
✨道路是曲折的,前途是光明的!
📝 专注C/C++、Linux编程与人工智能领域,分享学习笔记!
🌟 感谢各位小伙伴的长期陪伴与支持,欢迎文末添加好友一起交流!

- 前言
-
- 一、核心概念
-
- [1.1 两种缓冲区](#1.1 两种缓冲区)
- [1.2 接口对比](#1.2 接口对比)
- [1.3 返回值差异](#1.3 返回值差异)
- 二、缓冲区刷新策略
-
- [2.1 三种刷新模式](#2.1 三种刷新模式)
- [2.2 刷新时机总结](#2.2 刷新时机总结)
- 三、现象解析
-
- 现象一:直接输出到显示器
- 现象二:重定向到文件
- 现象三:fork但不重定向
- [现象四:fork + 重定向(核心现象)](#现象四:fork + 重定向(核心现象))
- [现象五:close(1) + 无换行符](#现象五:close(1) + 无换行符)
- [现象六:write + close(1)](#现象六:write + close(1))
- 四、深度原理
-
- [4.1 用户缓冲区在哪里?](#4.1 用户缓冲区在哪里?)
- [4.2 为什么需要用户缓冲区?](#4.2 为什么需要用户缓冲区?)
- [4.3 数据流向图](#4.3 数据流向图)
- 五、关键要点总结
-
- [5.1 核心结论](#5.1 核心结论)
- [5.2 刷新流程](#5.2 刷新流程)
- 六、实际应用建议
前言
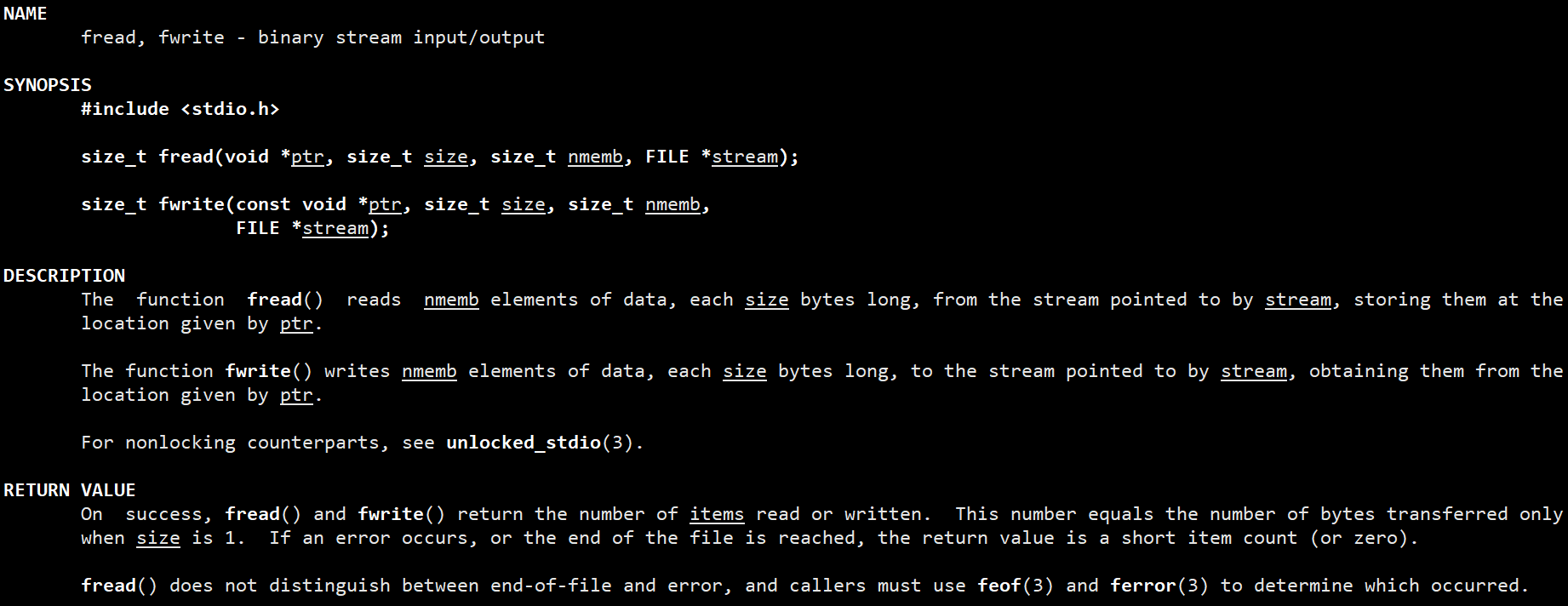
本文深入探讨Linux系统中用户缓冲区的概念与工作原理。通过分析C语言文件接口(printf、fprintf、fwrite)与系统调用接口(write)的区别,揭示缓冲区在文件IO中的重要作用。
一、核心概念
1.1 两种缓冲区
Linux系统中存在两个层面的缓冲区:
| 类型 | 位置 | 归属 | 刷新机制 |
|---|---|---|---|
| 用户缓冲区 | 用户空间 | C语言库FILE结构体 | 由库函数控制 |
