
# Grafana面板配置片段
panels:
- title: "集群状态概览"
type: stat
options:
colorMode: "value"
graphMode: "area"
targets:
- expr: "sum(kafka_server_replicamanager_underreplicatedpartitions)"
legendFormat: "未同步分区数"
- expr: "sum(kafka_server_replicamanager_offlinereplicacount)"
legendFormat: "离线副本数"
- expr: "sum(kafka_controller_kafkacontroller_activecontrollercount)"
legendFormat: "活跃控制器数"
- title: "消息吞吐量(每秒)"
type: graph
options:
legend:
show: true
tooltip:
shared: true
targets:
- expr: "sum(rate(kafka_server_brokertopicmetrics_messagesin_total[5m]))"
legendFormat: "进入消息总量"
- expr: "sum(rate(kafka_server_brokertopicmetrics_bytesout_total[5m]))"
legendFormat: "流出字节总量"2. 业务流监控面板
关注业务视角的消息流转和处理状态,主要面向业务团队和产品经理:
核心指标:
- 订单处理量和成功率
- 各环节处理延迟
- 异常订单比例
- 峰值处理能力
实现细节:
yaml
# Grafana面板配置片段
panels:
- title: "订单处理流程状态"
type: flowchart
options:
showLegend: true
targets:
- expr: "sum(rate(order_creation_total[5m]))"
legendFormat: "订单创建"
- expr: "sum(rate(payment_processing_total[5m]))"
legendFormat: "支付处理"
- expr: "sum(rate(inventory_update_total[5m]))"
legendFormat: "库存更新"
- expr: "sum(rate(logistics_dispatch_total[5m]))"
legendFormat: "物流派送"
- title: "各环节处理延迟(秒)"
type: heatmap
options:
yBucketBound: "auto"
targets:
- expr: "rate(order_processing_duration_bucket[5m])"
legendFormat: "{{le}}"3. 端到端延迟监控面板
专注于消息从生产到消费的全链路延迟监控,面向性能优化团队:
核心指标:
- 端到端消息延迟
- 各环节处理时间占比
- 延迟分布热力图
- 慢消息追踪
实现方式:
- 生产者埋点记录发送时间戳
- 消息头部携带跟踪ID和时间戳
- 消费者记录接收和处理完成时间
- 计算各环节耗时
面板配置:
yaml
# Grafana面板配置片段
panels:
- title: "消息端到端延迟(毫秒)"
type: graph
options:
series:
- color: "#5794F2"
yaxes:
- format: "ms"
targets:
- expr: "histogram_quantile(0.95, sum(rate(kafka_message_e2e_latency_bucket[5m])) by (le, topic))"
legendFormat: "P95 - {{topic}}"
- expr: "histogram_quantile(0.99, sum(rate(kafka_message_e2e_latency_bucket[5m])) by (le, topic))"
legendFormat: "P99 - {{topic}}"
- title: "延迟构成比例"
type: piechart
options:
displayLabels: ["name", "percent"]
targets:
- expr: "avg(kafka_producer_latency_avg)"
legendFormat: "生产者"
- expr: "avg(kafka_broker_processing_time_avg)"
legendFormat: "Broker处理"
- expr: "avg(kafka_consumer_processing_time_avg)"
legendFormat: "消费者处理"4. 告警与异常检测面板
集中展示系统告警和自动检测到的异常,面向运维团队和值班人员:
核心功能:
- 活跃告警列表
- 告警历史统计
- 异常模式识别
- 自动诊断建议
实现细节:
yaml
# Grafana面板配置片段
panels:
- title: "活跃告警"
type: table
options:
showHeader: true
columns:
- field: "labels.alertname"
title: "告警名称"
- field: "labels.severity"
title: "严重性"
- field: "annotations.summary"
title: "概述"
- field: "state"
title: "状态"
- field: "activeAt"
title: "开始时间"
targets:
