系列文章目录
文章目录
- 系列文章目录
- 前言
- 零、SFT的局限?
- 一、模型对齐
-
- [1.1 模型对齐的必要性](#1.1 模型对齐的必要性)
- [1.2 通往模型对齐的三道关隘](#1.2 通往模型对齐的三道关隘)
- 二、RLHF
-
- [2.1 理解RLHF](#2.1 理解RLHF)
- [2.2 RLHF 的核心步骤](#2.2 RLHF 的核心步骤)
- [三、LLaMA-Factory RLHF(DPO)实战](#三、LLaMA-Factory RLHF(DPO)实战)
-
- [3.1 LLaMA-Factory 介绍](#3.1 LLaMA-Factory 介绍)
- [3.2 环境搭建](#3.2 环境搭建)
- [3.3 训练准备](#3.3 训练准备)
- 总结
前言
零、SFT的局限?
无论是
PEFT还是全量微调,主要方法大多是有监督微调(Supervised Fine-tuning, SFT) ,即用 成对的"(指令, 回答)" 数据来训练模型。
SFT是一个存在天花板的技术,它教会了模型模仿高质量的范例,但很显然,无法让模型理解 人类的偏好。人类不希望模型用冷冰冰的语言,毫无创造力的句式以及千篇一律的答复,更不希望模型瞎编乱造、甚至危言耸听。- 这算是
SFT的局限:
- 缺乏泛化能力,模型只能很好地响应数据集中出现过的指令模式,无法覆盖用户千奇百怪的真实意图。
- 对齐不足:模型的回答可能在事实上正确,但在风格、语气、安全性或有用性上,并不符合人类的期望。它只知道"正确答案",却不知道"更好的答案"。
- 对齐 是英文 alignment 的翻译
一、模型对齐
1.1 模型对齐的必要性
为了跨越从"遵循指令"到"理解偏好"的鸿沟,我们需要一种新的训练范式。基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF) 正是解决这一问题的关键技术。
- 模型对齐的目标是:让模型超越简单的模仿学习,真正理解并内化人类复杂的价值观,使其输出更符合我们的期望。
SFT与RLHF在核心理念与实现方式上的关键差异:
| 对比维度 | 监督微调 (SFT) | 人类反馈强化学习 (RLHF) |
|---|---|---|
| 核心目标 | 模仿正确答案(指令遵循) | 对齐人类偏好(有用/无害/诚实) |
| 数据需求 | 高质量的 (指令, 回答) 对 | 提示词 (Prompt) + 偏好排序/评分 |
