Postgres的IO架构和调优方法
前言
我们在高配置的服务器上,部署PG完成后,使用 pgbench 工具测试时发现在硬件资源并没有到达瓶颈,而 TPS 始终上不去的情况,而这种情况可能和IO有关系、接下来分享一下 IO 架构的关处理逻辑以及实用的调优技巧。
例如以下的一个测试案例,使用pgbench -c 32 -j 32 的情况下进行测试结果如下:
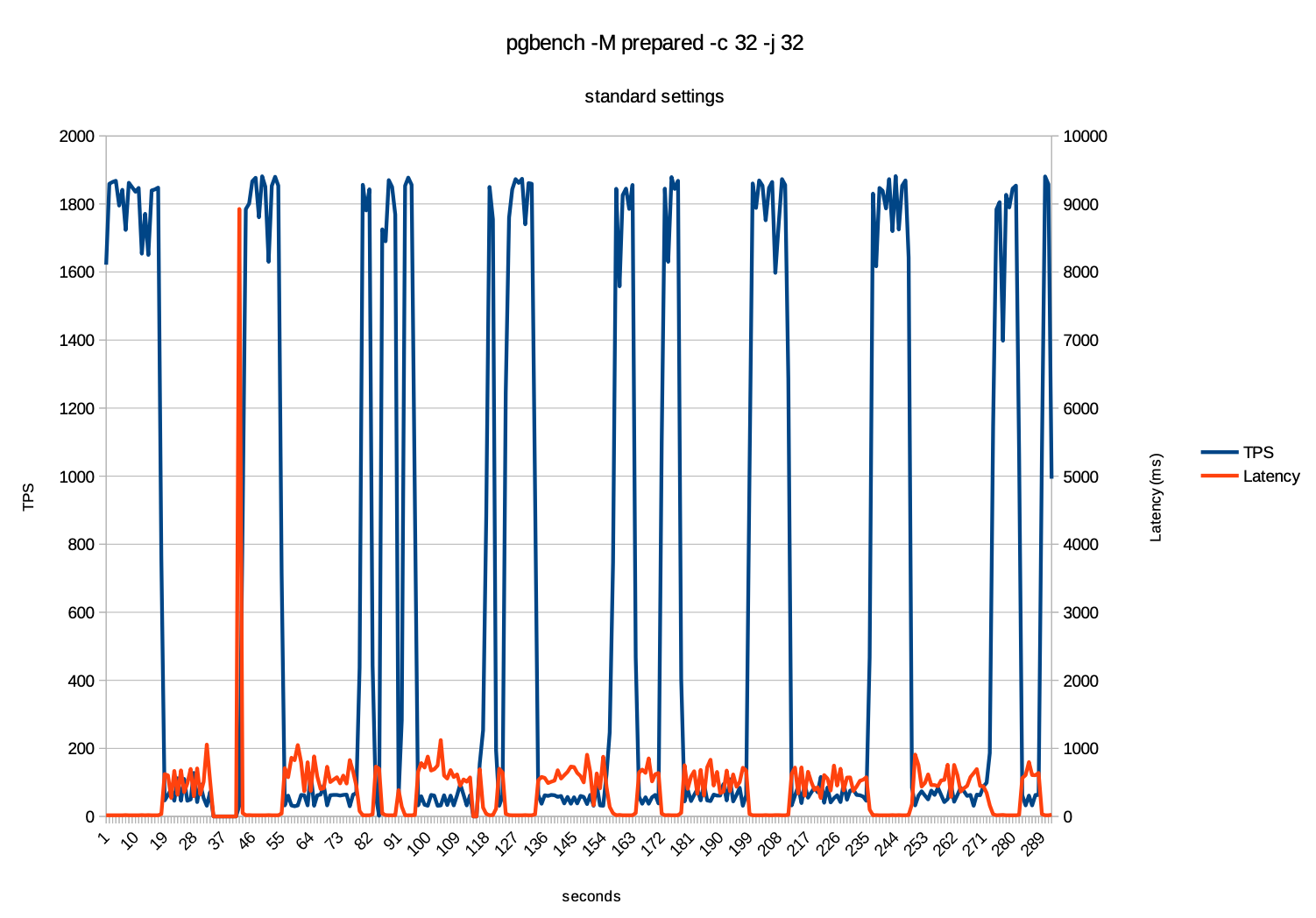
在以上的测试中可以观察出:
- 蓝色曲线:TPS 周期性的出现尖峰和谷底的情况。
- 黄色曲线:在TPS下降时 延迟会迅速的增加,远高于正常的范围值
- 周期性的波动:在以上的图上也可以看出波动出现了周期性的,大约每30-40秒出现一次
以上问题的分析及解决方式
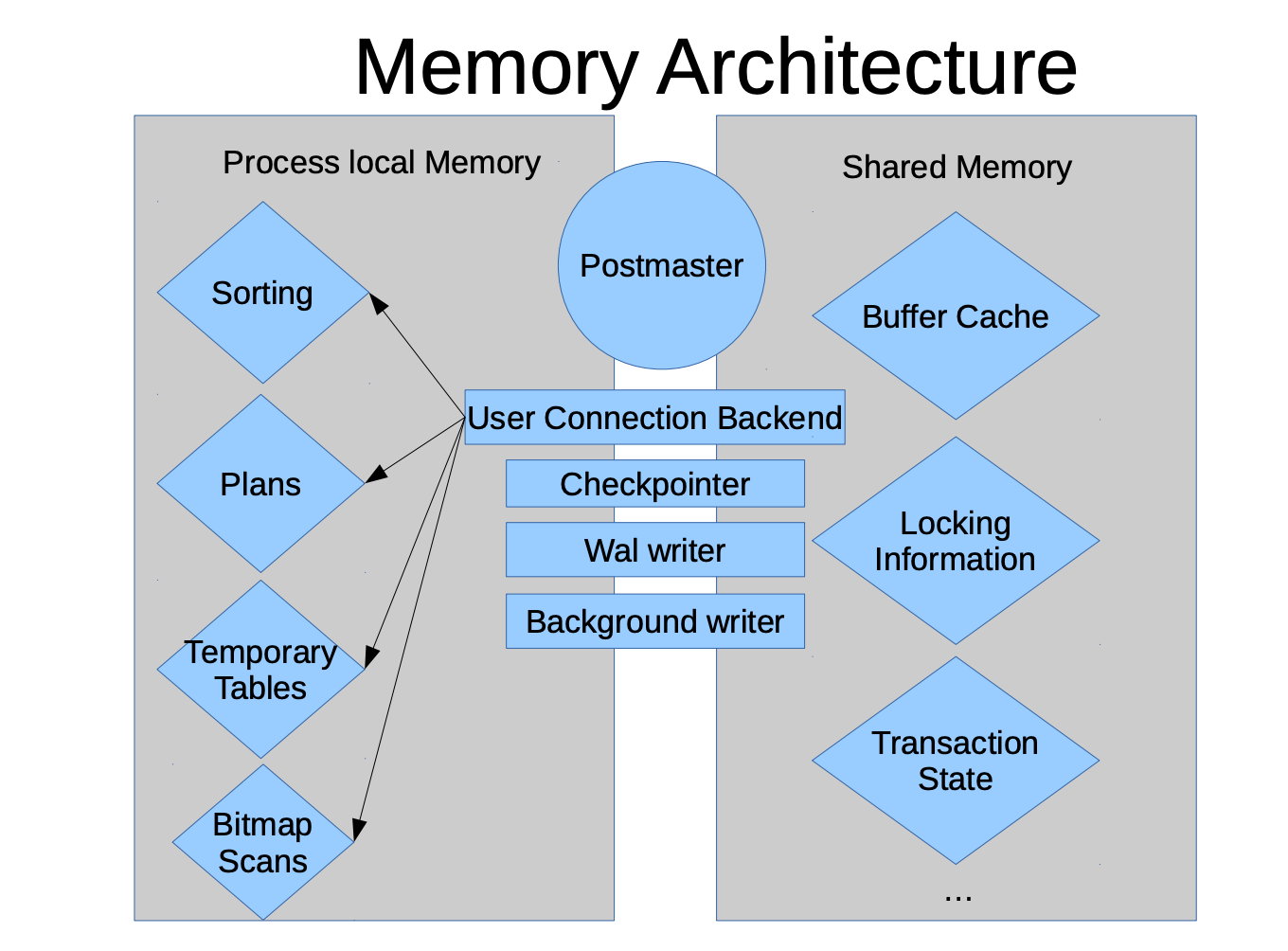
为了搞清楚以上出现的问题,首先需要了解下PG的内存架构,内存架构分为进程本地内存和共享内存,如下:
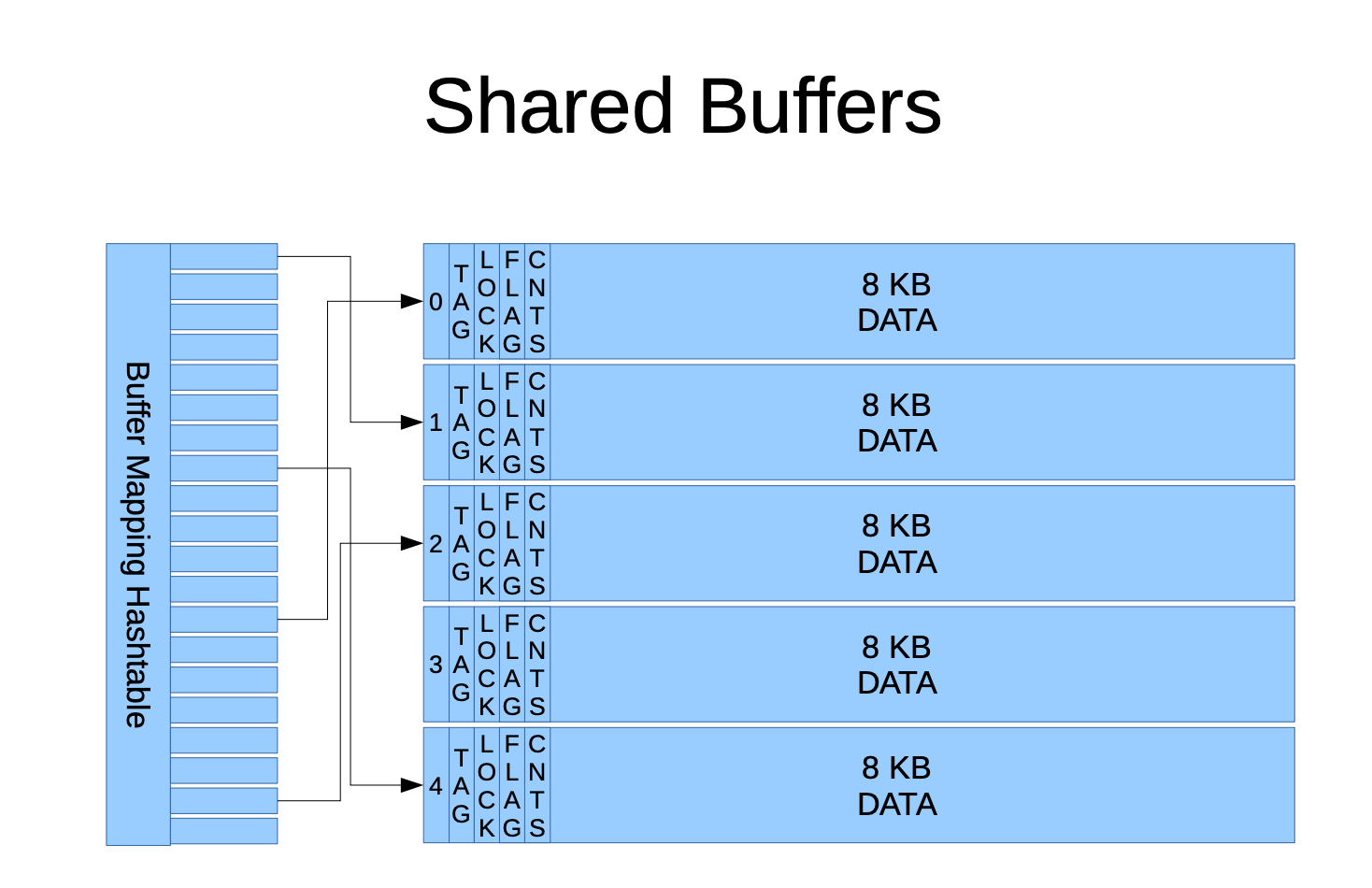
Shared Buffers
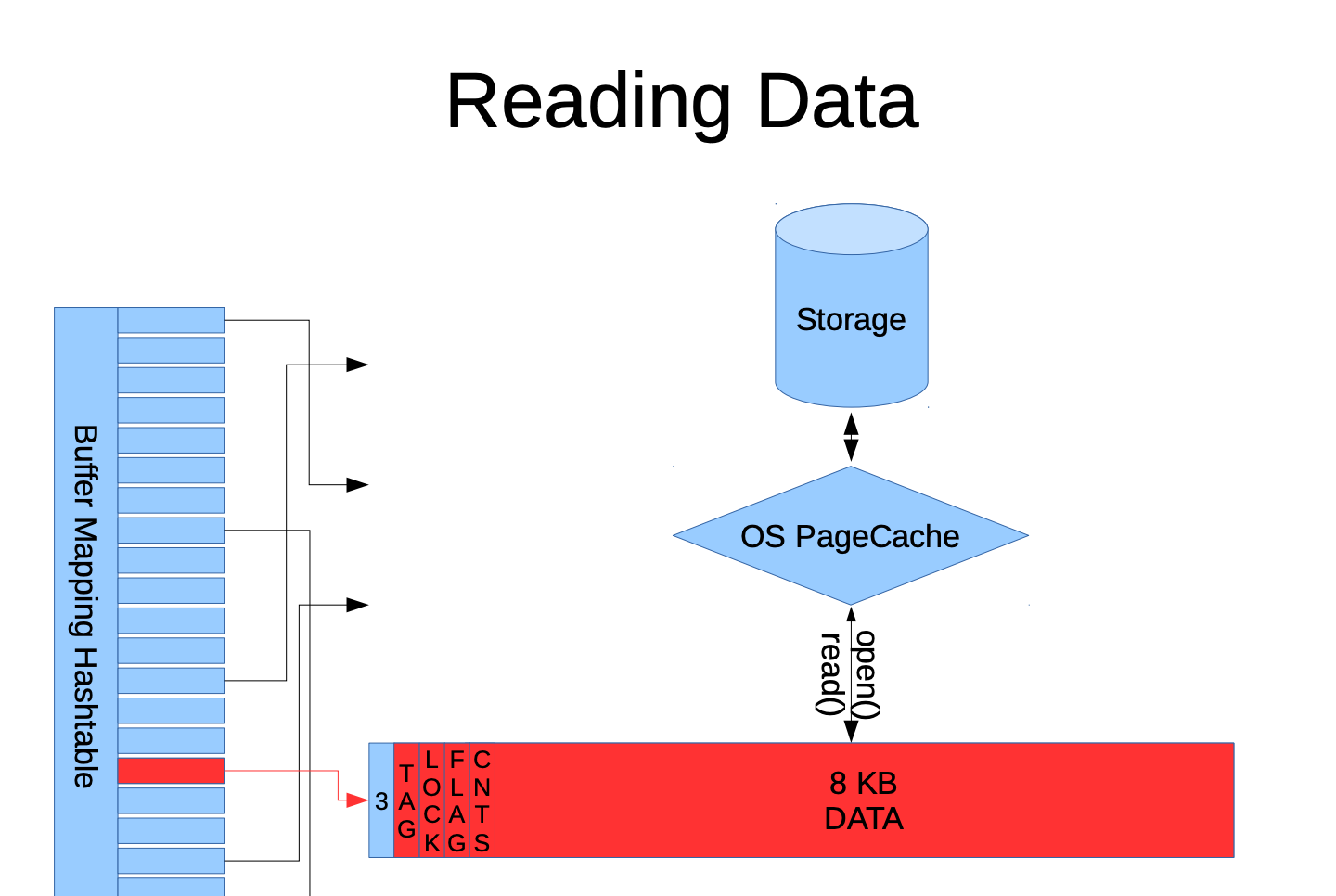
PG中有 Buffer Mapping Hash Table 哈希表,主要作用是保存着与表数据块的映射关系,例如一个 test 表的 pg_relation_filepath 为 base/5/16385 ,那么会构造映射到希表的三元组的键(relfilenode=16385, forknum=MAIN_FORKNUM, blocknum=0) 作为唯一的值,则为 (16385,0,0),如果 test 表的数据超过8KB,blocknum 则依次增加。
