数据建模:从规范到分析的设计哲学
在数据管理领域,数据建模是确保信息系统有效性的基石。两种主流建模方法------ER模型 与维度模型------代表了不同的设计哲学和应用场景。本文将系统性地探讨这两种模型的核心概念、原理及应用场景,为数据架构决策提供理论依据和实践指导。
目录
[1. ER模型的概念](#1. ER模型的概念)
[2. ER模型的对象关系](#2. ER模型的对象关系)
[3. ER模型的函数依赖与范式](#3. ER模型的函数依赖与范式)
[4. ER模型的三大范式](#4. ER模型的三大范式)
[5. 维度模型的概念及理解](#5. 维度模型的概念及理解)
[6. 为什么数据仓库建模选择维度模型而不是ER模型?](#6. 为什么数据仓库建模选择维度模型而不是ER模型?)
1. ER模型的概念
-
专业解释 :实体-关系模型是一种用于描述现实世界概念结构的数据模型。它通过实体、属性和实体间的联系来抽象和表示业务中的数据及其关系,是数据库逻辑设计的核心工具,最终可转换为关系数据库中的表结构。
-
通俗理解 :就像建筑师的"房屋结构蓝图"。它不关心房间刷什么颜色的漆(具体数据值),只精确界定有多少个房间(实体)、每个房间的用途和尺寸(属性)、以及房间之间如何连通(关系)。其核心目标是消除数据冗余,保证数据一致性。
-
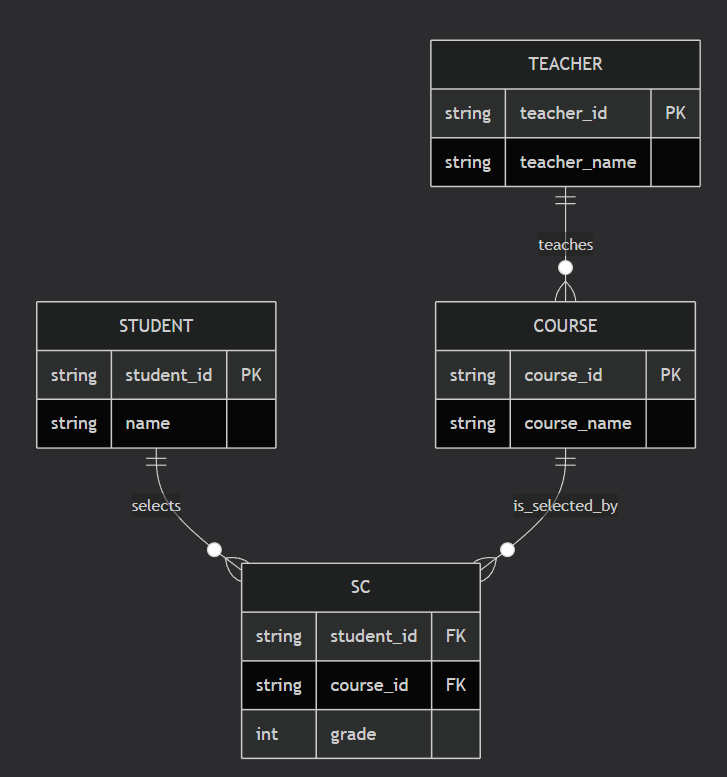
实际举例:为一个简单的"学生选课系统"建模。
-
实体 :
学生、课程、教师 -
属性 :
学生有学号、姓名;课程有课程号、课程名;教师有工号、姓名。 -
联系 :
学生选修课程(多对多),并产生"成绩"属性;教师讲授课程(一对多)。
-
2. ER模型的对象关系
-
专业解释 :ER模型中主要包含三类对象:实体 、属性 和联系。
-
实体:客观存在并可相互区分的事物,对应数据库中的表。
-
属性:实体所具有的某一特征,对应表中的列。
-
