开篇介绍:
hello 大家,在上一篇博客中,我们共同了解了C++中的内存管理,并且掌握了new和delete的用法,同时还了解了它们与malloc。calloc、free的区别,不知道大家收获如何呢?
那么在本篇博客中,我们就要一起了解一下,C++中真真正正的牛波一的一个设计:模版,可以这么说,在模版还没出来之前,当时的人们还不是那么接受C++,但是当模版一问世,C++彻底席卷全球,扬名立万。
那么,模版究竟是什么,又有什么魅力,能够让C++变得厉害起来呢?在这一篇博客中,我们就将研究:C++模版初阶诶,注意,只是初阶,这也就代表还有进阶的,但是那个我们要留到后面再说,目前来说,我们对C++的模版的掌握程度达到模版初阶就行。
OK,话不多说,我们发车。
泛型编程:
我们先看下面一段代码:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
......可以看到,上面是交换函数,这个大家应该不陌生,我们排序算法中经常用到,那么正如上面一样,如果我们想要交换int类型的数据时,我们就得写一个int类型的swap函数,而要是想交换float类型的数据,我们还得写一个float类型的swap函数,大家是不是会觉得好麻烦呀,是的,确实很麻烦。
而且上面我们是使用函数重载来实现的,有以下几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
- 代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?

就像上图这样子,如果在 C++ 中,能有这样一个 "模具" 就好了 ------ 向模具里填充不同 "材料"(也就是不同的数据类型),就能直接得到对应材料的 "铸件"(即自动生成该具体类型的代码)。这样一来,开发者无疑能省下不少为重复逻辑耗费的精力。巧的是,前辈们早已为我们打造好了这一工具,如今我们只需直接用它来提升效率就行。
诶,有的有的,那就是C++中的模版了。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
接下来,我们将正式开始了解模版。
函数模版:
函数模板概念:
函数模板代表着一个函数家族,它与具体类型无关,在使用时会被参数化,并根据实参类型生成该函数的特定类型版本。
函数模板格式:
函数模板的格式通常为:
template <typename 类型参数1, typename 类型参数2, ...>
返回值类型 函数名(参数列表) {
// 函数体
}其中,typename 也可以用 class 替代(切记:不能使用struct代替class),用于声明类型参数(即通用的类型占位符)。在使用函数模板时,编译器会根据传入的实参类型,自动将类型参数替换为具体类型,生成对应的函数版本,从而实现一份模板代码能处理多种不同类型数据的功能。
更详细的大家可以看下面这个代码:
//模版初阶:
//使用模版实现交换函数模版
