目录
[2. LLM工程化挑战](#2. LLM工程化挑战)
[2.1. 自然语言(NLP)歧义](#2.1. 自然语言(NLP)歧义)
[2.2. 成本和延迟](#2.2. 成本和延迟)
[2.3. 提示、微调、替代方案](#2.3. 提示、微调、替代方案)
[3. 任务组合性](#3. 任务组合性)
[3.1. 代理、工具和控制流](#3.1. 代理、工具和控制流)
[3.2. 测试代理](#3.2. 测试代理)
1.回顾LLM原理
上节链接:https://blog.csdn.net/m0_62102955/article/details/157247515?spm=1001.2014.3001.5502
在上一节中,我们从Transformer入手,基于从最基本的自注意力机制学起,逐步深入学习大模型机理,对于LLM(Decoder-Only Transformer),其本质可分为以下步骤:
词元生成(Tokenization):将原始句子切分为一系列词元(tokens),并映射为对应的 token ids。不同语言、不同 tokenizer 的切分结果可能不同,词元序列长度也会随之变化。
词元嵌入(Embedding):将 token ids 查表映射为 Token Embedding 向量,同时引入位置信息(Position Embedding 或 RoPE 等位置编码机制)。这一阶段得到的表示既包含"词元是什么",也包含"它在序列中的位置"。
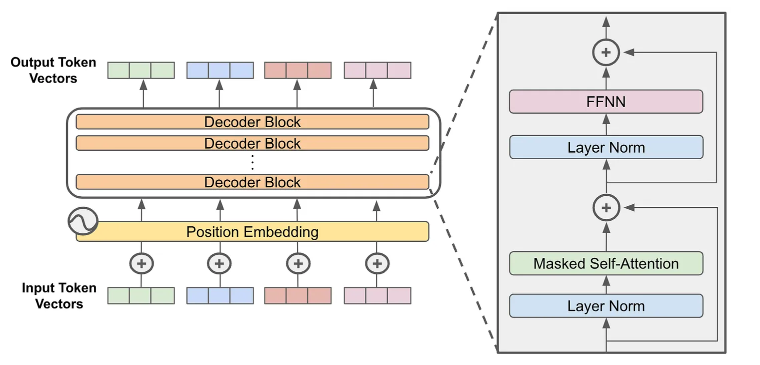
掩码自注意力(Masked Self-Attention):在 Decoder-only 架构中,为保证自回归生成,第 ttt 个位置在计算注意力时只能使用当前位置及其之前的内容
,不能"看到"未来位置