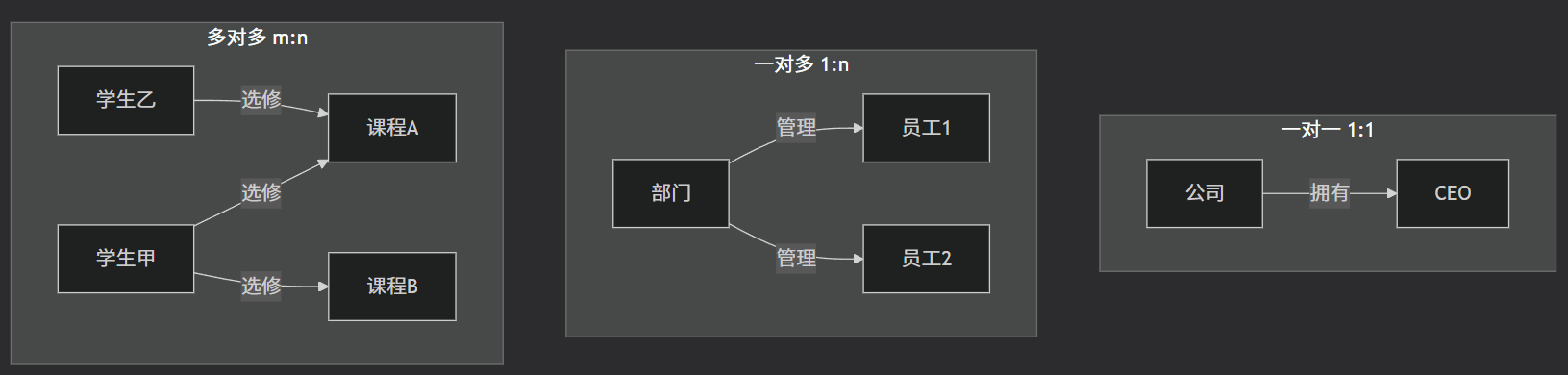
联系:实体与实体之间的关联,分为一对一、一对多、多对多三种类型。
-
-
通俗理解:可以把ER模型看作一个"人际关系网络图"。
-
实体 = 人(如:张三、李四)。
-
属性 = 人的特征(如:身高、职业、电话号码)。
-
联系 = 人与人之间的关系(如:张三 是 李四的"上司"1对1;一个部门经理 管理 多个员工1对多;一个学生 选修 多门课程,一门课程 被 多个学生选修多对多)。
-
-
关系类型图示:
3. ER模型的函数依赖与范式
函数依赖是理解数据规范化的关键,它描述了一个属性或属性集对另一个属性或属性集的决定关系。
| 依赖类型 | 专业定义 | 通俗比喻 | 举例(表:选课(学号, 课程号, 姓名, 课程名, 成绩)) |
|---|---|---|---|
| 完全函数依赖 | 设X、Y是属性集,若Y依赖于X(X→Y),且对于X的任何真子集X',Y都不依赖于X',则称Y完全依赖于X。 | 必须靠完整的钥匙才能开门。少一把都不行。 | (学号, 课程号) → 成绩。仅知道学号或仅知道课程号,都无法确定唯一成绩。 |
| 部分函数依赖 | 若Y依赖于X,但Y不完全依赖于X(即存在X的真子集X'使得X'→Y),则称Y部分依赖于X。 | 用一把大钥匙串中的某一小钥匙就能开门。 | (学号, 课程号) → 姓名。因为学号 → 姓名成立,姓名只依赖于学号,与课程号无关。这是数据冗余的根源。 |
| 传递函数依赖 | 在关系R中,若X→Y,Y→Z,且Y不依赖于X,Z不依赖于Y,则称Z传递依赖于X。 | A认识B,B认识C,那么A间接认识C。 | 在学生(学号, 所属系, 系主任)中,学号→所属系,所属系→系主任,则系主任传递依赖于学号。 |
4. ER模型的三大范式
范式是数据库设计的一系列规范,旨在减少数据冗余和操作异常。
-
第一范式 :属性不可再分。确保每列都是原子值。
-
违规示例 :