- expr: "ALERTS{alertstate=\"firing\"}"
- title: "异常检测"
type: gauge
options:
showThresholdLabels: true
showThresholdMarkers: true
thresholds:
steps:
- value: 0
color: "green"
- value: 3
color: "yellow"
- value: 7
color: "orange"
- value: 10
color: "red"
targets:
- expr: "sum(kafka_anomaly_score)"
legendFormat: "异常评分"实施效果与价值
实施这套全链路监控体系后,我们获得了显著的业务价值和技术收益:
直接效果
-
故障检测提前
- MTTR(平均恢复时间)降低了45%,从平均38分钟降至21分钟
- 73%的问题在用户感知前被发现并解决
- 严重故障数量同比下降52%
-
性能提升
- 端到端消息处理延迟降低了35%
- 吞吐量提升25%,支持了业务30%的增长而无需扩容
- 资源利用率提高20%,降低了硬件成本
-
运维效率
- 故障定位时间缩短60%,从平均25分钟降至10分钟以内
- 自动化处理的告警比例从15%提升到65%
- 值班人员响应负担降低70%
业务价值
-
用户体验提升
- 订单处理端到端时间缩短42%
- 下单高峰期系统稳定性提升,支付成功率提高2.5%
- 系统可用性从99.95%提升至99.99%
-
业务洞察
- 发现并优化了3个核心业务流程的瓶颈
- 基于消息流量模式,优化了促销活动时间,提高转化率
- 为产品团队提供了用户行为数据,指导功能优化
-
成本降低
- 硬件资源成本降低约22%
- 故障处理人力成本降低约35%
- 由于提前发现问题,避免了若干次潜在的重大故障,价值无法直接量化但显著
经验总结
在项目实施过程中,我们总结了以下关键经验:
-
全链路视图至关重要
- 孤立监控各组件无法发现系统级问题
- 业务上下文结合技术指标才能真正理解系统运行状态
-
分层设计适应不同用户
- 技术团队需要详细指标
- 业务团队需要业务语言描述的状态
- 管理层需要高层次摘要和趋势
-
自动化是规模化的关键
- 手动分析无法应对大量监控数据
- 自动异常检测和诊断显著提高效率
- 持续改进告警规则和阈值至关重要
-
监控即产品
- 监控系统本身应视为面向用户的产品
- 用户体验和易用性直接影响采纳度
- 需要持续收集反馈并迭代改进
项目关键启示:监控不仅是技术工具,更是连接技术和业务的桥梁。当我们能够将技术指标与业务价值关联起来,监控系统才能真正发挥最大价值。
这个案例展示了一个成功的全链路监控体系如何从技术实现到业务价值交付的完整过程。通过综合应用本文前面章节讨论的各种理念和技术,我们构建了一个不仅能发现问题,还能创造价值的监控系统。
九、未来展望
随着技术的不断发展和业务需求的持续变化,Kafka监控体系也在不断演进。未来的监控系统将更加智能、自动化,并与其他系统深度集成。本章我们将探讨Kafka监控的未来发展趋势。
智能化监控趋势
传统的基于规则和阈值的监控正在向智能化监控转变,AI/ML技术正在为监控系统带来革命性的变化。
机器学习在异常检测中的应用
机器学习可以帮助我们发现传统方法难以察觉的复杂异常模式:
-
无监督学习异常检测
- 基于聚类分析识别异常行为
- 使用降维技术捕捉高维异常
- 时间序列分解和季节性调整
-
预测性监控
- 使用时间序列预测模型预判未来状态
- 提前发现潜在问题的趋势
- 构建正常行为基线,检测偏差
-
智能根因分析
- 基于图模型的故障传播分析
- 使用因果推断技术定位根本原因
- 结合专家系统提供修复建议
示例:基于LSTM的Kafka消费延迟预测模型:
python
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
# 准备历史数据
def prepare_data(lag_series, time_steps=10):
X, y = [], []
for i in range(len(lag_series) - time_steps):
X.append(lag_series[i:(i + time_steps)])
y.append(lag_series[i + time_steps])
return np.array(X), np.array(y)
# 加载历史Lag数据
df = pd.read_csv('consumer_lag_history.csv')
lag_values = df['lag_value'].values.reshape(-1, 1)
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
lag_scaled = scaler.fit_transform(lag_values)
# 准备训练数据,使用过去10个时间点预测下一个点
X, y = prepare_data(lag_scaled, 10)
X = X.reshape(X.shape[0], X.shape[1], 1)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(10, 1)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X, y, epochs=100, batch_size=32, verbose=2)
# 使用模型进行预测
def predict_next_lag(current_values):
x = current_values[-10:].reshape(1, 10, 1)