前馈网络(FFN/MLP):注意力子层负责在序列范围内进行信息检索与融合(决定"从哪里取信息"),而 FFN 对每个位置的表示进行独立的非线性加工与特征重组(决定"如何把信息加工成更有用的特征")。FFN 不会学习掩码本身;掩码是注意力中的结构约束。FFN 只是基于注意力与残差路径传递过来的表示,在"只能利用历史信息"的条件下不断适应并提升对下一词预测的表征能力。
这一节我们将聚焦LLM的工程化,系统性的获取相关知识,明确LLM工程化的问题和技术,为后续的深入设计和研究打下基础。
参考内容: https://huyenchip.com/2023/04/11/llm-engineering.html?utm_source=chatgpt.com
2. LLM工程化挑战
2.1. 自然语言(NLP)歧义
在计算机发展的大部分历史中,工程师们都是用编程语言编写指令的。编程语言"大多"是精确的。歧义会令开发者感到沮丧,甚至产生强烈的厌恶感(想想Python或JavaScript中的动态类型)。
在即时响应式设计中,指令是用自然语言编写的,这比编程语言灵活得多。这可以带来良好的用户体验,但却可能导致糟糕的开发者体验。
这种灵活性来自两个方面:用户如何定义指令,以及 LLM 如何响应这些指令。
首先,用户自定义提示符的灵活性会导致静默失败。如果有人不小心修改了代码,例如添加了一个随机字符或删除了一行,程序很可能会报错。但是,如果有人不小心更改了提示符,程序仍然会运行,但输出结果会截然不同。
用户自定义提示的灵活性固然令人烦恼,但LLM生成的响应的歧义性却可能成为致命缺陷。这会导致两个问题:
(1)输出格式不明确
基于 LLM 的下游应用程序需要特定格式的输出才能进行解析。我们可以编写明确的提示信息来指定输出格式,但无法保证输出始终 遵循此格式。 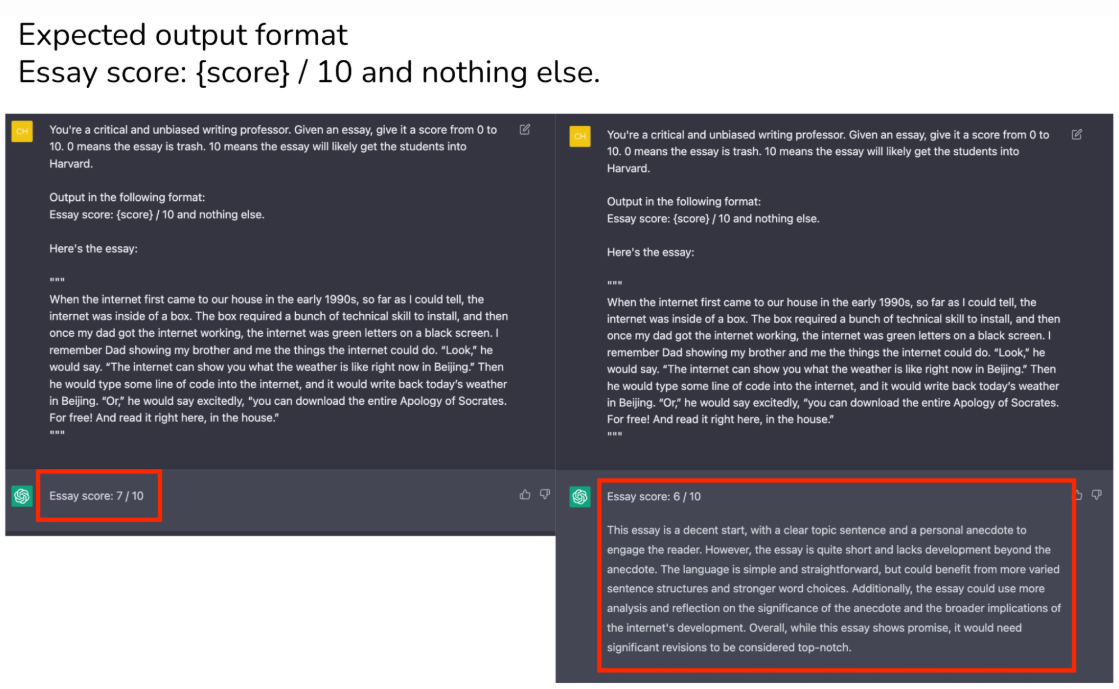
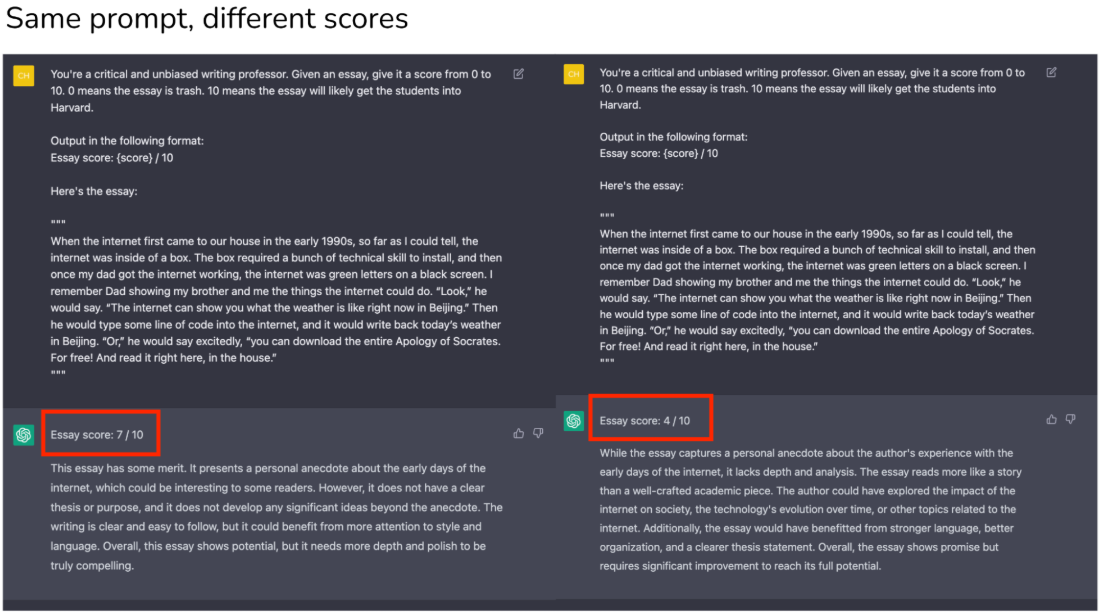
正如上图所示,同样输入一个essay(散文)进行打分。用户期望输出格式是:散文分数,满分为10分,并且不要其他任何东西。而输出可能符合要求,而有些可能存在其他内容。