联系人列值为"张三,13800138000",包含了姓名和电话。 -
解决 :拆分为
联系人姓名和联系人电话两列。
-
-
第二范式 :满足1NF,且消除非主属性对主键的
部分函数依赖。-
场景 :
选课表(学号[PK], 课程号[PK], 姓名, 课程名, 成绩)。姓名部分依赖于主键(仅依赖于学号)。 -
解决 :拆表!拆成
学生表(学号[PK], 姓名)和选课成绩表(学号[PK], 课程号[PK], 成绩)。课程名也类似处理。
-
-
第三范式 :满足2NF,且消除非主属性对主键的
传递函数依赖。-
场景 :
学生表(学号[PK], 所属系, 系主任)。存在学号→所属系→系主任的传递依赖。 -
解决 :继续拆!拆成
学生表(学号[PK], 所属系)和院系表(系名[PK], 系主任)。
-
范式化过程就是一个"拆表"的过程,目的是使数据模型结构清晰、冗余极低、更新高效。
5. 维度模型的概念及理解
-
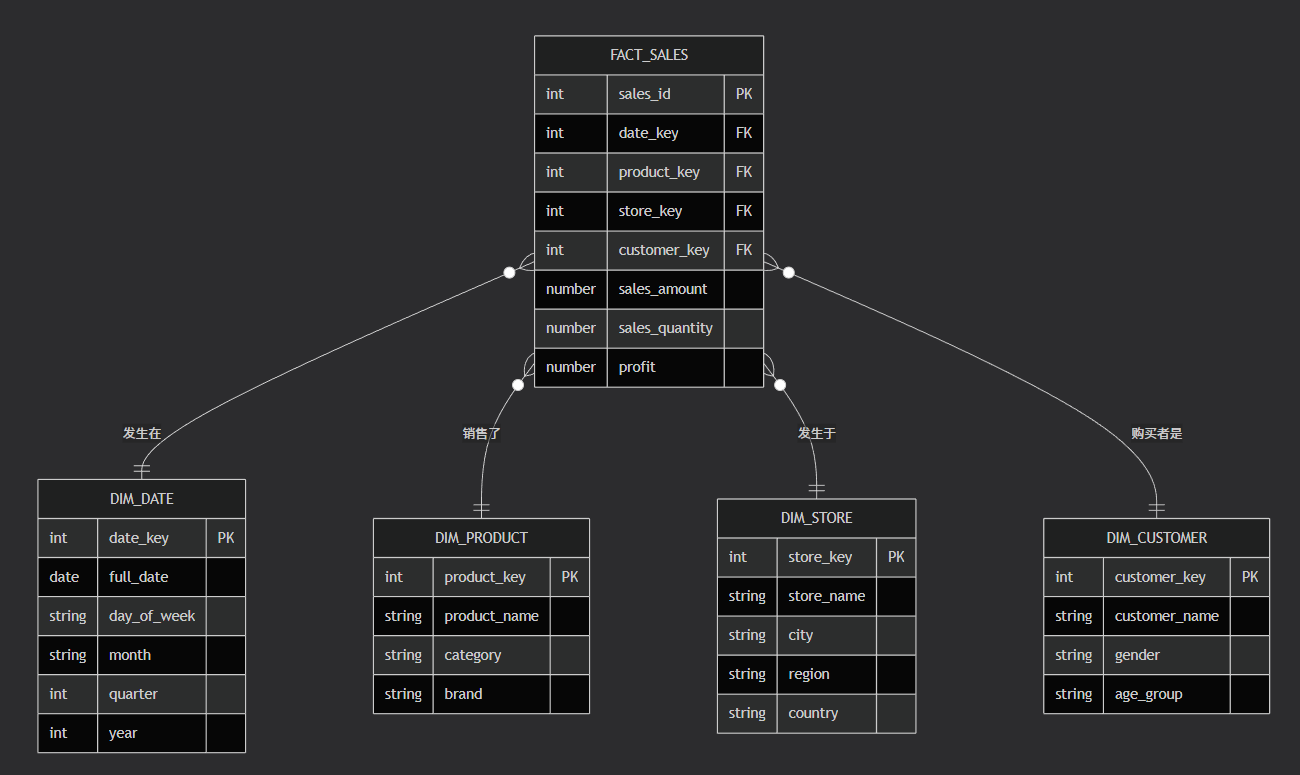
专业解释 :维度模型是一种面向分析场景的数据库设计技术,专为快速、直观的查询和数据聚合 而优化。它由事实表 和维度表组成,形成星型或雪花型架构。事实表存储业务过程的度量值,维度表提供描述事实的上下文。
-
通俗理解:就像一份"商业报告"或"Excel数据透视表"。
-
事实表 = 报告中的数字指标(如:销售额、销售量、利润)。
-
维度表 = 用来筛选和分组 这些数字的角度(如:按时间年/月/日、按产品类别/名称、按地区国家/城市、按客户类型)。
-
核心思想是:用空间换时间,用冗余换清晰。
-
-
实际举例:一个零售公司的销售分析模型。
-
事实表 :
销售事实表。包含:销售金额、销售成本、销售数量等度量值,以及链接到各个维度表的外键(如时间键、产品键、商店键、客户键)。 -
维度表 :
时间维度表、产品维度表、商店维度表、客户维度表。
-
6. 为什么数据仓库建模选择维度模型而不是ER模型?
