Plan-and-Act:让AI智能体学会"先想后做"
📖 论文标题 :Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
👥 作者 :Lutfi Eren Erdogan, Zhengyuan Yang, Linjie Li, Shuohang Wang, Ahmed Awadallah, Chenguang Zhu, Liangke Gui, Lijuan Wang
🏫 机构 :Microsoft
📅 发表 :arXiv 2503.09572
🎯 一句话总结
Plan-and-Act 将智能体的"想"和"做"分离成两个专门的模块------Planner负责战略规划,Executor负责战术执行------再配合动态重规划机制和高效的合成数据生成,在Web导航任务上达到了57.58%的SOTA成功率。
📖 问题背景:为什么"边想边做"不好使?
你有没有这样的经历:一边写代码一边想架构,结果写到一半发现设计有问题,又得推倒重来?这种"边想边做"的模式,对人类来说就已经很吃力,对AI智能体来说更是灾难。
长周期任务的挑战
当LLM智能体面对复杂的多步骤任务时,比如"在GitHub上关注这个项目的顶级贡献者",它需要:
- 理解目标:搞清楚"顶级贡献者"是什么意思
- 制定策略:先找到贡献者列表,再识别谁是第一名
- 执行操作:点击正确的按钮,在正确的页面上操作
- 应对变化:页面加载失败怎么办?布局变了怎么办?
如果让一个模型同时处理这些,认知负荷太大了。就像让一个人一边下棋一边算账一边聊天------每件事都做不好。
现有方法的困境
| 方法 | 思路 | 问题 |
|---|---|---|
| ReAct | 让模型边想边做,每步都输出reasoning | 高层策略和低层操作混在一起,容易顾此失彼 |
| 单一规划 | 先生成完整计划,再执行 | 计划是静态的,无法应对环境变化 |
| 强化学习 | 通过大量trial-and-error学习 | 需要海量交互数据,成本高昂 |
更关键的是:LLM本身并没有针对"规划"这个任务进行过训练。它们见过大量的对话、代码、文章,但几乎没见过"给定一个目标,输出一个结构化的执行计划"这种数据。