虽然这种情况在现在的一些模型已经基本不会出现这种状况,比如GPT-5,Gemini-3.2等,但是对于长期记忆(long-tem memory),仍然存在输出格式不明确的问题。比如,这个打分要求已经反馈给LLM时间很长了,后面就算是一直输入essay,也会在某个时间点开始,不再符合要求。
(2)输出结果不确定
用户在使用应用程序时,期望获得一定的一致性。试想一下,每次您在保险公司网站上查询报价时,得到的报价都不一样。LLM 是随机的------无法保证每次输入相同数据时,LLM 都会给出相同的输出。
最简单的方式就是设置温度(temperature)为0来强制 LLM 给出相同的响应,但是这种方式会降低置信。想象一下,一位老师只有在特定的教室里才能给你一致的分数。如果这位老师在不同的教室里,他给你的分数就会千差万别。
如何解决这种歧义问题?
要缓解这种歧义,关键是把 LLM 当作非确定性组件,用工程闭环把不确定性"收口",而不是指望一次提示永远正确。
对于输出格式不明确:优先采用结构化输出(如 JSON/schema/函数调用),并在程序端做解析与校验,失败时触发"仅修格式"的重试或回退,避免静默失败。与此同时,要把"格式约束"纳入及时评估:用固定样例集做解析通过率与违约类型统计(多字段、缺字段、类型错误、夹带自然语言等),并对每次提示改动做回归测试,确保格式稳定性不因微小改动而退化。
对于输出结果不确定:通过明确的任务量表(rubric)和一致的提示模板减少自由度,配合采样参数控制(temperature/top-p 等),必要时用多次采样取中位数/投票并做二次核验,提高稳定性。这里同样需要"及时评估"来验证两点:一是模型是否真正理解 few-shot 示例(把示例回灌检查能否复现预期输出),二是是否对示例过拟合(用独立评估集计算 RMSE/一致性等指标)。一个实用技巧是让模型先生成"它认为会得到某个分数的样例",再回灌验证其评分边界是否自洽。
最后,为了让上述策略可持续落地,必须进行提示版本控制 与实验记录:对提示模板、示例集、评分量表、采样参数进行版本化管理,记录每个版本在固定评估集上的指标与失败样例分布。并在此基础上做持续优化:按需引入链式推理(CoT)、多次生成聚合(自洽性)、任务拆解等高收益技巧,但任何优化都应以离线评估与回归测试为前置门槛,确保系统在概率性前提下仍具备可控、可维护的一致行为。
2.2. 成本和延迟
(1)成本
用户输入内容提示越详细,模型性能(理论上)就越好,但是推理成本也会增加。
OpenAI API 会对输入和输出tokens(词元)都收费。根据任务的不同,一个简单的提示可能需要 300 到 1000 个词元。如果想要添加更多上下文信息,例如在提示中添加自己的文档或从互联网上检索的信息,那么仅提示本身就可能产生高达 1 万个词元。
冗长的提示所带来的成本不在于实验,而在于推断。
从实验角度来看,快速工程是一种成本低廉且快速启动项目的方法 。例如,即使您使用以下设置的 GPT-4,您的实验成本也仅略高于 300 美元。而传统的机器学习方法,例如数据收集和模型训练,通常成本更高,耗时更长。LLMOps 的成本在于推断。
Prompt: 10k tokens ($0.06/1k tokens)
Output: 200 tokens ($0.12/1k tokens)
Evaluate on 20 examples
Experiment with 25 different versions of prompts(2)延迟
输入标记可以并行处理,这意味着输入长度对延迟的影响不会太大。然而,输出长度会显著影响延迟,这可能是由于输出标记是按顺序生成的。
即使输入(51 个词元)和输出(1 个词元)都非常短, gpt-3.5-turbo的延迟也约为 500 毫秒。如果输出词元增加到 20 个以上,延迟将超过 1 秒。 
这其中包含了模型的延迟和网络延迟,而主要影响来源于网络延迟和低效工程开销,这个和模型本身关系不大,在硬件、网络等环境的提升下,延迟在未来将会显著降低。
虽然对于许多应用场景来说,半秒钟似乎很长,但考虑到模型的规模以及API使用范围,这个延迟还是不能被忽视的。
LLM的成本和延迟分析
成本与延迟的优化核心是"压缩无效输入、限制无用输出、把不确定性后移到可验证环节":能用结构化字段表达的就不要长篇解释,能用检索/缓存复用的就不要重复喂上下文,能用短步骤流水线解决的就不要一次生成大段文本。
2.3. 提示、微调、替代方案
**提示:**对于每个样本,明确告诉模型它应该如何响应
**微调:**训练一个模型来决定如何响应,这样就不必再提示中指定响应方式了
在考虑提示与微调时,主要有 3 个因素:数据可用性、性能和成本。
如果只有几个例子,提示功能可以快速轻松地上手。由于输入标记长度的限制,提示中可以包含的例子数量也有限制。
当然,微调模型以使其适应特定任务所需的样本数量取决于任务和模型本身。但根据经验,如果使用数百个样本进行微调,模型性能通常会有显著提升。然而,其效果可能不会比提示式训练好多少。
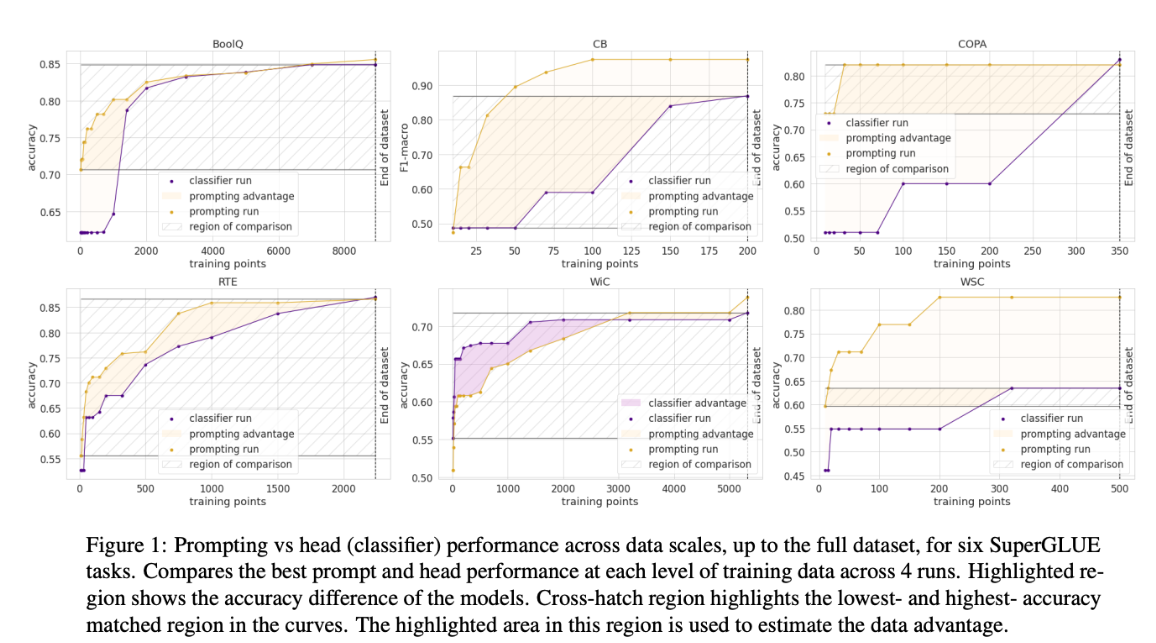
在https://arxiv.org/abs/2103.08493(2021)一文中,Scao 和 Rush 发现,一个提示大约相当于 100 个示例(注意:不同任务和模型之间的差异很大------见下图)。总体趋势是,随着示例数量的增加,微调比提示能带来更好的模型性能。用于微调模型的示例数量没有上限。
(1) 提示调优
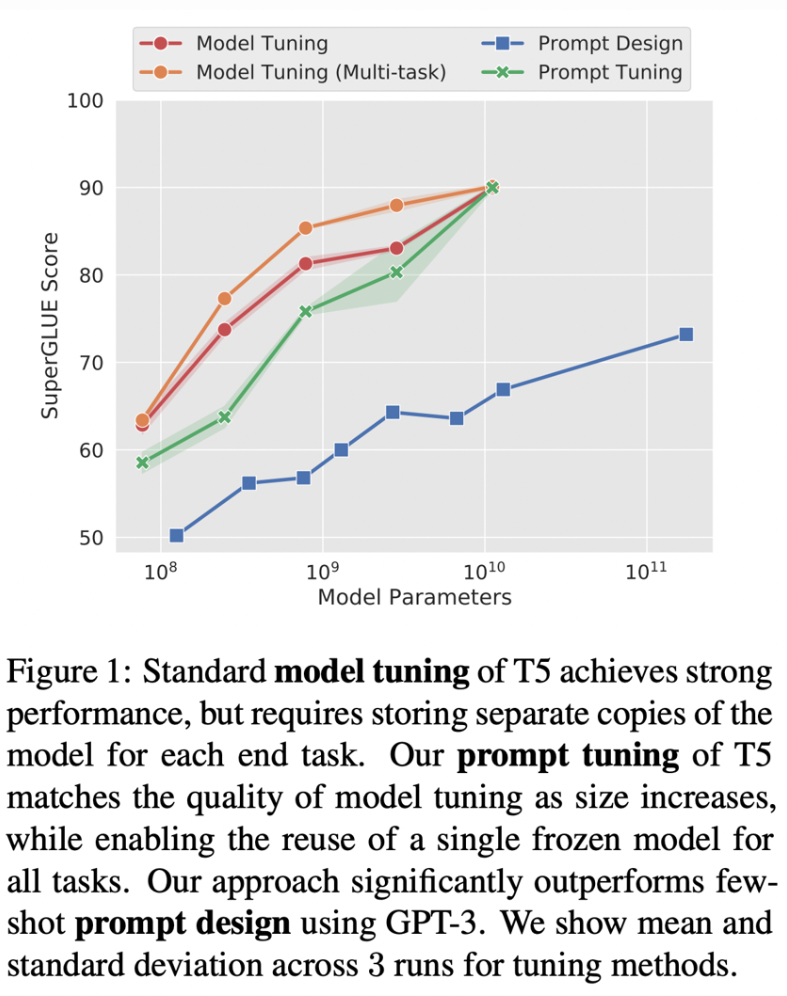
https://arxiv.org/abs/2104.08691介于提示和微调之间的一种巧妙方法,由 Leister 等人于 2021 年提出。该方法从提示开始,但并非直接修改提示本身,而是通过编程方式改变提示的嵌入向量。为了实现提示调优,需要能够将提示的嵌入向量输入到 LLM 模型中,并从中生成词元(token)。目前,这只能在开源 LLM 中实现,OpenAI API 尚不支持。在 T5 数据集上,提示调优的性能似乎远优于提示工程,并且可以赶上模型调优(见下图)。
(2)蒸馏调优
2023年3月,一群斯坦福大学的学生提出了一个很有前景的想法:利用一个更大的语言模型(text-davinci-003 ,拥有1750亿个参数)生成的样本,对一个较小的开源语言模型(LLaMA-7B,LLaMA的70亿参数版本)进行微调。这种训练小型模型来模仿大型模型行为的技术被称为"蒸馏"。最终得到的微调模型与text-davinci-003的行为相似,但体积更小,运行成本更低。
为了进行微调,他们使用了 52k 条指令,并将这些指令输入到text-davinci-003 中以获得输出,然后用这些输出来微调 LLaMa-7B。生成这些指令的成本低于 500 美元。微调的训练过程成本低于 100 美元。参见Stanford Alpaca:一种指令跟踪的 LLaMA 模型(Taori 等人,2023)。
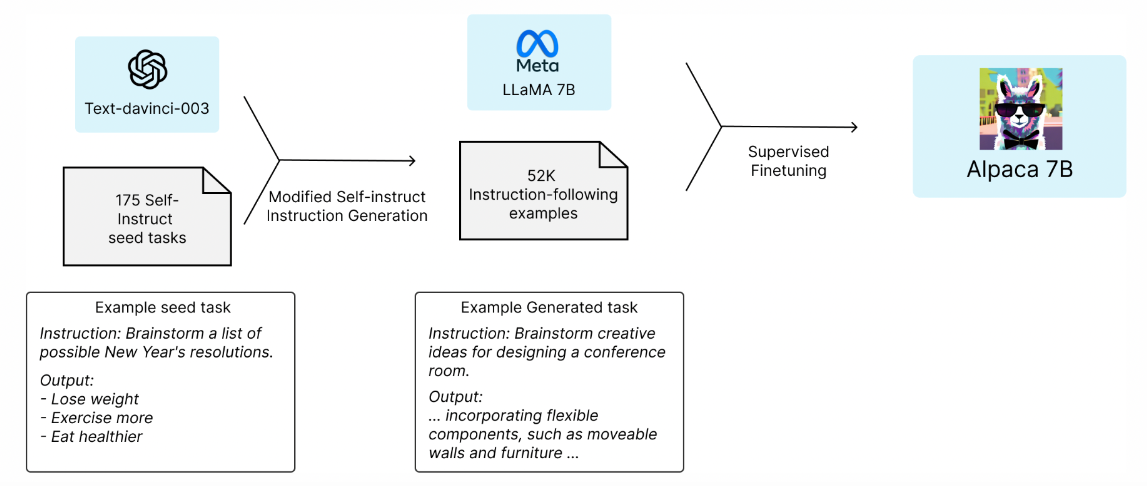
这种方法的吸引力显而易见。短短三周,他们的 GitHub 代码库就获得了近 2 万个 star!相比之下,HuggingFace 的 transformers代码库花了超过一年的时间才达到类似的 star 数量,而TensorFlow代码库则用了 4 个月。
3. 任务组合性
3.1. 代理、工具和控制流
代理(Agents): 值得是能够根据给定控制流(Control flows) 完成多任务的应用程序。一个任务可以利用一个或多个工具(Tools)。
**工具:**使用的程序或者功能,例如:SQL工具。
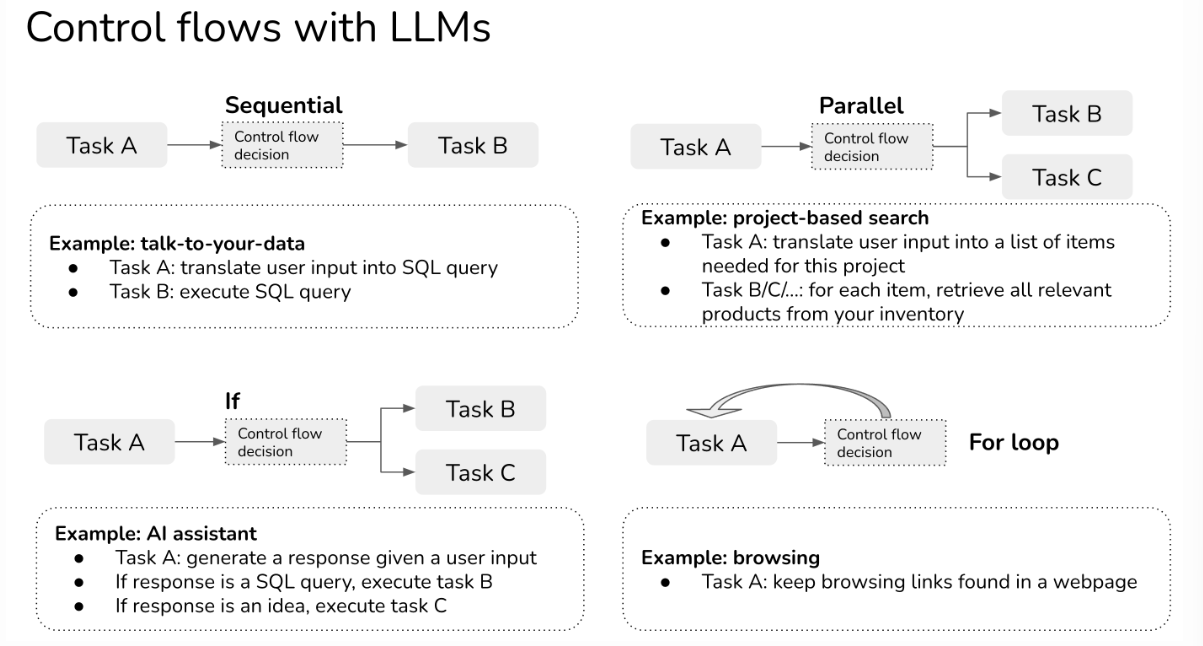
**控制流:**指一个任务按顺序执行。还有其他类型的控制流,例如并行控制流、if语句控制流和for循环控制流。
控制流从运行模式上分为四种:顺序、并行、选择和循环。
- A执行完才到B
- A和B并行
- A执行后根据判断结果决定执行C或B
