1、Embedding和Reranker
Embedding 阶段
核心目标是快速召回,从海量候选集中筛选出 Top-K 相关内容,要求速度快,通常是双塔架构。
对于双塔结构,其实本质上是说有一个并行的网络结构,结构上是两个独立的子网络(塔),分别处理 查询(Query)和候选(Candidate) 的特征,最后通过向量相似度(如内积、余弦相似度)计算匹配分数。
xml
Query → [塔1:Encoder] → Query Embedding
↘
相似度计算(内积/余弦) → 匹配分数
↗
Candidate → [塔2:Encoder] → Candidate Embedding核心特点
双塔独立,无交叉:Query 和 Candidate 的特征在 Embedding 阶段完全分开处理,两个塔的参数互不干扰,仅在最后一步计算相似度。
支持离线预计算(核心优势),候选集(如文档、商品、向量库中的数据)的 Embedding 可以提前离线计算好,存入向量数据库。
线上推理时,只需要实时计算 Query 的 Embedding,再和向量库中的候选 Embedding 做相似度检索,速度极快(毫秒级)。
牺牲精度换速度,因为缺少 Query 和 Candidate 的深层特征交互,匹配精度相对单塔较低,适合召回阶段。
广泛应用
其实已经广泛应用在许多场景,也是Faiss等向量检索库的存在基础。
Reranker 阶段
核心目标是精准排序,对召回的少量候选集做精细化打分,要求精度高,通常是单塔架构。
xml
Query特征 + Candidate特征 → [单塔:Shared Encoder] → 特征交叉 → 全连接层 → 匹配分数核心特点
特征深度交叉(核心优势),Query 和 Candidate 的特征从输入层就开始融合,模型可以学习到两者的复杂关联(比如 Query 中的关键词和 Candidate 中上下文的依赖关系),匹配精度远高于双塔。
不支持离线预计算:必须同时输入 Query 和 Candidate 才能计算分数,无法提前缓存 Candidate 的特征。线上推理时,需要对召回的每个候选集都和 Query 一起输入模型计算,速度较慢(适合小批量数据)。
牺牲速度换精度:计算成本高,适合排序阶段(对召回的 Top-K 候选集做精准排序)。
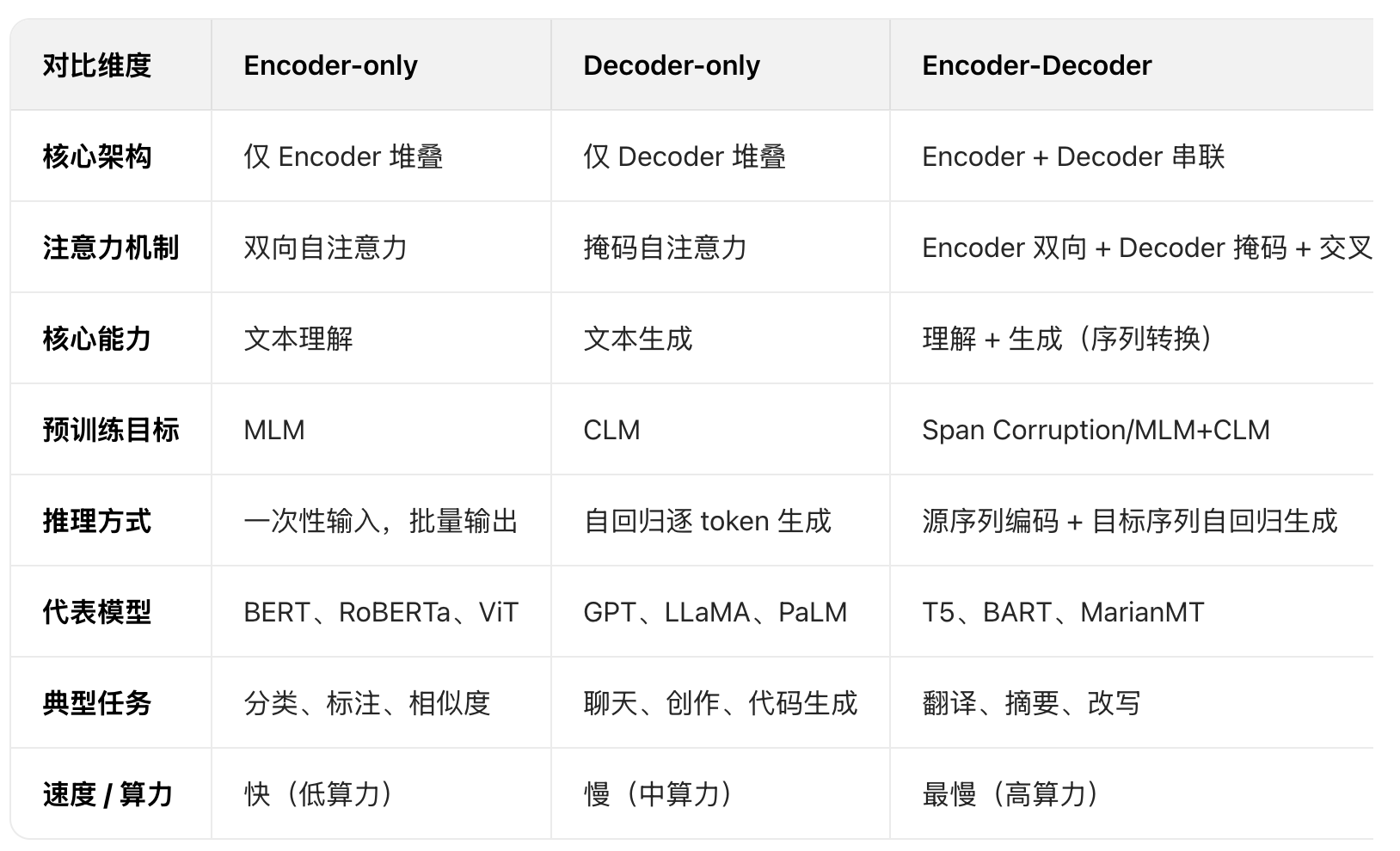
2、BERT(Bidirectional Encoder Representations from Transformers)
Google 于 2018 年提出的预训练语言模型,核心创新是基于 Transformer Encoder (Encoder-only)实现的双向上下文建模,彻底解决了传统预训练模型(如 ELMo 单向、GPT 左到右)无法同时利用左右上下文的问题,在文本分类、命名实体识别、问答等 NLP 任务上实现了性能突破。
2.1、BERT 的核心特性
BERT 仅使用 Encoder,每个 token 能同时关注到左右两侧的上下文信息(比如理解 "苹果" 是水果还是公司,需要依赖前后文)。
