经典医学图像分割模型
- [一、🏛️ CNN 黄金时代:从开天辟地到登峰造极 (2015 - 2021)](#一、🏛️ CNN 黄金时代:从开天辟地到登峰造极 (2015 - 2021))
-
- [1. 【2014.11】语义分割的起源:FCN](#1. 【2014.11】语义分割的起源:FCN)
- [2. 【2015.05】医学分割的基石:U-Net](#2. 【2015.05】医学分割的基石:U-Net)
- [3. 【2015.11】效率与显存的平衡:SegNet](#3. 【2015.11】效率与显存的平衡:SegNet)
- [4. 【2015.12】骨干网络的革命:ResNet](#4. 【2015.12】骨干网络的革命:ResNet)
- [5. 【2016.01】维度的跨越:V-Net (与 3D U-Net)](#5. 【2016.01】维度的跨越:V-Net (与 3D U-Net))
- [6. 【2016.12】多尺度的特征融合:FPN](#6. 【2016.12】多尺度的特征融合:FPN)
- [7. 【2016.12】聚合上下文信息:PSPNet](#7. 【2016.12】聚合上下文信息:PSPNet)
- [8. 【2017.03】实例分割的里程碑:Mask R-CNN](#8. 【2017.03】实例分割的里程碑:Mask R-CNN)
- [9. 【2015-2018】语义分割的标杆:DeepLab 系列 (v1~v3+)](#9. 【2015-2018】语义分割的标杆:DeepLab 系列 (v1~v3+))
- [10. 【2018.07】结构的极致精修:U-Net++](#10. 【2018.07】结构的极致精修:U-Net++)
- [11. 【2018.04】门控机制的引入:Attention U-Net](#11. 【2018.04】门控机制的引入:Attention U-Net)
- [12. 【2019.08】永远的高分辨率:HRNet](#12. 【2019.08】永远的高分辨率:HRNet)
- [13. 【2019.01】全景分割的统一:Panoptic FPN](#13. 【2019.01】全景分割的统一:Panoptic FPN)
- [14. 【2021.12】CNN 时代的终结者:nnU-Net](#14. 【2021.12】CNN 时代的终结者:nnU-Net)
- [二、🌪️ Transformer 时代:全局感知的觉醒与架构重构 (2017 - 2022)](#二、🌪️ Transformer 时代:全局感知的觉醒与架构重构 (2017 - 2022))
-
- 第一部分:理论基石 (Foundations)
-
- [1. 【2017.06】万物之源:Transformer ------ Attention Is All You Need](#1. 【2017.06】万物之源:Transformer —— Attention Is All You Need)
- [2. 【2020.10】视觉的跨界:ViT(Vision Transformer)](#2. 【2020.10】视觉的跨界:ViT(Vision Transformer))
- [3. 【2021.03】骨干的进化:Swin Transformer(Shifted Windows Transformer)](#3. 【2021.03】骨干的进化:Swin Transformer(Shifted Windows Transformer))
- [第二部分:2D 分割革新 (2D Segmentation)](#第二部分:2D 分割革新 (2D Segmentation))
-
- [1. 【2020.12】分割的 ViT 时刻:SETR(SEgmentation TRansformer)](#1. 【2020.12】分割的 ViT 时刻:SETR(SEgmentation TRansformer))
- [2. 【2021.02】混合架构先驱:TransUNet(Transformers and U-Net)](#2. 【2021.02】混合架构先驱:TransUNet(Transformers and U-Net))
- [3. 【2021.05】纯 Transformer 架构:Swin-Unet(Shifted Window Transformer Unet)](#3. 【2021.05】纯 Transformer 架构:Swin-Unet(Shifted Window Transformer Unet))
- [4. 【2021.05】高效分割之王:SegFormer(Segmentation Transformer)](#4. 【2021.05】高效分割之王:SegFormer(Segmentation Transformer))
- [第二部分:3D 医学霸主 (3D Medical Segmentation)](#第二部分:3D 医学霸主 (3D Medical Segmentation))
-
- [1. 【2021.03】3D 医学分割基石:UNETR(UNEt TRansformers)](#1. 【2021.03】3D 医学分割基石:UNETR(UNEt TRansformers))
- [2. 【2022.01】3D 版 Swin 的进化:Swin-UNETR(Swin UNEt TRansformers)](#2. 【2022.01】3D 版 Swin 的进化:Swin-UNETR(Swin UNEt TRansformers))
- [三、🌌 大模型纪元:提示驱动与通用分割的奇点时刻 (2023 - 至今)](#三、🌌 大模型纪元:提示驱动与通用分割的奇点时刻 (2023 - 至今))
-
- [1. 【2023.04】视觉分割的 GPT 时刻:SAM(Segment Anything Model)](#1. 【2023.04】视觉分割的 GPT 时刻:SAM(Segment Anything Model))
- [2. 【2023.06】实时版的 SAM:FastSAM](#2. 【2023.06】实时版的 SAM:FastSAM)
- [3. 【2023.04】医学领域的通用基座:MedSAM(Segment anything in medical images)](#3. 【2023.04】医学领域的通用基座:MedSAM(Segment anything in medical images))
- [4. 【2024.07】统一视频与图像的进化:SAM 2](#4. 【2024.07】统一视频与图像的进化:SAM 2)