- relfilenode:为表/索引/物化视图等的relnode 值,表示与物理磁盘的实际的文件
- forknum:表示与relfilenode有四个不同的fork的值:
MAIN_FORKNUM代表的是主数据
FSM_FORKNUM代表的 Free Space Map
VM_FORKNUM 代表的是Visibility Map
INIT_FORKNUM代表的是初始化fork - blocknum:对应数据页的偏移序号,从0开始,序号依次增加,每个数据页为8KB
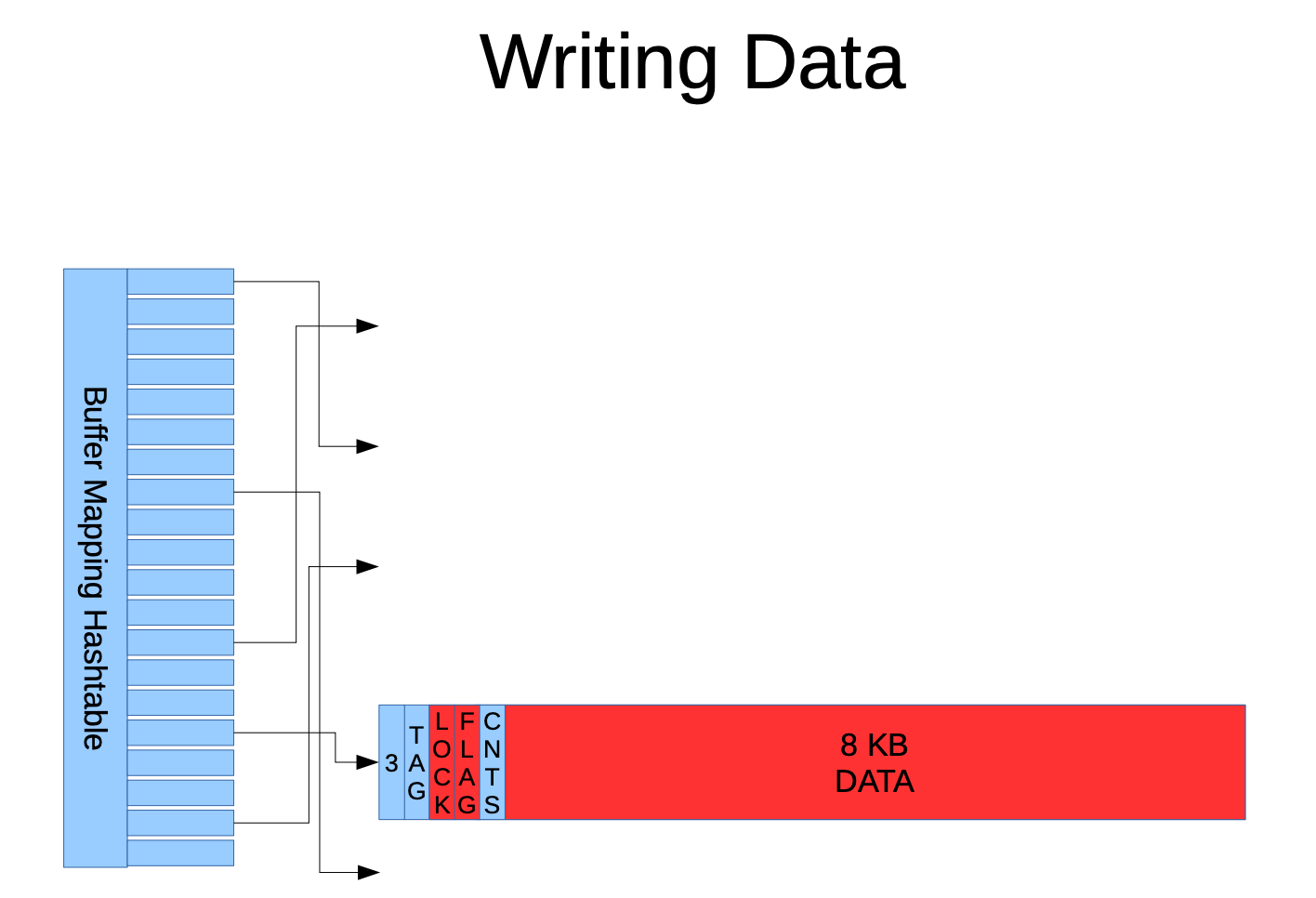
当写入数据时,PG 首先在 Buffer Mapping Hash Table 中查找目标页面的键,如果不存在,则从 Shared Buffers 池中选择一个空闲缓冲区,如果没有空闲的缓冲区,则通过 LRU(时钟扫描算法)替换一个最不活跃的缓冲区,并将新数据页加载到该缓冲区中,实现高效写入。
当数据查询时会构建该表查询条件的数据块的ID,再根据该DI构造哈希表需要的键,如果该键存在于Buffer Mapping Hash Table 中,访问 shared_buffer 中的DATA区域直接进行返回数据,速度非常快。如果该键不在哈希表中则会使用一种LRU(时钟扫描算法)选择一个可替换的缓冲区,如果所有缓冲区都被占用,则调用操作系统的接口来申请内存页,最终通过操作系统的 OS PageCache 从磁盘加载数据。