| 学习方式 | 填鸭式教学(拟合分布) | 探索式学习(试错与反馈) |
| 优化信号 | Token 级预测概率(交叉熵) | 整句生成质量评分(标量奖励) |
| 泛化能力 | 局限于训练数据分布 | 可泛化到未见过的复杂指令 |
1.2 通往模型对齐的三道关隘
在实践中,对齐训练通常划分为三个阶段,分别面向通用语言能力 、指令遵循 与偏好对齐。
- 基础模型预训练,获得通用语言能力
- 在大规模(万亿级 Token)无标注文本数据(网页、书籍、代码等)上进行自回归预训练。
- 通过预测下一个词的任务,模型能够习得广泛的语料知识并具备基础的生成能力,从而得到一个基础语言模型。
- 这一阶段的训练门槛极高,不仅算力成本巨大,还需在超大规模数据与模型上解决复杂的收敛稳定性问题。
- 有监督指令微调,获得指令遵循能力
- 使用少量(千到几万条)高质量"指令-回答"对,对基础模型进行有监督微调,使其学会理解并执行人类指令。
- 这一阶段通常使用 (prompt, response) 格式的数据,并可结合 QLoRA 等参数高效微调技术进行训练。它的目标是在指令上下文中实现条件生成,以此显著提升模型的指令遵循与任务完成能力,
- 最终获得一个在指定任务与约束条件下更为可控的 "指令模型"(Instruction-tuned LM)。
- 高质量的 SFT 数据集是模型能力养成的关键。根据目标的不同,数据集可以分为两类:
- 任务型指令数据集:如 WizardLM Evol‑Instruct 70k (AI 生成) 和 Dolly-15k (专家编写),它们主要由单轮的"指令-回答"构成,核心目标是教会模型如何"做事",准确地遵循指令完成特定任务。
- 对话型数据集:这类数据集的代表作就是 OpenAssistant (OASST)。它专注于教会模型如何"聊天",其独特性和重要性体现在:来源真实且多样,专注于多轮对话,丰富的反馈信号:数据不仅包含对话文本,还有人工标注的质量评分和多种标签(可作为偏好学习/奖励建模的有益信号)。OASST不仅是优秀的
SFT数据,也是训练奖励模型(Reward Model)、进行 RLHF 的宝贵材料。
- 基于人类反馈的强化学习
- 这一阶段是模型从"及格"走向"卓越"的关键跨越。虽然经过