- [5. 【2025.11】全能感知的集大成者:SAM 3](#5. 【2025.11】全能感知的集大成者:SAM 3)
- [6. 【2025.11】从像素到体素的跨越:SAM 3D](#6. 【2025.11】从像素到体素的跨越:SAM 3D)
一、🏛️ CNN 黄金时代:从开天辟地到登峰造极 (2015 - 2021)
【PyTorch项目实战】语义分割:U-Net、UNet++、U2Net
1. 【2014.11】语义分割的起源:FCN
这是深度学习在图像分割领域的开山之作,它让计算机视觉从"识别图片里有什么"跨越到了"识别像素点是什么"。
- 中文主题:FCN:全卷积网络用于语义分割
- 论文题目:Fully Convolutional Networks for Semantic Segmentation
- 作者团队:Jonathan Long, Evan Shelhamer, Trevor Darrell
- 所属机构:UC Berkeley (加州大学伯克利分校)
- 发表时间/会议:2014年提交,CVPR 2015
- 源码地址:https://github.com/shelhamer/fcn.berkeleyvision (原始Caffe版)
一句话核心:FCN 是语义分割的鼻祖,它创造性地将分类网络(如 VGG)中的全连接层替换为卷积层,首次实现了任意尺寸图像的端到端像素级预测,奠定了现代分割模型的基础。
2. 【2015.05】医学分割的基石:U-Net
无论过去多少年,U-Net 依然是医学影像分析领域引用率最高、最无法绕过的模型。
- 中文主题:U-Net:用于生物医学图像分割的卷积网络
- 论文题目:U-Net: Convolutional Networks for Biomedical Image Segmentation
- 作者团队:Olaf Ronneberger, Philipp Fischer, Thomas Brox
- 所属机构:University of Freiburg (弗莱堡大学)
- 发表时间/会议:2015年5月提交,MICCAI 2015
- 源码地址:https://github.com/milesial/Pytorch-UNet (目前最流行的复现版)
一句话核心:U-Net 被誉为医学分割的"圣经",其标志性的对称"编码器-解码器"结构与跳跃连接(Skip Connections),完美解决了医学图像数据量少、边缘定位难的问题,是后续所有 Transformer 混合架构模仿的对象。
3. 【2015.11】效率与显存的平衡:SegNet
在显卡资源匮乏的早期,SegNet 提供了一种极其优雅的解决方案,主要用于自动驾驶场景。
- 中文主题:SegNet:一种用于图像分割的深度卷积编码器-解码器架构
- 论文题目:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- 作者团队:Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla
- 所属机构:University of Cambridge (剑桥大学)
- 发表时间/会议:2015年提交,TPAMI 2017
- 源码地址:https://github.com/alexgkendall/SegNet-Tutorial
一句话核心:SegNet 的核心创新在于引入"最大池化索引"来记录位置进行上采样,这大幅减少了显存占用并保留了边缘信息,是早期追求计算效率与边缘精度的代表性工作。
4. 【2015.12】骨干网络的革命:ResNet
虽然 ResNet 最初是为图像分类设计的,但它的出现彻底改变了分割模型的设计模式。几乎所有现代分割模型(DeepLab, PSPNet, U-Net变体)都使用 ResNet 作为"编码器"来提取特征。
- 中文主题:ResNet:用于图像识别的深度残差学习
- 论文题目:Deep Residual Learning for Image Recognition
- 作者团队:Kaiming He (何恺明), Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 所属机构:Microsoft Research Asia (MSRA) (微软亚洲研究院)
- 发表时间/会议:2015年12月提交,CVPR 2016 (Best Paper)
- 源码地址:https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py (Torchvision 官方实现)
一句话核心:ResNet 通过引入"残差连接 (Residual Connection)"解决了深层网络梯度消失和退化的问题,让网络深度从十几层跃升至上百层,成为了计算机视觉领域(包括分割任务)最通用的特征提取骨干网络。
5. 【2016.01】维度的跨越:V-Net (与 3D U-Net)
在医学影像中,医生通常需要查看 3D 的 CT 或 MRI 数据。V-Net 和 3D U-Net 几乎同时期提出,将 2D 卷积扩展为 3D,实现了真正的"体素级"分割。
- 中文主题:V-Net:用于三维医学图像分割的全卷积神经网络
- 论文题目:V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
- 作者团队:Fausto Milletari, Nassir Navab, Seyed-Ahmad Ahmadi
- 所属机构:Technical University of Munich & Johns Hopkins University
- 发表时间/会议:2016年6月提交,3DV 2016
- 源码地址:https://github.com/mattmacy/vnet.pytorch (常用的 PyTorch 复现)
一句话核心:V-Net 不仅将 U-Net 架构扩展至 3D 领域以处理体积数据,更重要的是提出了著名的 Dice Loss 损失函数,有效解决了医学图像中背景极大、病灶极小的正负样本极度不平衡问题。
6. 【2016.12】多尺度的特征融合:FPN
在分割任务中,如何同时处理"大物体"和"小物体"一直是个难题。FPN 给出了一个教科书般的解决方案,成为了 Mask R-CNN 等模型的标配组件。
- 中文主题:FPN:用于目标检测的特征金字塔网络
- 论文题目:Feature Pyramid Networks for Object Detection
- 作者团队:Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, et al.
