前言
物联网、工业互联网和金融科技发展得越来越快,时序数据也跟着迎来了爆发式增长。作为海量时序数据存储、分析和决策支持的核心工具,时序数据库早就成了数字经济时代离不开的关键支撑。现在,国产化替代的浪潮席卷各行各业,数据库作为信息技术的"底座",自主可控、安全可靠这两点变得越来越重要。中电科金仓自己研发的KingbaseES(KES)时序数据库(KES_TSDB),在技术架构、性能优化、生态兼容这些方面不断突破,在国产化替代的进程中成功实现了技术突围,给金融、制造、能源、电信等关键行业,提供了成熟又好用的落地实践方案。

一、时序数据库国产化替代的行业背景与核心诉求
1.1 市场格局与替代紧迫性
根据行业数据统计,2024年全球时序数据库市场规模已经达到3.88亿美元,亚马逊AWS、InfluxData、Oracle TimesTen这些国外产品占了大部分市场份额。在金融、电信这些关键领域,国外时序数据库长期处于主导地位,背后藏着数据安全风险和技术"卡脖子"的隐患。随着信创政策越推越深,时序数据库的国产化替代已经从"可选项"变成了"必选项",核心需求主要集中在自主可控、性能适配、生态兼容这三个方面。
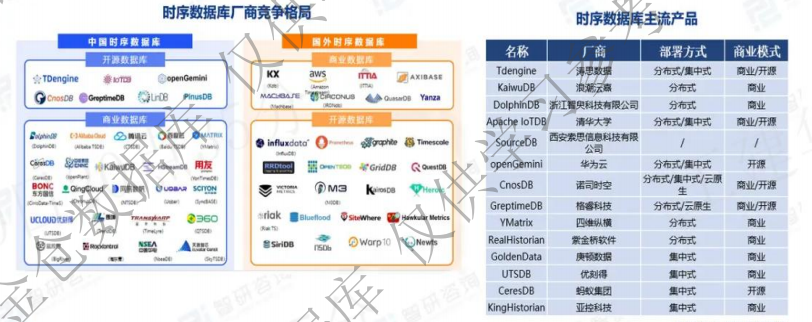
国内时序数据库市场是"开源和商业并行"的竞争格局,开源产品有TDengine、openGemini这些,商业产品则包括KingbaseES、KaiwuDB等。中电科金仓作为国产商业数据库的核心代表企业,一直坚持做商业软件自主研发,不涉及开源业务。和国外产品比起来,国产商业时序数据库在本地化服务响应、行业场景深度适配、政策合规性保障这些方面有天然优势,但在性能极限突破、多协议兼容支持、跨平台迁移适配这些技术指标上,还得继续努力精进。
1.2 关键行业替代核心需求
不同行业的时序数据场景差别很大,但对国产化时序数据库的核心需求却有共性:
- 金融行业:得能扛住每秒百万级的交易数据写入,满足合规监控、风险管理的实时查询需求,还得保障事务一致性和数据安全性;
- 工业制造:要兼容多种工业协议,能实现设备传感器数据的高并发采集和长期存储,给预测性维护提供历史趋势分析支持;
- 能源行业:要处理海量的能耗监测数据,支持冷热数据分级存储来控制成本,同时还要保证跨区域数据查询能高效响应;
- 电信行业:得实现网络性能指标的实时监控和异常检测,支持千万级终端设备的并发数据上报。
二、KingbaseES时序数据库的技术突围:核心能力构建
KingbaseES时序数据库基于中电科金仓自主研发的内核架构,精准对准国产化替代场景的核心痛点,打造出了"高性能、高兼容、高可靠"的技术体系,核心突破点主要在以下五个方面:
2.1 全场景数据迁移兼容:降低替代门槛
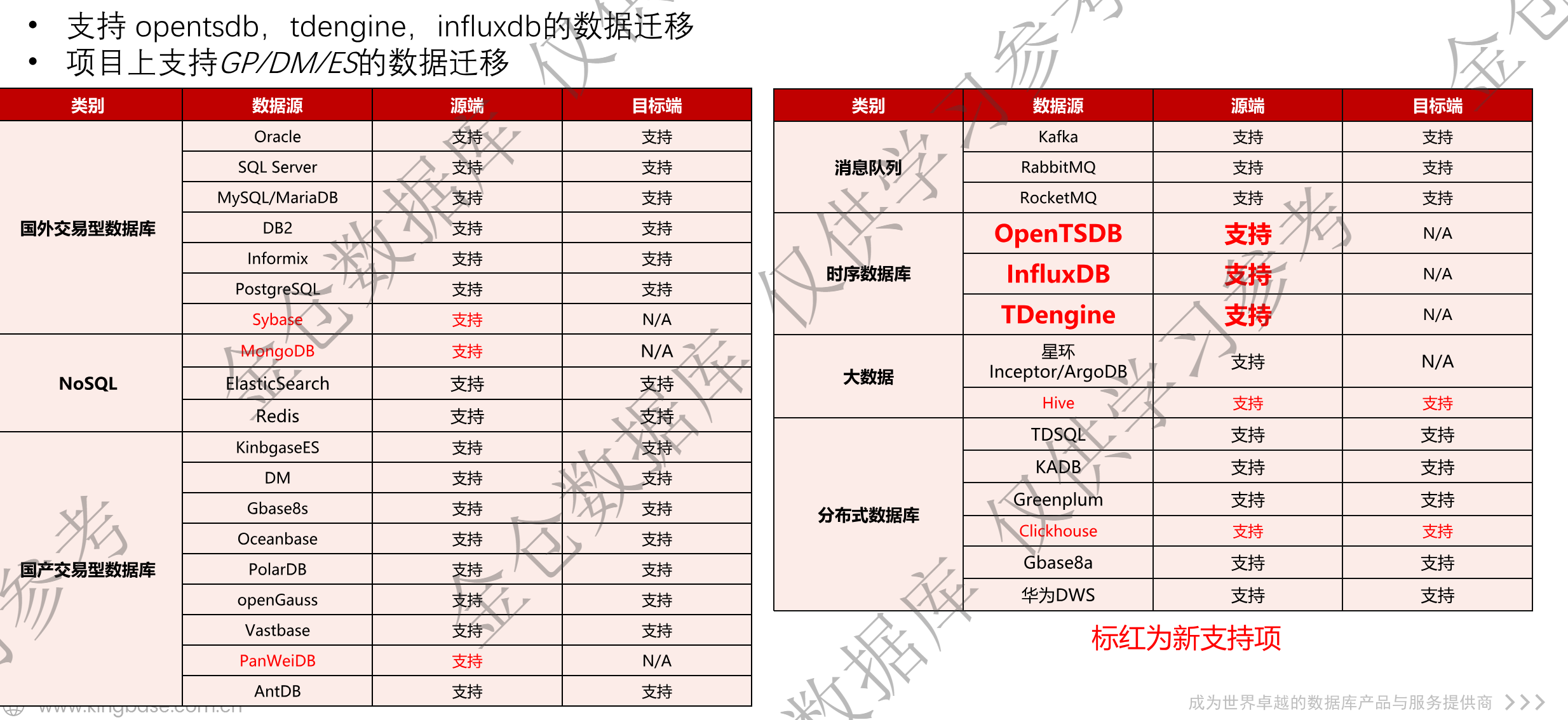
国产化替代过程中,最麻烦的就是存量系统的数据迁移和平滑过渡。KES_TSDB全面支持国内外主流数据库、时序数据库以及大数据平台的迁移,不管是Oracle、SQL Server、MySQL这些国外交易型数据库,KingbaseES、DM、openGauss这些国产数据库,还是InfluxDB、TDengine、OpenTSDB这些时序数据库,都能轻松对接,形成了完整的迁移生态,让用户体验"零感知"迁移。
迁移能力核心特性:
- 支持结构化数据、时序数据、消息队列数据的跨源迁移,包括Kafka、RabbitMQ这些消息中间件的数据接入;
- 提供增量迁移和断点续传机制,能保障迁移过程中业务不中断,避免数据丢失或不一致;
- 针对时序数据时间戳的特性优化了迁移算法,支持时间随机乱序的历史数据高效导入,能适配复杂的存量数据场景。
典型迁移代码示例(InfluxDB数据迁移至KES_TSDB):
python
from kingbase_tsdb import KES_TSDB_Client
from influxdb import InfluxDBClient
import logging
# 配置日志输出
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 初始化客户端(实际使用时替换为真实连接信息)
influx_client = InfluxDBClient(
host='192.168.1.100',
port=8086,
database='industrial_data',
timeout=30
)
kes_client = KES_TSDB_Client(
host='192.168.1.200',
port=54321,
database='kes_industrial',