🧠 核心思想:分而治之
Plan-and-Act的核心思想很朴素:把一个复杂问题拆成两个相对简单的问题。
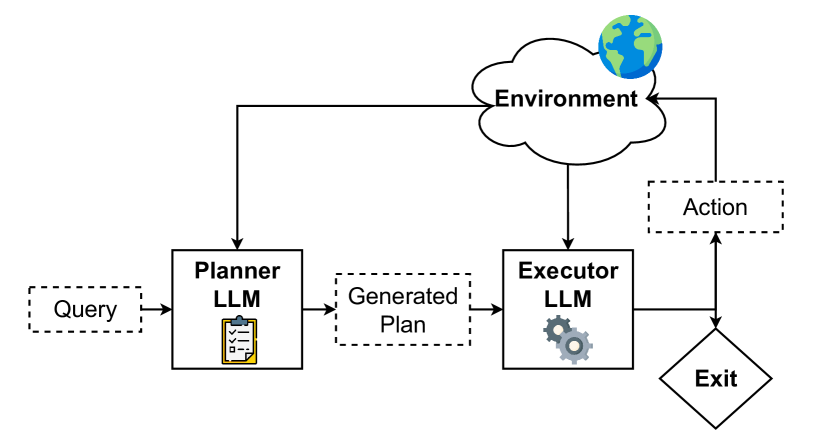
图1:Plan-and-Act整体架构------Planner生成计划,Executor执行操作,两者协同完成任务
这个架构图展示了整体流程:
- Planner LLM:接收用户查询,输出结构化的高层计划
- Executor LLM:接收计划和当前环境状态(HTML),输出具体操作
- 环境:执行操作,返回新的状态
为什么这种分离是有效的?想象一下军事指挥:
- 将军(Planner):制定战略,决定"先攻A再取B"
- 士兵(Executor):执行战术,搞清楚"怎么攻A"
将军不需要知道每把枪的操作方式,士兵不需要理解整体战局。各司其职,效率更高。
🏗️ 方法详解:Plan-and-Act的三大支柱
支柱一:Planner(规划器)
Planner的职责是将用户的目标分解成结构化的步骤列表。它的输出格式是这样的:
markdown
## Step 1
Reasoning: 用户想关注项目的顶级贡献者,需要先找到贡献者列表
Step: Navigate to the Contributors section of the project
## Step 2
Reasoning: 在贡献者列表中,第一位就是顶级贡献者
Step: Identify the top contributor and click their profile
## Step 3
Reasoning: 进入个人主页后,点击Follow按钮完成关注
Step: Click the Follow button to follow the top contributor几个设计要点:
1. 高层抽象
计划步骤是高层描述,不涉及具体的HTML元素或坐标。"Navigate to Contributors section"而不是"Click element #13"。这样的好处是:即使页面布局变了,计划依然有效。
2. 包含推理