- 所属机构:Facebook AI Research (FAIR)
- 发表时间/会议:2016年12月提交,CVPR 2017
- 源码地址:https://github.com/facebookresearch/detectron2 (集成在 Detectron2 中)
一句话核心:FPN 通过构建"自顶向下"的路径和横向连接,将深层的高语义特征与浅层的高分辨率特征融合,让模型在不同尺度上都能拥有强大的语义感知能力,解决了多尺度目标检测与分割的难题。
7. 【2016.12】聚合上下文信息:PSPNet
在语义分割中,"水"和"天空"、"床"和"被子"往往容易混淆。PSPNet 告诉我们,看清局部必须先看懂全局(Global Context)。
- 中文主题:PSPNet:金字塔场景解析网络
- 论文题目:Pyramid Scene Parsing Network
- 作者团队:Hengshuang Zhao (赵恒爽), Jianping Shi, Jiaya Jia (贾佳亚), et al.
- 所属机构:CUHK (香港中文大学) & SenseTime (商汤科技)
- 发表时间/会议:2016年12月提交,CVPR 2017 (Winner of ImageNet Scene Parsing Challenge 2016)
- 源码地址:https://github.com/hszhao/PSPNet
一句话核心:PSPNet 提出了"金字塔池化模块 (Pyramid Pooling Module)",通过以不同比例聚合背景上下文信息,极大地增强了模型对复杂场景的理解能力,有效解决了物体外观相似导致的混淆问题。
8. 【2017.03】实例分割的里程碑:Mask R-CNN
何恺明大神的又一力作,它不仅能框出物体,还能精确地描绘出物体的轮廓,是全景分割的前奏。
- 中文主题:Mask R-CNN:目标检测与实例分割的统一框架
- 论文题目:Mask R-CNN
- 作者团队:Kaiming He (何恺明), Georgia Gkioxari, Piotr Dollár, Ross Girshick
- 所属机构:Facebook AI Research (FAIR)
- 发表时间/会议:2017年3月提交,ICCV 2017 (Best Paper)
- 源码地址:https://github.com/facebookresearch/detectron2 (官方继任者 Detectron2)
一句话核心:Mask R-CNN 在 Faster R-CNN 的基础上增加了一个并行的 Mask 分支,并提出了 RoI Align 层来消除 ROI Pooling 带来的量化误差,完美统一了目标检测与实例分割任务,实现了像素级的精准定位。
9. 【2015-2018】语义分割的标杆:DeepLab 系列 (v1~v3+)
这是 Google 团队对语义分割长达几年的探索,其中 DeepLab v3+ 被视为传统 CNN 分割模型的巅峰之作。
- 中文主题:DeepLab v3+:空洞卷积与ASPP的集大成者
- 论文题目:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (以最终版本 v3+ 为例)
- 作者团队:Liang-Chieh Chen, Yukun Zhu, George Papandreou, et al.
- 所属机构:Google Research
- 发表时间/会议:DeepLab v1 (ICLR 2015) -> v3+ (ECCV 2018)
- 源码地址:https://github.com/tensorflow/models/tree/master/research/deeplab
一句话核心:DeepLab 系列的核心贡献在于引入 空洞卷积 (Atrous Conv) 和 ASPP (空洞空间金字塔池化),在不降低图像分辨率的前提下大幅扩大了感受野,v3+ 更是结合了编解码器结构,成为了语义分割领域长期霸榜的精度标杆。
10. 【2018.07】结构的极致精修:U-Net++
U-Net++ 认为原版 U-Net 的长连接(Skip Connection)直接将编码器和解码器特征拼接过于粗糙,因此设计了一种"套娃"式的密集连接结构。
- 中文主题:U-Net++:用于医学图像分割的嵌套 U-Net 架构
- 论文题目:U-Net++: A Nested U-Net Architecture for Medical Image Segmentation
- 作者团队:Zongwei Zhou, Nima Tajbakhsh, et al.