user='sysdba',
password='kingbase',
pool_size=10 # 连接池优化
)
try:
# 分页查询InfluxDB数据(避免一次性加载过多数据)
start_time = '2024-01-01T00:00:00Z'
end_time = '2024-01-02T00:00:00Z'
batch_interval = '1h' # 按小时分批查询
current_time = start_time
total_migrated = 0
while current_time < end_time:
next_time = (pd.to_datetime(current_time) + pd.Timedelta(hours=1)).strftime('%Y-%m-%dT%H:%M:%SZ')
query = f'''SELECT * FROM sensor_data WHERE time >= '{current_time}' AND time < '{next_time}' '''
result = influx_client.query(query)
points = list(result.get_points())
if not points:
current_time = next_time
continue
# 数据格式转换
kes_points = []
for point in points:
kes_point = {
'measurement': 'sensor_data',
'tags': {'device_id': point.get('device_id', ''), 'location': point.get('location', '')},
'time': point['time'],
'fields': {
'temperature': point.get('temperature', 0.0),
'pressure': point.get('pressure', 0.0)
}
}
kes_points.append(kes_point)
# 批量写入KES_TSDB,失败自动重试
retry_count = 3
while retry_count > 0:
try:
kes_client.write_points(kes_points, batch_size=3600)
batch_count = len(kes_points)
total_migrated += batch_count
logging.info(f"迁移时段 {current_time} - {next_time}:成功迁移{batch_count}条数据")
break
except Exception as e:
retry_count -= 1
logging.error(f"写入失败,剩余重试次数{retry_count}:{str(e)}")
time.sleep(2)
current_time = next_time
logging.info(f"迁移完成!累计迁移{total_migrated}条时序数据至KES_TSDB")
except Exception as e:
logging.error(f"迁移过程异常终止:{str(e)}")
finally:
influx_client.close()
kes_client.close()多源数据库迁移适配代码示例:
python
def migrate_from_different_sources(source_type, config):
"""
多源数据库迁移统一入口
:param source_type: 源数据库类型(oracle/mysql/influxdb/tdengine)
:param config: 连接配置字典
:return: 迁移成功条数
"""
kes_client = KES_TSDB_Client(
host=config['kes_host'],
port=config['kes_port'],
database=config['kes_db'],
user=config['kes_user'],
password=config['kes_pwd']
)
total = 0
try:
if source_type == 'oracle':
# Oracle数据库迁移逻辑
import cx_Oracle
conn = cx_Oracle.connect(f"{config['user']}/{config['pwd']}@{config['host']}:{config['port']}/{config['sid']}")