每个步骤都有Reasoning字段,解释为什么要做这一步。这不仅提高了可解释性,还能帮助Executor更好地理解意图。
3. 灵活粒度
步骤的粒度是灵活的。简单任务可能只有2步,复杂任务可能有10步。Planner需要学会根据任务复杂度调整规划粒度。
支柱二:Executor(执行器)
Executor是一个标准的LLM智能体,负责将高层计划转化为具体操作。它的输入包括:
- 当前要执行的计划步骤
- 当前页面的HTML状态
- 之前的操作历史
输出是具体的操作指令,比如:
python
do(action="Click", element="13") # 点击第13号元素
do(action="Type", argument="John Doe", element="5") # 在第5号元素中输入文本
exit(message="任务完成") # 结束任务并返回结果Executor还有一个"垃圾回收"机制:每次操作后,它会清理掉不再需要的HTML信息,避免上下文窗口被无关内容淹没。
支柱三:动态重规划(Dynamic Replanning)
静态计划的最大问题是:它无法预见执行过程中的意外。
比如用户说"找到这个项目的顶级贡献者并关注他"。在执行前,我们不知道顶级贡献者是谁。只有点击进入Contributors页面后,才能看到"John Doe"排在第一位。
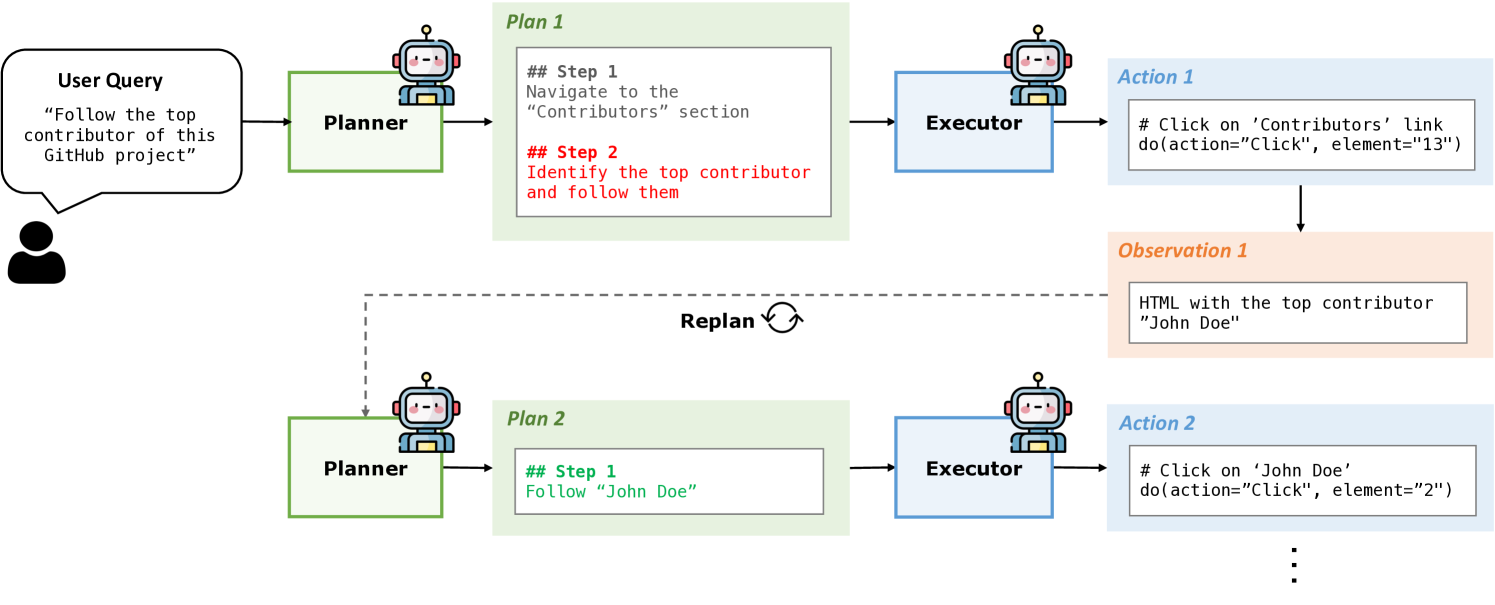
图2:动态重规划示例------初始计划只说"关注top contributor",执行后发现具体是"John Doe",新计划就能使用这个具体信息
Plan-and-Act的解决方案是:在每次Executor迭代后,让Planner根据新的环境状态重新生成计划。
这个机制带来几个好处:
- 适应性:计划能够根据实际情况动态调整
- 隐式记忆:关键信息会被编码进新的计划中(比如"John Doe"这个名字)
- 错误恢复:如果某步执行失败,Planner可以生成替代方案
实验显示,动态重规划带来了约10%的成功率提升,是非常关键的组件。
📊 合成数据生成:解决"没有训练数据"的难题
一个核心问题是:LLM从来没有针对"规划"任务训练过。WebArena数据集只有原始的操作轨迹,没有对应的高层计划。手工标注?成本太高。
