本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
前言
在 Azure AI 生态系统中,Azure Machine Learning (Azure ML) 工作区是所有机器学习活动的中心枢纽。上一文已经初步搭建了这个服务,那么现在我们登录进去。
登录进去之后我们可以看到下图所示:
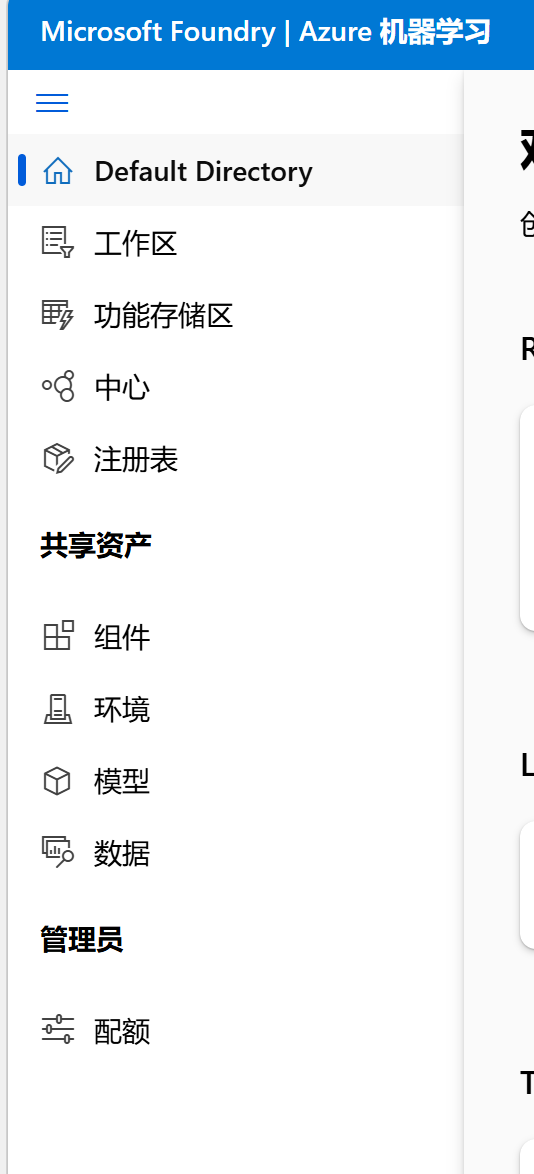
默认目录
类似主页功能, 在 Azure 机器学习中,默认目录是你进行所有操作的基础环境。它包含了工作区、功能存储区、中心和注册表等核心组件。