- 所属机构:Arizona State University (ASU) (亚利桑那州立大学)
- 发表时间/会议:2018年7月提交,MICCAI 2018
- 源码地址:https://github.com/MrGiovanni/UNetPlusPlus
一句话核心:U-Net++ 通过设计密集嵌套的跳跃连接(Nested Skip Pathways),填补了编码器与解码器特征图在语义层级上的巨大鸿沟,挖掘了 U-Net 架构的剩余潜力,显著提升了医学图像分割的精度。
11. 【2018.04】门控机制的引入:Attention U-Net
在 Transformer 尚未统治视觉界之前,Attention U-Net 率先尝试在 CNN 中引入"注意力"概念,通过数学门控来聚焦重点。
- 中文主题:Attention U-Net:学习在胰腺分割中关注哪里
- 论文题目:Attention U-Net: Learning Where to Look for the Pancreas
- 作者团队:Ozan Oktay, Jo Schlemper, et al.
- 所属机构:Imperial College London (帝国理工学院)
- 发表时间/会议:2018年4月提交,MIDL 2018
- 源码地址:https://github.com/ozan-oktay/Attention-Gated-Networks
一句话核心:Attention U-Net 在 CNN 解码器中巧妙地引入了门控注意力机制(Attention Gate),在不增加额外计算开销的前提下,让模型学会自动抑制背景噪声,聚焦于形状不规则的病灶区域。
12. 【2019.08】永远的高分辨率:HRNet
传统网络(如 ResNet, U-Net)都是先缩小分辨率再放大,这不可避免地导致空间信息丢失。HRNet 打破了这一惯例。
- 中文主题:HRNet:用于视觉识别的深度高分辨率表示学习
- 论文题目:Deep High-Resolution Representation Learning for Visual Recognition
- 作者团队:Jingdong Wang (王井东), Ke Sun, et al.
- 所属机构:Microsoft Research Asia (MSRA) (微软亚洲研究院)
- 发表时间/会议:2019年提交,CVPR 2019 / TPAMI
- 源码地址:https://github.com/HRNet/HRNet-Semantic-Segmentation
一句话核心:HRNet 摒弃了传统先下采样后上采样的"串联"思路,而是让高分辨率特征流贯穿始终,并多次融合低分辨率特征,显著提升了分割任务对空间位置的精准度(Pixel-level Precision)。
13. 【2019.01】全景分割的统一:Panoptic FPN
它标志着分割任务的新阶段------全景分割(Panoptic Segmentation),即同时搞定"数人头"(实例分割)和"刷墙面"(语义分割)。
- 中文主题:Panoptic FPN:全景特征金字塔网络
- 论文题目:Panoptic Feature Pyramid Networks
- 作者团队:Alexander Kirillov, Ross Girshick, Kaiming He (何恺明), et al.
- 所属机构:Facebook AI Research (FAIR)
- 发表时间/会议:2019年1月提交,CVPR 2019
- 源码地址:https://github.com/facebookresearch/detectron2
一句话核心:Panoptic FPN 结合了语义分割(FCN 分支)和实例分割(Mask R-CNN 分支)的思路,利用共享的 FPN 特征,统一了背景(Stuff)和前景物体(Thing)的分割任务,定义了全景分割的标准基线。
14. 【2021.12】CNN 时代的终结者:nnU-Net
这篇论文是对过去几年"魔改模型结构"风气的一次降维打击。它告诉大家:与其改模型,不如改数据处理。
- 中文主题:nnU-Net:一种基于深度学习的生物医学图像分割自配置方法
- 论文题目:nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation
- 作者团队:Fabian Isensee, Klaus H. Maier-Hein, et al.