cursor = conn.cursor()
cursor.execute("SELECT device_id, collect_time, value FROM sensor_table WHERE collect_time BETWEEN :start AND :end",
start=config['start_time'], end=config['end_time'])
batch_data = []
for row in cursor:
batch_data.append({
'measurement': 'oracle_sensor',
'tags': {'device_id': row[0]},
'time': row[1],
'fields': {'value': row[2]}
})
if len(batch_data) >= 1000:
kes_client.write_points(batch_data)
total += len(batch_data)
batch_data.clear()
if batch_data:
kes_client.write_points(batch_data)
total += len(batch_data)
elif source_type == 'tdengine':
# TDengine数据库迁移逻辑
from taos import connect
conn = connect(host=config['host'], port=config['port'], user=config['user'], password=config['pwd'], database=config['db'])
cursor = conn.cursor()
cursor.execute(f"SELECT device_id, ts, temperature FROM meters WHERE ts >= '{config['start_time']}'")
batch_data = []
for row in cursor.fetchall():
batch_data.append({
'measurement': 'tdengine_meters',
'tags': {'device_id': row[0]},
'time': row[1],
'fields': {'temperature': row[2]}
})
if len(batch_data) >= 3600:
kes_client.write_points(batch_data)
total += len(batch_data)
batch_data.clear()
print(f"{source_type}数据库迁移完成,共迁移{total}条数据")
return total
except Exception as e:
print(f"{source_type}迁移失败:{str(e)}")
return 0
finally:
kes_client.close()
# 调用示例
config = {
'kes_host': '192.168.1.200',
'kes_port': 54321,
'kes_db': 'kes_industrial',
'kes_user': 'sysdba',
'kes_pwd': 'kingbase',
'host': '192.168.1.101',
'port': 6030,
'user': 'root',
'pwd': 'taosdata',
'db': 'industrial',
'start_time': '2024-01-01 00:00:00',
'end_time': '2024-01-02 00:00:00'
}
# 从TDengine迁移
migrate_from_different_sources('tdengine', config)2.2 高性能架构设计:突破时序处理瓶颈
时序数据"高写入、高查询、大容量"的特点,对数据库性能提出了极高要求。KES_TSDB通过优化分布式架构、革新存储引擎、升级查询算法,实现了核心性能指标的跨越式突破:
(1) 高并发写入优化
- 支持预定义子表和集群并行插入机制,解决了多节点分区阻塞的问题,让写入性能能跟着节点数量一起线性提升;
- 深度优化了批量写入策略,在64核CPU、512G内存的服务器配置下,当workers设为24、batch-size设为36000时,写入性能能达到1274万metrics/秒,应对超大规模时序数据采集完全没问题;
