- 本文列举了LLMUnity包中的几个重要脚本,自己在GPT的帮助下,学习这个Unity的包,进行一些脚本的拆解分析,仅供抛砖引玉,请多赐教!
文章目录
- 一、LLM参数面板设置
-
- [1. Remote (远程模式)](#1. Remote (远程模式))
- [2. Num Threads (线程数)](#2. Num Threads (线程数))
- [3. Num GPU Layers (GPU 显存层数)](#3. Num GPU Layers (GPU 显存层数))
- [4. Debug (调试模式)](#4. Debug (调试模式))
- [5. Parallel Prompts (并行提示词数)](#5. Parallel Prompts (并行提示词数))
- [6. Dont Destroy On Load (载入时不销毁)](#6. Dont Destroy On Load (载入时不销毁))
- 7.Model
- [8.Context Size](#8.Context Size)
- [9.Batch Size](#9.Batch Size)
- [10.Chat Template](#10.Chat Template)
- 二、LLMCharacter参数面板设置
-
- 1.Remote
- 2.Llm
- 3.Save
- [4.Save Cache](#4.Save Cache)
- [5.Debug Prompt](#5.Debug Prompt)
- 6.Stream
- [7.Player Name](#7.Player Name)
- [8.AI Name](#8.AI Name)
- 9.Prompt
- [10、Model Settings (推理控制参数)](#10、Model Settings (推理控制参数))
-
- [(1)Num Predict:](#(1)Num Predict:)
- (2)Slot:
- (3)Grammar:
- [(4)Grammar JSON:](#(4)Grammar JSON:)
- [(5)Cache Prompt:](#(5)Cache Prompt:)
- (6)Seed:
- [(7)Temperature :](#(7)Temperature :)
- [(8)Top K / Top P / Min P / Typical P:](#(8)Top K / Top P / Min P / Typical P:)
- [(9)Ignore Eos:](#(9)Ignore Eos:)
- 三、ChatBot参数面板设置
-
- [1、Chat Container (聊天容器):](#1、Chat Container (聊天容器):)
- [2、LLM Character (LLM 角色引用):](#2、LLM Character (LLM 角色引用):)
- [3、Player Color / AI Color:](#3、Player Color / AI Color:)
- [4、Font Color / Font / Font Size:](#4、Font Color / Font / Font Size:)
- [5、Sprite (精灵图):](#5、Sprite (精灵图):)
- [6、Bubble Width (气泡宽度):](#6、Bubble Width (气泡宽度):)
- [7、Text Padding (文字内边距):](#7、Text Padding (文字内边距):)
- [8、Bubble Spacing (气泡间距):](#8、Bubble Spacing (气泡间距):)
- 四、SimpleInteraction简单的交互聊天功能
-
- [1、Chat() 开始聊天](#1、Chat() 开始聊天)
- [2、CancelRequests() 停止聊天/取消聊天](#2、CancelRequests() 停止聊天/取消聊天)
- 五、RAG相关
-
- 1、LLM(GameObject):
- 2、LLMRAG(GameObject):
- 3、RAG(GameObject):
-
- [3.1、 RAG.cs](#3.1、 RAG.cs)
- [3.2、 LLMEmbedder.cs](#3.2、 LLMEmbedder.cs)
- 3.3、SimpleSearch.cs
- 3.4、DBSearch.cs
- 4、LLMCharacter(GameObject):
- 5、两个大模型实例有啥异同?
-
- (1)哪两个模型?
- (2)共同点(它们"像"的地方)
- (3)核心差异(真正决定用途的地方)
-
- [3.1🧠 Qwen3-4B特点](#3.1🧠 Qwen3-4B特点)
- [3.2 📚 Construct-RAG](#3.2 📚 Construct-RAG)
- [3.3 量化策略不同(影响稳定性)](#3.3 量化策略不同(影响稳定性))
- [3.4 "回答风格"差异(非常直观)](#3.4 “回答风格”差异(非常直观))
- [3.5 什么时候用谁?](#3.5 什么时候用谁?)
- (4)两个模型的工作流程
-
- [4.1 总体工作流程](#4.1 总体工作流程)
- [4.2 普通大模型工作流程](#4.2 普通大模型工作流程)
- [4.3 RAG大模型工作流程](#4.3 RAG大模型工作流程)
- [4.4 两个模型那个一个更吃软硬件资源](#4.4 两个模型那个一个更吃软硬件资源)
- 6、LLMEmbedder.cs脚本解读
-
- (1)一句话概述脚本功能:
- (2)具体介绍:
- (3)脚本的工作流程
- (4)什么是Embedding?
- (5)向量搜索的具体案例解析
-
- [5.1 知识库:假设知识库里有三段话,也就是三个知识点:](#5.1 知识库:假设知识库里有三段话,也就是三个知识点:)
- [5.2 提问:现在,用户提出的问题是:](#5.2 提问:现在,用户提出的问题是:)
- [5.3 处理方式:第一步,向量化](#5.3 处理方式:第一步,向量化)
- [5.4 处理方式:第二步,搜索(执行向量计算)](#5.4 处理方式:第二步,搜索(执行向量计算))
- [5.5 Embedding 与大模型聊天异同(这是关键区别)](#5.5 Embedding 与大模型聊天异同(这是关键区别))
- [5.6 向量化是怎样的一个过程,是怎么把String变成float\[\]的?](#5.6 向量化是怎样的一个过程,是怎么把String变成float[]的?)
- 7、SimpleSearch.cs脚本解读
-
- (1)功能概述
- (2)工作流程
- (3)数据结构组成
-
- [3.1 知识库的表示](#3.1 知识库的表示)
- [3.2 一次搜索的缓存](#3.2 一次搜索的缓存)
- (4)知识库的主要方法Fn()
-
- [4.1 【添加AddInternal/移除RemoveInternal】知识向量](#4.1 【添加AddInternal/移除RemoveInternal】知识向量)
- [4.2 【检索IncrementalSearch】知识向量](#4.2 【检索IncrementalSearch】知识向量)
- [4.3 【IncrementalFetchKeys ------ 分批取 Top-K】](#4.3 【IncrementalFetchKeys —— 分批取 Top-K】)
- 8、RAG.cs脚本解读
-
- (1)功能概述
- (2)工作流程
- (3)面板参数介绍
-
- [3.1 Search Type (SearchMethods 枚举)](#3.1 Search Type (SearchMethods 枚举))
- [3.2 Chunking Type (ChunkingMethods 枚举)](#3.2 Chunking Type (ChunkingMethods 枚举))
- [3.3 Search (SearchMethod 类型)](#3.3 Search (SearchMethod 类型))
- [3.4 Chunking (Chunking 类型)](#3.4 Chunking (Chunking 类型))
- 9、KnowledgeBaseGame.cs脚本解释
-
- (1)功能概述
- (2)面板参数介绍
- (3)脚本里的知识库有哪些
-
- [3.1 知识来源](#3.1 知识来源)
- [3.2 进入 RAG 的只有"问题"](#3.2 进入 RAG 的只有“问题”)
- [3.3 检索时用到的知识库](#3.3 检索时用到的知识库)
- [3.4 持久化的知识库](#3.4 持久化的知识库)
一、LLM参数面板设置
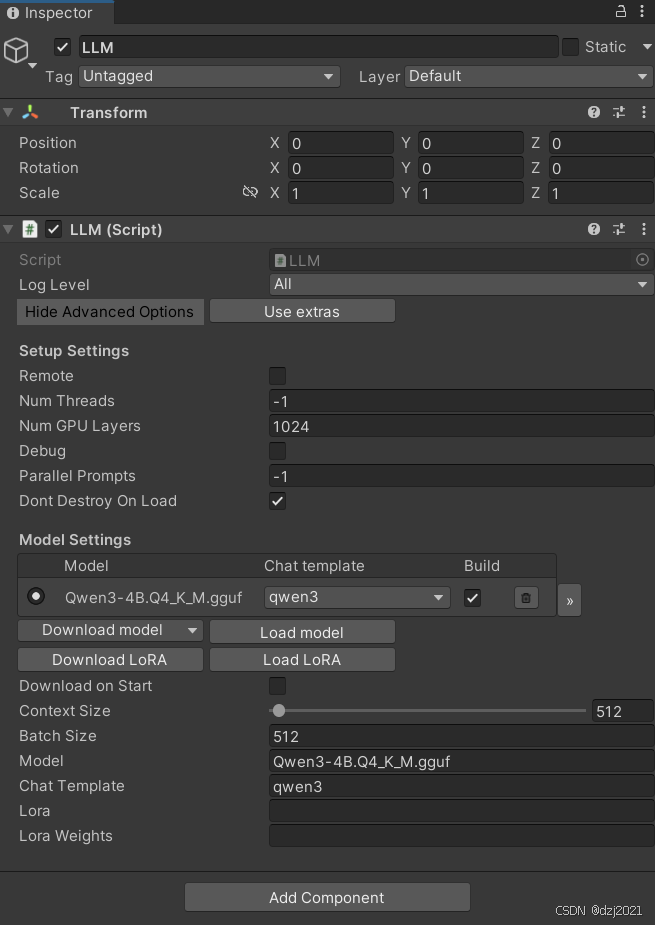
- LLM脚本的作用
LLM 是 LLMUnity 的"核心服务节点",负责在 Unity 内部启动、管理并桥接一个本地/远程的大语言模型推理服务(llama.cpp 系系),并向 Unity 层暴露统一的 API(Completion / Embedding / Tokenize / Slot / LoRA / Server)。
可理解为:Unity 世界 ⇄ C# ⇄ 原生 llama.cpp 服务 ⇄ 模型文件(gguf)
- LLM脚本在架构中的位置
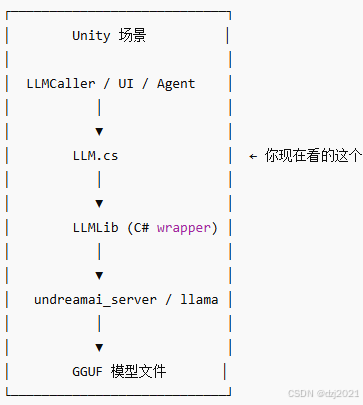
LLM.cs 是中枢调度者,不是"调用者",也不是"UI"
1. Remote (远程模式)
- 功能:启用或禁用远程服务器功能。
- 含义:勾选后,脚本会将 Unity 实例变成一个 Web 服务器,允许外部设备通过网络访问此 LLM。
- 技术细节:它会将主机地址设置为 0.0.0.0(监听所有网络接口),并支持 API Key 验证和 SSL 加密传输。
2. Num Threads (线程数)
- 功能:指定模型推理时使用的 CPU 线程数量。
- 含义:如果设置为 -1,则默认使用所有可用的 CPU 核心。
- 移动端优化:在 Android 平台上,如果设为 0 或更小,脚本会自动检测并使用设备的大核(Big Cores)来提升性能。
3. Num GPU Layers (GPU 显存层数)
- 功能:决定将多少层模型从内存卸载到 GPU 显存中。
- 含义:设置为 0 表示不使用 GPU。
- 回退机制:如果用户的显卡不支持或显存不足,LLM 会自动退回到 CPU 运行。增加此数值通常能显著提高推理速度,但受显存大小限制。
4. Debug (调试模式)
- 功能:在 Unity 编辑器的控制台中记录 LLM 的输出日志。
- 含义:开启后,脚本会捕获底层的 llama.cpp 警告或错误信息并打印出来。
- 用途:主要用于排查模型加载失败、权重问题或底层崩溃的原因。
5. Parallel Prompts (并行提示词数)
- 功能:设置可以并行处理的提示词数量。
- 含义:如果设置为 -1,其数量将等同于场景中 LLMCaller 对象的数量。
- 用途:这决定了服务器同时开启的"槽位(Slots)"数量,允许模型同时为多个 NPC 生成回复,而不需要排队。
6. Dont Destroy On Load (载入时不销毁)
- 功能:控制在切换 Unity 场景时是否保留该 LLM 游戏对象。
- 含义:如果勾选(默认为 true),当游戏加载新场景时,LLM 服务器会持续运行,无需重新初始化或重新加载大型模型文件。
7.Model
- 功能: 指定主语言模型文件。
- 含义: 必须是 .gguf 格式的文件。脚本在 Awake 时会验证该路径是否存在,如果为空或文件不存在,服务器将无法启动。
8.Context Size
- 功能: 定义模型可接收的最大 Token 输入数量(即"记忆长度")。
- 含义: 设置为 0 时将自动采用模型的默认上下文长度。较大的数值会消耗更多内存/显存,若超过 32768 且模型本身支持很大,脚本会发出警告以防内存溢出。
9.Batch Size
- 功能: 设置 Prompt 预处理时的批处理 Token 数量。
- 含义: 影响模型处理输入提示词的速度。较大的 Batch Size 可以加速推理前的准备阶段,但会显著增加瞬时显存占用。
10.Chat Template
- 功能: 选择对话包装模板。
- 含义: 不同系列的模型(如 Llama, Gemma)需要特定的格式才能正确理解对话逻辑。通过 SetTemplate 方法,可以在运行时动态更改此设置。
二、LLMCharacter参数面板设置
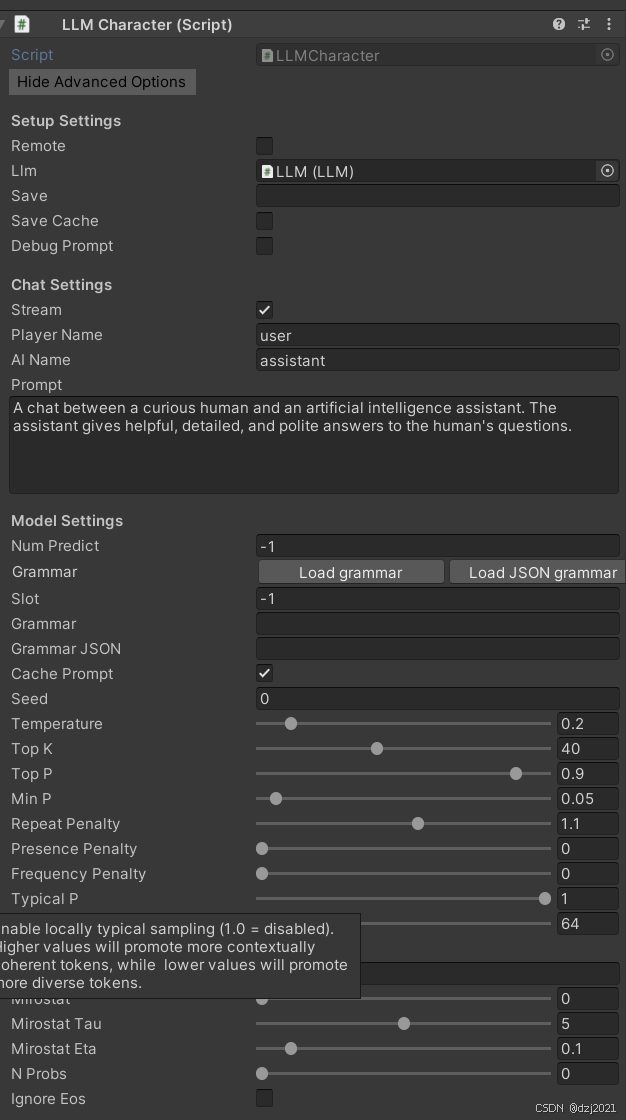
- 脚本的功能作用
LLMCharacter = "一个有记忆、有性格、有采样参数、有历史、有 slot 的 AI 角色实例"
- 该脚本在LLMUnity中的位置:
LLM (服务器 / 模型 / 推理内核)
└── LLMCharacter (一个 AI 角色)
├── Chat 历史
├── Prompt / System Prompt
├── Sampling 参数
├── Slot / Cache
├── Grammar
└── Save / Load
👉 一个 LLM 可以挂多个 LLMCharacter
👉 每个 LLMCharacter = 一个 NPC / 助手 / 讲解员
- 继承关系说明
-
(1)LLM
👉 管模型 / server / native
-
(2)LLMCaller
👉 管"如何向 LLM 发请求"
-
(3)LLMCharacter
👉 管"我是一个什么样的 AI,在怎么聊天"
所以:
LLMCharacter = 面向"对话/角色"的高层封装
- 工作过程
1️⃣ 向 LLM 注册一个 slot
每个 Character 占一个上下文槽
slot = cache + KV cache 的绑定点
2️⃣ 加载 Grammar(如果有)
GBNF / JSON Schema
用来"强约束输出格式"
3️⃣ 初始化历史
清空 chat
加 system prompt
尝试从磁盘加载历史
1.Remote
- 功能: 开启/关闭远程服务器模式。
- 含义: 勾选后,Unity 实例会作为一个网络服务器运行,监听 0.0.0.0 及指定端口,允许外部设备通过 API Key 访问该模型。它是绑定在某个 LLM(服务器)上的"角色级对话控制器"
2.Llm
- 功能: 引用 LLM 脚本实例。
- 含义: LLMCharacter 需要通过该引用找到对应的推理引擎(LLM 对象),从而分配槽位并发送推理请求。
3.Save
- 功能:设置聊天历史记录的文件名。
- 含义: 脚本会将对话历史序列化为 JSON 并存储在设备的 persistentDataPath 目录下。若留空则不自动保存。
4.Save Cache
- 功能: 是否保存模型的 KV 缓存 (KV Cache)。
- 含义: 开启后,加载历史记录时无需重新计算之前的 Token 序列。每个角色约需 100MB 空间,但能实现对话状态的"秒恢复"。
5.Debug Prompt
- 功能:在 Unity 编辑器控制台打印构建好的最终 Prompt。
- 含义: 实际发送给 AI 的文本包含模板、历史、系统指令等。开启此项可查看发送的原始内容,方便排查逻辑问题。
6.Stream
- 功能: 开启流式文本输出。
- 含义: 推荐开启。AI 回复会实时逐字显示,类似打字机效果,而不是等待整个句子生成完毕才弹出,能极大降低玩家等待感。
7.Player Name
- 功能: 定义玩家(用户)的名称。
- 含义: 该名称将插入到聊天模板中,作为用户消息的起始标志(例如 user:)。
8.AI Name
- 功能: 定义 AI 角色的名称。
- 含义: 用于模板中标识 AI 回复的起始标志(例如 assistant:),确保模型明白接下来的对话由它产生。
9.Prompt
- 功能: 设置系统提示词 (System Prompt)。
- 含义: 描述 AI 的角色定位和任务规则。它是 AI 大脑的"基调",例如告知 AI :"你是一个博学、有礼貌且乐于助人的向导"。
10、Model Settings (推理控制参数)
这些参数直接影响 AI 生成文本的长度和遵循的逻辑。
(1)Num Predict:
- 【功能】 限制模型生成的最大 Token 数量。
- 【含义】 设置为 -1 表示无限生成(直到模型自行停止),设置为正整数则会在达到该字符长度后强制停止。
(2)Slot:
-
【功能】 分配当前角色的推理槽位 ID。
-
【含义】 每个 LLMCharacter 在初始化时都会在 LLM 服务器中注册并获得一个槽位,用于维护独立的上下文,确保多个 NPC 同时对话互不干扰。
-
额外补充:
slot = 大模型的一块"对话内存位",用来保存当前对话的上下文和 KV Cache。
换句话说:
slot 决定了模型"是不是同一个脑子在继续想
把 LLM 当成一个老师,每个 slot,就是老师桌子上的 一个笔记本

(3)Grammar:
- 【功能】 指定 GBNF(GGML Backus-Naur Form)语法文件。
- 【含义】 强制 AI 的输出必须符合特定的语法规则,例如强制其只回答"是"或"否"。
(4)Grammar JSON:
- 【功能】 使用 JSON Schema 约束输出格式。
- 【含义】 当需要 AI 以结构化数据(如 JSON 格式的对象)回复时使用,常用于解析游戏指令。
(5)Cache Prompt:
- 【功能】 决定是否缓存已计算过的提示词。
- 【含义】 启用后,如果下一轮对话的内容与之前重合,则无需重新计算重合部分,能极大提高响应速度。
(6)Seed:
- 【功能】 设置随机数种子。
- 【含义】 设置固定数值可确保在相同输入下,AI 每次生成的回复完全一致(用于调试或固定表现)。
(7)Temperature :
- 【功能】 控制生成结果的随机性。
- 【含义】 数值越高回复越有创意但逻辑越松散,数值越低回复越稳定、保守。
(8)Top K / Top P / Min P / Typical P:
- 【功能】 各种概率截断采样算法。
- 【含义】 它们共同决定从词库中筛选候选词的范围。例如 Top K 限制在前 K 个最可能的词中选择,Top P 则是在累计概率达到 P 的词群中选择。
(9)Ignore Eos:
- 【功能】 忽略终止符。
- 【含义】 开启后,模型即使预测到了"结束标记"也会继续强制生成,通常用于特定长文本生成需求。
三、ChatBot参数面板设置
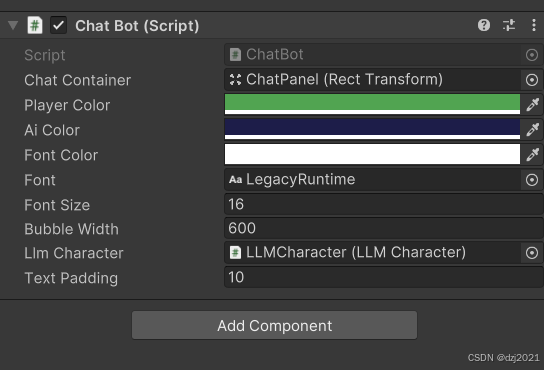
- 脚本的功能作用
这个 ChatBot.cs 是 LLMUnity 官方示例里"把 LLMCharacter 接到 Unity UI 的完整聊天壳"。
一句话说清它的定位:
ChatBot =「UI 聊天界面 + 输入控制 + 把用户输入转给 LLMCharacter + 把模型输出实时显示出来」
它不做 AI 推理,只做 UI + 交互 + 调度。
1、Chat Container (聊天容器):
- 【功能】 指定存放聊天气泡的 UI 父节点(通常是一个带有 Scroll Rect 或 Vertical Layout Group 的 Transform)。
- 【含义】 所有生成的玩家和 AI 对话气泡都会作为此对象的子物体。脚本会根据此容器的高度动态计算气泡位置。
2、LLM Character (LLM 角色引用):
- 【功能】 关联负责处理对话逻辑的 LLMCharacter 脚本实例。
- 【含义】 聊天机器人通过此引用发送玩家输入,并接收 AI 生成的回复文本。
3、Player Color / AI Color:
- 【功能】 分别设置玩家和 AI 气泡的背景颜色。
- 【含义】 用于在视觉上快速区分对话双方。例如,玩家通常设为绿色,AI 设为深蓝色。
4、Font Color / Font / Font Size:
- 【功能】 设置气泡内文字的颜色、字体文件及字号大小。
- 【含义】 定义聊天文本的排版样式。如果未指定字体,脚本会默认加载系统内置字体。
5、Sprite (精灵图):
- 【功能】 设置聊天气泡使用的背景图片。
- 【含义】 通常是一个"九宫格"(Sliced)样式的图片,确保气泡在拉伸时边缘不失真。
6、Bubble Width (气泡宽度):
【功能】 定义对话气泡的最大宽度。
【含义】 限制文本在 UI 上的横向伸缩范围,超过此宽度后文字会自动换行。
7、Text Padding (文字内边距):
【功能】 设置文字距离气泡边缘的间隙。
【含义】 防止文字紧贴气泡边界,使 UI 看起来更美观。
8、Bubble Spacing (气泡间距):
【功能】 设置上下两个对话气泡之间的距离。
【含义】 控制对话列表的垂直疏密程度。
四、SimpleInteraction简单的交互聊天功能
这个脚本是 LLMUnity 示例(Sample)里非常典型的一个"最小交互脚本",名字叫 SimpleInteraction。
它实现了一个最简单的"玩家输入一句话 → LLM 回复 → 显示在 UI 上"的聊天交互流程。
适用场景:
- Demo / 示例场景
- 教学用最小聊天界面
- 验证 LLMUnity 是否正常工作的测试脚本
1、Chat() 开始聊天
重要的方法:
- Chat(参数1,参数2,参数3)
参数1:用户提问的信息(string)
参数2:回调方法,传回一个答案信息(Action)
参数3:回调方法,只回调,不回传(Action)
csharp
/// <summary>
/// Chat functionality of the LLM.
/// It calls the LLM completion based on the provided query including the previous chat history.
/// The function allows callbacks when the response is partially or fully received.
/// The question is added to the history if specified.
/// </summary>
/// <param name="query">user query</param>
/// <param name="callback">callback function that receives the response as string</param>
/// <param name="completionCallback">callback function called when the full response has been received</param>
/// <param name="addToHistory">whether to add the user query to the chat history</param>
/// <returns>the LLM response</returns>
public virtual async Task<string> Chat(string query, Callback<string> callback = null, EmptyCallback completionCallback = null, bool addToHistory = true)
{
// handle a chat message by the user
// call the callback function while the answer is received
// call the completionCallback function when the answer is fully received
await LoadTemplate();
if (!CheckTemplate()) return null;
if (!await InitNKeep()) return null;
ChatRequest request = await PromptWithQuery(query);
string result = await CompletionRequest(request, callback);
if (addToHistory && result != null)
{
await chatLock.WaitAsync();
try
{
AddPlayerMessage(query);
AddAIMessage(result);
}
finally
{
chatLock.Release();
}
if (save != "") _ = Save(save);
}
completionCallback?.Invoke();
return result;
}2、CancelRequests() 停止聊天/取消聊天
csharp
public void CancelRequests()
{
llmCharacter.CancelRequests();
//...
}五、RAG相关
1、LLM(GameObject):
-
- LLM.cs,模型为:Qwen3-4B.Q4_K_M.gguf
它的职责:
(1)提供 自然语言理解 + 生成能力
(2)不关心知识库、不做检索
(3)更偏向「会说话、会推理」
(4)他只是语言引擎(大脑),但它不知道我的世界观,不知道我的资料(不调用我的知识库)。
- LLM.cs,模型为:Qwen3-4B.Q4_K_M.gguf
2、LLMRAG(GameObject):
-
- LLM.cs,模型为:Construct-RAG.Q6_K.gguf
它的职责:
(1)这个 LLM 不是用来和玩家聊天的,而是用来:
(2)构造 RAG Prompt
(3)理解"检索到的文本 + 玩家问题"
(4)有时用于 重写查询 / 压缩上下文
(5)它是知识整理专用大脑(RAG模型)
- LLM.cs,模型为:Construct-RAG.Q6_K.gguf
3、RAG(GameObject):
3.1、 RAG.cs
核心职责:
👉 RAG 总调度器
(1)它负责把下面两件事串起来:
(2)文本 → 向量(LLMEmbedder)
(3)向量 → 相似文本(SimpleSearch)
3.2、 LLMEmbedder.cs
核心职责
👉 Embedding 生成器
(1)调用 embedding 模型
(2)把文本转成 float\[\]
(3)用于:
知识库初始化
玩家问题向量化
(4)它解决的是:
"怎么把一句话,变成数学向量?"
3.3、SimpleSearch.cs
核心职责:
👉 最简单、最直观的向量搜索
一般包含:
(1)Dot Product
(2)Cosine Similarity
(3)排序
(4)Top-K 返回
特点:
(1)不依赖数据库
(2)不用 FAISS
(3)不用 HNSW
(4)全内存暴力搜索
3.4、DBSearch.cs
核心职责:
👉 高效、近似最近邻的向量搜索(ANN)
一般包含:
(1)HNSW 图构建与查询
(2)向量量化压缩(Float16 / Int8 等)
(3)余弦 / 内积 / 欧氏距离计算
(4)Top-K + 过滤器(group、分组、去重)快速返回
特点:
(1)依赖专业向量数据库库(usearch)
(2)使用 HNSW 算法(层次可导航小世界图)
(3)支持高效的近似最近邻检索
(4)内存 + 速度平衡极佳,适合中大型知识库
- 总结:SimpleSearch和DBSearch的异同
| 项目 | SimpleSearch | DBSearch (推荐) |
|---|---|---|
| 搜索方式 | 暴力搜索(brute-force) | 近似最近邻(Approximate Nearest Neighbor, ANN) |
| 底层算法 | 全遍历 + 余弦/内积相似度计算 | HNSW(层次可导航小世界图) + 向量量化 |
| 依赖外部库 | 无(纯 C# 实现) | 是(usearch 库) |
| 准确性 | 100% 精确(exact match) | 近似(高质量参数下召回率极高,实际几乎无差别) |
| 速度 | 慢,随知识条目线性增长(条目多就明显卡) | 非常快(毫秒级,即使上万条也高效) |
| 适用知识规模 | 适合小规模(几百~2000 条以内) | 适合中大型(几千~几十万条) |
| 内存占用 | 较高(完整存储所有 float\[\] 向量) | 较低(支持 Float16 / Int8 等量化压缩) |
| 增量检索实现 | 先一次性算完所有排序 → 缓存 → 分页切片 | 每次 IncrementalFetch 实时搜索 + filter 过滤 |
| 分组过滤(group)支持 | 支持(但需先过滤再全算) | 原生支持高效 filter 回调(分组 + 去重) |
| 可调参数 | 几乎无 | 多项高级参数(量化类型、connectivity、expansion 等) |
| 保存/加载效率 | 序列化整个 Dictionary(较慢、体积大) | usearch 原生高效二进制格式(快、体积小) |
| 官方推荐 | 仅用于调试、小 demo | 大多数情况下首选(文档反复强调 "recommended") |
| 典型使用场景 | 测试、教学、知识条目极少 | 正式游戏、大量设定/对话历史/物品/剧情知识库 |
一句话总结
-
SimpleSearch:简单粗暴、精确但慢,像"人工一本本翻书"
-
DBSearch:聪明高效、近似但极快,像"智能图书馆秒找书"
4、LLMCharacter(GameObject):
-
- LLMCharacter.cs
👉 对 LLM 的"人格封装器"
(1)主要负责:
对话历史管理
System Prompt
角色设定
多轮对话上下文
在 KnowledgeBaseGame 中的作用
不直接检索知识
不直接算 embedding
(2)但它决定:
说话风格
是否记得之前说过什么
是否像"同一个人"
(3)你可以理解为:
🧍 "给大模型穿上一层角色皮肤"
- LLMCharacter.cs
-
5、两个大模型实例有啥异同?
(1)哪两个模型?
Qwen3-4B.Q4_K_M.gguf
Construct-RAG.Q6_K.gguf
(2)共同点(它们"像"的地方)
| 维度 | 说明 |
|---|---|
| 文件格式 | .gguf(llama.cpp / LLMUnity 可直接用) |
| 模型类型 | Decoder-only LLM(自回归生成) |
| 使用方式 | 都通过 LLM.cs 调用 |
| 能力基础 | 都能理解自然语言并生成回答 |
| 部署形态 | 本地运行、可离线 |
(3)核心差异(真正决定用途的地方)
| 项目 | Qwen3-4B | Construct-RAG |
|---|---|---|
| 定位 | 通用大模型 | RAG 专用生成模型 |
| 核心目标 | 聊天 + 推理 | 基于上下文回答 |
| 是否假设"有资料" | ❌ | ✅ |
3.1🧠 Qwen3-4B特点
- 更依赖模型内参数知识
- 即使不给上下文,也会努力回答
- 更容易"补全 / 猜测"
👉 优点:
✔ 表达自然
✔ 推理能力强
👉 风险:
⚠ 幻觉概率相对高
3.2 📚 Construct-RAG
- 强依赖 prompt 里的 Context / Evidence
- 更倾向于: "根据以下内容回答"
- 当资料不足时,更容易:
保守回答
承认不知道
👉 优点:
✔ 更"守规矩"
✔ 适合制度、手册、实验步骤
3.3 量化策略不同(影响稳定性)
| 项目 | Qwen3-4B | Construct-RAG |
|---|---|---|
| 量化 | Q4_K_M | Q6_K |
| 压缩程度 | 更激进 | 更保守 |
| 显存 / 内存 | 更省 | 略高 |
| 事实保真 | 中等 | 较好 |
| 👉 RAG 场景下,Q6 通常更稳 |
3.4 "回答风格"差异(非常直观)
| 场景 | Qwen3-4B | Construct-RAG |
|---|---|---|
| 闲聊 | 自然 | 偏正式 |
| 编故事 | 擅长 | 不擅长 |
| 按资料复述 | 一般 | 很强 |
| 严格按文本 | 容易发挥 | 比较死板 |
3.5 什么时候用谁?
✅ 用 Qwen3-4B 的情况
- NPC 对话
- AI 助手闲聊
- 推理、总结
- 非严格事实场景
✅ 用 Construct-RAG 的情况
- 知识库问答
- 实验步骤 / 规范
- 教学系统
- "不能乱说"的场景
(4)两个模型的工作流程
4.1 总体工作流程
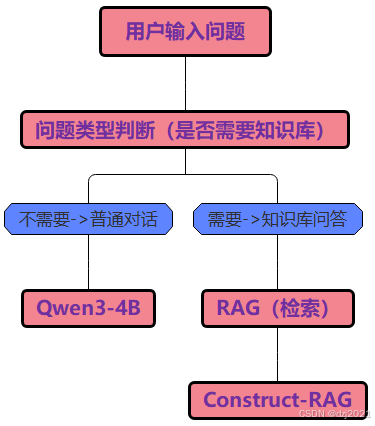
4.2 普通大模型工作流程
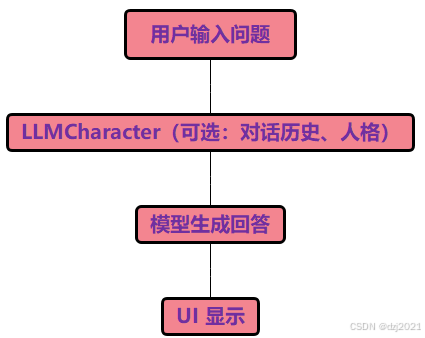
4.3 RAG大模型工作流程

4.4 两个模型那个一个更吃软硬件资源
- 资源消耗
| 项目 | Q4 | Q6 |
|---|---|---|
| 内存 / 显存 | 更低 | 更高 |
| 推理速度 | 更快 | 稍慢 |
| 部署门槛 | 更低 | 更高 |
- 模型效果(非常关键)
| 项目 | Q4 | Q6 |
|---|---|---|
| 语言流畅度 | 好 | 更好 |
| 事实稳定性 | 一般 | 更稳 |
| 长上下文 | 易漂 | 更稳 |
| RAG 场景 | 勉强 | 更适合 |
- 总结
在「同等大模型规模」条件下:👉 RAG 一定比普通模型更耗资源(软硬件都是)。
普通模型 = 只跑一次推理
RAG 模型 = 推理 + 向量计算 + 检索 + 额外 Prompt 拼接
| 项目 | 普通模型(Qwen3-4B) | RAG(Construct-RAG) |
|---|---|---|
| LLM 推理 | ✅ 有 | ✅ 有(同级别) |
| 向量嵌入(Embedding) | ❌ 无 | ✅ 有(额外一次模型推理) |
| 向量相似度计算 | ❌ 无 | ✅ 有(CPU/GPU 都可能) |
| 检索排序(Top-K) | ❌ 无 | ✅ 有 |
👉 RAG 至少多一次 Embedding 模型推理
- 运行期内存比较
| 内存项 | 普通模型(Qwen3-4B.Q4_K_M) | RAG 模型(Construct-RAG.Q6_K) | 说明 |
|---|---|---|---|
| 主 LLM 权重 | ✅ 有 | ✅ 有 | 两者相同级别 |
| Embedding 模型权重 | ❌ 无 | ✅ 有 | RAG 专属 |
| KV Cache | ✅ 有 | ✅ 有(更大) | Prompt 更长 |
| 向量数据库(RAM) | ❌ 无 | ✅ 有 | 文档向量 |
| Top-K Context 文本 | ❌ 无 | ✅ 有 | 原始文本缓存 |
| 检索 / 排序中间数据 | ❌ 无 | ✅ 有 | 相似度计算 |
| Unity 管理对象 / List | 少 | 多 | RAG 链路更长 |
6、LLMEmbedder.cs脚本解读
- 词语解释:
---(1)embedding------植入,嵌入的意思。
---(2)embedder------嵌入器。
---(3)LLMEmbedder------大预言模型嵌入器。
(1)一句话概述脚本功能:
LLMEmbedder 是 RAG 流程中"把文本变成向量"的专用入口,只负责 Embedding,不负责聊天。
- 该脚本在RAG模型工作流程中的位置:
csharp
用户输入
↓
LLMEmbedder ✅(就是它)
↓
SimpleSearch
↓
RAG.cs
↓
LLM.cs(Construct-RAG)(2)具体介绍:
csharp
LLMEmbedder = 一个"只允许绑定 Embedding 模型的 LLMCaller 派生类"它做了三件事:
- (1)继承通用 LLM 调用能力
- (2)强制只使用 embeddingsOnly 的 LLM
- (3)防止你在 Inspector 里"接错模型
(3)脚本的工作流程
- 1.接收:
--- =>用户问题
--- 或文档文本 - 2.调用:
--- Embedding 专用 LLM - 3.输出:
--- float\[\] 向量 - 4.交给:
--- SimpleSearch 做相似度计算
(4)什么是Embedding?
Embedding = 把一段文字,变成一串能表示"语义含义"的数字向量
比如这句话:
csharp
"离心机启动前检查"人一眼就看懂了,但是大模型不懂,所以需要进行向量化处理,翻译成向量:
csharp
[0.021, -0.13, 0.77, ...]这样就把【人话】翻译成【数学】
(5)向量搜索的具体案例解析
5.1 知识库:假设知识库里有三段话,也就是三个知识点:
csharp
1.「离心机启动前需要检查电源和转子」
2.「板式换热器由多层金属板组成」
3.「中药气雾剂需要过滤处理」5.2 提问:现在,用户提出的问题是:
csharp
"离心机开机前要注意什么?"5.3 处理方式:第一步,向量化
| 文本 | Embedding 后 |
|---|---|
| 用户问题 | 向量 A |
| 知识 1 | 向量 B |
| 知识 2 | 向量 C |
| 知识 3 | 向量 D |
5.4 处理方式:第二步,搜索(执行向量计算)
csharp
算 A·B → 很大(语义接近)
算 A·C → 很小
算 A·D → 很小
👉 计算机"知道"该选哪段知识5.5 Embedding 与大模型聊天异同(这是关键区别)
| 项目 | Embedding | 大模型聊天 |
|---|---|---|
| 输入 | 文本 | 文本 |
| 输出 | 数字向量 | 文字 |
| 是否生成句子 | ❌ | ✅ |
| 是否推理 | ❌ | ✅ |
| 是否"会说话" | ❌ | ✅ |
5.6 向量化是怎样的一个过程,是怎么把String变成float\[\]的?
大概过程如下:
csharp
string
↓
分词(Tokenizer)
↓
Token ID 序列
↓
Embedding 模型(神经网络前向计算)
↓
池化 / 汇总
↓
float[] 向量详细知识需要脑部相关资料:
csharp
文本怎么变成数字
↓
神经网络怎么处理一串数字
↓
为什么这些数字能表示"语义相似"7、SimpleSearch.cs脚本解读
(1)功能概述
csharp
SimpleSearch 是一个最朴素的向量检索器:
把"问题向量"与"所有知识向量"做暴力相似度计算,按相似度排序,返回 Top-K。它不是大模型,也不生成文本,只负责"找最像的知识"
(2)工作流程
csharp
LLMEmbedder → SimpleSearch(本脚本的功能) → RAG.cs- 输入:
一个 float\[\](用户问题的 embedding) - 输出:
若干个 最相关的知识条目 key - 用途:
给 RAG.cs 提供"上下文候选文本"
(3)数据结构组成
3.1 知识库的表示
- embeddings:知识库本体
csharp
SortedDictionary<int, float[]> embeddings| key | value |
|---|---|
| 文本ID | 该文本的 embedding 向量 |
- 📌 等价理解
csharp
"这是一个:
文档ID → 文档语义向量 的表"3.2 一次搜索的缓存
incrementalSearchCache
csharp
Dictionary<int, List<(int, float)>> incrementalSearchCache它存的是:
- 一次搜索的 完整排序结果
- (文档ID, 距离) 的列表
👉 用来支持 分批取 Top-K(而不是一次性全返回)
(4)知识库的主要方法Fn()
4.1 【添加AddInternal/移除RemoveInternal】知识向量
csharp
protected SortedDictionary<int, float[]> embeddings = new SortedDictionary<int, float[]>();- 添加知识向量
csharp
protected override void AddInternal(int key, float[] embedding)
{
embeddings[key] = embedding;
}- 移除知识向量
csharp
protected override void RemoveInternal(int key)
{
embeddings.Remove(key);
}以上是知识库管理的功能。
4.2 【检索IncrementalSearch】知识向量
csharp
public override int IncrementalSearch(float[] embedding, string group = "")
{
int key = nextIncrementalSearchKey++;
List<(int, float)> sortedLists = new List<(int, float)>();
if (dataSplits.TryGetValue(group, out List<int> dataSplit))
{
if (dataSplit.Count >= 0)
{
float[][] embeddingsSplit = new float[dataSplit.Count][];
for (int i = 0; i < dataSplit.Count; i++) embeddingsSplit[i] = embeddings[dataSplit[i]];
float[] unsortedDistances = InverseDotProduct(embedding, embeddingsSplit);
sortedLists = dataSplit.Zip(unsortedDistances, (first, second) => (first, second))
.OrderBy(item => item.Item2)
.ToList();
}
}
incrementalSearchCache[key] = sortedLists;
return key;
}它做了什么?
👉 用一句话概括:
把"问题向量"与当前 group 下的所有知识向量,逐个算相似度并排序
csharp
1. 给定一个"查询向量",
2. 在指定 group 的知识向量中,
3. 逐个计算相似度 → 排序 → 缓存结果,
4. 并返回一个"搜索会话 ID"。4.3 【IncrementalFetchKeys ------ 分批取 Top-K】
csharp
public override ValueTuple<int[], float[], bool> IncrementalFetchKeys(int fetchKey, int k)
{
if (!incrementalSearchCache.ContainsKey(fetchKey)) throw new Exception($"There is no IncrementalSearch cached with this key: {fetchKey}");
bool completed;
List<(int, float)> sortedLists;
if (k == -1)
{
sortedLists = incrementalSearchCache[fetchKey];
completed = true;
}
else
{
int getK = Math.Min(k, incrementalSearchCache[fetchKey].Count);
sortedLists = incrementalSearchCache[fetchKey].GetRange(0, getK);
incrementalSearchCache[fetchKey].RemoveRange(0, getK);
completed = incrementalSearchCache[fetchKey].Count == 0;
}
if (completed) IncrementalSearchComplete(fetchKey);
int[] results = new int[sortedLists.Count];
float[] distances = new float[sortedLists.Count];
for (int i = 0; i < sortedLists.Count; i++)
{
results[i] = sortedLists[i].Item1;
distances[i] = sortedLists[i].Item2;
}
return (results.ToArray(), distances.ToArray(), completed);
}执行流程:
cpp
① 校验 fetchKey 是否存在
② 判断是"取全部"还是"取 Top-K"
③ 如果是 Top-K,则从缓存中"剪掉"已取部分
④ 判断是否取完
⑤ 若取完,清理搜索缓存
⑥ 拆分成 int[] / float[]
⑦ 返回 (结果, 距离, 是否完成)8、RAG.cs脚本解读
(1)功能概述
它是【知识库外挂】的管理器脚本,它把LLMEmbedder,SimpleSearch,DBSearch和LLM(RAG)集成在一起。
(2)工作流程
csharp
玩家问问题 →
问题向量化 →
在知识库向量索引里找最相似的文本 →
把找到的文本塞进 Prompt →
LLM 根据这些"官方资料"生成回答 →
显示给玩家(3)面板参数介绍
3.1 Search Type (SearchMethods 枚举)
这是 检索方式 的选择。决定了用什么算法来做向量相似度搜索。
| 选项 | 实际含义 | 性能特点与适用场景 | 官方推荐度 |
|---|---|---|---|
| SimpleSearch | 暴力全遍历搜索(brute-force) | 所有向量都算一遍相似度,精确但速度随数据量线性下降。适合知识条目很少(< 1000--2000 条)的测试/调试场景 | 不推荐生产使用 |
| DBSearch | 使用 usearch 库的 HNSW 近似最近邻搜索 (ANN) | 速度极快,即使几万条知识也能毫秒级返回。内存友好,支持量化压缩。绝大多数实际项目首选 | ★★★★★(强烈推荐) |
3.2 Chunking Type (ChunkingMethods 枚举)
这是 文本分块策略 的选择。决定了在把文本存进向量索引之前,是否/怎么把长文本切成小块。
| 选项 | 实际含义 | 功能与适用场景 | 推荐场景 |
|---|---|---|---|
| NoChunking | 不切分,整段文本作为一个 embedding 单位 | 简单直接,适合原本就很短的文本或已经手动分好段的内容。长文本容易导致语义焦点丢失。 | 短内容、快速测试 |
| TokenSplitter | 按 token 数量切分(通常 200--512 token 一块) | 最常用方式,保证每块都在模型上下文窗口内,语义相对完整。推荐大多数项目使用。 | 通用首选 |
| WordSplitter | 按单词边界切分(不跨词) | 块大小不均匀,适合英文内容较多的情况。中文效果一般。 | 以英文为主的文本 |
| SentenceSplitter | 按句子边界切分(尽量保持完整句子) | 语义最完整的一种切分方式,块大小可能偏大(有些长句子)。适合追求语义精确的项目。 | 追求语义质量的项目 |
一句话建议:
- 大多数项目推荐 TokenSplitter(平衡性最好)
- 如果特别在意语义完整性,可选 SentenceSplitter
- 文本本来就很短(每段 < 200 字)时,可直接用 NoChunking
3.3 Search (SearchMethod 类型)
这是 实际被创建出来的搜索组件引用。
- 这个字段在 Inspector 上通常是只读的(灰色),由 RAG 在运行时或 OnValidate 时根据 searchType 自动创建并赋值。
- 如果你选了 DBSearch,这里就会自动出现一个 DBSearch 组件(子物体或同物体)。
- 如果选了 SimpleSearch,这里就是 SimpleSearch 组件。
- 一般不需要手动改这个字段,除非你想在运行时动态替换搜索方式(高级用法)。
作用:它是 RAG 把控制权真正交给底层搜索引擎的桥梁。
3.4 Chunking (Chunking 类型)
和 search 字段类似,这是 实际被创建出来的分块组件引用。
-
根据 chunkingType 自动生成:
--- NoChunking → 这个字段为 null
--- 其他选项 → 对应出现 TokenSplitter / WordSplitter / SentenceSplitter 组件
-
也是只读/自动管理的字段,一般不需要手动拖拽或修改。
-
如果启用了分块,RAG 在 Add 文本时会先走 chunking 分块,再把每个小块交给 search 去存向量。
9、KnowledgeBaseGame.cs脚本解释
(1)功能概述
KnowledgeBaseGame.cs 是一个典型的"RAG + LLM 驱动的知识问答小游戏 Demo",
它展示了在 Unity 中如何:
1. 把预设的 Q&A 灌进 RAG(只 embedding 问题)
2. 用 group 实现 NPC 专属知识库
3. 玩家提问 → RAG 找最相似问题 → 取出答案 → 喂 LLM 生成自然回复
4. 同时结合硬编码谜题系统,形成完整的"探案对话游戏"体验(2)面板参数介绍
| 分组 | 字段名称 | 类型 | 作用与说明 | 是否必须 | 备注 / 示例用途 |
|---|---|---|---|---|---|
| UI elements | Character Select | Dropdown | 下拉菜单,用于选择当前对话的 NPC(Butler / Maid / Chef) | 是 | 切换角色时会更新 currentBotName 并显示对应图片 |
| UI elements | Player Text | InputField | 玩家输入问题的地方(聊天输入框) | 是 | 提交后触发 OnInputFieldSubmit → 调用 RAG 检索 → LLM 生成回复 |
| UI elements | AIText | Text | 显示 AI(当前选中的仆人)的回复内容 | 是 | 通过 SetAIText() 方法更新 |
| Bot texts | Butler Text | TextAsset | 管家(Butler)的预设 Q&A 文本文件(格式:问题 | 答案,每行一个) | 是 |
| Bot texts | Maid Text | TextAsset | 女仆(Maid)的预设 Q&A 文本文件 | 是 | 同上,group = "Maid" |
| Bot texts | Chef Text | TextAsset | 厨师(Chef)的预设 Q&A 文本文件 | 是 | 同上,group = "Chef" |
| Bot images | Butler Image | RawImage | 管家的头像/立绘,在选择 Butler 时显示 | 是 | 通过 botImages 字典控制显隐 |
| Bot images | Maid Image | RawImage | 女仆的头像/立绘 | 是 | 同上 |
| Bot images | Chef Image | RawImage | 厨师的头像/立绘 | 是 | 同上 |
| Buttons | Notes Button | Button | 打开"笔记"面板(显示线索笔记) | 是 | 调用 ShowNotes() |
| Buttons | Map Button | Button | 显示/打开地图图片 | 是 | 调用 ShowMap() |
| Buttons | Solve Button | Button | 打开"解谜"面板(选择凶手、地点、工具) | 是 | 调用 ShowSolve() |
| Buttons | Help Button | Button | 打开"帮助"面板 | 是 | 调用 ShowHelp() |
| Buttons | Submit Button | Button | 提交谜题答案(三选一),判断是否正确 | 是 | 调用 SubmitAnswer(),正确显示 SuccessImage,错误显示 FailText |
| Panels | Notebook Image | RawImage | 笔记本背景图,在打开 Notes/Solve/Help 面板时显示 | 是 | 作为背景装饰,点击空白处可关闭 |
| Panels | Notes Panel | GameObject | 笔记内容面板(通常放线索文本) | 是 | ShowNotes() 激活 |
| Panels | Solve Panel | GameObject | 解谜选择面板(包含 Answer1/2/3 下拉框) | 是 | ShowSolve() 激活 |
| Panels | Help Panel | GameObject | 帮助/提示面板 | 是 | ShowHelp() 激活 |
| Panels | Map Image | RawImage | 地图图片,点击 Map Button 显示 | 是 | 点击空白处关闭 |
| Panels | Success Image | RawImage | 解谜成功时显示的庆祝/通关图片 | 是 | SubmitAnswer() 判断正确后激活 |
| Panels | Fail Text | Text | 解谜答案错误时显示的失败提示文字 | 是 | 选择错误时激活,Answer 下拉框变化时隐藏 |
| Panels | Answer 1 | Dropdown | 谜题第一个选项:凶手选择(e.g. Professor Pluot) | 是 | 解谜三选一的第一项 |
| Panels | Answer 2 | Dropdown | 谜题第二个选项:地点选择(e.g. Living Room) | 是 | 第二项 |
| Panels | Answer 3 | Dropdown | 谜题第三个选项:工具选择(e.g. A Hollow Bible) | 是 | 第三项,全部选对则通关 |
| Models | Llm Character | LLMCharacter | 负责生成自然语言回复的 LLM 角色组件 | 是 | 调用 Chat() 方法生成回答,AIName 会随角色切换变化 |
| Models | Rag | RAG | RAG 知识库组件,用于检索当前 NPC 最相似的预设问题 | 是 | 核心:把 Q&A 中的问题 embedding 进去,检索时只搜 currentBotName 的 group |
| Models | Num RAG Results | int | 每次检索返回的相似问题数量(默认 3) | 是 | 控制 Prompt 中会喂给 LLM 几个"可能答案" |
(3)脚本里的知识库有哪些
3.1 知识来源
真正构成"知识库"的内容来自三个 TextAsset:
- ButlerText
- MaidText
- ChefText
这些文件里每行是一个"问题|答案",例如:
csharp
textWho killed Professor Pluot?|I don't know...
Where was the murder?|In the living room...3.2 进入 RAG 的只有"问题"
在 CreateEmbeddings() 中:
csharp
foreach (string question in questions) await rag.Add(question, botName);
→ 只把问题 embedding 进去(group = botName),答案并没有 embedding。3.3 检索时用到的知识库
- rag.Search(question, numRAGResults, currentBotName)
csharp
→ 只在当前 NPC 的 group 里找最相似的 3 个问题
→ 找到相似问题后,从 botQuestionAnswers[currentBotName] 字典里取出对应答案
→ 把这些答案拼进 Prompt 喂给 LLM3.4 持久化的知识库
-
第一次在 Editor 运行时,会把所有问题 embedding 后保存到 KnowledgeBaseGame.zip
-
后续启动直接 rag.Load(ragPath) 加载,避免重复计算
-
三个角色的分工:
-
- butler ------ 男管家
csharp
butler ------ 男管家
指英式家庭中负责管理家务、统筹其他佣人、接待宾客的高级男性仆人,地位和职责高于普通佣人。-
- chef ------ 主厨 / 厨师长
csharp
chef ------ 主厨 / 厨师长
特指专业且具备较高厨艺水平的厨师,负责菜单制定、菜品烹饪和厨房管理;如果是家庭雇佣的专属厨师,也可以直接译为厨师。-
- maid ------ 女佣 / 女仆
csharp
maid ------ 女佣 / 女仆
泛指家庭中负责清洁、整理、杂务的女性佣人,根据具体职责细分,还可以有 house maid(客房女佣)、parlor maid(客厅女佣) 等。