以下的 Clock Sweep 的图示代表了shared buffers共有36个缓冲区,序号从0 - 35,指向 4 的指针表示CNT 为 0 代表未被频繁的访问,指向2 的指针代表CNT 3 代表比较活跃。因为 shared_buffers 是按照设置的参数设置有固定的内存池大小,当 shared_buffers 都被占用时,新页面的加载需要通过 Clock-Sweep 找到最不活跃的缓冲区进行替换,并通过操作系统的 read() 系统调用从磁盘加载数据,当读取的数据不在缓冲区时从而会频繁的触发read() 的调用动作,从而增加了耗时。
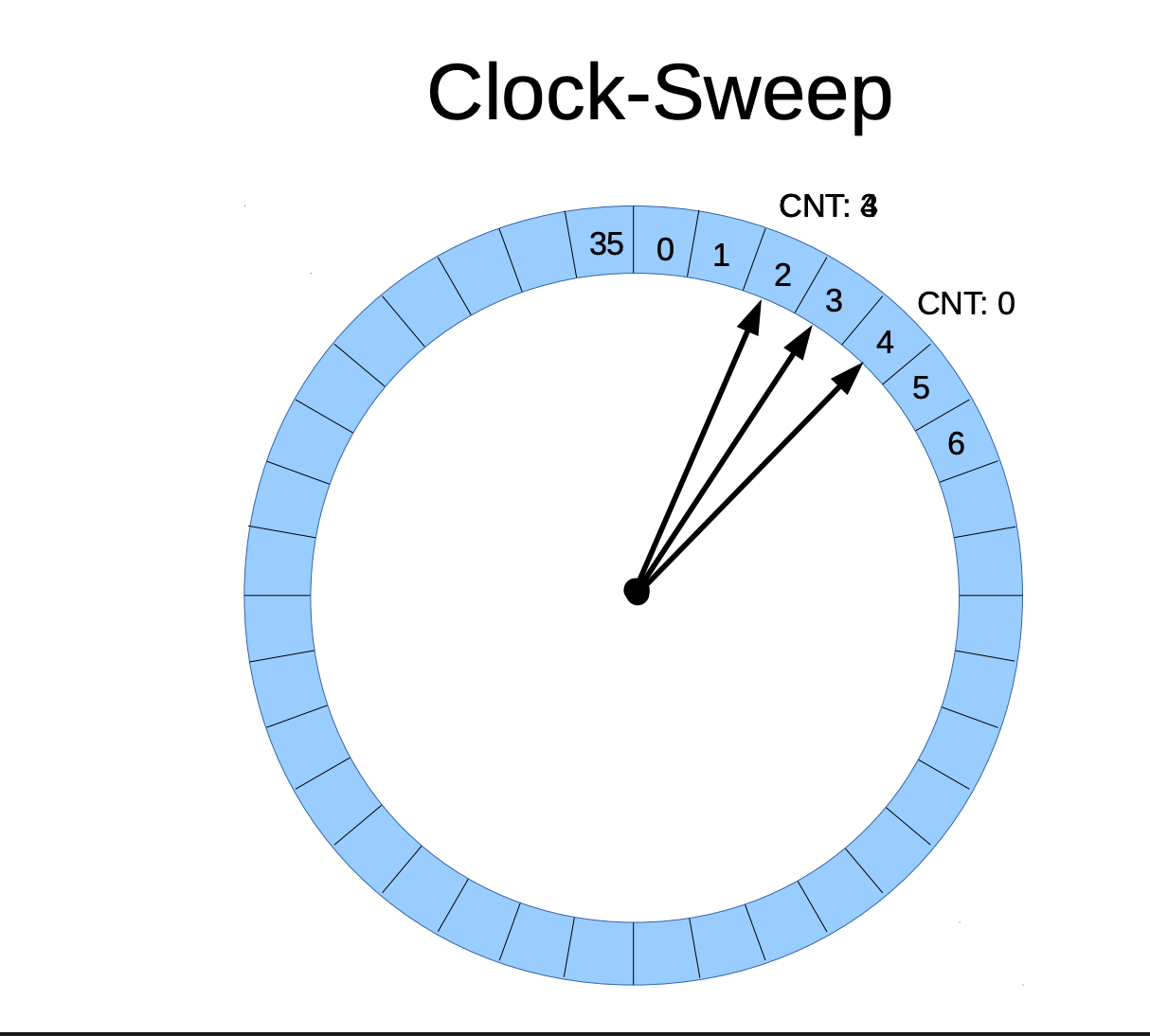
因为 shared_buffers 是按照设置的参数设置有固定的内存池大小,当 Shared Buffers 缓存全部被占用时, 通过 Clock-Sweep 算法选择最不活跃的缓冲区进行替换,并调用操作系统的 read() 系统调用从磁盘加载数据,如果该数据不在共享缓冲区中,则会频繁触发 read() 操作,导致 I/O 增加、响应延迟上升,从而影响查询性能。
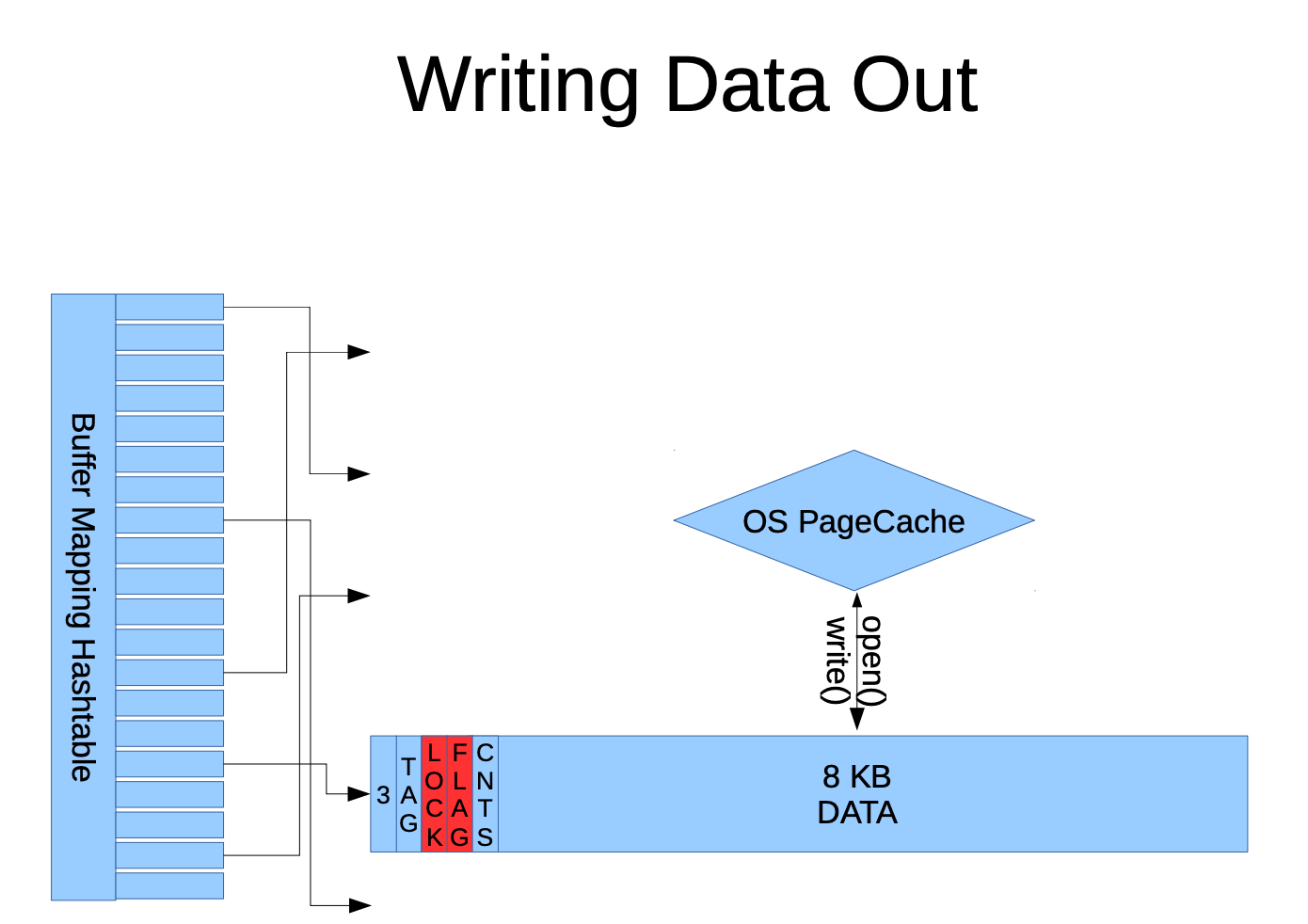
WAL 日志
PG 在内存中的数据块是以 8KB 作为一个缓冲区储存的(可以通过with-blocksize修改),再每个缓冲区中不仅存储了表的数据,还包含相关的元信息,这些数据如果尚未写入磁盘,需要先记录到 WAL 日志中,以确保即使发生崩溃也能正确恢复。