- 创新实现了数据压缩状态下的直接更新,更新性能比传统方案提升50%,很适合时序数据补录、修正这类业务场景。
(2) 高效查询引擎
- 支持基于时间窗口的聚合查询、时空联合查询,还有关系数据和时序数据的混合关联查询,各种复杂的业务分析场景都能适配;
- 针对超大规模数据集优化了查询路径,5节点集群处理100亿条船舶定位数据时,按年查询的响应时间能达到毫秒级,比行业平均水平高出不少;
- 内置了45种分析函数和10种时序函数,统计分析、趋势计算、异常识别这些核心需求都能覆盖到。
(3)时序数据复杂查询示例:
sql
-- 1. 时间窗口聚合查询(按10分钟粒度统计设备平均温度)
SELECT
device_id,
TIME_BUCKET('10m', collect_time) AS time_slot,
AVG(temperature) AS avg_temp,
MAX(pressure) AS max_pressure,
COUNT(*) AS data_count
FROM sensor_measurements
WHERE collect_time BETWEEN '2024-01-01 00:00:00' AND '2024-01-01 23:59:59'
GROUP BY device_id, time_slot
ORDER BY device_id, time_slot;
-- 2. 时空联合查询(查询指定区域内设备的异常数据)
SELECT
sm.device_id,
sm.collect_time,
sm.temperature,
sm.pressure,
gps.location
FROM sensor_measurements sm
JOIN device_gps gps ON sm.device_id = gps.device_id
WHERE
sm.collect_time >= CURRENT_TIMESTAMP - INTERVAL '1h'
AND ST_DWithin(gps.location, ST_SetSRID(ST_MakePoint(116.403874, 39.914885), 4326), 1000) -- 1公里范围内
AND sm.temperature > 80; -- 温度异常阈值
-- 3. 多表关联分析(结合设备档案与运维记录进行故障根因分析)
SELECT
sm.device_id,
d.model,
d.manufacturer,
COUNT(DISTINCT CASE WHEN sm.temperature > 80 THEN sm.collect_time::DATE END) AS abnormal_days,
MAX(m.maintain_time) AS last_maintain_time
FROM sensor_measurements sm
JOIN device_info d ON sm.device_id = d.device_id
LEFT JOIN maintain_records m ON sm.device_id = m.device_id
WHERE sm.collect_time BETWEEN '2024-01-01' AND '2024-01-31'
GROUP BY sm.device_id, d.model, d.manufacturer
HAVING COUNT(DISTINCT CASE WHEN sm.temperature > 80 THEN sm.collect_time::DATE END) >= 3; -- 连续3天异常2.3 冷热数据智能分级存储
通过表空间自动管理机制,能智能识别热数据(近期经常访问的数据)和冷数据(历史上很少访问的数据),把热数据存到高性能存储介质上保证查询效率,冷数据则迁移到低成本存储里降低运维成本。再加上5:1~10:1的自适应压缩比优化,整体存储成本能降低60%以上。
冷热数据分离配置示例:
sql
-- 创建热数据与冷数据存储表空间(指定存储介质类型)
CREATE TABLESPACE ts_hot
LOCATION '/data/kes/hot'
WITH (storage_type = 'ssd'); -- 热数据存储在SSD
CREATE TABLESPACE ts_cold
LOCATION '/data/kes/cold'
WITH (storage_type = 'hdd', compression_level = 'high'); -- 冷数据存储在HDD并启用高压缩
-- 创建时序表并配置冷热数据生命周期管理