- 工作区:这是你进行实验、训练模型和部署服务的主要区域。
- 功能存储区:用于存储和管理数据功能,方便数据的预处理和特征工程。
- 中心:提供各种工具和资源,帮助你更高效地管理模型和数据。
- 注册表:用于管理和跟踪模型的版本,确保模型的可追溯性和一致性。
共享资产
在 Azure 机器学习中,共享资产是团队协作和资源共享的重要部分。
- 组件:可以复用的代码模块,帮助你快速构建和部署模型。
- 环境:定义了模型运行时所需的软件和配置,确保模型在不同环境中的稳定运行。
- 模型:训练好的机器学习模型,可以进行版本管理和部署。
- 数据:用于训练和测试模型的数据集,支持数据的版本管理和访问控制。
管理员
管理员负责整个工作区的管理和维护,确保资源的合理分配和使用。
- 配额:管理员可以设置和管理资源配额,避免资源的过度使用,保证系统的稳定运行。
实操演示
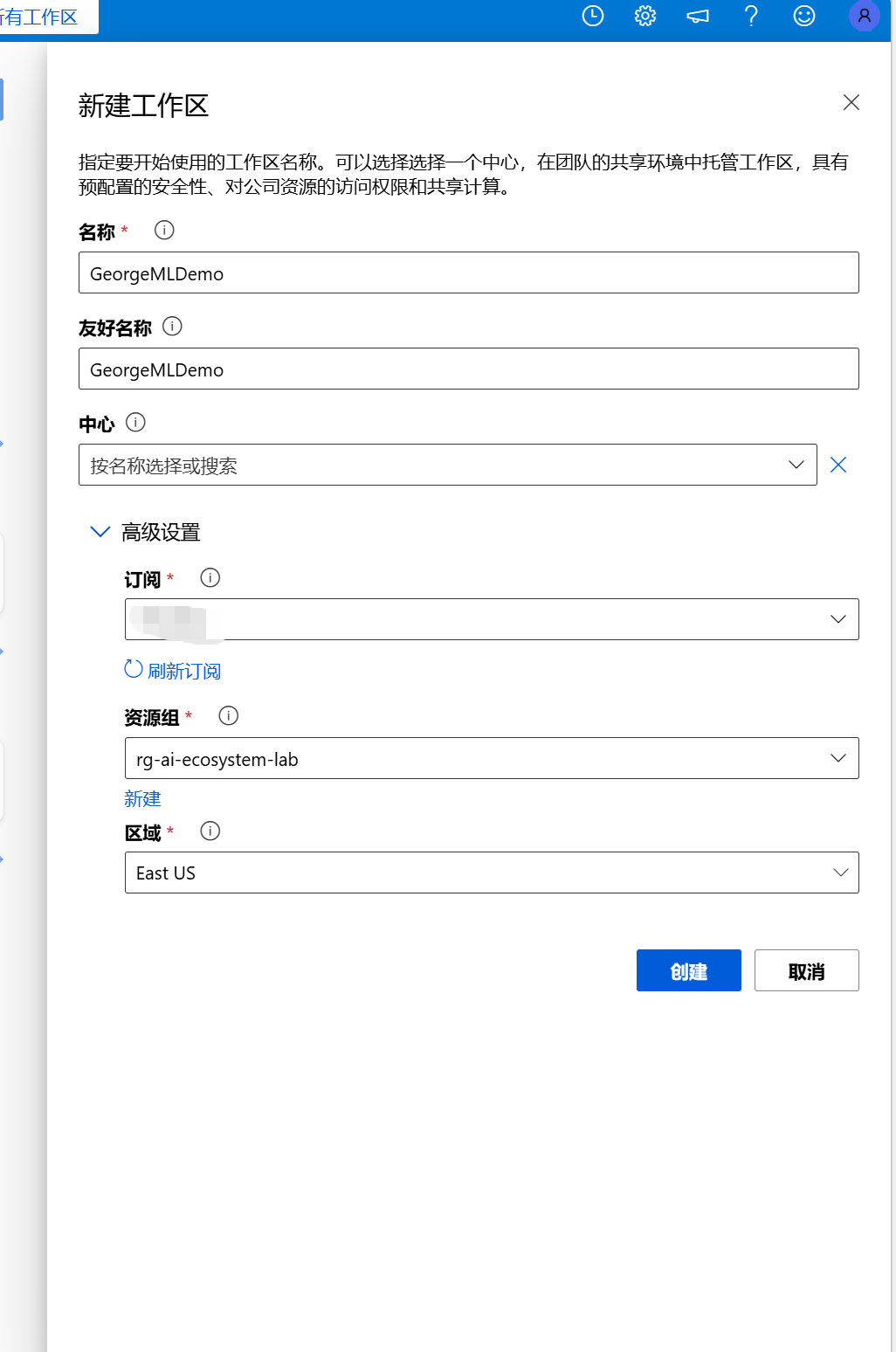
接下来快速演示一下,首先我们新建一个工作区:
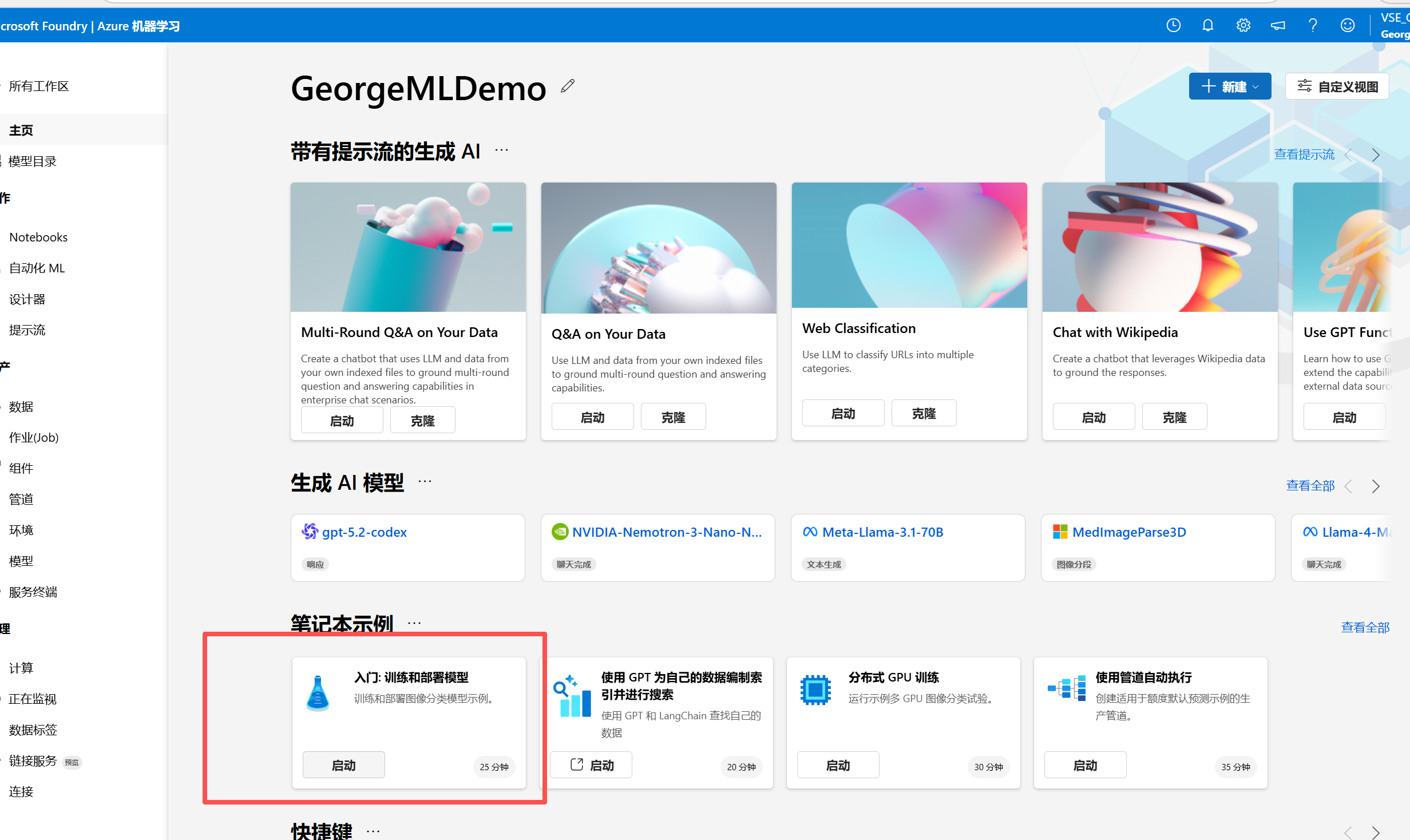
启动下面红框处的示例:
可以看到有下面的一个快速入门,可以点击"克隆此笔记本"进行开始操作:
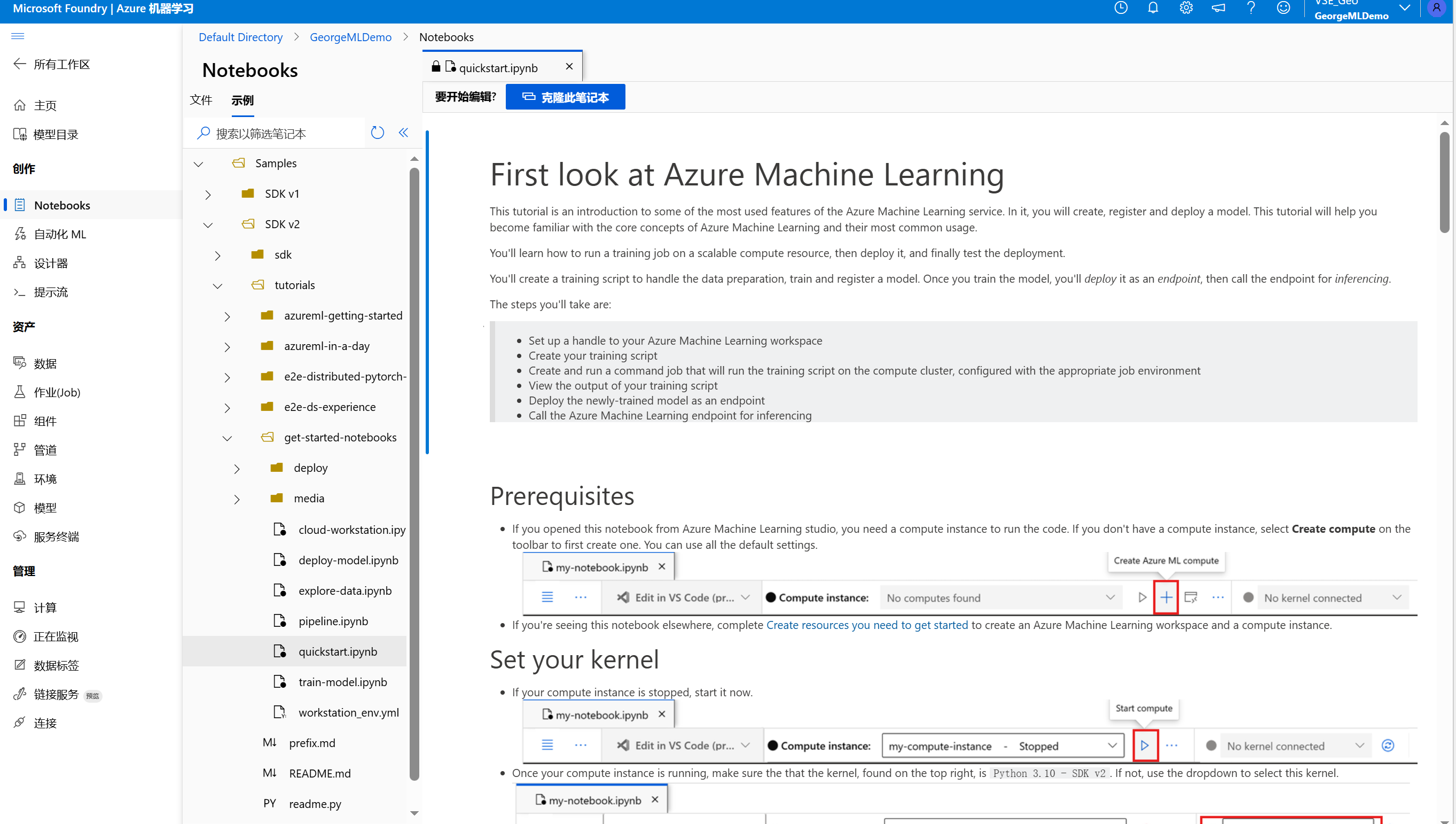
