我们看一下情况
cpp
#include<iostream>
#include<pthread.h>
#include<vector>
using namespace std;
int a=10000000;
void* fun(void*s){
while(a>0){
--a;
}
return nullptr;
}
int main(){
vector<pthread_t> ids;
for(int x=0;x<10;++x){
pthread_t id;
pthread_create(&id,nullptr,fun,nullptr);
ids.emplace_back(move(id));
}
for(int x=0;x<10;++x){
pthread_join(ids[x],nullptr);
}
cout<<"a:"<<a<<endl;
return 0;
}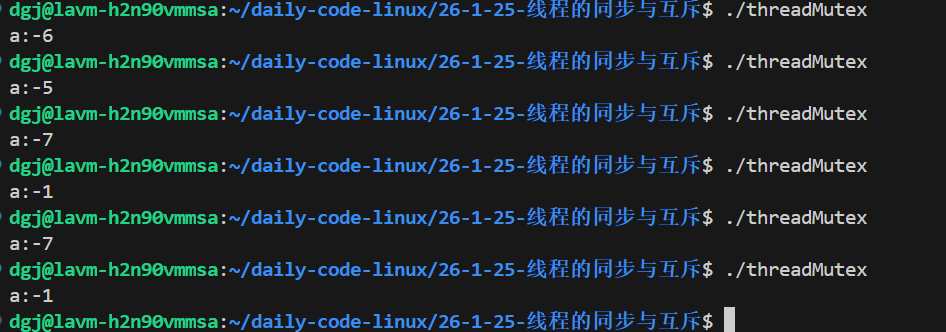
以上原因的出现是a--操作不是一次CPU指令完成的,它要经过CPU拷贝,CPU计算,CPU写回,如果两个线程CPU同时拷贝0进行计算再放回,那么相当于两次--等于-1
线程互斥
进程间互斥相关概念
对于上面的例子 a就是共享资源
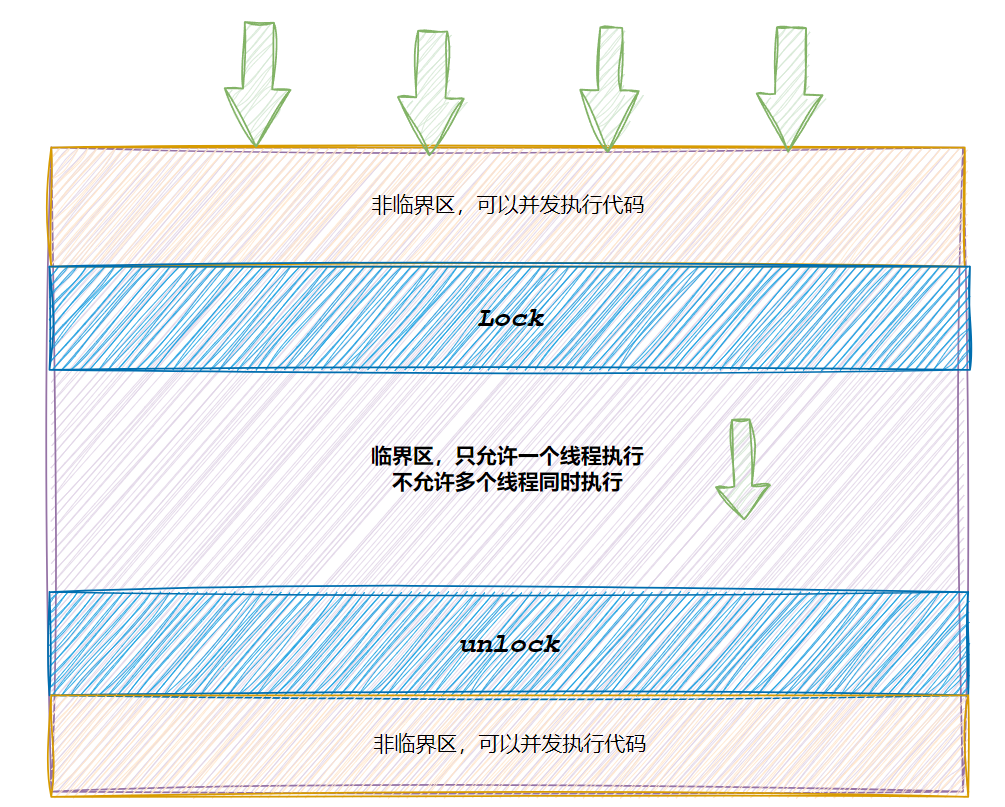
临界资源,就是一次只能由一个线程操作的资源
临界区:每个线程内部,访问临界资源的代码叫临界区
互斥:任何时刻只有一个线程进入临界区操作
原子性:不会被任何调度机制打断的操作,此操作只有两个状态,完成和未开始
互斥量mutex
有些情况如栈内创建的局部变量,是线程独有的,不会有线程安全的问题。
但是还有些情况是需要线程间共享的,这样的变量就是共享变量。多个线程并发使用会导致一系列的问题
对应临界区问题我们可以使用mutex来保证每次只有一个线程进入
初始化互斥量
cpp
//静态分配
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
//动态分配
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const
pthread_mutexattr_t *restrict attr);
//参数:
//mutex:要初始化的互斥量
//attr:NULL销毁互斥量
使用 PTHREAD_ MUTEX_ INITIALIZER 初始化的互斥量不需要销毁
不要销毁一个已经加锁的互厅量
已经销毁的互厅量,要确保后面不会有线程再尝试加锁
cpp
int pthread_mutex_destroy(pthread_mutex_t *mutex);互斥量加锁和解锁
cpp
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:成功返回0,失败返回错误号调用pthread_ lock时,可能会遇到以下情况:
互斥量处于未锁状态,该函数会将互斥量锁定,同时返回成功
发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁。
那么我们看一下开头的代码是否可以了:
cpp
#include<iostream>
#include<pthread.h>
#include<vector>
using namespace std;
int a=10000000;
pthread_mutex_t _mutex;
void* fun(void*s){
while(a>0){
pthread_mutex_lock(&_mutex);
--a;
pthread_mutex_unlock(&_mutex);
}
return nullptr;
}
int main(){
pthread_mutex_init(&_mutex,nullptr);
vector<pthread_t> ids;
for(int x=0;x<10;++x){
pthread_t id;
pthread_create(&id,nullptr,fun,nullptr);
ids.emplace_back(move(id));
}
for(int x=0;x<10;++x){
pthread_join(ids[x],nullptr);
}
cout<<"a:"<<a<<endl;
return 0;
}看看结果:
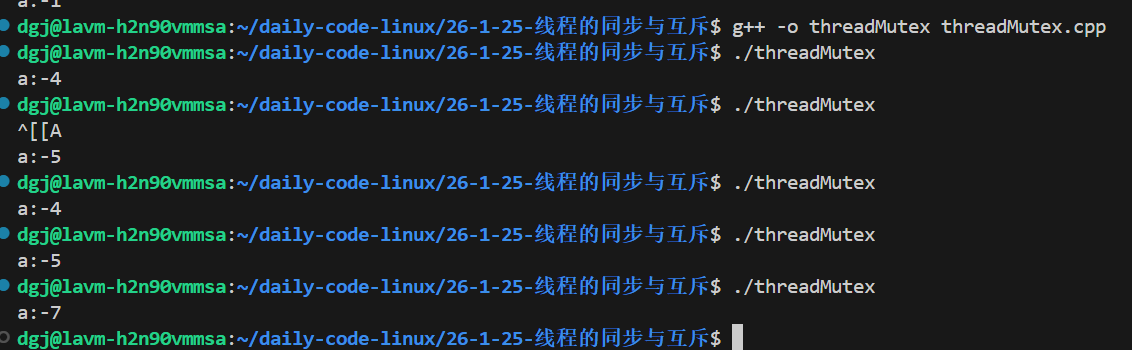
为什么还是有问题?是锁没有用吗?错了,我们的临界区判断错了!在判断a>0的时候,此时可能最后一次a=1已经在计算了,我们如果再进入for循环计算就会导致多计算。因此下面才是正常的
cpp
#include<iostream>
#include<pthread.h>
#include<vector>
using namespace std;
int a=10000000;
pthread_mutex_t _mutex;
void* fun(void*s){
while(true){
pthread_mutex_lock(&_mutex);
