基于模式匹配的方法无法描述发音中的各种变动性。例如,不同人在发一个'a'或同一个人发两次'a'时,都会存在差异。此外,人在识别声音时不仅需要听清发音,还需要有语言背景,才能理解对方说的话。我们都有这样的经验:参加一个专业性很强的报告会时,即便听清楚了演讲者的每一个发音,如果没有相关的专业背景,依然很难理解其内容。为了克服这些局限,20 世纪 80 年代,研究者引入了统计模型方法,用以对发音过程进行更精准的建模。这一方法引入了两类核心模型:声学模型------用于描述发音的各种变动性;语言模型------引入语言背景知识,帮助系统选择更合理的句子。
声学模型的目的是描述语音的生成过程。该模型将句子拆分为最基本的发音单元------音素,而每个音素再细分为三个更小的基元,称为"状态"。语音的生成过程可以看作是状态的跳转过程。
隐马尔可夫模型(Hidden Markov Model, HMM)是应用最广泛的声学模型。如图 所示,每个音素(如b、p、m、f 等)被表示为一个独立的 HMM,这些音素的 HMM 前后连接组成句子。本质上,一个 HMM 是一个状态序列,包含若干状态(图中是 3 个)。状态之间可以顺序跳转(图中圈与圈之间的连接),也可以在同一个状态内部循环(圈上的自环连接)。每个状态都对应一个概率分布函数,描述其可能生成的声学特征(如共振峰)。通过这种状态跳转和生成,隐马尔可夫模型可以描述一个完整的发音过程,并且可以计算模型对一段语音的生成概率。
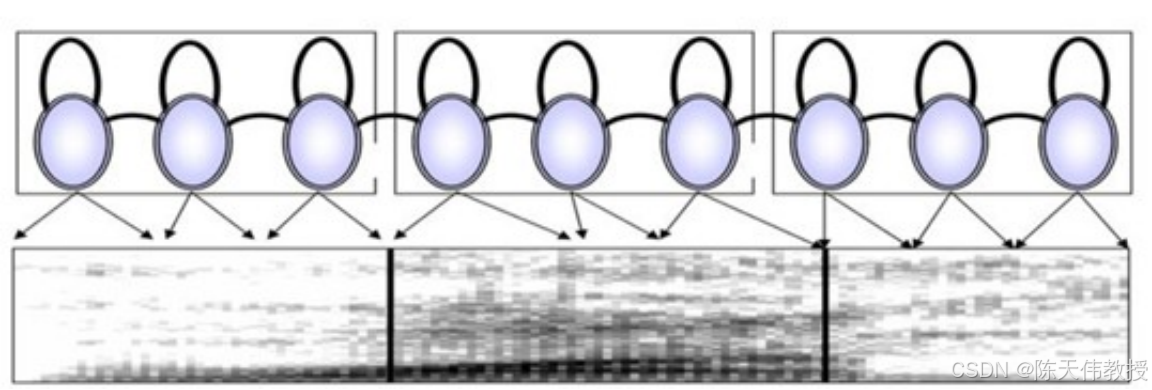
隐马尔可夫模型(HMM)描述语音的生成过程。每个圆圈代表一个状态,每三个状态代表一个发音单元(音素)。
在为每个音素建立了对应的 HMM 模型后,即可对音素进行识别。具体方法:将待识别的语音送入每个音素的HMM;计算每个HMM 生成该语音的概率;选择生成概率最高的HMM,其对应的音素即为识别结果。对于连续语音识别,情况更加复杂,因为需要考虑音素之间在时间上的拼接顺序,并选择生成整段语音概率最大的拼接方式。
HMM 是一种生成模型,旨在描述语音的生成过程。这一模型的识别过程本质上是对语音生成过程的一种反向推理。在 2012 年之前,HMM 一直是语音识别领域的主流技术,直到深度学习技术的兴起才逐渐被取代。
语言模型在语音识别中,除了声学信息,语言信息同样重要。语言信息可以通过语言模型引入,用来选择更合理的句子。图展示了一个例子。在这个例子中,待识别的句子在发音上比较模糊,声学模型难以区分"鱼刺"、"鱼翅"和"鱼池"这三个词。此时,语言模型可以发挥作用。根据语言背景知识,"我被鱼刺卡了"更符合常理,语言模型赋予其更高的概率(0.80)。因此,基本上可以断定句子里说的是"鱼刺"。

不同句子的语言模型分数不同