template <typename type1>//后面不用加分号,下面直接跟函数
// 模版 <类型名字 类型形参名字(其实就是相当于随便给个名字)>
//后面在我们传入参数的时候,编译器会自动识别我们传入的数据类型
//然后把type1替换为识别到的数据类型
void Swap(type1& a, type1& b)//这里的交换函数不能直接swap,因为STL里面有个一样的swap模版
{
type1 temp = a;
a = b;
b = temp;
}
void testSwap()
{
int a = 10;
int b = 20;
double m = 10.10;
double n = 20.20;
//隐式实例化:让编译器根据实参推演模板参数的实际类型
cout << "a==" << a << " " << "b==" << b << endl;
cout << "m==" << m << " " << "n==" << n << endl;
cout << endl;
Swap(a, b);//type1==int
Swap(m, n);//type1==double
cout << "a==" << a << " " << "b==" << b << endl;
cout << "m==" << m << " " << "n==" << n << endl;
}当我们使用模版的时候,比如上面的Swap,里面的type1在我们给函数传入参数的时候,编译器会自动进行判断我们传入的参数是什么类型,然后将type1替换为它所识别到的类型,就是相当于把所有的地方的type1都改为它所识别到的类型。
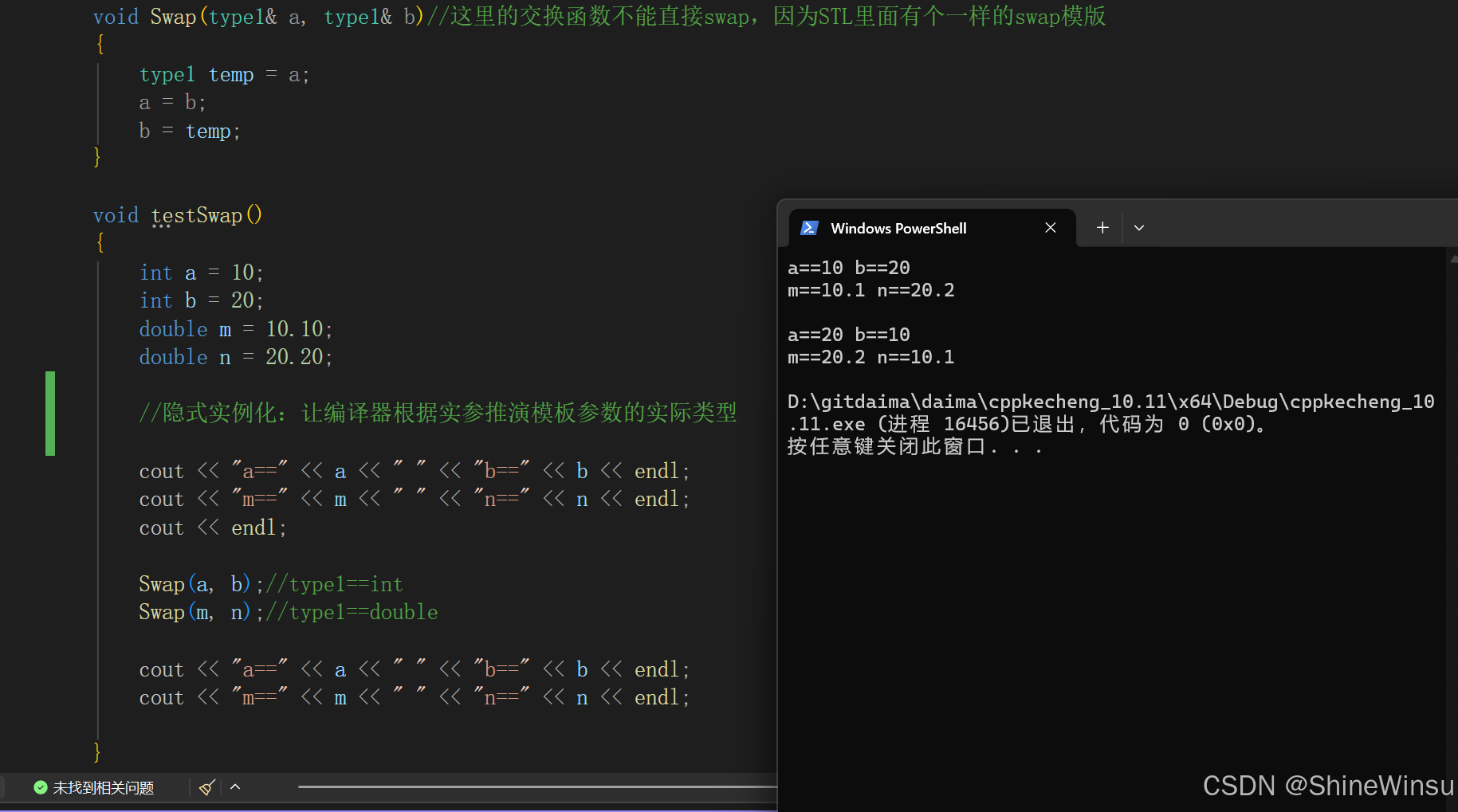
我们运行一下,发现确实是交换成功了,通过一个模版实现了不同类型的交换,而且大家要注意,实际上编译器是生成了两个函数,只不过我们看不到而已,并不是就只是那一个函数模版。
我们再看一个例子加强我们的理解:
//创建一个加法函数模版
template <typename type1,typename type2>
//如果有多个不同类型的,可以写多个typename
//即如上
type1 add(type1 a, type2 b)//返回type1类型的数据
{
return a + b;
}
void testadd()
{
int a = 10;
int b = 20;
double m = 10.10;
double n = 20.20;
//隐式实例化:让编译器根据实参推演模板参数的实际类型
cout << "mul:a*b==" << mul(a, b) << endl;//type1==int
cout << "mul:m*n==" << mul(m, n) << endl;//type1==double
cout << endl;
cout << "add:a+b==" << add(a, b) << endl;//type1==int type2=int