prediction = model.predict(x)
return scaler.inverse_transform(prediction)[0][0]
# 预测未来12小时的Lag趋势
future_prediction = []
last_sequence = lag_scaled[-10:].reshape(1, 10, 1)
for _ in range(12):
next_pred = model.predict(last_sequence)[0]
future_prediction.append(next_pred)
# 更新序列,加入新预测,移除最早的值
last_sequence = np.append(last_sequence[:,1:,:], [[next_pred]], axis=1)
# 转换回原始比例
future_prediction = scaler.inverse_transform(np.array(future_prediction).reshape(-1, 1))
print("预测的未来12小时消费Lag趋势:", future_prediction.flatten())前沿实践:我们最近在一个大型零售企业的Kafka平台中实施了智能异常检测系统,该系统能够学习每个Topic和Consumer Group的正常行为模式,包括日内、周内和季节性模式。这套系统在试点阶段就发现了多个传统监控未能察觉的异常,如一个支付处理Topic的周期性延迟模式变化,最终追查到是一个批处理作业的资源竞争导致的。异常检测的准确率达到92%,误报率较传统阈值监控降低了70%。
自动化运维响应
监控系统的价值最终体现在问题的解决上,自动化运维响应是未来的关键方向:
-
自动修复能力
- 基于既定策略的自动修复操作
- 自动触发扩容/缩容操作
- 智能负载均衡和资源调配
-
闭环工作流
- 监控-检测-分析-修复的闭环流程
- 自动生成和更新runbook
- 学习人工操作模式并自动化
-
渐进式自动化
- 低风险操作完全自动化
- 中等风险操作"人在环中"(Human-in-the-loop)
- 高风险操作提供建议但由人工执行
自动化运维脚本示例(针对分区不平衡问题):
python
#!/usr/bin/env python3
# 自动检测并修复Kafka分区不平衡问题
import subprocess
import json
import time
import logging
import requests
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 配置参数
KAFKA_HOME = "/opt/kafka"
BOOTSTRAP_SERVERS = "kafka1:9092,kafka2:9092,kafka3:9092"
IMBALANCE_THRESHOLD = 0.2 # 20%不平衡视为需要干预
PROMETHEUS_URL = "http://prometheus:9090/api/v1/query"
ALERT_API = "http://alert-gateway:8080/api/notify"
def get_partition_distribution():
"""从Prometheus获取分区分布信息"""
query = 'count(kafka_server_replicamanager_partitioncount) by (instance)'
response = requests.get(PROMETHEUS_URL, params={'query': query})
if response.status_code != 200:
logger.error(f"Prometheus查询失败: {response.text}")
return None
result = response.json()
partition_counts = {}
for item in result.get('data', {}).get('result', []):
instance = item['metric']['instance']
count = float(item['value'][1])
partition_counts[instance] = count
return partition_counts
def check_imbalance(partition_counts):
"""检查分区分布是否不平衡"""
if not partition_counts:
return False, 0
min_count = min(partition_counts.values())
max_count = max(partition_counts.values())
avg_count = sum(partition_counts.values()) / len(partition_counts)
# 计算不平衡度
imbalance_ratio = (max_count - min_count) / avg_count
return imbalance_ratio > IMBALANCE_THRESHOLD, imbalance_ratio
def generate_reassignment_plan():
"""生成分区重分配计划"""
# 获取所有topic
cmd = f"{KAFKA_HOME}/bin/kafka-topics.sh --bootstrap-server {BOOTSTRAP_SERVERS} --list"
topics = subprocess.check_output(cmd, shell=True).decode().strip().split('\n')