- TAG: 表示该页面的唯一标识键,即 ``(relfilenode=16385, forknum=MAIN_FORKNUM, blocknum=0)`
- LFCKG:表示缓冲区的锁状态或 latch 状态,在多线程操作时,确保了具有安全的共享缓冲区
- FOLCAT:控制页面内部的空间使用情况,表示tuple的偏移量、
free space的指针位置、页头以及FSM相关数据的信息 - CNTS:记录该缓冲区的活跃度,由
Clock-Sweep 算法算法控制

当 mytbl 上由索引时,当在插入一条数据,会在WAL日志中不仅记录了操作的类型、还会记录对应的事务ID、序列号以及相关的描述等。这些记录确保了数据的一致性、持久性,当集群异常的崩溃可以根据WAL进行恢复。
rmgr:(Resource Manager),值由Heap、Btree、Transaction、Storage、Toast、XLOG等
tx: 事务 ID(Transaction ID),全局唯一标识该事务
lsn:Log Sequence Number(日志序列号),全局递增,用于定位日志位置
desc:描述字段

每一次的执行checkpoint操作,便是将内存中的数据写入到磁盘,称为是"刷脏",记录一个checkpoint记录点,便于根据此检查点进行恢复数据,此操作也是将 Shared Buffers 中的修改永持久化到数据磁盘上。checkpoint 的运行机制分为6个部分,分别是:
- PG 记录当前的WAL的写入位置,并将这次位置标记成
checkpoint的七点 - 跟新内部状态、清理临时的结构、准备刷盘的列表
- 扫描
shared_buffers中的脏缓冲区、调用系统的write()方法将数据落到对应的relfilenode对应的磁盘文件上 - 对所有的上一次的checkpoint的从未修改过的文件执行fsync() ,确保数据从OS写入到了磁盘上
- 写入一条wal 的位置、已刷盘的脏页信息、并预估下次checkpoint的时间
- 移除已不再需要的WAL 日志文件
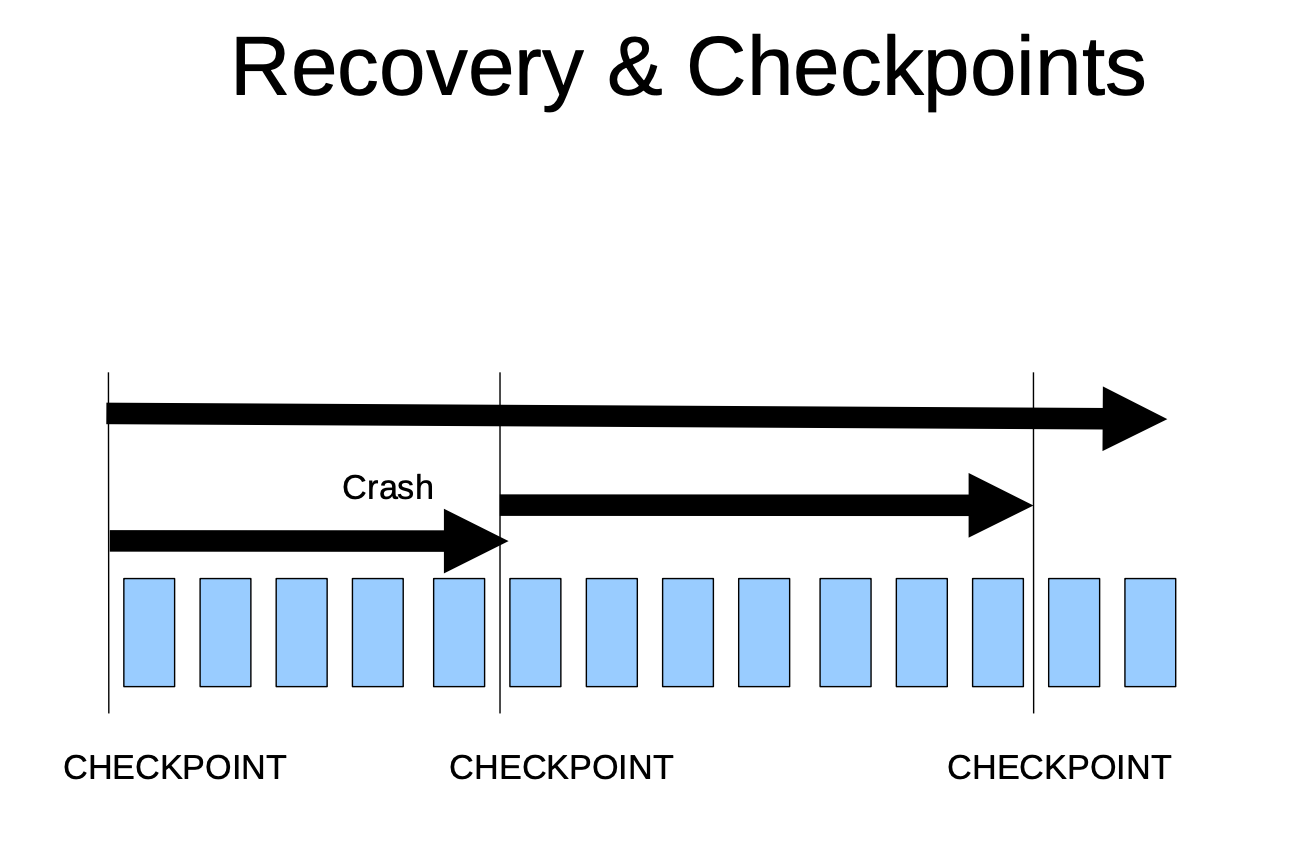
触发checkpoint的方式有手动执行checkpoint、手动关闭集群、checkpoint_timeout 参数到执行时间、触发 checkpoint_segments/max_wal_size 的条件。以确保内存中的数据已被全部写入到磁盘上。
调整内存进行对比测试
在以上已经了解了 shared_buffers 参数的大小会直接影响数据读取的方式,如果 缓存中有数据则会查询非常快,如果缓存中没有数据则会频繁的调用系统的read()从磁盘上加载数据,下面则是一组对比。
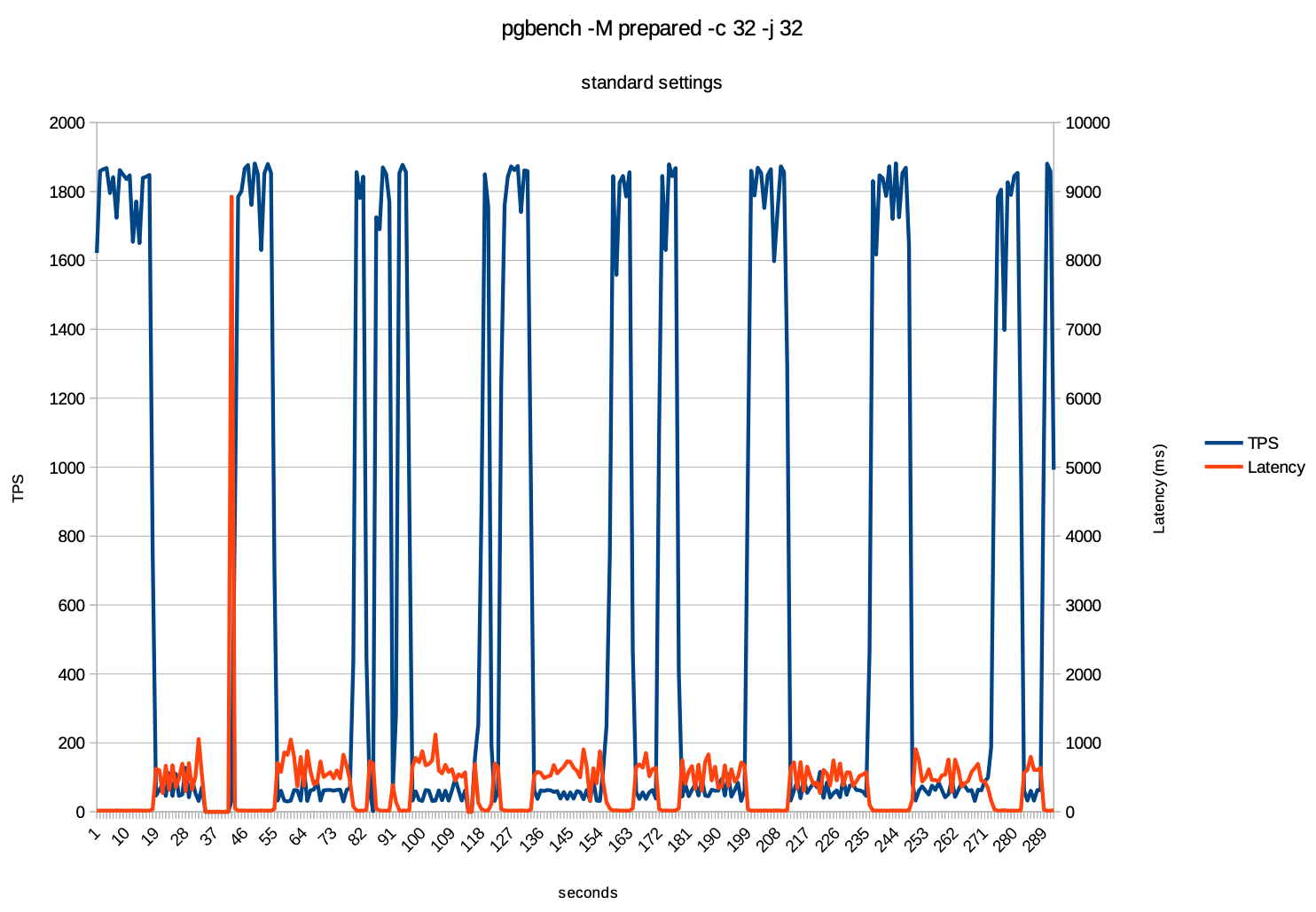
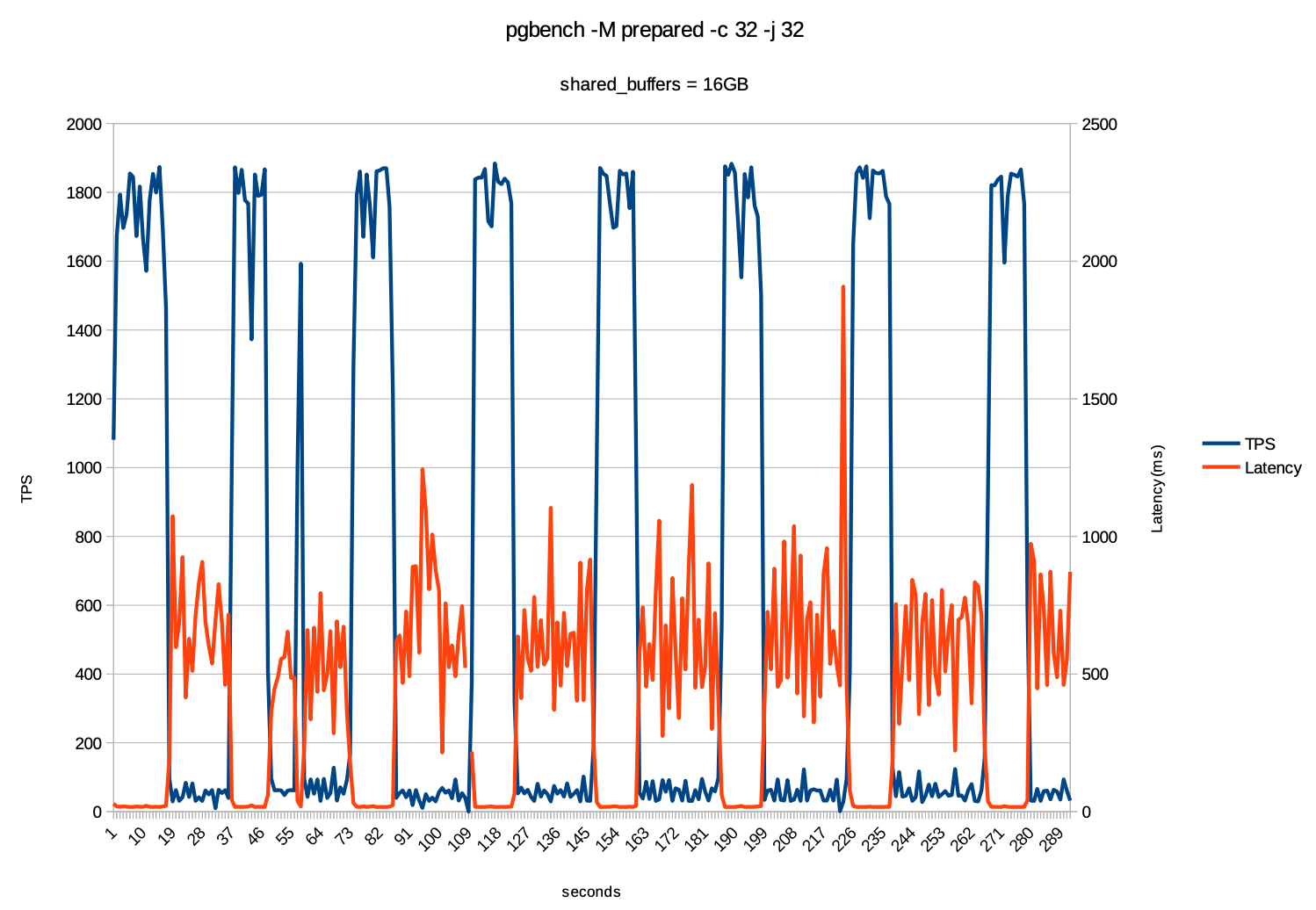