cout << "add:a+n==" << add(m, n) << endl;//type1==double type2=double
cout << endl;
cout << "add:a+m==" << add(a, m) << endl;//type1==int type2=double
cout << "add:m+a==" << add(m, a) << endl;//type1==double type2=int
}老样子,我们运行一下:
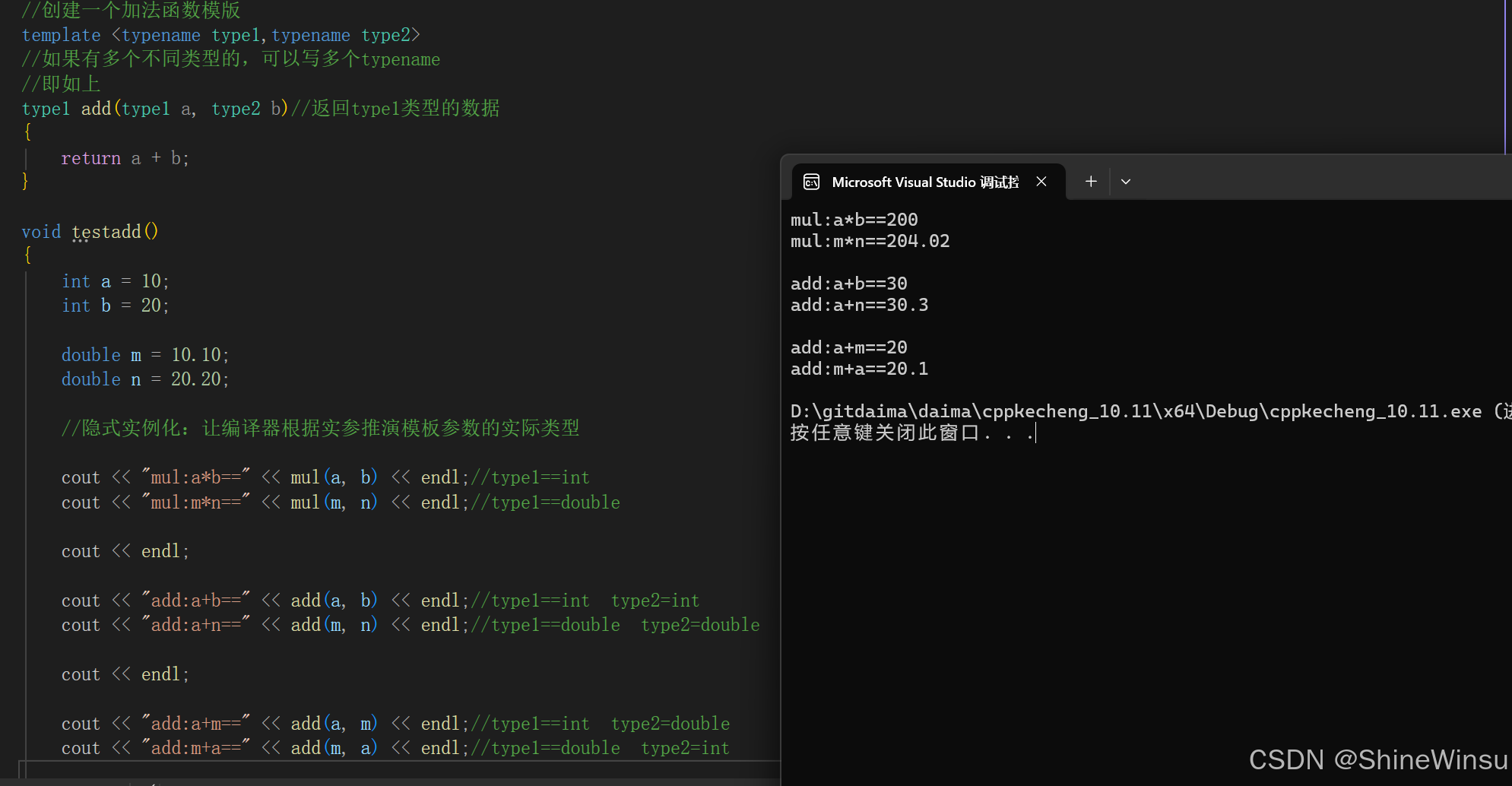
可以看到,也是顺利实现了,嘎嘎好使有木有。
函数模板的原理:
函数模板本质上是一个函数的 "设计蓝图",它自身并非可直接执行的函数,而更像一套生成函数的规则或模具。
这个模具的核心价值在于:当我们需要针对不同类型(如 int、double、自定义类等)实现逻辑相同的函数时,无需手动编写多个重复的具体函数(比如分别写 swap_int、swap_double、swap_Student),只需定义一份函数模板,指定通用的逻辑和类型参数(如 template <typename T>)。
之后,当我们用具体类型调用模板时(如 swap (3,5) 或 swap (2.5, 3.8)),编译器会自动根据传入的类型,套用模板中的逻辑,生成对应类型的具体函数(如 int 版本的 swap 或 double 版本的 swap)。
这相当于把原本需要开发者手动完成的重复编码工作(为每种类型写相似函数),转交给了编译器自动处理,既减少了代码冗余,又避免了手动编写多个版本可能出现的疏漏,让开发者能更专注于核心逻辑的设计。
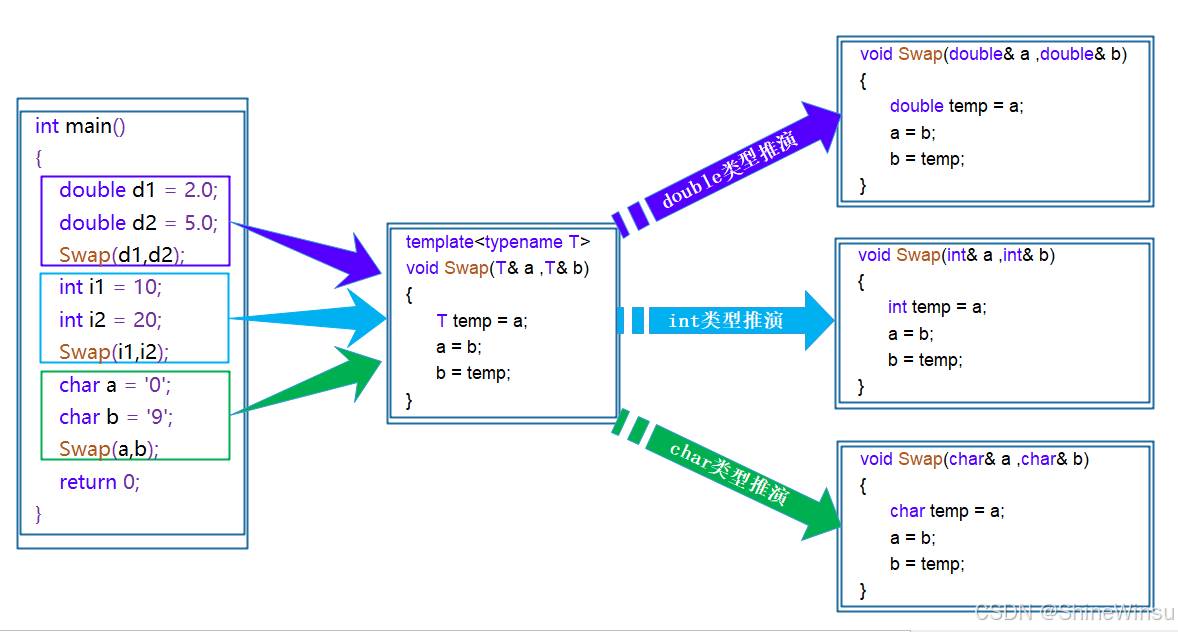
在编译器的编译阶段,当代码中使用函数模板时,会触发一个关键过程:模板实例化 。这个过程完全由编译器主导,核心是根据传入实参的具体类型,将模板中的类型参数(如T)替换为该类型,最终生成一份针对此类型的具体函数代码。
具体来说,当你调用swap(a, b)(假设a和b是double类型)时:
-
编译器首先会检查实参类型,发现
a和b都是double,因此推导出模板中的类型参数T应该是double; -
接着,编译器会以函数模板为 "蓝本",将模板中所有
T的位置替换为double,生成一份专门处理double类型的函数代码:void swap(double& a, double& b) { double temp = a; a = b; b = temp; } -
后续对
double类型变量的swap调用,实际上执行的就是这份编译器生成的专用代码。
同样地,当传入char类型实参时,编译器会重复这一过程:推导出T=char,然后生成char版本的swap函数:
void swap(char& a, char& b) {
char temp = a;
a = b;
b = temp;
