Dinky+Flink SQL达梦数据库实时同步到Doris简单实现
- 组件版本
- 环境搭建
- [Flink lib包准备](#Flink lib包准备)
- Dinky配置
- FinkSQL实现拉链表测试
组件版本
1.dinky版本:dinky-release-1.19-1.2.2
2.flink版本:flink-1.19.2
3.flink cdc版本:flink cdc 3.3.0
4.hadoop版本:hadoop-3.4.1
5.doris版本:doris-4.0.2-rc02
6.dm数据库版本:03134284458-20251113-301923-20178
PS:dm数据库DM8 2023年3季度及以后的版本,版本号不小于8.1.3.77。使用SELECT BUILD_VERSION FROM V$INSTANCE;或SELECT * FROM V$VERSION;查看版本号
环境搭建
达梦数据库安装和配置
安装
请看官网:https://eco.dameng.com/document/dm/zh-cn/start/install-dm-windows-prepare.html
配置
1.开启归档模式(具体看官网)
目前DBMS_LOGMNR只支持对归档日志进行分析,数据库需开启归档模式。
在你的达梦数据库实例下创建dmarch.ini文件(和dm.ini同级)
达梦数据库的本地归档配置:
https://eco.dameng.com/community/article/6597be7c8dd922d3c20da198e345f31a
powershell
[ARCHIVE_LOCAL1]
ARCH_TYPE = LOCAL
## 这儿是你归档的路径,自定义
ARCH_DEST = /data/dm8/dmdata/arch
ARCH_FILE_SIZE = 1024
ARCH_SPACE_LIMIT = 2048修改dm.ini
powershell
#configuration file