克隆之后创建一个计算资源
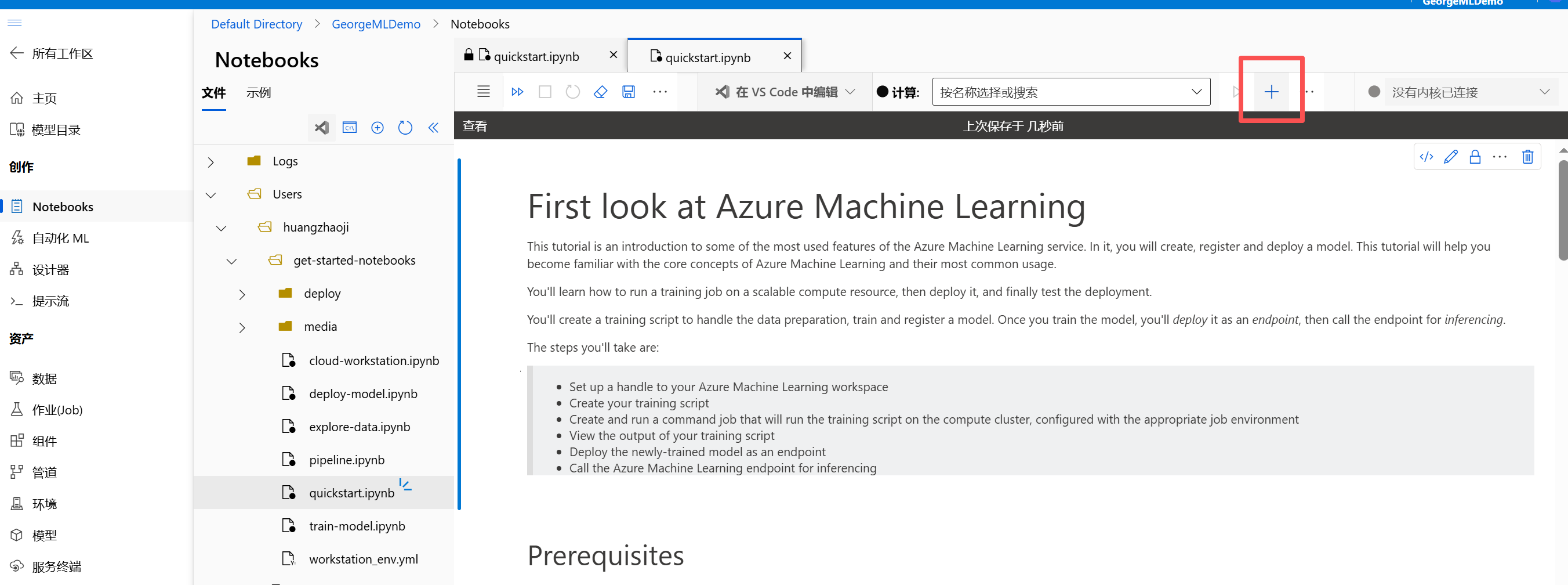
这里选择最便宜的
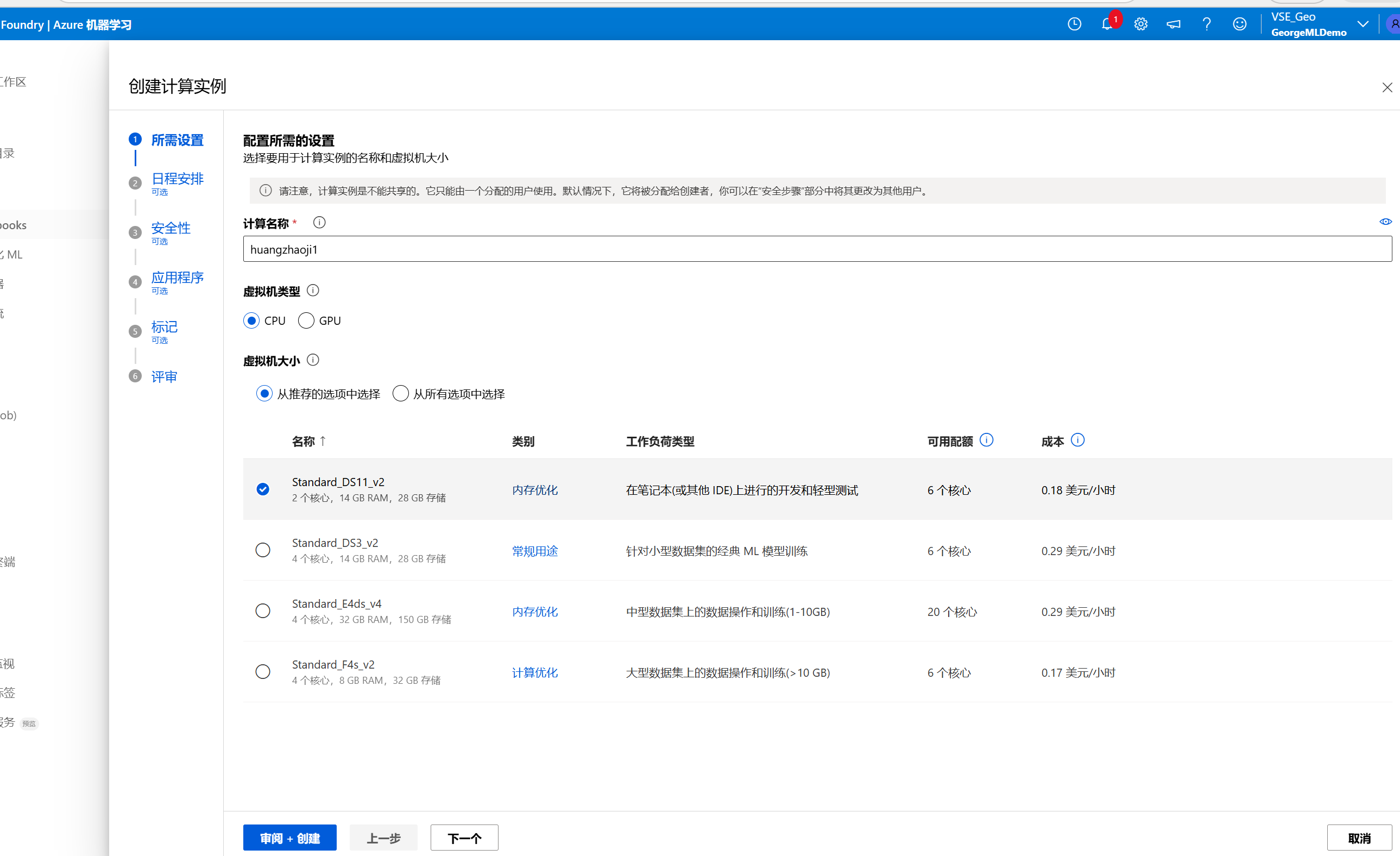
按照示例一步一步运行,然后可以看到在作业处已经生成了作业并排队。
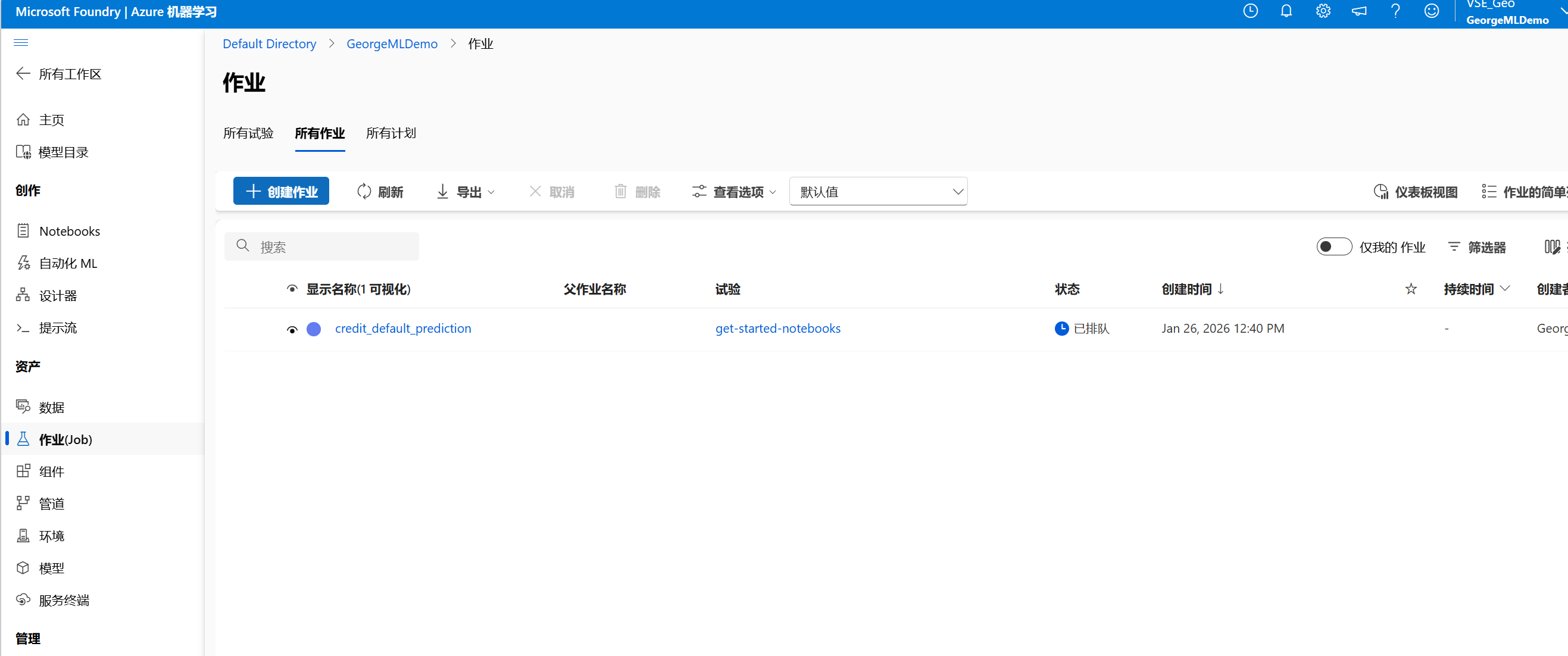
作业已经启动运行。
运行成功:
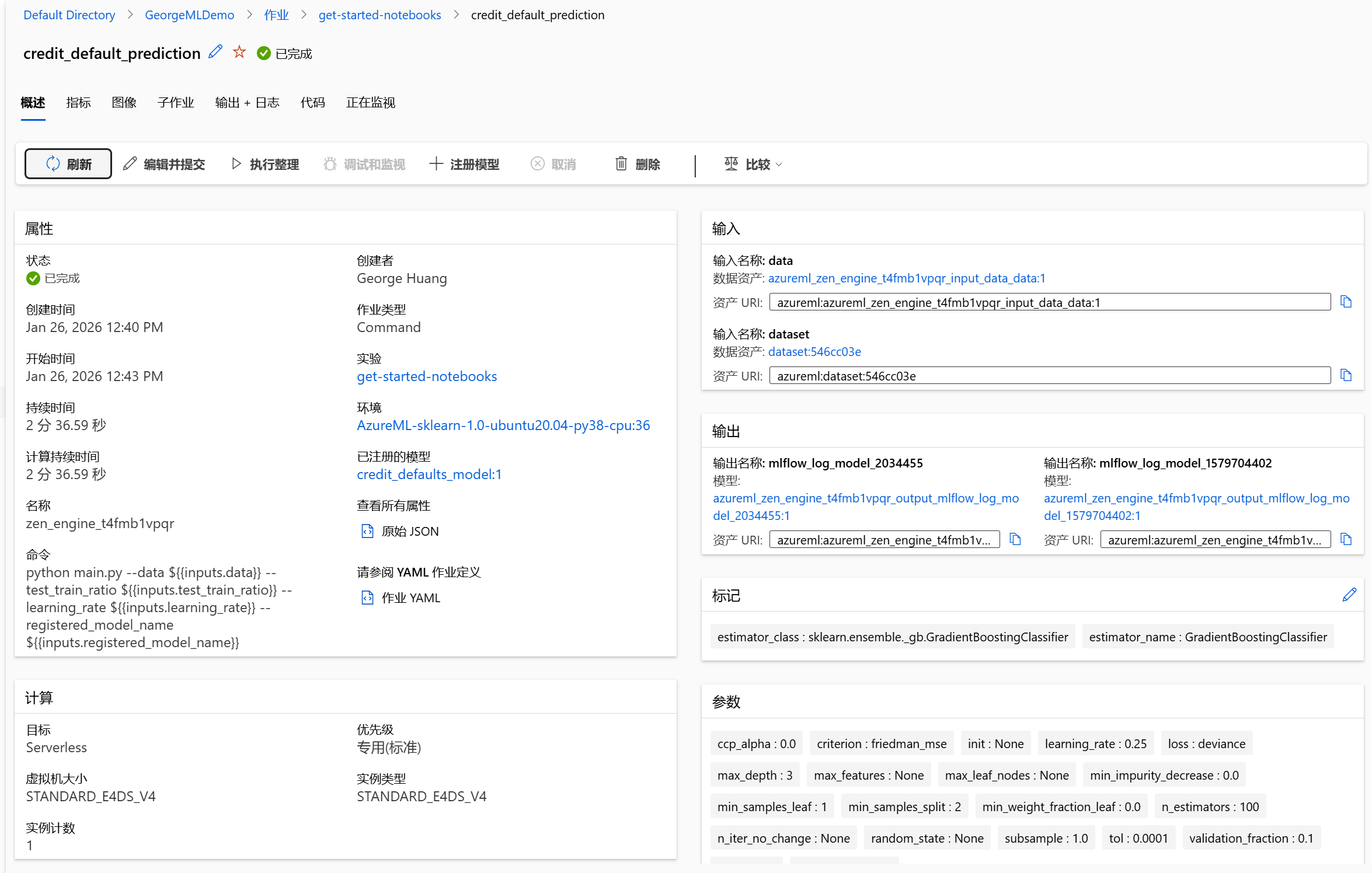
实际运用流程
ML 是通过对数据进行模型训练生成结果的过程,在实际运用中,我们可以按照下面步骤进行服务的使用以便完成我们的目标:
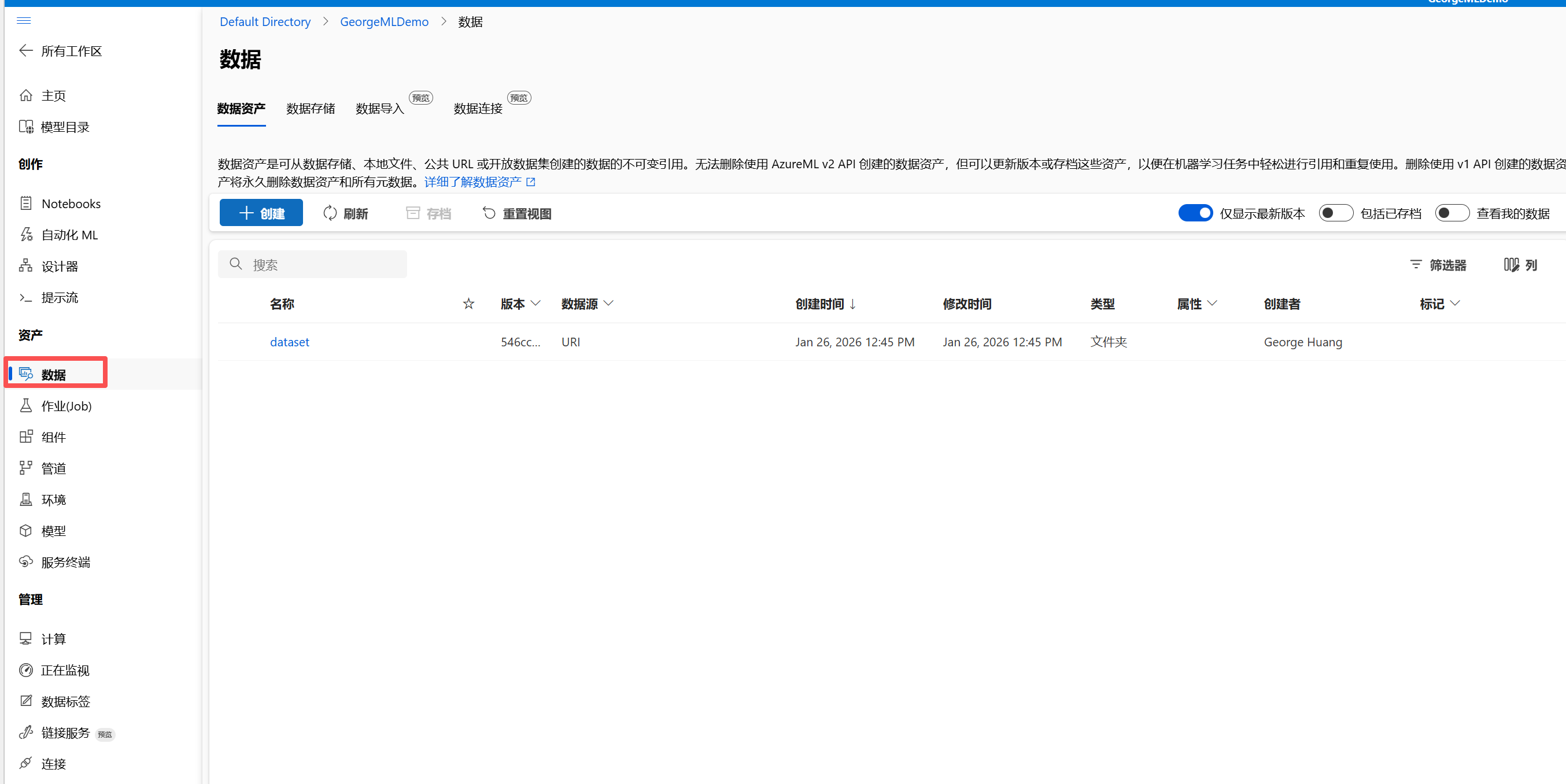
1.数据准备(数据)
- 数据获取:首先,你需要通过"数据"部分来上传或连接到你的数据源。这可以是本地文件、数据库或其他数据存储。
- 数据预处理:使用"Notebooks"或"自动化 ML"来清洗和预处理数据,确保数据的质量和格式适合后续的模型训练。
2. 模型训练(自动化 ML / 设计器)
- 自动化 ML:如果你希望快速得到一个模型,可以使用"自动化 ML"功能。它会自动尝试多种模型和参数组合,找到最佳模型。
