(本博客为Datawhale的baseLLM开源学习项目的学习笔记)
在前面的内容中,为了在消费级显卡上加载大模型,我们已经初步了解了量化技术的魔力--只需几行代码配置BitsAndBytesConfig,庞大的模型就能"塞"进显存。但我们还并不清楚这背后的int8或int4到底发生了什么以及除了微调时用到的BitsAndBytes,还有哪些量化技术更适合推理部署。
一、小资源干大活
1.冗余与压缩
量化,听起来是一个复杂的数学概念,但实际上非常简单,就是用较少的信息来表示数据,在尽量不损失模型性能的前提下,降低资源开销。深度学习模型(无论是CV还是NLP)普遍表现出显著的参数冗余性。早在1989年,Yann LeCun等人就在论文《Optimal Brain Damage》中指出神经网络中存在大量参数可以被删除而不影响准确率;而后续著名的"彩票假设"(The Lottery Ticket Hypothesis)更是进一步证明,密集网络中包含一个极小的子网络("中奖彩票")它的性能可与原始网络媲美。量化技术正是利用这一特性,通过降低非关键参数的数值精度(例如从FP16降至INT4)在大幅减少显存占用和计算量的同时,尽可能保持模型的原始性能。
比如一张原本几十MB的高清无损照片(如RAW格式),在压缩为几百KB的JPG格式后,虽然丢失了大量人眼难以察觉的色彩细节(精度降低)但我们依然能清晰地识别出照片中的人物和风景。这种现象说明原始数据中包含大量对于"视觉理解"来说非必须的冗余信息。量化的过程也是类似,我们试图找出模型参数中那些对最终输出影响不大的微小精度,将其削减,在大幅降低显存占用的同时,保留模型的核心能力,实现"瘦身不降智"。
2.量化的价值
量化技术主要带来两方面的巨大收益:
(1)**降低显存开销:**通常模型以FP16(16位浮点数)格式存储,若量化为INT8(8位整数),显存占用直接减半;若进一步量化为INT4(4位整数),显存占用仅为原来的1/4。原本需要多张A100才能加载的千亿模型,量化后可能只需一张消费级显卡即可运行。
(2)**提升推理速度:**数据量的减少意味着内存带宽(Memory Bandwidth)压力的降低。在LLM推理这种典型的"内存受限(Memory-bound)"场景下,更快的权重加载速度直接转化为更快的Token生成速度。
二、从"装不下"到"跑得动"
1.精度与显存的关系
模型权重通常以浮点数形式存储,不同的精度决定了每个参数占用的字节数:
FP32:单精度浮点数,占用4Bytes。这是深度学习训练的默认精度,但在推理时通常不需要这么高。
FP16/BF16:半精度浮点数,占用2Bytes。
FP16:传统的半精度,数值范围较小,容易溢出。
BF16:Google提出的格式,牺牲了小数位精度以换取与FP32相同的数值范围(指数位),训练更稳定,是目前大模型训练的主流选择。
INT8:8位整数,占用1Byte。
INT4:4位整数,占用0.5Byte(即4bit)
2.显存估算公式
再动手实践之前,我们需要学会如何估算一个模型到底需要多少显存。在计算机存储单位中,1GB = 1024MB,1MB = 1024KB。但在估算模型参数量(如7B = 7Billion)和显存(GB)时,为了方便,通常近似认为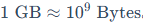 。如果追求精确计算,记得除以