}这个过程的本质是编译器在编译期为每种需要的类型 "复制并修改" 模板代码,最终生成多个逻辑相同但类型不同的具体函数。这些生成的函数与手动编写的重载函数完全等效,但整个过程无需开发者干预 ------ 编译器自动完成了类型推演、代码生成和关联调用的全部工作,既保证了类型安全,又避免了手动编写重复代码的繁琐。
函数模板的实例化:
函数模板的实例化,指的是编译器根据具体类型生成对应函数版本的过程。根据类型参数的确定方式,分为隐式实例化 和显式实例化两种:
隐式实例化:让编译器根据实参推演模板参数的实际类型
隐式实例化的核心是 "编译器自动干活"------ 当调用函数模板时,编译器会分析传入的实参类型,自动推演出模板参数(比如template <class T>里的T)该替换成哪种具体类型,再基于这个类型生成对应的函数版本,整个过程无需开发者手动指定类型。
以之前写的Add模板为例:调用Add(a1, a2)时,实参a1和a2都是int类型,编译器会自动推演 "模板参数T应该是int",然后生成专门处理int的Add函数(即int Add(const int& left, const int& right));调用Add(d1, d2)时,实参是double,编译器又会推演T为double,生成double版本的Add函数。
但要注意,编译器的推演有个 "规则":必须让所有实参推导出的模板参数类型一致。比如若调用Add(a1, d1)(a1是int、d1是double),编译器既从a1推导出T=int,又从d1推导出T=double,两个类型冲突,就会编译报错 ------ 这是因为模板推演时,编译器不会主动做类型转换(怕转换出错背锅),必须靠开发者保证实参类型统一,才能完成隐式实例化。
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有
一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要
背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a1, (int)d1);
return 0;
}我们可以再看下面这个例子:
//创建一个减法函数模版
template <typename type1>
type1 sub(type1 a, type1 b)
{
return a - b;
}
//如果既有模版函数,又有我们自己自定义的确切的同名函数
//那么编译器会先调用我们自己确切的定义的函数
//会把函数模版放在后面使用
//因为编译器也想偷懒,可以这么理解
void testsub()
{
cout << endl;
//此时我们就要测一点不一样的了
int a = 10;
double b = 0.1;
cout << sub(a, b) << endl;
//此时type1既要为a的类型int,又要为b的类型double
//因为编译器无法识别到底要把哪个传给type1
//所以编译器报错
}所以大家要注意避免这种情况的发生。
那么如果我们非要这样子呢,就要只设置一个type,但是要传不同类型的参数呢?那我们要怎么办呢?