SFT微调的模型已经能流畅地遵循指令,但它本质上仍是在进行"模仿学习",受限于标注数据的质量,会存在"只知其一不知其二"的问题,且容易产生幻觉或不安全的输出。 RLHF引入了人类价值观作为指导信号,通过构建奖励模型来模拟人类的判别标准,并利用强化学习算法让模型在生成过程中不断"试错"并学习如何获得更高的奖励。- 这一过程不再要求模型死记硬背固定的标准答案,而是鼓励它探索出更符合有用性(Helpful)、诚实性(Honest)和无害性(Harmless)(简称 3H 原则)的回复路径。
二、RLHF
2.1 理解RLHF
-
在深入具体步骤之前,我们需要理解为什么 文本生成任务 可以被建模为强化学习问题。
-
AI生成文本不是一次完成的,而是像走迷宫------每一步选一个词,直到走完。
-
在
RLHF框架中,将token生成过程建模为 片段的 episodic 马尔可夫决策过程 MDP- 片段:特指从接收用户提示到生成完整输出的单次生成任务。
-
从公式的角度讲,RLHF 的目标就是寻找一个最优策略 π θ \pi_\theta πθ,使得生成的完整序列期望奖励最大化:
max π E x ∼ D , y ∼ π ( ⋅ ∣ x ) R ( x , y ) \max_\pi \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi(\cdot|x)} R(x, y) πmaxEx∼D,y∼π(⋅∣x)R(x,y)
- 状态 (State, s t s_t st):当前已生成的上下文,包括用户提示 x x x 和已生成的 Token 序列 y < t y_{<t} y<t。即 s t = ( x , y 1 , . . . , y t − 1 ) s_t = (x, y_1, ..., y_{t-1}) st=(x,y1,...,yt−1)。
动作 (Action, a t a_t at):模型在当前时间步生成的下一个 Token y t y_t yt。
策略 (Policy, π θ \pi_\theta πθ):即我们的大语言模型。 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st) 对应模型在当前上下文下预测下一个 Token 的概率分布。
奖励 (Reward, R R R):通常在整个回答生成完毕(Episode 结束)后,由奖励模型给予一个标量反馈 R ( x , y ) R(x, y) R(x,y)。中间步骤的奖励通常为 0。
2.2 RLHF 的核心步骤
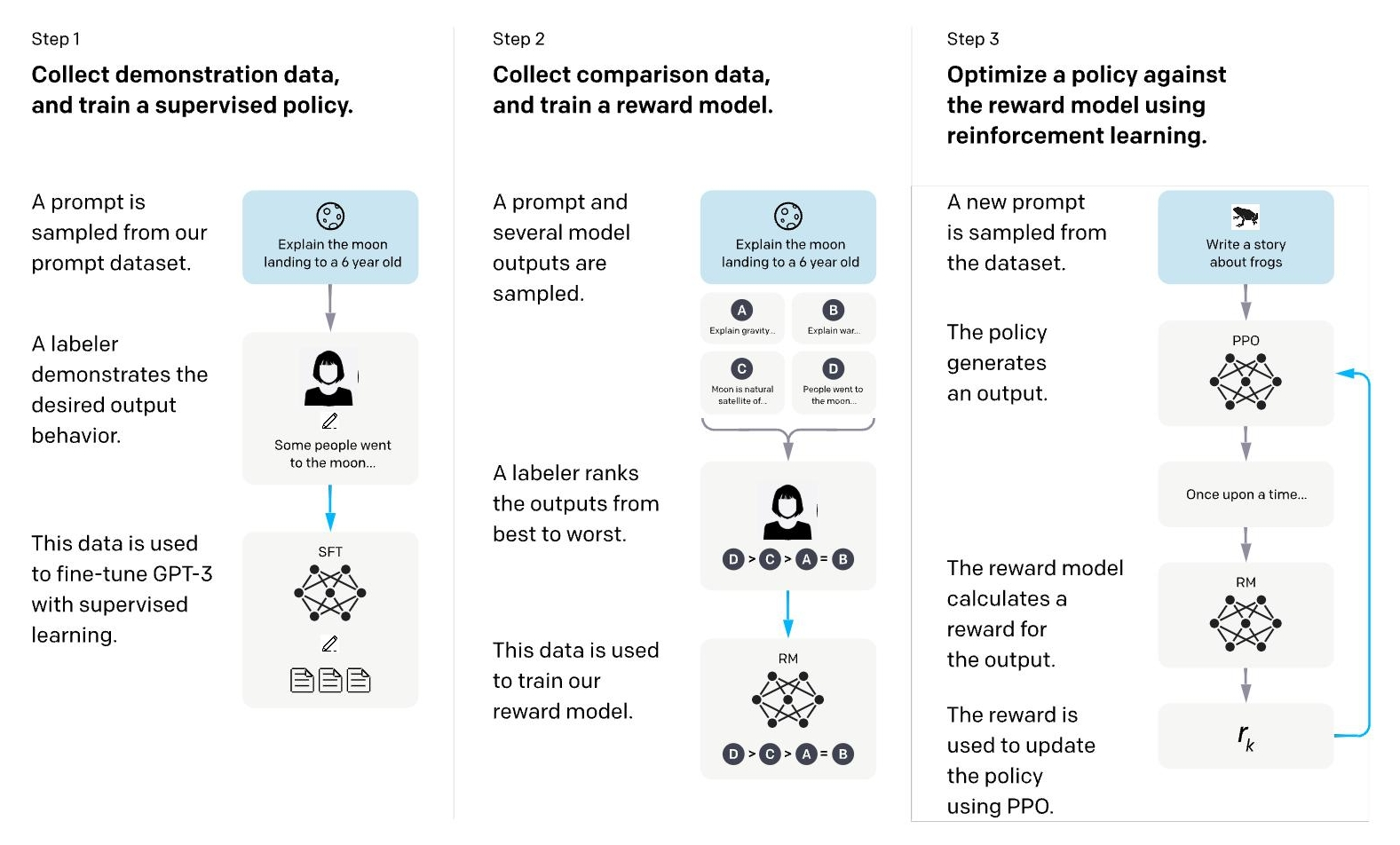
RLHF的流程主要包含 三个核心 步骤:
- 通过有监督微调得到初始策略模型;