CREATE TABLE sensor_measurements (
device_id TEXT,
collect_time TIMESTAMPTZ,
temperature NUMERIC,
pressure NUMERIC,
humidity NUMERIC,
PRIMARY KEY (device_id, collect_time)
) PARTITION BY RANGE (collect_time)
WITH (
timeseries_cold_move_policy = '90 days', -- 数据超过90天自动迁移至冷存储
timeseries_expire_policy = '365 days', -- 数据超过1年自动清理
hot_tablespace = 'ts_hot',
cold_tablespace = 'ts_cold',
compression_type = 'auto' -- 自动选择最优压缩算法
);
-- 创建索引优化查询性能
CREATE INDEX idx_sensor_device_time ON sensor_measurements (device_id, collect_time DESC);
CREATE INDEX idx_sensor_temp_abnormal ON sensor_measurements (temperature) WHERE temperature > 80;2.4 工业级协议兼容:适配垂直行业场景
工业制造、能源电力这些行业的时序数据采集,得依赖各种各样的工业协议。KES_TSDB内置了全面的工业化接口支持,覆盖OPC-UA、Modbus TCP/RTU、MQTT、Telegraf这些主流协议,能直接对接传感器、工业控制器、物联网终端这些设备,不用额外部署适配中间件,大大降低了系统架构的复杂度和运维成本。
2.4.1 工业协议接入架构:

2.4.2 工业协议数据采集代码示例(Modbus TCP协议):
python
from pymodbus.client import ModbusTcpClient
from kingbase_tsdb import KES_TSDB_Client
import time
import datetime
# 初始化KES_TSDB客户端
kes_client = KES_TSDB_Client(
host='192.168.1.200',
port=54321,
database='industrial_db',
user='sysdba',
password='kingbase'
)
def collect_modbus_data(device_ip, device_id, start_addr, count, interval=5):
"""
从Modbus TCP设备采集数据并写入KES_TSDB
:param device_ip: 设备IP地址
:param device_id: 设备标识
:param start_addr: 寄存器起始地址
:param count: 采集寄存器数量
:param interval: 采集间隔(秒)
"""
client = ModbusTcpClient(device_ip, port=502, timeout=3)
try:
while True:
try:
# 连接Modbus设备并读取数据
if not client.connected:
client.connect()
# 读取保持寄存器(根据设备类型调整读取函数)
response = client.read_holding_registers(
address=start_addr,
count=count,
slave=1 # 从站地址
)
if not response.isError():
# 解析数据(示例:温度、压力、湿度)
data = {
'temperature': response.registers[0] / 10.0, # 假设温度精度为0.1℃
'pressure': response.registers[1] / 100.0, # 假设压力精度为0.01MPa
'humidity': response.registers[2] / 10.0 # 假设湿度精度为0.1%RH
}
# 构造时序数据点
ts_point = {
'measurement': 'modbus_sensor',
'tags': {'device_id': device_id, 'device_ip': device_ip},
'time': datetime.datetime.utcnow().isoformat() + 'Z',