# 准备topics.json文件
topics_json = {"topics": [{"topic": topic} for topic in topics], "version": 1}
with open("/tmp/topics_to_move.json", "w") as f:
json.dump(topics_json, f)
# 获取broker列表
cmd = f"{KAFKA_HOME}/bin/kafka-broker-api-versions.sh --bootstrap-server {BOOTSTRAP_SERVERS}"
output = subprocess.check_output(cmd, shell=True).decode()
brokers = [line.split("(")[0].strip() for line in output.split('\n') if "(kafka.server.BrokerApiVersions)" in line]
broker_ids = ','.join([b.split(':')[0] for b in brokers])
# 生成重分配计划
cmd = f"{KAFKA_HOME}/bin/kafka-reassign-partitions.sh --bootstrap-server {BOOTSTRAP_SERVERS} " \
f"--topics-to-move-json-file /tmp/topics_to_move.json " \
f"--broker-list {broker_ids} " \
f"--generate"
plan = subprocess.check_output(cmd, shell=True).decode()
# 提取JSON部分
json_str = plan.split("Proposed partition reassignment configuration")[1].strip()
reassignment_json = json.loads(json_str)
with open("/tmp/reassignment_plan.json", "w") as f:
json.dump(reassignment_json, f)
return "/tmp/reassignment_plan.json"
def execute_reassignment(plan_file):
"""执行分区重分配"""
cmd = f"{KAFKA_HOME}/bin/kafka-reassign-partitions.sh --bootstrap-server {BOOTSTRAP_SERVERS} " \
f"--reassignment-json-file {plan_file} " \
f"--execute"
result = subprocess.check_output(cmd, shell=True).decode()
logger.info(f"重分配执行结果: {result}")
return "Successfully started" in result
def verify_reassignment():
"""验证重分配结果"""
cmd = f"{KAFKA_HOME}/bin/kafka-reassign-partitions.sh --bootstrap-server {BOOTSTRAP_SERVERS} " \
f"--reassignment-json-file /tmp/reassignment_plan.json " \
f"--verify"
result = subprocess.check_output(cmd, shell=True).decode()
logger.info(f"重分配验证结果: {result}")
return "Reassignment of partition" in result and "completed successfully" in result
def send_notification(message, level="info"):
"""发送通知"""
payload = {
"title": "Kafka分区重平衡操作",
"message": message,
"level": level,
"source": "partition_rebalancer",
"timestamp": int(time.time())
}
try:
response = requests.post(ALERT_API, json=payload)
logger.info(f"通知发送结果: {response.status_code}")
except Exception as e:
logger.error(f"发送通知失败: {e}")
def main():
logger.info("开始检查Kafka分区分布")
# 1. 检查分区分布
partition_counts = get_partition_distribution()
imbalanced, ratio = check_imbalance(partition_counts)
if not imbalanced:
logger.info(f"分区分布正常,不平衡率: {ratio:.2f}")
return
logger.warning(f"检测到分区分布不平衡,不平衡率: {ratio:.2f}")
send_notification(f"检测到Kafka分区不平衡,不平衡率: {ratio:.2f},准备执行自动重平衡", "warning")
# 2. 生成重分配计划
try:
plan_file = generate_reassignment_plan()