-
预训练任务设计
MLM(Masked Language Model):随机掩盖输入中 15% 的 token,让模型预测被掩盖的 token,强制模型学习上下文语义。
NSP(Next Sentence Prediction):让模型判断两个句子是否为连续的上下文(比如句子 A 是 "今天天气很好",句子 B 是 "我们去公园散步" 为连续;句子 B 是 "猫喜欢吃鱼" 为不连续),学习句子级语义。
-
模型规模
原始 BERT 提供两个版本:
BERT-Base:12 层 Transformer Encoder,768 维隐藏层,12 个注意力头,约 1.1 亿参数。
BERT-Large:24 层 Transformer Encoder,1024 维隐藏层,16 个注意力头,约 3.4 亿参数。
2.2 BERT 的输入向量组成
BERT 的输入是经过特殊处理的 token 序列,最终输入到模型的向量是 3 种向量的逐元素相加,具体组成如下:
-
基础输入:Token Embeddings(词嵌入向量)
作用:将每个离散的 token 转换为低维稠密向量,是输入的基础语义表示。
生成方式:
对输入文本做 WordPiece 分词(解决未登录词问题,比如 "打篮球" 可能被切分为 "打""篮球";"Transformer" 是一个完整 token)。
每个 token 对应预训练好的词嵌入矩阵中的一个向量(维度与模型隐藏层一致,如 BERT-Base 为 768 维)。
特殊 token:BERT 定义了 3 个核心特殊 token,必须加入输入序列:
CLS:句子的分类标记,放在输入序列的最开头,其对应的输出向量常用于下游分类任务(如文本分类的类别判断)。
SEP:分隔标记,用于分隔两个句子(如 NSP 任务、问答任务中的问题和上下文)。
MASK:掩码标记,仅用于预训练阶段,替换被掩盖的 token。
示例(句子对输入):
plaintext
原始句子对:句子1"我爱中国",句子2"中国很美丽"
分词后序列:CLS 我 爱 中国 SEP 中国 很 美丽 SEP
-
位置编码:Position Embeddings(位置嵌入向量)
作用:Transformer Encoder 是无序的(仅通过注意力机制建模 token 关系,没有内置的位置信息),因此需要显式加入位置编码,让模型知道每个 token 在序列中的位置。
生成方式:
BERT 使用 可学习的位置嵌入(区别于原始 Transformer 的正弦余弦位置编码)。
位置嵌入的维度与 Token Embeddings 一致(768 维),每个位置( BERT 最大输入长度 512,可能)对应一个唯一的可学习向量。
无论输入序列多长,位置编码的索引从 0 开始递增,超过最大长度会被截断。
-
句子编码:Segment Embeddings(句子嵌入向量)
作用:用于区分输入序列中的不同句子(仅在句子对任务中需要,如 NSP、问答)。
生成方式:
是可学习的向量,维度同样为 768 维。
定义两个句子类型:A 和 B:
第一个句子(含 CLS)的所有 token 对应 Segment A 向量;