那么有两种解决方法:
第一种种就是强制转换:
//对此,我们有两种解决方法:
//第一种:强制转换:
cout << "a-b==" << sub(a, (int)b) << endl;
//将b强制转换为int类型,此时编译器就会将int传给type1,正常运行
cout << "a-b==" << sub((double)a, b) << endl;
//将a强制转换为double类型,此时编译器就会将double传给type1,正常运行在使用模板函数时,若传入的参数类型不一致(比如一个是 int,一个是 double),编译器就没办法确定模板参数的具体类型,进而报错。
而强制转换的思路是,把其中一个参数的类型转换成和另一个参数一致的类型。就像代码里:
sub(a, (int)b)是把b强制转换成int类型,这样两个参数就都是int类型了,编译器能确定模板参数为int,模板函数能正常生成并运行;sub((double)a, b)是把a强制转换成double类型,两个参数都成了double类型,编译器也能确定模板参数为double,模板函数也能正常工作。
那么第二种方法就是非常厉害的一个方法了:
显式实例化: 调用函数模板时,在函数名后用<>包裹具体类型(如func<int>())
显式实例化是指在使用函数模板时,通过在函数名后加 <具体类型> 的方式,主动指定模板参数的实际类型,强制编译器生成该类型对应的函数版本,而非依赖编译器从实参中自动推导。
具体来说,当调用函数模板时,正常情况下编译器会根据实参类型推导模板参数(比如 Add(1, 2) 会推导出 T=int),这是隐式实例化。但如果在函数名后显式指定类型(如 Add<int>(1, 2.5)),编译器就会严格按照指定的 int 类型生成函数,即使实参类型不匹配(这里会自动将 2.5 转换为 int 类型)。
这种方式的核心作用是解决类型推导的歧义或限制:
- 当实参类型不同导致推导冲突时(比如
Add(1, 2.5)中1是int、2.5是double),显式指定Add<int>(1, 2.5)或Add<double>(1, 2.5)可明确告诉编译器使用哪种类型。 - 当模板参数无法从实参推导时(比如无参模板函数
template <typename T> T create()),必须显式实例化(如create<int>())才能让编译器生成对应函数。
简单讲,显式实例化就是开发者 "接管" 了模板参数的确定权,让编译器按指定类型生成代码,避免了隐式推导可能出现的问题。
大家可以结合下面这个例子进行了解:
//第二种:显式实例化:
//在函数名后的<>中指定模板参数的实际类型
//那么就相当于是我们直接告诉编译器type1是什么类型
cout << "a-b==" << sub<int>(a, b) << endl;
//此时编译器会把a和b都转换为int类型
//并且把int传给type1
cout << "a-b==" << sub<double>(a, b) << endl;
//此时编译器会把a和b都转换为double类型
//并且把double传给type1那么一般来说,推荐使用显式实例化,显式实例化能让开发者更主动地控制模板参数类型,避免隐式实例化时可能出现的类型推导歧义(比如不同实参类型导致编译器无法确定模板参数),还能明确指定生成特定类型的函数版本,使代码的行为更可预测,所以一般更推荐使用。
最后,我们运行一下上面的代码:
可以看到,结果正常。
模板参数的匹配原则:
1.一个非模板函数能够和与之同名的函数模板同时存在,并且这个函数模板还能被实例化为与该非模板函数完全一致的形式。
比如下面这个例子:
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}首先看代码部分:
- 定义了一个专门处理
int类型加法的非模板函数int Add(int left, int right),它的作用就是对两个int类型的数进行相加操作。 - 同时还定义了一个通用的加法函数模板
template<class T> T Add(T left, T right),这个模板可以根据传入的不同类型参数,生成对应类型的加法函数。
然后看 Test 函数里的调用情况:
- 当调用
Add(1, 2)时,因为实参是int类型,编译器会优先匹配已经存在的非模板函数 (也就是专门处理int的那个Add函数),这时候编译器不需要对模板进行 "特化"(也就是不需要根据模板生成特定类型的函数实例)。 - 当调用
Add<int>(1, 2)时,这是显式地要求编译器对模板进行实例化,生成int类型的模板函数版本。此时生成的这个函数,和之前的非模板Add函数,在功能和形式上是完全一致的。