logger.info(f"重分配计划已生成: {plan_file}")
send_notification("分区重分配计划已生成,准备执行")
except Exception as e:
logger.error(f"生成重分配计划失败: {e}")
send_notification(f"生成分区重分配计划失败: {str(e)}", "error")
return
# 3. 执行重分配
try:
success = execute_reassignment(plan_file)
if success:
logger.info("重分配任务已成功启动")
send_notification("分区重分配任务已启动,将在后台执行")
else:
logger.error("重分配任务启动失败")
send_notification("分区重分配任务启动失败", "error")
return
except Exception as e:
logger.error(f"执行重分配失败: {e}")
send_notification(f"执行分区重分配失败: {str(e)}", "error")
return
# 4. 定期检查重分配状态
max_checks = 12 # 最多检查12次
check_interval = 300 # 每5分钟检查一次
for i in range(max_checks):
time.sleep(check_interval)
try:
completed = verify_reassignment()
if completed:
logger.info("重分配已完成")
# 再次检查分布情况
new_partition_counts = get_partition_distribution()
still_imbalanced, new_ratio = check_imbalance(new_partition_counts)
if still_imbalanced:
logger.warning(f"重分配后仍存在不平衡,不平衡率: {new_ratio:.2f}")
send_notification(f"分区重分配已完成,但仍存在不平衡,不平衡率从 {ratio:.2f} 降至 {new_ratio:.2f}", "warning")
else:
logger.info(f"重分配成功,当前不平衡率: {new_ratio:.2f}")
send_notification(f"分区重分配成功完成,不平衡率从 {ratio:.2f} 降至 {new_ratio:.2f}", "info")
break
except Exception as e:
logger.error(f"检查重分配状态失败: {e}")
else:
logger.warning("重分配状态检查超时,请手动验证结果")
send_notification("分区重分配状态检查超时,请运维人员手动验证结果", "warning")
if __name__ == "__main__":
main()实践趋势:在我们最近的项目中,自动化运维响应已经在低风险场景取得了显著成效。例如,我们实现了Consumer Group消费延迟的自动扩容,当监测到某个Consumer Group的Lag持续增长且超过阈值时,系统会自动增加消费者实例数。在实施该功能三个月后,消费延迟相关的人工干预次数减少了80%,同时系统的资源利用率提高了15%,因为不需要为应对高峰期预留过多冗余资源。
与其他系统的集成
未来的Kafka监控不会是孤立的系统,而是与企业的其他技术和业务系统深度集成的有机部分。
与追踪系统的结合
分布式追踪系统能够提供请求级别的细粒度可见性,与Kafka监控结合可以实现端到端的全景视图:
-
消息流与请求流关联
- 将Kafka消息与上下游服务请求关联
- 追踪单个业务事务的全链路流程
- 识别跨系统的性能瓶颈
-
异常传播分析
- 追踪故障如何在系统间传播
- 识别错误的根源和影响范围
- 减少跨团队故障归责争议
-
服务网格集成
- 与Istio等服务网格平台集成
- 利用服务网格提供的细粒度控制能力
- 基于追踪数据实现自动流量控制和故障隔离
追踪系统与Kafka监控集成示例:
java
// 生产者端集成OpenTelemetry追踪
public class TracedKafkaProducer {
private final KafkaProducer<String, String> producer;
private final Tracer tracer;
public TracedKafkaProducer(Properties config) {
this.producer = new KafkaProducer<>(config);
// 获取全局Tracer
this.tracer = GlobalOpenTelemetry.getTracer("kafka-producer");
}
public Future<RecordMetadata> send(String topic, String key, String value) {
// 获取当前活动Span上下文
Span parentSpan = tracer.getCurrentSpan();
Context context = parentSpan != null ? Context.current().with(parentSpan) : Context.current();
// 创建新的Span用于追踪Kafka发送操作
Span span = tracer.spanBuilder("kafka.produce")
.setParent(context)
.setAttribute("messaging.system", "kafka")