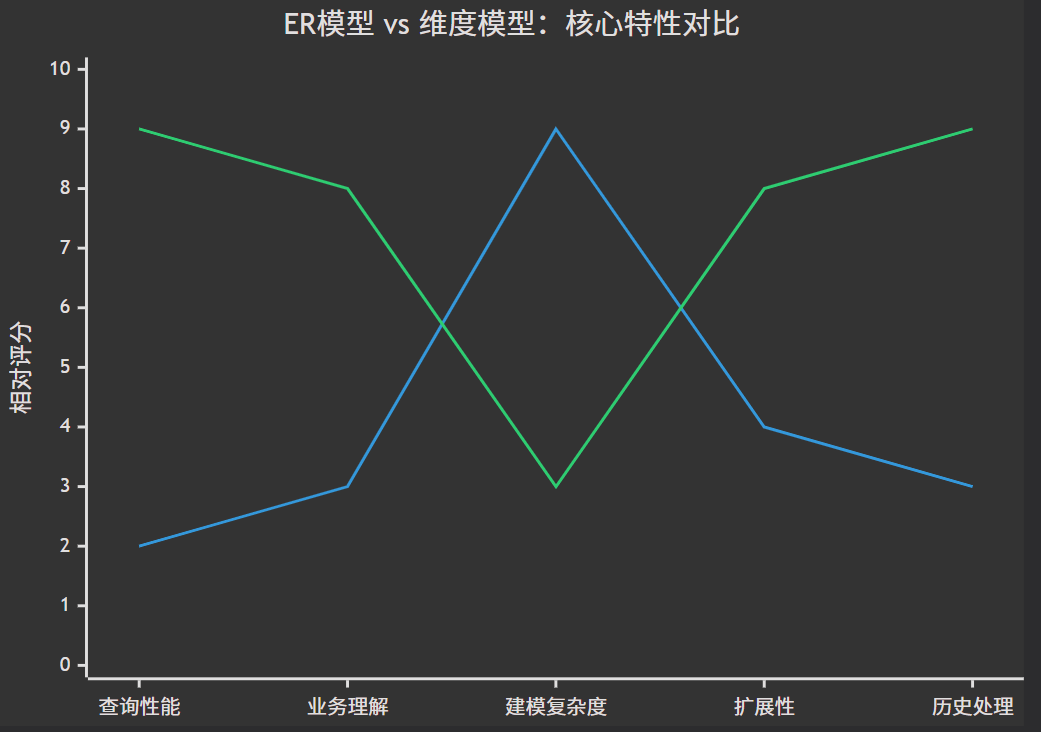
这是数据仓库设计的核心抉择,原因根植于两者不同的设计目标。
| 对比维度 | ER模型 (用于OLTP事务处理) | 维度模型 (用于OLAP分析处理) | 对数据仓库的意义 |
|---|---|---|---|
| 设计目标 | 高并发事务处理,保证数据一致性、完整性、无冗余。 | 高速复杂查询与聚合分析,提升查询性能与用户可理解性。 | 数据仓库核心需求是分析性能 和业务可读性,而非事务处理。 |
| 数据结构 | 高度规范化,表数量多,关系复杂(像蜘蛛网)。 | 反规范化,结构简单(星型/雪花型),关系清晰。 | 简化查询。分析时通常需要多表关联,星型模型关联路径短且固定,性能远优于复杂的ER关联。 |
| 数据冗余 | 极低,节省存储空间。 | 较高,维度表存在有意冗余(如年月日都在时间维度)。 |
用空间换时间。存储成本低,计算成本高。冗余避免了大量的表连接,极大加速了查询。 |
| 可理解性 | 需要对业务和数据结构有很深理解,对业务用户不友好。 | 直观映射业务流程,业务用户能轻松理解"事实"和"分析维度"。 | 便于自助分析。让业务人员能直接基于维度模型构建报表和进行数据透视,降低使用门槛。 |
| 查询模式 | 针对少量记录的精确增、删、改、查。 | 针对海量历史数据的扫描、过滤、分组和聚合。 | 数据仓库的查询几乎都是读密集型的聚合分析,维度模型为此量身定制。 |
总结 :数据仓库选择维度模型,本质上是为了分析性能和应用敏捷性而进行的战略性反规范化。它牺牲了一定的存储空间和数据冗余,换来了查询速度的极大提升和业务逻辑的极度清晰,完美契合了数据仓库支持决策分析的根本目的。而ER模型作为源头业务系统的设计典范,则是维度模型高质量数据的重要来源。在实际的大数据体系中,二者相辅相成,共同构成从操作数据到分析数据的完整链路。