在以上的图形中可以明显的看出使用默认的shared_buffers值时,TPS 出现了拉锯式的波动,出现的尖峰和谷底明显,到达最高TPS时便很快下降,在37秒时延迟突然出现了剧增的情况。而把 shared_buffers 调到16GB 时,如下图则明显改善了很多。
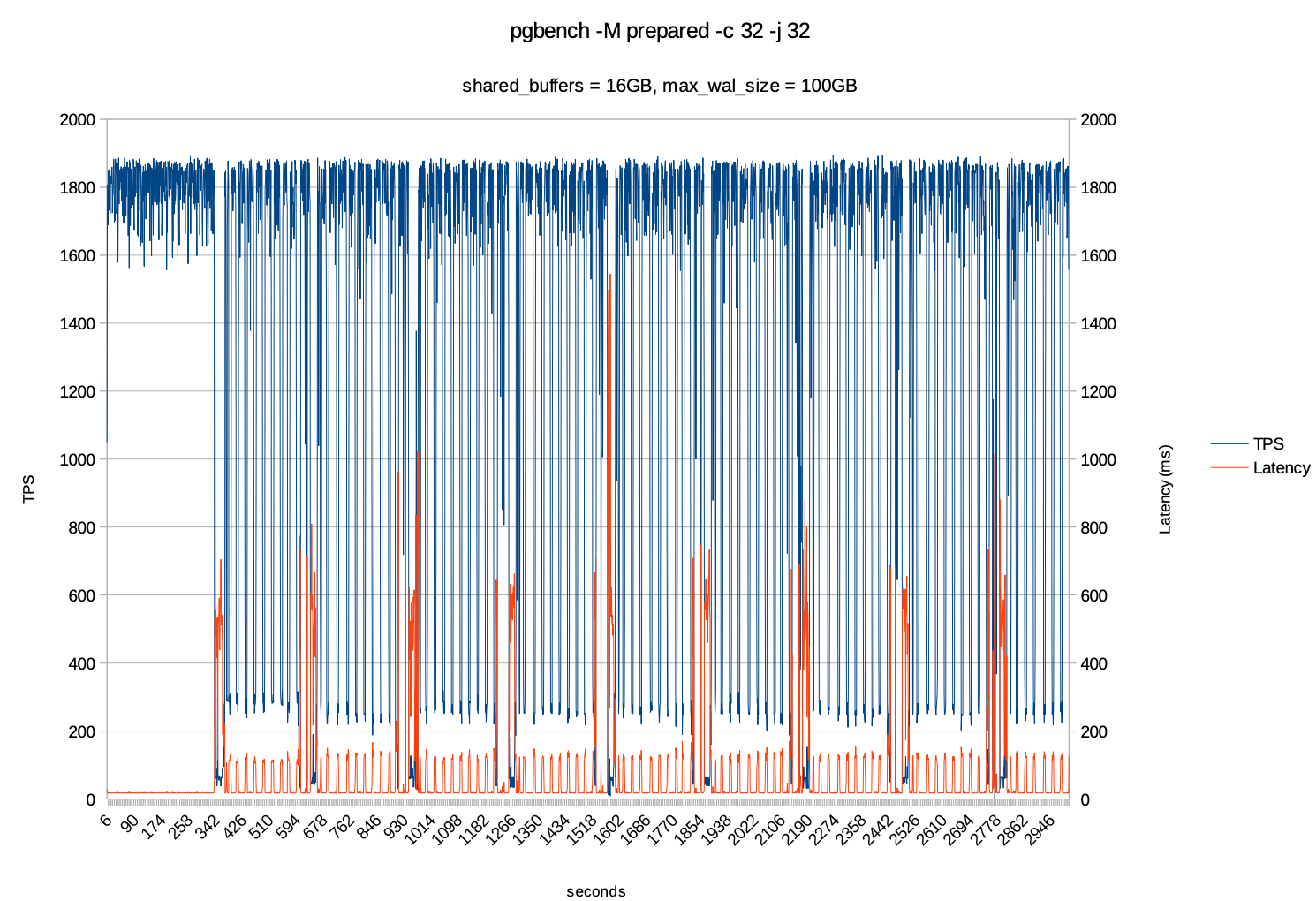
在 shared_buffers 调到 16GB 的同时,又把 max_wal_size 调100GB,让数据全部在wal的文件中,减少fsync 的操作。测试期间TPS 维持在1700+ 以上,延迟大约在50ms 以内,并且没有出现明显的尖峰和谷底。
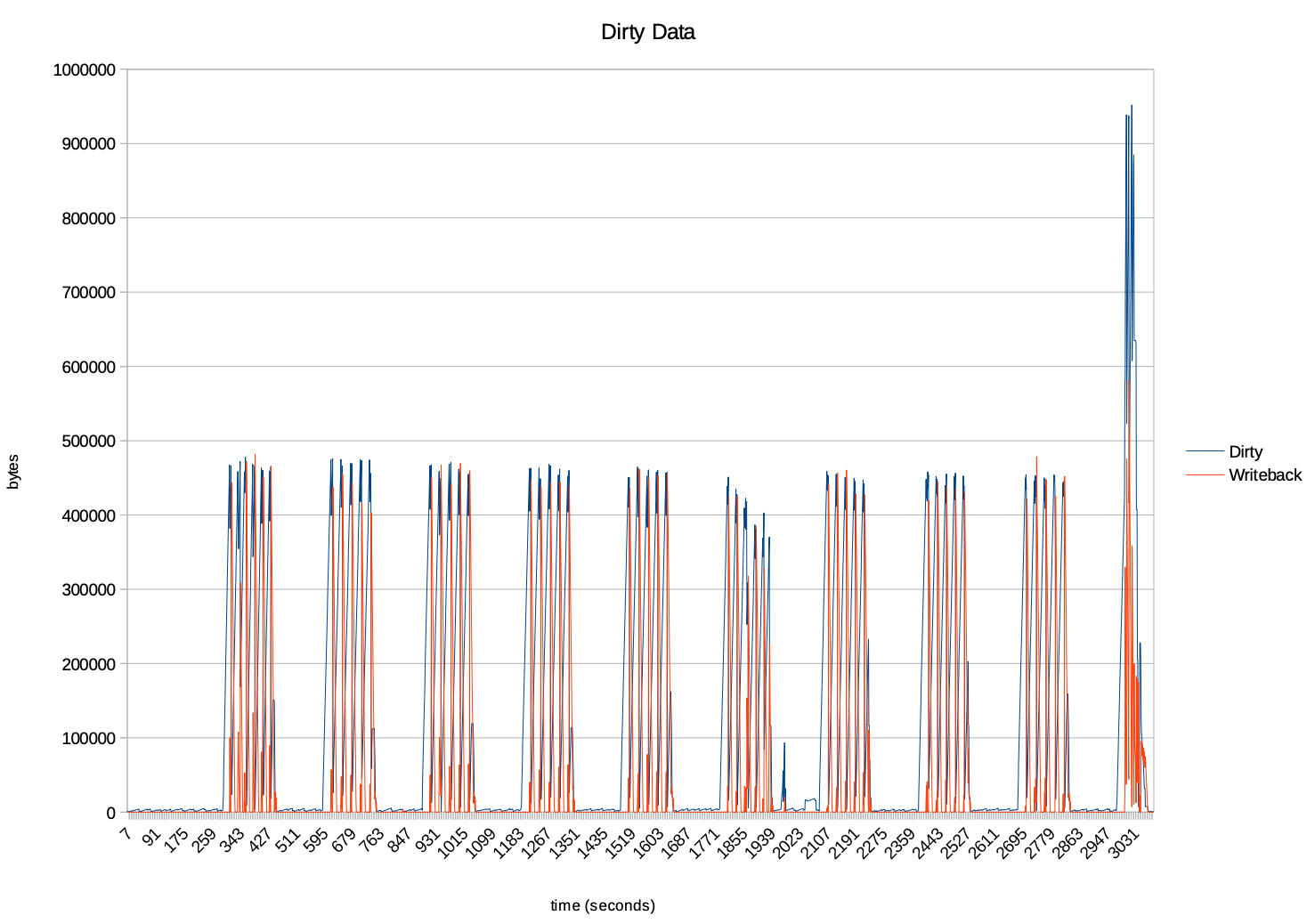
PG 在测试期间通过在事务内的数据修改、但尚未写入磁盘的数据块在 shared_buffers 中,被 bgwriter 和 checkpoint 刷盘变化趋势。bgwriter 每一次扫描shared_buffers 中的缓冲区,找到 dirty pages 并writeback 操作,变出现了"周期性"变化的趋势。checkpoint的操作是受checkpoint_timeout 的设置的值影响,当到达次设置时便会触发一次writeback的操作,也会导致 dirty data 快速清空,从而也导致了"锯齿状"的形状。在最后的一个异常的波动可能是测试期间积累的大量的未刷盘操作,执行了 sync 操作,所导致了异动。
在以下的测试把 dirty pages 去掉,也是会存在checkpoint的抖动,在执行checkpoint时所导致的TPS下降、延迟增加的现象、但整体是较稳定的。