。如果追求精确计算,记得除以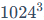 。模型所需显存大小的通用估算公式如下:
。模型所需显存大小的通用估算公式如下:
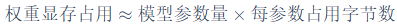
以之前训练过的Qwen2.5为例,这里选择Qwen2.5-7B(约70亿参数,即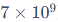 ):
):
(1)FP16/BF16精度(2 Bytes/参数):
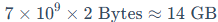
(2)INT8量化(1Byte/参数):
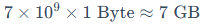
(3)INT4量化(0.5Byte/参数):
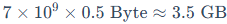
除了上述模型权重的静态占用,实际运行时还需要预留显存给KV Cache(上下文缓存)、激活值(中间层计算结果)、框架开销(pytorch/cuda)等。所以实际显存需求通常比估算高20%-30%。例如加载7B的INT4模型(3.5GB权重),推荐显存至少6GB起步。
三、Transformers中的主流集成方案
虽然量化方法层出不穷,但在Hugging Face Transformers的官方文档与实践中,最常用的三类集成方式是加载GPTQ、AWQ以及bitsandbytes(bnb)。在代码层面,它们通常通过AutoModel*.from_pretrained(..., quantization_config=...)搭配相应的配置类(如GPTQConfig、AwqConfig、BitsAndBytesConfig)实现相对统一的调用体验。
如果从使用场景来区分,GPTQ和AWQ主要面向推理部署与加速,它们属于PTQ(Post-Training Quantization)算法,生成的模型通常以量化后的检查点形式保存,加载后显存占用低且推理速度快。bitsandbytes则既常用于8bit/4bit推理,也是诸如QLoRA在内的一系列低显存微调方案的核心依赖,尤其擅长让大模型在单卡上完成4-bit训练。
1.面向生成式模型的高效量化
GPTQ(Generative Pre-trained Transformer Quantization)是一种面向大规模生成式Transformer的训练后量化(Post-Training Quantization,PTQ)技术。它是经典的OBQ(Optimal Brain Quantization)算法在超大模型上的高效进化版,基于近似二阶信息实现了一次性权重量化(one-shot weight quantization)。GPTQ解决了以往简单的"四舍五入"(Round-to-Nearest, RTN)量化在模型参数超过百亿级时会导致严重精度崩溃的问题,成功将1750亿参数的超大模型压缩至3-bit或4-bit,且几乎不损失精度。
GPTQ的量化目标是最小化量化前后激活值的平方误差:
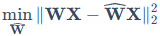
其中,W为原始权重矩阵,X为输入激活值矩阵, 为量化后的权重矩阵。
为量化后的权重矩阵。
GPTQ的成功依赖于三个关键机制:
(1)二阶信息补偿: 它利用海森矩阵(Hessian Matrix,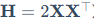 )的二阶信息来判断权重的重要性。这就是识别"冗余参数"的重要数学工具。海森矩阵描述了损失函数曲面的曲率,如果某个权重方向上的曲率很小(平坦),说明该权重的微小变化对总误差影响不大,它是相对"冗余"的;反之则是"关键"参数。GPTQ利用其逆矩阵
)的二阶信息来判断权重的重要性。这就是识别"冗余参数"的重要数学工具。海森矩阵描述了损失函数曲面的曲率,如果某个权重方向上的曲率很小(平坦),说明该权重的微小变化对总误差影响不大,它是相对"冗余"的;反之则是"关键"参数。GPTQ利用其逆矩阵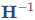 来更新剩余权重,以补偿当前权重量化带来的误差
来更新剩余权重,以补偿当前权重量化带来的误差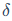 :
:
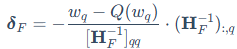
其中,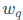 是当前被量化的权重,
是当前被量化的权重,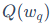 是其量化值,
是其量化值,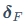 是对剩余未量化权重集合F的更新向量,
是对剩余未量化权重集合F的更新向量,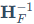 是对应当前未量化权重的海森矩阵逆矩阵。
是对应当前未量化权重的海森矩阵逆矩阵。
(2)**任意顺序与延迟批量更新:**GPTQ发现大模型不需要像OBQ那样进行昂贵的"贪心排序",只需要按顺序量化即可。同时,它引入了Lazy Batch-Updates(延迟批量更新)策略,将计算密集型的更新操作分块执行(如128列为一组),大大提升了GPU利用率。
(3)**Cholesky分解:**为了解决大模型下海森矩阵逆计算的数值不稳定性问题,GPTQ引入了Choleskey分解,确保了算法在千亿参数规模下的稳健运行。
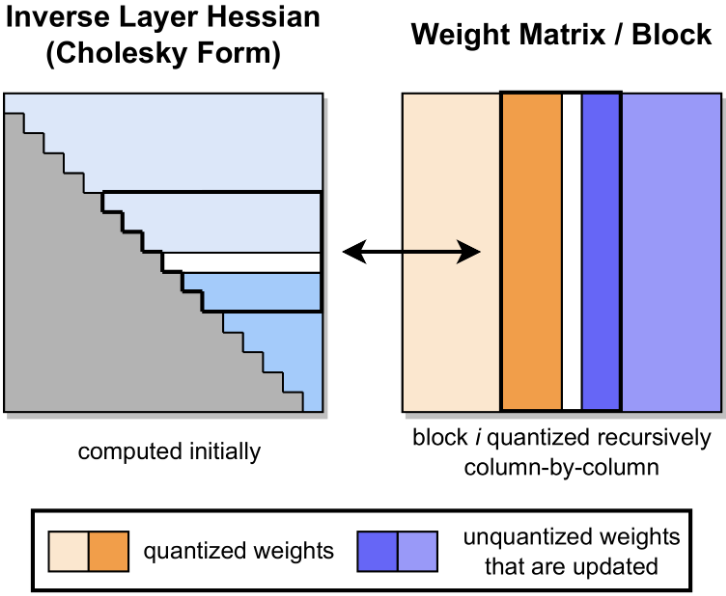
GPTQ的量化过程是分块进行的。如下图所示,加粗的列块(Block)表示当前正在处理的列。左侧灰色部分是利用Cholesky分解预先计算好的逆Hessian信息。在处理当前块(橙色部分)时,算法会递归地逐列量化(中间白色列),并将量化误差利用预计算的Hessian信息"推"给后续未量化的权重(右侧蓝色部分)进行更新补偿,从而最大程度保留模型精度。
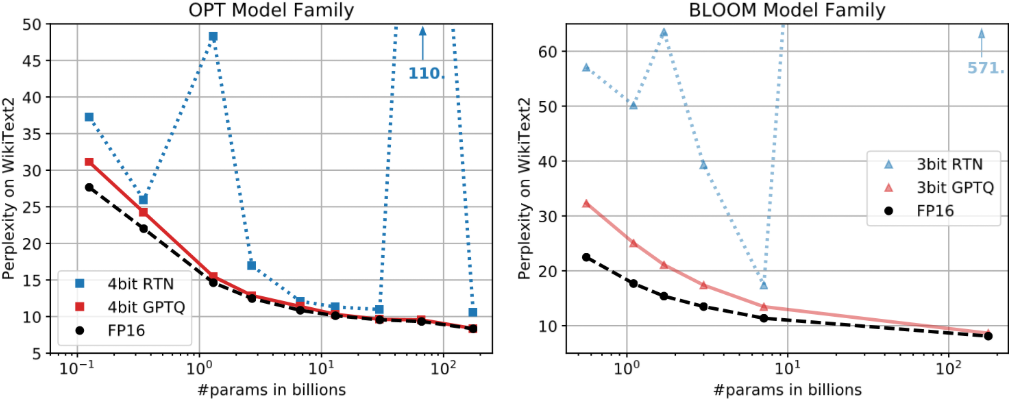
得益于上述优化,GPTQ能以极快的速度(如1750亿参数仅需4小时)完成量化。实验表明,模型规模越大,GPTQ带来的相对精度损失反而越小。如下图所示,在OPT模型家族中,随着参数量增加(横轴向右),传统RTN方法(蓝线)的困惑度(PPL)急剧上升,意味着模型"崩了";而GPTQ(红线)则紧贴全精度基线(黑虚线),展现了极强的鲁棒性。生成的INT4模型配合ExLlama等专用内核,推理速度可达FP16的3-4倍。