- 所属机构:DKFZ (德国癌症研究中心)
- 发表时间/会议:2018年起霸榜比赛,Nature Methods 2021 正式发表
- 源码地址:https://github.com/MIC-DKFZ/nnUNet (工业级标准库)
一句话核心:nnU-Net 是 CNN 时代的最终答案,它本质上不是一个新的网络架构,而是一套极致的"自适应训练框架",证明了在医学分割中,自动化的数据预处理、重采样和训练策略比单纯魔改网络结构重要得多。
二、🌪️ Transformer 时代:全局感知的觉醒与架构重构 (2017 - 2022)
核心突破:打破 CNN 局部感受野限制,利用 Self-Attention 捕捉全局长距离依赖。
第一部分:理论基石 (Foundations)
1. 【2017.06】万物之源:Transformer ------ Attention Is All You Need
- 中文主题:Transformer:彻底改变 NLP 的注意力机制架构
- 论文题目:Attention Is All You Need
- 作者团队:Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. (著名的"Transformer 八子")
- 所属机构:Google Brain, Google Research
- 发表时间/会议:2017年6月提交,NeurIPS 2017 接收
- 源码地址:
- 官方 (TensorFlow/原始):https://github.com/tensorflow/tensor2tensor
- 现代工业标准 (Hugging Face):https://github.com/huggingface/transformers
- 代码逐行注解版 (哈佛大学 NLP 组 - 学习必看 ):http://nlp.seas.harvard.edu/annotated-transformer/
一句话核心:Transformer 是深度学习史上的分水岭,它摒弃了传统的 RNN 和 CNN 循环/卷积结构,提出"Attention Is All You Need",完全基于 Self-Attention(自注意力)机制,成为了后来 BERT、GPT 以及 ViT 等万物大模型的共同基石。
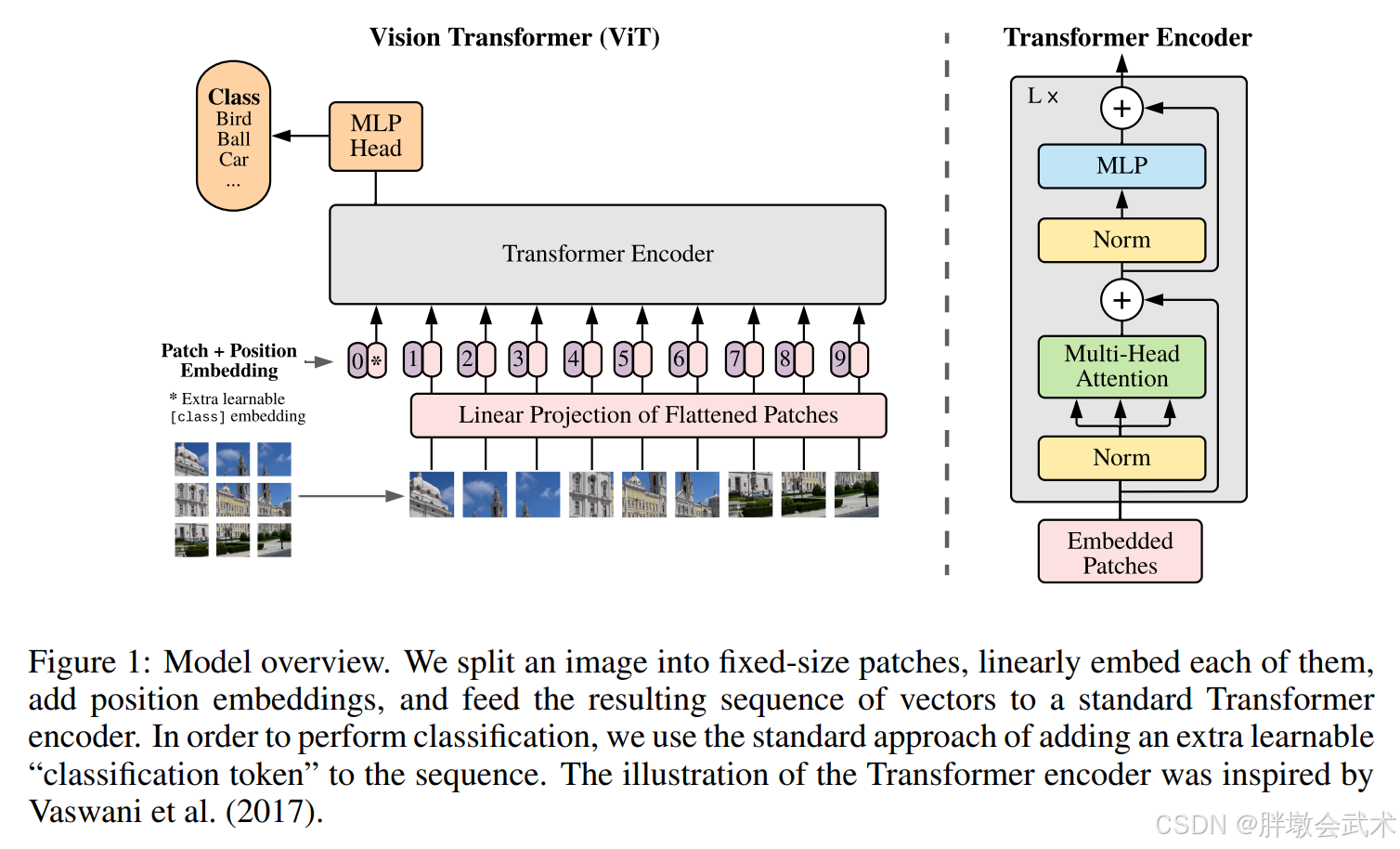
2. 【2020.10】视觉的跨界:ViT(Vision Transformer)
- 中文主题:ViT:用于大规模图像识别的 Transformer
- 论文题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- 作者团队:Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, et al.