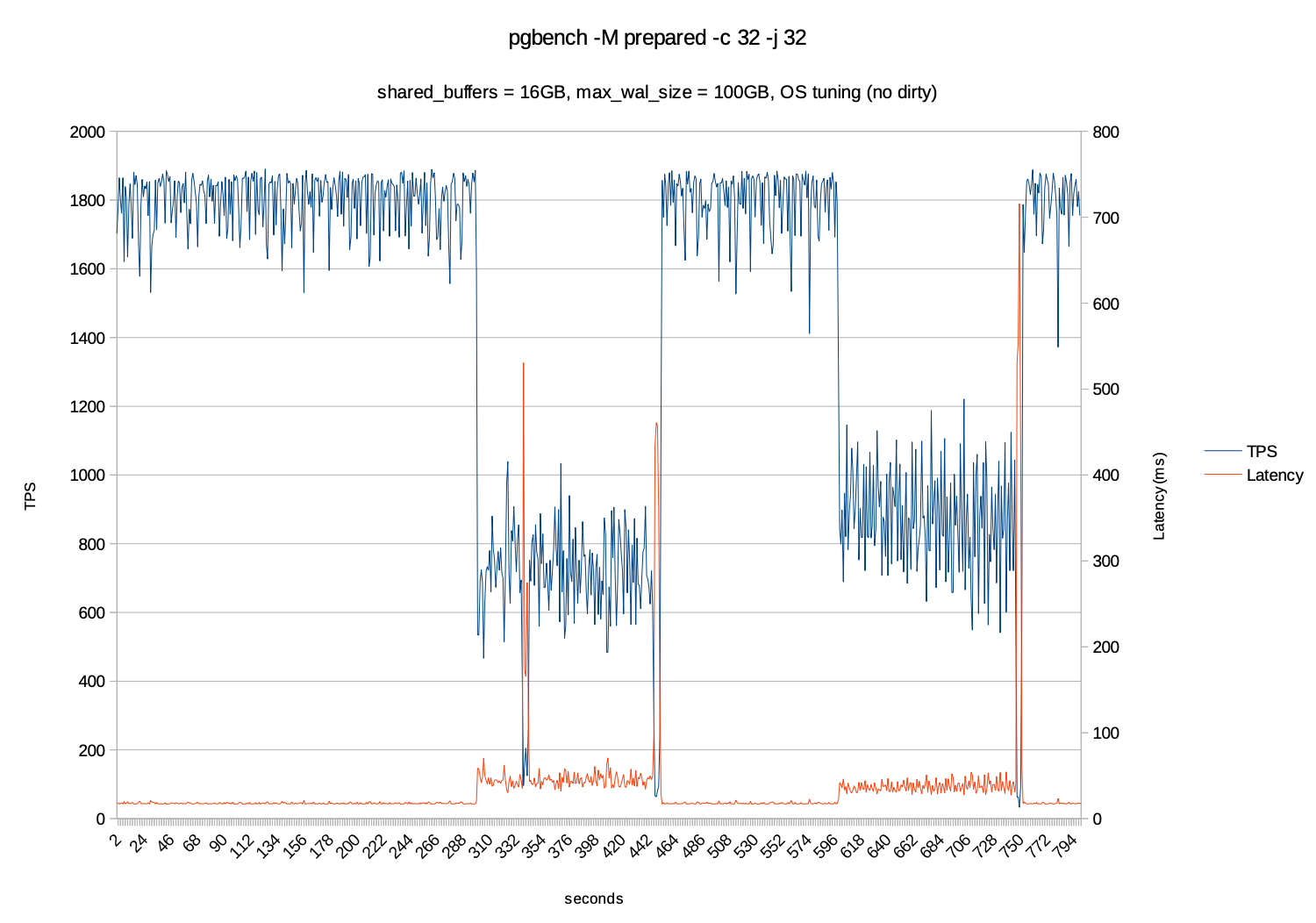
当设置checkpoint_timeout = 300s时并且checkpoint_completion_target=0.9 及checkpoint的周期拉长到90%的时间,及270秒内完成,让数据落盘更加的平滑,而不是瞬间刷完所有脏页,避免出现波峰和波谷的现象。
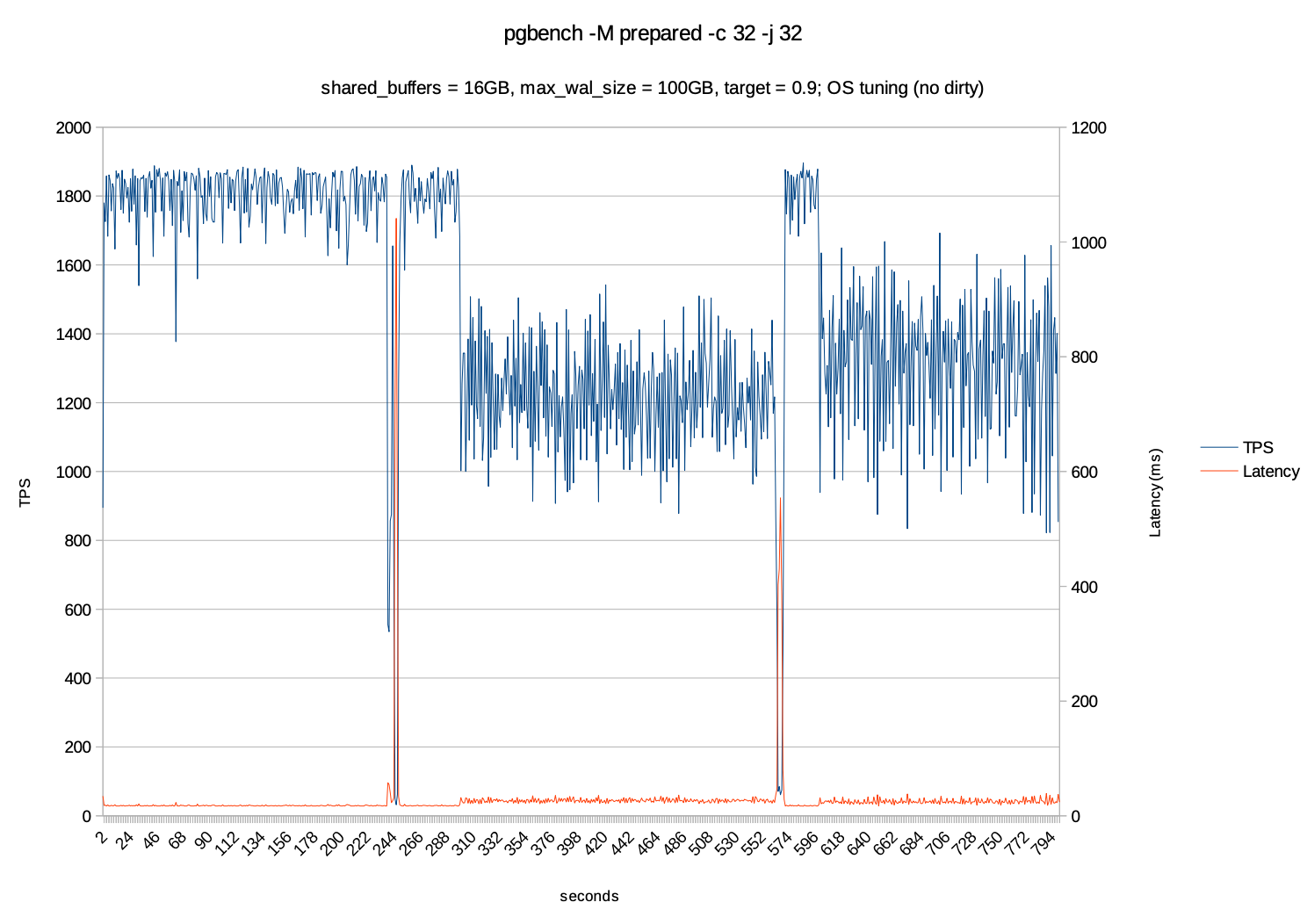
在 shared_buffers = 16GB、max_wal_size = 100GB、checkpoint_completion_target = 0.9并且在开启 flushing的情况时,减少 "脏页" 的增加,加快数据持久化速度,降低 checkpoint 的冲击的情况下,和没有开启flushing之前已具有明显的改善。
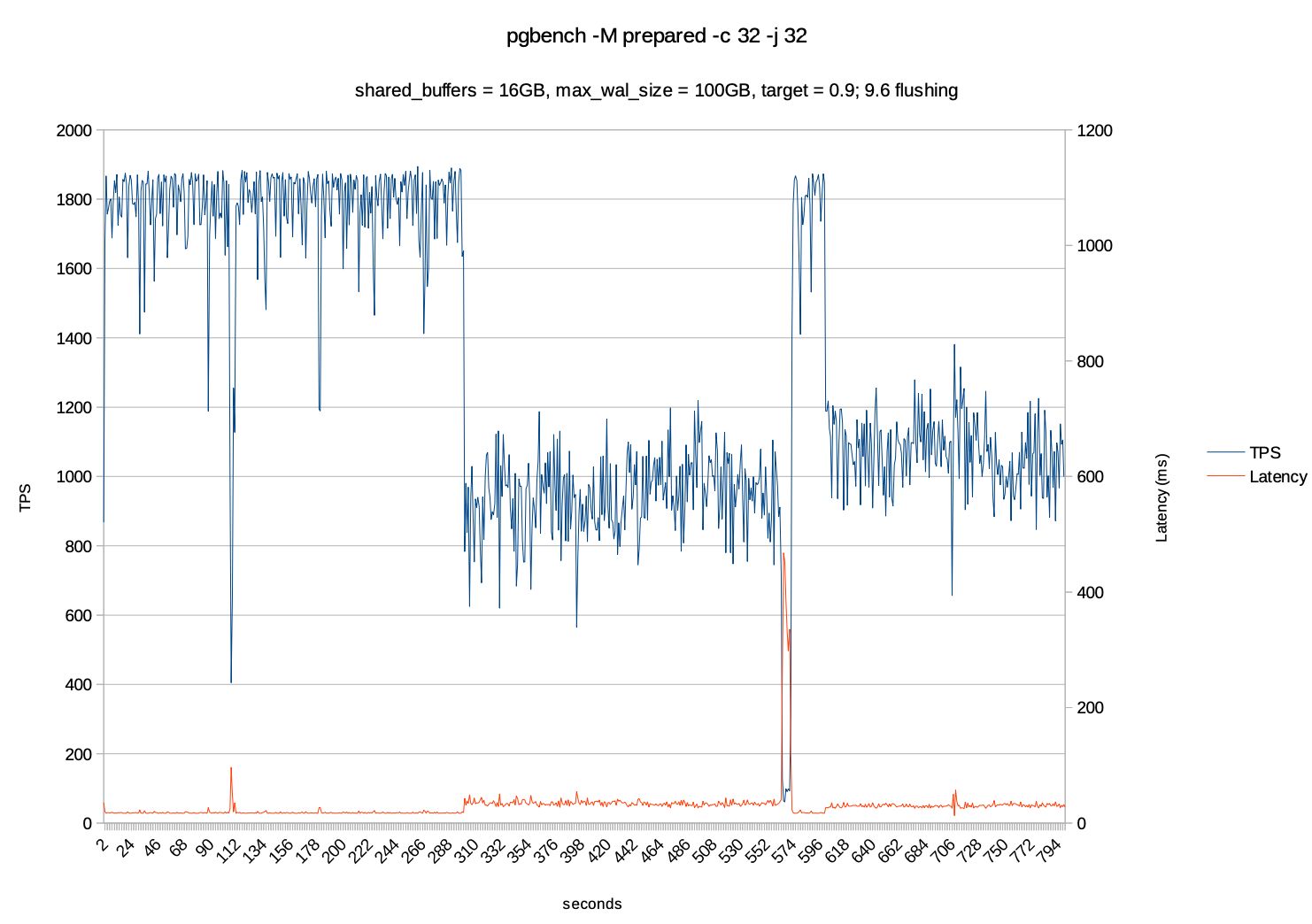
OS 层级调优
在优化PG数据库时,OS层面的调优也会起到重要的作用,在Linux中的Dirty Page Management(脏页管理)涉及的参数有dirty_writeback_centisecs、dirty_bytes、dirty_ratio、dirty_background_bytes这几个的参数的具体的作用及配置建议如下:
- dirty_writeback_centisecs:控制内核多长时间检查一次是否将脏页写入到磁盘上,该值的默认值是500即5秒检查一次,需要调成100或者200,目的是频繁的触发writeback 写操作,避免大量的脏页堆积到内存中,一次性的进行写入导致IO波动较大。
- dirty_bytes / dirty_ratio :当内存中的脏页达到多少时,阻塞新的写入,该值的比例设置成5%或者10%即可,避免太多的数据在OS的缓存中,避免一次性较多的checkpoint的操作,可以把vm.dirty_ratio = 10和 vm.dirty_background_ratio = 5 让PG 的进程尽早的把数据写入到磁盘,而不是等待OS的自动处理
- dirty_background_bytes :当脏页达到多少时,启动后台的进程进行异步写回,该值通常小于dirty_ratio,目的是提前触发写回,防止脏页堆积,避免一次性大量的写入,让写盘更加平稳,特别适合于负载较高的场景,可以把vm.dirty_background_ratio = 5 实现渐进写盘,而不是爆发式写盘。

在PG复杂将脏页写到磁盘上的进程是 bgwriter,但是bgwriter是从shared_buffers 中挑选任意的页面进行写入,而这种写入是随机的,而不是顺序写的,无法使用磁盘的优势,bgwriter的在HDD的磁盘上不是很优化,而在SSD上则可以适当的调整,可以适当调整 bgwriter_delay 、bgwriter_lru_maxpages 、 bgwriter_lru_multiplier 来增大一次性bgwriter 写入的大小。

参考资料: