1 简介
元启发式优化算法通常基于迭代改变个体位置,导致种群切换搜索区域。这可能导致原始搜索区域没有被深入探索,从而降低算法的优化性能。为了加深种群和个体之间的联系,本文提出了一种称为经验交换策略(EES)的进化策略。EES考虑了个体和种群之间的关系,加深了个体和种群之间的联系。EES已经结构化为三个不同的阶段:经验稀缺阶段(ESC)、经验交叉阶段(ECR)、经验共享阶段(ESH)。
在ESC中,由于许多区域没有被搜索,人口缺乏搜索经验,主要依靠原始算法来寻找位置。这可以保留原始算法的优化效果,探索更多的位置。ECR,由于人口积累了更多的经验,个人会根据更多的参考人口经验来更新他们的位置。这可以提高搜索范围的准确性,并进行更详细的搜索。在ESH中,人口积累了大量的经验,个人根据人口的经验进行更详细的搜索。通过ESH,人口可以集中搜索,以更精细地找到更好的位置。
2. 经验交换策略 (EES)
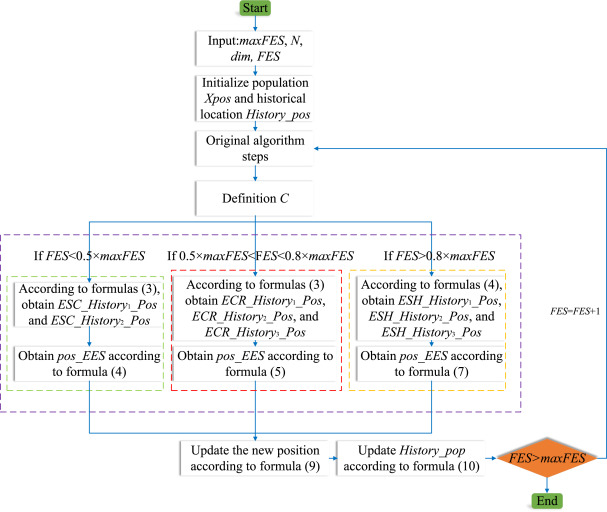
2.1. EES 灵感与概述
元启发式优化算法的主要原理是通过迭代搜索来逼近更优的解。然而,并非每次更新都能找到更好的解。要找到一个更好的解是很困难的,尤其是当算法陷入局部最优时。本文提出了一种经验交换策略 (EES),以提高元启发式优化算法的优化能力。EES 基于种群的历史位置和自身位置交换经验。EES 可以改善种群之间的联系,并增强算法的优化能力。因为许多算法通常由最优解引导,每个解都与最优解存在某种关系。随着种群在搜索过程中不断积累经验,探索区域不断深化。种群之间的联系也更多。因此,EES 使用不同的公式来寻找更好的解。
2.2. 初始化种群与历史种群
在优化算法中,每个个体都是一个 1×dim1 \times dim1×dim 的矩阵,每个个体可以获得一个适应度值。NNN 是种群数量。如公式 (1) 所示。
Hi=pos1,pos2,...,posN(1)H_i = pos_1, pos_2, \\ldots, pos_N \tag{1}Hi=pos1,pos2,...,posN(1)
Xpos=pos1,1pos1,2⋯pos1,dimpos2,1pos2,2⋯pos2,dim⋮⋮⋱⋮posN,1posN,2⋯posN,dimX_{pos} = \begin{bmatrix} pos_{1,1} & pos_{1,2} & \cdots & pos_{1,dim} \\ pos_{2,1} & pos_{2,2} & \cdots & pos_{2,dim} \\ \vdots & \vdots & \ddots & \vdots \\ pos_{N,1} & pos_{N,2} & \cdots & pos_{N,dim} \\ \end{bmatrix}Xpos= pos1,1pos2,1⋮posN,1pos1,2pos2,2⋮posN,2⋯⋯⋱⋯pos1,dimpos2,dim⋮posN,dim
其中 HiH_iHi 是历史种群的位置,XposX_{pos}Xpos 是初始种群的位置。dimdimdim 表示种群维度。posi,jpos_{i,j}posi,j 表示第 iii 个个体和第 jjj 个维度。每个个体的更新如下:
posi,j=posi,j+(ub−lb)×rand(1,dim)(2)pos_{i,j} = pos_{i,j} + (ub - lb) \times \text{rand}(1, dim) \tag{2}posi,j=posi,j+(ub−lb)×rand(1,dim)(2)
其中 ububub 是上界,lblblb 是下界。
表 2. 改进算法的类型和主要方法
| 年份 | 策略类型 | 主要方法 |
|---|---|---|
| 2020 | 通用策略 | 辅助解选择方案的优化 |
| 2020 | 改进策略 | 复合变异策略和重启策略 |
| 2021 | 通用策略 | 选择性领先对立和动态对立 |
