在前面的文章中我们自己定义并实现了一个自定义协议,从序列化和反序列化,到封装报文,解析报文等,这就是我们自己实现的一个应用层协议。虽然我们说, 应用层协议是我们程序员自己定的,但实际上,已经有大佬们定义了一些现成的,又非常好用的应用层协议 ,供我们直接参考使用,HTTP(超文本传输协议)就是其中之一,所以下面我们就来认识一下
一、HTTP 协议介绍
1.概念
**HTTP(HyperText Transfer Protocol,超文本传输协议)**是互联网中最重要的应用层协议之一。它定义了客户端(如浏览器)与服务器之间进行通信的规则和格式,主要用于传输超文本(如HTML文档)以及其他网络资源。
简单来说,HTTP 定义了客户端(通常是 Web 浏览器)和服务器之间如何通信。它规定了客户端可以发送哪些请求,以及服务器应该返回哪些响应
2.HTTP 的工作流程(一次典型的网页访问)
- 建立 TCP 连接:客户端(浏览器)首先与服务器的 80 端口(HTTP)或 443 端口(HTTPS)建立一个 TCP 连接。
- 发送 HTTP 请求:客户端向服务器发送一个 HTTP 请求报文。
- 服务器处理请求:服务器接收、解析请求,并执行相应的操作(例如查找资源、运行程序)。
- 返回 HTTP 响应:服务器将处理结果封装成一个 HTTP 响应报文,发回给客户端。
- 关闭连接:在 HTTP/1.0 中,连接通常会关闭。在 HTTP/1.1 及以后版本中,连接可能被保持以供后续请求复用。
- 客户端渲染:浏览器接收到响应后,解析 HTML、CSS、JavaScript,并渲染出完整的页面。
二、HTTP协议的格式
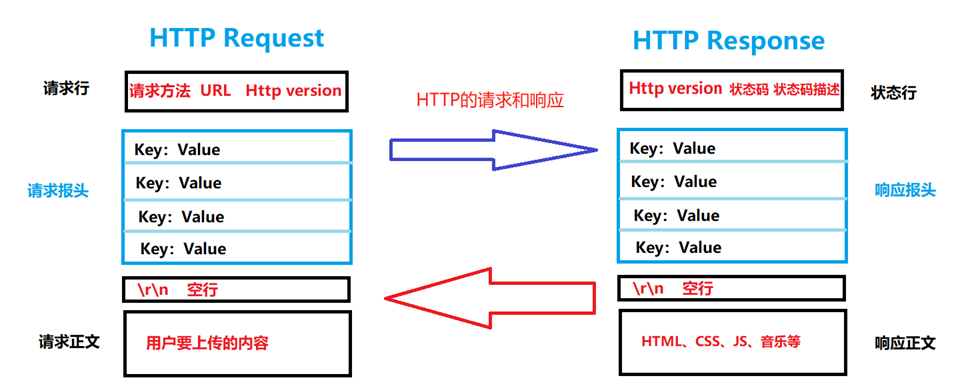
其中请求行(状态行)和请求报头(响应报头)被统称为http报头,而请求正文(响应正文)被称为有效载荷,可以省略。
http协议请求格式
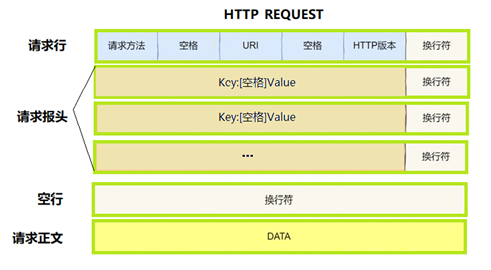
**请求格式包含请求方法,url,http版本,请求报头,以及正文。**其中元素之间用空格和换行符隔开,用于区分不同元素,用于解决粘包问题。
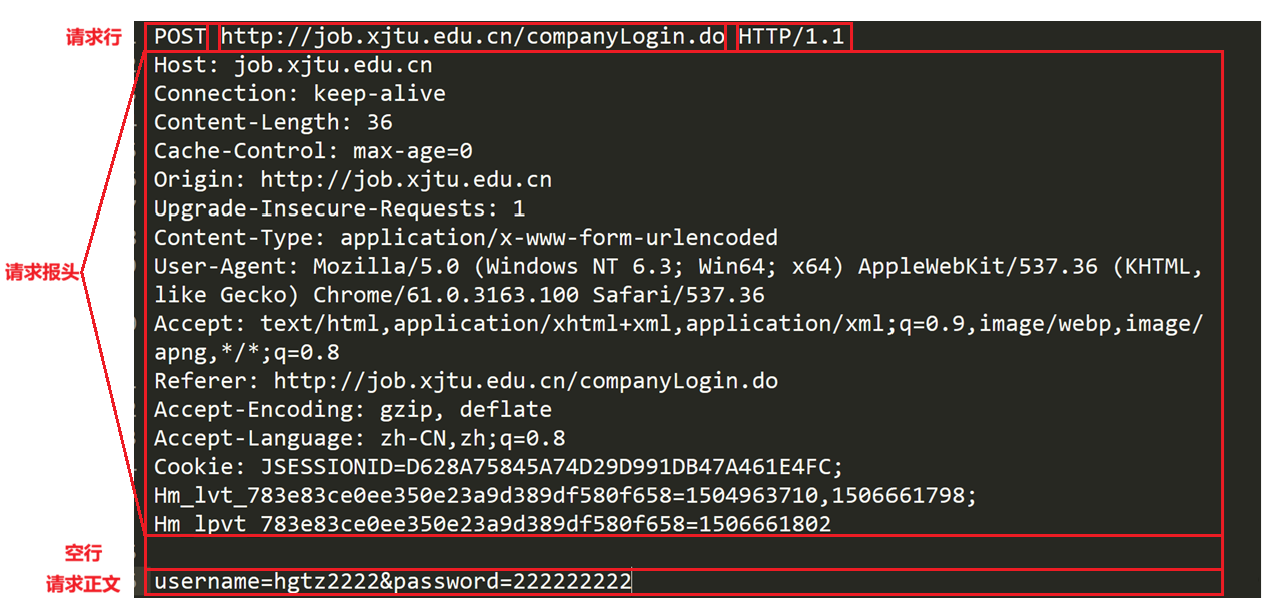
示例:
1.URL
URL(Uniform Resource Locator)统一资源定位符,简单说就是我们日常生活中的网址,我们通过这个唯一的url就能访问到特定的资源。
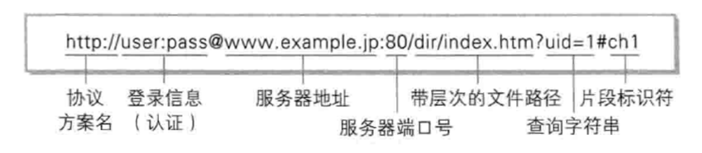
- http/https:标识当前使用的协议,它定义了客户端和服务器之间通信的规则。
- //:表示 URL想访问服务器的什么资源。
- www.example.jp:表示服务器的域名,特定格式的字符串,可以解析为IP地址
- 80:表示服务器进程的端口号,是一个不能随便更改的值,与协议名称是一对一的(https协议常用的端口号为443,http协议常用的端口号为80)。正因如此,端口号很多时候都被隐藏了。
- /:80后面的第一个斜杠表示web根目录。