ARCH_INI=1 #dmarch.inin2.开启物理逻辑日志
物理逻辑日志是按照特定格式存储服务器逻辑操作,开启后DBMS_LOGMNR才能挖掘数据库系统的历史执行语句。需将dm.ini中参数RLOG_APPEND_LOGIC设置为1或2(如果使用Flink SQL,并且使用Flink SQL适配的connector-jdbc进行入库,则需要将RLOG_APPEND_LOGIC设置为2)。LOGMNR_PARSE_LOB设置为1,表示允许LOGMNR包解析行外大字段逻辑日志。
powershell
#redo log
RLOG_APPEND_LOGIC = 2 #Type of logic records in redo logs
LOGMNR_PARSE_LOB = 1 #Whether to parse LOB logic log using DBMS_LOGMNR, 0: FALSE, 1: TRUEDoris安装
其他安装
略
Flink lib包准备
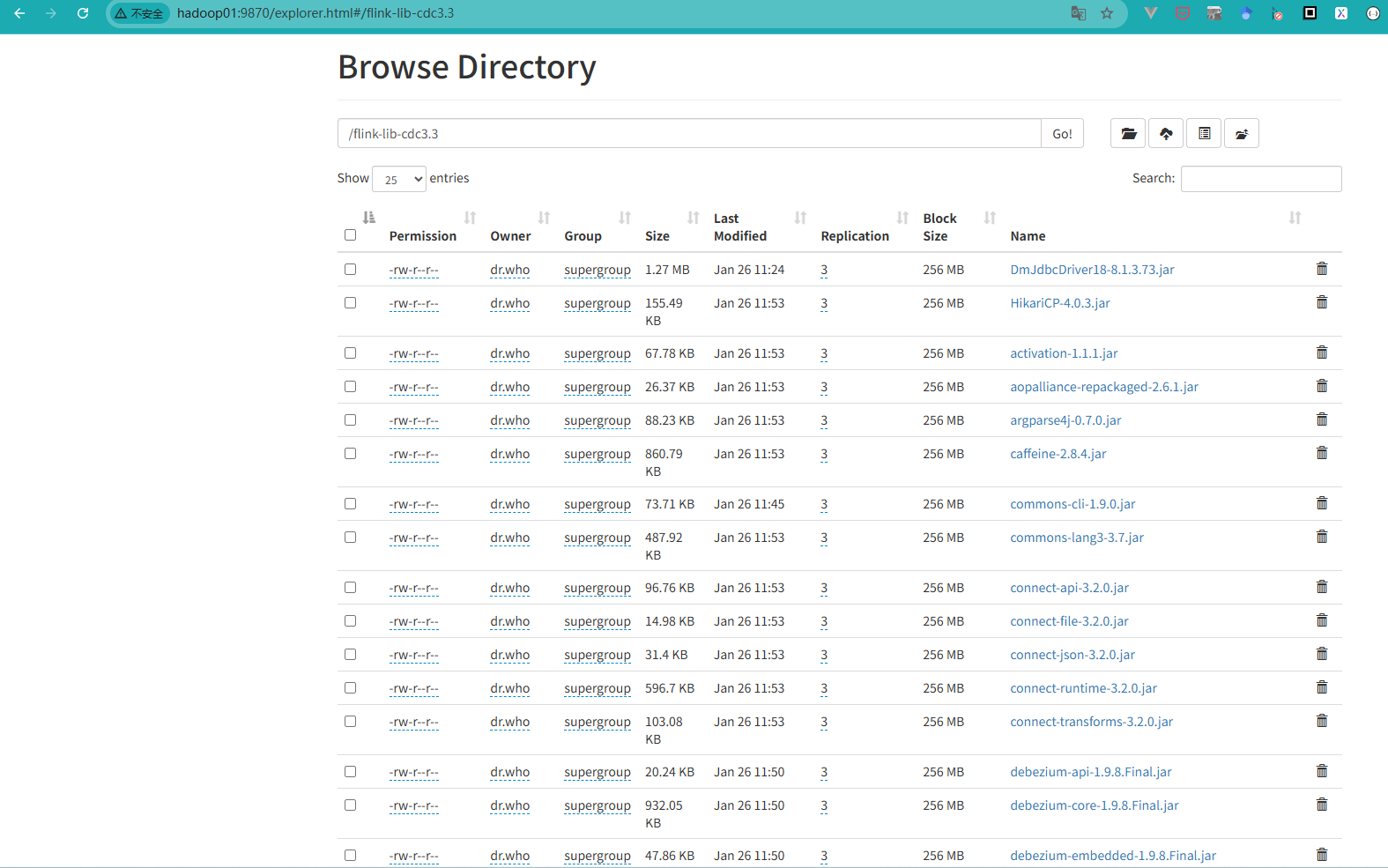
进入你的hdfs,比如我这儿的是:http://hadoop01:9870/explorer.html#/
创建目录: /flink-lib-cdc3.3
把你的flink cdc 3.3.0相关的包和达梦连接器上传到这个目录下。
如图所示。
Dinky配置
打开并登录dinky
http://dinky01:8888/#/datastudio
在注册中心添加集群
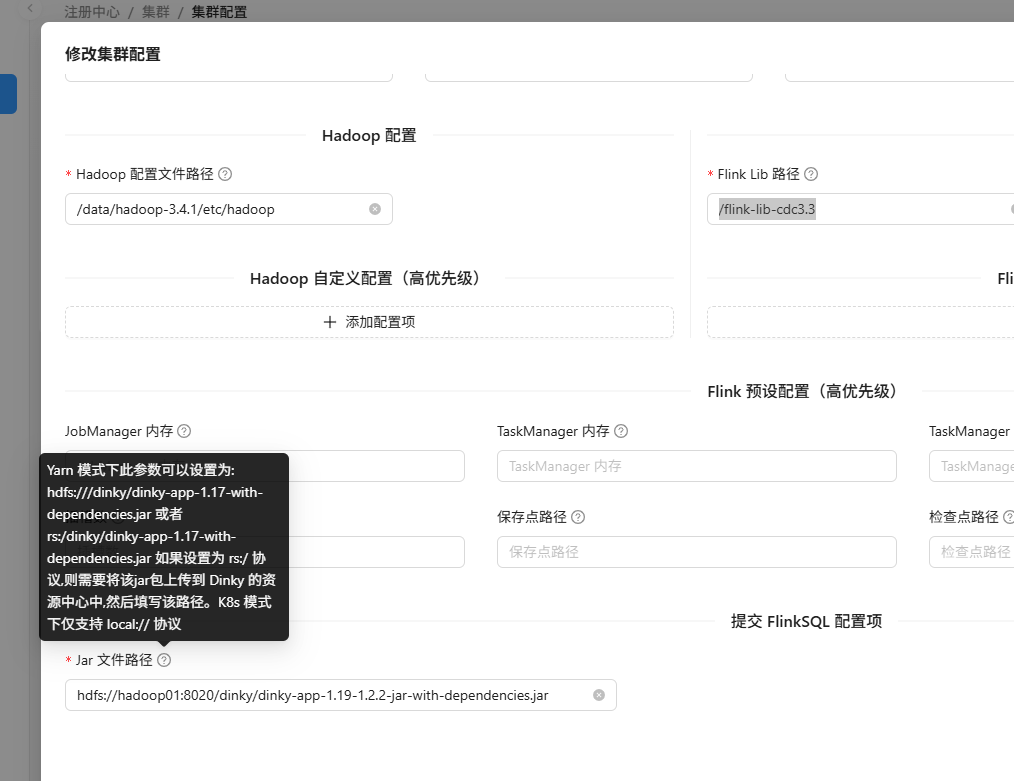
在这儿填写Fink Lib路径为刚刚在hdfs中创建好的路径 /flink-lib-cdc3.3

注意FinkSQL配置项
FinkSQL实现拉链表测试
达梦数据库表
原表
sql
CREATE TABLE "test"."dm_cdc_table"
(
"cid" INT NOT NULL,
"sid" INT,
"cls" VARCHAR(50),
"score" INT,