'fields': data
}
# 写入KES_TSDB
kes_client.write_points([ts_point])
print(f"[{datetime.datetime.now()}] 设备{device_id}数据采集成功:{data}")
time.sleep(interval)
except Exception as e:
print(f"数据采集异常:{str(e)}")
time.sleep(10) # 异常时延长重试间隔
finally:
client.close()
kes_client.close()
# 启动多设备采集(可通过多线程扩展)
if __name__ == "__main__":
import threading
# 设备配置列表
devices = [
{'ip': '192.168.1.101', 'id': 'sensor_001', 'start_addr': 0, 'count': 3},
{'ip': '192.168.1.102', 'id': 'sensor_002', 'start_addr': 0, 'count': 3},
{'ip': '192.168.1.103', 'id': 'sensor_003', 'start_addr': 0, 'count': 3}
]
# 启动采集线程
for dev in devices:
t = threading.Thread(
target=collect_modbus_data,
args=(dev['ip'], dev['id'], dev['start_addr'], dev['count'], 5)
)
t.daemon = True
t.start()
# 主线程保持运行
while True:
time.sleep(3600)2.5 分布式与高可用保障:支撑核心业务稳定
针对关键行业7×24小时不间断的业务需求,KES_TSDB搭建了多层次的高可用保障体系:
- 支持Sharding分片集群部署,能实现数据容量和处理性能的线性伸缩,满足千万级监控指标的长期管理需求;
- 提供完善的集群监控运维工具(Kemcc),支持单机、RWC以及Sharding集群的统一监控、告警和运维操作,降低了集群管理的复杂度;
- 支持集群整体备份恢复和故障自动切换,数据可靠性能达到99.999%,能保障核心业务一直运行。
Sharding集群部署配置示例:
sql
-- 1. 创建Sharding集群节点组
CREATE SHARDING GROUP kg_group1 (
node1:54321, -- 节点1
node2:54321, -- 节点2
node3:54321 -- 节点3
);
-- 2. 创建分片表空间(分布在不同节点)
CREATE TABLESPACE shard_ts1 ON kg_group1.node1 LOCATION '/data/kes/shard1';
CREATE TABLESPACE shard_ts2 ON kg_group1.node2 LOCATION '/data/kes/shard2';
CREATE TABLESPACE shard_ts3 ON kg_group1.node3 LOCATION '/data/kes/shard3';
-- 3. 创建时序分片表(按设备ID哈希分片)
CREATE TABLE sensor_sharding (
device_id TEXT,
collect_time TIMESTAMPTZ,
temperature NUMERIC,
pressure NUMERIC,
PRIMARY KEY (device_id, collect_time)
) PARTITION BY RANGE (collect_time)
SHARDED BY HASH (device_id) INTO 3 SHARDS -- 按设备ID哈希分为3个分片
WITH (
shard_tablespaces = ['shard_ts1', 'shard_ts2', 'shard_ts3'],
timeseries_cold_move_policy = '90 days',
high_availability = 'on' -- 启用高可用模式
);
-- 4. 配置集群备份策略
ALTER SHARDING GROUP kg_group1
SET BACKUP POLICY (
backup_type = 'incremental', -- 增量备份
backup_interval = '24h', -- 备份间隔24小时