- 设计器:对于更复杂的场景,可以使用"设计器"来手动构建机器学习管道。你可以选择不同的算法、调整参数,并可视化地连接各个组件。
3. 模型评估与选择(作业(Job) / 管道)
- 作业(Job):在训练模型后,你可以通过"作业(Job)"来查看训练过程和结果。这里可以找到模型的性能指标,帮助你评估模型的优劣。
- 管道:使用"管道"来自动化模型训练和评估流程。你可以创建包含数据预处理、模型训练和评估的完整管道,方便重复执行和优化。
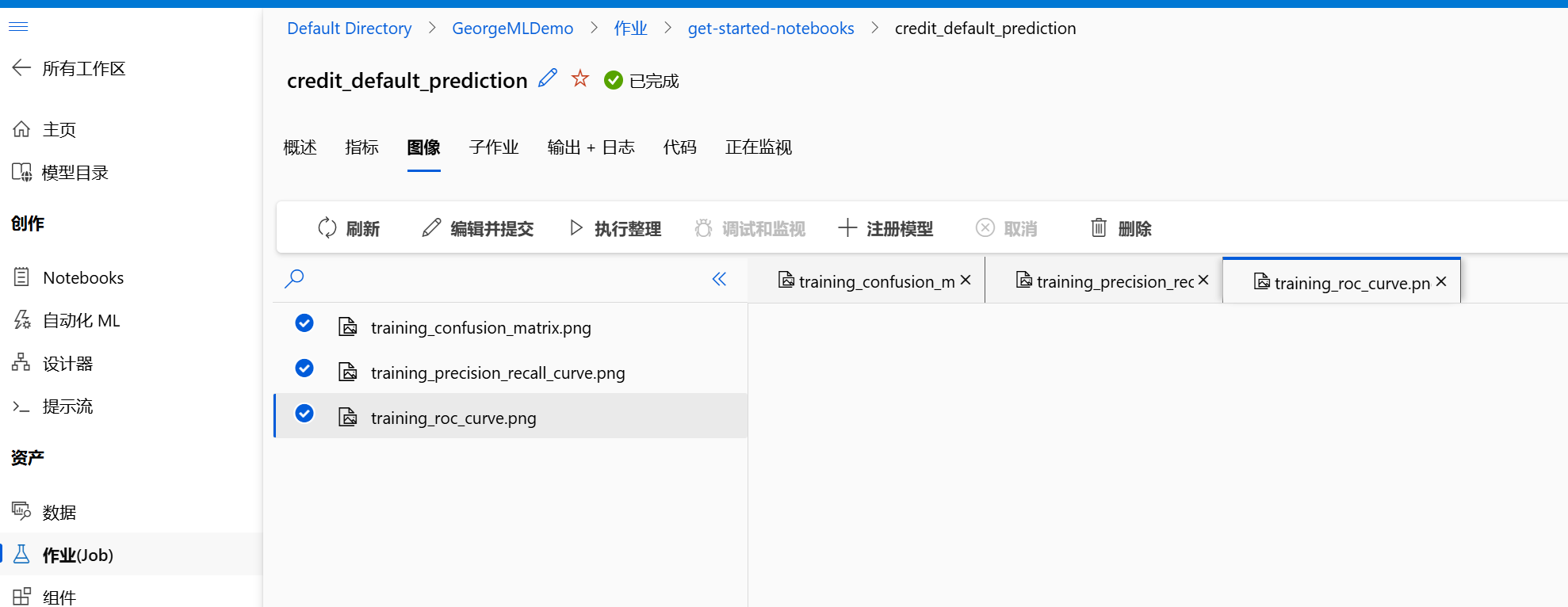
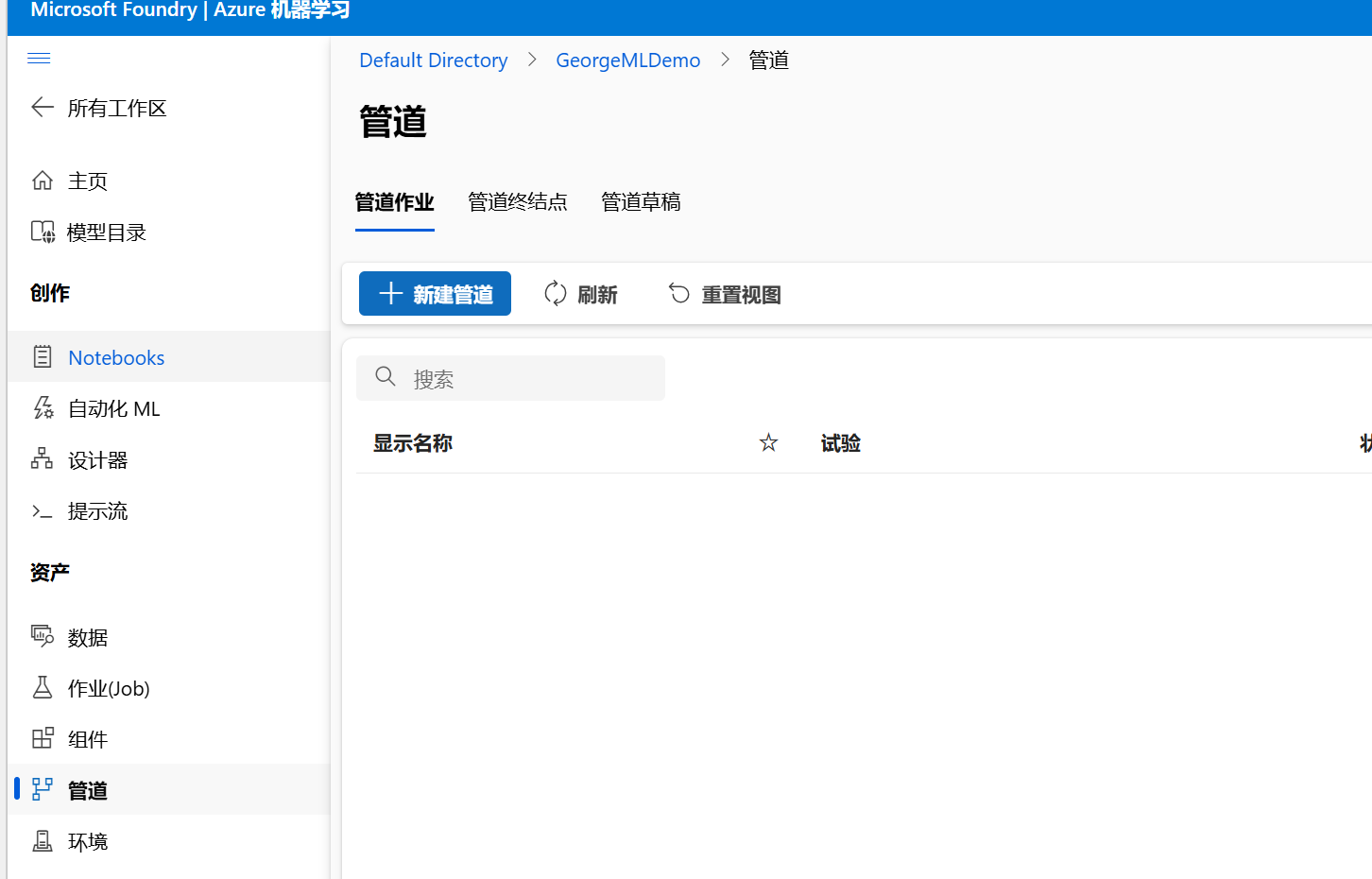
4. 模型部署(模型 / 服务终端)
- 模型:在找到满意的模型后,可以在"模型"部分进行模型的注册和管理。
- 服务终端:通过"服务终端"来部署模型,使其可以通过 API 调用。这样,模型就可以集成到实际的应用程序中,进行预测和服务。
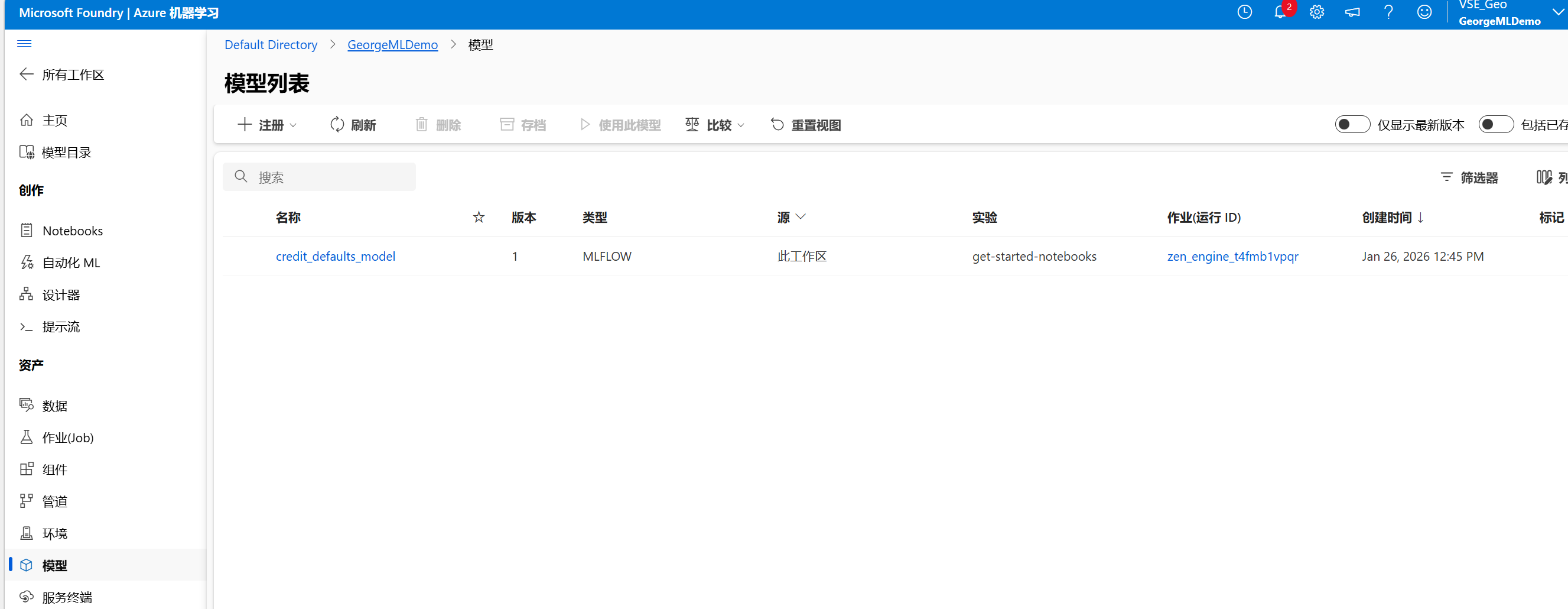
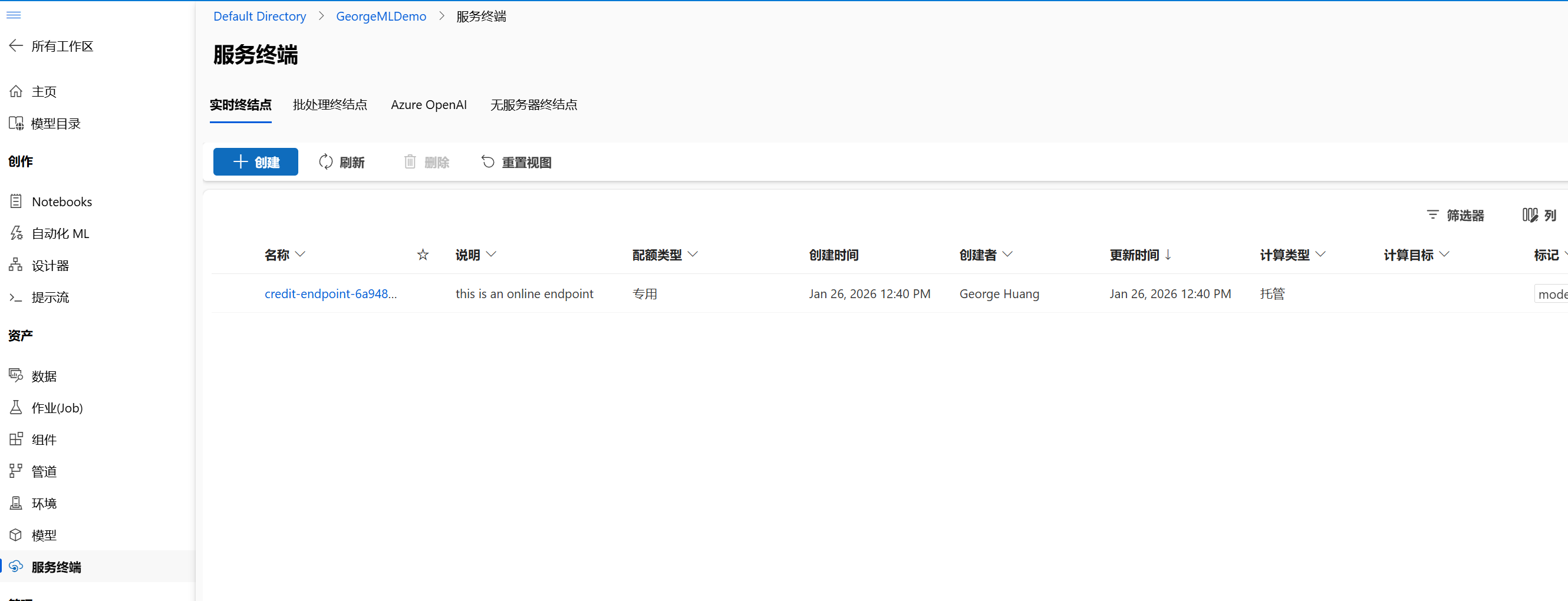
5. 监控与优化(正在监视 / 数据标签)
- 正在监视:部署模型后,使用"正在监视"来监控模型的运行状态和性能。这有助于及时发现和解决潜在问题。
- 数据标签:如果模型的预测结果需要进一步优化,可以使用"数据标签"来获取更多标注数据,用于模型的再训练和优化。
6. 资源管理(计算 / 连接服务)
- 计算:管理你的计算资源,确保有足够且合适的计算能力来支持数据处理和模型训练。
- 连接服务:管理与外部服务的连接,如数据存储、监控工具等,确保整个工作流程的顺畅运行。
小结
本文演示了Azure AI体系中一个重要服务Azure ML, 大概浏览了其内部结构,但是要深入使用一个服务,并不是一篇文章可以做到的,所以这里仅是简要演示。
接下来的几篇将会做更加深入的演示,首先是数据工程在AI系统中的设计。