NOT CLUSTER PRIMARY KEY("cid")) STORAGE(ON "MAIN", CLUSTERBTR);Doris表
sql
CREATE TABLE `dm_cdc_test_son_sink` (
`cls` varchar(255) NOT NULL,
`dw_end_time` varchar(255) NOT NULL,
`is_current` BOOLEAN ,
`id` varchar(255) NOT NULL,
`score` int NULL,
`update_time` varchar(255) NULL,
`dw_start_time` varchar(255) NULL
)
UNIQUE KEY (`cls`, `dw_end_time`, `is_current`)
COMMENT 'test'
DISTRIBUTED BY HASH(`cls`, `dw_end_time`, `is_current`) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);这儿注意,因为是拉链表,使用的是UNIQUE KEY 模式。至于另外两种模式DUPLICATE KEY, AGGREGATE KEY,请自行了解。
FinkSQL
实时统计(有历史记录,拉链表,只有修改数据才会新增数据)
sql
-- 配置参数(原有配置保留)
SET execution.checkpointing.checkpoints-after-tasks-finish.enabled = true;
SET pipeline.operator-chaining = false;
SET state.backend.type = rocksdb;
SET execution.checkpointing.interval = 8000;
SET state.checkpoints.num-retained = 10;
SET cluster.evenly-spread-out-slots = true;