| 内核缓冲区 | 内核空间 | 操作系统 | 由OS控制 |
1.2 接口对比
c
// C语言库函数接口
printf("hello printf\n"); // 写入用户缓冲区
fprintf(stdout, "hello fprintf\n"); // 写入用户缓冲区
fwrite(str, len, 1, stdout); // 写入用户缓冲区
// 系统调用接口
write(1, str, len); // 直接写入内核缓冲区关键区别:
- C库函数先写入用户缓冲区,再由底层调用write刷新到内核
- write系统调用直接写入内核缓冲区,无用户缓冲区
1.3 返回值差异
c
size_t ret1 = fwrite(str, len, 1, stdout); // 返回:写入的块数
ssize_t ret2 = write(1, str, len); // 返回:写入的字节数

二、缓冲区刷新策略
2.1 三种刷新模式
| 模式 | 触发条件 | 典型场景 |
|---|---|---|
| 无缓冲 | 立即刷新 | fflush()函数 |
| 行缓冲 | 遇到\n刷新 |
显示器输出 |
| 全缓冲 | 缓冲区满时刷新 | 普通文件写入 |
2.2 刷新时机总结
- 遇到换行符
\n(行缓冲模式) - 缓冲区满(全缓冲模式)
- 进程正常退出
- 主动调用
fflush() - 关闭流
fclose()
三、现象解析
现象一:直接输出到显示器
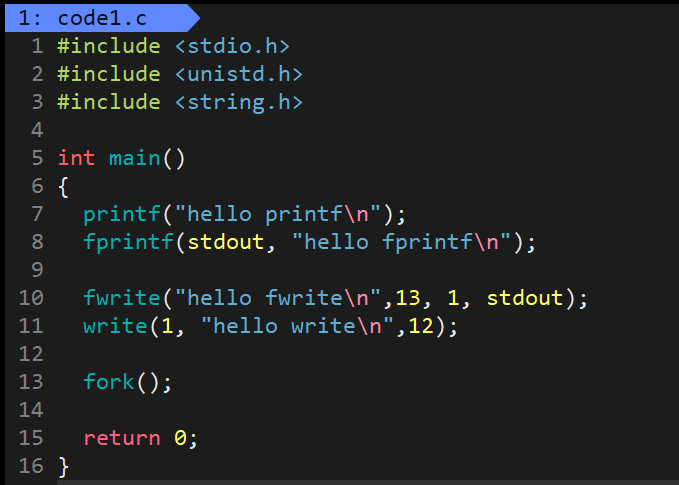
c
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
fwrite("hello fwrite\n", 13, 1, stdout);
write(1, "hello write\n", 12);
结果:四个函数都正常输出到屏幕
解释 :显示器采用行缓冲,遇到\n立即刷新。
现象二:重定向到文件
c