| 2022 | 改进策略 | 三角游走策略和莱维飞行游走策略 |
| 2023 | 通用策略 | 个体优化保留度量 |
| 2023 | 通用策略 | 引导学习策略 |
| 2023 | 通用策略 | 记忆回溯策略 |
| 2023 | 改进策略 | Q-学习机制 |
| 2023 | 改进策略 | 层级策略 |
| 2023 | 通用策略 | 幽灵对立学习 |
| 2024 | 改进策略 | Halton 自适应二次插值和分段邻域 |
| 2024 | 改进策略 | 基于 Runge-Kutta 和 Golden sine 的策略 |
2.3. 经验共享阶段 (ESC)
在策略的经验共享阶段,种群中的每个个体都有很大的待搜索区域,每次搜索都可能找到更好的适应度值。因为原始算法使得找到更好的适应度值变得容易。因此,更新位置参考价值较弱。然而,一些算法在 ESC 中仍然无法收敛。因此,EES 在 ESC 中主要关注自身位置,并选择通过经验交换获得的两个位置进行交叉以获得更好的适应度值。图 1 是 EES 的 ESC 中公式的示意图。具体公式如下:
ESS_History_pos(j)={posi,j,if rand<0.85posi,j,otherwise(3)ESS\History\pos(j) = \begin{cases} pos{i,j}, & \text{if } rand < 0.85 \\ pos{i,j}, & \text{otherwise} \end{cases} \tag{3}ESS_History_pos(j)={posi,j,posi,j,if rand<0.85otherwise(3)
其中 ESS_History_posESS\_History\_posESS_History_pos 是经验交换的主公式,用于后期策略的经验交换。
在 ESC 阶段,选择两个有经验的个体来获得新位置。因为种群处于搜索的早期阶段,仍有许多待搜索区域未被探索,且种群搜索经验较少。此时,算法参考少量种群经验来更新位置,主要由原始算法的个体来探索新位置。如以下公式所示。
pos_ESS(i,:)=pos(i,:)+(ESC_History1_pos−ESC_History2_pos)×C(4)pos\_ESS(i,:) = pos(i,:) + (ESC\History{1\_pos} - ESC\History{2\_pos}) \times C \tag{4}pos_ESS(i,:)=pos(i,:)+(ESC_History1_pos−ESC_History2_pos)×C(4)
其中 pos_ESS(i,:)pos\_ESS(i,:)pos_ESS(i,:) 是更新后获得的新位置。CCC 是经验交换因子。CCC 根据不同的选择问题选择不同的常数,更有利于算法的收敛。ESC_History1_posESC\History{1\_pos}ESC_History1_pos 和 ESC_History2_posESC\History{2\_pos}ESC_History2_pos 从公式 (3) 获得。
ESC 可以为那些难以找到探索区域的算法找到更好的搜索位置,同时保证原算法的有效性。
2.4. 经验交叉阶段 (ECR)
随着搜索区域的不断探索,许多算法已经找到了更好的适应度值。此时,种群中的每个个体获得了大量的探索经验,不断获得的位置都向更好的适应度值移动。因此,更新位置具有很强的参考价值。而一些算法,由于更新公式的原因,导致种群被困在不同区域,无法找到更好的解。此时,通过根据不同的经验个体进行向上交叉来获得新位置。与 ESC 相比,ECR 多选择了一个经验个体。因为与 ESC 相比,ECR 使用了更多的经验个体,可以增强个体与种群之间的信息交换,从而获得更好的解。因此,在 ECR 中,EES 选择了三个通过经验交换获得的位置,并与自身位置进行交叉选择以获得更好的解。更新后的位置与其他位置不同,可以探索更多的区域。图 2 是 EES 的 ECR 公式示意图。具体公式如下:
pos_ECS(i,:)=pos(i,:)+(ECR_History1_pos−ECR_History2_pos)×(1−r1)×C(5)pos\_ECS(i,:) = pos(i,:) + (ECR\History{1\_pos} - ECR\History{2\_pos}) \times (1 - r_1) \times C \tag{5}pos_ECS(i,:)=pos(i,:)+(ECR_History1_pos−ECR_History2_pos)×(1−r1)×C(5)
其中 r1r_1r1 是一个 0 到 1 的随机数。ECR_History1_posECR\History{1\_pos}ECR_History1_pos 和 ECR_History2_posECR\History{2\_pos}ECR_History2_pos 从公式 (3) 获得。
ECR 通过经验在个体间交叉共享信息,提高了算法的搜索效率。根据 ECR,陷入局部最优的算法可以通过信息交叉获得新位置。这样,算法可以更准确地找到最优位置。
图 2. 经验交叉阶段的更新过程
2.5. 经验共享阶段 (ESH)
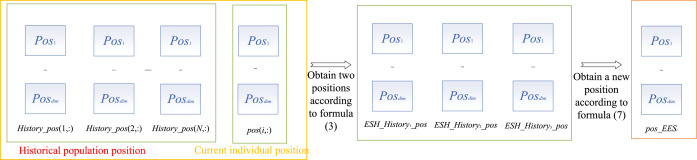
在 ESH 中,许多算法很难找到更好的位置,导致算法无法收敛。此时,种群中的每个个体都获得了大量的探索经验,更新位置具有很强的参考价值。经过长期的搜索,种群已经选择了一个好的区域进行探索,但仍需要更精细的搜索能力。与 ECR 相比,ESH 也选择三个经验个体来更新位置。这可以在保证复杂度不过高的同时,增强种群间的信息共享。与 ECR 不同,ESH 主要基于个体经验来寻找更细致的位置。因此,通过与一个经验个体取平均,可以增强当前个体与经验个体之间的信息共享。之后,将另外两个经验个体进行交叉相减,以寻找更精细的解。因此,在 ESH 中,EES 选择了三个通过经验交换获得的位置,并根据公式 (7) 获得新位置。通过使用公式 (7),更新后的位置与其他位置不同,可以探索更细致的位置。图 3 是 EES 的 ESH 中公式的示意图。
pos_ESH(i,:)=pos(i,:)+ESH_History1_pos/2+(ESH_History2_pos−pos(i,:))×r2×C(6)pos\_ESH(i,:) = pos(i,:) + ESH\History{1\_pos} / 2 + (ESH\History{2\_pos} - pos(i,:)) \times r_2 \times C \tag{6}pos_ESH(i,:)=pos(i,:)+ESH_History1_pos/2+(ESH_History2_pos−pos(i,:))×r2×C(6)
其中 r2r_2r2 是一个 0 到 1 的随机数。ESH_History1_posESH\History{1\_pos}ESH_History1_pos 和 ESH_History2_posESH\History{2\_pos}ESH_History2_pos 从公式 (3) 获得。
在 ESH 中,算法难以找到更好的位置。此时,通过个体之间的经验共享,新的个体可以在搜索区域进行更细致的搜索,并增强算法的开发能力。
图 3. 经验共享阶段的更新过程
Heming Jia, Honghua Rao, Experience Exchange Strategy: An evolutionary strategy for meta-heuristic optimization algorithms, Swarm and Evolutionary Computation, Volume 98,2025, 102082, https://doi.org/10.1016/j.swevo.2025.102082.