作者设计了一套精巧的合成数据生成管道,分三个阶段:
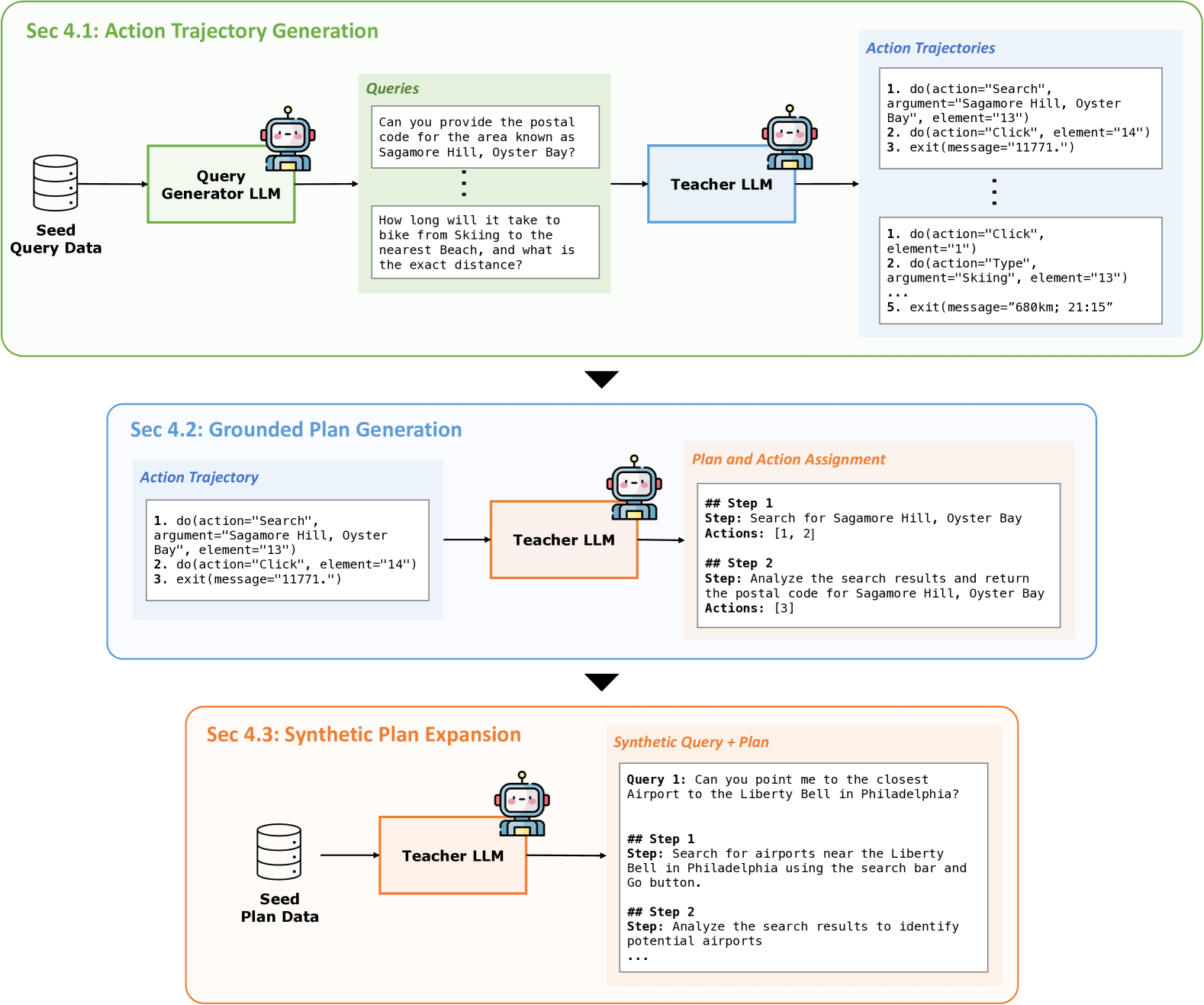
图3:三阶段合成数据生成------从轨迹生成到计划标注再到大规模扩展
阶段一:动作轨迹生成(Action Trajectory Generation)
- 查询生成:用LLM基于种子数据生成新的用户查询
- 轨迹收集:用演示智能体在真实Web环境中执行这些查询
- 质量过滤:用结果监督奖励模型(ORM)过滤成功的轨迹
这一步的产出是:大量的"查询-操作序列"对。
阶段二:基于轨迹的计划生成(Grounded Plan Generation)
这是最巧妙的部分。作者采用了逆向工程的思路:
既然我们有了成功的操作轨迹,能不能反推出执行这些操作背后的高层计划?
具体做法:
- 把成功的操作轨迹交给Teacher LLM(GPT-4)
- 让它分析这些操作,反推出高层计划
- 同时标注每个计划步骤对应哪些底层操作
这样生成的计划是有据可查的(grounded)------它一定能被成功执行,因为我们是从成功轨迹反推出来的。
python
# 示例:从轨迹反推计划
# 原始轨迹
trajectory = [
'do(action="Search", argument="Sagamore Hill, Oyster Bay", element="13")',
'do(action="Click", element="14")',
'exit(message="11771")'
]
# 反推出的计划
plan = """
## Step 1
Step: Search for Sagamore Hill, Oyster Bay
Actions: [1, 2]
## Step 2
Step: Analyze the search results and return the postal code
Actions: [3]
"""阶段三:合成计划扩展(Synthetic Plan Expansion)
环境交互太慢了------通过模拟器收集轨迹可能需要数天甚至数周。能不能不依赖环境,纯靠LLM生成更多数据?