- 所属机构:Google Research, Brain Team (谷歌大脑)
- 发表时间/会议:2020年10月提交,ICLR 2021 (Oral) 接收
- 源码地址:
- 官方 (JAX):https://github.com/google-research/vision_transformer
- PyTorch版 (最常用):https://github.com/lucidrains/vit-pytorch
一句话核心:ViT 是计算机视觉领域的一个里程碑,它打破了 CNN 在图像识别领域的垄断地位,直接把 NLP 中的 Transformer 架构搬到了图像上。
简单来说:CNN 是像拿着放大镜一点点扫描图片;ViT 是把图片切成碎片,然后像拼图一样,通过分析碎片之间的关系来理解整张图。
模型概述:我们将图像分割成固定大小的图像块,对每个图像块进行线性嵌入,添加位置嵌入,并将得到的向量序列输入到标准的Transformer编码器中。为了进行分类,我们采用标准方法,在序列中添加一个额外的可学习的"分类标记"。
3. 【2021.03】骨干的进化:Swin Transformer(Shifted Windows Transformer)
- 中文主题:Swin Transformer:基于滑动窗口的层级式视觉 Transformer
- 论文题目:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 作者团队:Ze Liu, Yutong Lin, Yue Cao, Han Hu, et al.
- 所属机构:Microsoft Research Asia (MSRA) (微软亚洲研究院)
- 发表时间/会议:2021年3月提交,ICCV 2021 (Best Paper / 马尔奖)
- 源码地址:
- 官方 (PyTorch):https://github.com/microsoft/Swin-Transformer
- Timm集成版 (工业界最常用):https://github.com/huggingface/pytorch-image-models
一句话核心:Swin Transformer 是 ViT 的 "工业级" 进化版,它通过引入 "滑动窗口 (Shifted Windows)" 机制和类似 CNN 的层级结构,大幅降低了计算复杂度,一举拿下了 ICCV 2021 最佳论文奖,成为了各种视觉任务(分类、检测、分割)的首选骨干网络。
第二部分:2D 分割革新 (2D Segmentation)
1. 【2020.12】分割的 ViT 时刻:SETR(SEgmentation TRansformer)
这是将 ViT 真正用于分割的开山鼻祖(自然图像领域),地位相当于 CNN 中的 FCN。
- 中文主题:SETR:基于 Transformer 的序列到序列语义分割
- 论文题目:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
- 作者团队:Sixiao Zheng, Jiachen Lu, et al.
- 所属机构:Fudan University (复旦大学), Tencent Youtu Lab
- 发表时间/会议:2020年12月提交,CVPR 2021
- 源码地址:https://github.com/fudan-zvg/SETR
一句话核心:SETR 第一次抛弃了 CNN 编码器,直接用纯 ViT 提取特征,证明了把图片像素拉直成序列(Sequence),依然可以做精细的语义分割,是 TransUNet 等后续工作的灵感来源之一。
2. 【2021.02】混合架构先驱:TransUNet(Transformers and U-Net)
- 中文主题:TransUNet:首个结合 Transformer 和 U-Net 的医学图像分割模型
- 论文题目:TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
- 作者团队:Jieneng Chen, Yongyi Lu, Qihang Yu, et al. (Alan Yuille 团队)
- 所属机构:Johns Hopkins University (JHU) (约翰霍普金斯大学) 等
- 发表时间/会议:2021年2月提交 ArXiv,后续在医学影像相关领域产生巨大影响力
- 源码地址:
- 官方 (PyTorch):https://github.com/Beckschen/TransUNet
- 常用复现库 (MONAI):https://github.com/Project-MONAI/MONAI (MONAI 现已集成类似架构)
一句话核心:TransUNet 是混合架构(Hybrid Architecture)的先驱,它将 ViT 塞进了 U-Net 的"瓶颈层"作为编码器,既保留了 CNN 提取局部细节的能力,又利用 Transformer 捕捉到了医学图像中至关重要的长距离依赖(全局上下文)。
3. 【2021.05】纯 Transformer 架构:Swin-Unet(Shifted Window Transformer Unet)
【PyTorch项目实战】Swin-Unet:用于医学图像分割的类Unet纯Transformer模型
- 中文主题:Swin-Unet:一种用于医学图像分割的类Unet纯Transformer架构
- 论文题目:Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
- 作者团队:Hu Cao, Yueyue Wang, Joy Joy, Dongsheng Ruan, et al.