retention_period = '7d', -- 备份保留7天
backup_path = '/backup/kes/sharding'
);
-- 5. 配置故障自动切换
ALTER SHARDING GROUP kg_group1
SET FAILOVER POLICY (
detect_interval = '10s', -- 故障检测间隔10秒
failover_timeout = '60s', -- 故障切换超时60秒
standby_nodes = ['node4:54321', 'node5:54321'] -- 备用节点
);2.6 生态协同能力:融入国产化技术栈
KES_TSDB深度适配国产化软硬件生态,全面支持统信UOS、麒麟这些主流国产操作系统,兼容x86和国产芯片架构,能和Hadoop、Spark这些大数据平台无缝对接,和国产中间件、应用系统形成协同联动。同时,它全面支持SQL标准接口,降低了应用系统迁移改造的难度,实现了"即插即用"的国产化替代体验,让用户的信创改造进程更快。
与大数据平台集成示例(Spark对接KES_TSDB):
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_unixtime
# 创建SparkSession(适配国产化大数据平台)
spark = SparkSession.builder \
.appName("KES_TSDB_Spark_Integration") \
.config("spark.jars", "/path/to/kingbase-jdbc.jar") \
.config("spark.sql.adaptive.enabled", "true") \
.getOrCreate()
# 1. 从KES_TSDB读取时序数据
kes_url = "jdbc:kingbase8://192.168.1.200:54321/industrial_db"
kes_properties = {
"user": "sysdba",
"password": "kingbase",
"driver": "com.kingbase8.Driver"
}
# 读取传感器数据(按时间范围过滤)
sensor_df = spark.read \
.jdbc(url=kes_url,
table="(SELECT device_id, collect_time, temperature, pressure FROM sensor_measurements WHERE collect_time >= '2024-01-01') AS ts_data",
properties=kes_properties)
# 数据预处理
sensor_df = sensor_df \
.withColumn("collect_date", from_unixtime(col("collect_time").cast("long") / 1000, "yyyy-MM-dd")) \
.filter(col("temperature") > 0) # 过滤无效数据
# 2. 时序数据分析(统计每日设备平均温度)
daily_avg_df = sensor_df.groupBy("device_id", "collect_date") \
.agg(
col("temperature").avg().alias("avg_temp"),
col("temperature").max().alias("max_temp"),
col("pressure").avg().alias("avg_pressure")
) \
.orderBy("device_id", "collect_date")
daily_avg_df.show(20, truncate=False)
# 3. 分析结果写回KES_TSDB
daily_avg_df.write \
.jdbc(url=kes_url,
table="sensor_daily_analysis",
mode="append",
properties=kes_properties)
# 4. 保存分析结果到国产对象存储(示例:兼容S3协议的国产存储)
daily_avg_df.write \
.format("parquet") \
.option("path", "s3a://kes-tsdb-analysis/daily_avg/202401/") \
.option("fs.s3a.access.key", "your_access_key") \