- /dir/index.htm:这个字符串表示文件路径,当请求发到服务端上时,就会在这个目录下查找对应文件,进行传输。
- ?uid=1:?后面是客户端向服务端传递的参数 ,参数之间用&分隔,格式为 参数=值
- #ch1:片段(也称为"锚点")用于指向资源内部的某个特定部分,用#分隔。浏览器在加载完整个页面后,会自动滚动到该片段所标识的位置。它不会被发送到服务器
真实的url与示例上的会不太一样,有省略的或者新增的部分。
URL编码(urlencode 和 urldecode)
像?:/等这样的字符,已经被url当作特殊字符理解了,所以不能随意出现。所以,当传递的参数中有这些特殊字符时,就必须进行转义(urlencode)
URLDecode是URLEncode的逆过程,将编码后的字符恢复为原始字符
规则: 使用百分号 % 后跟两位十六进制数来表示该字符的 ASCII 码
- 将需要转码的字符转换为16进制
- 从右到左取4位(不足4位直接处理)
- 每2位作为一组,前面加上%
- 格式为:%XY
常见例子:
- 空格: 编码为 %20 或 + (编码为+并不是标准的 URL 编码方式,而是 特定上下文中的特殊约定)。
- 中文: 如"中国"在 UTF-8 编码下会被编码为 %E4%B8%AD%E5%9B%BD。
- 符号: & 编码为 %26,? 编码为 %3F。
示例:
- 一个未编码的 URL:https://example.com/search?q=hello world&lang=zh-CN
- 编码后的 URL:https://example.com/search?q=hello world\&lang=zh-CN
例如:
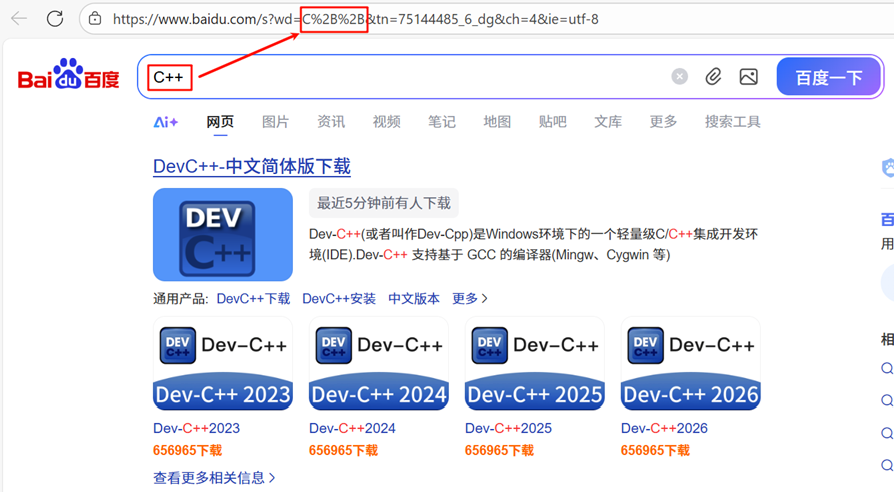
上图中 "+" 被转义成了 "%2B"
编码解码的网站:
https://tool.chinaz.com/tools/urlencode.aspx
2.method请求方法
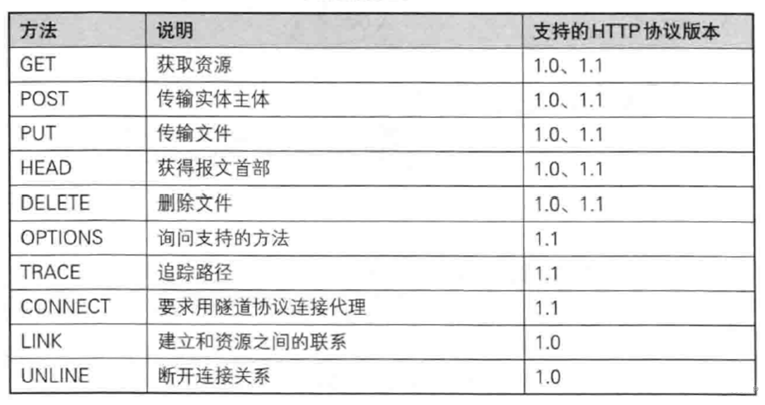 其中GET和POST方法是最常用的:
其中GET和POST方法是最常用的:
- GET方法:如果提交参数,是通过url方式进行提交的。
- POST方法:如果提交参数,是通过正文进行提交的。
GET方法:通过URL传递需要提交的参数

POST方法:在请求正文传递需要提交的参数
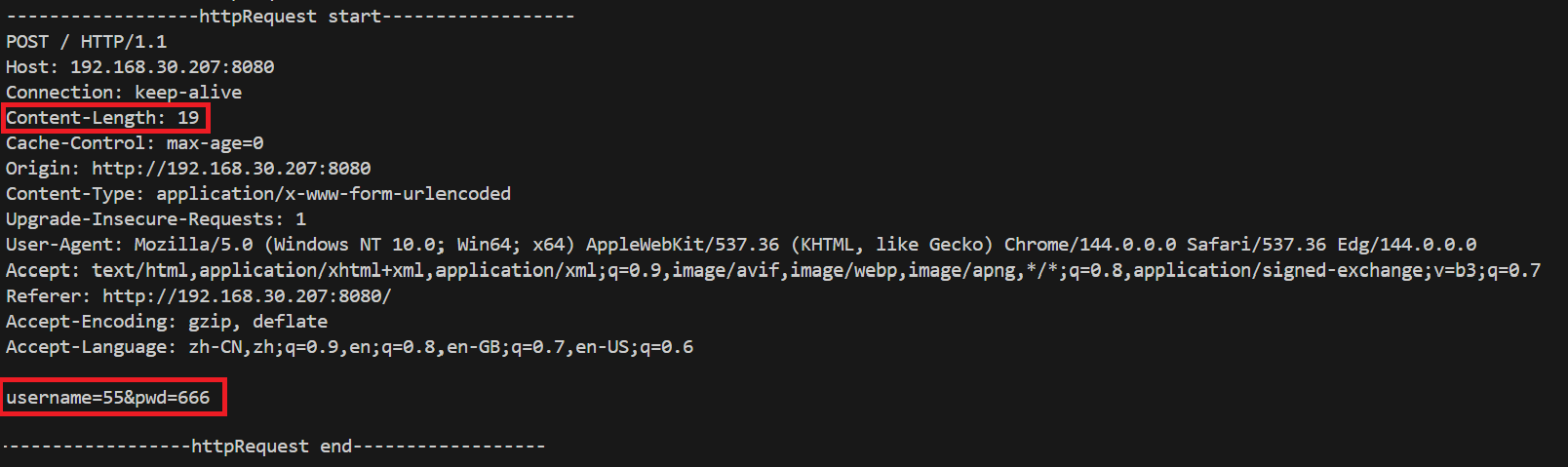

它们的区别在于:
- 参数提交的位置不同,POST方法比较私密(私密 != 安全),不会回显到浏览器的url输入框。
- GET方法是通过url传参的,而url是有大小限制的,和具体浏览器有关;POST方法是由正文部分传参,一般大小没有限制。
3.请求报头
请求报头用于说明,例如说明客户端浏览器类型,可接受数据格式,是否缓存,是否长连接等。
下面是一些常见报头:
- **Cookie:**携带客户端本地存储的信息,用于记录用户偏好,登陆状态信息等。
- **Content-Type:**指定正文数据的格式(传表单数据、JSON数据、文件上传......)
- **Content-Length:**请求正文字节数
- **Accept:**可接受的内容类型,JSON格式HTML格式等等
- **Host:**请求的主机名和端口号
- **Referer:**告知当前的请求从何处跳转
4.HTTP 版本
HTTP 有很多版本,HTTP1.0 HTTP1.1 HTTP2.0 等等。
- HTTP1.0 支持GET,POST等多种方法,但是只能建立短连接,每次访问都要重新建立新连接。
- HTTP1.1 在HTTP1.0 的基础上支持了长连接,客户端可以一次发送多个请求,不需要没发送一个请求建立一次连接,大大增加了效率。
http协议响应格式
1.状态码
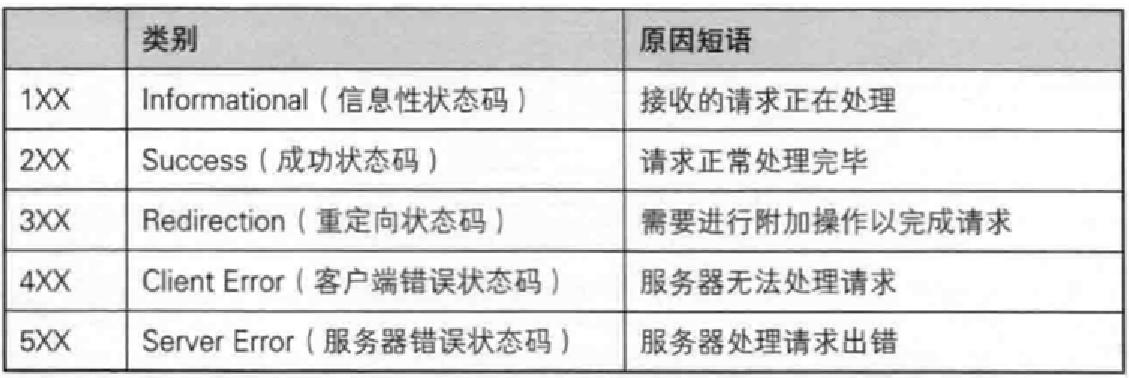
状态码是服务端给客户端的实际反馈,任务是否成功失败的原因是什么等等。
任务码分为五类,分别由1,2,3,4,5开头。
- 1,2,3开头的状态码是请求正常响应
- 4开头是客户端出错(eg.客户端申请不存在的资源)
- 5开头是服务端出错(eg.服务器挂掉了)
1xx:表示服务器已经接收请求正在响应
- 100:上传大文件时,服务端告知客户端继续上传
2xx:服务器成功处理数据返回
- 200(OK):服务器成功返回网络内容
- 201:服务器文章创建成功
- 204:删除文章后服务器表示无内容返回成功
3xx:请求资源位置变更
- 301:永久重定向,访问的资源永久更改位置
- 302(Redirect):临时重定向,访问的资源临时更改位置
4xx:客户端存在错误
- 404(Not Found):填写表单不正确错误返回
- 401:访问登陆页面时未登录访问失败
- 403(Forbidden):尝试访问没有权限的页面
- 404:访问不存在的网络连接
5xx:服务端存在错误
- 500:服务器崩溃,数据库崩溃
重定向概念
重定向的例子:
- 访问网站时,跳转到另一个广告网址
- 登陆后,自动跳转到首页
**HTTP中的重定向:**当客户端访问一个服务器不可用的资源后,服务端返回一个新的url,并且状态码是3XX,浏览器会自动用这个新的url向新地址的服务端发起请求,无需用户点击,是浏览器自动跳转的。
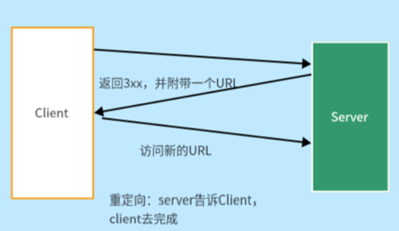
重定向状态码,需要浏览器提供支持,server要告诉浏览器应该跳转到哪里。而http报头 中的Location就起到这个作用。
构造响应报头:
cpp
resp_hander +="Location: http://www.example.com/\r\n";//重定向示例即可实现重定向
永久重定向和临时重定向
status code = 301 : 永久重定向,搜索引擎或者浏览器会自动将书签、历史记录、搜索引擎对应的记录中旧链接更新为新链接。下次就直接访问新链接。
status code = 302: 临时重定向,原来的URL仍然有效,下次还访问旧链接。
2.响应报头
响应报头的主要作用是告知客户端如何处理数据,或传递服务相关信息。
下面是一些常见报头
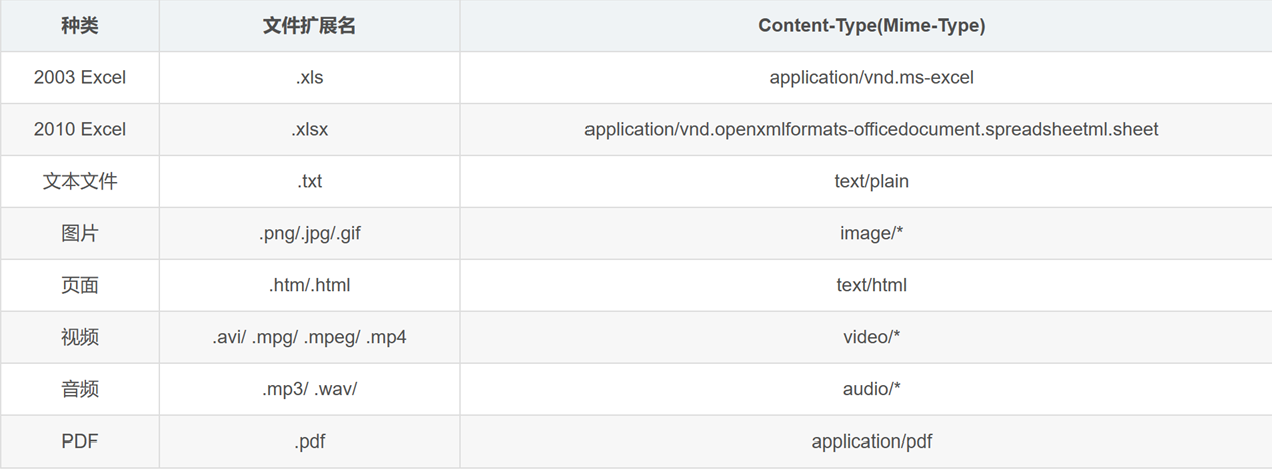
- **content-type:**指定正文格式,是传表单数据,JSON数据还是文件上传等等
- **content-length:**请求正文长度(字节)
- **content-encoding:**告知客户端正文使用的压缩格式
- **Location:**指定重定向,告知客户端需要跳转的新url
Content-Type对应类型标识可以看下面的表格:
http协议常见报头
| 字段名 | 含义 | 样例 |
|---|---|---|
| Accept | 客户端可接受的响应内容类型 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8 |
| Accept-Encoding | 客户端支持的数据压缩格式 | Accept-Encoding: gzip, deflate, br |
| Accept-Language | 客户端可接受的语⾔类型 | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 |
| Host | 请求的主机名和端口号 | Host: www.example.com:8080User-Agent |
| User-Agent | 客户端的软件环境信息 | User-Agent: Mozilla/5.0 (Windows NT 10.0;Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 |
| Cookie | 客户端发送给服务器的HTTP cookie信息 | Cookie: session_id=abcdefg12345; user_id=123 |
| Referer | 请求的来源URL | Referer:http://www.example.com/previous_page.html |
| Content-Type | 实体主体的媒体类型 | Content-Type: application/x-www-formurlencoded (对于表单提交) 或 Content-Type:application/json (对于JSON数据) |
| Content-Length | 实体主体的字节大小 | Content-Length: 150 |
| Authorization | 认证信息,如用户名和密码 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== (Base64编码后的用户名:密码) |
| Cache-Control | 缓存控制指令 | 请求时: Cache-Control: no-cache 或 CacheControl: max-age=3600 ;响应时: CacheControl: public, max-age=3600 |
| Connection | 请求完后是关闭还是保持连接 | Connection: keep-alive 或 Connection: close |
| Date | 请求或响应的日期和时间 | Date: Wed, 21 Oct 2023 07:28:00 GMT |
| Location | 重定向的目标URL(与3xx状态码配合使用) | Location:http://www.example.com/new_location.html (与302状态码配合使用) |
| Server | 服务器类型 | Server: Apache/2.4.41 (Unix) |
| Last-Modified | 资源的最后修改时间 | Last-Modified: Wed, 21 Oct 2023 07:20:00 GMT |
| ETag | 资源的唯⼀标识符,用于缓存 | ETag: "3f80f-1b6-5f4e2512a4100" |
| Expires | 响应过期的日期和时间 | Expires: Wed, 21 Oct 2023 08:28:00 GMT |
三、HTTP通信的简单模拟
如何能保证读取完整的报文?
- 通过换行符能保证读取到完整的一行
- 读到空行保证 请求行+请求报头/状态行+响应报头 读完
- 如果有正文,报头中会有属性Content-Length:XXX,代表正文的长度,保证读到完整的正文
如何实现序列化?
以 \r\n 为分隔符,将状态行、响应报头、空行、正文连接成长字符串

telnet测试工具:直接读取响应报文
不需要通过浏览器发送请求,可以使用 telnet+IP地址127.0.0.1+端口号的方式进行本地环回发送http请求。
安装telnet工具:
bash
sudo yum install telnet使用示例:
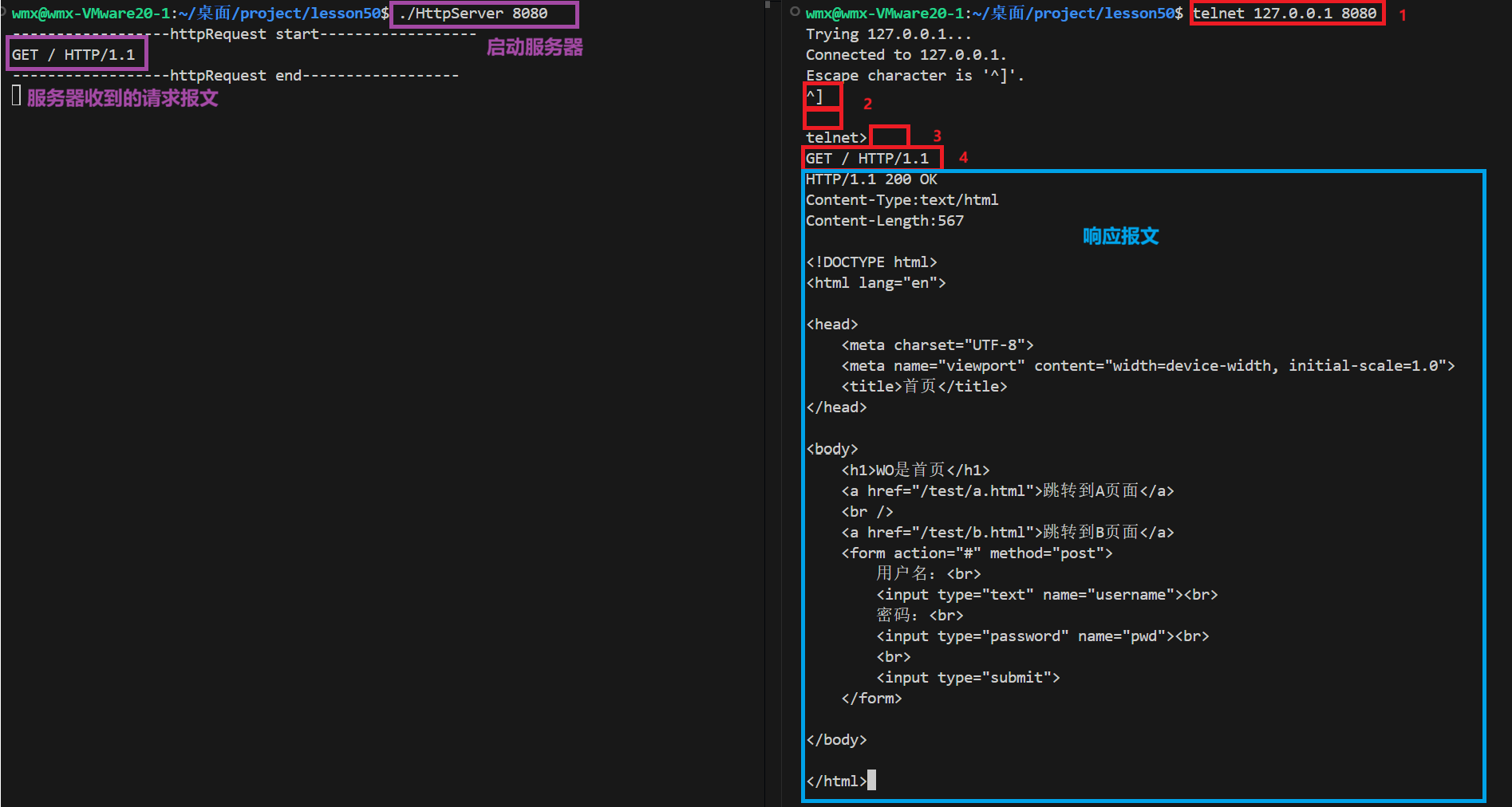
运行程序,使用8080作为端口号:
- 输入telnet 127.0.0.1 8080向服务器发送请求
- 按Ctrl+ ]键,再按Enter键,会显示telent>
- 再按Enter键,跳到下一行
- 手动输入请求行GET / HTTP/1.1,按Enter键
此时我们就向服务端发送了请求,通过处理后我们也能收到服务器的响应,这些响应就会以文本形式读取,不会被解析。
1.测试代码
启动服务器=》通过在浏览器输入IP地址+端口号,客户端与服务端建立TCP连接=》服务器获取请求并打印(用作测试)
protocol.hpp
cpp
#pragma once
#include <iostream>
#include <cstring>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
// 客户端请求结构体
class HttpRequest
{
public:
std::string inbuffer;
public:
HttpRequest()
{
}
};
// 服务器响应结构体
class HttpResponse
{
public:
std::string outbuffer;
public:
HttpResponse()
{
}
};HttpServer.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <sys/types.h>
#include <sys/socket.h>
#include <functional>
#include <strings.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <thread>
#include "protocol.hpp"
using namespace std;
typedef std::function<void(const HttpRequest &, HttpResponse &)> func_t;
enum
{
USAGE_ERROR = 1,
SOCKET_ERROR = 2,
BIND_ERROR = 3,
LISTEN_ERROR = 4,
ACCEPT_ERROR = 5,
READ_ERROR = 6,
WRITE_ERROR = 7
};
class HttpServer
{
private:
uint16_t _port; // 端口号
int _listen_sockfd; // socket描述符(文件描述符)
func_t _func; // 处理函数
public:
HttpServer(func_t func, const uint16_t &port)
: _port(port),
_listen_sockfd(-1),
_func(func)
{
}
// 初始化服务器
void InitServer()
{
// 1. 创建socket
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0); // IPv4协议 TCP模式 默认值
if (_listen_sockfd == -1)
{
exit(SOCKET_ERROR);
}
// 2. 绑定bind
struct sockaddr_in local; // IPv4 网络地址结构体
bzero(&local, sizeof(local)); // 清空结构体
local.sin_family = AF_INET; // 表示使用 IPv4 协议
local.sin_port = htons(_port); // 端口号 htons 主机字节序转网络字节序
local.sin_addr.s_addr = INADDR_ANY; // 系统定义的宏(值为 0x00000000,对应 IPv4 地址 0.0.0.0)
int n = bind(_listen_sockfd, (struct sockaddr *)&local, sizeof(local)); // 绑定socket与地址
if (n < 0)
{
exit(BIND_ERROR);
}
// 3. 监听listen
n = listen(_listen_sockfd, 5); // 最大连接数5
if (n < 0)
{
exit(LISTEN_ERROR);
}
}
// 处理客户端请求
void serviceClient(int client_sockfd)
{
HttpRequest req;
HttpResponse resp;
char buffer[4096];
ssize_t n = recv(client_sockfd, buffer, sizeof(buffer) - 1, 0);//假设能够一次性读取完整的Http请求
if (n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
_func(req, resp);
send(client_sockfd, resp.outbuffer.c_str(), resp.outbuffer.size(), 0);
}
}
// 启动服务器
void Start()
{
while (true)
{
// 4. 与客户端连接accept
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int client_sockfd = accept(_listen_sockfd, (struct sockaddr *)&peer, &len);
if (client_sockfd < 0)
{
continue;
}
// 多线程
std::thread t(&HttpServer::serviceClient, this, client_sockfd);
t.detach(); // 分离线程
}
}
~HttpServer()
{
}
};HttpServer.cpp
cpp
#include <iostream>
#include <memory>
#include "HttpServer.hpp"
#include "protocol.hpp"
using namespace std;
void HandlerRequest(const HttpRequest &req, HttpResponse &resp)
{
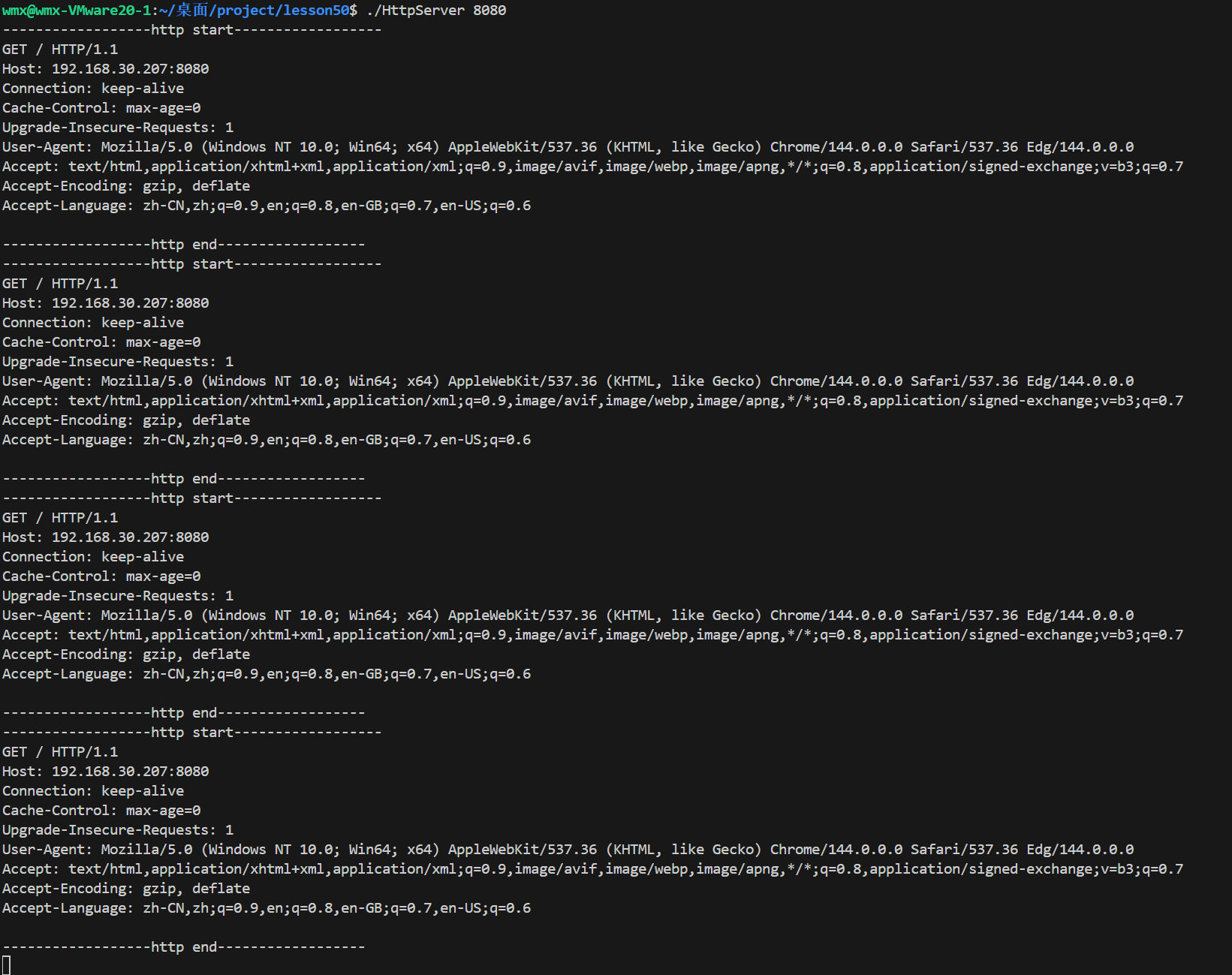
cout << "------------------http start------------------" << endl;
resp.outbuffer = req.inbuffer;
cout << req.inbuffer;
cout << "------------------http end------------------" << endl;
}
// 输入 ./tcpServer port
int main(int argc, char *argv[])
{
if (argc != 2)
{
cerr << "Usages:" << argv[0] << " port" << endl;
exit(USAGE_ERROR);
}
uint16_t _port = atoi(argv[1]);
unique_ptr<HttpServer> httpserver(new HttpServer(HandlerRequest, _port));
httpserver->InitServer();
httpserver->Start();
return 0;
}运行结果
获得一张完整的网页需要多次http请求(获取网页的图标、内容......),再由浏览器进行组合和渲染
2.模拟实现
文件结构:其中wwwroot是web根目录,index.html是首页
protocol.hpp
cpp
#pragma once
#include <iostream>
#include <cstring>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/stat.h>
#define SEP "\r\n"
const std::string default_root = "./wwwroot";
const std::string default_page = "index.html";
// 客户端请求结构体
class HttpRequest
{
public:
std::string inbuffer;
std::string method;
std::string url;
std::string httpversion;
std::string path;
std::size_t filesize = -1;
public:
HttpRequest()
{
}
// 解析http请求行
void ParseHttpRequest()
{
// 获取请求行
size_t pos = inbuffer.find(SEP);
if (pos == std::string::npos)
{
std::cerr << "ParseHttpRequest error" << std::endl;
return;
}
std::string request_line = inbuffer.substr(0, pos);
// 解析请求行: 方法 URL 版本 eg: GET /index.html HTTP/1.1
size_t pos_method = request_line.find(" ");
if (pos_method == std::string::npos)
{
std::cerr << "ParseHttpRequest error" << std::endl;
return;
}
method = request_line.substr(0, pos_method); // 获取请求方法 eg: GET
size_t pos_url = request_line.find(" ", pos_method + 1);
if (pos_url == std::string::npos)
{
std::cerr << "ParseHttpRequest error" << std::endl;
return;
}
url = request_line.substr(pos_method + 1, pos_url - pos_method - 1); // 获取请求URL eg: /index.html