- 所属机构:Huazhong University of Science and Technology (HUST) (华中科技大学)
- 发表时间/会议:2021年5月提交 ArXiv,ECCV 2022 (MCV Workshop) 接收
- 源码地址:
- 官方 (PyTorch):https://github.com/HuCaoFighting/Swin-Unet
一句话核心:Swin-Unet 是首个专为医学图像分割设计的"纯 Transformer" U-Net 架构,它完全剔除了卷积神经网络 (CNN),利用 Swin Transformer 模块构建了双臂 U 型结构,证明了纯 Transformer 在医学密集预测任务上也能超越传统 CNN。
4. 【2021.05】高效分割之王:SegFormer(Segmentation Transformer)
如果说 Swin Transformer 是为了刷分,SegFormer 就是为了落地。它在医学分割中也极受欢迎。
- 中文主题:SegFormer:简单高效的 Transformer 语义分割设计
- 论文题目:SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
- 作者团队:Enze Xie, Wenhai Wang, et al.
- 所属机构:NVIDIA, HKU
- 发表时间/会议:2021年5月提交,NeurIPS 2021
- 源码地址:https://github.com/NVlabs/SegFormer
一句话核心:SegFormer 移除了 Transformer 中繁重的位置编码(Positional Encoding),提出了轻量级的 MLP 解码器,在速度和精度之间取得了完美平衡,是目前工业界和医学轻量化部署的首选架构。
第二部分:3D 医学霸主 (3D Medical Segmentation)
1. 【2021.03】3D 医学分割基石:UNETR(UNEt TRansformers)
TransUNet 解决了 2D 切片,而 UNETR 解决了医学领域最头疼的 3D 体数据 (CT/MRI) 处理问题。
- 中文主题:UNETR:用于 3D 医学图像分割的 Transformer
- 论文题目:UNETR: Transformers for 3D Medical Image Segmentation
- 作者团队:Ali Hatamizadeh, et al.
- 所属机构:NVIDIA (英伟达)
- 发表时间/会议:2021年3月提交,WACV 2022
- 源码地址:https://github.com/Project-MONAI/research-contributions/tree/master/UNETR (官方集成在 MONAI 中)
一句话核心:UNETR 是 3D 医学分割的里程碑,它直接将 3D 体素(Voxel)切块输入纯 Transformer 编码器,解决了 CNN 在 3D 空间中感受野有限的问题,成为处理立体器官分割的标准基线。
2. 【2022.01】3D 版 Swin 的进化:Swin-UNETR(Swin UNEt TRansformers)
这是 UNETR 的升级版,也是目前医学影像竞赛(如 BTCV)中的常客。
- 中文主题:Swin-UNETR:用于医学图像分割的类 Swin Transformer
- 论文题目:Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
- 作者团队:Ali Hatamizadeh, et al.
- 所属机构:NVIDIA
- 发表时间/会议:2022年1月提交,MICCAI 2022
- 源码地址:https://github.com/Project-MONAI/research-contributions/tree/master/SwinUNETR
一句话核心:Swin-UNETR 将 Swin Transformer 的"滑动窗口"机制引入 3D 分割,相比初代 UNETR,它计算量更小、收敛更快、精度更高,是目前 3D 医学分割最强的 Transformer 基线之一。
三、🌌 大模型纪元:提示驱动与通用分割的奇点时刻 (2023 - 至今)
【PyTorch项目实战】SAM(Segment Anything Model)
【PyTorch项目实战】SAM3:概念分割 + 3D重建(模型 + 人体)
【PyTorch项目实战】FastSAM(快速分割一切)
核心突破:从"特定任务训练"转向"预训练基础模型 + 提示词交互"。
1. 【2023.04】视觉分割的 GPT 时刻:SAM(Segment Anything Model)
这是计算机视觉领域的"核弹级"工作,Meta 用 11 亿个掩码(Mask)暴力美学地解决了"分割一切"的问题。
- 中文主题:SAM:分割一切模型
- 论文题目:Segment Anything
- 作者团队:Alexander Kirillov, Eric Mintun, Nikhila Ravi, et al.