2.激活感知权重量化
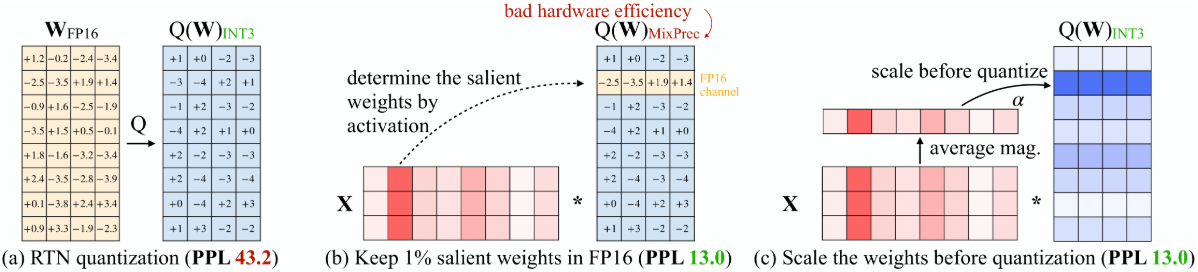
**AWQ(Activation-aware Weight Quantization)**提出了一种更符合直觉且高效的量化思路,特别适合端侧部署。与GPTQ依赖复杂的二阶信息进行误差补偿不同,AWQ另辟蹊径,发现权重的"重要性"并不取决于权重本身的大小,而取决于它所处理的激活值的大小。实验表明,仅保留1%的"显著权重"(即对应激活值较大的通道)为FP16精度,就能极大恢复模型性能。有趣的是,如果按权重本身的L2范数来选这1%,效果和随机选差不多;但如果按激活值增幅来选,效果立竿见影。
为了工程落地,AWQ并没有真正把这1%的权重存成FP16(混合精度会拖累推理速度),而是采用了一种精妙的数学等价变换。如下图所示,(a)中简单的RTN量化导致PPL高达43.2,模型基本"报废";(b)展示了如果保留1%显著权重为FP16,PPL能降回13.0,但混合精度效率低。AWQ的做法是(c)找出那些对应较大激活值的权重通道,给它们乘上一个放大系数s(Scale up),同时在输入x上除以s。
**原理:**在不改变线性层输出(例如y=wx)的前提下,将"重要通道"的权重按系数s放大、并将对应输入按1/s缩小,使得整体计算在数学上保持等价,但被放大的权重在量化时的相对误差更小
**效果:**当权重被放大后,其数值范围变大,相对量化误差(Relative Quantization Error)就会变小。AWQ的优化目标是找到一组最优的缩放因子s,使得量化误差最小:
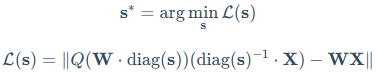
其中,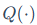 表示量化函数,W为原始权重,X为输入特征,s为我们需要寻找的最佳缩放因子向量,diag(s)是由s构成的对角矩阵。这就好比用一把尺子去量物体,把物体放大后再量,读数的相对精度自然就高了。最终AWQ在全INT量化下也能达到与混合精度相当的性能(PPL 13.0)。
表示量化函数,W为原始权重,X为输入特征,s为我们需要寻找的最佳缩放因子向量,diag(s)是由s构成的对角矩阵。这就好比用一把尺子去量物体,把物体放大后再量,读数的相对精度自然就高了。最终AWQ在全INT量化下也能达到与混合精度相当的性能(PPL 13.0)。
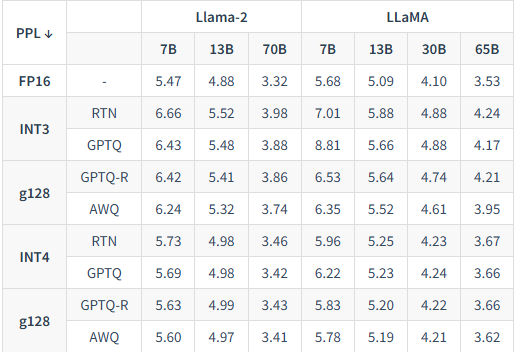
通过下表的实验结果可以看到,在Llama-2-7B/13B/70B等不同规模的模型上,AWQ(W4-g128)的困惑度始终低于RTN和GPTQ。特别是在70B模型上,AWQ的INT4量化效果(PPL 3.41)几乎与FP16全精度基线(PPL 3.32)持平,证明了其在保护模型性能方面的优越性。
在LLaMA、Mistral等模型上,AWQ的INT4量化几乎能达到FP16的无损性能水平。而且它具有端侧友好性,配合论文提出的TinyChat推理框架,作者展示了在高配Jetson Orin上以小batch形式运行Llama-2-70B的可能性;在树莓派等资源更受限的设备上,理论上也可以以INT4形式跑7B模型,但整体更偏Demo/实验性质,速度和体验都会受到一定限制。
3.BitsAndBytes(BNB)