httpversion = request_line.substr(pos_url + 1); // 获取HTTP版本 eg: HTTP/1.1
// 删除请求行
inbuffer.erase(0, pos + strlen(SEP));
// 设置web默认访问路径
path = default_root + url;
if (path[path.size() - 1] == '/')
{
path += "index.html";
}
// 获取访问资源的大小
struct stat st;
if (stat(path.c_str(), &st) == 0)
{
filesize = st.st_size;
}
}
};
// 服务器响应结构体
class HttpResponse
{
public:
std::string outbuffer;
public:
HttpResponse()
{
}
};HttpServer.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <sys/types.h>
#include <sys/socket.h>
#include <functional>
#include <strings.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <thread>
#include "protocol.hpp"
using namespace std;
typedef std::function<void(const HttpRequest &, HttpResponse &)> func_t;
enum
{
USAGE_ERROR = 1,
SOCKET_ERROR = 2,
BIND_ERROR = 3,
LISTEN_ERROR = 4,
ACCEPT_ERROR = 5,
READ_ERROR = 6,
WRITE_ERROR = 7
};
class HttpServer
{
private:
uint16_t _port; // 端口号
int _listen_sockfd; // socket描述符(文件描述符)
func_t _func; // 处理函数
public:
HttpServer(func_t func, const uint16_t &port)
: _port(port),
_listen_sockfd(-1),
_func(func)
{
}
// 初始化服务器
void InitServer()
{
// 1. 创建socket
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0); // IPv4协议 TCP模式 默认值
if (_listen_sockfd == -1)
{
exit(SOCKET_ERROR);
}
// 2. 绑定bind
struct sockaddr_in local; // IPv4 网络地址结构体
bzero(&local, sizeof(local)); // 清空结构体
local.sin_family = AF_INET; // 表示使用 IPv4 协议
local.sin_port = htons(_port); // 端口号 htons 主机字节序转网络字节序
local.sin_addr.s_addr = INADDR_ANY; // 系统定义的宏(值为 0x00000000,对应 IPv4 地址 0.0.0.0)
int n = bind(_listen_sockfd, (struct sockaddr *)&local, sizeof(local)); // 绑定socket与地址
if (n < 0)
{
exit(BIND_ERROR);
}
// 3. 监听listen
n = listen(_listen_sockfd, 5); // 最大连接数5
if (n < 0)
{
exit(LISTEN_ERROR);
}
}
// 处理客户端请求
void serviceClient(int client_sockfd)
{
// 5. 通信recv/send
// 读取完整的http请求=》解析请求=》处理请求=》构造响应=》发送响应
HttpRequest req;
HttpResponse resp;
char buffer[4096];
ssize_t n = recv(client_sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
req.inbuffer = buffer;
req.ParseHttpRequest(); // 解析http请求行
_func(req, resp); // 处理请求,构造响应
send(client_sockfd, resp.outbuffer.c_str(), resp.outbuffer.size(), 0); // 发送响应
}
}
// 启动服务器
void Start()
{
while (true)
{
// 4. 与客户端连接accept
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int client_sockfd = accept(_listen_sockfd, (struct sockaddr *)&peer, &len); //
if (client_sockfd < 0)
{
continue;
}
// 多线程
std::thread t(&HttpServer::serviceClient, this, client_sockfd);
t.detach(); // 分离线程
}
}
~HttpServer()
{
}
};HttpServer.cpp
cpp
#include <iostream>
#include <memory>
#include <string>
#include <fstream>
#include "HttpServer.hpp"
#include "protocol.hpp"
using namespace std;
bool readFile(const string &path, string *body)