.setAttribute("messaging.destination", topic)
.setAttribute("messaging.destination_kind", "topic")
.setAttribute("messaging.kafka.key", key)
.startSpan();
try (Scope scope = span.makeCurrent()) {
// 将追踪上下文注入消息头
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 注入SpanContext到消息头
final SpanContext spanContext = span.getSpanContext();
record.headers().add("trace_id", spanContext.getTraceId().getBytes());
record.headers().add("span_id", spanContext.getSpanId().getBytes());
// 发送消息并处理回调
return producer.send(record, (metadata, exception) -> {
if (exception != null) {
span.setStatus(StatusCode.ERROR, exception.getMessage());
span.recordException(exception);
} else {
span.setAttribute("messaging.kafka.partition", metadata.partition());
span.setAttribute("messaging.kafka.offset", metadata.offset());
}
span.end();
});
} catch (Exception e) {
span.setStatus(StatusCode.ERROR, e.getMessage());
span.recordException(e);
span.end();
throw e;
}
}
}
// 消费者端集成OpenTelemetry追踪
public class TracedKafkaConsumer {
private final KafkaConsumer<String, String> consumer;
private final Tracer tracer;
private final MessageProcessor processor;
public TracedKafkaConsumer(Properties config, MessageProcessor processor) {
this.consumer = new KafkaConsumer<>(config);
this.tracer = GlobalOpenTelemetry.getTracer("kafka-consumer");
this.processor = processor;
}
public void pollAndProcess(Duration timeout) {
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
// 从消息头提取追踪信息
byte[] traceIdBytes = record.headers().lastHeader("trace_id").value();
byte[] spanIdBytes = record.headers().lastHeader("span_id").value();
// 构建父Span上下文
String traceId = new String(traceIdBytes);
String parentSpanId = new String(spanIdBytes);
// 创建新的消费Span,关联到产生Span
Span span = tracer.spanBuilder("kafka.consume")
.setAttribute("messaging.system", "kafka")
.setAttribute("messaging.destination", record.topic())
.setAttribute("messaging.kafka.partition", record.partition())
.setAttribute("messaging.kafka.offset", record.offset())
.setAttribute("messaging.kafka.key", record.key())
.setParent(createParentContext(traceId, parentSpanId))
.startSpan();
try (Scope scope = span.makeCurrent()) {
// 处理消息
processor.process(record);
// 更新处理状态
span.setAttribute("processing.success", true);
} catch (Exception e) {
span.setStatus(StatusCode.ERROR, e.getMessage());
span.recordException(e);
throw e;
} finally {
span.end();
}
}
}
private Context createParentContext(String traceId, String spanId) {
// 构建父上下文...
// 实现略,需要使用特定的OpenTelemetry API