.option("fs.s3a.secret.key", "your_secret_key") \
.option("fs.s3a.endpoint", "http://国产存储地址:8080") \
.save()
spark.stop()三、关键行业落地实践:国产化替代的标杆案例
3.1 海洋观测监测系统国产化替代项目
项目背景:
有个海洋观测监测系统要做信创升级改造,得支撑12-15万艘船舶的定位数据采集和分析,日峰值写入量能达到3000万条,3年下来要存储300亿条定位数据。原来的系统用的是Intel芯片+Redhat操作系统+5节点GP数据库架构,扩展能力不够、国产化适配性差,查询响应还慢,根本满足不了业务增长的需求。
解决方案:
采用"x86+统信UOS操作系统+3节点KES Sharding集群"架构,核心设计有这几点:
- 用Sharding分片技术实现数据分布式存储,5节点(32VCPU/64G)的配置能支持1.5亿条/天的1KB数据写入,应对业务峰值完全没问题;
- 借助冷热数据分离和自适应压缩技术,历史数据压缩比能达到8:1,300亿条数据的存储成本直接降低了75%;
- 通过时序索引优化和查询路径规划,跨5节点100亿行数据的按年查询,响应时间能做到毫秒级,给海洋灾害预警快速决策提供了支撑。
实施效果:
- 写入性能比原来的GP数据库提升了3倍,查询响应速度快了10倍,完全满足海洋观测监测的实时性要求;
- 支持灵活横向扩展,想加节点就能加,能应对数据量增长,适配未来的业务扩展;
- 100%满足信创国产化要求,硬件、操作系统、数据库全栈都能自主可控,数据安全可控性明显提升。
3.2 工业制造预测性维护场景应用
项目需求:
一家汽车零部件制造厂要监控2000台生产设备的运行状态,采集振动、温度等10类指标,实现设备故障预测和维护决策。要求每秒能写入10万条数据,历史数据查询延迟不能超过500ms,还得兼容现有的工业控制协议,和生产系统无缝对接。
解决方案:
- 用KES_TSDB单机部署方案,通过Modbus TCP协议直接采集设备传感器数据,不用额外装适配网关,降低了系统复杂度;
- 利用时序聚合查询和内置的分析函数,实时计算设备运行指标趋势,识别异常特征,给故障预测模型训练提供支持;
- 配置了冷热数据分离策略,热数据保留3个月保证查询效率,冷数据压缩存储,整体存储成本降低了70%。
实施效果:
- 设备故障预警准确率达到了92%,计划性维护比例提高了,设备停机时间减少40%,维护成本降低30%;
- 单机写入性能稳定在15万条/秒,比业务需求高不少,查询延迟控制在300ms以内,满足实时监控的要求;
- 完全替代了原来的InfluxDB,迁移过程没什么感知,国产化适配率100%,还通过了信创合规认证。
四、时序数据库国产化替代的未来展望与研发规划
4.1 行业技术发展趋势
现在,时序数据库技术有三个核心发展方向:一是分布式存储和内存计算深度融合,用来应对PB级的时序数据处理需求;二是预测分析和AI能力一体化集成,实现时序数据的智能洞察和主动决策,据Gartner预测,到2025年,超过60%的企业都会用预测分析来指导业务决策;三是云边协同架构越来越普及,满足边缘设备数据就地处理的需求,麦肯锡研究显示,到2025年,全球超过50%的数据都会在边缘设备上处理。
4.2 KingbaseES时序数据库三年规划
为了持续巩固国产化替代的优势,中电科金仓给KES_TSDB制定了明确的研发路线图,重点放在核心技术突破和行业场景深化上:
- 2026年:让产品界面更好用,完成和Hadoop等大数据生态的深度对接,通过信通院时序数据库标准测试,让压缩比能和行业标杆产品持平;
- 2027年:支持云边协同架构(按项目驱动),新增采集点安全控制功能,集成时序分析模型,强化异常检测和趋势分析能力,适配边缘计算场景;
- 2028年:实现内核级多模数据融合,支持流批一体处理,打造成熟的产品生态,成为金融、工业、能源等关键领域国产化替代的首选产品。
五、结语
在国产化替代的浪潮里,中电科金仓KingbaseES时序数据库靠自主创新作为核心驱动力,凭着全场景兼容、高性能架构、工业级适配和完善的生态支持,成功打破了国外产品的市场垄断,给关键行业提供了安全可靠、高效好用的国产化解决方案。从海洋观测到工业制造,从金融交易到电信监控,KES_TSDB的落地实践,充分证明了国产商业时序数据库的技术实力和应用价值。
未来,中电科金仓会继续深耕时序数据库技术研发,深化行业场景适配,提升核心竞争力,帮更多企业实现时序数据管理的自主可控,给数字经济高质量发展筑牢数据库底座,推动国产数据库产业再上一个新台阶。