目录
- 前言
- [1 引言:为什么要引入 3D 虚拟人](#1 引言:为什么要引入 3D 虚拟人)
-
- [1.1 文本与语音交互的能力边界](#1.1 文本与语音交互的能力边界)
- [1.2 具身表达对训练沉浸感的提升](#1.2 具身表达对训练沉浸感的提升)
- [2 XmovAvatar SDK 能力概览](#2 XmovAvatar SDK 能力概览)
-
- [2.1 实时 3D 渲染能力](#2.1 实时 3D 渲染能力)
- [2.2 语音驱动动画能力](#2.2 语音驱动动画能力)
- [2.3 状态与事件回调机制](#2.3 状态与事件回调机制)
- [3 AvatarService 的设计思路](#3 AvatarService 的设计思路)
-
- [3.1 为什么要进行 SDK 二次封装](#3.1 为什么要进行 SDK 二次封装)
- [3.2 连接管理与生命周期控制](#3.2 连接管理与生命周期控制)
- [3.3 错误处理与状态同步](#3.3 错误处理与状态同步)
- [4 虚拟人与 AI 对话的协同机制](#4 虚拟人与 AI 对话的协同机制)
-
- [4.1 AI 回复到语音合成的衔接](#4.1 AI 回复到语音合成的衔接)
- [4.2 语音驱动嘴型与动画](#4.2 语音驱动嘴型与动画)
- [4.3 字幕与视觉反馈同步](#4.3 字幕与视觉反馈同步)
- [5 虚拟人状态建模](#5 虚拟人状态建模)
-
- [5.1 核心状态定义](#5.1 核心状态定义)
- [5.2 状态切换与用户感知](#5.2 状态切换与用户感知)
- [6 具身交互的体验设计要点](#6 具身交互的体验设计要点)
-
- [6.1 延迟控制的重要性](#6.1 延迟控制的重要性)
- [6.2 动画与语言节奏的匹配](#6.2 动画与语言节奏的匹配)
- [6.3 避免机械感的设计策略](#6.3 避免机械感的设计策略)
- [7 小结](#7 小结)
- 参考资料
前言
随着大模型能力的持续增强,AI 系统正在从"能对话"逐步走向"会表现"。在以训练、对抗、表达为核心目标的辩论场景中,单纯依赖文本或语音已经难以满足沉浸感与临场感的需求。具身智能的引入,使 AI 不再只是一个隐藏在屏幕背后的算法实体,而是以"虚拟人"的形式直接参与到交互过程中,成为用户感知 AI 的第一入口。
在"辩核 AI 具身辩论数字人系统"中,虚拟人并非装饰性展示组件,而是承担着表达、反馈、节奏控制等关键职责。本文将围绕 XmovAvatar SDK 在系统中的引入背景、能力封装方式以及与 AI 对话系统的协同机制,系统性地阐述"虚拟人即界面"的设计理念与工程实现。
1 引言:为什么要引入 3D 虚拟人
1.1 文本与语音交互的能力边界
在多数 AI 应用中,文本输入输出仍然是主流交互方式,语音交互则在一定程度上提升了自然度。然而,在辩论训练这一高度强调情绪、节奏与对抗氛围的场景中,这两种交互形式存在明显上限。