return Context.current(); // 简化版
}
}前沿实践:在一个大型金融支付平台中,我们实现了Kafka与Jaeger的深度集成,使每个消息都能追踪从API请求、到Kafka生产、到消费处理、再到下游操作的完整路径。这为我们提供了前所未有的可见性,例如,我们可以准确定位某个特定交易ID在整个系统中的处理路径和耗时分布。在一次严重的性能下降事件中,这套集成系统帮助我们在15分钟内定位到根本原因是数据库连接池配置变更导致的,而传统方法可能需要数小时的调查。
与日志系统的协同
日志和指标是观测性的两大支柱,它们的有机结合能够提供更全面的系统视图:
-
日志增强型指标
- 从日志中提取结构化指标
- 日志事件与指标异常的关联分析
- 日志模式识别和异常检测
-
上下文感知日志
- 基于监控异常自动增强日志级别
- 在关键性能阈值触发时收集更详细日志
- 日志与指标时间轴关联
-
统一可观测性平台
- 日志、指标、追踪的统一视图
- 基于共享上下文的问题关联
- 统一的查询和分析接口
日志与指标协同示例:
java
// 基于监控状态动态调整日志级别的Agent
public class DynamicLoggingAgent {
private final PrometheusClient prometheusClient;
private final LoggingManager loggingManager;
private final ScheduledExecutorService scheduler;
// 监控规则配置
private final List<MonitoringRule> rules = Arrays.asList(
new MonitoringRule(
"kafka_consumer_lag_high",
"sum(kafka_consumer_group_lag{group='payment-processor'}) > 10000",
"org.example.kafka.consumer.PaymentProcessor",
Level.DEBUG,
Duration.ofMinutes(15)
),
new MonitoringRule(
"kafka_broker_high_cpu",
"avg(system_cpu_usage{job='kafka'}) > 0.8",
"kafka.server",
Level.DEBUG,
Duration.ofMinutes(10)
)
);
public DynamicLoggingAgent(String prometheusUrl) {
this.prometheusClient = new PrometheusClient(prometheusUrl);
this.loggingManager = new LoggingManager();
this.scheduler = Executors.newScheduledThreadPool(1);
}
public void start() {
// 每分钟检查一次监控规则
scheduler.scheduleAtFixedRate(this::checkRules, 0, 1, TimeUnit.MINUTES);
}
private void checkRules() {
for (MonitoringRule rule : rules) {
try {
boolean isTriggered = prometheusClient.queryAlert(rule.getQuery());
if (isTriggered && !rule.isActive()) {
// 激活规则,提升日志级别
loggingManager.setLogLevel(rule.getLoggerName(), rule.getTargetLevel());
rule.activate();
// 记录事件
log.info("提升日志级别: {} -> {} 由于触发规则: {}",
rule.getLoggerName(), rule.getTargetLevel(), rule.getName());
// 设置自动恢复
scheduler.schedule(() -> {
if (rule.isActive()) {
loggingManager.resetLogLevel(rule.getLoggerName());
rule.deactivate();
log.info("恢复日志级别: {} 规则超时: {}",
rule.getLoggerName(), rule.getName());
}
}, rule.getDuration().toMillis(), TimeUnit.MILLISECONDS);
}
} catch (Exception e) {
log.error("检查规则失败: " + rule.getName(), e);
}
}
}
// 监控规则定义
private static class MonitoringRule {
private final String name;
private final String query;
private final String loggerName;
private final Level targetLevel;
private final Duration duration;
private boolean active = false;
// 构造函数和getter/setter省略...
public void activate() {
this.active = true;
}
public void deactivate() {
this.active = false;
}
public boolean isActive() {
return active;
}
}
}最佳实践:在一个电子商务平台的物流系统中,我们实现了"智能日志增强"功能。当系统检测到某个物流Topic的消费Lag异常增长时,相关消费者的日志级别会自动从INFO提升为DEBUG,并启动详细的消息采样记录。同时,我们开发了一个日志分析器,能够从日志中提取结构化数据并生成指标,如消息处理成功率、第三方API调用延迟等。这种双向集成使得运维团队能够在单一界面中看到系统状态的完整视图,大幅提高了问题定位效率。
十、总结与参考资料
通过本文的探讨,我们全面梳理了构建Kafka监控体系的关键环节和最佳实践。从指标收集、存储可视化到问题诊断、自动化运维,我们不仅关注了技术细节,更强调了业务价值和未来趋势。
本文要点总结
-
监控体系的核心价值
- 监控不仅是发现问题的工具,更是保障系统可靠性和业务连续性的关键基础设施
- 从被动响应到主动预防的转变需要全面、深入的监控体系支持
- 监控数据不仅有技术价值,还能为业务决策提供重要依据
-
关键监控指标梳理
- 多层次监控(集群、Broker、Topic、Consumer)确保全面覆盖
- 不同指标反映系统不同方面的健康状况,需要综合分析
- 核心指标(如副本同步、消费Lag)应重点关注
-
指标收集方案
- JMX是Kafka监控的基础,可通过多种工具采集
- 客户端埋点提供更贴近业务的监控视角
- 自带工具可用于性能基准测试和问题诊断
-
存储与可视化选择
- Prometheus+Grafana适合中小规模部署和开源社区
- ELK适合已有日志平台的团队
- 自研方案适合有特殊需求的大型企业
-
监控体系最佳实践
- 分层监控策略确保全面覆盖各个层面
- 完善的告警体系避免告警风暴和误报
- 监控数据的价值在于应用,包括容量规划、性能调优和业务洞察
-
踩坑经验与案例分享
- 监控系统本身的稳定性同样重要
- 大规模集群面临的扩展性挑战需要特别关注
- 全链路监控案例展示了综合实践的价值
-
未来发展趋势
- 智能化监控将减少人工干预
- 自动化运维响应提高效率,降低成本
- 与追踪、日志系统的深度集成提供更全面的可观测性
开源工具与框架推荐
构建Kafka监控体系可利用多种优秀的开源工具:
-
指标采集工具
- Prometheus JMX Exporter - 轻量级JMX指标采集器
- Jolokia - 将JMX转换为REST API
- Telegraf - 多功能指标采集代理
-
监控系统
- Prometheus - 强大的时序数据库和监控系统
- Grafana - 最流行的可视化平台
- ELK Stack - 日志和指标的综合平台
-
Kafka专用工具
- Kafka Manager - Yahoo开发的Kafka管理工具
- Kafka Monitor - LinkedIn开发的端到端监控
- Kafdrop - Kafka Web UI
-
追踪系统
- Jaeger - 分布式追踪系统
- OpenTelemetry - 开放标准的可观测性框架
-
异常检测与AI工具
- Prophet - Facebook的时间序列预测库
- Anomaly Detection Toolkit - 时间序列异常检测工具包
- TensorFlow - 构建AI模型的框架
延伸阅读资料
想要深入了解Kafka监控和性能优化,可参考以下资料:
-
官方文档
- Apache Kafka Documentation - 官方文档
- Confluent Kafka Monitoring - Confluent平台监控文档
-
技术书籍
- 《Kafka: The Definitive Guide》- O'Reilly出版
- 《Kafka Streams in Action》- Manning出版
- 《Prometheus: Up & Running》- O'Reilly出版
-
技术博客
- Confluent Blog - Kafka创始团队的技术博客
- DZone Kafka Zone - 丰富的Kafka文章资源
- Medium Kafka Tag - 社区分享的实践经验
-
论文与研究
- "Kafka: a Distributed Messaging System for Log Processing" - LinkedIn技术论文
- "Monitoring Distributed Systems" - Google SRE Handbook章节
-
社区资源
- Kafka Summit - 会议录像和演讲资料
- Stack Overflow Kafka Tag - 常见问题解答
最后的建议
构建Kafka监控体系是一个持续改进的过程,不是一蹴而就的任务。以下是一些实用建议:
-
从小做起,逐步完善
- 先监控最关键的指标和系统
- 基于实际问题和需求不断扩展
- 重视反馈,持续优化告警规则
-
结合业务上下文
- 监控不仅是技术指标,更应关注业务影响
- 与业务团队密切合作,了解关键业务流程
- 将技术指标与业务KPI关联
-
重视自动化和标准化
- 监控配置应代码化,便于版本控制和复制
- 建立标准模板,减少重复工作
- 投资自动化工具,降低运维成本
-
知识沉淀与分享
- 记录问题与解决方案,建立知识库
- 定期回顾和分析历史告警数据
- 分享经验,培养团队监控文化
Kafka作为现代数据架构的核心组件,其健康运行对业务至关重要。一个完善的监控体系不仅是技术团队的盾牌,更是业务发展的助推器。希望本文能够为你构建自己的Kafka监控体系提供有价值的参考和启发。
监控的终极目标不是收集更多数据,而是提供更多洞察;不是发出更多告警,而是解决更多问题;不是应对更多故障,而是预防潜在风险。通过不断实践和完善,你的Kafka监控体系将成为保障业务稳定和推动技术进步的重要力量。