SET execution.time-characteristic = 'ProcessingTime';
-- SET table.exec.timezone = 'Asia/Shanghai';
-- CDC 源表(保持不变)
CREATE TABLE IF NOT EXISTS dm_cdc_table (
cid INT,
sid INT,
cls STRING,
score INT,
PRIMARY KEY (cid) NOT ENFORCED
) WITH (
'connector' = 'dm-cdc',
'hostname' = '192.168.32.133',
'port' = '5237',
'username' = 'SYSDBA',
'password' = 'SYSDBAa123',
'database-name' = 'Dameng',-- 固定
'schema-name' = 'test', -- 模式名称
'table-name' = 'dm_cdc_table',-- 表名称
'scan.startup.mode' = 'initial',
'debezium.database.tablename.case.insensitive' = 'true',
'debezium.lob.enabled' = 'true',
-- 'server-time-zone' = 'UTC',
-- 'scan.incremental.snapshot.enabled' = 'true',
-- 'debezium.snapshot.mode' = 'initial', -- 或者key是scan.startup.mode,initial表示要历史数据,latest-offset表示不要历史数据
-- 'debezium.datetime.format.date' = 'yyyy-MM-dd',
-- 'debezium.datetime.format.time' = 'HH-mm-ss',
-- 'debezium.datetime.format.datetime' = 'yyyy-MM-dd HH-mm-ss',
-- 'debezium.datetime.format.timestamp' = 'yyyy-MM-dd HH-mm-ss',
'debezium.datetime.format.timestamp.zone' = 'UTC+8'
);
-- Sink 表(主键为 (cls, dw_end_time, is_current))
CREATE TABLE IF NOT EXISTS test_son_flink_sink (
cls STRING,
dw_end_time STRING,
is_current BOOLEAN,
id STRING,
score INT,
update_time STRING,
dw_start_time STRING,
PRIMARY KEY (cls, dw_end_time, is_current) NOT ENFORCED
) WITH (
'connector' = 'doris',
'fenodes' = '192.168.21.201:8030',
'username' = 'root',
'password' = '',
'table.identifier' = 'test.dm_cdc_test_son_sink',
-- 注意这儿缓冲区至少10000
'sink.buffer-flush.max-rows' = '10000',
-- 'sink.properties.format' = 'json',
-- 'sink.properties.strip_outer_array' = 'true',
'sink.parallelism' = '2' -- 写入Doris的并行度(根据集群规模调整)
);
-- 执行更新逻辑
INSERT INTO test_son_flink_sink
WITH
-- 计算新记录的 score
newa_score AS (
SELECT
cls,
SUM(score) AS new_score
FROM dm_cdc_table
GROUP BY cls
),
-- 获取当前有效旧记录的字段(包含所有字段)
olda_current AS (
SELECT
cls,
score AS old_score,
dw_start_time,
dw_end_time,
is_current,
id,
update_time
FROM test_son_flink_sink
WHERE is_current = TRUE
),
-- 筛选出需要更新的 cls(score 变化或新 cls)
changed_cls AS (
SELECT
newa.cls,
newa.new_score,
olda.id AS old_id,
olda.old_score,
olda.dw_start_time AS old_dw_start_time,
olda.dw_end_time AS old_dw_end_time,
olda.update_time AS old_update_time
FROM newa_score AS newa
LEFT JOIN olda_current AS olda ON newa.cls = olda.cls
WHERE newa.new_score <> olda.old_score OR olda.cls IS NULL
),
-- 生成新记录(仅当需要变化时)
newa_records AS (
SELECT
cls,
'9999-12-31 23:59:59' AS dw_end_time,
TRUE AS is_current,
UUID() AS id,
new_score AS score,
DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss') AS update_time,
DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss') AS dw_start_time
FROM changed_cls
),
-- 生成失效的旧记录(仅当 score 变化时)
closed_olda_records AS (
SELECT
olda.cls AS cls,
DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss') AS dw_end_time,
FALSE AS is_current,
olda.id AS id,
olda.old_score AS score,
olda.update_time AS update_time,
olda.dw_start_time AS dw_start_time -- 修正:直接引用 olda_current 的 dw_start_time
FROM changed_cls AS changed
JOIN olda_current AS olda ON changed.cls = olda.cls
WHERE changed.new_score <> olda.old_score
)
-- 合并新记录和失效的旧记录
SELECT
cls,
dw_end_time,
is_current,
id,
score,
update_time,
dw_start_time
FROM newa_records
UNION ALL
SELECT
cls,
dw_end_time,
is_current,
id,
score,
update_time,
dw_start_time
FROM closed_olda_records;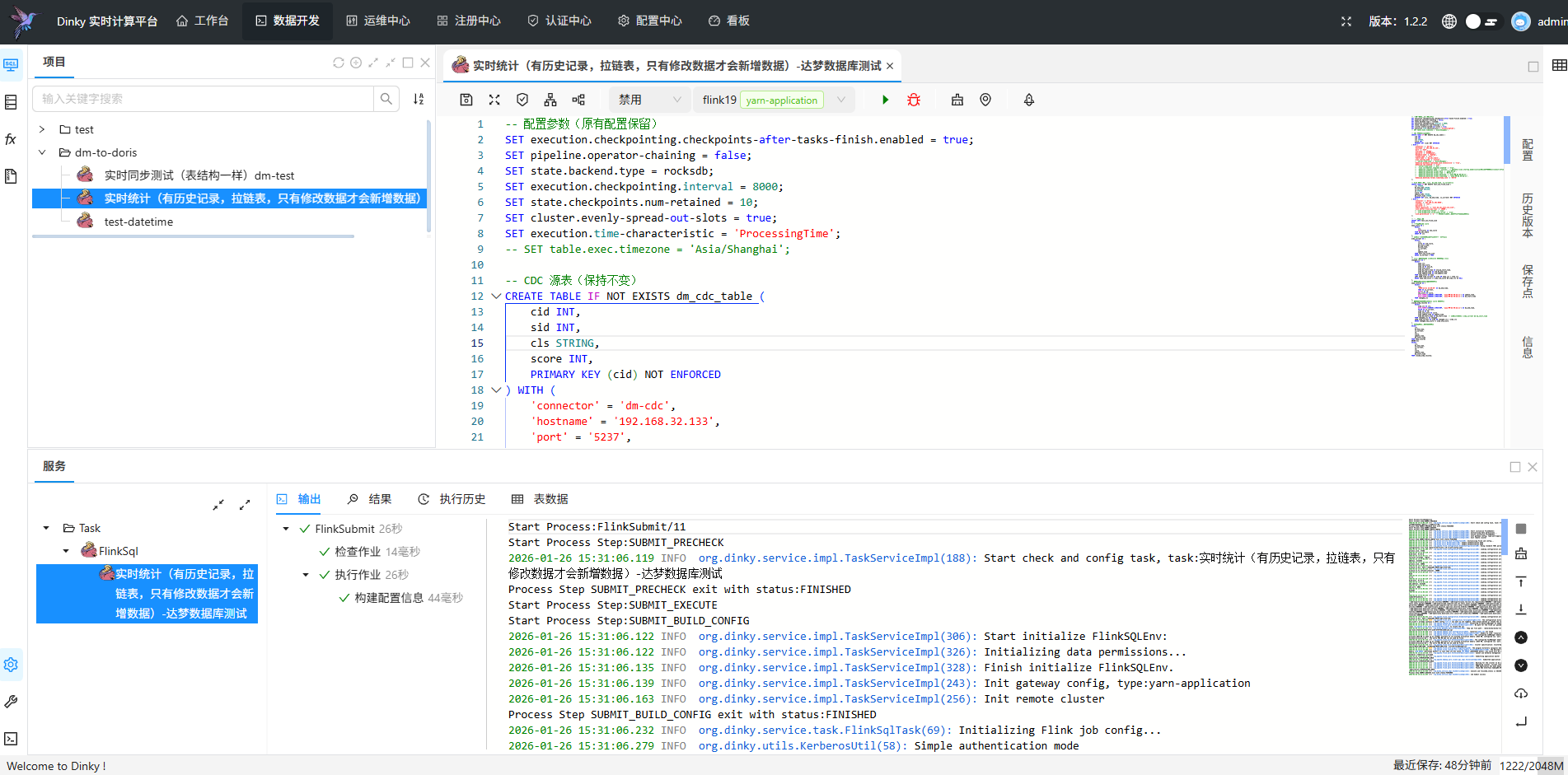
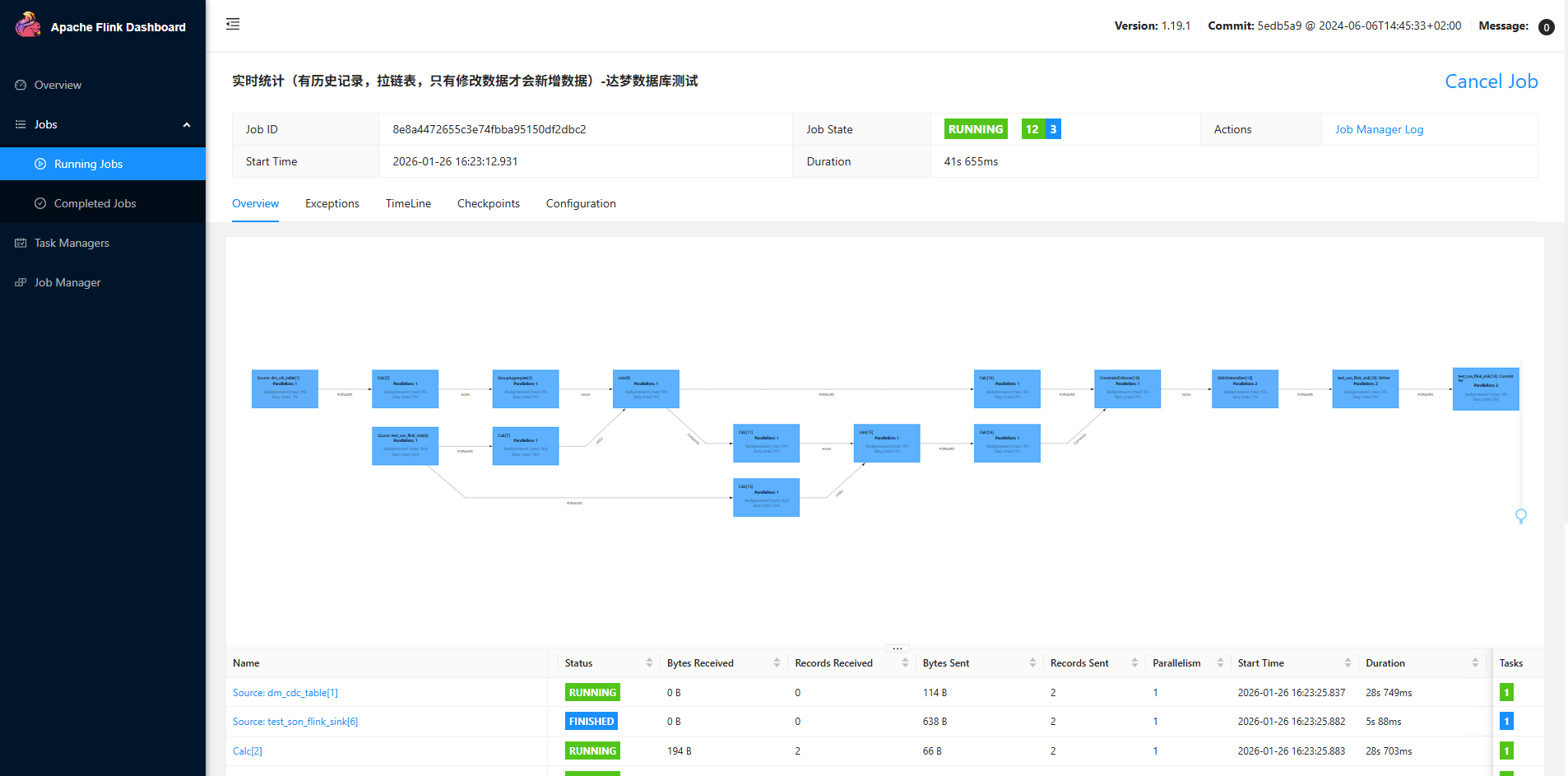
点运行后看状态
访问yarn:http://hadoop03:8088/cluster/apps
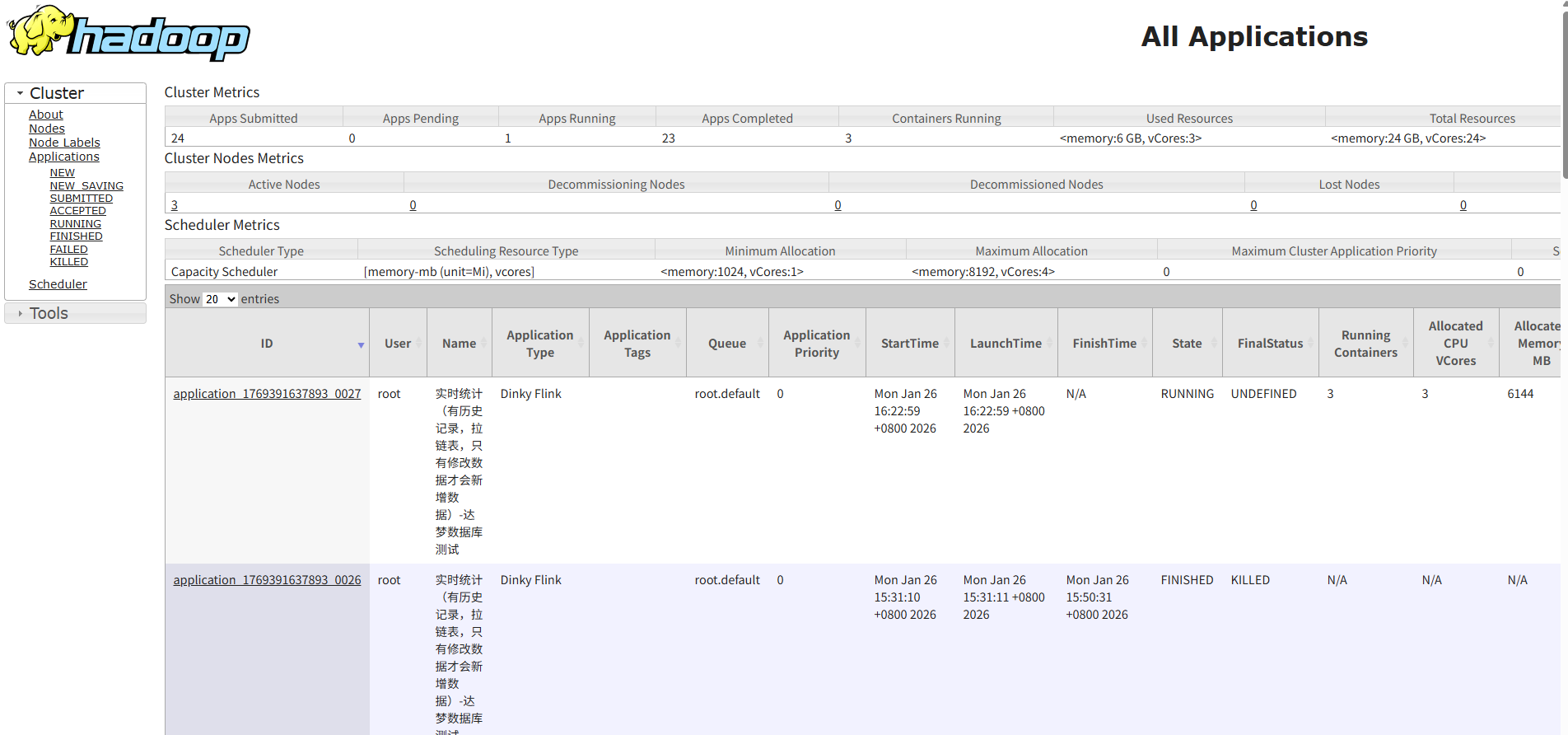
已经在运行了。