- 所属机构:Meta AI (FAIR)
- 发表时间/会议:2023年4月发布,ICCV 2023 (Best Paper Honorable Mention)
- 源码地址:https://github.com/facebookresearch/segment-anything
一句话核心:SAM 是首个图像分割的基础模型 (Foundation Model),它基于 ViT 架构,利用海量数据 (SA-1B) 训练出了强大的零样本泛化能力,允许用户通过点、框或文本提示 (Prompt) 实时分割任何物体。
2. 【2023.06】实时版的 SAM:FastSAM
SAM 虽然强但太慢(ViT 计算重),FastSAM 用工业界最成熟的 YOLO 技术实现了"既要快又要好"。
- 中文主题:FastSAM:快速分割一切
- 论文题目:Fast Segment Anything
- 作者团队:Xu Zhao, Wenchao Ding, et al.
- 所属机构:CASIA-IVA-Lab (中科院自动化所)
- 发表时间/会议:2023年6月发布,ArXiv
- 源码地址:https://github.com/CASIA-IVA-Lab/FastSAM
一句话核心:FastSAM 摒弃了沉重的 Transformer,利用 YOLOv8-seg (CNN) 将任务解耦为"全实例分割 + 提示匹配",在保持与 SAM 相当性能的同时,推理速度提升了 50 倍,达到了毫秒级实时水平。
3. 【2023.04】医学领域的通用基座:MedSAM(Segment anything in medical images)
SAM 在自然图像上很强,但在医学图像(灰度、低对比度)上表现不佳。MedSAM 是第一个填补这一鸿沟的通用医学模型。
- 中文主题:MedSAM:医学图像中的"分割一切"
- 论文题目:Segment Anything in Medical Images
- 作者团队:Jun Ma (马军), Bo Wang (王博), et al.
- 所属机构:University of Toronto (多伦多大学) & UHN
- 发表时间/会议:2023年4月发布,Nature Communications (2024) 接收
- 源码地址:https://github.com/bowang-lab/MedSAM
一句话核心:MedSAM 是首个专门针对医学图像的通用分割基础模型,它收集了百万级多模态医学数据对 SAM 进行全参数微调,结束了医学领域"一个器官训练一个专用模型"的碎片化时代。
4. 【2024.07】统一视频与图像的进化:SAM 2
SAM 解决了静态图像的分割,而 SAM 2 引入了"时间"维度,解决了视频中物体遮挡、形变和重出现的连续分割难题。
- 中文主题:SAM 2:在图像和视频中分割一切
- 论文题目:SAM 2: Segment Anything in Images and Videos
- 作者团队:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, et al.
- 所属机构:Meta FAIR (基础人工智能研究院)
- 发表时间/会议:2024年7月发布,ArXiv / SIGGRAPH 2024 (相关展示)
- 源码地址:https://github.com/facebookresearch/sam2
一句话核心:SAM 2 是首个统一图像与视频分割的基础模型,它引入了"流式记忆机制 (Streaming Memory)",不仅继承了 SAM 的零样本图像分割能力,更能对视频中的目标进行持续、连贯的追踪与分割,即使目标短暂消失也能重新找回。
5. 【2025.11】全能感知的集大成者:SAM 3
这是 SAM 家族从"几何分割"迈向"语义理解"的关键一步,不再仅仅把物体切出来,还能理解它是什么(开放词汇)。
- 中文主题:SAM 3:开放世界全能感知模型
- 论文题目:SAM 3: Open-Vocabulary Segment Anything and Everything
- 作者团队:Meta FAIR Team (Alexander Kirillov, et al.)
- 所属机构:Meta FAIR
- 发表时间/会议:2025年11月发布
- 源码地址:https://github.com/facebookresearch/sam3 (示例地址)
一句话核心:SAM 3 是视觉感知的集大成者,它彻底打破了检测、分割与追踪的任务边界,并引入了强大的"开放词汇 (Open-Vocabulary)"能力,无需微调即可识别和分割极其罕见或抽象的概念,实现了真正的通用视觉理解。
6. 【2025.11】从像素到体素的跨越:SAM 3D
与 SAM 3 同期发布,标志着 Meta 的视觉大模型正式进军三维物理世界,解决了从 2D 照片生成 3D 资产的难题。
- 中文主题:SAM 3D:将分割能力提升至三维世界
- 论文题目:SAM 3D: Segment and Reconstruct Anything in 3D
- 作者团队:Meta GenAI & FAIR Team
- 所属机构:Meta AI
- 发表时间/会议:2025年11月发布
- 源码地址:https://github.com/facebookresearch/sam3d
一句话核心:SAM 3D 实现了从"看懂图片"到"构建世界"的跨越,它能够仅凭单张 2D 图像或稀疏视角,直接重建并分割出具有完整几何结构和纹理的 3D 物体(SAM 3D Objects)甚至人体(SAM 3D Body),极大降低了 3D 内容创作的门槛。