- 不断执行A直到符合条件
3.2. 测试代理
为了保证代理的可靠性,我们需要在将它们组合起来之前,分别构建和测试每个任务。主要有两种故障模式:
(1)一项或多项任务失败。可能原因:
- 控制流程错误:选择了非可选操作。
- 一项或多项任务产生错误结果。
(2)所有任务都产生了正确的结果,但整体解决方案是错误的。
- Press 等人 (2022) 将此称为"可组合性差距":即模型在所有子问题都能正确回答的组合问题中所占的比例。
与软件工程类似,您可以而且应该对每个组件以及控制流进行单元测试。对于每个组件,您可以定义一些(input, expected output)评估示例,以便在每次更新提示或控制流时评估应用程序。您还可以对整个应用程序进行集成测试。
4.总结
在"应用"层面,LLM 落地通常不是单一对话,而是围绕若干高频场景形成可组合的任务链:消费端更集中在 AI 助手/聊天机器人 (日程、笔记、邮件、预订、购物等)以及 编程与游戏内容 (写代码、调试、生成玩法与角色对话),教育侧则覆盖 总结、出题、批改作文、讲题与辩论陪练 等学习辅助;企业侧最典型的是 Talk-to-your-data ,其常见工作流可抽象为"将内部知识组织成数据库(SQL/图/向量/文本)→把自然语言转成查询→执行查询→把结果再翻译成自然语言",并可扩展到客服/政策问答等场景;此外还有 搜索与推荐 的重构(先把用户模糊需求转为可检索的商品清单再检索匹配),以及围绕 销售文案与 SEO 的内容生产与博弈(内容生成更容易、搜索生态可能更嘈杂、品牌信任权重上升等)。 作为小结,需要把这些用例当作"系统工程"而非"提示技巧集合":应用仍在早期、API/基础设施/术语与成本延迟都在快速变化,许多今天看起来重要的提示微调技巧未必长期关键,因此更可持续的做法是建立自己的评估与迭代节奏------减少被噪音牵着走(过滤热点、只读高质量摘要),或通过持续上手新工具只关注"增量变化",以在快速演进中保持可用的工程判断与路线选择。