// 同样的代码,但执行时重定向:./code1> log.txt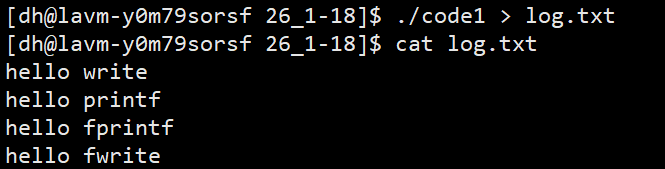
结果:log.txt中包含4行输出
解释:重定向后,输出目标从显示器变为普通文件,但仍能正常写入。
现象三:fork但不重定向
c
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
fwrite("hello fwrite\n", 13, 1, stdout);
write(1, "hello write\n", 12);
fork(); // 创建子进程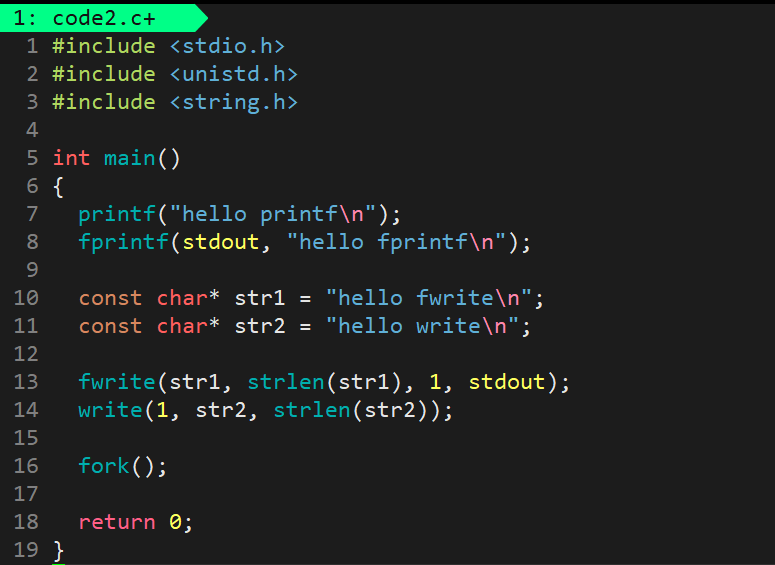
结果:每个消息只打印一次
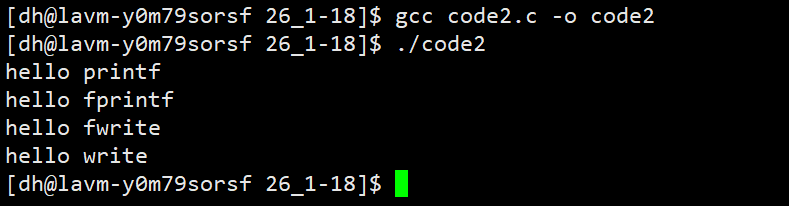
解释:由于是行缓冲,数据在fork前已刷新到内核,用户缓冲区为空。
现象四:fork + 重定向(核心现象)
c
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
fwrite("hello fwrite\n", 13, 1, stdout);
write(1, "hello write\n", 12);
fork(); // 创建子进程
// 执行时重定向:./test > log.txt结果:
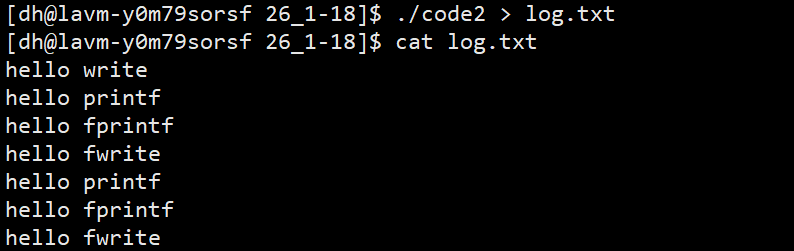
plain
hello write
hello printf
hello fprintf
hello fwrite
hello printf
hello fprintf
hello fwrite详细解释:
- 为什么write只出现一次?
- write直接写入内核缓冲区,不经过用户缓冲区
- fork时没有数据需要拷贝
- 为什么C库函数出现两次?
- 重定向后变成全缓冲模式,数据留在用户缓冲区
- fork时父子进程各自拷贝一份用户缓冲区(写时拷贝)
- 进程退出时,各自刷新缓冲区,导致数据重复
- 为什么write排在最前面?