第二个句子的所有 token 对应 Segment B 向量;
若输入是单句子,所有 token 都使用 Segment A 向量。
-
BERT 输入向量的最终计算
BERT 的输入向量是 Token Embeddings + Position Embeddings + Segment Embeddings 的逐元素相加,公式如下:
Input_Vec=Token_Emb+Pos_Emb+Seg_Emb
三个向量的维度完全相同(如 768 维),相加后得到最终的输入表示,送入 Transformer Encoder 进行编码。
注意:是逐元素相加,不是拼接(拼接会导致维度翻倍,增加计算量)。
3、T5(Text-to-Text Transfer Transformer)
Google 于 2019 年提出的 Encoder-Decoder 架构预训练语言模型,其核心创新是将所有 NLP 任务统一为 "文本到文本" 的格式,打破了理解类任务与生成类任务的界限,实现了真正的通用任务适配。不同于 Encoder-only(如 BERT)专注理解、Decoder-only(如 GPT)专注生成,T5 采用完整的 Transformer Encoder-Decoder 结构,兼顾了语义理解和文本生成能力,在翻译、摘要、问答、分类等数十种 NLP 任务上都取得了优异效果。
3.1、 T5 的核心设计理念
T5 的核心思想是:No Task is Special(没有任务是特殊的)。
传统 NLP 任务需要针对不同任务设计不同的输出形式(如分类任务输出标签 ID、翻译任务输出目标文本),而 T5 把所有任务都转化为 "输入文本 → 输出文本" 的形式,仅通过在输入中添加任务前缀来区分任务类型。
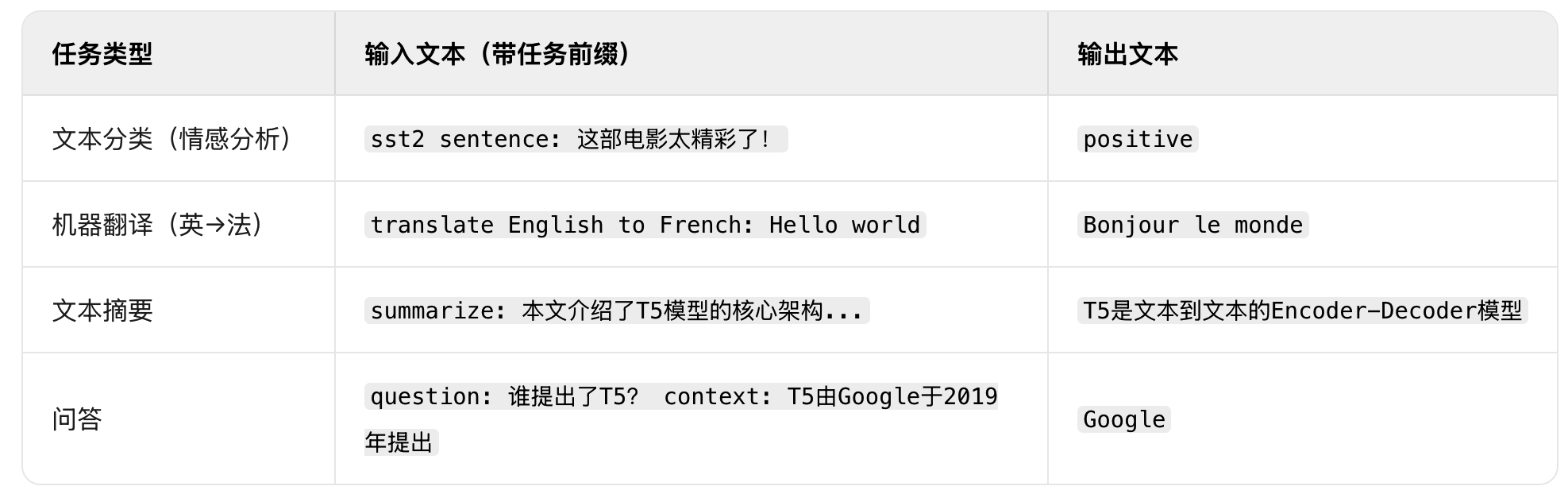
示例:不同任务的文本到文本转化,模型设计的优势在于:模型不需要为不同任务设计不同的输出头,预训练和微调的目标完全一致,都是 "生成目标文本"。
3.2、 T5 的模型架构
T5 采用 标准的 Transformer Encoder-Decoder 结构,由 Encoder、Decoder 两部分组成,且两者均为多层堆叠的 Transformer 块:
- Encoder 部分(编码器)
作用:对输入文本(含任务前缀)进行双向上下文编码,生成源文本的语义表示向量。
结构:每层包含 双向自注意力层 + 前馈神经网络(FFN)。
双向自注意力:输入序列的每个 token 可以关注到左右所有 token,充分理解上下文语义(与 BERT 一致)。
归一化与残差连接:每个子层都配有 Layer Normalization 和残差连接,提升训练稳定性。 - Decoder 部分(解码器)
作用:基于 Encoder 输出的语义表示,自回归生成目标文本。
结构:每层包含 3 个子层,顺序为:
掩码自注意力层:确保生成 token 时只能看到左侧已生成的 token(与 GPT 一致,防止信息泄露)。
