本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- Linux的魔法世界:进程、内存与操作系统的三重奏
-
- 第一章:进程------操作系统里的"执行单元"
- 第二章:操作系统内核------幕后的总指挥
-
- [用户空间 vs 内核空间](#用户空间 vs 内核空间)
- 系统调用:跨越边界的桥梁
- 调度器:时间的管理者
- 第三章:虚拟内存------最伟大的魔法
- 第四章:三者关系------完整的图景
- 第五章:深入实践------动手探索
- 总结
- 参考资源
Linux的魔法世界:进程、内存与操作系统的三重奏
想象一下,你打开了一个音乐播放器,又启动了浏览器,再开了一个文本编辑器。电脑同时运行着这么多程序,却不会互相干扰,这是为什么?
如果我说,这一切都发生在同一个物理内存条上,你可能会更困惑。今天,我们就来揭开Linux操作系统的魔法面纱,探索进程、操作系统内核和虚拟内存空间是如何协同工作的。
第一章:进程------操作系统里的"执行单元"
什么是进程?
你可能在编程时听说过"程序"和"进程"这两个词。初学者经常把它们搞混,但它们其实有本质区别:
| 概念 | 生活比喻 | 核心特点 |
|---|---|---|
| 程序 | 冰箱里的食谱 | 静态的,躺在磁盘上的文件 |
| 进程 | 正在做饭的厨师 | 动态的,占用CPU和内存的执行实例 |
一个程序可以同时对应多个进程。就像同一份烘焙食谱(程序),可以有五个人(五个进程)在各自的厨房里同时制作蛋糕。
每个进程都有一个独一无二的身份证号------PID(Process ID)。在Linux中,你可以用这个号码来和进程"交流"。
进程的"背包"------内存区域
当一个进程启动时,操作系统会为它分配一个"背包",里面装着它需要的所有东西。这个背包按区域划分:

进程虚拟地址空间(每个进程都有自己独立的一份)
┌─────────────────────────────┐ ↑
│ 命令行参数和环境 │ 高地址
├─────────────────────────────┤ │
│ 栈 (Stack) │ │ 函数调用、局部变量
│ ↓ │ │ 向下生长
├─────────────────────────────┤ │
│ ▲ │ │
│ │ │ │
│ 内存映射段 (mmap) │ │ 动态库、共享内存
├─────────────────────────────┤ │
│ 堆 (Heap) │ │ malloc/new分配的内存
│ ▲ │ │ 向上生长
├─────────────────────────────┤ │
│ BSS段 │ │ 未初始化的全局变量
├─────────────────────────────┤ │
│ 数据段 │ │ 已初始化的全局变量
├─────────────────────────────┤ │
│ 代码段 │ │ 只读,程序指令
├─────────────────────────────┤ │
│ 保留空间 │ │ 防止NULL指针访问
└─────────────────────────────┘ │ 0x0000000000000000栈(Stack):就像一摞盘子。每次调用函数,放一个新盘子;函数返回,拿走一个盘子。存放局部变量和函数调用信息。
堆(Heap) :程序运行时动态申请的内存在这里。malloc、new申请的内存都来自堆。
代码段(Text):程序的机器码,只读的------不能修改正在运行的代码。
来看看你的进程
打开终端,试试这些命令:
bash
# 查看所有进程
ps -ef
# 查看当前shell进程的信息
ps -f $$
# 实时监控进程(像任务管理器)
top
# 更漂亮的版本(如果安装了htop)
htop
# 查看某个进程占用的内存
cat /proc/1/status | grep -i mem试着运行一个简单程序,然后找到它的PID:
bash
# 在后台运行一个简单的sleep程序
sleep 300 &
# 最后一行显示的数字就是PID,比如[1] 12345
# 现在查看这个进程的详细信息
cat /proc/12345/status你会看到一堆有趣的信息:进程名字、状态、父进程PID、内存使用情况等。
进程间通信:它们如何"聊天"
进程是相互隔离的,但有时候需要交流。Linux提供了多种方式:
管道(Pipes):像一根管子,一个进程往里写,另一个进程从里面读。
bash
# 查看文件内容,然后过滤出包含"python"的行
cat somefile.txt | grep python这里cat和grep是两个进程,管道|连接了它们的输出和输入。
共享内存:最快的方式,多个进程可以直接读写同一块内存区域。
信号(Signals) :像发送一个"通知",比如Ctrl+C就是发送SIGINT信号。
第二章:操作系统内核------幕后的总指挥
用户空间 vs 内核空间
你写的程序运行在"用户空间"------一个受限的环境。为什么?主要是为了安全:
用户空间:
- 只能访问自己的内存
- 不能直接操作硬件
- 需要通过系统调用请求帮助
内核空间:
- 可以访问所有内存
- 可以操作硬件
- 拥有最高权限
这就像一个国家:普通公民(用户空间)不能随便进入政府办公区(内核空间),需要办理手续(系统调用)。
系统调用:跨越边界的桥梁
当你的程序需要做一些"特权操作"时,比如打开文件或创建新进程,必须调用系统调用。
c
// 用户代码
int fd = open("myfile.txt", O_RDONLY); // 系统调用!这行代码背后发生了什么:
用户程序调用open()
↓
切换到内核模式
↓
内核检查权限,打开文件
↓
返回文件描述符
↓
切换回用户模式
↓
用户程序继续执行调度器:时间的管理者
电脑只有一个CPU(或者几个),却有几十甚至上百个进程都在"想"运行。谁来决定谁什么时候能跑?调度器(Scheduler)!
调度器给每个进程分配"时间片"(Time Slice),通常是几毫秒。时间片用完,就切换到下一个进程。因为切换很快,我们感觉所有程序在同时运行。
进程的状态:
创建 → 就绪 → 运行 → 阻塞 → 就绪
↑ ↓
└────────────────┘- 就绪(Ready):准备好了,等着CPU
- 运行(Running):正在CPU上执行
- 阻塞(Blocked):等待某个事件(比如网络数据)
你可以查看进程状态:
bash
ps -eo pid,stat,cmd | head状态字母含义:
R= Running/RunnableS= Sleeping(可中断的等待)D= Uninterruptible sleep(通常在等待I/O)T= Stopped(被暂停)Z= Zombie(僵尸进程)
第三章:虚拟内存------最伟大的魔法
为什么需要虚拟内存?
如果进程直接访问物理内存,会有大问题:
- 没有隔离:一个进程的错误可能破坏其他进程
- 地址冲突:每个进程都想用0x1000这个地址
- 内存不足:物理内存有限,但程序想要的更多
虚拟内存解决了这些问题!每个进程都以为自己拥有整个地址空间,实际上访问的是映射后的物理内存。
虚拟地址空间大小
在现代64位Linux系统上(x86-64架构):
┌─────────────────────────────┐
│ 内核空间 (128TB) │ 0xffff800000000000 +
├─────────────────────────────┤
│ 非 canonical 区间 │
├─────────────────────────────┤
│ 用户空间 (128TB) │ 0x0000000000000000 +
└─────────────────────────────┘实际上,Linux默认使用48位虚拟地址(256TB),而不是完整的64位(太大了用不完)。
- 用户空间:0x0000000000000000 到 0x00007fffffffffff(128TB)
- 内核空间:0xffff800000000000 到 0xffffffffffffffff(128TB)
页表:地址翻译的秘密武器
虚拟内存不是整块映射,而是分成固定大小的"页"(Pages)。默认页大小是4KB。
页表(Page Table) 存储虚拟页到物理页的映射关系。
x86-64使用4级页表结构:
虚拟地址(48位):
┌─────┬─────┬─────┬─────┬─────┐
│ PML4│ PDPT│ PDT │ PTE │ 偏移 │
└─────┴─────┴─────┴─────┴─────┘
9位 9位 9位 9位 12位
每次查找一级 → 最终得到物理页号这看起来很复杂,但硬件MMU(内存管理单元)会自动完成这个翻译过程,速度非常快。
为了更快,CPU有TLB(Translation Lookaside Buffer)------一个缓存,存储最近的地址翻译结果。
来看一个真实的进程内存布局
写个小程序看看自己的内存长什么样:
c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global_var = 100; // 数据段
int uninit_var; // BSS段
void print_address(const char* name, void* addr) {
printf("%-20s: %p\n", name, addr);
}
int main() {
int local_var = 200; // 栈上
int* heap_var = malloc(sizeof(int)); // 堆上
*heap_var = 300;
printf("=== 内存地址演示 ===\n\n");
print_address("代码段", (void*)main);
print_address("数据段", &global_var);
print_address("BSS段", &uninit_var);
print_address("堆", heap_var);
print_address("栈", &local_var);
printf("\n按回车查看 /proc/self/maps...\n");
getchar();
// 让程序一直运行,方便查看
printf("PID: %d\n", getpid());
printf("查看内存映射: cat /proc/%d/maps\n", getpid());
printf("按回车退出...\n");
getchar();
free(heap_var);
return 0;
}编译运行:
bash
gcc -o memory_demo memory_demo.c
./memory_demo输出类似:
=== 内存地址演示 ===
代码段 : 0x55c8c7b2d14a
数据段 : 0x55c8c7c4a010
BSS段 : 0x55c8c7c4a068
堆 : 0x55c8c92312a0
栈 : 0x7ffd8e9b646c你会发现:
- 栈地址很高(接近用户空间顶部)
- 堆地址在中间
- 代码、数据、BSS在较低的位置
保持程序运行,在另一个终端查看:
bash
# 查看完整的内存映射
cat /proc/$(pgrep memory_demo)/maps
# 或者用 pmap(如果安装了)
pmap $(pgrep memory_demo)输出格式:
55c8c7b2d000-55c8c7b2e000 r-xp 00000000 08:01 123456 /path/to/memory_demo
55c8c7b2e000-55c8c7b2f000 r--p 00001000 08:01 123456 /path/to/memory_demo
55c8c7b2f000-55c8c7b30000 rw-p 00002020 08:01 123456 /path/to/memory_demo
...每列含义:
- 虚拟地址范围
- 权限(r=读,w=写,x=执行,p=私有)
- 偏移量
- 设备和inode
- 文件路径
缺页中断:按需加载
你可能好奇:程序很大,启动时要把所有代码都加载到内存吗?
答案是:不用!
当程序启动时,操作系统只设置好页表,并不真的加载所有页面。当程序真正访问某个地址时:
- CPU发现该页不在内存中
- 触发缺页中断
- 操作系统把需要的页从磁盘加载到内存
- 更新页表
- 重新执行指令
这叫"按需加载"(Demand Paging),节省了内存和时间。
Copy-on-Write:聪明的内存共享
当你用fork()创建子进程时,内核不会立即复制父进程的所有内存。相反:
- 父子进程共享相同的物理页
- 所有页标记为"只读"
- 当任何一方尝试写入时:
- 触发缺页中断
- 复制该页
- 重新设置权限
这大大提高了性能!fork()几乎是瞬间完成的,因为只是复制了页表指针。
第四章:三者关系------完整的图景
现在让我们把所有线索串起来。
从命令行到程序运行的旅程
当你在终端输入./myprogram arg1 arg2时:
1. Shell解析命令
↓
2. Shell调用fork()创建子进程
↓
3. 子进程调用execve()替换自己
- 读取程序文件
- 创建新的虚拟地址空间
- 设置页(代码、数据、BSS)
- 设置栈,放入参数和环境变量
↓
4. 调度器将新进程放入就绪队列
↓
5. 新进程开始执行 main() 函数
↓
6. 每次内存访问:
虚拟地址 → 页表翻译 → 物理地址 → 访问内存操作系统如何协调一切
用一个比喻总结:
| 组件 | 角色 | 职责 |
|---|---|---|
| 进程 | 工人 | 执行具体任务 |
| 虚拟内存 | 私人办公室 | 每个工人有自己的空间 |
| 页表 | 地址簿 | 虚拟地址和真实地址的对应 |
| 内核 | 管理者 | 分配资源,调度任务 |
| 调度器 | 时间管理员 | 决定谁什么时候工作 |
| MMU | 翻译官 | 自动完成地址翻译 |
完整的数据流图
┌─────────────────────────────────────────────────────────────┐
│ 用户空间 │
│ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ 进程 A │ │ 进程 B │ │
│ │ ┌────────┐ │ │ ┌────────┐ │ │
│ │ │ 代码段 │ │ │ │ 代码段 │ ││
│ │ ├────────┤ │ │ ├────────┤ │ │
│ │ │ 栈 │ │ │ │ 栈 │ │ │
│ │ └────────┘ │ │ └────────┘ │ │
│ │ 虚拟地址: │ │ 虚拟地址: │ │
│ │ 0x1000 │ │ 0x1000 │ (相同虚拟地址!) │
│ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │
└─────────┼─────────────────────────┼────────────────────────────┘
│ │
│ 系统调用/中断 │
│ │
┌─────────┴─────────────────────────┴────────────────────────────┐
│ 内核空间 │
│ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ 页表A: 0x1000 → 物理页 0xABC000 │ │
│ │ 页表B: 0x1000 → 物理页 0xDEF000 │ │
│ └──────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ 调度器 │ │
│ │ (决定谁在CPU上运行) │ │
│ └──────────────────────────────────────────────────┘ │
│ │
└────────────────────┬─────────────────────────────────────────┘
│ MMU自动翻译
↓
┌─────────────────────────────────────────────────────────────┐
│ 物理内存 │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 0xABC000 │ │ 0xDEF000 │ │ 其他页 │ │
│ │ (进程A) │ │ (进程B) │ │ │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────┘关键点:进程A和进程B都使用虚拟地址0x1000,但它们映射到不同的物理页面!
第五章:深入实践------动手探索
使用/proc文件系统
/proc是Linux提供的一个神奇目录,它不是真正的文件系统,而是内核信息的窗口。
bash
# 查看所有进程
ls /proc
# 查看当前进程的命令行
cat /proc/self/cmdline
# 查看当前进程的内存映射
cat /proc/self/maps
# 查看当前进程的完整状态
cat /proc/self/status
# 统计所有进程的内存使用
for pid in $(ls /proc | grep -E '^[0-9]+$'); do
mem=$(cat /proc/$pid/status 2>/dev/null | grep VmRSS | awk '{print $2}')
name=$(cat /proc/$pid/comm 2>/dev/null)
echo "$name: $mem KB"
done | sort -k2 -rn | head -10观察Copy-on-Write
写个小程序验证写时复制:
c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/wait.h>
int global = 1;
int main() {
printf("开始: &global = %p, global = %d\n", &global, global);
pid_t pid = fork();
if (pid == 0) {
// 子进程
printf("子进程: 修改前 global = %d\n", global);
global = 2;
printf("子进程: 修改后 global = %d\n", global);
printf("子进程: &global = %p\n", &global);
return 0;
} else {
// 父进程
wait(NULL); // 等待子进程完成
printf("父进程: global = %d\n", global);
printf("父进程: &global = %p\n", &global);
}
return 0;
}编译运行,你会发现父子进程修改了同一个变量,但值不同!因为修改时发生了写时复制。
性能优化技巧
了解这些原理后,你可以写出更高效的代码:
1. 减少缺页中断:
- 尽量连续访问内存(更好的局部性)
- 使用
mlock()锁定关键内存页
2. 合理使用栈和堆:
- 小对象用栈(自动释放、快)
- 大对象用堆(栈空间有限)
3. 内存对齐:
- 对齐的内存访问更快
posix_memalign()分配对齐内存
4. 了解你的内存:
bash
# 查看系统内存信息
cat /proc/meminfo
# 查看页面大小
getconf PAGESIZE总结
核心概念
- 进程:程序的动态执行实例,有自己独立的虚拟地址空间
- 虚拟内存:每个进程独享的"假"内存,通过页表映射到物理内存
- 页表:虚拟地址到物理地址的映射表,CPU的MMU硬件自动翻译
- 内核:操作系统的核心,管理进程、内存、硬件等所有资源
- 调度器:决定哪个进程在CPU上运行,实现"多任务"幻觉
三者的关系
它们不是独立的概念,而是一个完整的系统:
进程 ←─ 虚拟内存(每个进程有自己的一套)
↑
│
操作系统内核 ─→ 管理所有进程和内存
│
└──→ 调度器决定谁运行虚拟内存是连接进程和物理内存的桥梁,内核是管理一切的指挥家。
为什么理解这些很重要?
理解这些底层原理,你就能:
- 更好地调试内存问题
- 写出更高效的代码
- 理解操作系统行为
- 学习更高级的主题(如容器、虚拟化)
继续探索的路径
书籍推荐:
- 《深入理解Linux内核》------经典之作
- 《Linux内核设计与实现》------更容易入门
- 《操作系统概念》------理论基础
在线资源:
- Linux内核官方文档
- man页面(
man proc、man mmap等) - LWN.net------Linux内核新闻
实践项目:
- 写一个简单的shell(实现
fork、exec、pipe) - 实现一个简单的内存分配器
- 研究
strace工具,追踪系统调用
最后的话
操作系统是程序员最好的老师。理解了Linux是如何管理进程和内存的,你就掌握了计算机系统最核心的魔法。这些知识不仅有趣,还能让你写出更好的程序。
现在,打开终端,运行几个命令,感受一下那些在你电脑上默默工作的进程吧!
bash
# 最后的探索
echo "=== 你的系统在运行什么? ==="
ps aux --sort=-%mem | head -5
echo -e "\n=== 内存使用情况 ==="
free -h
echo -e "\n=== 祝你探索愉快! ==="
Happy Hacking!
参考资源
- Linux Kernel Documentation
- man pages: proc(5)
- Understanding the Linux Kernel
- Linux Memory Management
- What Every Programmer Should Know About Memory
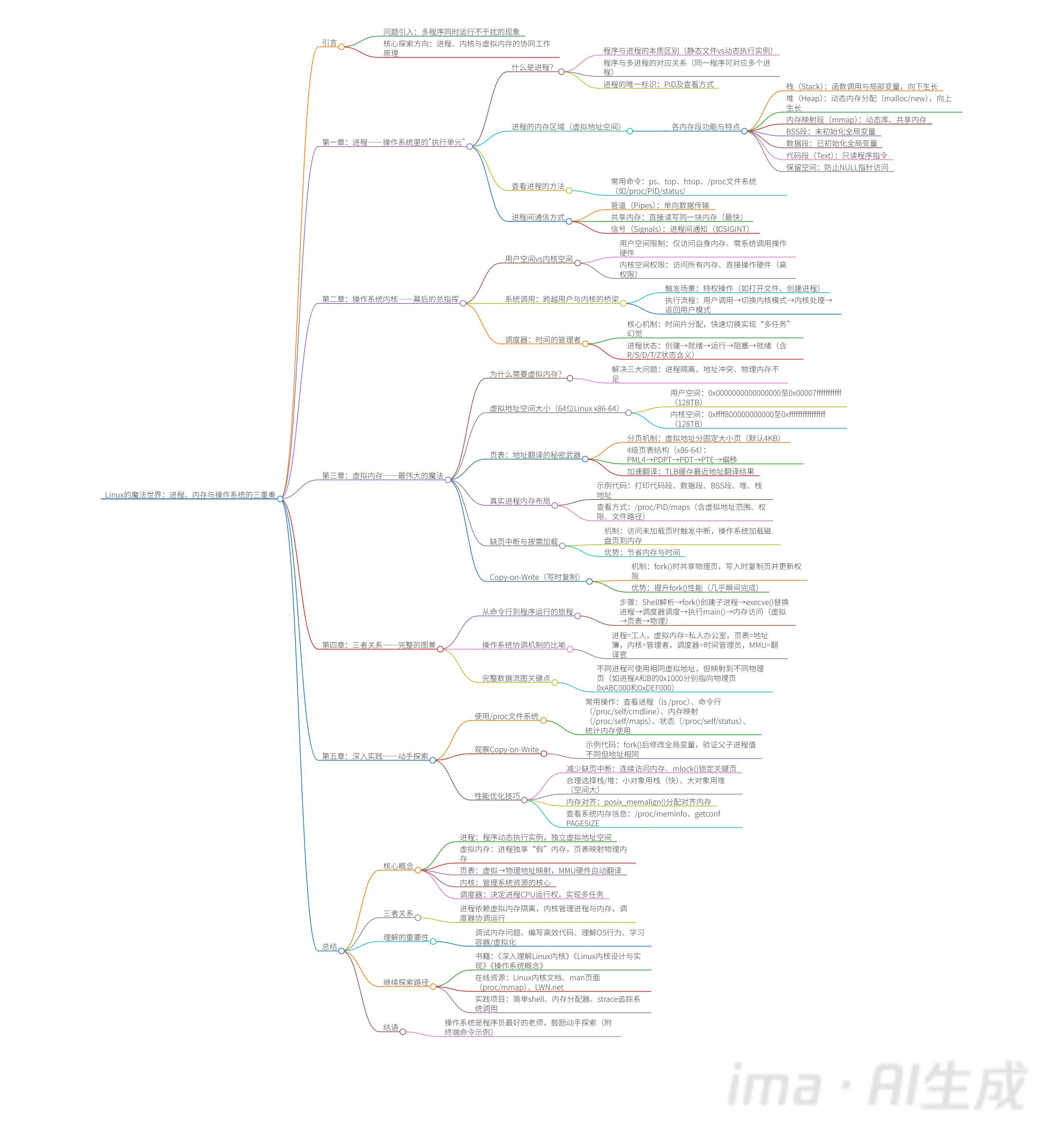
下面是ima生成的脑图总结:
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