- write直接写入内核,不等待缓冲区满
- C库函数需要等待进程退出才刷新
验证代码(观察缓冲区刷新时机):
c
printf("hello printf\n");
sleep(1);
fprintf(stdout, "hello fprintf\n");
sleep(1);
fwrite("hello fwrite\n", 13, 1, stdout);
sleep(1);
write(1, "hello write\n", 12);
sleep(2);
fork();配合监控脚本:
bash
while :; do cat log.txt; sleep 1; echo "---"; done现象五:close(1) + 无换行符
c
printf("hello printf"); // 无换行符
fprintf(stdout, "hello fprintf");
fwrite("hello fwrite", 12, 1, stdout);
close(1); // 关闭stdout结果:屏幕没有任何输出
解释:
- 无
\n触发刷新 - close(1)关闭了文件描述符
- 进程退出时无法找到有效的fd来刷新数据
现象六:write + close(1)
c
write(1, "hello write", 11); // 无换行符
close(1);结果:正常输出
解释:
- write是系统调用,直接写入内核缓冲区
- 内核保证数据最终写入硬件(显示器)
- 不依赖用户缓冲区的刷新机制
四、深度原理
4.1 用户缓冲区在哪里?
plain
FILE结构体(用户空间)
├── fd(文件描述符)
├── 缓冲区指针 ──────→ 堆空间(用户缓冲区)
├── 缓冲区大小
└── 其他维护信息
c
FILE* fp = fopen("test.txt", "w");
// fp指向malloc分配的结构体
// 结构体中包含指向堆上缓冲区的指针4.2 为什么需要用户缓冲区?
1. 提高效率
plain
无缓冲:写100次 → 100次系统调用
有缓冲:写100次 → 1次系统调用(批量刷新)2. 支持格式化
plain
printf("%d", 123); // 将整数转换为字符流
scanf("%d", &a); // 将字符流转换为整数缓冲区承担数据格式转换的任务。
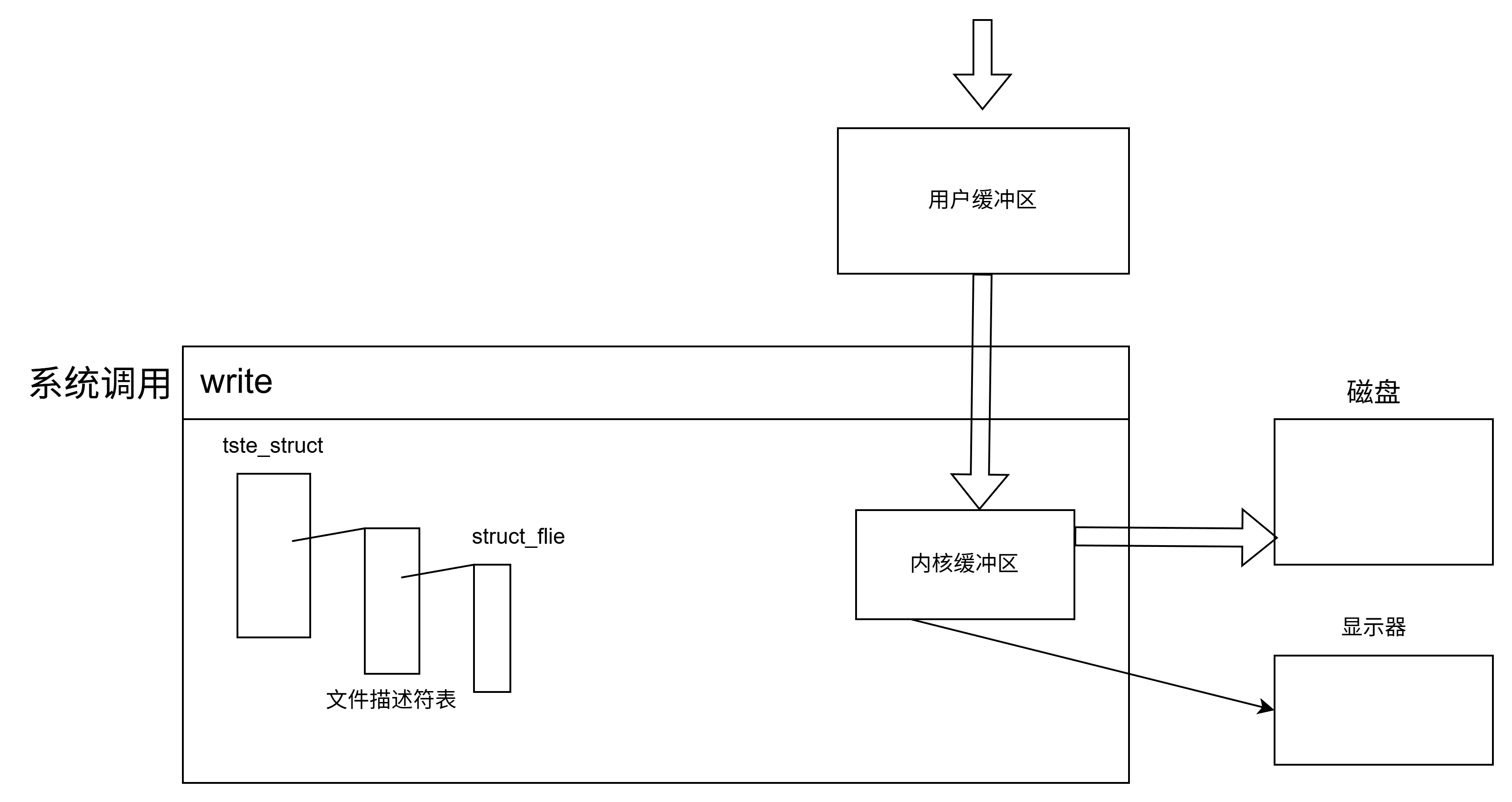