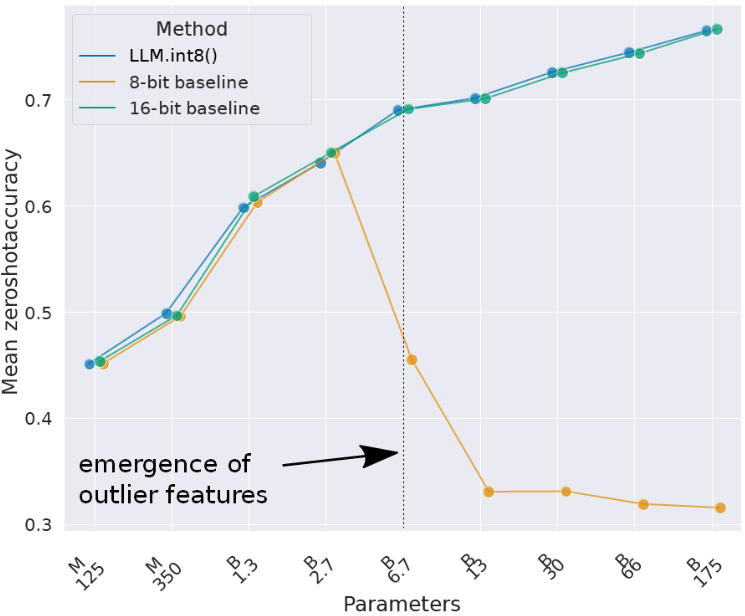
在之前的实践中,我们通过配置BitsAndBytesConfig轻松实现了4-bit量化加载。如果说GPTQ和AWQ是侧重于"精打细算"的量化算法,那么BNB则是承载了LLM.int8()和QLoRA等前沿研究的工程基石。它不仅是一个底层的CUDA库,更包含了一整套处理大模型量化难题的解决方案。BNB的主要贡献是解决了大模型量化中一个棘手的"离群值"问题。研究发现,当模型参数规模超过67亿(6.7B)时,Transformer层中会系统性地涌现出少量数值巨大的离群特征(Emergent Outliers)虽然这些特征只占所有参数的约0.1%,但它们对模型性能非常重要。传统的8-bit量化会将这些巨大的数值强制截断或粗糙量化,导致模型精度瞬间崩塌(如困惑度暴增)。如下图所示,在6.7B参数规模处,普通8-bit量化(橙线)的准确率急剧下降,而LLM.int8()(蓝线)则保持了与16-bit基线一致的性能。
LLM.int8()解决这一问题的主要原理是混合精度分解(Mixed-precision Decomposition) 。它就像一个智能筛子,在推理过程中动态探测特征值的大小。对于99.9%的常规数值,使用**向量级量化(Vector-wise Quantization)**把它们压缩为8-bit进行矩阵乘法,以节省显存:
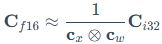
其中,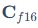 是近似的FP16的输出结果,
是近似的FP16的输出结果,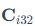 是INT8矩阵乘法得到的INT32结果,
是INT8矩阵乘法得到的INT32结果,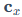 和
和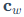 分别是输入X和权重W的量化缩放因子(Scaling Factors)。
分别是输入X和权重W的量化缩放因子(Scaling Factors)。
而对于那0.1%超过阈值(如6.0)的"离群"维度O,则自动拆分出来,保持FP16高精度计算。最后将两部分结果合并(见图13-5):
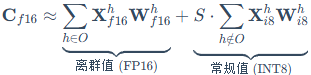
其中,h代表特征维度,O是离群特征维度的集合,S是去归一化项(对应上面的缩放因子乘积)。为了便于理解,这里对缩放因子、和S的张量维度及广播方式做了简化,实际工程实现中会针对batch/head/channel等维度分别维护缩放因子。
这种"抓大放小"的策略,让我们可以在几乎不损失任何精度的情况下,用INT8的显存开销运行超大模型。
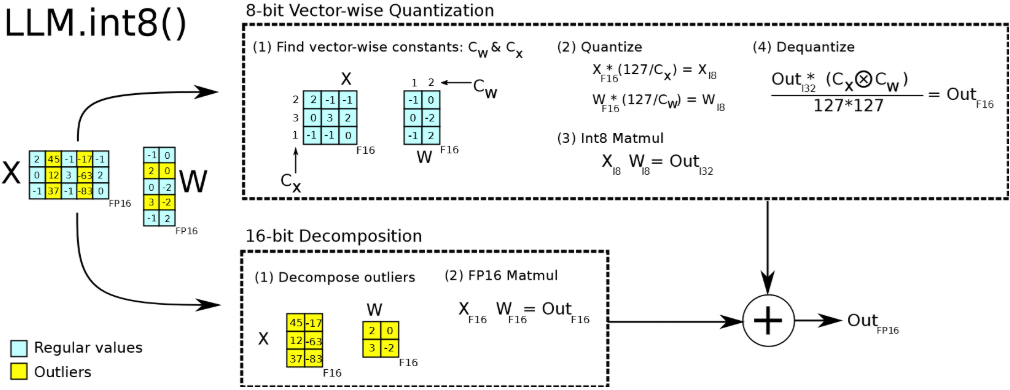
在此基础上,BNB进一步演进,成为了微调技术QLoRA的主要依赖。它引入了NormalFloat4(NF4)数据类型,这是一种专门为正态分布权重量身定制的4-bit类型,比标准的INT4具有更高的信噪比。如今,通过BitsAndBytesConfig,我们可以轻松调用这些技术,在单张消费级显卡上不仅能加载大模型,还能进行高效的微调。