if(a>0){
--a;
}
else{
pthread_mutex_unlock(&_mutex);
break;
}
pthread_mutex_unlock(&_mutex);
}
return nullptr;
}
int main(){
pthread_mutex_init(&_mutex,nullptr);
vector<pthread_t> ids;
for(int x=0;x<10;++x){
pthread_t id;
pthread_create(&id,nullptr,fun,nullptr);
ids.emplace_back(move(id));
}
for(int x=0;x<10;++x){
pthread_join(ids[x],nullptr);
}
cout<<"a:"<<a<<endl;
return 0;
}封装mutex
这里我就不细说了,比较简单
cpp
class Mutex
{
public:
// 删除不要的拷⻉和赋值
Mutex(const Mutex &) = delete;
const Mutex &operator=(const Mutex &) = delete;
Mutex()
{
int n = pthread_mutex_init(&_mutex, nullptr);
(void)n;
}
void
Lock()
{
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
void
Unlock()
{
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
pthread_mutex_t *GetMutexOriginal() // 获取原始指针
{
return &_mutex;
}
~Mutex()
{
int n = pthread_mutex_destroy(&_mutex);
(void)n;
}
private:
pthread_mutex_t _mutex;
};
class LockGuard
{
public:
LockGuard(Mutex &mutex) : _mutex(mutex)
{
_mutex.Lock();
}
~LockGuard()
{
_mutex.Unlock();
}
private:
Mutex &_mutex;
};当然C++11已经有了对应的封装了,这里是让大家了解底层的原理和简单的模拟
线程同步
条件变量
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
同步概念与竞态条件
同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步
竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解
条件变量函数
初始化
cpp
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t
*restrict attr);
//参数:
//cond:要初始化的条件变量
//attr:NULL销毁
cpp
int pthread_cond_destroy(pthread_cond_t *cond)等待条件满足
cpp
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict
mutex);
//参数:
//cond:要在这个条件变量上等待
//mutex:互斥量,后⾯详细解释唤醒等待
cpp
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);底层原理
条件变量底层是使用一个队列管理存储休眠的线程Id,那么既然是队列,避免不了是临界区,因此需要锁,而锁哪来?直接外面获取锁即可,条件变量默认执行pthread_cond_wait时,认为此时的锁已经上锁了,然后将线程Id加入到队列,并解除锁(此时阻塞了不需要锁了,让其他线程来持有锁,可以继续调用pthread_cond_wait来进入等待队列),然后自身进入阻塞状态。被唤醒后线程就会竞争锁,因为需要将自己从队列移除,这个操作也要加锁。函数就可以返回了,至于为什么不解锁,是因为有条件变量唤醒线程就是为了操作临界区资源的,后面也肯定跟着临界区,所以没必要解锁,后面代码是要加锁的。
举例
cpp
pthread_mutex_t _mutex;
pthread_cond_t _cond;
#include<string>
void* test(void*str){
string name =to_string(reinterpret_cast<pthread_t>(str));
while(true){
pthread_mutex_lock(&_mutex);
pthread_cond_wait(&_cond,&_mutex);
cout<<"name:"<<name<<" is work"<<endl;
pthread_mutex_unlock(&_mutex);
