系列专栏------机器学习入门系列,持续更新,收藏点赞关注不迷路;
目录
[2.1 欧式距离](#2.1 欧式距离)
[2.2 曼哈顿距离](#2.2 曼哈顿距离)
[2.3 切比雪夫距离](#2.3 切比雪夫距离)
[三、 KNN算法API介绍](#三、 KNN算法API介绍)
[3.1 KNN 分类API](#3.1 KNN 分类API)
[3.2 KNN 回归API](#3.2 KNN 回归API)
[4.1 归一化处理](#4.1 归一化处理)
[4.2 数据标准化](#4.2 数据标准化)
[5.1 实现流程如下](#5.1 实现流程如下)
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。后续会补一章(入门(0)-介绍重点概念)
一、KNN算法简介
K-近邻算法(K Nearest Neighbor,简称KNN)。
算法思想: 如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别
**思考:**如何确定相似性?
**答:**使用样本"距离"来确定,距离包括有欧氏距离、曼哈顿距离、切比雪夫距离;
首先我们来先了解几个概念:
**样本相似性:**样本都是属于一个任务数据集的。样本距离越近则越相似。
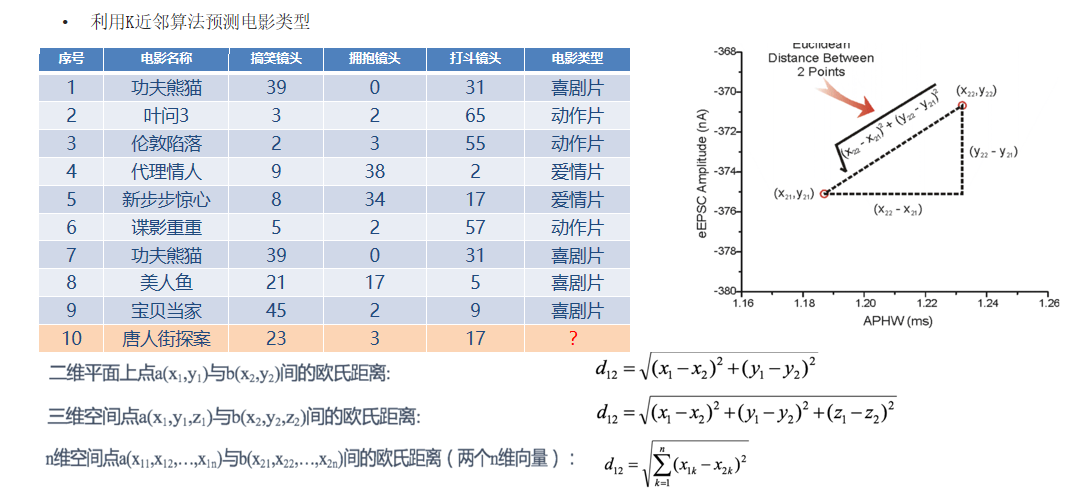
根据以上公式,我们计算未知样本与其它样本之间的距离,假设K=5:则选取距离样本10最近的5个样本,进行投票选举,喜剧类占多数,因此,样本10也被归为喜剧类。
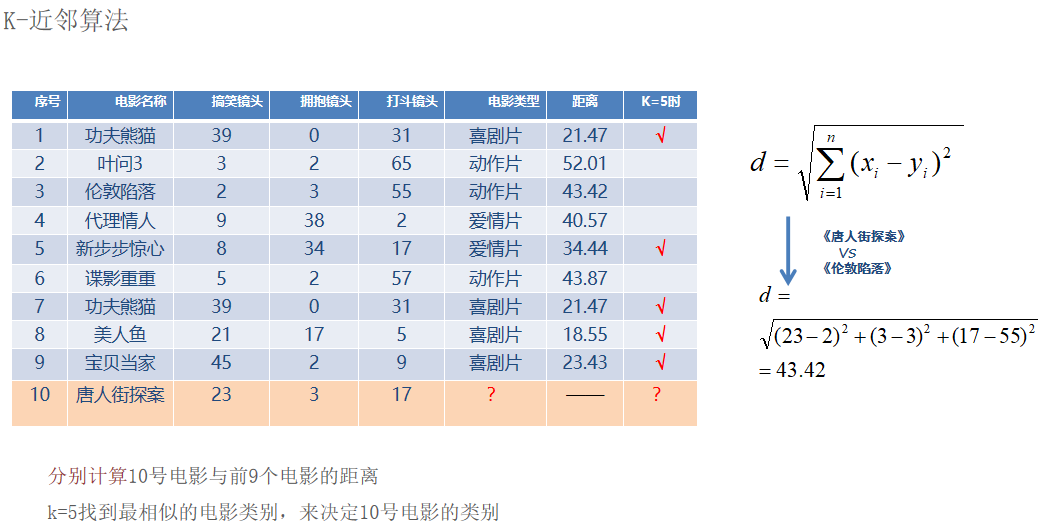
注意K值的选择:


二、样本距离度量方式
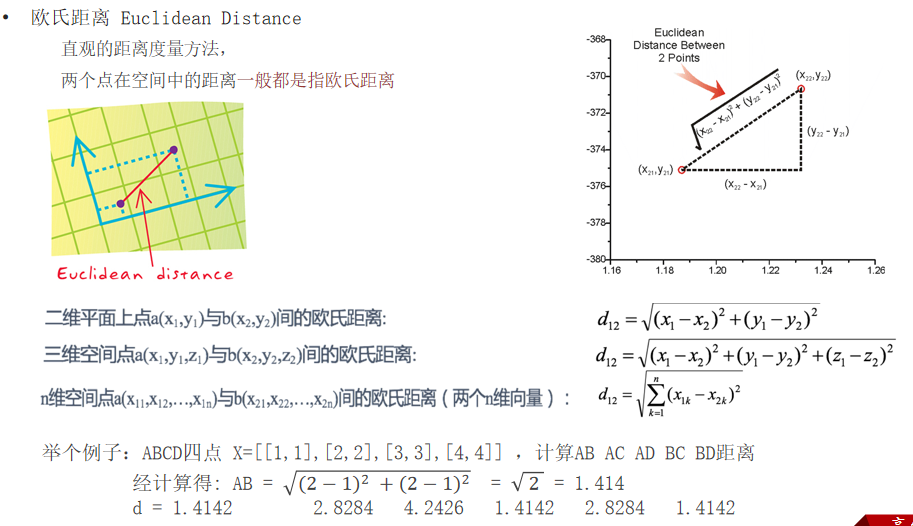
2.1 欧式距离
**欧氏距离(Euclidean Distance):**两点之间的直线距离长度
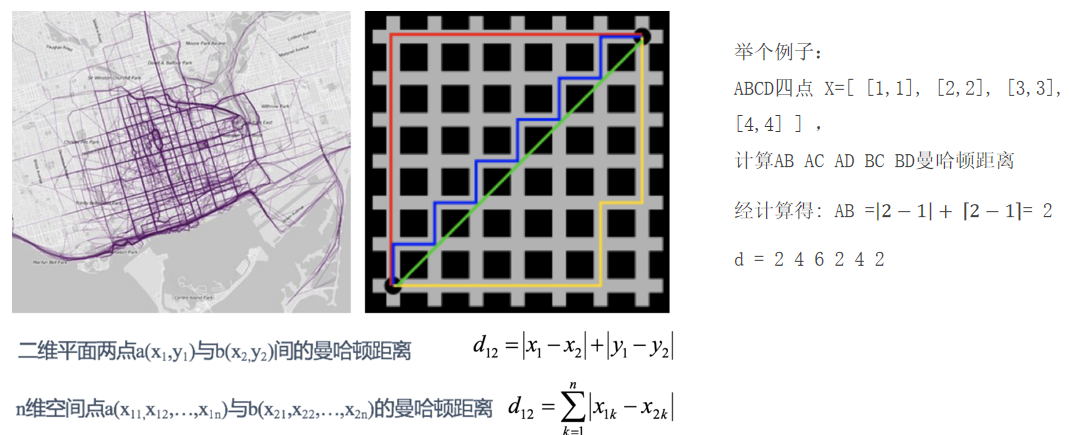
2.2 曼哈顿距离
**曼哈顿距离(Manhattan Distance):**也称为"城市街区距离"(City Block distance),曼哈顿城市特点:横平竖直
2.3 切比雪夫距离
**切比雪夫距离 Chebyshev Distance:**国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。 国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。

总结
直接上图

三、 KNN算法API介绍
3.1 KNN 分类API
**语法:**sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
**n_neighbors:**int,可选(默认= 5),k_neighbors查询默认使用的邻居数