- 收集人类偏好数据训练一个奖励模型;
- 使用奖励模型作为信号,通过强化学习算法(如 PPO)进一步优化策略模型。
三、LLaMA-Factory RLHF(DPO)实战
-
相比于传统的
PPO,DPO省去了训练 独立的奖励模型(Reward Model) 和复杂的 强化学习采样过程,直接在偏好数据上优化策略,更加稳定且高效。 -
本节使用开源社区流行的微调框架
LLaMA-Factory,配合阿里发布的轻量级指令模型Qwen2.5-0.5B-Instruct,在单张消费级显卡(甚至 CPU)上跑通DPO对齐流程。
3.1 LLaMA-Factory 介绍
-
LLaMA-Factory 是一个简洁高效的大型语言模型(Large Language Model)训练与微调平台,旨在让开发者能够"零代码"地完成大模型的定制化训练。它具有以下特点:
- 广泛的模型支持:支持业界主流的开源模型,如 LLaMA、Qwen(通义千问)、Baichuan(百川)、ChatGLM、Mistral、Yi 等。
- 全流程覆盖:涵盖了从 预训练(Pre-Training)、指令监督微调(SFT) 到 RLHF(包含奖励模型建模、PPO、DPO、KTO、ORPO 等)的完整训练阶段。
- 高效的微调技术:内置了 LoRA、QLoRA、DoRA、GaLore 等多种参数高效微调(PEFT)方法,大幅降低了显存需求。
- 易用的交互界面:提供名为 LLaMA-Board 的 Web UI 界面,通过可视化操作即可配置训练参数、监控训练进度以及进行模型对话测试。
- 硬件友好:支持 DeepSpeed、FlashAttention 等加速技术,并支持 4-bit/8-bit 量化训练,使得普通消费级显卡也能运行大模型训练。
3.2 环境搭建
shell
# 克隆 LLaMA-Factory 仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git- 使用本地python环境,推荐 3.12
- 进入 LLaMA-Factory 目录
python
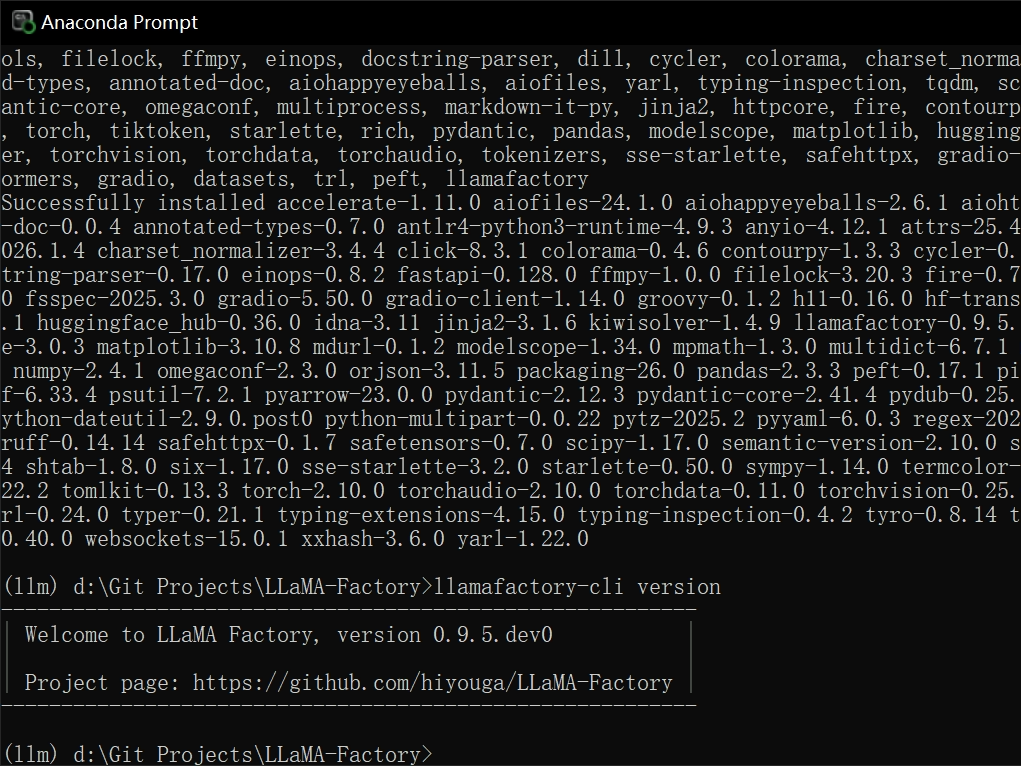
# 安装依赖
pip install -e .[metrics]
# 验证安装
llamafactory-cli version- 可以看到如下输出
- 使用 Web UI
python
# 启动 Web UI
llamafactory-cli webui- 自动启动浏览器