文本交互缺乏即时反馈与情绪传达,用户需要通过阅读自行构建对话氛围;语音交互虽然弥补了语调与节奏,但依然缺少"对方正在思考""即将反驳"等关键状态提示,整体体验更接近智能音箱而非真实辩手。

1.2 具身表达对训练沉浸感的提升
引入 3D 虚拟人后,AI 的状态不再是抽象的内部逻辑,而是通过形象、动作、姿态显性化呈现。虚拟人的抬头、停顿、张口、转身,本质上都是对 AI 内部状态的可视化映射。这种具身表达显著增强了用户的代入感,使训练过程更接近真实对抗。
在辩论训练中,沉浸感并非"好看"即可,而是直接影响选手的专注度、心理压力与临场反应能力,这正是虚拟人存在的核心价值。
2 XmovAvatar SDK 能力概览
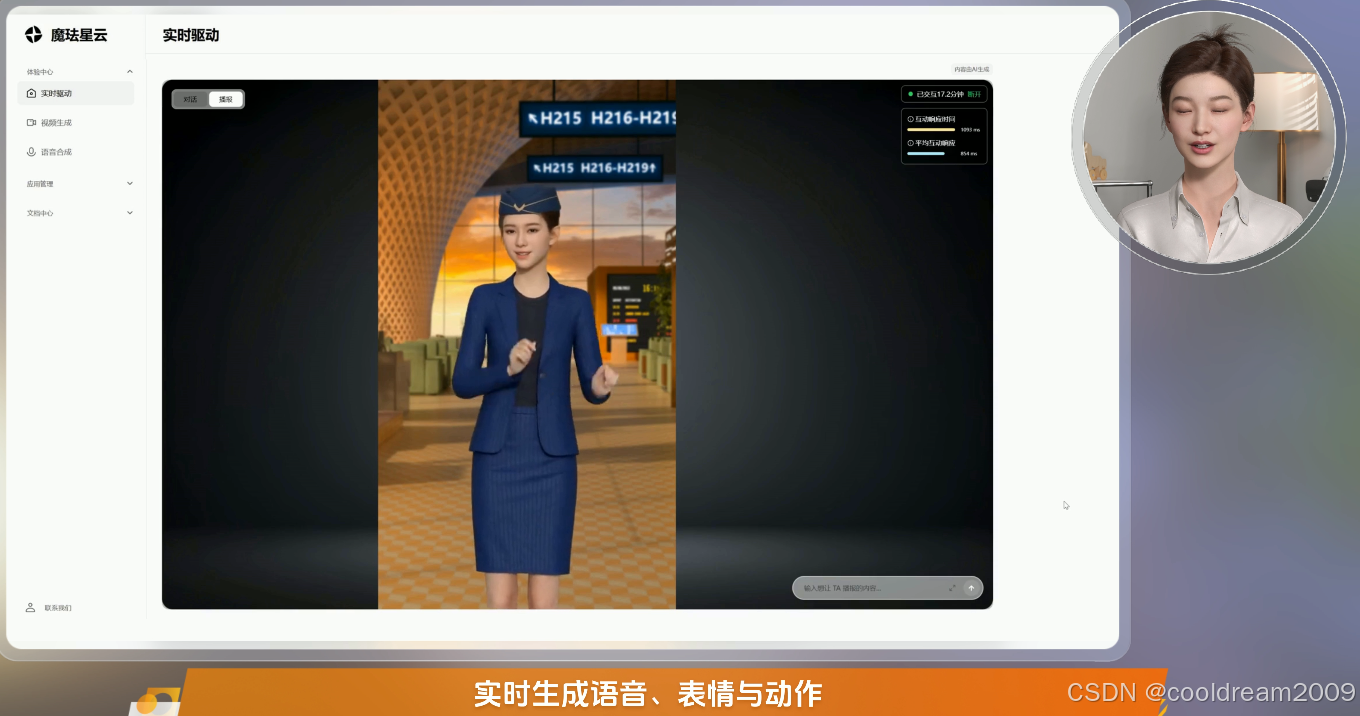
2.1 实时 3D 渲染能力
XmovAvatar SDK 提供了基于 WebGL 的实时 3D 虚拟人渲染能力,能够在浏览器环境中稳定运行。这一特性使系统无需依赖重型客户端,即可实现跨平台部署,适配教学、训练与在线对抗等多种使用场景。
SDK 支持多模型加载、光照配置以及基础动作系统,为后续的交互扩展预留了充足空间。
2.2 语音驱动动画能力
在具身辩论系统中,语音是虚拟人行为的核心驱动力。XmovAvatar SDK 内置了语音驱动嘴型与面部动画的能力,能够根据语音流实时生成对应的口型变化,从而实现"所听即所见"的同步体验。
这一能力是虚拟人"活起来"的关键,也是其区别于传统动画角色的重要特征。
2.3 状态与事件回调机制
SDK 提供了完整的事件回调体系,用于感知虚拟人的加载完成、开始说话、结束说话、异常中断等状态变化。这些回调为上层系统提供了可靠的同步信号,使虚拟人能够与 AI 对话、语音合成、字幕系统形成闭环协作。
3 AvatarService 的设计思路
3.1 为什么要进行 SDK 二次封装
直接在业务代码中调用第三方 SDK,往往会导致耦合度过高、状态分散、错误难以统一处理等问题。在具身辩论系统中,虚拟人属于核心交互模块,其稳定性和可控性尤为重要。
因此,系统引入了 AvatarService 作为中间层,对 XmovAvatar SDK 进行统一封装,隔离具体实现细节,为上层业务提供稳定、语义化的接口。
3.2 连接管理与生命周期控制
AvatarService 负责虚拟人的完整生命周期管理,包括初始化、加载、激活、休眠与销毁等阶段。通过集中管理连接状态,系统能够明确判断当前虚拟人是否可用,从而避免在异常状态下触发不必要的业务逻辑。
生命周期的明确划分,也为资源释放与性能优化提供了基础。
3.3 错误处理与状态同步
在实时交互系统中,网络抖动、资源加载失败、音频异常等问题不可避免。AvatarService 内部对 SDK 抛出的异常进行统一捕获与转换,将底层错误映射为业务可理解的状态码,并同步至全局状态管理模块。