4.3 数据流向图
plain
┌─────────────────────────────────────────────────────┐
│ 用户程序 │
│ │
│ printf/fprintf/fwrite → 用户缓冲区(FILE中) │
│ ↓ │
│ fflush() │
│ ↓ │
└──────────────────────────────┼──────────────────────┘
│ write系统调用
↓
┌─────────────────────────────────────────────────────┐
│ 操作系统内核 │
│ │
│ 内核缓冲区 │
│ ↓ │
│ 刷新策略(OS控制) │
│ ↓ │
└──────────────────────────────┼──────────────────────┘
│
↓
┌─────────────────────────────────────────────────────┐
│ 硬件设备 │
│ (显示器/磁盘文件/网络) │
└─────────────────────────────────────────────────────┘五、关键要点总结
5.1 核心结论
- C库函数 ≠ 系统调用
- C库函数:用户缓冲区 → 内核缓冲区 → 硬件
- 系统调用:直接 → 内核缓冲区 → 硬件
- 重定向改变缓冲策略
- 显示器:行缓冲(遇到
\n刷新) - 普通文件:全缓冲(满了才刷新)
- 显示器:行缓冲(遇到
- fork + 重定向 = 数据重复
- 前提:数据在用户缓冲区中未刷新
- 机制:写时拷贝导致父子进程各自持有一份缓冲区
- 用户缓冲区属于进程
- 存在于FILE结构体中
- FILE结构体在堆上分配
5.2 刷新流程
plain
printf("hello\n")
↓
写入用户缓冲区
↓
遇到\n → 触发刷新
↓
调用write(fd, "hello\n", 6)
↓
数据进入内核缓冲区
↓
OS按策略刷新到硬件六、实际应用建议
- 调试技巧:遇到IO问题时,检查是否忘记刷新缓冲区
- 性能优化:批量写入比频繁写入效率更高
- fork注意:fork前确保刷新缓冲区,避免数据重复
- 重定向注意:了解目标设备的缓冲策略差异
✍️ 坚持用 清晰易懂的图解 + 可落地的代码,让每个知识点都 简单直观!
💡 座右铭 :"道路是曲折的,前途是光明的!"