3.3 训练准备
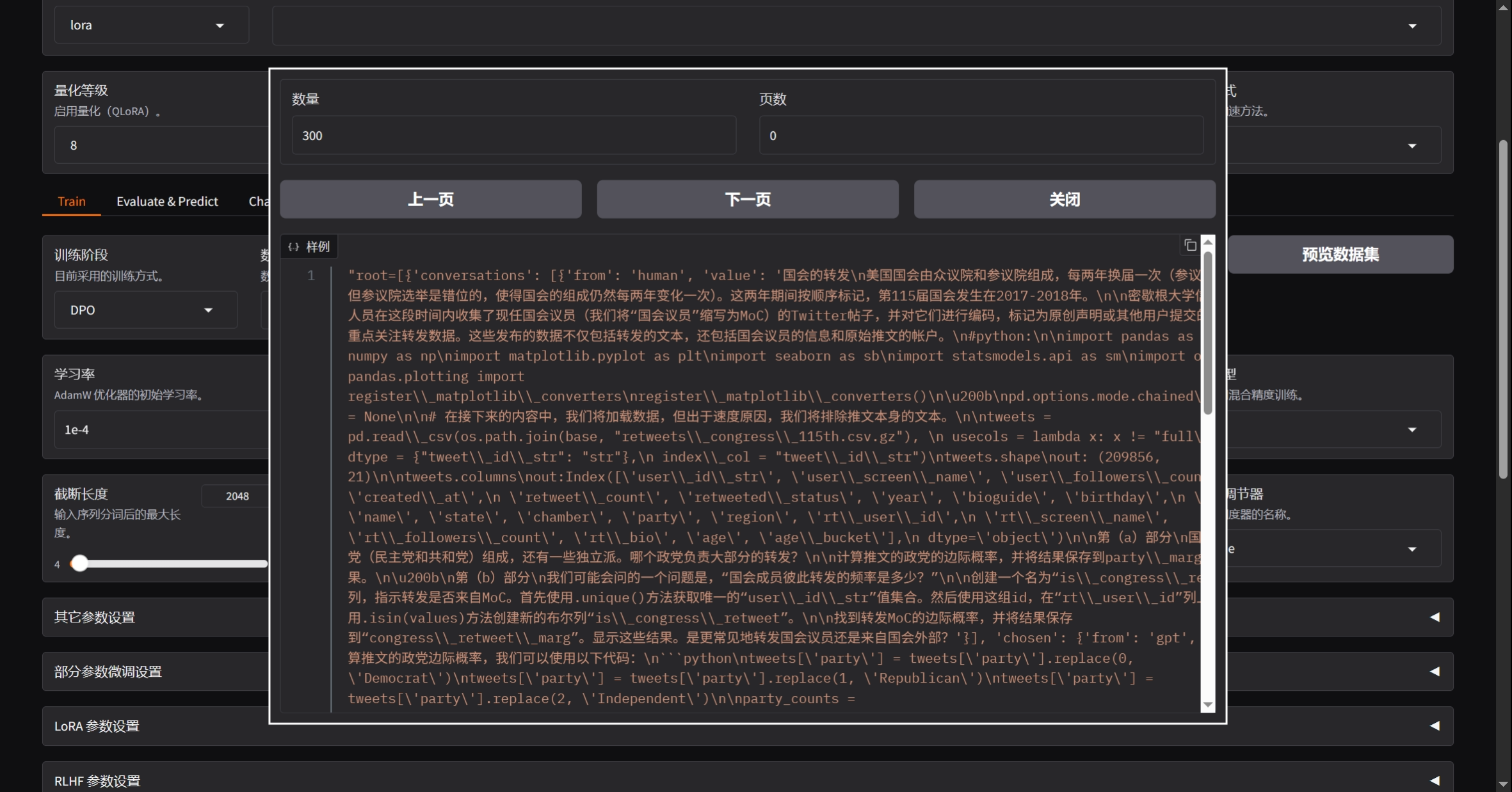
- 预览数据集
- 预览命令
python
llamafactory-cli train `
--stage dpo `
--do_train True `
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct `
--preprocessing_num_workers 16 `
--finetuning_type lora `
--template qwen `
--flash_attn auto `
--dataset_dir data `
--dataset dpo_zh_demo `
--cutoff_len 2048 `
--learning_rate 0.0001 `
--num_train_epochs 3.0 `
--max_samples 100000 `
--per_device_train_batch_size 1 `
--gradient_accumulation_steps 8 `
--lr_scheduler_type cosine `
--max_grad_norm 1.0 `
--logging_steps 5 `
--save_steps 100 `
--warmup_steps 0 `
--packing False `
--enable_thinking True `
--report_to none `
--output_dir saves\Qwen2.5-0.5B-Instruct\lora\train_2026-01-26-20-39-04 `
--bf16 True `
--plot_loss True `
--trust_remote_code True `
--ddp_timeout 180000000 `
--include_num_input_tokens_seen True `
--optim adamw_torch `
--quantization_bit 8 `
--quantization_method bnb `
--double_quantization True `
--lora_rank 8 `
--lora_alpha 16 `
--lora_dropout 0 `
--lora_target all `
--pref_beta 0.1 `
--pref_ftx 0 `
--pref_loss sigmoid