3.2 KNN 回归API
**语法:**sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)

四、特征预处理
特征预处理的方式包括两种:归一化和标准化(常用)
为什么做归一化和标准化 ?
答: 特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,**容易影响(支配)目标结果,使得一些模型(算法)无法学习到其它的特征。**如下图的体重;
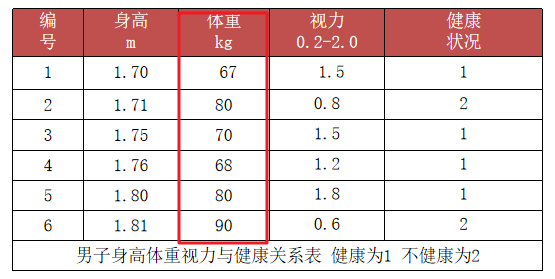
4.1 归一化处理
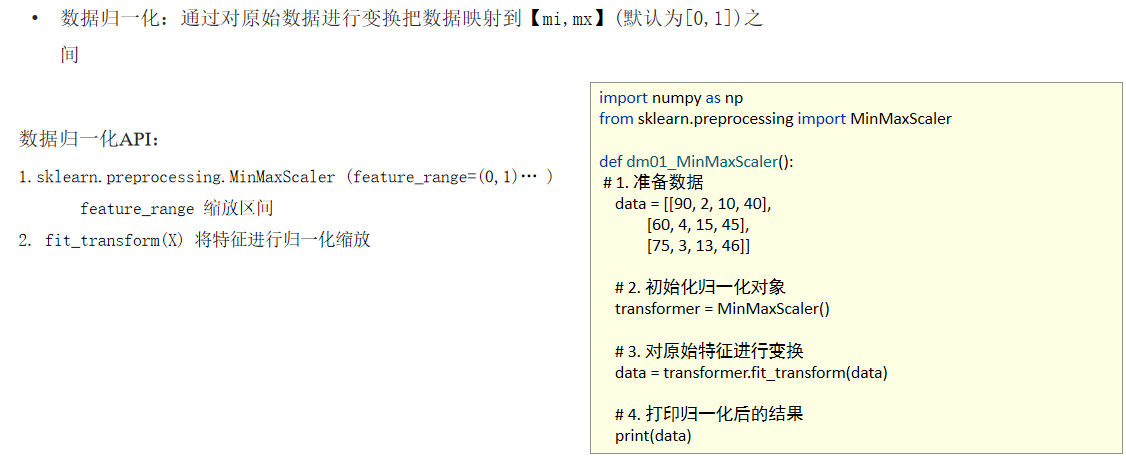
**归一化:**通过对原始数据进行变换把数据映射到【mi,mx】(默认为0,1)之间

数据归一化特点:
-
如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
-
**应用场景:**最大值与最小值非常容易受异常点影响,鲁棒性较差,只适合传统精确小数据场景
-
**API接口:**sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)... )
4.2 数据标准化
数据标准化:通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据。

数据标准化特点:
-
如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
-
**应用场景:**适合现代嘈杂大数据场景。
-
**API接口:**sklearn.preprocessing.StandardScaler( )
五、鸢尾花综合案例
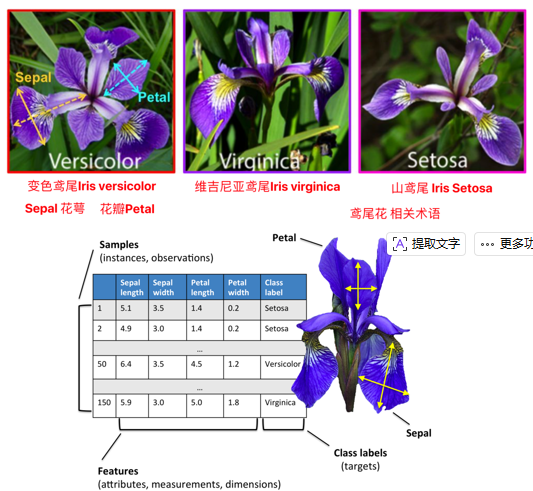
5.1 实现流程如下
先导入需要的包:
python
# 导包
import pandas as pd
# todo 数据分割
from sklearn.model_selection import train_test_split
# todo 数据标准化
from sklearn.preprocessing import StandardScaler
# todo 导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
# todo 模型评估分数
from sklearn.metrics import accuracy_score- 导入数据
python
my_irlr_data = pd.read_csv('data/iris.csv',sep=',',names=['花萼长','花萼宽','花瓣长','花瓣宽','标签'])- 数据预处理
python
# 划分数据,讲数据划分为训练集和测试集
X_train, X_test, y_train, y_test = (
train_test_split(my_irlr_data.loc[:,'花萼长':'花瓣宽'],my_irlr_data['标签']
,train_size=0.2,random_state=666,shuffle=True))
# 数据标准化
ss_model = StandardScaler()
x_train = ss_mode.fit_transform(X_train)
x_test = ssmode.transform(X_test)- 模型训练
python
mode = KNeighborClassifier(5)
pred = mode.fit(x_train)- 模型测试
python
y_pre = KNN_mode.predict(x_test)- 模型预测
python
y_pre = KNN_mode.predict(x_test)
acc = accuracy_score(y_test,y_pre)
print(f'准确率:{acc}')总结
以上就是今天要讲的内容,本文主要讲解机器学习的入门案例知识;后续将会持续更新,请大家多多关注;若有不懂的可以随时问博主或者AI。