作者的做法:
- 用阶段二生成的查询-计划对作为种子
- 让LLM基于这些种子,生成大量结构相似但内容不同的新数据
- 针对性增强:分析模型在验证集上的失败案例,针对性地生成更多相关数据
这一步生成了15000个查询-计划对,而生成时间只需要1小时(使用GPT-4)。相比之下,通过环境交互收集同等数量的数据需要几周时间。
🧪 实验结果:全面碾压基线
主实验:WebArena-Lite
WebArena-Lite是一个包含165个测试用例的Web导航基准,任务涉及电商、社交媒体、内容管理等多种场景。
| 配置 | 成功率 | 说明 |
|---|---|---|
| No Planner (ReAct) | 9.85% | 纯执行器,边想边做 |
| + Base Planner | 14.21% | 加入未微调的Planner |
| + Finetuned Planner | 29.63% | 使用轨迹数据微调Planner |
| + Data Expansion | 39.40% | 加入合成数据扩展 |
| + Dynamic Replanning | 53.94% | 加入动态重规划,超过之前SOTA |
| + Chain of Thought | 57.58% | 最终版本,新SOTA |
表1:逐步改进的消融实验结果(基础模型:LLaMA-3.3-70B-Instruct)
几个关键发现:
1. Planner的质量是瓶颈
单纯增强Executor的数据收益有限。但一个高质量的Planner配合基础版Executor,就能达到44.24%的成功率。这说明:规划能力比执行能力更稀缺。
2. 动态重规划贡献巨大
从39.40%到53.94%,提升了14.5个百分点。这验证了静态计划确实是重大限制。
3. 合成数据非常有效
从29.63%到39.40%,纯靠合成数据就提升了近10个百分点。而且合成数据的生成成本极低。
跨数据集泛化:WebVoyager
WebVoyager是一个真实世界的Web导航数据集,网站不是模拟器而是真实的互联网页面。
| 方法 | 成功率 |
|---|---|
| SeeAct (GPT-4V) | 51.1% |
| Agent-E | 73.2% |
| WebPilot | 75.2% |
| Plan-and-Act (Llama-3.1-8B) | 58.08% |
| Plan-and-Act (QWQ-32B) | 81.36% |
表2:WebVoyager结果对比(文本模式)
用8B的小模型就超过了GPT-4V,用32B模型达到了81.36%的新SOTA。这说明Plan-and-Act的框架设计是有效的,不只是"大力出奇迹"。
完整WebArena结果
在完整的WebArena数据集(812个测试用例)上:
| 方法 | 成功率 |
|---|---|
| WebRL (Llama-3.1-8B) | 32.64% |
| AgentOccam | 42.0% |
| WebPilot | 42.0% |
| Plan-and-Act (Llama-3.3-70B) | 45.7% |
| Plan-and-Act (QWQ-32B) | 48.15% |
表3:完整WebArena结果对比
🔧 工程实现细节
Planner的输入输出格式
输入:
User Query: Follow the top contributor of this GitHub project
Current State: [HTML of the project page]
Previous Actions: None输出:
markdown
## Step 1
Reasoning: To follow the top contributor, I first need to access the list of contributors
Step: Navigate to the Contributors section of the project
## Step 2
Reasoning: The contributors are typically sorted by contribution count, so the first one is the top
Step: Identify and click on the top contributor's profile
## Step 3
Reasoning: On the contributor's profile page, I can follow them using the Follow button
Step: Click the Follow buttonExecutor的输入输出格式
输入:
Current Plan Step: Navigate to the Contributors section of the project
HTML State:
[1] <a>Code</a>
[2] <a>Issues</a>
[13] <a>Contributors</a>
...输出:
python
do(action="Click", element="13")关键超参数
| 参数 | 值 | 说明 |
|---|---|---|
| 基础模型 | LLaMA-3.3-70B-Instruct | Planner和Executor使用同一基础模型 |
| 微调数据量 | ~15,000 | 合成查询-计划对 |
| 重规划频率 | 每步 | 每次Executor操作后都重规划 |
| HTML截断长度 | 8K tokens | 避免上下文过长 |
与其他方法的架构对比
| 特性 | ReAct | WebRL | AgentOccam | Plan-and-Act |
|---|---|---|---|---|
| 规划-执行分离 | ❌ | ❌ | ✅ | ✅ |
| 动态重规划 | - | - | ❌ | ✅ |
| 显式推理链 | ✅ | ❌ | ❌ | ✅ |
| 需要强化学习 | ❌ | ✅ | ❌ | ❌ |
| 合成数据扩展 | - | - | ❌ | ✅ |
💡 我的思考与启发
1. "分治"的力量
Plan-and-Act再次验证了一个古老的工程智慧:复杂问题要分解。
把"理解目标+制定策略+执行操作+应对变化"这个复杂任务,拆成"规划"和"执行"两个子任务,每个子任务的难度都大大降低。这不仅让模型更容易学习,也让系统更容易调试和优化。
2. 合成数据的价值被低估了
论文中最让我印象深刻的是合成数据生成那部分。用1小时生成15000个样本,效果还不错------这说明对于很多任务,我们缺的不是数据,而是好的数据生成方法。
逆向工程的思路很有启发:先用各种方式搞到成功的结果,再反推过程。这在很多场景都可以借鉴。
3. 动态重规划是刚需
静态计划的局限性在实验中体现得很明显。任何涉及"未知信息"的任务------比如"找到排名第一的XXX"------都需要先执行某些操作才能获取关键信息。
这让我想到人类的计划方式:我们很少一开始就制定完整的计划,而是有个大致方向,边做边调整。Plan-and-Act的动态重规划机制正是模拟了这种行为模式。
4. 局限性和改进方向
视觉理解的缺失:当前版本只用文本(HTML)作为输入,没有利用页面的视觉信息。很多Web操作其实是基于"看到"什么------按钮的颜色、位置、大小。加入视觉理解可能会进一步提升性能。
计划粒度的自适应:当前的计划步骤粒度是比较固定的。理想情况下,简单任务应该用粗粒度计划,复杂任务才需要细粒度分解。
错误恢复能力:虽然有动态重规划,但目前主要是"重新规划剩余步骤",而不是"分析失败原因并调整策略"。加入更显式的错误分析机制可能有帮助。
5. 落地建议
适合使用Plan-and-Act的场景:
- 复杂的多步骤自动化任务
- 需要适应动态环境的智能体
- 有一定标注数据但不够多的场景(可以用合成数据扩展)
不太适合的场景:
- 简单的单步任务(增加了不必要的复杂性)
- 对延迟敏感的实时系统(两个模型串行推理有延迟)
- 完全无法预测的高度动态环境
🔗 延伸阅读
| 工作 | 核心思想 | 与Plan-and-Act的关系 |
|---|---|---|
| ReAct | 推理和行动交织进行 | Plan-and-Act将两者分离 |
| WebArena | Web导航评测基准 | Plan-and-Act的主要评测环境 |
| WebRL | 用强化学习训练Web智能体 | Plan-and-Act用监督学习替代RL |
| AgentOccam | 简化的Web智能体设计 | 思路类似,但无动态重规划 |
| SeeAct | 多模态Web智能体 | Plan-and-Act目前只用文本 |
📝 结语
Plan-and-Act的成功告诉我们:有时候最简单的思路就是最有效的。
"先想清楚再动手"------这个道理人人都懂,但在AI智能体设计中,很多工作还是让模型"边想边做"。Plan-and-Act通过一个干净的架构设计和一套高效的数据生成方法,把这个朴素的道理变成了实打实的性能提升。
对于正在构建智能体系统的开发者,Plan-and-Act提供了一个值得借鉴的范式:不要指望一个模型解决所有问题,把复杂任务拆分成多个专门的子任务,往往能事半功倍。
下一步的关键问题是:如何让Planner真正理解任务的本质,而不只是生成"看起来合理"的计划?这可能需要更深层次的世界模型和推理能力。期待后续的研究能在这个方向上有所突破。