}
}
int main()
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond,nullptr);
vector<pthread_t> ids;
for (long long x = 0; x < 10; ++x)
{
pthread_t id;
pthread_create(&id, nullptr, test,(void*)x);
ids.emplace_back(move(id));
}
for(int x=0;x<100;++x){
pthread_cond_signal(&_cond);
}
for (int x = 0; x < 10; ++x)
{
pthread_join(ids[x], nullptr);
}
cout << "a:" << a << endl;
return 0;
}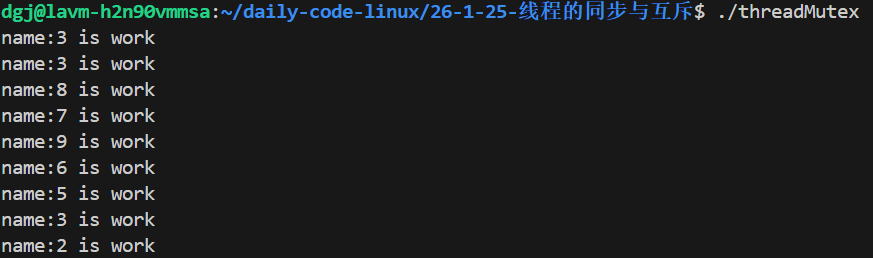
这里最后阻塞了,为什么只成功唤醒了9次?,还有91个呢?我们加个计数器看看唤醒100次没
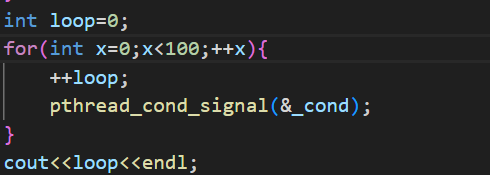
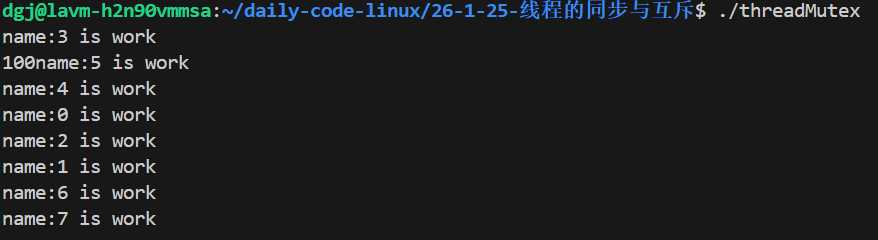
确实唤醒了100次,这里我说原因吧,当线程初始化完,线程开始执行各自的函数,等线程进入死循环时,此时有锁,因此十个线线程竞争一把锁,然后有个竞争到了,就会进入条件变量的等待队列,可能还有线程还在进这个等待队列呢,pthread_cond_signal就执行了,而且这个操作速度非常快,它会直接把等待队列的所有线程唤醒了(因为有100次),然后后续唤醒第n(n<10)次,发现没有线程,就会直接跳过。导致后面唤醒是假的。等后续竞争锁的线程往队列里面加入时,唤醒次数已经用光了,所以只打印了几个。
这里我们还可以这样证明一下,我们加个sleep(1)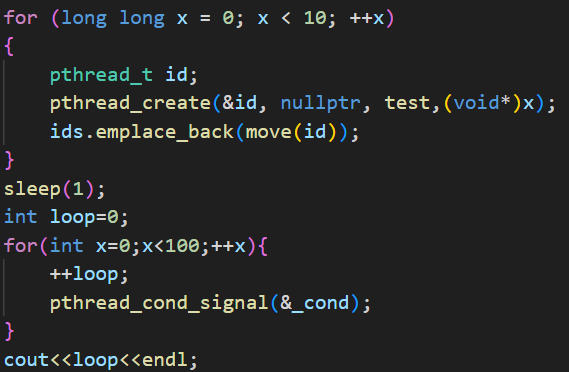
我们可以猜测一下结果,这个sleep(1)就会使所有线程都进入等待队列,然后一次性在100唤醒下全部唤醒,然后执行打印和竞争锁。而打印和竞争锁的速度很慢,所以大概率只会打印十次
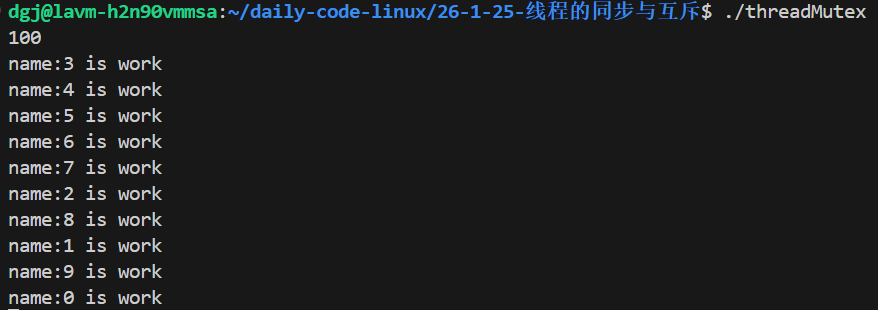
虚假唤醒
我们还得解决上面没有最后让线程退出的情况:
cpp
#include<unistd.h>
#include<atomic>
pthread_mutex_t _mutex;
pthread_cond_t _cond;
size_t num=0;
std::atomic<bool> flat =true;
#include<string>
void* test(void*str){
string name =to_string(reinterpret_cast<pthread_t>(str));
while(true){
pthread_mutex_lock(&_mutex);
if(flat){
pthread_cond_wait(&_cond,&_mutex);
}
if(!flat){
pthread_mutex_unlock(&_mutex);
break;
}
cout<<"name:"<<name<<" is work"<<endl;
++num;
pthread_mutex_unlock(&_mutex);
}
return nullptr;
}
#include<thread>
int main()
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond,nullptr);
vector<pthread_t> ids;
for (long long x = 0; x < 100; ++x)
{
pthread_t id;
pthread_create(&id, nullptr, test,(void*)x);
ids.emplace_back(move(id));
}
int loop=0;
for(int x=0;x<50;++x){
++loop;
pthread_cond_signal(&_cond);
this_thread::sleep_for(chrono::milliseconds(2));
}
cout<<loop<<" "<<num<<endl;
flat=false;
this_thread::sleep_for(chrono::milliseconds(1000));
pthread_cond_broadcast(&_cond);
for (int x = 0; x < 100; ++x)
{
pthread_join(ids[x], nullptr);
}
cout << "a:" << a << endl;
return 0;
}这个代码可以吗?我们使用一个全局变量num,在答应pthread_cond_signal次数的同时,我们也打印num真实执行的次数。
执行此时多时,就会碰巧遇到num>50的情况
这是为什么?
这个原因就是虚假唤醒
定义
虚假唤醒 是指线程从条件变量的等待中(如 pthread_cond_wait())被唤醒,即使没有其他线程显式地发送信号或广播。
为什么会发生虚假唤醒?
1. 性能优化
-
现代操作系统和硬件为了性能,可能允许虚假唤醒
-
在某些多处理器系统上,避免条件变量的精确实现带来的性能开销
-
允许虚假唤醒可以使条件变量的实现更高效
2. 信号处理
-
某些信号可能中断系统调用,导致线程从等待中返回
-
即使信号处理函数没有显式唤醒线程
3. 实现细节
-
POSIX 标准明确允许虚假唤醒
-
Linux 的 futex 实现可能产生虚假唤醒
因此我们需要给pthread_cond_signal加一个while循环的包裹,只有真正有资源任务时才能跳出循环往下走,防止虚假唤醒导致线程跳出if直接往下走。
因为性能的原因,实现真实唤醒的开销比我们加个while循环要大得多
生产者消费者模型
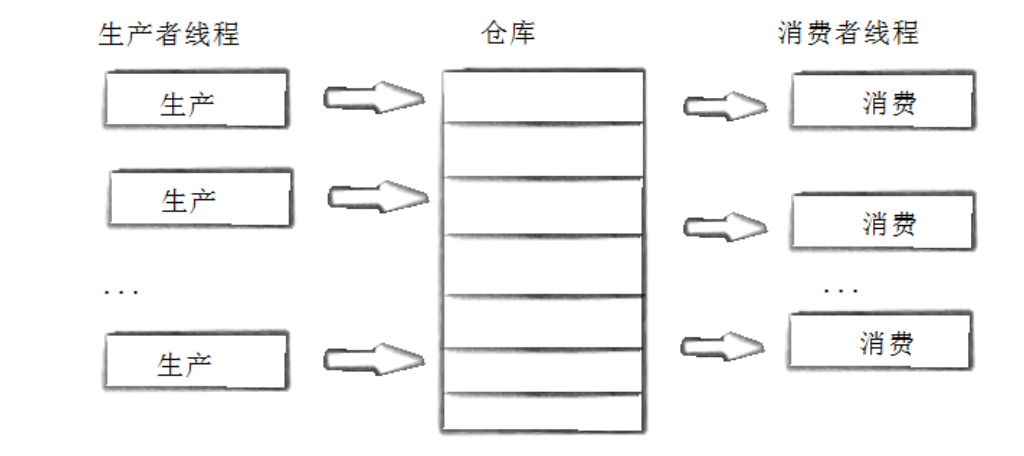
生产者消费者模型就如上图,生产者可能有时生产速度很快,如果直接给消费者,那么就会出现拥堵,如果直接给消费者,这会导致生产者不能继续生产,需要一直等消费者要;而且生产者不知道哪个消费者需要货物,消费者不知道哪个生产者有货物。因此我们需要一个中间仓库,让生产者往仓库放东西,消费者往仓库取东西,这样生产者可以尽可能多的生产,而不是等待消费者取,两者也知道去什么地方放东西和取东西。这个可以将生产者和消费者的操作进行解耦,如果后续增加生产者和消费者,也不许要动相关的代码。
基于阻塞队列式的条件变量实现的生产者消费者模型
用队列作为仓库,push作为生产者操作,pop作为消费者的操作。生产者应该有一个条件变量,消费者也应有个条件变量。当消费者去pop时队列没有东西应该被消费者的条件变量所阻塞,只有当有生产者来的时候使用signal或者boardcast唤醒;当有生产者去push的时候,如果队列满了,应该被生产者的条件变量阻塞,当有消费者来的时候再被生产者使用signal或者boardcast唤醒。具体是用signal还是boardcast,主要看生产者和消费者一下消费几个生产几个,做到匹配。
以下是实现加测试:
cpp
#include <iostream>
#include <pthread.h>
#include <vector>
#include <queue>
#include <random>
#include <time.h>
#include <optional>
#include <thread>
#include <string>
class lockGuard
{
public:
lockGuard(pthread_mutex_t &x) : _mutex(x)
{
pthread_mutex_lock(&_mutex);
}
~lockGuard()
{
pthread_mutex_unlock(&_mutex);
}
private:
pthread_mutex_t &_mutex;
};
template <class T>
class blockQueue
{
public:
blockQueue(size_t size) : _capacity(size)
{
pthread_cond_init(&_productor, nullptr);
pthread_cond_init(&_consumer, nullptr);
pthread_mutex_init(&_mutex, nullptr);
}
~blockQueue(){
pthread_cond_destroy(&_productor);
pthread_cond_destroy(&_consumer);
pthread_mutex_destroy(&_mutex);
}
void push(const T &val)
{
lockGuard k(_mutex);
while (_queue.size() >= _capacity && _isrunning)
{
pthread_cond_wait(&_productor, &_mutex);
}
if (_queue.size() < _capacity && _isrunning)
{
_queue.emplace(val);
pthread_cond_signal(&_consumer);
}
}
T pop()
{
T ret=-1;
lockGuard k(_mutex);
while (_queue.empty() && _isrunning)
{
pthread_cond_wait(&_consumer, &_mutex);
}
if (!_queue.empty() && _isrunning)
{
ret = std::move(_queue.front());
_queue.pop();
pthread_cond_signal(&_productor);
}
return ret;
}
size_t size()
{
lockGuard k(_mutex);
return _queue.size();
}
void stop()
{
lockGuard k(_mutex);
_isrunning = false;
pthread_cond_broadcast(&_consumer);
pthread_cond_broadcast(&_productor);
}
void run()
{
lockGuard k(_mutex);
_isrunning = true;
pthread_cond_broadcast(&_consumer);
pthread_cond_broadcast(&_productor);
}
bool isrunning()
{
lockGuard k(_mutex);
return _isrunning;
}
private:
std::queue<T> _queue;
pthread_cond_t _productor, _consumer;
pthread_mutex_t _mutex;
size_t _capacity;
bool _isrunning = true;
};
pthread_mutex_t print_lock = PTHREAD_MUTEX_INITIALIZER;
void print(const std::string &x)
{
lockGuard k(print_lock);
std::cout << x << std::endl;
}
blockQueue<int> bq(10);
void *Pop(void *)
{
while (bq.isrunning())
{
int a = bq.pop();
std::string buf("获取到");
buf += std::to_string(a);
print(buf);
print(std::to_string(bq.size()));
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
return nullptr;
}
void *Push(void *)
{
while (bq.isrunning())
{
int rad = rand() % 100;
std::string buf("放入");
buf += std::to_string(rad);
print(buf);
bq.push(rad);
print(std::to_string(bq.size()));
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
return nullptr;
}
int main()
{
srand((unsigned int)time(nullptr));
std::vector<pthread_t> threads;
for (int x = 0; x < 5; ++x)
{
pthread_t t;
pthread_create(&t, nullptr, Pop, nullptr);
threads.emplace_back(t);
}
for (int x = 0; x < 5; ++x)
{
pthread_t t;
pthread_create(&t, nullptr, Push, nullptr);
threads.emplace_back(t);
}
std::this_thread::sleep_for(std::chrono::seconds(3));
bq.stop();
for (int x = 0; x < 10; ++x)
{
pthread_join(threads[x], nullptr);
}
return 0;
}信号量
很多条件变量的操作,所满足的条件有部分是和数量有关的,例如生产者消费者模型,它其实本质是因为数量的增加和减少的相关限制。
因此有了信号量,它是纯进行计数,当数量等于0时就会进行阻塞。这里有专门的名词:P V,P表示计数自减1,V表示自增1,且当为0时阻塞。一般不用怕信号量无限增长,因为信号量是和现实资源挂钩的,资源不可能无限
那么我们先自己实现一个:
cpp
#include <iostream>
#include <pthread.h>
#include <vector>
#include <queue>
#include <random>
#include <time.h>
#include <optional>
#include <thread>
#include <string>
using namespace std;
class lockGuard
{
public:
lockGuard(pthread_mutex_t &x) : _mutex(x)
{
pthread_mutex_lock(&_mutex);
}
~lockGuard()
{
pthread_mutex_unlock(&_mutex);
}
lockGuard(const lockGuard&)=delete;
lockGuard(lockGuard&&)=delete;
lockGuard& operator=(const lockGuard&)=delete;
lockGuard& operator=(lockGuard&&)=delete;
private:
pthread_mutex_t &_mutex;
};
class sem{
public:
sem(size_t beginNum=0):_num(beginNum){
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_cond,nullptr);
}
~sem(){
pthread_cond_destroy(&_cond);
pthread_mutex_destroy(&_mutex);
}
void V(){
lockGuard k(_mutex);
++_num;
pthread_cond_signal(&_cond);
}
void P(){
lockGuard k(_mutex);
while(_num<=0){
pthread_cond_wait(&_cond,&_mutex);
}
--_num;
}
private:
pthread_mutex_t _mutex;
pthread_cond_t _cond;
size_t _num=0;
};POSIX信号量
初始化
cpp
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
//参数:
//pshared:0表⽰线程间共享,⾮零表⽰进程间共享
//value:信号量初始值当pshared为非零时,需要将信号量放在共享内存里面,才能使信号量起效果
销毁信号量
cpp
int sem_destroy(sem_t *sem);等待信号量
cpp
//功能:等待信号量,会将信号量的值减1
int sem_wait(sem_t *sem);//P()发布信号量
cpp
//功能:发布信号量,表⽰资源使⽤完毕,可以归还资源了。将信号量值加1。
int sem_post(sem_t *sem);//V()基于环形队列的信号量实现的生产者消费者模型
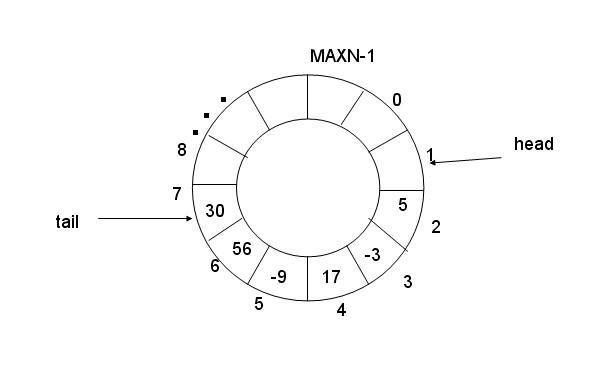
这个实现和阻塞队列是差不多的,只不过变成一个环形的了。这里是使用数组来模拟环形的队列,假如限定环形队列的长度是n,开始的时候生产者和消费者的起点都是下标0,当生产者生产满了,此时的情况和生产者和消费者都没有产出是一样的,所以我们可以加一个长度,让数组变为n+1,此时生产者最快也只会到消费者后一格位置。
cpp
#include <iostream>
#include <pthread.h>
#include <vector>
#include <queue>
#include <random>
#include <time.h>
#include <optional>
#include <thread>
#include <string>
#include<semaphore.h>
#include<random>
using namespace std;
class lockGuard
{
public:
lockGuard(pthread_mutex_t &x) : _mutex(x)
{
pthread_mutex_lock(&_mutex);
}
~lockGuard()
{
pthread_mutex_unlock(&_mutex);
}
private:
pthread_mutex_t &_mutex;
};
pthread_mutex_t print_lock = PTHREAD_MUTEX_INITIALIZER;
void print(const std::string &x)
{
lockGuard k(print_lock);
std::cout << x << std::endl;
}
template<class T>
class ringQueue{
public:
ringQueue(size_t size)
:_vec(size,T()),
_capacity(size),
_productorPos(0),
_consumerPos(0)
{
sem_init(&_lastNum,0,0);
sem_init(&_emtpyNum,0,size);
pthread_mutex_init(&_consumerLock,nullptr);
pthread_mutex_init(&_productorLock,nullptr);
}
~ringQueue(){
sem_destroy(&_lastNum);
sem_destroy(&_emtpyNum);
pthread_mutex_destroy(&_consumerLock);
pthread_mutex_destroy(&_productorLock);
}
void push(const T&val){
sem_wait(&_emtpyNum);
lockGuard k(_productorLock);
_vec[_productorPos]=val;
_productorPos=(_productorPos+1)%_capacity;
sem_post(&_lastNum);
}
T pop(){
sem_wait(&_lastNum);
lockGuard k(_consumerLock);
T ret = move(_vec[_consumerPos]);
_vec[_consumerPos]=0;
_consumerPos=(_consumerPos+1)%_capacity;
sem_post(&_emtpyNum);
return ret;
}
private:
size_t _capacity;
size_t _productorPos;
size_t _consumerPos;
sem_t _lastNum;
sem_t _emtpyNum;
vector<T>_vec;
pthread_mutex_t _consumerLock;
pthread_mutex_t _productorLock;
};
int main(){
std::srand(static_cast<unsigned int>(std::time(nullptr)));
ringQueue<int> ring(10);
vector<thread>threads;
for(int x=0;x<5;++x){
thread t([&](){
while(true){
int rd=std::rand()%100 +1;
string buf("插入:");
buf+=to_string(rd);
print(buf);
ring.push(rd);
this_thread::sleep_for(chrono::milliseconds(1000));
}
});
threads.emplace_back(move(t));
}
for(int x=0;x<5;++x){
thread t([&](){
while(true){
string buf("获取:");
buf+=to_string(ring.pop());
print(buf);
this_thread::sleep_for(chrono::milliseconds(1000));
}
});
threads.emplace_back(move(t));
}
for(int x=0;x<10;++x)threads[x].join();
return 0;
}代码加测试,这里pop弹出置为0是测试看会不会出现取出0的错误情况。

这里有注意事项,push的sem_post必须写在末尾,原因是你先post,那么_emptyNum就会++,那么就可能导致在pop那直接进入拿取值,但此时可能push还没有把值加入进去,就导致拿取了垃圾数据,就出了问题。
线程池
线程池的原理就是生产者消费者模型,我们来捋一捋。首先我们将任务作为货物放进仓库(任务队列),有消费者(任务线程)来获取任务并执行,然后生产者就是其他线程,只要有任务一来,直接交给线程池来完成即可。和生产者消费者模型就是一个东西,这里我就不做实现了。
线程安全与重入问题
线程安全
就是多个线程在访问共享资源时,能够正确地执行,不会相互干扰或破坏彼此的执行结果。一般而言,多个线程并发同一段只有局部变量的代码时,不会出现不同的结果。但是对全局变量或者静态变量进行操作,并且没有锁保护的情况下,容易出现该问题。
重入
同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
线程安全的不一定是可重入的,线程安全要加锁,如果当线程加锁了,突然被信号打断,如果继续进入这个函数因为上锁而死锁
可重入不一定是线程安全的,可重入是说被信号打断,再次进入这个函数不会导致程序异常或者数据、结构异常,如果访问的是临界区资源且没锁,那么就不是线程安全的
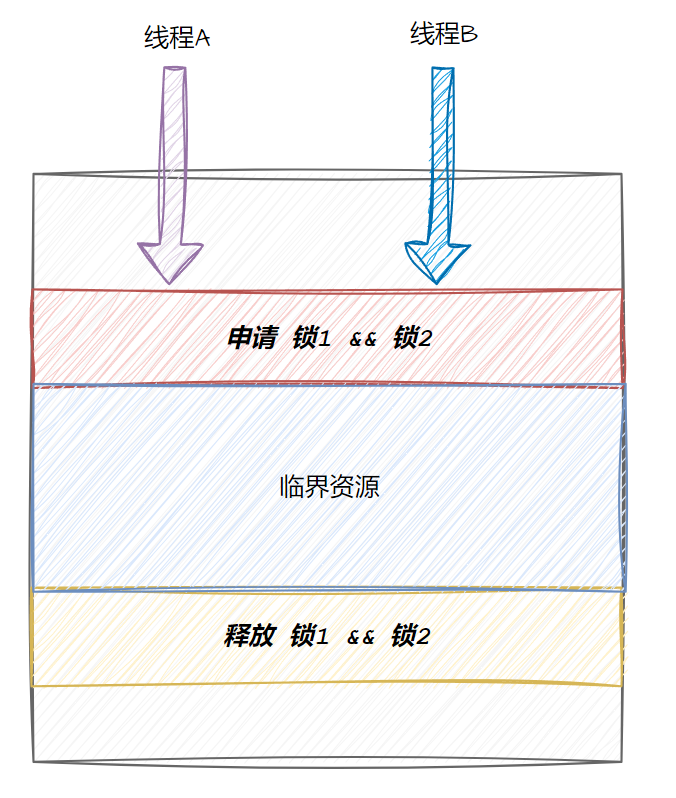
死锁
举个例子,如果一个线程要访问一个临界变量需要同时持有锁1和锁2,那么此时就很可能出现死锁,比如线程1申请到了锁1,线程2申请到了锁2,导致双方都要申请对方的锁,就都阻塞了
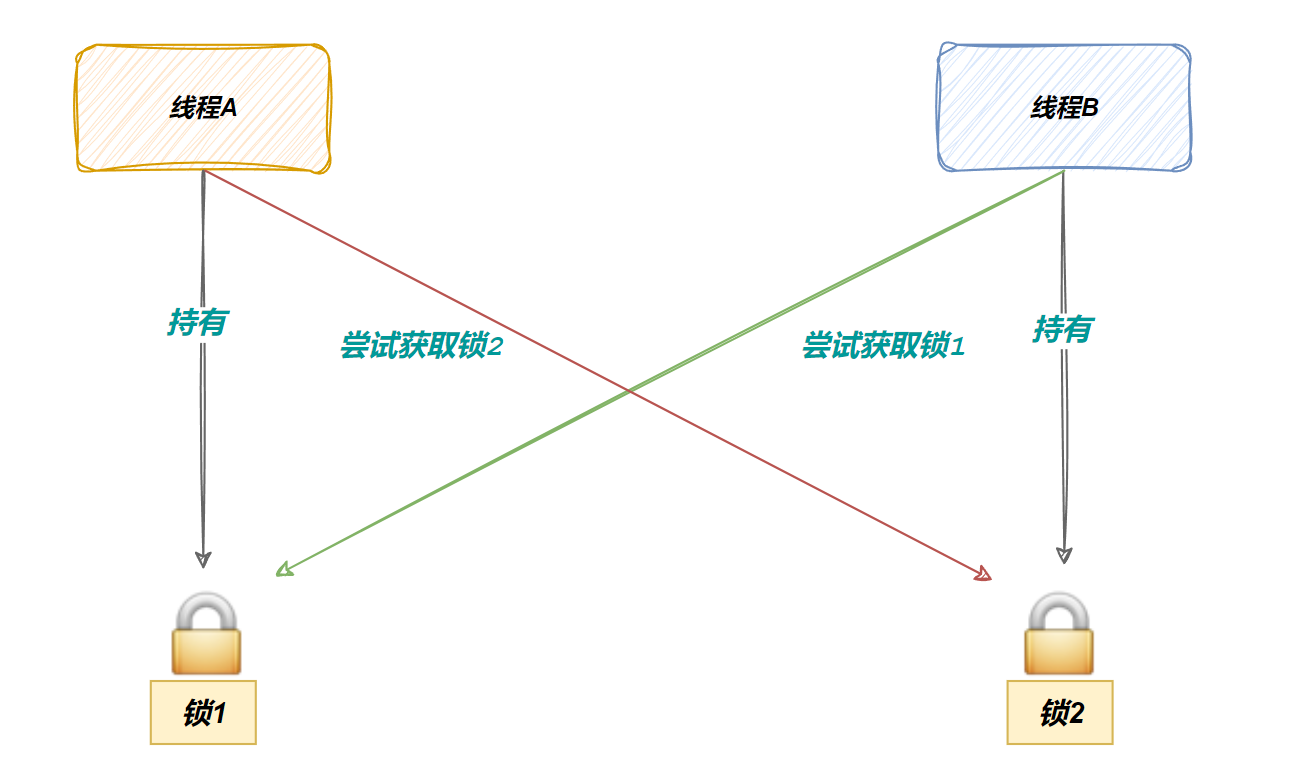
最后导致:

死锁的四个必要条件
互斥条件
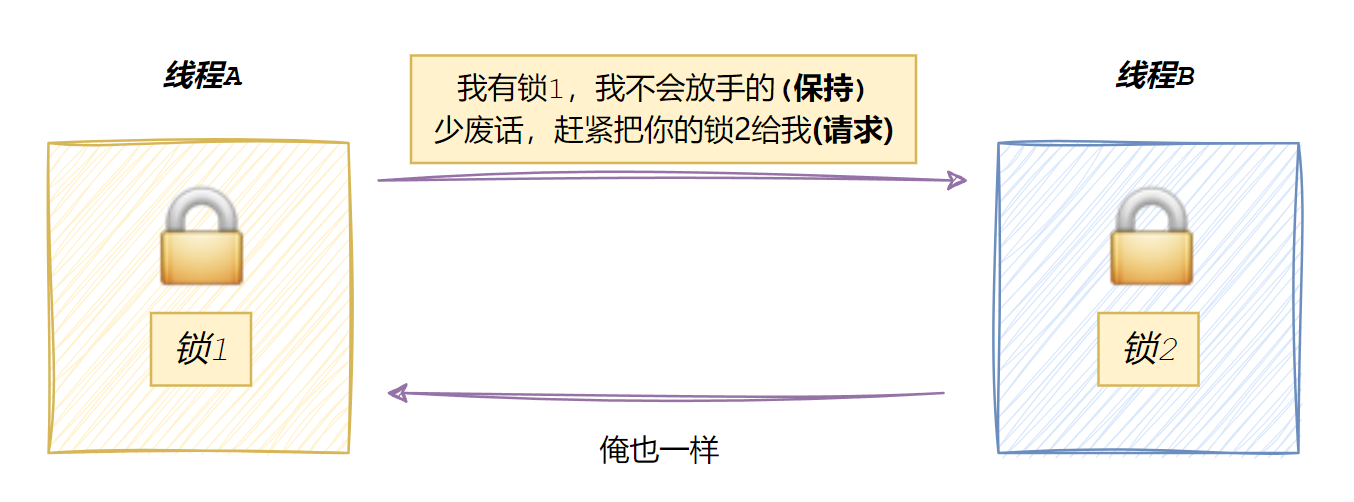
⼀个资源每次只能被⼀个执行流使用
请求与保持条件
一个执行流因请求资源而阻塞是,对自己的资源保持不放
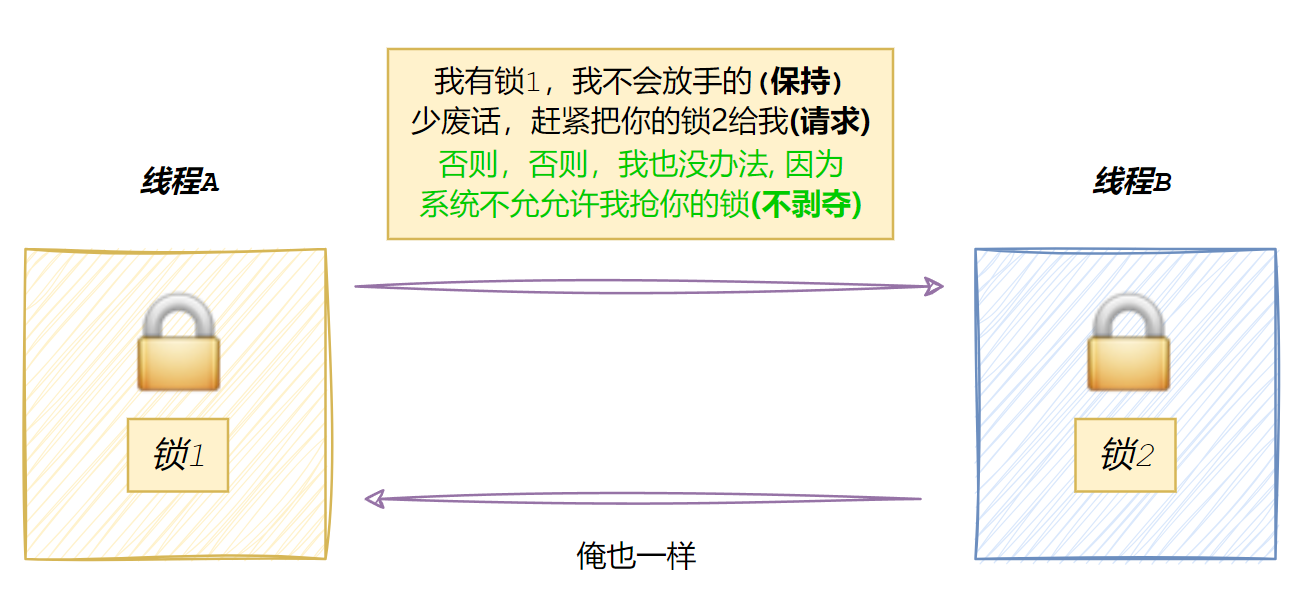
不剥夺条件
一个线程获取的锁,在未使用完之前不能被剥夺
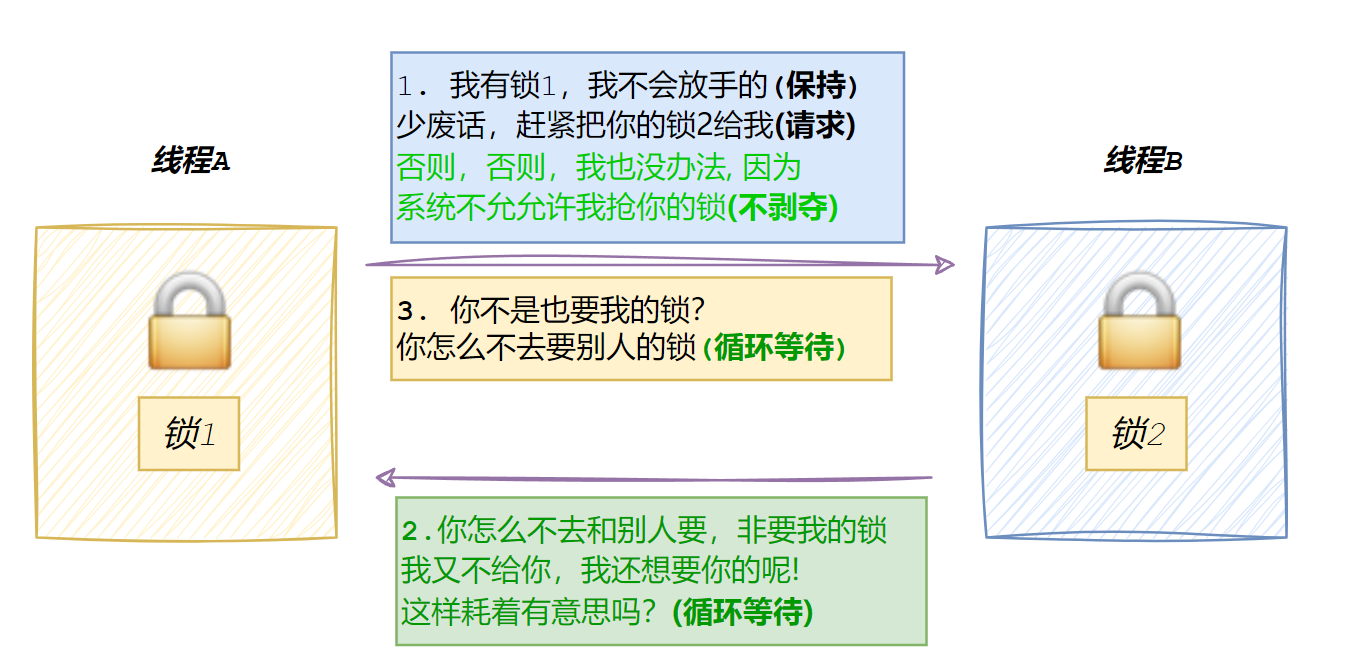
循环等待条件
若干执行流之间形成⼀种头尾相接的循环等待资源的关系
其他锁的种类
悲观锁
害怕数据被修改,于是马上上锁
读写锁
有些情况线程只读比较多,可以用读写锁;
自旋锁
是获取不到锁的时候,不会阻塞放弃CPU,而是循环申请锁,防止线程切换带来开销,多用于临界区代码量比较少的情况。
递归锁
正常情况下,如果递归有送,上锁后递归,就会导致死锁,递归锁就是防止递归时的死锁。
超时锁
给互斥锁的互斥给一个时间上线,超时了就不等了去干别的事情
乐观锁
不怕数据修改,数据操作完后再进行数据的对比,如果操作前数据没变,那么就直接写入。但是需要使用版本号避免ABA问题:加入线程1要准备提交日志,此时资源是未提交状态,然后线程2提交了,提交完设置回未提交状态,线程1以为没有提交就会再提交一次。
乐观锁和读写锁的区别,两个在多读少些的情况都很耐打,建议是在具体场景下测试一下。