一觉醒来,AI 基础设施领域迎来重磅更新。微软原计划于 2025 年发布的下一代自研 AI 芯片 Maia 200,终于正式问世。
这并不是一颗"对标参数"的展示型芯片,而是微软为大模型推理规模化 专门打造的第一方 AI 推理加速器,目标只有一个:让每一个 AI token 生成得更便宜、更快、更稳定。
一、为 AI 推理而生,而不是"通用加速器"
从设计初衷看,Maia 200 就不是传统意义上的"全能芯片"。微软官方给它的定位非常明确:AI 推理专用基础设施。
Maia 200 采用台积电 3nm 工艺,集成了:
- 原生 FP8 / FP4 张量核心
- 全新设计的内存系统
- 216GB HBM3e 内存
- 7TB/s 内存带宽
- 272MB 片上 SRAM
- 专用数据传输引擎(DMA)
这套设计的核心目标只有一个:让大模型在推理阶段的数据流动不再成为瓶颈。
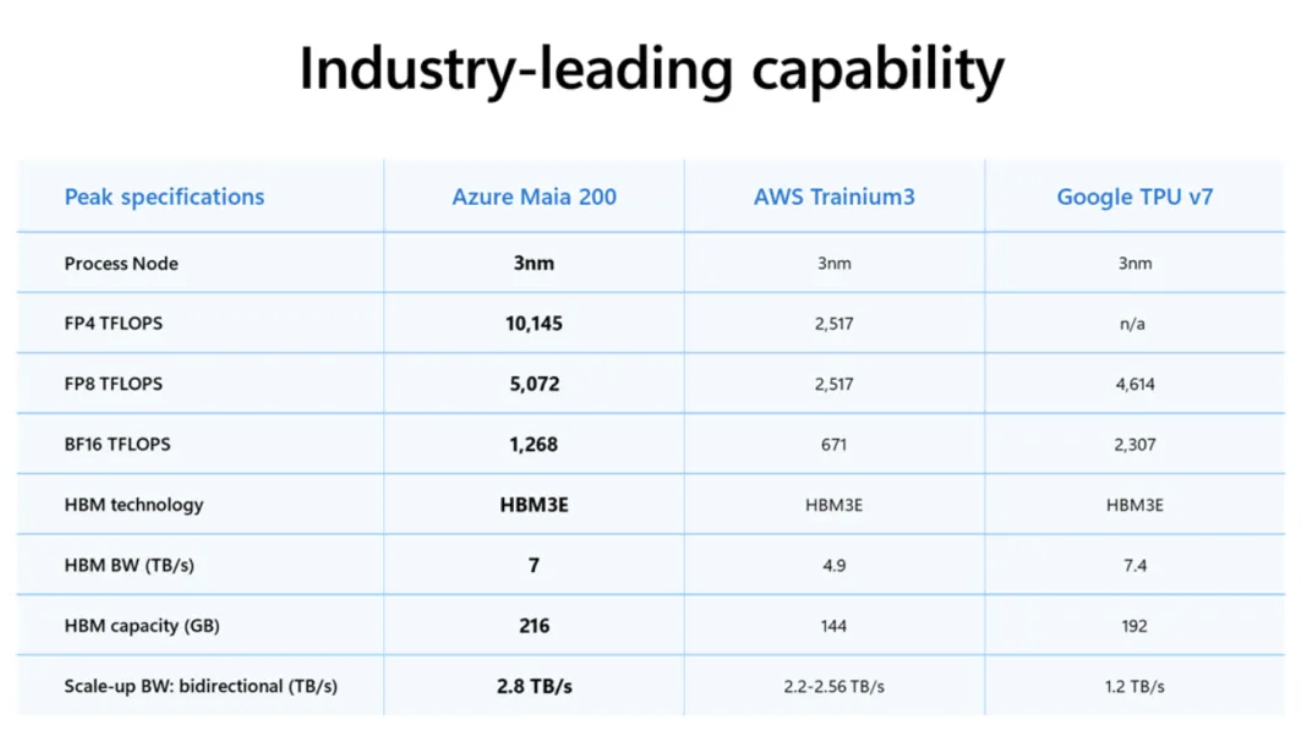
微软直言,Maia 200 是其"表现最强的第一方硅片":
- FP4 性能约为 第三代 Amazon Trainium 的 3 倍
- FP8 性能 超过谷歌第七代 TPU
与此同时,Maia 200 也是微软目前 能效最高的推理系统 ,在相同成本下,其性能比微软现有集群中最新一代硬件提升约 30%。

二、不只是芯片,而是 AI 基础设施的一部分
与其说 Maia 200 是一颗芯片,不如说它是微软 异构 AI 基础设施战略的一环。
它将直接为多个核心 AI 产品提供算力支持,包括:
- OpenAI 最新一代模型(如 GPT-5.2)
- Microsoft Foundry
- Microsoft 365 Copilot
同时,微软超级智能团队也将使用 Maia 200 进行 合成数据生成与强化学习。在合成数据流水线中,Maia 200 的架构更有利于高质量、特定领域数据的快速生成与筛选,从而为后续模型训练提供更精准的反馈信号。
目前,Maia 200 已部署在美国中部(爱荷华州德梅因附近)数据中心,并计划扩展至美国西部及更多区域。
三、算力之外,真正的瓶颈在"数据怎么跑"
在 AI 系统中,FLOPS 从来不是唯一决定性能的因素。数据如何在芯片、加速器、节点和集群之间流动,往往才是决定推理效率的关键。
Maia 200 针对这一点进行了系统级优化:
- 重构内存子系统,围绕低精度数据类型优化
- 引入专用 DMA 引擎与片上网络(NoC)
- 显著提升 Token 吞吐能力,而非单点算力指标
在系统层面,微软还为 Maia 200 引入了 基于标准以太网的双层 Scale-up 网络设计。在不依赖私有互连协议的前提下,实现了:
- 单加速器 2.8 TB/s 双向 Scale-up 带宽
- 在多达 6,144 个加速器的集群中,保持可预测、高效的集合通信
- 更低功耗与更优的 Azure 全球机架 TCO
这意味着:大规模推理不再是"堆 GPU",而是工程化系统能力的比拼。
四、云原生的芯片开发方式,才是隐藏优势
Maia 200 的另一个关键点在于:它不是"先造芯片,再想怎么用"。
微软在芯片真正流片前,就已经通过高保真预芯片环境,完整模拟了大语言模型的计算与通信模式,把:
- 芯片架构
- 网络
- 系统软件
- 数据中心部署
当作一个整体进行联合优化。
结果是:
- 从首颗芯片到数据中心机架部署,时间缩短了一半以上
- 首批封装件到位后数日内,AI 模型即成功运行
- 在云规模下持续提升 每美元性能 与 每瓦特性能
Sinokap 视角:AI 时代,基础设施决定上限
Maia 200 的发布再次说明了一件事:
AI 的竞争,正在从模型能力,转向基础设施能力。
对于企业来说,这意味着:
- AI 不再只是"买一个模型 API"
- 真正的挑战在于:算力、网络、数据、安全、运维是否支撑长期运行
- AI 是否能稳定、可控地进入生产环境,而不是成为新的风险点
Sinokap 持续关注全球 AI 基础设施与企业 IT 架构演进,帮助企业在现有环境中评估:
- AI 工作负载是否具备可扩展性
- 云与本地架构是否存在单点风险
- AI 引入后对安全、合规与运维的影响
我们相信,在大规模 AI 时代,基础设施不是后台成本,而是决定创新边界的核心能力。