Encoder-Decoder 注意力层:解码器的每个 token 可以关注到编码器输出的所有源文本 token(核心是建立输入与输出的关联,比如翻译任务中对齐源语言和目标语言的词汇)。
前馈神经网络(FFN):对注意力输出做非线性变换。
3.3、 T5 的预训练目标:Span Corruption
T5 摒弃了 BERT 的 MLM(掩码语言模型)和 GPT 的 CLM(因果语言模型),采用了全新的预训练目标 ------Span Corruption(片段破坏),更贴近 "文本到文本" 的任务范式。
Span Corruption 的具体流程
随机选择输入文本中的连续片段:比如从句子 T5 is a text-to-text model 中随机选择连续的 2 个 token text-to-text。
用一个特殊 token 替换该片段:特殊 token 的格式为 <extra_id_0>,替换后句子变为 T5 is a <extra_id_0> model。
让模型预测被替换的片段内容:模型的输出目标是 <extra_id_0> text-to-text,即先输出特殊 token,再输出被破坏的片段。
核心优势
相比 MLM 只替换单个 token,Span Corruption 替换连续片段,更能训练模型理解文本的短语级、句子级语义。
预训练目标与下游任务的 "文本到文本" 格式完全一致,减少了预训练到微调的鸿沟。
4、CLIP(Contrastive Language-Image Pre-training)
OpenAI 于 2021 年提出的革命性多模态模型,核心是通过对比学习让图像与文本编码器在同一向量空间对齐,实现零样本分类、跨模态检索等能力。模型架构主要依赖的是双编码器 + 统一嵌入空间。CLIP 由图像编码器和文本编码器两部分组成,两者独立训练但输出向量映射到同一高维空间,结构如下:

核心应用
内容检索:电商商品图搜、视频字幕匹配、学术论文图文检索。
内容审核:图文一致性校验,识别违规图文配对。
多模态交互:智能相册分类、AI 绘画提示优化、机器人视觉语义理解。
衍生模型
FLIP:优化训练效率,降低算力成本;
BLIP:融合生成式能力,提升图文生成与理解精度;
CLIP ViT-L/14-336px:更高分辨率输入,提升细粒度识别能力。
5、Decoder和encoder 架构图
Transformer 的原始架构(《Attention Is All You Need》)由 Encoder(编码器) 和 Decoder(解码器) 两部分组成,两者的核心差异在于注意力层是否有mask层。
Decoder-only 成为大模型主流:GPT、LLaMA 等模型证明,足够大的参数量 + 海量数据能让 Decoder-only 模型兼具理解与生成能力,成为通用大语言模型的首选架构。
Encoder-Decoder 向轻量化演进:通过参数共享、知识蒸馏等技术降低算力开销,专注于高精度序列转换任务。
多模态融合:三大范式均向多模态扩展(如 CLIP 的 Encoder-only、GPT-4 的 Decoder-only、Flamingo 的 Encoder-Decoder),实现图文、音视频的统一建模。