这种设计使前端其他模块无需关心虚拟人细节,只需基于状态变化作出响应。
4 虚拟人与 AI 对话的协同机制
4.1 AI 回复到语音合成的衔接
当大模型生成辩论回复后,文本并不会直接展示给用户,而是首先进入语音合成模块。生成的语音流将作为虚拟人表达的触发源,从根本上确保"说话"是虚拟人行为的起点。
这种设计避免了文本与语音的割裂,使虚拟人的每一次表达都具有明确的行为驱动。
4.2 语音驱动嘴型与动画
语音合成完成后,音频数据被传入 AvatarService,由其协调 XmovAvatar SDK 启动语音驱动动画。嘴型变化、头部微动与基础表情同步进行,从而形成自然的说话效果。
在工程实践中,这一过程需要严格控制延迟,否则会显著降低用户对"真实感"的信任。
4.3 字幕与视觉反馈同步
在训练场景中,字幕依然具有重要价值,尤其是在语速较快或内容复杂的辩论中。系统通过统一的时间轴管理机制,将字幕展示与语音播放、虚拟人动画进行同步,确保多模态信息的一致性。
5 虚拟人状态建模
5.1 核心状态定义
为了让用户清晰感知 AI 的当前行为,系统为虚拟人定义了明确的状态模型。主要状态包括:空闲状态、思考中状态、说话中状态。
每一种状态都对应不同的视觉表现,例如思考状态下的停顿、轻微动作,以及说话状态下的持续动画输出。
5.2 状态切换与用户感知
状态切换并非纯技术行为,而是直接影响用户心理预期的重要信号。当虚拟人进入思考状态时,用户能够直观理解 AI 正在生成回应,从而减少等待焦虑;当进入说话状态时,注意力自然集中于内容本身。
这种显性状态建模,是具身交互相对于传统对话框的重要优势。
6 具身交互的体验设计要点
6.1 延迟控制的重要性
在具身系统中,延迟不仅是性能问题,更是体验问题。语音、动画与文本之间的不同步,会迅速破坏沉浸感。因此,系统在设计时将端到端延迟作为核心指标之一。
6.2 动画与语言节奏的匹配
虚拟人的动作节奏需要与语言节奏保持一致,过快会显得浮躁,过慢则会显得迟钝。通过对语音时长与动画参数的动态调整,系统尽量避免"机械播报"的观感。
6.3 避免机械感的设计策略
在实践中,总结出一条重要经验:宁可减少动作数量,也要保证每一次动作都有明确意义。克制的动画设计,反而更容易让用户接受虚拟人作为"对手"而非"玩偶"。
7 小结
虚拟人在具身辩论系统中并非附属组件,而是 AI 与用户之间的第一界面。通过对 XmovAvatar SDK 的合理封装与深度整合,系统实现了从大模型思考到具身表达的完整链路。
未来,随着表情系统、动作库与情绪建模的进一步引入,虚拟人将不再只是"会说话",而是逐步具备更接近真实辩手的表现能力。这也正是具身智能在训练型 AI 系统中的长期演进方向。
参考资料
- XmovAvatar SDK 官方技术文档
- Embodied AI 与 Human-Computer Interaction 相关研究论文
- Web 端 3D 渲染与实时交互工程实践资料
- 多模态人机交互系统设计相关书籍