总结一下,核心意思就是:非模板函数和同名的函数模板可以同时存在;而且函数模板能够被实例化,生成和非模板函数完全一样的特定类型版本。在调用的时候,编译器会优先匹配非模板函数,但也可以通过显式的方式,让模板生成和非模板函数一致的版本。
2.对于非模板函数和同名的函数模板,在调用时,若两者匹配条件相同,则会优先调用非模板函数,而非从模板生成实例;但如果模板能产生匹配度更高的函数版本,那么会选择该模板生成的实例。
比如下面这个例子:
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}规则核心
当非模板函数和同名函数模板都能匹配调用时:
- 若两者 "匹配程度相同",优先调用非模板函数;
- 若函数模板能生成 "匹配度更高" 的函数版本,则选择模板生成的实例。
代码示例分析
- 非模板函数与模板的定义
- 非模板函数 :
int Add(int left, int right)------ 专门处理两个int类型的加法。 - 函数模板 :
template<class T1, class T2> T1 Add(T1 left, T2 right)------ 通用加法,支持 "第一个参数为T1、第二个参数为T2" 的任意类型组合。
- 调用场景 1:
Add(1, 2)
- 实参
1和2都是int类型。 - 非模板函数
Add(int, int)完全匹配(无需类型转换); - 函数模板也能生成
Add<int, int>来匹配,但 "匹配程度" 和非模板函数相同。 - 因此,优先调用非模板函数,编译器不会实例化模板。
- 调用场景 2:
Add(1, 2.0)
- 实参是
int(1)和double(2.0)。 - 非模板函数
Add(int, int)要匹配的话,需要将double类型的2.0隐式转换为int(会损失精度,匹配度低); - 函数模板能生成
Add<int, double>------ 第一个参数T1=int匹配1,第二个参数T2=double匹配2.0,无需类型转换,匹配度更高。 - 因此,选择模板生成的实例 ,编译器会根据实参实例化出
Add<int, double>来调用。
总结
这种规则既保证了 "已有非模板函数的优先性"(避免不必要的模板实例化),又支持 "模板对复杂类型的更灵活匹配",让代码调用更合理。
3. 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
在 C++ 中,模板函数和普通函数在类型转换方面有着明显的区别:
模板函数的类型转换规则
模板函数是基于模板参数来生成具体函数的。在调用模板函数时,编译器需要根据传入的实参来推演模板参数的类型。为了保证类型的严格匹配,模板函数不允许自动进行类型转换。
例如,假设有一个模板函数 template <typename T> T Add(T a, T b),如果我们尝试调用 Add(1, 2.5)(其中 1 是 int 类型,2.5 是 double 类型),编译器会因为无法确定模板参数 T 到底是 int 还是 double 而报错。因为模板函数要求两个参数的类型必须完全匹配(由同一个 T 推导而来),不会自动将 int 转换为 double,或者将 double 转换为 int 来满足模板参数的一致性。
普通函数的类型转换规则
普通函数(非模板函数)在调用时,允许进行自动类型转换。当传入的实参类型与函数形参类型不一致时,只要符合 C++ 的类型转换规则,编译器会自动将实参类型转换为形参类型。
比如,有一个普通函数 int Add(int a, int b),如果我们调用 Add(1, 2.5),编译器会自动将 double 类型的 2.5 转换为 int 类型(即 2),然后再调用该函数,计算结果为 3。常见的自动类型转换包括整型和浮点型之间的转换、小整数类型(如 char、short)向大整数类型(如 int)的转换等,只要这种转换是安全的(不会导致数据丢失或未定义行为等严重问题),普通函数就会进行自动类型转换。
总结来说,模板函数为了确保类型推演的准确性和模板生成代码的正确性,严格要求实参类型与模板参数推导的类型一致,不进行自动类型转换;而普通函数则遵循 C++ 常规的类型转换规则,支持自动类型转换。
类模版:
类模板是 C++ 中实现泛型编程的重要机制,它允许我们创建一个通用的类框架,其中的成员变量类型、成员函数的参数和返回值类型等可以用模板参数来表示,从而能适配多种不同的数据类型。
类模板的声明形式
类模板的声明形式通常为:
template <typename T>
class 类名 {
// 成员变量,类型可以是 T
T member;
public:
// 成员函数,返回值或参数类型可以是 T
T getMember() const { return member; }
void setMember(const T& val) { member = val; }
};这里的 T 是模板参数,它可以代表任意类型(如 int、double、std::string,甚至自定义类类型),类模版并不是指类的类型是type什么什么的,而是类中的成员变量可以是type类型的,成员函数的返回值什么的也是可以的,类模板本身不是一个实际存在的类,只有当我们用具体的类型去实例化它时,才会生成真正的类(即模板类)。
实现栈类模版:
那么我们接下来通过实现栈类模版来帮助大家理解类模版:
// 类模板声明,type1 是模板参数,代表栈中元素的类型,可以是 int、double、自定义类等任意类型
template <typename type1>
class stack
{
public:
// 构造函数,初始化栈
// capacity 是栈的初始容量,默认值为 4
stack(int capacity = 4)
: mcapacity(capacity) // 初始化栈的容量为传入的 capacity(或默认 4)
, marr(new type1[mcapacity]) // 为存储栈元素的数组 marr 分配大小为 mcapacity 的内存空间,用于存放 type1 类型的元素
, msize(0) // 初始化栈中元素个数为 0,即栈为空
{ }
// 析构函数,用于释放栈占用的资源
~stack()
{
delete[] marr; // 释放动态分配的数组 marr 的内存
marr = nullptr; // 将指针置空,防止野指针
mcapacity = msize = 0; // 将容量和元素个数置 0
}
// 入栈操作:将元素 x 压入栈顶
void stackpush(const type1& x)
{
// 先判断栈是否已满(元素个数等于容量)
if (msize == mcapacity)
{
// 栈已满,需要扩容,新容量为原来的 2 倍
type1* temp = new type1[mcapacity * 2];
// 将原数组 marr 中的元素复制到新数组 temp 中,复制的字节数为 msize * sizeof(type1)(保证所有已有元素都复制过去)
memcpy(temp, marr, msize * sizeof(type1));
delete[] marr; // 释放原数组的内存
marr = temp; // 将 marr 指向新分配的更大的数组
mcapacity = mcapacity * 2; // 更新栈的容量为原来的 2 倍
}
marr[msize] = x; // 将元素 x 放入数组当前的栈顶位置(msize 索引处)
++msize; // 栈中元素个数加 1
}
// 出栈操作:将栈顶元素弹出
void stackpop()
{
msize--; // 只需将元素个数减 1,逻辑上栈顶元素被弹出(后续入栈会覆盖该位置)
}
// 获取栈顶元素
type1 stacktop()
{
return marr[msize - 1]; // 返回数组中索引为 msize - 1(栈顶)的元素
}
private:
type1* marr; // 指向存储栈元素的动态数组的指针
int msize; // 栈中当前元素的个数
int mcapacity; // 栈的容量(能存储的最大元素个数)
};那么其实我们实现的类模版就是在主函数我们创建比如栈这个类变量的时候,可以指定栈中存储的是什么类型的数据,因为我们是用type1* marr,假设在主函数中为int,那么编译器就会将类中的type1全部改为int。
大家其实可以类比我们之前在C语言写的typedef int nmae1来理解,我们每次如果想修改存储的数据类型,是把typedef int nmae1里面的int改为char或者什么什么类型,大家可以这么看待类模版。
类模板的实例化:
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的
类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
即对于类模版而言,我们是要使用显式实例化,是不能使用隐式实例化的,如果我们直接创建类变量,而不显式实例化的话,编译器是会报错的,希望大家注意,可以看一下下面这个例子:
void teststack()
{
//注意要显式实例化加在类名字后面
//而不是类变量名字后面
stack<int> st1;
//此时编译器就会把type1全部转换为int
stack<char> st2;
//此时编译器就会把type1全部转换为char
//有了类模版之后
//我们就可以随心所欲的创建存储不同类型数据的栈了
//相比于c语言的typedef好用太多
//因为C语言只能使用一次
//想要连续的,就得多个文件
}OK,到这里,我们的C++模版初阶就大功告成了。
结语:模版---C++ 泛型编程的魔法钥匙,开启高效编程新征程
亲爱的朋友们,当你逐行读完这篇关于 C++ 模版初阶的内容时,我们其实已经一起完成了一次 "从重复劳动到高效编程" 的思维跨越。回想开篇时我们面对的困境 ------ 为了交换不同类型的数据,不得不写一堆逻辑相同、仅类型有别的重载函数,那时的繁琐与无奈,想必大家还记忆犹新。而现在,当我们能用一份函数模版搞定 int、double、char 甚至自定义类型的交换,用一个栈类模版轻松创建存储不同数据的栈结构时,应该能真切感受到模版这份 "C++ 礼物" 的珍贵。
在这篇内容里,我们从泛型编程的痛点切入,一步步揭开了模版的神秘面纱。先是函数模版,它像一位 "智能工匠",拿着我们定义的 "逻辑模具",只要我们传入具体类型的 "材料",就能自动打造出对应类型的函数。我们知道了它的格式怎么写,明白了隐式实例化时编译器如何根据实参 "猜" 类型,也掌握了显式实例化时如何主动 "告诉" 编译器该用什么类型 ------ 尤其是当实参类型冲突时,显式实例化就像一剂 "特效药",能轻松解决编译器的 "选择困难症"。
接着,我们又深入学习了模板参数的匹配原则,这让我们明白:非模板函数和同名函数模版可以和平共存,编译器会优先选择更 "贴合" 的那个 ------ 要么是完全匹配的非模板函数,要么是能生成更高匹配度的模版实例。而模板函数与普通函数在类型转换上的差异,更让我们懂得了模版的 "严谨性":它不允许自动类型转换,正是为了避免隐式转换可能带来的精度丢失或逻辑错误,这份严谨,恰恰是模版保证代码安全性的关键。
再到类模版,我们通过亲手实现一个栈类模版,彻底打破了 "一个类只能处理一种类型" 的局限。原来,只需用模板参数替代具体类型,一个类框架就能适配无数种数据类型 ------ 想要存储 int 就实例化stack<int>,想要存储 char 就实例化stack<char>,这种灵活性,是 C 语言的typedef远远无法比拟的。我们也牢牢记住了类模版的核心规则:它没有隐式实例化,必须显式指定类型才能生成真正的类,这既是它的 "特殊要求",也是它能精准适配不同类型的 "底气"。
回顾整个学习过程,模版带给我们的远不止 "少写几行代码" 这么简单。它真正改变的,是我们编写代码的思维方式 ------ 从 "为每种类型写一份逻辑" 的 "重复思维",转变为 "写一份通用逻辑适配所有类型" 的 "泛型思维"。这种思维的升级,不仅能大幅减少代码冗余、提高代码可维护性,更能让我们把精力聚焦在核心逻辑的设计上,而不是在重复劳动中消耗时间。
或许此刻,你还会觉得模版的某些细节有点绕 ------ 比如显式实例化的语法、模板参数的匹配优先级,或是类模版实例化时的注意事项。但请不要着急,任何新知识的掌握都需要一个过程。就像我们刚开始学new和delete时会困惑于内存泄漏,刚开始学函数重载时会分不清调用优先级一样,只要多写几次代码、多调试几个例子,这些细节很快就会变得 "得心应手"。
而且请记住,我们今天学的还只是 "模版初阶"。在模版的进阶世界里,还有类模版的特化、模版的编译机制、可变参数模版等更强大的特性等着我们去探索。那些特性,会让我们对泛型编程的理解更上一层楼,也会让我们写出的代码更优雅、更高效。
所以,亲爱的朋友们,不要因为 "初阶" 就轻视这份知识。模版就像一把 "魔法钥匙",今天我们用它打开了 C++ 泛型编程的大门,未来,它还会帮我们打开更多高级特性的大门。无论是日常开发中的工具类设计,还是后续学习 STL(标准模板库)------ 要知道,STL 的 vector、list、map 等容器,本质上都是用类模版实现的 ------ 模版都是我们不可或缺的基础。
最后,我想对每一位正在学习 C++ 的朋友说:编程的路上没有捷径,但每学会一个重要的知识点,就意味着我们离 "写出更好的代码" 更近了一步。模版或许不是 C++ 中最简单的知识点,但它绝对是最有价值的知识点之一。希望大家能把今天学到的模版知识好好消化,多动手实践,用模版去优化自己的代码,去解决实际的问题。
当你下次再遇到需要处理多类型数据的场景时,希望你能立刻想起模版 ------ 想起用一份函数模版搞定所有类型的交换,用一个类模版适配所有类型的容器。那时你会发现,模版不仅是一种语法,更是一种高效编程的 "武器"。
愿我们都能带着这份对模版的理解,在 C++ 的学习之路上继续前行,不断探索,不断成长。相信未来的某一天,当你回头看时,会感谢今天认真学习模版的自己 ------ 因为正是这份积累,让你在编程的道路上走得更稳、更远。加油,未来的 C++ 工程师们!