{
std::ifstream file(path.c_str());
if (!file.is_open())
{
return false;
}
char ch;
while ((ch = file.get()) != EOF)
{
body->push_back(ch);
}
file.close();
return true;
}
void HandlerRequest(const HttpRequest &req, HttpResponse &resp)
{
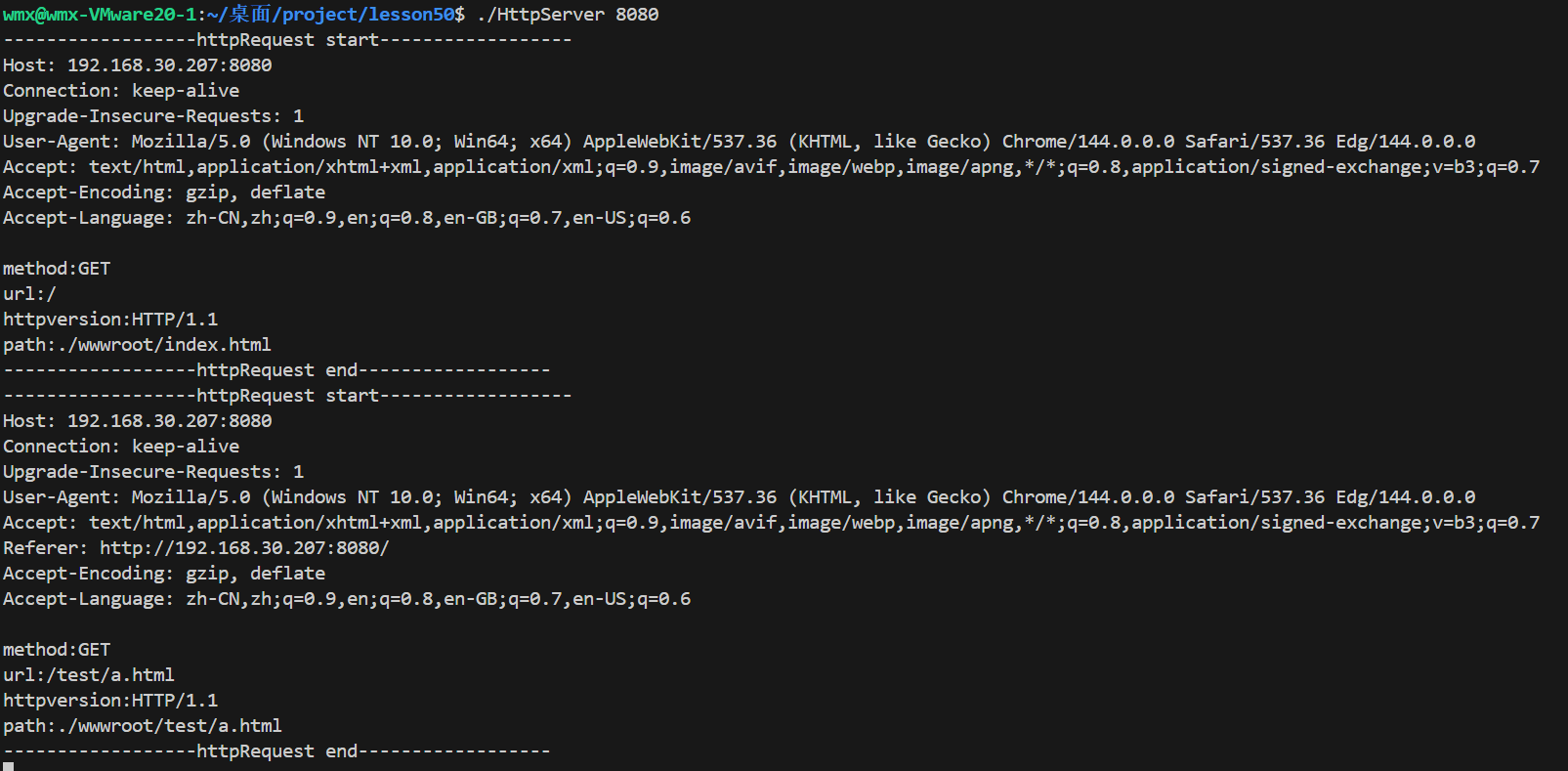
cout << "------------------httpRequest start------------------" << endl;
cout << req.inbuffer;
cout << "method:" << req.method << endl;
cout << "url:" << req.url << endl;
cout << "httpversion:" << req.httpversion << endl;
cout << "path:" << req.path << endl;
cout << "------------------httpRequest end------------------" << endl;
string resp_line = "HTTP/1.1 200 OK\r\n"; // 构造状态行
// 构造响应报头
string resp_hander = "Content-Type:text/html\r\n"; // 指定响应类型为html
if (req.filesize > 0)
{
resp_hander += "Content-Length:" + to_string(req.filesize) + "\r\n"; // 指定响应正文的长度
}
// resp_hander +="Location: http://www.example.com/\r\n";//重定向示例
string resp_black = "\r\n"; // 构造空行
string resp_body; // 响应正文
if (!readFile(req.path, &resp_body)) // 读取文件失败
{
resp_body = "<html><body><h1>404 Not Found</h1></body></html>";
}
resp.outbuffer = resp_line + resp_hander + resp_black + resp_body;
}
// 输入 ./tcpServer port
int main(int argc, char *argv[])
{
if (argc != 2)
{
cerr << "Usages:" << argv[0] << " port" << endl;
exit(USAGE_ERROR);
}
uint16_t _port = atoi(argv[1]);
unique_ptr<HttpServer> httpserver(new HttpServer(HandlerRequest, _port));
httpserver->InitServer();
httpserver->Start();
return 0;
}index.html
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>首页</title>
</head>
<body>
<h1>WO是首页</h1>
<a href="/test/a.html">跳转到A页面</a>
<br />
<a href="/test/b.html">跳转到B页面</a>
</body>
</html>a.html
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>我的网页</title>
</head>
<body>
<h1>这是A页面</h1>
<br/>
<a href="/index.html">返回首页</a>
</body>
</html>b.html
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>我的网页</title>
</head>
<body>
<h1>这是B页面</h1>
<br/>
<a href="/index.html">返回首页</a>
</body>
</html>运行结果


四、长连接
一个网页中有多种类型的资源(图片、文字......),而一次请求只能获取一种类型的资源。所以,一个网页的形成就需要浏览器发起多次http请求 ,解析响应。而每次请求都需要建立和关闭TCP链接,会消耗大量资源,所以需要长链接。
- 在HTTP/1.0中,每次请求和响应都需要建立和关闭TCP链接,这被称为短链接。
- 而在HTTP/1.1中,引入了**持久链接(也称为长链接)**的概念,允许多个请求和响应通过同一个TCP链接进行传输。
在HTTP/1.1中,持久链接通过在请求报头中添加"Connection: keep-alive" 来表示客户端希望保持链接,而服务器则可以在响应报头中添加"Connection: keep-alive" 来确认是否支持持久链接。如果服务器不支持持久链接,会在**响应报头中添加"Connection: close"**来表示关闭链接。
五、会话保持
1.引入
访问网页时往往需要登陆账号,只需要输入用户名和密码一次,之后也不会退出登录 。但是HTTP是一种无状态协议,每次请求并不会记录它曾经请求了什么。所以,在第一次登录后,在网站内进行网页跳转时,是打开一个新的网页,理论上需要再次输入账号密码,但不符合现实。
这就与Cookie技术有关
2.Cookie 工作原理与用途
Cookie通常用来记录服务器发送到浏览器的一小部分数据,这份数据在浏览器中保存下来,它用来记录一些用户信息,用户偏好等等。
- 当用户第一次访问网站时,客户端会在http协议请求的 set-cookie 报头中存储用户的信息(账号密码......)
- 用户将数据传给服务器,服务器将这份数据传回给浏览器,并在本地浏览器保存下来
- 之后向这个网站申请访问时,浏览器会自动将已保存的用户登录信息添加到http请求报头中,通过HTTP协议发送给服务器。
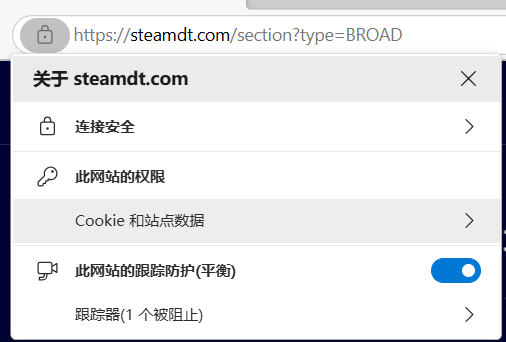
如我们打开一个浏览器,随意一个网站左上角处可以找到一把锁,点开里面的Cookie和站点数据,内部就存储着浏览器记录的用户在当前网站的一些信息偏好。
有了Cookie的存在,当我们使用一些登陆平台时不再需要每打开一次网址就登陆一次,浏览器保存了用户的账号密码,每当用户访问该网站时,客户端会携带Cookie信息一同发送给服务端。
当然Cookie也存在着安全隐患,由于Cookie存储着本人特有的信息,如若被不法之人恶意窃取,通过一些技术脚本获得到我们的Cookie信息,那么它们就可以拿着这些信息冒充我们的身份去访问服务器
3.内存级与文件级Cookie技术
我们在登录CSDN后,关掉浏览器后再次打开CSDN你还是能保持登录状态。
这又是怎么实现的呢?
Cookie又分为内存级和文件级
- 内存级Cookie:将登录信息保存在浏览器的缓冲区中,当浏览器被关闭时,进程结束,保存的信息也失效了,重新打开浏览器后还需要重新登录。
- 文件级Cookie:将信息保存在文件中,文件是放在磁盘上的,无论浏览器怎么打开关闭,文件中的信息都不会删除,在之后发送HTTP请求时,浏览器从该文件中读取信息并加到请求报头中。
根据日常使用浏览器的情况,大部分网站在你登陆后,关闭浏览器再次打开时登陆状态依旧保持,所以大部分情况下的Cookie都是文件级别的,而且这些文件是可以从我们的计算机中找到的。
4.Cookie 格式
Cookie格式分为请求头 Cookie 和响应头 set-cookie ,它们的参数都很类似,我们就选 set-cookie来介绍
Set-Cookie: name=value; [属性1=值1]; [属性2=值2]; ...其中name=value 是必选选项,其余属性都可以自由选择,每个属性之间用分号+空格隔开。其中的name可以是用户姓名,主题颜色,登陆状态等,value就是键值对应用户id,颜色,登录情况。
属性:
Expires:
设置Cookie过期时间,决定了Cookie的生命周期,采用格林威治时间,格式如下
Expires=Wed, 21 Oct 2026 07:28:00 GMT 星期几 日 月 年 具体时间 这几部分组成
Domain:设定特定的访问域名,该份Cookie数据只有访问该域名时才会生效
Domain=.example.com
Path:指定访问该域名下的特定路径,我们只能访问根目录下的某一个特定的文件夹
Path=/admin
Secure:设定仅允许https协议下才允许携带,否则不通过,此处只需填写用户名
Secure(无值,仅写属性名)
5.Session 工作原理
既然Cookie文件储存了许多我们的隐私信息,那么一旦这些Cookie文件被不法份子盗取,他们就可以冒用我们的身份进行一些非法操作,并且进行一些非法操作。(比如说QQ盗号)
所以为了保证信息安全,我们需要通过session与其进行配合:
- 用户首次访问服务器时,服务器上会创建一个Session文件,用于保存用户的账号密码以及浏览痕迹等信息。
- 而每个Session文件都会分配一个特定的session id,通过 响应头set-Cookie 将session id传回给客户端,保存在Cookie中。
- 当客户端再次访问时,就是通过 请求头Cookie 传递 session id 访问网站。
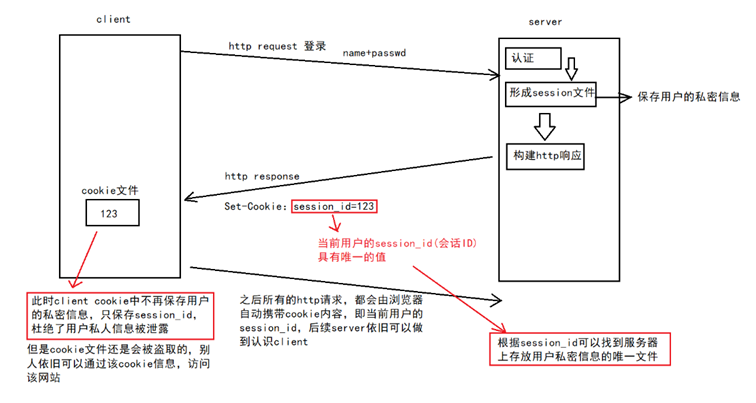
这样避免了将敏感信息暴露在外部,而是使用session id 这种无实际意义的值进行了替代。即使它人拿到了session id,也需要进行解密才能使用,增加了安全性。
虽然session并不能有效的防止信息泄露,但是衍生出了一些防御措施:例如通过常用ip地址判定用户账号是否存在异常,如果存在异常地址登录,服务器则会废弃掉当前的session_id,让用户重新认证登录。